前言
隨著圖形硬體變得越來越通用和可編程化,采用實時3D圖形渲染的應用程式已經開始探索傳統渲染管線的替代方案,以避免其缺點,其中一項最流行的技術就是所謂的延遲渲染,這項技術主要是為了支持大量的動態燈光,而不需要一套復雜的著色器程式,

為了迎接這一章的專案,會對原來的代碼有許多改動,并且會有許多引申的內容,
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什么問題也可以在這里匯報,
前向渲染(Forward Rendering)的問題
在設計渲染器時,最重要的一個方面是確定如何處理光照,這非常重要,因為它需要進行涉及到光照強度以及幾何體表面一點的反射顏色的計算,通常它包含如下步驟:
- 基于光照型別和衰弱屬性,確定哪些光照需要應用到當前的特定像素上
- 使用材質、表面屬性以及剛才確定需要用到的光照來為每個像素計算顏色
- 確定這些像素是否在陰影中,即光照是否能打到該像素,
這種傳統的處理方式通常叫做前向渲染,通過前向渲染,幾何體使用大量存盤在頂點屬性資料、紋理、常量緩沖區中的表面屬性來進行渲染,然后,根據輸入的幾何體對每個像素進行光柵化操作,結合材質資料對一個或多個燈光進行光照計算,最終的計算結果將輸出到每個像素中,并且可能與之前存在渲染目標的結果進行累加,這種方式是直接且直觀的,在可編程圖形硬體出現之前,它是實時3D圖形渲染的絕大部分方式,早期固定管線的GPU支持三種不同的光照型別:點光源、聚光燈、方向光,
而隨著實時渲染引擎的發展以適應可編程硬體和更復雜的場景,這些基本的光照型別由于其靈活性和普遍性,大部分都被保留了下來,然而,它們的使用方式已經開始顯示出它們的年邁,這是因為在現代硬體和API下,當它們開始支持大量的動態光源時,前向渲染暴露出幾項關鍵的弱點:
第一個缺點是,光源的使用與場景中繪制的幾何體的粒度(物件)掛鉤,換句話說,當我們開啟一個點光源,我們必須將其應用到在任何特定的繪制呼叫期間經過光柵化后的所有幾何體當中,一開始我們可能注意不到這會帶來什么樣的問題,尤其是我們在場景中只是添加了少數幾盞燈光,然而隨著光源數目的增長,著色器的計算量開始劇增,選擇性地應用光源就開始變得重要了,這么做是為了減少像素著色器中光照計算的執行次數,但因為我們只能在每次繪制之間完成光照的修改,導致我們在剔除不需要的燈光時受到了限制,那些燈光本應該只會影響到光柵化中的一小部分幾何體的情況,我們卻又不得不將那盞燈光應用到所有的幾何體,雖然我們可以將場景中的網格分割成更小的部分來提升粒度,但這增加了當前幀的繪制呼叫的數目(從而導致CPU開銷的提升),這還增加了需要確定光照是否影響網格的相交測驗的數目,給CPU帶來了更大的負擔,另一個相關的后果是我們在單批次渲染多個幾何體實體的能力將會降低,因為單批次中所有幾何體實體所使用的燈光數目必須是相同的,這些實體可能會出現在場景中的不同位置,它們本應該會受到不同燈光組合的影響,
另一個前向渲染的主要缺點是著色器程式的復雜性問題,為了控制大量的燈光和各種材質變化的燈光型別,可能會導致所需的著色器排列組合產生的數量激增,大量的著色器排列組合不是我們所期望的,因為這會增加記憶體的使用,以及著色器程式之間切換的開銷,由于依賴于這些組合怎么被編譯,它們還會顯著增加編譯的次數,使用多著色器程式的另一種選擇是使用動態流控制,這將影響GPU的性能,另一種方法是一次只渲染一個燈光,并將結果添加到渲染目標中,這稱為多通道渲染(multi-pass rendering),然而,這種方法需要為多次變換和光柵化幾何體付出代價,即便忽略掉與許多排列組合相關的問題,生成的像素著色器程式本身也可能變得非常昂貴和復雜,這是因為需要評估材質屬性并對所有活動的光源執行必要的照明和陰影計算,這會使得著色器程式難以撰寫、維護和優化,它們的性能還與場景的過度繪制有關,因為過度繪制會產生甚至不可見的著色像素,一個只使用z深度的預處理可以顯著減少過度繪制,但它的效率受到硬體中Hi-Z單元的實作的限制,著色器執行也會被浪費,因為像素著色器必須在至少2x2個四邊形中進行,這對于具有許多小三角形的高度細分場景尤其不利,
這些缺陷共同導致很難在場景中擴展動態光照的數目,同時為實時應用保持足夠的性能,然而如果你非常仔細地去看這些描述,你將會注意到所有這些缺陷根源自前向渲染固有的一個主要問題:光照與場景幾何圖形的光柵化緊密耦合,如果我們將這兩個步驟進行解耦,我們就有可能限制或完全繞過其中的一些缺點,仔細觀察光照程序中的第二步,我們可以發現為了計算光照,需要利用到材質屬性和幾何體表面屬性,這意味著如果我們有這樣一個步驟,在渲染程序中將所有需要的這些屬性放入一個緩沖區中(我們通常叫它為幾何緩沖區,或G-Buffer),緊接著我們就可以對所有場景中的燈光進行遍歷,并為每個像素計算出光照相關的值,這正是延遲渲染的前提,
使用RTX 2070 Mobile渲染帶1024點光源的Sponza場景,即便是開啟了預視錐體剔除,總體*均幀數僅有40幀:
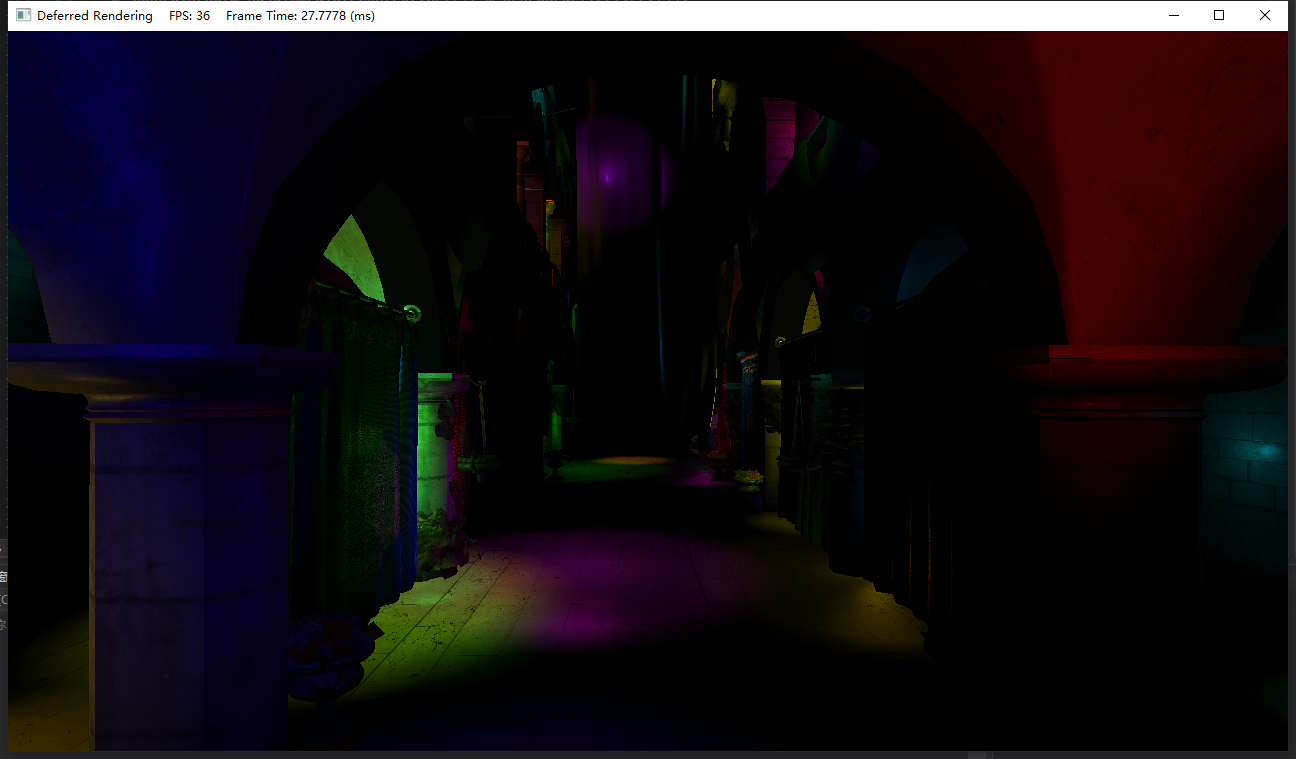
Pre-Z Pass/Depth Prepass
前向渲染也是有比較大的優化空間的,但現階段我們只講能夠很快實作的部分,
在繪制一個復雜場景的時候,可能會出現某些區域三角形反復覆寫繪制的情況,增加了很多不必要的繪制,為此我們可以在進行正式渲染前,先對場景中的物體只做深度測驗,不執行像素著色階段;然后第二遍場景繪制的時候只繪制和深度緩沖區中深度值相等的像素,這樣做可以有效減少像素著色器的執行次數,
Pre-Z Pass在C++端的代碼實作也十分簡單,具體可以參考專案中的代碼,
注意:在測驗幀數差距時務必使用Release模式,
延遲渲染管線
延遲渲染管線的第一步是幾何階段:渲染所有的場景幾何體到G-Buffer當中,這些緩沖區通常由一些渲染目標紋理所組成,但它們的各個通道用于逐像素存盤幾何體表面資訊,例如表面法向量和材質屬性等,
第二步是光照階段,在這一步中,可以將渲染表示為當前光照影響螢屏區域的幾何體的程序,對于每個待著色的像素片元,將從G-Buffer中采樣幾何體的資訊,然后與光照的屬性結合來確定對于該像素產生的光照貢獻值,再與所有其它影響那一像素的光源的貢獻值累加到一起,來確定最終表面的發光顏色,
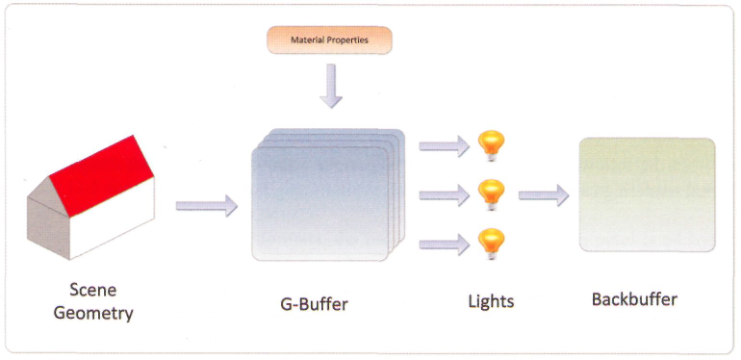
因為延遲渲染避免了前向渲染的主要缺陷(光照與幾何體緊密耦合),它擁有下面這些優勢:
- 著色器的組合數目將大幅減少,因為光照和陰影的計算可以移動到獨立的著色器程式中進行,
- 可以更加頻繁地批處理網格實體,因為我們在渲染場景幾何體的時候不再需要光照引數,所以,對于網格的所有實體,活動的光源可以不需要相同,
- 不再需要在CPU執行作業來確定哪些燈光影響螢屏的不同區域,取而代之的是,碰撞體或螢屏空間四邊形可以光柵化在燈光影響的螢屏部分上,深度和模板測驗也可以用于進一步減少著色器執行的次數,
- 總共需要的著色器和渲染框架體系可以被簡化,因為光照和幾何體已經被解耦了,
這些優勢使得延遲渲染在渲染引擎中非常流行,不幸的是,這種方法也會產生一些缺陷:
- 必須有大量的記憶體和帶寬專門用于G-Buffer的生成和采樣,因為它需要存盤計算該像素所需的任何資訊,
- 使用硬體MSAA變得困難,不是說使用延遲渲染就不能使用MSAA了,開啟MSAA可能意味著連同G-Buffer的占用空間也會成倍的提升,而且可能帶來顯著提升的計算負擔,
- 透明幾何體的處理不能以不透明幾何體處理的方式進行,因為它不能被渲染進G-Buffer,又因為G-Buffer僅僅能夠保存單個表面的屬性,且渲染透明幾何體需要計算為多個重疊的逐像素光照,并將計算顏色的結果結合起來,
- 如果使用BRDF材質模型的話,這種方式將變得不再簡單,因為計算像素最終的顏色已經被移到光照pass了
渲染相關的著色器
現假定我們的場景中只包含一系列的點光源,并且使用的是Phong光照模型,不引入陰影和SSAO,沒有透明物體,對于材質,我們只用到漫反射貼圖,
在幾何階段,有:
// ConstantBuffers.hlsl
cbuffer CBChangesEveryInstanceDrawing : register(b0)
{
matrix g_WorldInvTransposeView;
matrix g_WorldView;
matrix g_ViewProj;
matrix g_Proj;
matrix g_WorldViewProj;
}
cbuffer CBPerFrame : register(b1)
{
float4 g_CameraNearFar;
uint g_LightingOnly;
uint g_FaceNormals;
uint g_VisualizeLightCount;
uint g_VisualizePerSampleShading;
}
// Rendering.hlsl
//--------------------------------------------------------------------------------------
// 幾何階段
//--------------------------------------------------------------------------------------
Texture2D g_TextureDiffuse : register(t0);
SamplerState g_SamplerDiffuse : register(s0);
struct VertexPosNormalTex
{
float3 posL : POSITION;
float3 normalL : NORMAL;
float2 texCoord : TEXCOORD;
};
struct VertexPosHVNormalVTex
{
float4 posH : SV_POSITION;
float3 posV : POSITION;
float3 normalV : NORMAL;
float2 texCoord : TEXCOORD;
};
VertexPosHVNormalVTex GeometryVS(VertexPosNormalTex input)
{
VertexPosHVNormalVTex output;
output.posH = mul(float4(input.posL, 1.0f), g_WorldViewProj);
output.posV = mul(float4(input.posL, 1.0f), g_WorldView).xyz;
output.normalV = mul(float4(input.normalL, 0.0f), g_WorldInvTransposeView).xyz;
output.texCoord = input.texCoord;
return output;
}
對光照階段,有:
// Rendering.hlsl
float3 ComputeFaceNormal(float3 pos)
{
return cross(ddx_coarse(pos), ddy_coarse(pos));
}
struct SurfaceData
{
float3 posV;
float3 posV_DX;
float3 posV_DY;
float3 normalV;
float4 albedo;
float specularAmount;
float specularPower;
};
SurfaceData ComputeSurfaceDataFromGeometry(VertexPosHVNormalVTex input)
{
SurfaceData surface;
surface.posV = input.posV;
// 右/下相鄰像素與當前像素的位置差
surface.posV_DX = ddx_coarse(surface.posV);
surface.posV_DY = ddy_coarse(surface.posV);
// 該表面法線可用于替代提供的法線
float3 faceNormal = ComputeFaceNormal(input.posV);
surface.normalV = normalize(g_FaceNormals ? faceNormal : input.normalV);
surface.albedo = g_TextureDiffuse.Sample(g_SamplerDiffuse, input.texCoord);
surface.albedo.rgb = g_LightingOnly ? float3(1.0f, 1.0f, 1.0f) : surface.albedo.rgb;
// 將空漫反射紋理映射為白色
uint2 textureDim;
g_TextureDiffuse.GetDimensions(textureDim.x, textureDim.y);
surface.albedo = (textureDim.x == 0U ? float4(1.0f, 1.0f, 1.0f, 1.0f) : surface.albedo);
// 我們沒有藝術資產相關的值來設定下面這些,現在暫且設定成看起來比較合理的值
surface.specularAmount = 0.9f;
surface.specularPower = 25.0f;
return surface;
}
//--------------------------------------------------------------------------------------
// 光照階段
//--------------------------------------------------------------------------------------
struct PointLight
{
float3 posV;
float attenuationBegin;
float3 color;
float attenuationEnd;
};
// 大量的動態點光源
StructuredBuffer<PointLight> g_Light : register(t5);
// 這里分成diffuse/specular項方便后續延遲光照使用
void AccumulatePhong(float3 normal, float3 lightDir, float3 viewDir, float3 lightContrib, float specularPower,
inout float3 litDiffuse, inout float3 litSpecular)
{
float NdotL = dot(normal, lightDir);
[flatten]
if (NdotL > 0.0f)
{
float3 r = reflect(lightDir, normal);
float RdotV = max(0.0f, dot(r, viewDir));
float specular = pow(RdotV, specularPower);
litDiffuse += lightContrib * NdotL;
litSpecular += lightContrib * specular;
}
}
void AccumulateDiffuseSpecular(SurfaceData surface, PointLight light,
inout float3 litDiffuse, inout float3 litSpecular)
{
float3 dirToLight = light.posV - surface.posV;
float distToLight = length(dirToLight);
[branch]
if (distToLight < light.attenuationEnd)
{
float attenuation = linstep(light.attenuationEnd, light.attenuationBegin, distToLight);
dirToLight *= rcp(distToLight);
AccumulatePhong(surface.normalV, dirToLight, normalize(surface.posV),
attenuation * light.color, surface.specularPower, litDiffuse, litSpecular);
}
}
void AccumulateColor(SurfaceData surface, PointLight light,
inout float3 litColor)
{
float3 dirToLight = light.posV - surface.posV;
float distToLight = length(dirToLight);
[branch]
if (distToLight < light.attenuationEnd)
{
float attenuation = linstep(light.attenuationEnd, light.attenuationBegin, distToLight);
dirToLight *= rcp(distToLight);
float3 litDiffuse = float3(0.0f, 0.0f, 0.0f);
float3 litSpecular = float3(0.0f, 0.0f, 0.0f);
AccumulatePhong(surface.normalV, dirToLight, normalize(surface.posV),
attenuation * light.color, surface.specularPower, litDiffuse, litSpecular);
litColor += surface.albedo.rgb * (litDiffuse + surface.specularAmount * litSpecular);
}
}
// Forward.hlsl
//--------------------------------------------------------------------------------------
// 計算點光源著色
float4 ForwardPS(VertexPosHVNormalVTex input) : SV_Target
{
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
float3 litColor = float3(0.0f, 0.0f, 0.0f);
[branch]
// 用灰度表示當前像素接受的燈光數目
if (g_VisualizeLightCount)
{
litColor = (float(totalLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
for (uint lightIndex = 0; lightIndex < totalLights; ++lightIndex)
{
PointLight light = g_Light[lightIndex];
AccumulateColor(surface, light, litColor);
}
}
return float4(litColor, 1.0f);
}
ddx和ddy
對于ddx和ddy,在光柵化程序中,GPU會在同一時刻并行運行很多像素著色器(如32-64個一組)而不是逐像素來執行,然后這些像素將組織在2x2一組的像素分塊中,
這里的偏導數對應的是這一像素塊中的變化率,ddx就是拿右邊像素的值減去左邊像素的值,ddy則是拿下面像素的值減去上面像素的值,x和y為螢屏的坐標,
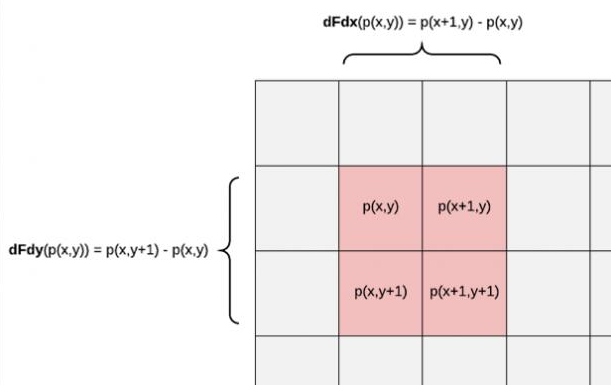
而ddx和ddy系列的函式只能用于像素著色器,是因為它需要依賴的是像素片元中的輸入資料來求偏導,
例如,若傳遞的是posH,則有:
\[dFdx(posH(x,y))=posH(x+1,y)-posH(x,y)==(1,0,z(x+1,y)-z(x,y),0) \]我們可以通過對位置求偏導,來求出該像素點處所屬三角表面的法線,
float3 ComputeFaceNormal(float3 pos)
{
return cross(ddx_coarse(pos), ddy_coarse(pos));
}
需要注意的是,通過這種方式求出來的法線,會和它對應三角面的所有像素用這種方式求出來的法線是*似相同的,但它不要求傳入的頂點有法線資料,因此它適用于頂點沒有法線屬性的情況,在有頂點法線時,三角面內的像素法線是通過插值得到到的,看起來表面就會比較光滑,

此外ddx/ddy還有精度較低的ddx_coarse/ddy_coarse和精度較高的ddx_fine/ddx_fine版本
實際上,在對紋理進行采樣時,選用哪一級的mipmap正是依賴于ddx和ddy的資訊,螢屏空間的貼圖uv偏導數過大表示貼圖理我們過遠,就會選擇mipLevel更高的子紋理,
經典延遲渲染
多渲染目標(Multiple Render Targets)
要使用延遲渲染,當前的圖形庫必須要能支持多渲染目標,在C++端,這是通過ID3D11DeviceContext::OMSetRenderTargets所提供的:
void ID3D11DeviceContext::OMSetRenderTargets(
UINT NumViews,
ID3D11RenderTargetView * const *ppRenderTargetViews,
ID3D11DepthStencilView *pDepthStencilView
);
對Direct3D 11來說,我們最多能夠同時設定八個RTV,即像素著色器最多能夠同時向八個紋理輸出資料,
在HLSL,我們需要通過SV_Target[n]來指定當前變數輸出到哪個渲染目標,例如:
struct PixelOut
{
float4 Normal_Specular : SV_Target0;
float4 Diffuse : SV_Target1;
};
PixelOut PS(PixelIn input)
{
// ...
}
G-Buffer布局的初設計
回看前面的前向渲染的著色器代碼,我們可以得知漫反射顏色、鏡面反射顏色的計算公式為:
\[Diffuse=Albedo\times lightContrib \times (N\cdot L)\\ Specular= specAmount\times Albedo \times lightContrib \times (R\cdot V)^{specPow}\\ R=reflect(L, N) \]這里只以物體的漫反射貼圖作為Albedo的貢獻部分,lightContrib受光照強度和衰弱的影響,而衰弱的計算需要用到光源位置與表面位置,在不考慮優化的情況下,G-Buffer需要存放的資訊有:
- 表面法線,3個float
- 漫反射系數Albedo,4個float
- 鏡面反射強度系數和材質光滑程度SpecPower,2個float
- 像素點所處的世界坐標,3個float
為了讓我們的G-Buffer包含所有需要用于計算上面公式的值,我們需要存盤12個不同的浮點數到我們的G-Buffer渲染目標當中,因為在一張紋理中,每個像素最多存盤4個值,我們使用3個G-Buffer就可以將它們全部存入,我們可以設計出如下的布局:
// | x | y | z | w |
// RT0: | Normal | SpecPower | float4
// RT1: | Albedo | float4
// RT2: | PositionV | SpecAmount | float4
// 注意:該版本的GBuffer與專案中的有差別
struct GBuffer
{
float4 normal_specPow : SV_Target0;
float4 albedo : SV_Target1;
float4 posV_specAmount : SV_Target2;
}
由于表面指向觀察點的向量是通過eyePosW - surface.posW求得的,轉換到觀察空間后,觀察點的坐標為原點,這樣只需要傳入surface.posV而不需要在常量緩沖區提供攝像機的eyePosW,但這樣光源需要傳入的也是light.posV,在光照計算時統一在觀察空間進行,
渲染程序
在幾何階段,我們使用GeometryVS著色器處理頂點,使用下面基礎版本的像素著色器將幾何資訊寫入到GBuffer:
// GBuffer.hlsl
//--------------------------------------------------------------------------------------
// G-buffer 渲染
//--------------------------------------------------------------------------------------
void GBufferPS(VertexPosHVNormalVTex input, out GBuffer outputGBuffer)
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
outputGBuffer.normal_specPow = float4(surface.normalV, surface.specularPower);
outputGBuffer.albedo = surface.albedo;
outputGBuffer.posV_specAmount = float4(surface.posV, surface.specularAmount);
}
然后在光照階段,我們的頂點著色器要能夠覆寫全屏,可以使用如下的代碼:
// FullScreenTriangle
// 使用一個三角形覆寫NDC空間
// (-1, 1)________ (3, 1)
// | | /
// (-1,-1)|___|/ (1, -1)
// | /
// (-1,-3)|/
float4 FullScreenTriangleVS(uint vertexID : SV_VertexID) : SV_Position
{
float4 output;
float2 grid = float2((vertexID << 1) & 2, vertexID & 2);
float2 xy = grid * float2(2.0f, -2.0f) + float2(-1.0f, 1.0f);
return float4(xy, 1.0f, 1.0f);
}
這樣通過一個超大的三角形覆寫NDC空間,并且不需要提供輸入布局和頂點緩沖區資料:
deviceContext->IASetInputLayout(nullptr);
deviceContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
deviceContext->IASetVertexBuffers(0, 0, nullptr, nullptr, nullptr);
// ...
deviceContext->Draw(3, 0);
像素著色器的基礎版本如下:
// Rendering.hlsl
struct SurfaceData
{
float3 posV;
float3 posV_DX; // 忽略
float3 posV_DY; // 忽略
float3 normalV;
float4 albedo;
float specularAmount;
float specularPower;
};
// GBuffer.hlsl
SurfaceData ComputeSurfaceDataFromGBuffer(uint2 posViewport)
{
// 從GBuffer讀取資料
GBuffer rawData;
rawData.normal_specPow = g_GBufferTextures[0].Load(posViewport.xy).xyzw;
rawData.albedo = g_GBufferTextures[1].Load(posViewport.xy).xyzw;
rawData.posV_specAmount = g_GBufferTextures[2].Load(posViewport.xy).xyzw;
// 解碼到合適的輸出
SurfaceData data;
data.posV = rawData.posV_specAmount.xyz;
data.specularPower = rawData.posV_specAmount.w;
data.normalV = rawData.normal_specPow.xyz;
data.specularAmount = rawData.normal_specPow.w;
data.albedo = rawData.albedo;
return data;
}
// BasicDeferred.hlsl
// posViewport表示的是(螢屏坐標xy + 0.5偏移, NDC深度, 1)
float4 BasicDeferredPS(float4 posViewport : SV_Position) : SV_Target
{
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
float3 lit = float3(0.0f, 0.0f, 0.0f);
[branch]
if (g_VisualizeLightCount)
{
// 用亮度表示該像素會被多少燈光處理
lit = (float(totalLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGBuffer(uint2(posViewport.xy));
// 避免對天空盒/背景像素著色
if (surface.posV.z < g_CameraNearFar.y)
{
for (uint lightIndex = 0; lightIndex < totalLights; ++lightIndex)
{
PointLight light = g_Light[lightIndex];
AccumulateColor(surface, light, lit);
}
}
}
return float4(lit, 1.0f);
}
渲染完場景后,還需要進行天空盒的渲染,現在的天空盒著色器代碼基礎版本為:
// SkyboxToneMap.hlsl
//--------------------------------------------------------------------------------------
// 使用天空盒幾何體渲染
//--------------------------------------------------------------------------------------
TextureCube<float4> g_SkyboxTexture : register(t5);
Texture2D<float> g_DepthTexture : register(t6);
// 場景渲染的紋理
Texture2D<float4> g_LitTexture : register(t7);
struct SkyboxVSOut
{
float4 posViewport : SV_Position;
float3 skyboxCoord : skyboxCoord;
};
SkyboxVSOut SkyboxVS(VertexPosNormalTex input)
{
SkyboxVSOut output;
// 注意:不要移動天空盒并確保深度值為1(避免裁剪)
output.posViewport = mul(float4(input.posL, 0.0f), g_ViewProj).xyww;
output.skyboxCoord = input.posL;
return output;
}
float4 SkyboxPS(SkyboxVSOut input) : SV_Target
{
uint2 coords = input.posViewport.xy;
float3 lit = float3(0.0f, 0.0f, 0.0f);
float depth = g_DepthTexture.Load(coords);
// 檢查天空盒的狀態(注意:反轉Z!)
// 如果不使用反轉Z,則為depth >= 1.0f
[branch]
if (depth <= 0.0f && !g_VisualizeLightCount)
lit += g_SkyboxTexture.Sample(g_SamplerDiffuse, input.skyboxCoord).xyz;
else
lit += sampleLit;
return float4(lit, 1.0f);
}
這些著色器不是最終的版本,
由于渲染一幀的作業量主要來源于像素片元的執行數量和每個像素片元計算用到的光源數量,目前版本的延遲渲染相比前向渲染已經能夠減少像素片元的數量,但即便如此,基礎的延遲著色法的運行效率依然是低效的,因為目前我們渲染的每個像素仍然與場景中的所有光源所系結,提升燈光數量都會引起渲染一幀作業量的顯著增加,
此外,回顧之前的G-Buffer,如果這些元素都使用float4來存盤的話,那么每渲染一個像素就需要駐留48位元組,渲染1280x720解析度需要占用42.2MB顯存,而渲染1920x1080解析度需要占用94.9MB顯存,每幀都要駐留差不多100M的顯存用于主要渲染,占用了比較多的顯存帶寬,對性能也會有一定的影響,當然,后續我們可以想辦法對這些資料想辦法進行一些處理,降低顯存帶寬的占用,
這樣我們對延遲渲染的優化有兩個確定的方向:
- 降低G-Buffer的占用空間及減少像素著色器的輸出量
- 盡可能去掉對當前像素片元沒有影響的光源以減少運算量
在這一章我們將討論前者,下一章則對后者進行討論,
G-Buffer相關的優化
由于延遲渲染需要同時對一到多個渲染目標進行輸出,這會占用較大的顯存帶寬,如果我們能降低輸出的數目,這意味著能減小顯存帶寬的占用,以及G-Buffer所占用的顯存空間, 為了降低G-Buffer的空間,我們可能會采用一些數學方法進行壓縮/解壓處理,即便這帶來了更多的運算量,得益于現代GPU龐大的運算單元,使得給GPU進行更多運算帶來的收益比增加顯存帶寬的占用要大得多,基于這個思想,我們將對存盤在G-Buffer中的資料,基于他們的值域、精度需求、打包/解包的開銷來尋找合適的存盤型別,
法向量
對于法線的壓縮,我們有兩種方向:
- 和之前的法線貼圖有點類似,我們可以將其用有符號8位整數來存盤(如
DXGI_FORMAT_R8G8B8A8_SNORM) - 考慮到法線是單位長度,我們可以考慮只用2個float來存盤
在這里由于我們有SpecPower和SpecAmount兩個float,選擇第二種方式似乎是一個不錯的選擇,可以構成float4,并且我們實際上可以用DXGI_FORMAT_R16G16B16A16_FLOAT來減少8位元組的占用,
考慮到法線的性質,我們可以用球面坐標系來表示一個法線,壓縮/解壓方式如下:
float2 CartesianToSpherical(float3 normal)
{
float2 s;
s.x = atan2(normal.y, normal.x) / 3.14159f;
s.y = normal.z;
return s;
}
float3 SphericalToCartesian(float2 p)
{
float2 sinCosTheta, sinCosPhi;
sincos(p.x * 3.14159f, sinCosTheta.x, sinCosTheta.y);
sinCosPhi = float2(sqrt(1.0f - p.y * p.y), p.y);
return float3(sinCosTheta.y * sinCosPhi.x,
sinCosTheta.x * sinCosPhi.x,
sinCosPhi.y
);
}
這種方式的主要缺點在于它需要使用三角函式(sin,cos,atan2),這些三角函式對運算單元的負擔會比較大,如果能有其它的方法避免三角函式的話會更好一些
另一種辦法是使用spheremap transformation,這種變換原來是用于將反射向量映射到[0, 1]范圍,但它也適用于法向量,它的作業原理是存盤在映射上的二維位置,每個位置對應球上的一個法線,具體做法如下:
float2 EncodeSphereMap(float3 normal)
{
return normalize(normal.xy) * (sqrt(-normal.z * 0.5f + 0.5f));
}
float3 DecodeSphereMap(float2 encoded)
{
float4 nn = float4(encoded, 1, -1);
float l = dot(nn.xyz, -nn.xyw);
nn.z = l;
nn.xy *= sqrt(l);
return nn.xyz * 2 + float3(0, 0, -1);
}
編碼程序:
\[x'=\frac{x}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)}\\ y'=\frac{y}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)}\\ \]解碼程序:
\[l=1-(x')^2-(y')^2=1-0.5(1-z)=0.5(1+z)\\ \sqrt{1-z^2}=\sqrt{x^2+y^2}\\ 2x'\sqrt{l}=\frac{2x}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)\cdot0.5(1+z)}=x\\ 2y'\sqrt{l}=\frac{2y}{\sqrt{x^2+y^2}}\cdot\sqrt{0.5(1-z)\cdot0.5(1+z)}=y\\ 2\cdot l-1=z \]整個運算程序最多就再用到開方,總體效率也比較理想,
漫反射顏色
由于顏色的值域通常在[0, 1],這意味著我們可以使用無符號規格化的8位整數格式DXGI_FORMAT_R8G8B8A8_UNORM來存盤,當然也可以將顏色值保存在sRGB空間,因為這通常用于漫反射紋理的存盤格式,使用DXGI_FORMAT_R8G8B8A8_UNORM_SRGB會讓硬體對像素著色器的輸出執行sRGB轉換,還有就是如果alpha通道不怎么需要用到的話也可以用DXGI_FORMAT_R10G10B16A2_UNORM來提升RGB的精度
注意:sRGB指的是標準的RGB顏色空間,通常用于影像檔案和顯示設備,使用sRGB使更多的精度用于較暗的顏色值,符合人類眼睛對這些顏色區域的自然敏感性
位置
位置通常需要高精度,且它要用于高頻陰影計算/光照計算中,為了存盤世界空間或觀察空間中的坐標,甚至16位的浮點數格式通常不足以避免Artifacts,幸運的是,我們還有別的方式存盤完整的XYZ值,在執行像素著色器的時候,螢屏空間坐標XY是可以通過SV_Position語意取得的,然后在渲染場景幾何體的時候,通過用到的觀察變換和投影變換矩陣是有可能恢復出觀察空間或世界空間的坐標的,
對螢屏中的任意一個像素,都有一個表示從攝像機到像素位置對應遠*面一點的方向向量,我們可以利用螢屏空間XY坐標來根據視錐體遠*面的四個角點進行線性插值來構建方向向量,然后標準化(如果你在觀察空間做這件事的話,就不需要再減去攝像機的位置),如果幾何體光柵化在當前像素位置,這意味著當前表面通過之前構建的方向向量從攝像機方向移動是可以接觸到的,我們只要再有攝像機到表面的距離就可以構建出該表面的坐標了:
// 重建位置的程序,當前GBuffer需要提供一個float存盤攝像機到表面的距離
// GBuffer頂點著色器
vOut.posV = mul(PosL, g_WorldView).xyz;
// GBuffer像素著色器
gBuffer.distance.x = length(gBuffer.posV);
// 光照階段頂點著色器
vOut.ViewRay = posW - g_CamPosW;
// 光照階段像素著色器
float3 viewRay = normalize(pIn.viewRay);
float viewDistance = g_TextureDistance.Sample(g_Sam, pIn.tex);
float3 posW = g_CamPosW + viewRay * viewDistance;
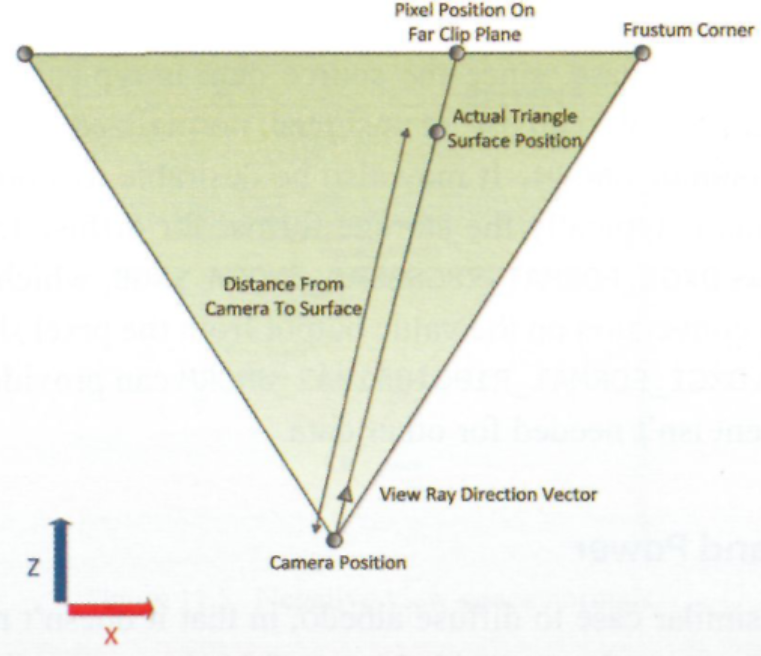
這為我們提供了一種靈活而又相當有效的方法,可以從存盤在G-Buffer中的單一高精度值中重建位置,
然而如果我們只考慮觀察空間的話,仍可以做進一步的優化:我們有辦法避免存盤多一個值,即通過透視投影的引數,我們可以從螢屏空間反推到觀察空間,仔細觀察下面的透視投影變換:
\[\begin{align} [x,y,z,1]\begin{bmatrix} m_{00} & 0 & 0 & 0 \\ 0 & m_{11} & 0 & 0 \\ 0 & 0 & m_{22} & 1 \\ 0 & 0 & m_{32} & 0 \\ \end{bmatrix}&=[m_{00}x,m_{11}y,m_{22}z+m_{32},z]\\ &\Rightarrow[\frac{m_{00}x}{z},\frac{m_{11}y}{z},m_{22}+\frac{B}{m_{32}}, 1] \end{align}\\ z_{ndc}=m_{22}+\frac{m_{32}}{z} \]其中ndc坐標我們可以通過像素著色器輸入的螢屏坐標和螢屏寬高的資訊求出來,這樣逆變換的條件也足夠了:
\[z=\frac{m_{32}}{z_{ndc}-m_{22}}\\ x=\frac{x_{ndc}\cdot z}{m_{00}}\\ y=\frac{y_{ndc}\cdot z}{m_{11}} \]在著色器代碼中,重建觀察空間坐標的方式如下:
float3 ComputePositionViewFromZ(float2 posNdc, float viewSpaceZ)
{
float2 screenSpaceRay = float2(posNdc.x / g_Proj._m00,
posNdc.y / g_Proj._m11);
float3 posV;
posV.z = viewSpaceZ;
posV.xy = screenSpaceRay.xy * posV.z;
return posV;
}
// ...
float2 gbufferDim;
uint dummy;
g_GBufferTextures[0].GetDimensions(gbufferDim.x, gbufferDim.y, dummy);
float2 screenPixelOffset = float2(2.0f, -2.0f) / gbufferDim;
float2 posNdc = (float2(posViewport.xy) + 0.5f) * screenPixelOffset.xy + float2(-1.0f, 1.0f);
// ndcZ = A + B/z => z = B/(ndcZ - A)
float viewSpaceZ = g_Proj._m32 / (ndcZ - g_Proj._m22);
float3 posV = ComputePositionViewFromZ(posNdc, viewSpaceZ);
反向Z(Reversed-Z)
然后是深度值的問題,觀察空間的深度值在經過透視投影后變為:
\[d=a\frac{1}{z}+b \]其中a,b與*/遠*面的設定關聯,把重映射后的深度值等距采樣,在該函式的影像如下:
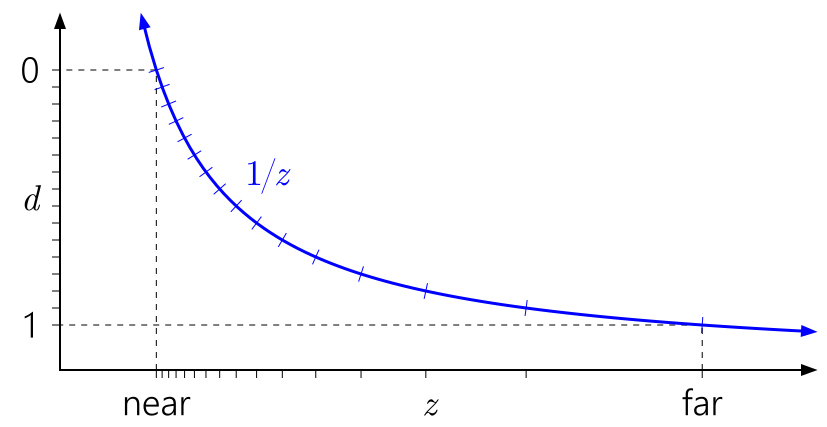
可以看到d的大部磁區域落在了**面上,然而考慮浮點數的精度問題,它的數值分布大部分也是落在0上,如果選出浮點數能表示的0-1范圍的所有d值,對應的圖如下:
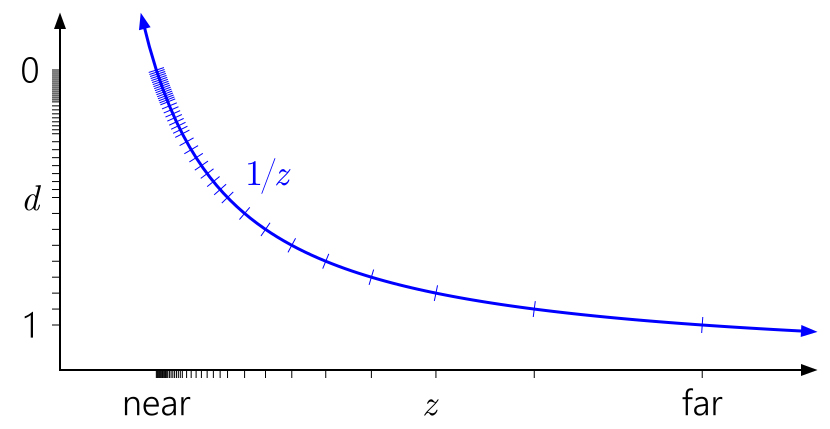
經過映射后發現這種現象被加劇了,絕大部分的點都被映射到**面上,這是一種浪費,且靠* 遠*面 的z值,在經過映射后得到的d,受到精度的限制變得會更加難以區分,使得多個相*的深度值被映射到同一個d值的可能性被放大,導致出現Z-Fighting的問題,
一種廣為人知的方法為反向Z,讓**面映射到d=1,遠*面映射到d=0:
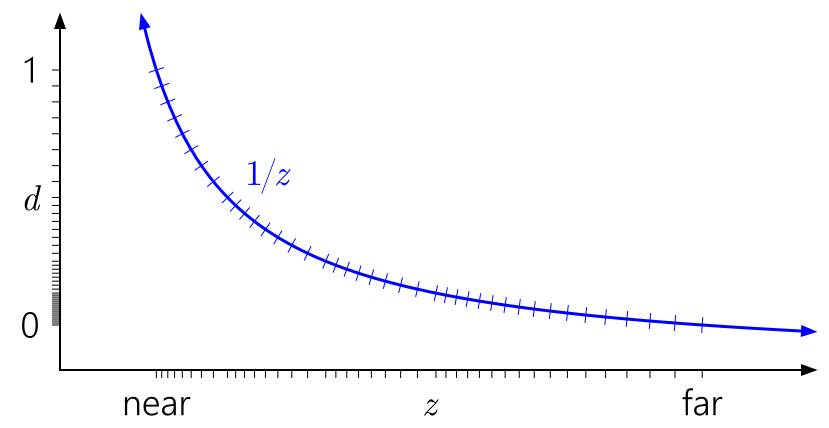
可以看到,反向Z可以利用浮點數的特性,讓其在靠* 遠*面 的分布也能變得較為均勻,從而較為良好地抵消掉重映射所帶來的影響,這可以使Z-Fighting出現問題的可能性大幅降低,
我們只需要:
- 在C++代碼中將視錐體的*/遠*面對調:
m_pCamera->SetFrustum(XM_PI / 3, AspectRatio(), 300.0f, 0.5f);
- 在清空深度緩沖區時用0清空:
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthBuffer->GetDepthStencil(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 0.0f, 0);
- 在深度測驗時使用>=比較方式(使用>=是為了兼容Forward PreZ-Pass,在實際繪制時能同時處理>和=的情況):
m_pd3dImmediateContext->SetDepthStencilState(RenderStates::DSSGreaterEqual.Get(), 0);
- 但是在構造碰撞視錐體的時候,別忘了把*/遠*面交換回來:
BoundingFrustum::CreateFromMatrix(frustum, DirectX::XMMatrixPerspectiveFovLH(m_pCamera->GetFovY(),
m_pCamera->GetAspectRatio(), m_pCamera->GetFarZ(), m_pCamera->GetNearZ()));
多重采樣
首先復習一下超采樣(SSAA),現渲染WxH大小的螢屏,為了降低走樣/鋸齒的影響,可以使用2倍寬高的后備緩沖區及深度緩沖區,光柵化的操作量增大到了4倍左右,同樣像素著色器的執行次數也增大到了原來的4倍左右,每個2x2的像素塊對應原來的1個像素,通過對這2x2的像素塊求*均值得到目標像素的顏色,
多重采樣(MSAA)采用的是一種較為折中的方案,以4xMSAA為例,指的是單個像素需要按特定的模式對周圍采樣4次:

假定當前像素位置為(x+0.5,y+0.5),在D3D11定義的采樣模式下,這四個采樣點的位置為:(x+0.375, y+0.125)、(x+0.875, y+0.375)、(x+0.125, y+0.625)、(x+0.625, y+0.875)
在光柵化階段,在一個像素區域內使用4個子采樣點,但每個像素仍只執行1次像素著色器的計算,這4個子采樣點都會計算自己的深度值,然后根據深度測驗和三角形覆寫性測驗來決定是否復制該像素的計算結果,為此深度緩沖區和渲染目標需要的空間依然為原來的4倍,
假設三角形1覆寫了2-3號采樣,且通過了深度測驗,則2-3號采樣復制像素著色器得到的紅色,此時渲染三角形2覆寫了1號采樣,且通過了深度測驗,則1號采樣復制像素著色器得到的藍色,在渲染完三角形后,對這四個采樣點的顏色進行一個resolve操作,可以得到當前像素最終的顏色,這里我們可以認為是對這四個采樣點的顏色求*均值,
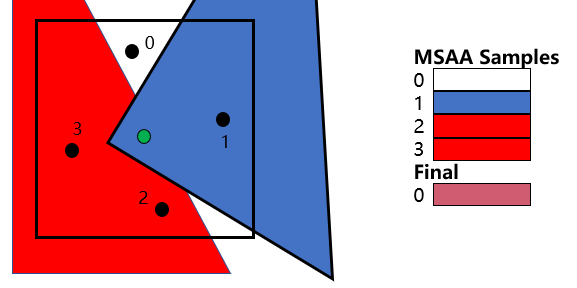
ID3D11DeviceContext::ResolveSubresource方法--將多重采樣的資源復制到非多重采樣的資源
void ID3D11DeviceContext::ResolveSubresource(
ID3D11Resource *pDstResource, // [In]目標非多重采樣資源
UINT DstSubresource, // [In]目標子資源索引
ID3D11Resource *pSrcResource, // [In]源多重采樣資源
UINT SrcSubresource, // [In]源子資源索引
DXGI_FORMAT Format // [In]決議成非多重采樣資源的格式
);
該API最常用于需要將當前pass的渲染目標結果作為下一個pass的輸入,源/目標資源必須擁有相同的資源型別和相同的維度,此外,它們必須擁有兼容的格式:
- 已經確定的型別則要求必須相同:比如兩個資源都是
DXGI_FORMAT_R8G8B8A8_UNORM,在Format中一樣要填上 - 若有一個型別確定但另一個型別不確定:比如兩個資源分別是
DXGI_FORMAT_R32_FLOAT和DXGI_FORMAT_R32_TYPELESS,在Format引數中必須指定DXGI_FORMAT_R32_FLOAT - 兩個不確定型別要求必須相同:如
DXGI_FORMAT_R32_TYPELESS,那么在Format引數中可以指定DXGI_FORMAT_R32_FLOAT或DXGI_FORMAT_R32_UINT等
若后備緩沖區創建的時候指定了多重采樣,正常渲染完后到呈現(Present)時會自動呼叫ResolveSubresource方法得到用于顯示的非多重采樣紋理,當然這僅限于交換鏈使用的是BLIT模型而非FLIP模型,因為翻轉模型的后備緩沖區不能使用多重采樣紋理,要使用MSAA我們需要另外新建一個等寬高的MSAA紋理先渲染到此處,然后ResolveSubresource到后備緩沖區,
讀取多重采樣資源
前面我們已經知道了如果創建多重采樣資源并作為渲染目標使用,而為了能夠在著色器使用多重采樣紋理,需要在HLSL宣告如下型別的資源:
Texture2DMS<type, sampleCount> g_Texture : register(t*)
非多重采樣的紋理設定的sampleCount是1,除了Texture2D型別,還可以傳入到Texture2DMS<float4, 1>中使用
Texture2DMS型別只支持讀取,不支持采樣:
T Texture2DMS<T>::Load(
in int2 coord,
in int sampleIndex
);
延遲著色+MSAA
延遲著色與多重采樣的兼容性并不是很好,但不代表延遲著色不能使用多重采樣,當然使用FXAA/TAA這些后處理會更好都是后話,現在需要補充多重采樣與Direct3D 11相關的應用內容,
給延遲著色添加多重采樣實際上是在幾何階段進行的,光照階段完成的相當于是Resolve的操作,渲染流程如下:
-
在幾何階段:
- 創建同等MSAA采樣頻率的G-Buffer,然后將幾何資訊渲染到G-Buffer中
-
在光照階段:
- 通過模板寫入,標記出需要應用逐樣本著色的區域(Per-Sample Shading),因為這是一件開銷較大的事情
- 利用模板測驗,在不需要逐樣本著色的區域,我們使用樣本0進行像素著色
- 同樣利用模板測驗,在需要逐樣本著色的區域,對每個樣本都呼叫像素著色
- 完成光照MSAA緩沖區的渲染后,我們在繪制天空盒時,對處于遠*面的像素繪制天空盒的顏色;否則讀取MSAA緩沖區在當前像素位置所有樣本的顏色來完成Resolve,
逐樣本著色(Per-Sample Shading)
如果我們對全屏區域進行逐樣本著色,那本質上進行的就是SSAA(超采樣)了,而真正需要逐樣本著色的地方通常是位于物體邊界的情況,逐樣本著色的像素著色器需要添加SV_SampleIndex:
float4 PS(float4 posViewPort : SV_Position, uint sampleIndex : SV_SampleIndex) : SV_Target
{
// ...
}
G-Buffer布局
目前的GBuffer布局如下:
struct GBuffer
{
float4 normal_specular : SV_Target0; // R16G16B16A16_FLOAT
float4 albedo : SV_Target1; // R8G8B8A8_UNORM
float2 posZGrad : SV_Target2; // R16G16_FLOAT
};
其中新增的posZGrad用于后面的逐樣本繪制需求檢測,目前這套G-Buffer每個像素只需要占據16位元組,相比原來的48位元組已經少了2/3的顯存占用,當然,如果使用了4xMSAA又要開多4倍的顯存,
幾何階段
幾何階段的著色器如下:
//
// 源自Rendering.hlsl
//
VertexPosHVNormalVTex GeometryVS(VertexPosNormalTex input)
{
VertexPosHVNormalVTex output;
output.posH = mul(float4(input.posL, 1.0f), g_WorldViewProj);
output.posV = mul(float4(input.posL, 1.0f), g_WorldView).xyz;
output.normalV = mul(float4(input.normalL, 0.0f), g_WorldInvTransposeView).xyz;
output.texCoord = input.texCoord;
return output;
}
//
// GBuffer.hlsl
//
struct GBuffer
{
float4 normal_specular : SV_Target0;
float4 albedo : SV_Target1;
float2 posZGrad : SV_Target2; // ( d(x+1,y)-d(x,y), d(x,y+1)-d(x,y) )
};
// 法線編碼
float2 EncodeSphereMap(float3 normal)
{
return normalize(normal.xy) * (sqrt(-normal.z * 0.5f + 0.5f));
}
//--------------------------------------------------------------------------------------
// G-buffer 渲染
//--------------------------------------------------------------------------------------
void GBufferPS(VertexPosHVNormalVTex input, out GBuffer outputGBuffer)
{
SurfaceData surface = ComputeSurfaceDataFromGeometry(input);
outputGBuffer.normal_specular = float4(EncodeSphereMap(surface.normalV),
surface.specularAmount,
surface.specularPower);
outputGBuffer.albedo = surface.albedo;
outputGBuffer.posZGrad = float2(ddx_coarse(surface.posV.z),
ddy_coarse(surface.posV.z));
}
頂點著色器使用GeometryVS,像素著色器使用GBufferPS,然后開啟>或>=深度測驗比較
光照階段
使用模板標記出需要應用逐樣本著色的區域
// GBuffer.hlsl
struct GBuffer
{
float4 normal_specular : SV_Target0;
float4 albedo : SV_Target1;
float2 posZGrad : SV_Target2; // ( d(x+1,y)-d(x,y), d(x,y+1)-d(x,y) )
};
// 上述GBuffer加上深度緩沖區(最后一個元素) t1-t4
Texture2DMS<float4, MSAA_SAMPLES> g_GBufferTextures[4] : register(t1);
// 檢查一個給定的像素是否需要進行逐樣本著色
bool RequiresPerSampleShading(SurfaceData surface[MSAA_SAMPLES])
{
bool perSample = false;
const float maxZDelta = abs(surface[0].posV_DX.z) + abs(surface[0].posV_DY.z);
const float minNormalDot = 0.99f; // 允許大約8度的法線角度差異
[unroll]
for (uint i = 1; i < MSAA_SAMPLES; ++i)
{
// 使用三角形的位置偏移,如果所有的采樣深度存在差異較大的情況,則有可能屬于邊界
perSample = perSample ||
abs(surface[i].posV.z - surface[0].posV.z) > maxZDelta;
// 若法線角度差異較大,則有可能來自不同的三角形/表面
perSample = perSample ||
dot(surface[i].normalV, surface[0].normalV) < minNormalDot;
}
return perSample;
}
// 使用逐采樣(1)/逐像素(0)標志來初始化模板掩碼值
void RequiresPerSampleShadingPS(float4 posViewport : SV_Position)
{
SurfaceData surfaceSamples[MSAA_SAMPLES];
ComputeSurfaceDataFromGBufferAllSamples(uint2(posViewport.xy), surfaceSamples);
bool perSample = RequiresPerSampleShading(surfaceSamples);
// 如果我們不需要逐采樣著色,拋棄該像素片元(例如:不寫入模板)
[flatten]
if (!perSample)
{
discard;
}
}
頂點著色器使用全屏三角形繪制,像素著色器使用RequiresPerSampleShadingPS,然后模板寫入,對需要逐采樣著色的像素標記為1,其余為0的默認進行逐像素著色
通過模板測驗來繪制逐像素著色的區域
float3 DecodeSphereMap(float2 encoded)
{
float4 nn = float4(encoded, 1, -1);
float l = dot(nn.xyz, -nn.xyw);
nn.z = l;
nn.xy *= sqrt(l);
return nn.xyz * 2 + float3(0, 0, -1);
}
SurfaceData ComputeSurfaceDataFromGBufferSample(uint2 posViewport, uint sampleIndex)
{
// 從GBuffer讀取資料
GBuffer rawData;
rawData.normal_specular = g_GBufferTextures[0].Load(posViewport.xy, sampleIndex).xyzw;
rawData.albedo = g_GBufferTextures[1].Load(posViewport.xy, sampleIndex).xyzw;
rawData.posZGrad = g_GBufferTextures[2].Load(posViewport.xy, sampleIndex).xy;
float zBuffer = g_GBufferTextures[3].Load(posViewport.xy, sampleIndex).x;
float2 gbufferDim;
uint dummy;
g_GBufferTextures[0].GetDimensions(gbufferDim.x, gbufferDim.y, dummy);
// 計算螢屏/裁剪空間坐標和相鄰的位置
// 注意:需要留意DX11的視口變換和像素中心位于(x+0.5, y+0.5)位置
// 注意:該偏移實際上可以在CPU預計算但將它放到常量緩沖區讀取實際上比在這里重新計算更慢一些
float2 screenPixelOffset = float2(2.0f, -2.0f) / gbufferDim;
float2 posNdc = (float2(posViewport.xy) + 0.5f) * screenPixelOffset.xy + float2(-1.0f, 1.0f);
float2 posNdcX = posNdc + float2(screenPixelOffset.x, 0.0f);
float2 posNdcY = posNdc + float2(0.0f, screenPixelOffset.y);
// 解碼到合適的輸出
SurfaceData data;
// 反投影深度緩沖Z值到觀察空間
float viewSpaceZ = g_Proj._m32 / (zBuffer - g_Proj._m22);
data.posV = ComputePositionViewFromZ(posNdc, viewSpaceZ);
data.posV_DX = ComputePositionViewFromZ(posNdcX, viewSpaceZ + rawData.posZGrad.x) - data.posV;
data.posV_DY = ComputePositionViewFromZ(posNdcY, viewSpaceZ + rawData.posZGrad.y) - data.posV;
data.normalV = DecodeSphereMap(rawData.normal_specular.xy);
data.albedo = rawData.albedo;
data.specularAmount = rawData.normal_specular.z;
data.specularPower = rawData.normal_specular.w;
return data;
}
float4 BasicDeferred(float4 posViewport, uint sampleIndex)
{
uint totalLights, dummy;
g_Light.GetDimensions(totalLights, dummy);
float3 lit = float3(0.0f, 0.0f, 0.0f);
[branch]
if (g_VisualizeLightCount)
{
// 用亮度表示該像素會被多少燈光處理
lit = (float(totalLights) * rcp(255.0f)).xxx;
}
else
{
SurfaceData surface = ComputeSurfaceDataFromGBufferSample(uint2(posViewport.xy), sampleIndex);
// 避免對天空盒/背景像素著色
if (surface.posV.z < g_CameraNearFar.y)
{
for (uint lightIndex = 0; lightIndex < totalLights; ++lightIndex)
{
PointLight light = g_Light[lightIndex];
AccumulateColor(surface, light, lit);
}
}
}
return float4(lit, 1.0f);
}
float4 BasicDeferredPS(float4 posViewport : SV_Position) : SV_Target
{
return BasicDeferred(posViewport, 0);
}
頂點著色器使用全屏三角形繪制,像素著色器使用BasicDeferredPS,然后模板測驗要求模板值為0才能進行著色,混合采用的是加法混合,由于在逐像素繪制的區域中,G-Buffer的4個子采樣存的內容是相同的(某種意義上這也是一種浪費),我們可以直接取子采樣0的資訊進行著色,
通過模板測驗來繪制逐樣本著色的區域
float4 BasicDeferredPerSamplePS(float4 posViewport : SV_Position,
uint sampleIndex : SV_SampleIndex) : SV_Target
{
float4 result;
if (g_VisualizePerSampleShading)
{
result = float4(1, 0, 0, 1);
}
else
{
result = BasicDeferred(posViewport, sampleIndex);
}
return result;
}
頂點著色器使用全屏三角形繪制,像素著色器使用BasicDeferredPerSamplePS,然后模板測驗要求模板值為1才能進行著色,混合采用的是加法混合,
天空盒與場景的同時繪制
// SkyboxToneMap.hlsl
//--------------------------------------------------------------------------------------
// 后處理, 天空盒等
// 使用天空盒幾何體渲染
//--------------------------------------------------------------------------------------
TextureCube<float4> g_SkyboxTexture : register(t5);
Texture2DMS<float, MSAA_SAMPLES> g_DepthTexture : register(t6);
// 常規多重采樣的場景渲染的紋理
Texture2DMS<float4, MSAA_SAMPLES> g_LitTexture : register(t7);
struct SkyboxVSOut
{
float4 posViewport : SV_Position;
float3 skyboxCoord : skyboxCoord;
};
SkyboxVSOut SkyboxVS(VertexPosNormalTex input)
{
SkyboxVSOut output;
// 注意:不要移動天空盒并確保深度值為1(避免裁剪)
output.posViewport = mul(float4(input.posL, 0.0f), g_ViewProj).xyww;
output.skyboxCoord = input.posL;
return output;
}
float4 SkyboxPS(SkyboxVSOut input) : SV_Target
{
uint2 coords = input.posViewport.xy;
float3 lit = float3(0.0f, 0.0f, 0.0f);
float skyboxSamples = 0.0f;
#if MSAA_SAMPLES <= 1
[unroll]
#endif
for (unsigned int sampleIndex = 0; sampleIndex < MSAA_SAMPLES; ++sampleIndex)
{
float depth = g_DepthTexture.Load(coords, sampleIndex);
// 檢查天空盒的狀態(注意:反向Z!)
if (depth <= 0.0f && !g_VisualizeLightCount)
{
++skyboxSamples;
}
else
{
lit += g_LitTexture.Load(coords, sampleIndex).xyz;
}
}
// 如果這里沒有場景渲染,則渲染天空盒
[branch]
if (skyboxSamples > 0)
{
float3 skybox = g_SkyboxTexture.Sample(g_SamplerDiffuse, input.skyboxCoord).xyz;
lit += skyboxSamples * skybox;
}
// Resolve 多重采樣(簡單盒型濾波)
return float4(lit * rcp(MSAA_SAMPLES), 1.0f);
}
頂點著色器使用SkyboxVS,像素著色器使用SkyboxPS,光柵化取消背面裁剪,
C++端的變化
目前對原來的代碼做了比較多的改動,比較重要的包括:
- Model的ObjReader改為使用tinyobj的ObjReader,以能夠匯入Sponza模型,并對Model支持子模型級別的視錐體裁剪,
- 添加了TextureManager類以避免紋理的重復讀取,內部使用DDSTextureLoader和stb_image讀取紋理
- 使用DirectX-Graphics-Samples中MiniEngine的CameraController實作對FirstPersonCamera的*滑移動
- 添加ImGui應對逐漸復雜的選項控制
- 添加Texture2D、Depth2D和StructuredBuffer類
具體的C++代碼細節建議直接閱讀原始碼,
演示
由于可改變的選項很多,演示起來也比較麻煩,這里只放出截屏,然后具體描述各自的功能
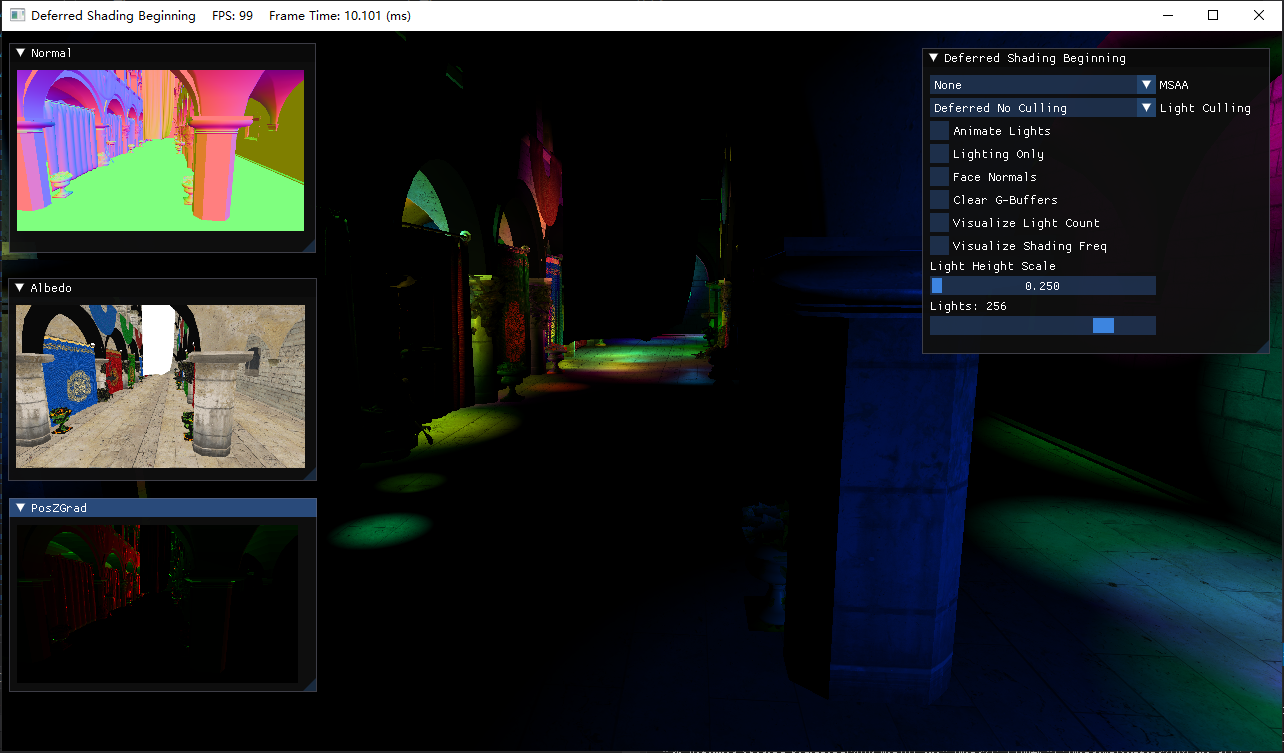
- MSAA:默認關閉,可選2x、4x、8x
- 光照裁剪模式:默認開啟延遲渲染+無光照裁剪,可選前向渲染、帶Pre-Z Pass的前向渲染
- Animate Lights:燈光的移動
- Face Normals:使用面法線
- Clear G-Buffer:默認不需要清除G-Buffer再來繪制,該選項開啟便于觀察G-Buffer中的圖
- Visualize Light Count:可視化每個像素渲染的光照數,最大255,目前沒有光照裁剪
- Visualize Shading Freq:在開啟MSAA后,紅色高亮的區域表示該像素使用的是逐樣本著色
- Light Height Scale:將所有的燈光按一定比例抬高
- Lights:燈光數,2的指數冪
- Normal圖:展示了從Normal_Specular G-Buffer還原出的世界坐標下的法線,經[-1, 1]到[0, 1]的映射
- Albedo圖:展示了Albedo G-Buffer
- PosZGrad圖:展示了觀察空間下的PosZ的梯度
在下一章我們將會重點討論光照裁剪技術,
補充&參考
Depth Precision Visualized
Deferred Rendering for Current and Future Rendering Pipelines
Compact Normal Storage for small G-Buffers · Aras' website (aras-p.info)
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什么問題也可以在這里匯報,
作者:X_Jun 出處:http://www.cnblogs.com/X-Jun/ 本文著作權歸X_Jun(博客園)所有(CSDN為x_jun96),歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連接,否則保留追究法律責任的權利,轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/437917.html
標籤:其他