1.收集資料
構建機器學習系統的關鍵部分之一是收集高質量的資料集,您可能會在資料上花費大量時間,這是必不可少的,因為我們的模型僅與它從中學習的資料一樣好,如果我們將嘗試構建一個經過訓練的物件檢測器,以檢測場景中佩戴頭盔的人,那么我們如何教機器檢測頭盔呢?正如您可能已經猜到的那樣,通過展示大量示例,有多種方法可以收集資料,對于影像,個人收集影像的最簡單方法之一是使用 Google 圖片搜索,
但是在搜索結果中手動下載圖片是一項繁瑣的任務,幸運的是,有一些工具可以提供幫助,有一個名為下載所有影像的 chrome 擴展程式,顧名思義,它可以通過單擊按鈕下載網頁中存在的所有影像,盡可能在搜索結果頁面上向下滾動,該工具將捕獲滾動的影像,
可能還有其他方法可以從 Google 搜索中批量下載圖片,這種方法看起來非常簡單,下載影像后,請務必檢查它們并洗掉任何不相關的影像,
2.標記資料
一旦我們收集到資料,下一步就是標記它們,在物件檢測中,標記意味著在影像中有我們感興趣的物件,并在感興趣物件周圍繪制邊界框,并將它們與相應的物件類別相關聯,以便我們可以清楚地將其顯示給機器,

這是該程序中勞動強度最大的部分,我們需要一張一張地瀏覽影像并手動標記每個影像中的物件,有很多工具可以幫助我們注釋影像,廣泛使用的開源工具之一是LabelImg,
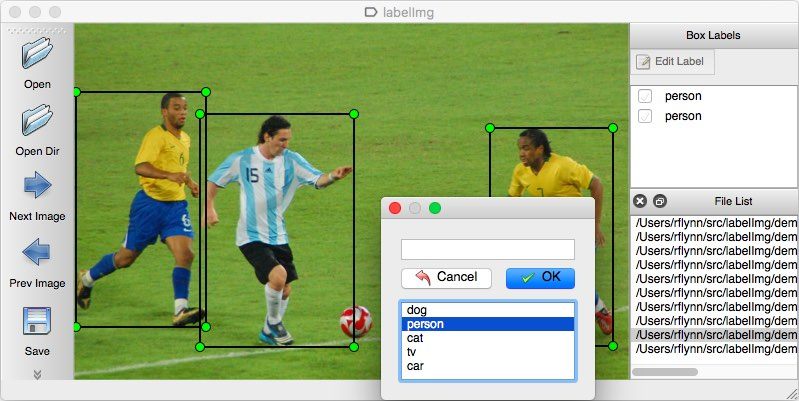
LabelImg 的好處是,它可以讓我們將標注直接保存為 YOLO 格式,有些工具不直接這樣做,我們需要自己將標注轉換成 YOLO 需要的格式,
您可以從終端使用 pip 輕松安裝 LabelImg,
pip install labelimg
成功安裝 labelImg 后,通過鍵入以下命令啟動它
labelImg [path to image] [classes file]
[path to image]是包含我們要標記的頭盔影像的目錄路徑,
[classes file]是我們列出要標記的物件類別的檔案,我們還沒有創建它,現在讓我們這樣做,
創建一個文本檔案(例如label.txt)并在檔案中添加“helmet”,由于我們只針對這一類別進行訓練,這就是我們需要添加的全部內容,如果我們要標記 10 個不同的物件,那么我們應該將它們全部放在這個檔案中,
創建檔案后,啟動 labelImg,例如,
labelImg ./helmet_images/image_1.jpg label.txt
打開視窗后,您可以單擊左側面板上的“打開目錄”按鈕,然后選擇含有所有頭盔影像的目錄,它將所有影像帶到 labelImg 以便我們可以一張一張地瀏覽,
加載完所有影像后,我們就可以開始標記影像了,
在繼續之前,將左側面板上的 PASCAL VOC 中的注釋格式更改為 YOLO,
- 鍵盤快捷鍵
W - 開始創建邊界框
Ctrl + S - 保存邊界框和標簽
D - 下一張圖片
A - 上一張圖片
可以在此處找到完整的快捷方式串列,但這些是我發現自己經常使用的快捷方式,
當您使用**Ctrl + S**保存標簽時,labelImg 會為每個影像創建一個與影像同名的文本檔案,該影像的所有標注資訊都保存在該檔案中,
例如,image_1.jpg將在同一目錄中有相應的image_1.txt,(如果您希望使用左側面板中的“更改保存目錄”,您可以更改目錄)
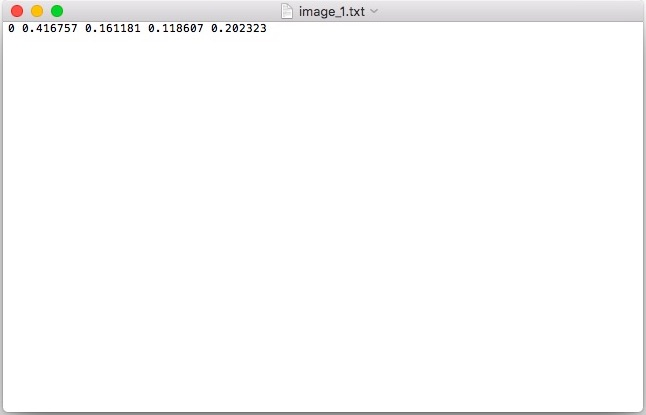
如果您想知道這些神秘數字是什么,它們實際上是以一種通常稱為YOLO 格式的特定格式存盤的,
object-id center_x center_y width height
object-id表示對應于我們之前在classes.txt中列出的物件類別的數字,
center_x 和 center_y表示邊界框的中心點,但是通過除以影像的寬度和高度,它們被歸一化為 0 和 1 之間的范圍,
例如,(0.25,0.75) 是位于 25% 寬度和 75% 高度的點,我們可以將這個數字(0.25,0.75)乘以影像的原始寬度和高度,得到真實點,事實上,我們將在推理結束后這樣做,以在影像上繪制預測,
width 和 height表示邊界框的寬度和高度,再次通過除以影像的原始寬度和高度歸一化為 0 到 1 的范圍,
每個檔案表示一張影像,檔案中的每一行表示一個邊界框及其類別
3.創建必要的檔案
除了標注之外,幾乎沒有與 DarkNet 期望用于訓練的資料相關的必要檔案,現在讓我們創建它們,
-
classes.names- 這與我們之前使用的classes.txt檔案相同,包含物件類別(在我們的例子中只是helmet),只是帶有.names擴展名,因此,您可以將檔案重命名為classes.names, -
train.txt- DarkNet 需要一個文本檔案,列出將用于訓練的所有影像,通常人們使用總資料集的60-90%進行訓練,并將剩余的用于測驗/驗證,這里對數字沒有真正的共識,視情況而定,
ls "$PWD/"*.jpg | head -100 > train.txt
我總共標記了 120 張影像(實際上很少),所以我使用 100 張影像進行訓練,使用 20 張影像進行驗證,轉到您擁有頭盔影像的目錄并運行上述命令,它應該創建一個文本檔案,列出目錄中前 100 個影像的路徑,(隨意更改您認為合適的數字)
test.txt- 此檔案將包含將用于驗證的影像串列,
ls "$PWD/"*.jpg | tail -20 > test.txt
轉到您擁有頭盔影像的目錄并運行上述命令,它應該創建一個文本檔案,列出目錄中最后 20 個影像的路徑,(再次,請隨意更改您認為合適的數字)
創建這些文本檔案后,您可以將它們從影像目錄移動到您正在處理的專案目錄中的適當位置,或者您可以將其保留在那里,
obj.data- 該檔案將包含以下幾行,
classes= 1
train = /path/to/train.txt
valid = /path/to/test.txt
names = /path/to/classes.names
backup = backup/
"classes"是我們訓練網路檢測的物件類別的數量,"backup"是 DarkNet 為我們保存訓練權重的地方,
參考目錄
https://www.visiongeek.io/2019/10/preparing-custom-dataset-for-training-yolo-object-detector.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/437957.html
標籤:AI
下一篇:3天AI進階實戰營——多目標跟蹤