目錄
- 一、均方誤差、精度與錯誤率
- 二、查準率、查全率與 F 1 F1 F1
- 2.1 查準率(Precision)與查全率(Recall)
- 2.2 混淆矩陣的可視化
- 2.3 P-R曲線與BEP
- 2.4 F 1 F1 F1 與 F β F_{\beta} Fβ?
- 三、ROC與AUC
- 3.1 ROC(Receiver Operating Characteristic)
- 3.2 AUC(Area Under roc Curve)
- References
一、均方誤差、精度與錯誤率
對模型的泛化性能進行評估,我們需要有衡量模型泛化能力的評價標準,這就是性能度量(Performance Measure),
在評估同一個模型的泛化能力時,使用不同的性能度量往往會導致不同的評判結果,這意味著模型的 “好壞” 是相對的,什么樣的模型是好的,不僅取決于演算法和資料,還取決于性能度量,
在預測任務中,給定大小為 m m m 的資料集
D = { ( x 1 , y 1 ) , ? ? , ( x m , y m ) } D=\{(\boldsymbol{x}_1,y_1),\cdots,(\boldsymbol{x}_m,y_m)\} D={(x1?,y1?),?,(xm?,ym?)}
其中 y i y_i yi? 是 x i \boldsymbol{x}_i xi? 的真實標記. 要評估模型 f f f 的性能,我們需要把預測結果 f ( x ) f(\boldsymbol{x}) f(x) 與真實標記 y y y 進行比較.
最簡單的性能度量有以下三種:
- 均方誤差(MSE): m s e ( f ; D ) = 1 m ∑ i = 1 m ( f ( x i ) ? y i ) 2 \displaystyle mse(f;D)=\frac1m \sum_{i=1}^m (f(\boldsymbol{x}_i)-y_i)^2 mse(f;D)=m1?i=1∑m?(f(xi?)?yi?)2;
- 精度(Accuracy): a c c ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) = y i ) \displaystyle acc(f;D)=\frac1m \sum_{i=1}^m \mathbb{I}(f(\boldsymbol{x}_i)=y_i) acc(f;D)=m1?i=1∑m?I(f(xi?)=yi?);
- 錯誤率(Error): e r r ( f ; D ) = 1 m ∑ i = 1 m I ( f ( x i ) ≠ y i ) \displaystyle err(f;D)=\frac1m \sum_{i=1}^m \mathbb{I}(f(\boldsymbol{x}_i)\neq y_i) err(f;D)=m1?i=1∑m?I(f(xi?)?=yi?).
其中 I ( ? ) \mathbb{I}(\cdot) I(?) 是指示函式,且精度和錯誤率滿足如下關系
a c c ( f ; D ) + e r r ( f ; D ) = 1 acc(f;D)+err(f;D)=1 acc(f;D)+err(f;D)=1
均方誤差常用于回歸任務,精度和錯誤率常用于分類任務,
sklearn.metrics 中提供了常見的性能度量,均方誤差、精度和錯誤率的實作如下:
""" 均方誤差 """
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_pred)
""" 精度 """
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_true, y_pred)
""" 錯誤率 """
from sklearn.metrics import accuracy_score
err = 1 - accuracy_score(y_true, y_pred)
二、查準率、查全率與 F 1 F1 F1
2.1 查準率(Precision)與查全率(Recall)
錯誤率和精度雖然常用,但并不能滿足所有的任務需求,
考慮這樣一個場景,假定先前我們根據西瓜資料集訓練出了一個能夠判斷好瓜還是壞瓜的模型,現在又有一車新的西瓜,我們用訓練好的模型對這些西瓜進行判別,自然地,錯誤率衡量了有多少比例的瓜被判斷錯誤,
但如果我們關心的是:
- 挑出來的瓜(模型判斷出的好瓜)有多少比例是真的好瓜,
- 所有真的好瓜中有多少比例被挑了出來(模型判斷為好瓜),
那么錯誤率顯然就不夠用了,因此有必要引入新的性能度量,
上面幾句話似乎有些繞口,接下來我們再用幾張圖去形象地闡釋一遍,
假定瓜農拉來的一車西瓜如下(只有6個):

西瓜上方是它的編號,下方是它的真實標簽,我們用學得的模型 f f f 對這六個西瓜的判斷結果如下:

可以看出,編號為 1 , 2 , 5 1,2,5 1,2,5 的西瓜都被判斷錯誤了,因此錯誤率為 3 / 6 = 0.5 3/6=0.5 3/6=0.5,精度也為 0.5 0.5 0.5.
- 挑出來的瓜(即模型判斷出的好瓜)為 2 , 4 , 5 , 6 2,4,5,6 2,4,5,6,這四個被挑出來的瓜只有 4 4 4 和 6 6 6 是真的好瓜,占比 0.5 0.5 0.5,
- 所有真的好瓜為 1 , 4 , 6 1,4,6 1,4,6,這三個真的好瓜中,只有 4 4 4 和 6 6 6 被挑出來了(即模型判斷為好瓜),占比 0.67 0.67 0.67,
接下來可以定義查準率和查全率了,不過在此之前,我們有必要引入混淆矩陣(Confusion Matrix),
對于二分類問題,可將樣例根據其真實類別與模型預測的類別組合劃分為四類:
- T P TP TP(True Positive):真實標記為正,預測標記也為正,
- F P FP FP(False Positive): 真實標記為負,但預測標記為正,
- T N TN TN(True Negative):真實標記為負,預測標記也為負,
- F N FN FN(False Negative):真實標記為正,但預測標記為負,
顯然有 T P + F P + T N + F N = m TP+FP+TN+FN=m TP+FP+TN+FN=m. 分類結果的混淆矩陣形式如下:
[ T N F P F N T P ] \begin{bmatrix} TN & FP \\ FN& TP \\ \end{bmatrix} [TNFN?FPTP?]
我們的查準率(Precision)與查全率(Recall)分別定義為:
P = T P T P + F P , R = T P T P + F N P=\frac{TP}{TP+FP},\quad R=\frac{TP}{TP+FN} P=TP+FPTP?,R=TP+FNTP?
例如,對于之前我們舉的例子,查準率和查全率分別為
P = 0.5 , R = 0.67 P=0.5,\quad R=0.67 P=0.5,R=0.67
現在計算混淆矩陣:
- 真的好瓜,且被模型判斷為好瓜的是 4 4 4 和 6 6 6,因此 T P = 2 TP=2 TP=2;
- 真的壞瓜,且被模型判斷為好瓜的是 2 2 2 和 5 5 5,因此 F P = 2 FP=2 FP=2;
- 真的好瓜,且被模型判斷為壞瓜的是 1 1 1,因此 F N = 1 FN=1 FN=1;
- 對于最后一個,我們可以直接套用公式,即 T N = 6 ? T P ? F P ? F N = 1 TN=6-TP-FP-FN=1 TN=6?TP?FP?FN=1;
從而混淆矩陣為
[ 1 2 1 2 ] \begin{bmatrix} 1 & 2 \\ 1& 2 \\ \end{bmatrix} [11?22?]
不難看出,查準率與查全率適用于分類任務,相應的實作如下:
""" 查準率 """
from sklearn.metrics import precision_score
precision = precision_score(y_true, y_pred)
""" 查全率 """
from sklearn.metrics import recall_score
recall = recall_score(y_true, y_pred)
對于本節一開始的例子,我們記好瓜為 1 1 1,壞瓜為 0 0 0,則:
from sklearn.metrics import precision_score, recall_score, accuracy_score
y_true = [1, 0, 0, 1, 0, 1]
y_pred = [0, 1, 0, 1, 1, 1]
print(accuracy_score(y_true, y_pred))
# 0.5
print(precision_score(y_true, y_pred))
# 0.5
print(recall_score(y_true, y_pred))
# 0.6666666666666666
結果與我們原先的計算相符,
2.2 混淆矩陣的可視化
對于二分類問題,我們的混淆矩陣是一個 2 × 2 2\times 2 2×2 矩陣,進而可知,對于 N N N 分類問題,我們的混淆矩陣是一個 N × N N\times N N×N 矩陣,
sklearn.metrics 中提供了計算混淆矩陣的函式:confusion_matrix(),我們依然使用 2.1 節中的例子,使用 confusion_matrix() 來計算相應的混淆矩陣:
from sklearn.metrics import confusion_matrix
y_true = [1, 0, 0, 1, 0, 1]
y_pred = [0, 1, 0, 1, 1, 1]
C = confusion_matrix(y_true, y_pred)
print(C)
# [[1 2]
# [1 2]]
輸出結果與我們 2.1 節中計算的相同,
對于多分類問題, confusion_matrix() 回傳的混淆矩陣
C
C
C 滿足:
C
i
j
C_{ij}
Cij? 代表真實類別為
i
i
i 但卻被模型預測為類別
j
j
j 的樣例個數,
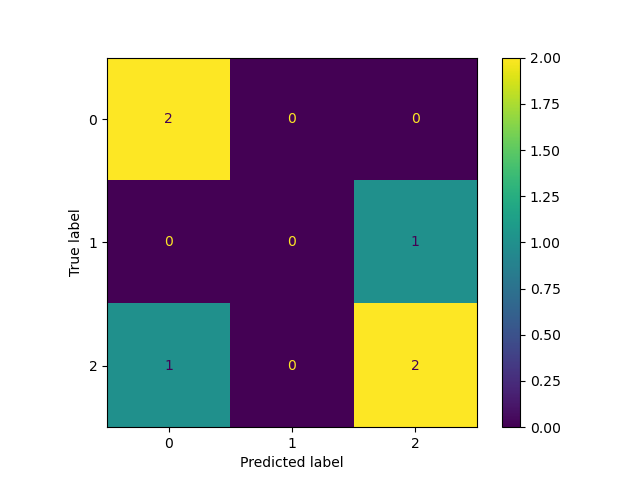
為了更好的展示混淆矩陣,我們考慮三分類問題,相應的 y_true 和 y_pred 設定為:
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
現在使用 ConfusionMatrixDisplay() 來實作混淆矩陣的可視化
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
C = confusion_matrix(y_true, y_pred)
disp = ConfusionMatrixDisplay(C)
disp.plot()
plt.show()
2.3 P-R曲線與BEP
查準率和查全率是一對矛盾的度量,一般來說,查準率高時,查全率往往偏低;查全率高時,查準率往往偏低,通常只有在一些簡單的任務中,才可能使得查準率和查全率都很高,
回到 2.1 節中的例子,我們根據西瓜資料集訓練出來的模型本質上是一個二分類器,事實上,許多二分類器的原理,就是設定一個閾值,然后對每一個樣例進行打分,分數大于等于該閾值的樣例被分為正類,分數小于該閾值的樣例被分為負類,
例如,設定閾值為 0.5 0.5 0.5,對于一個新樣本(西瓜),若它的得分高于 0.5 0.5 0.5,則被認為是好瓜,否則認為是壞瓜,
事實上,上述提到的精度、查準率、查全率全都依賴于具體的閾值,有些時候,我們希望不固定閾值,而是根據實際需求去調整,
依然使用 2.1 節中的例子,假定閾值就是 0.5 0.5 0.5,我們的二分類器對于六個樣例的打分情況如下:

我們根據這六個西瓜的得分將它們從高到低進行排序:
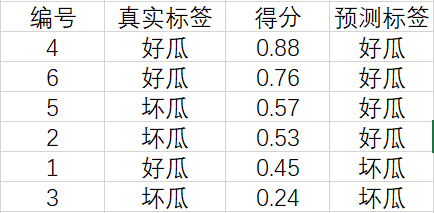
現在,我們從上往下遍歷,對于第一行的樣例,設它的得分 0.88 0.88 0.88 為閾值,大于等于該閾值的預測為正例,小于該閾值的預測為反例,相應的結果如下:
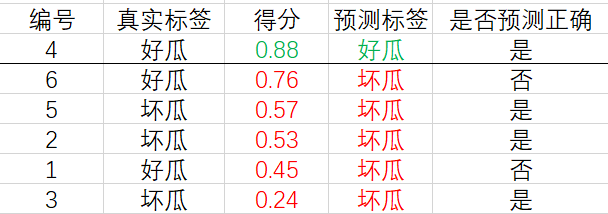
計算可得查準率和查全率分別為 P = 1 , ? R = 0.33 P=1,\, R=0.33 P=1,R=0.33.
對于第二行的樣例,設它的得分 0.76 0.76 0.76 為閾值,大于等于該閾值的預測為正例,小于該閾值的預測為反例,相應的結果如下:
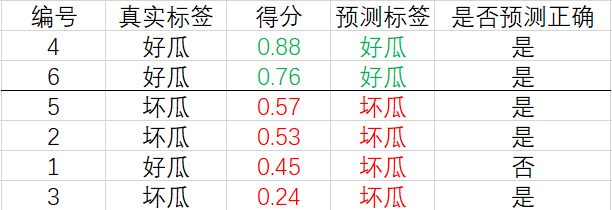
計算可得查準率和查全率分別為 P = 1 , ? R = 0.67 P=1,\, R=0.67 P=1,R=0.67.
以此類推,我們最終可以得到 6 6 6 個 ( R , P ) (R, P) (R,P) 值,代碼實作如下:
from sklearn.metrics import precision_score, recall_score
y_true = [1, 1, 0, 0, 1, 0]
for i in range(len(y_true)):
y_pred = [1] * (i + 1) + [0] * (len(y_true) - i - 1)
P = precision_score(y_true, y_pred)
R = recall_score(y_true, y_pred)
print((R, P))
輸出結果:
(0.3333333333333333, 1.0)
(0.6666666666666666, 1.0)
(0.6666666666666666, 0.6666666666666666)
(0.6666666666666666, 0.5)
(1.0, 0.6)
(1.0, 0.5)
我們將這六個點連起來繪制曲線:
from sklearn.metrics import precision_score, recall_score
import matplotlib.pyplot as plt
y_true = [1, 1, 0, 0, 1, 0]
R, P = [], []
for i in range(len(y_true)):
y_pred = [1] * (i + 1) + [0] * (len(y_true) - i - 1)
P += [precision_score(y_true, y_pred)]
R += [recall_score(y_true, y_pred)]
plt.plot(R, P)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.show()
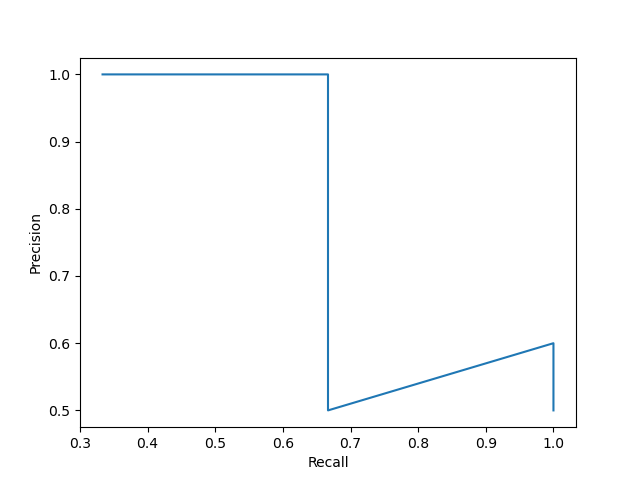
上圖稱為 P-R圖,其中的曲線稱為 P-R曲線,
P-R曲線的進一步討論:首先我們記真實標記為正和負的樣例個數分別為 m + m^+ m+ 和 m ? m^- m?,即
m + = T P + F N , m ? = T N + F P m^+=TP+FN,\quad m^-=TN+FP m+=TP+FN,m?=TN+FP
查準率與查全率可以寫為
P = T P T P + F P , R = T P m + P=\frac{TP}{TP+FP},\quad R=\frac{TP}{m^+} P=TP+FPTP?,R=m+TP?
現在考慮更一般的情形,我們將 m m m 個西瓜的得分(之前是六個西瓜的得分)從高到低進行排列得到一個有序串列:
s c o r e = [ h 1 h 2 ? h m ] \mathrm{score}= \begin{bmatrix} h_1 \\ h_2 \\ \vdots \\ h_m \end{bmatrix} score=??????h1?h2??hm????????
設閾值為 h h h,當 h > h 1 h>h_1 h>h1? 時,所有西瓜都會被預測為壞瓜,即沒有一個西瓜會被預測成好瓜,所以 T P = F P = 0 TP=FP=0 TP=FP=0,此時 P = 0 / 0 P=0/0 P=0/0 無意義,所以我們接下來的討論都將基于 h ≤ h 1 h\leq h_1 h≤h1?,一般而言,我們會把閾值 h h h 分別設定為每一個樣例的得分,從而會有 m m m 種閾值,
我們先取最小的閾值,即 h = h m h=h_m h=hm?,那么所有的瓜都會被預測成好瓜,即沒有一個瓜會被預測成壞瓜,所以 T N = F N = 0 TN=FN=0 TN=FN=0,此時有 T P = m + TP=m^+ TP=m+ 和 F P = m ? FP=m^- FP=m?,從而 R = 1 R=1 R=1 且 P = m + / ( m + + m ? ) = m + / m P=m^+/(m^++m^-)=m^+/m P=m+/(m++m?)=m+/m,這反映在P-R曲線上最后一個點的坐標為
( 1 , m + m ) \Big(1,\frac{m^+}{m}\Big) (1,mm+?)
如果 ( 1 , m + / m ) → ( 1 , 0 ) (1,m^+/m)\to(1,0) (1,m+/m)→(1,0),則有 m + ? m m^+\ll m m+?m,因此 m ? ? 0 m^-\gg0 m??0,結合上述的 T N = 0 TN=0 TN=0,這說明樣本中有大量的反例,且它們都被預測錯誤了,又因為 F N = 0 FN=0 FN=0,說明樣本中有少量的正例,且它們都被預測正確了,從而可知,如果P-R曲線的最后一個點趨于 ( 1 , 0 ) (1,0) (1,0),那么樣本分布極其不均衡(有著極多的反例和極少的正例),且分類器對于反例全部預測錯誤,對于正例全部預測正確,因此這種P-R曲線對應的分類器很糟糕,
我們再取最大的閾值,即 h = h 1 h=h_1 h=h1?,那么只有第一個西瓜會被預測為好瓜,剩余的西瓜都被預測為壞瓜,我們分以下兩種情況討論:
- 第一個西瓜本身就是好瓜,那么 T P = 1 TP=1 TP=1, F P = 0 FP=0 FP=0,從而 P = 1 P=1 P=1, R = 1 / m + R=1/m^+ R=1/m+,P-R曲線上第一個點的坐標為 ( 1 / m + , 1 ) (1/m^+,1) (1/m+,1);
- 第一個西瓜本身就是壞瓜,那么 F P = 1 FP=1 FP=1, T P = 0 TP=0 TP=0,從而 P = R = 0 P=R=0 P=R=0,P-R曲線上第一個點的坐標為 ( 0 , 0 ) (0, 0) (0,0),
大多數情況下我們的資料集規模都比較大,即 m + ? 0 m^+\gg0 m+?0,所以,當得分最高的樣例為正例時,P-R曲線上第一個點的坐標非常接近 ( 0 , 1 ) (0,1) (0,1) 但不等于 ( 0 , 1 ) (0,1) (0,1);當得分最高的樣例為反例時,P-R曲線上第一個點的坐標是 ( 0 , 0 ) (0,0) (0,0),
更直觀地來講,假設每一個 h i h_i hi? 都只對應一個瓜,當我們將 h h h 從 h 1 h_1 h1? 依次下調至 h m h_m hm? 時,相應的P-R曲線會依次從第一個點繪制到最后一個點,當 h h h 從 h i ? 1 h_{i-1} hi?1? 下調至 h i h_i hi? 時,若 h i h_i hi? 所對應的瓜本身是正例,則 T P ↑ TP \uparrow TP↑, F P FP FP 不變, F N ↓ FN \downarrow FN↓,從而 P ↑ P\uparrow P↑, R ↑ R\uparrow R↑,這反映在P-R曲線將會產生一條向右上方的線段,若 h i h_i hi? 所對應的瓜本身是反例,則 F P ↑ FP\uparrow FP↑, T P TP TP 不變, F N FN FN 也不變,從而 P ↓ P\downarrow P↓, R R R 不變,這反映在P-R曲線將會產生一條豎直向下的線段,
綜合以上討論可得出: 我們從 ( 0 , 0 ) (0,0) (0,0) 或 ( 1 / m + , 1 ) (1/m^+,1) (1/m+,1) 開始,根據有序串列依次下調閾值,每當經過一個正例,我們繪制一條斜向右上的線段;每當經過一個反例,我們繪制一條豎直向下的線段,如此進行下去直到抵達 ( 1 , m + / m ) (1, m^+/m) (1,m+/m),此時P-R曲線繪制完畢,
從繪制程序可以看出,我們的P-R曲線是呈鋸齒狀的,且呈 “下降” 趨勢,
當然,sklearn.metrics 中提供了繪制P-R曲線的函式,我們將真實標簽串列 y_true 和 得分串列 y_score 傳入 precision_recall_curve() 中可得到查準率、查全率和閾值,如下:
from sklearn.metrics import precision_recall_curve
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
precision, recall, thresholds = precision_recall_curve(y_true, y_score)
print(precision)
# [0.6 0.5 0.66666667 1. 1. 1. ]
print(recall)
# [1. 0.66666667 0.66666667 0.66666667 0.33333333 0. ]
print(thresholds)
# [0.45 0.53 0.57 0.76 0.88]
然后使用 PrecisionRecallDisplay() 來進行繪制:
from sklearn.metrics import precision_recall_curve, PrecisionRecallDisplay
import matplotlib.pyplot as plt
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
precision, recall, _ = precision_recall_curve(y_true, y_score)
disp = PrecisionRecallDisplay(precision, recall)
disp.plot()
plt.show()
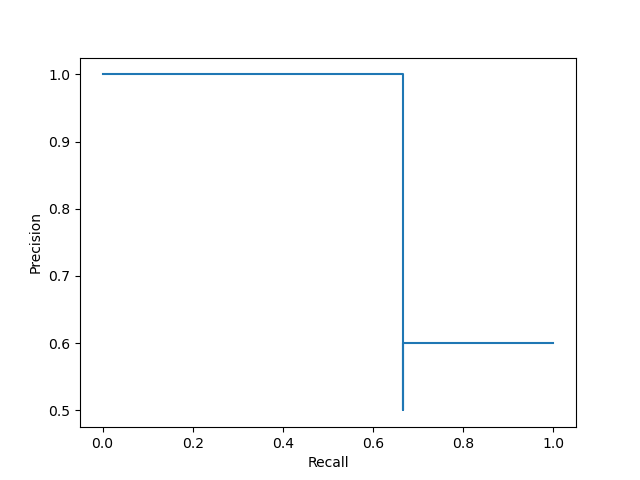
可能會有讀者疑惑,為什么這里的曲線和我們之前自己繪制的曲線不一樣,并且為什么 thresholds 中只有五個閾值呢?
我們先不用 PrecisionRecallDisplay(),只用 precision_recall_curve() 得到的結果去繪制:
from sklearn.metrics import precision_recall_curve
import matplotlib.pyplot as plt
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
precision, recall, _ = precision_recall_curve(y_true, y_score)
plt.plot(recall, precision)
plt.show()
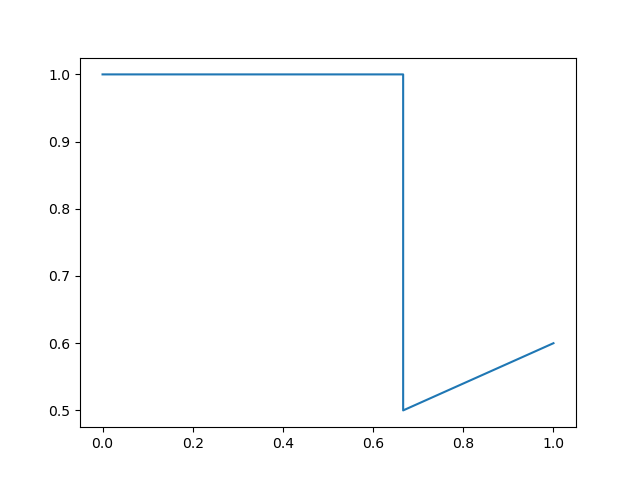
可以看出這張圖和上一張圖相比,僅僅是連線的方式有所改變,PrecisionRecallDisplay() 中取消了斜向右上的這種連線方式,為了美觀起見采用 “橫平豎直” 的方式去繪制,我們再來看一下 PrecisionRecallDisplay() 中 plot() 函式的部分原始碼:
def plot(self, ax=None, *, name=None, **kwargs):
...
line_kwargs = {"drawstyle": "steps-post"}
...
(self.line_,) = ax.plot(self.recall, self.precision, **line_kwargs)
...
return self
"step-post" 這一引數說明了P-R曲線將采用階梯形式進行繪制,詳情見檔案,
在上面的三張P-R圖中,我們已經知道了第二張圖和第三張圖僅僅是繪制方式的不同,接下來我們將第三張圖和第一張圖進行比較,
可以看到,相比于第一張圖,第三張圖去掉了最后一個點,并且在第一個點的前面加上了 ( 0 , 1 ) (0,1) (0,1) 這個點,這種做法的用意何在呢?
我們先來看下 precision_recall_curve() 的原始碼:
def precision_recall_curve(y_true, probas_pred, pos_label=None, sample_weight=None):
fps, tps, thresholds = _binary_clf_curve(y_true, probas_pred,
pos_label=pos_label,
sample_weight=sample_weight)
precision = tps / (tps + fps)
precision[np.isnan(precision)] = 0
recall = tps / tps[-1]
# stop when full recall attained
# and reverse the outputs so recall is decreasing
last_ind = tps.searchsorted(tps[-1])
sl = slice(last_ind, None, -1)
return np.r_[precision[sl], 1], np.r_[recall[sl], 0], thresholds[sl]
從 return 一行可以看出
(
0
,
1
)
(0,1)
(0,1) 這個點是強行加上去的,那原先P-R曲線上的最后一個點為什么會被去掉呢?
注意到這一行注釋:
# stop when full recall attained
即當
R
=
1
R=1
R=1 時停止計算,而我們的第一張圖的最后兩個點的橫坐標都為
1
1
1,因此最后一個點不會被計算,相應的最低閾值也不會添加進 thresholds 中,
事實上可以證明,如果得分最低的樣例是反例,則最后兩個點的橫坐標都為 1 1 1;如果得分最低的樣例是正例,則倒數第二個點的橫坐標為 1 ? 1 / m + 1-1/m^+ 1?1/m+,
至于為什么
(
0
,
1
)
(0,1)
(0,1) 會被強行添加至P-R曲線中,是因為 sklearn 想讓P-R曲線從
y
y
y 軸開始繪制,
為了方便接下來的敘述,我們將P-R曲線繪制成單調平滑的曲線(注意,現實任務中的P-R曲線通常是非單調,不平滑的,在很多區域有上下波動,可參考上圖),如下圖:
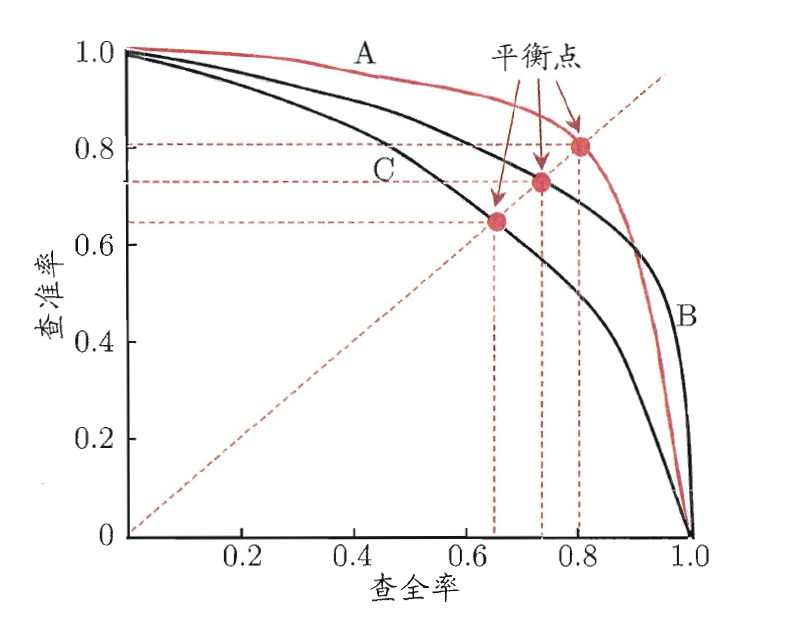
P-R 圖直觀地展示了分類器在樣本總體上的查全率與查準率,在進行比較時,若一個分類器的P-R曲線被另一個分類器的曲線完全包住,則可斷言后者的性能優于前者,例如,上圖中 B B B 的性能要優于 C C C,
如果兩個分類器的P-R曲線發生交叉,例如上圖中的 A A A 和 B B B,這時一個比較合理的判據是比較P-R曲線下面積的大小,它在一定程度上表征了分類器在查準率和查全率上取得相對 “雙高” 的比例,但這個值不容易估算,因此需要設計一些能綜合考察查準率和查全率的性能度量,
平衡點(Break-Even Point,簡稱BEP)就是這樣一種度量,它是 P = R P=R P=R 時的取值,對于本節一開始提到的例子,其平衡點為 0.67 0.67 0.67,
2.4 F 1 F1 F1 與 F β F_{\beta} Fβ?
上述提到的BEP過于簡化了一些,我們更常用的是 F 1 F1 F1 度量,它是基于查準率和查全率的調和平均定義的:
1 F 1 = 1 2 ( 1 P + 1 R ) \frac{1}{F1}=\frac12\left(\frac1P+\frac1R\right) F11?=21?(P1?+R1?)
化簡得到
F 1 = 2 ? P ? R P + R F1=\frac{2\cdot P\cdot R}{P+R} F1=P+R2?P?R?
在一些應用中,我們對查準率和查全率的重視程度有所不同,因此需要引入 F 1 F1 F1 度量的一般形式—— F β F_{\beta} Fβ?,它能讓我們表達出對查準率 / / /查全率的不同偏好,它定義為查準率和查全率的加權調和平均:
1 F β = 1 1 + β 2 ( 1 P + β 2 R ) , β > 0 \frac{1}{F_{\beta}}=\frac{1}{1+\beta^2}\left(\frac1P+\frac{\beta^2}{R}\right),\quad \beta>0 Fβ?1?=1+β21?(P1?+Rβ2?),β>0
化簡得到
F β = ( 1 + β 2 ) ? P ? R β 2 ? P + R , β > 0 F_{\beta}=\frac{(1+\beta^2)\cdot P\cdot R}{\beta^2\cdot P+R},\quad \beta>0 Fβ?=β2?P+R(1+β2)?P?R?,β>0
- β = 1 \beta=1 β=1, F β F_{\beta} Fβ? 退化為 F 1 F1 F1;
- β > 1 \beta>1 β>1,查全率有更大影響;
- β < 1 \beta<1 β<1,查準率有更大影響,
F 1 F1 F1 與 F β F_{\beta} Fβ? 是適用于分類任務的性能度量,相應的實作如下:
""" F1 """
from sklearn.metrics import f1_score
f1 = f1_score(y_true, y_pred)
""" Fbeta """
from sklearn.metrics import fbeta_score
fbeta = fbeta_score(y_true, y_pred, beta=0.5) # 以beta=0.5為例
三、ROC與AUC
3.1 ROC(Receiver Operating Characteristic)
此前我們已經提到,對 m m m 個樣例的得分從高到低排序可以得到一個有序串列,在不同的應用任務中,我們可根據任務需求來設定不同的閾值(截斷點),若更重視查準率,則可在串列中靠前的位置進行截斷;若更重視查全率,則可在串列中靠后的位置進行截斷,
因此,排序本身質量的好壞,體現了綜合考慮學習器在不同任務下的期望泛化性能的好壞,ROC曲線則是從這個角度出發來研究學習器泛化性能的有力工具,
ROC全稱是 受試者作業特征(Receiver Operating Characteristic),它源于二戰中用于敵機檢測的雷達信號分析技術,此后被引入機器學習領域中,
ROC曲線與P-R曲線很相似,在P-R曲線中,縱坐標采用的是查準率,橫坐標采用的是查全率,但在ROC曲線中,縱坐標采用的是真正例率(True Positive Rate,簡稱TPR),橫坐標采用的是假正例率(False Positive Rate,簡稱FPR),兩者分別定義為
T P R = T P T P + F N = R , F P R = F P T N + F P TPR=\frac{TP}{TP+FN}=R,\quad FPR=\frac{FP}{TN+FP} TPR=TP+FNTP?=R,FPR=TN+FPFP?
我們將諸 ( F P R , T P R ) (FPR,TPR) (FPR,TPR) 點用線段連接起來就得到了ROC曲線,
sklearn.metrics 中提供了實作ROC曲線的函式 roc_curve(),相應的用法如下:
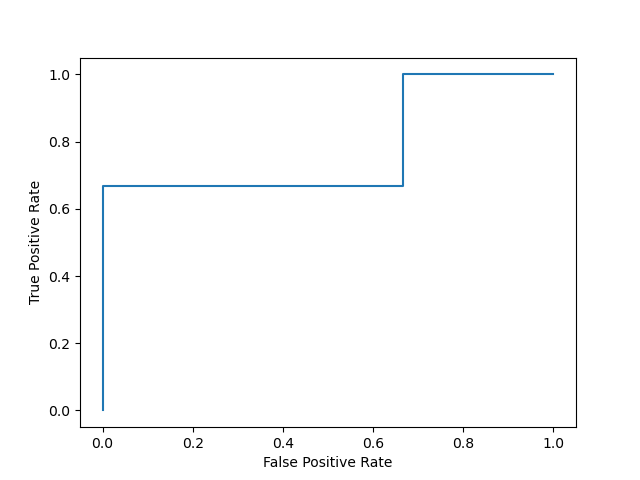
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
fpr, tpr, _ = roc_curve(y_true, y_score)
plt.plot(fpr, tpr)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
當然我們也可以直接用 RocCurveDisplay() 來快速繪制:
from sklearn.metrics import roc_curve, RocCurveDisplay
import matplotlib.pyplot as plt
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
fpr, tpr, _ = roc_curve(y_true, y_score)
disp = RocCurveDisplay(fpr=fpr, tpr=tpr)
disp.plot()
plt.show()
輸出結果和上圖是一致的,
從圖中可以看出,ROC曲線也呈鋸齒狀,且每一段都是橫平豎直的,此外,ROC曲線呈 “上升” 趨勢,它的第一個點和最后一個點一定會分別位于 ( 0 , 0 ) (0,0) (0,0) 和 ( 1 , 1 ) (1,1) (1,1),學習器的性能越好,ROC曲線越接近圖中的左上角,
設當前閾值所對應的點為 ( x , y ) (x,y) (x,y),我們依次下調閾值,當經過一個正例時,下一個點的坐標為 ( x , y + 1 / m + ) (x,y+1/m^+) (x,y+1/m+);當經過一個反例時,下一個點的坐標為 ( x + 1 / m ? , y ) (x+1/m^-,y) (x+1/m?,y),
3.2 AUC(Area Under roc Curve)
在進行學習器的比較時,與P-R圖相似,若一個學習器的ROC曲線被另一個學習器的曲線完全包住,則可斷言后者的性能優于前者,如果兩個學習器的ROC曲線發生交叉,那么我們就要比較ROC曲線下的面積,即AUC(Area Under roc Curve),如下圖所示
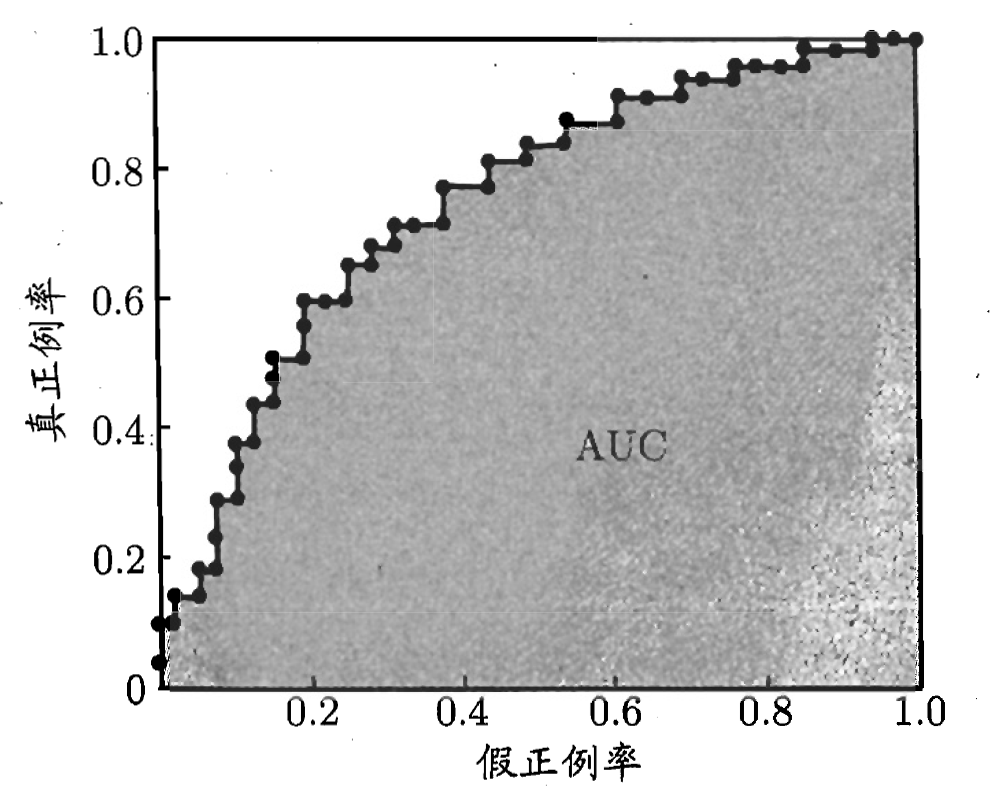
假定ROC曲線是由坐標為 ( x 1 , y 1 ) , ( x 2 , y 2 ) , ? ? , ( x m , y m ) (x_1,y_1),(x_2,y_2),\cdots,(x_m,y_m) (x1?,y1?),(x2?,y2?),?,(xm?,ym?) 的按序連接形成,其中 ( x 1 , y 1 ) = ( 0 , 0 ) , ? ( x m , y m ) = ( 1 , 1 ) (x_1,y_1)=(0,0),\,(x_m,y_m)=(1,1) (x1?,y1?)=(0,0),(xm?,ym?)=(1,1),則AUC為
A U C = ∑ i = 1 m ? 1 ( x i + 1 ? x i ) ? y i + 1 + y i 2 \mathrm{AUC}=\sum_{i=1}^{m-1}(x_{i+1}-x_i)\cdot \frac{y_{i+1}+y_i}{2} AUC=i=1∑m?1?(xi+1??xi?)?2yi+1?+yi??
sklearn.metrics 中的 auc() 就是根據上述公式進行計算的,相應代碼如下:
from sklearn.metrics import roc_curve, auc
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
fpr, tpr, _ = roc_curve(y_true, y_score)
print(auc(fpr, tpr))
# 0.7777777777777778
但上面這種做法需要先計算出橫縱坐標 fpr、tpr,更快捷的方法是使用 roc_auc_score():
from sklearn.metrics import roc_auc_score
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
print(roc_auc_score(y_true, y_score))
# 0.7777777777777778
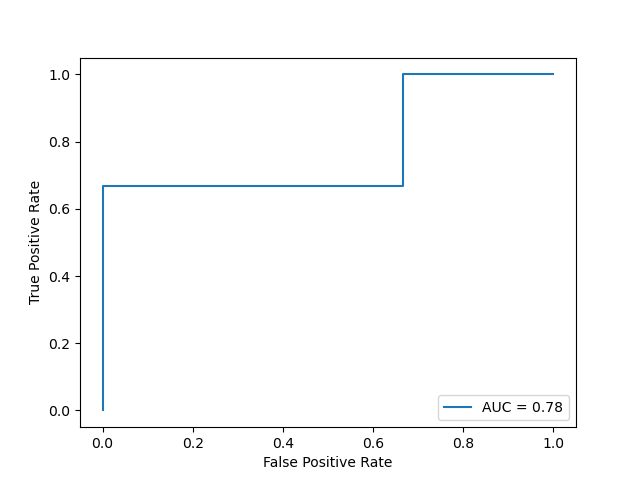
如果我們想要在ROC曲線圖上顯示AUC,則需要將AUC傳入 RocCurveDisplay() 中的 roc_auc 中:
from sklearn.metrics import roc_curve, RocCurveDisplay, auc
import matplotlib.pyplot as plt
y_true = [1, 0, 0, 1, 0, 1]
y_score = [0.45, 0.53, 0.24, 0.88, 0.57, 0.76]
fpr, tpr, _ = roc_curve(y_true, y_score)
roc_auc = auc(fpr, tpr)
disp = RocCurveDisplay(fpr=fpr, tpr=tpr, roc_auc=roc_auc)
disp.plot()
plt.show()
AUC的進一步討論:忽略不同樣例得分相同的情形,令 D + D^+ D+ 和 D ? D^- D? 分別表示正、反例集合,且 ∣ D + ∣ = m + , ? ∣ D ? ∣ = m ? |D^+|=m^+,\, |D^-|=m^- ∣D+∣=m+,∣D?∣=m?,則AUC可以表示成:
A U C = 1 m + m ? ∑ x + ∈ D + ∑ x ? ∈ D ? I [ f ( x + ) > f ( x ? ) ] \mathrm{AUC}=\frac{1}{m^+m^-}\sum_{\boldsymbol{x}^+\in D^+}\sum_{\boldsymbol{x}^-\in D^-}\mathbb{I}[f(\boldsymbol{x}^+)>f(\boldsymbol{x}^-)] AUC=m+m?1?x+∈D+∑?x?∈D?∑?I[f(x+)>f(x?)]
從上面的運算式可以看出,AUC實際上反應了樣本中一個正例得分大于一個負例得分的概率,即樣本預測的排序質量,
定義排序損失為
? r a n k = 1 m + m ? ∑ x + ∈ D + ∑ x ? ∈ D ? I [ f ( x + ) < f ( x ? ) ] \ell_{rank}=\frac{1}{m^+m^-}\sum_{\boldsymbol{x}^+\in D^+}\sum_{\boldsymbol{x}^-\in D^-}\mathbb{I}[f(\boldsymbol{x}^+)<f(\boldsymbol{x}^-)] ?rank?=m+m?1?x+∈D+∑?x?∈D?∑?I[f(x+)<f(x?)]
容易看出 A U C + ? r a n k = 1 \mathrm{AUC}+\ell_{rank}=1 AUC+?rank?=1,即 ? r a n k \ell_{rank} ?rank? 是ROC曲線上方的面積,
References
[1] 機器學習.周志華
[2] Metrics and scoring: quantifying the quality of predictions.
[3] 11565 P-R、ROC、DET 曲線及 AP、AUC 指標全決議(上).
[4] sklearn’s precision_recall_curve incorrect on small example.
[5] sklearn precision_recall_curve and threshold.
[6] How does sklearn select threshold steps in precision recall curve?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/437972.html
標籤:AI
上一篇:OpenCV-人像—酷感冷艷濾鏡
下一篇:YOLOv4網路結構詳解