計算機視覺與深度學習
本文按照北京郵電大學計算機學院魯鵬老師的計算機視覺與深度學習課程按章節進行整理,需要的同學可借此系統學習該課程詳盡知識~
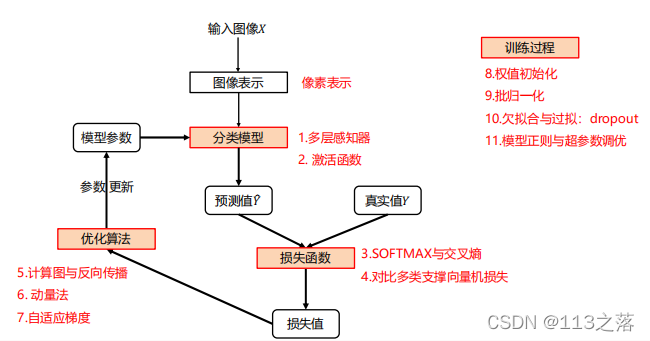
第四章 全連接神經網路
- 計算機視覺與深度學習
- 本節重點
- 一、分類模型
- 1.多層感知器
- 全連接神經網路權值
- 全連接神經網路與線性分類器區分
- 全連接神經網路繪制及命名
- 2.激活函式
- 網路結構設計
- 激活函式缺陷
- 激活函式選擇
- 二、損失函式
- 1.SOFTMAX與交叉熵(交叉熵損失)
- 示例
- 2.交叉熵損失與多類支撐向量機損失對比
- 三、優化演算法
- 1.計算圖與反向傳播
- 示例一
- 示例二
- 2.梯度下降演算法缺陷
- 3.動量法
- 4.自適應梯度法
- 5.ADAM法
- 訓練程序
- 1.權值初始化
- Xavier初始化
- HE初始化(MSRA)
- 2.批歸一化
- 3.欠擬合與過擬合
- 應對過擬合
- 權重正則化
- 隨機失活(Dropout)
- 4.超引數調優
- 學習率設定
- 超引數優化方法
- 超引數搜索策略
- 超引數標尺空間
本節重點
一、分類模型
1.多層感知器

全連接神經網路權值
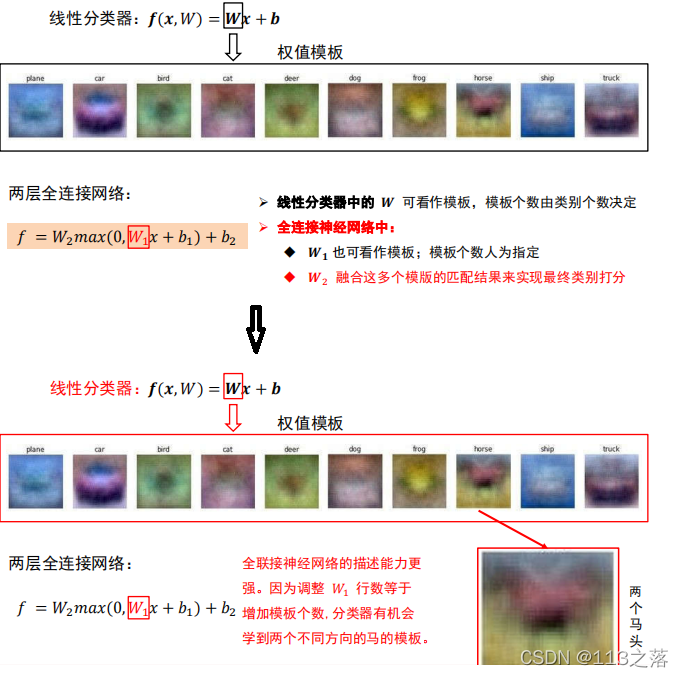
全連接神經網路與線性分類器區分
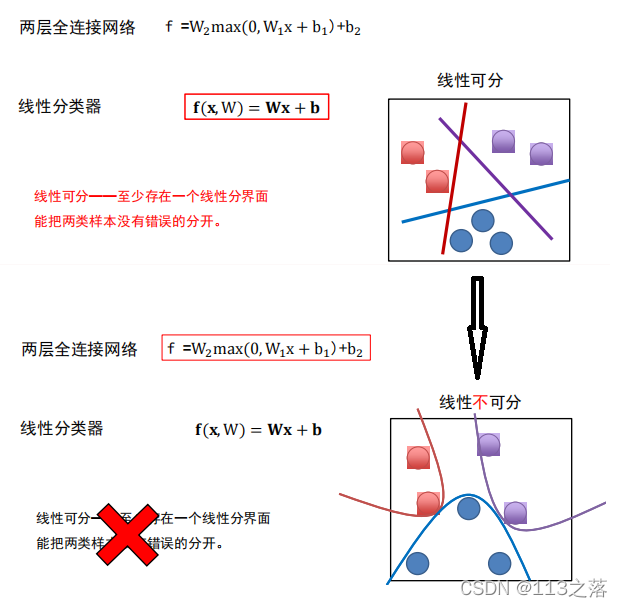
全連接神經網路繪制及命名
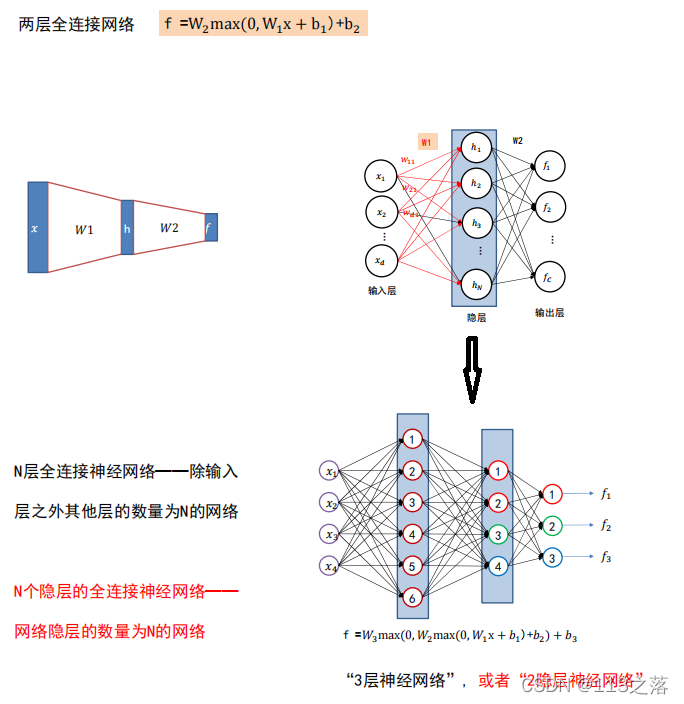
2.激活函式

常用的激活函式
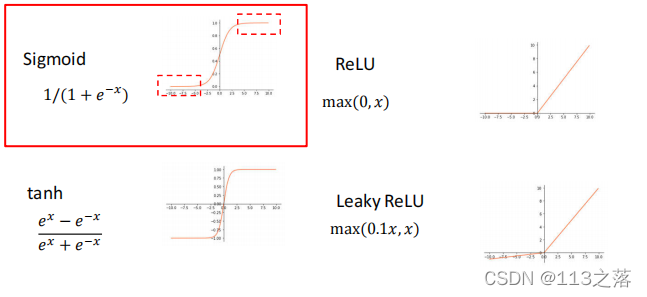
網路結構設計
- 用不用隱層,用一個還是用幾個隱層? (深度設計)
- 每隱層設定多少個神經元比較合適? (寬度設計)
注:
1)神經元個數越多,分界面就可以越復雜,在這個集合上的分類能力就越強,
2)輸入層與輸出層的神經元個數由任務決定,而隱層數量以及每個隱層的神經元個數需要人為指定,
依據分類任務的難易程度來調整神經網路模型的復雜程度,分類任務越難,我們設計的神經網路結構就應該越深、越寬,但是,需要注意的是對訓練集分類精度最高的全連接神經網路模型,在真實場景下識別性能未必是最好的(過擬合),
激活函式缺陷
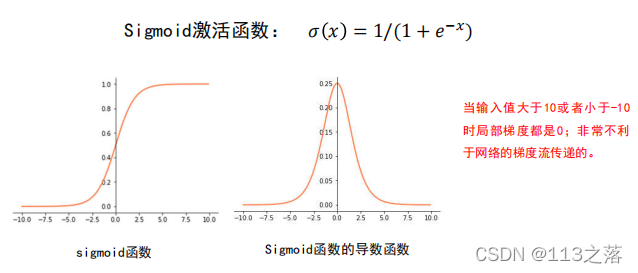
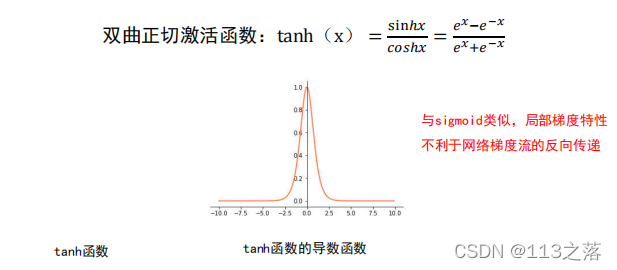
梯度消失是神經網路訓練中非常致命的一個問題,其本質是由于鏈式法則的乘法特性導致的,
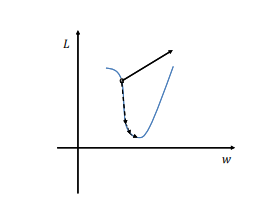
梯度爆炸:斷崖處梯度乘以學習率后會是一個非常大得值,從而“飛”出了合理區域,最終導致演算法不收斂,
解決方案:把沿梯度方向前進的步長限制在某個值內就可以避免“飛”出了,這個方法也稱為梯度裁剪,
激活函式選擇
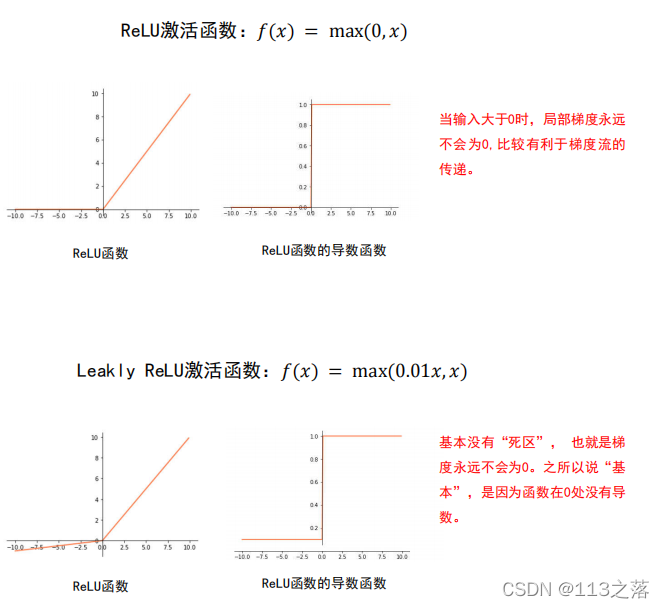
盡量選擇ReLU函式或者Leakly ReLU函式,相對于Sigmoi d/tanh,RelLU函式或者Leakly ReLU函式會讓梯度流更加順暢,訓練程序收斂得更快,
二、損失函式
1.SOFTMAX與交叉熵(交叉熵損失)
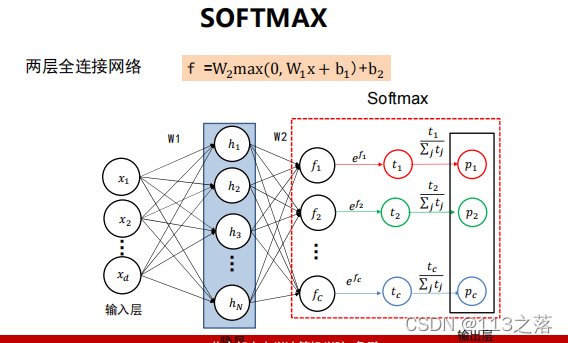
示例

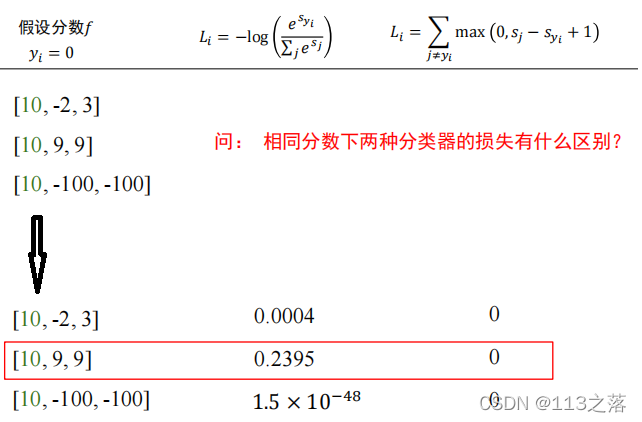
2.交叉熵損失與多類支撐向量機損失對比

三、優化演算法
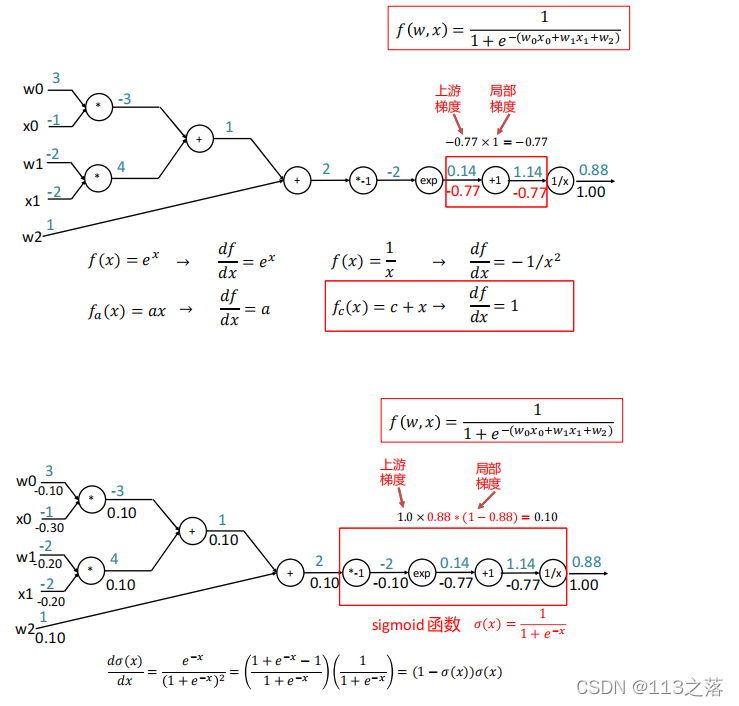
1.計算圖與反向傳播
計算圖是一種有向圖,它用來表達輸入、輸出以及中間變數之間的計算關系,圖中的每個節點對應著一種數學運算,
示例一
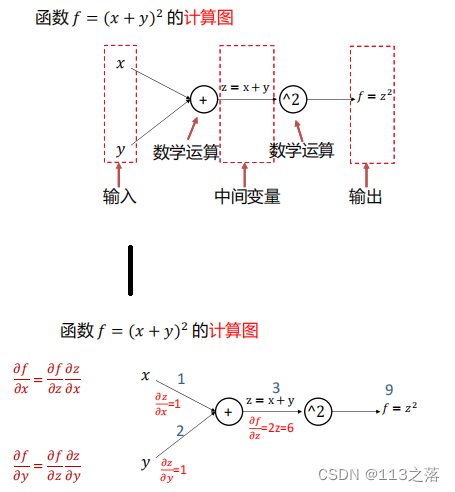
示例二
附:計算圖中常見的門單元
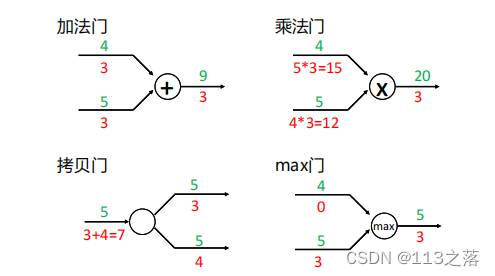
總結
- 任意復雜的函式,都可以用計算圖的形式表示,
- 在整個計算圖中,每個門單元都會得到一些輸入,然后,進行下面兩個計算:
a)這個門的輸出值
b)其輸出值關于輸入值的區域梯度, - 利用鏈式法則,門單元應該將回傳的梯度乘以它對其的輸入的區域梯度,從而得到整個網路的輸出對該門單元的每個輸入值的梯度,
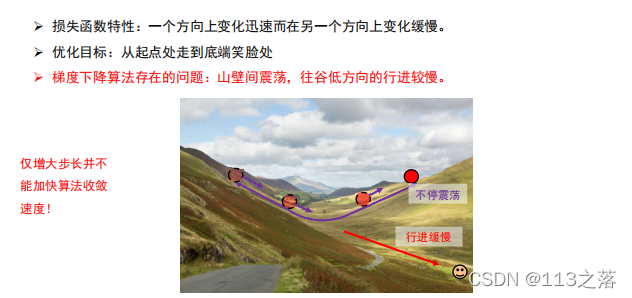
2.梯度下降演算法缺陷
3.動量法

4.自適應梯度法

5.ADAM法

訓練程序
1.權值初始化

Xavier初始化
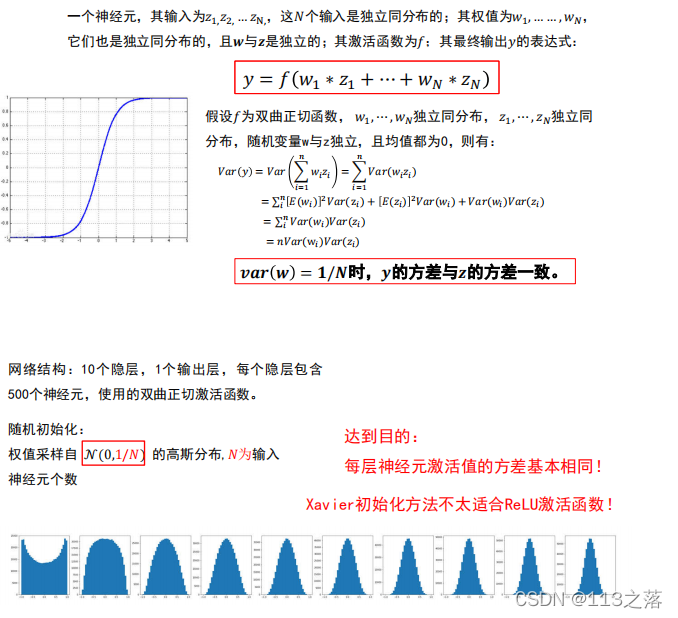
HE初始化(MSRA)

權值初始化方法選擇
- 好的初始化方法可以防止前向傳播程序中的資訊消失,也可以解決反向傳遞程序中的梯度消失,
- 激活函式選擇雙曲正切或者Sigmoi d時,建議使用Xaizer初始化方法,
- 激活函式選擇ReLU或Leakly ReLU時,推薦使用He初始化方法,
2.批歸一化
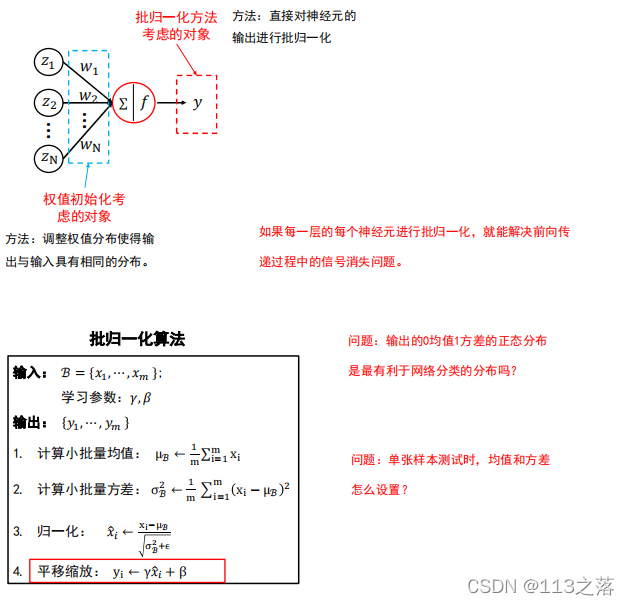
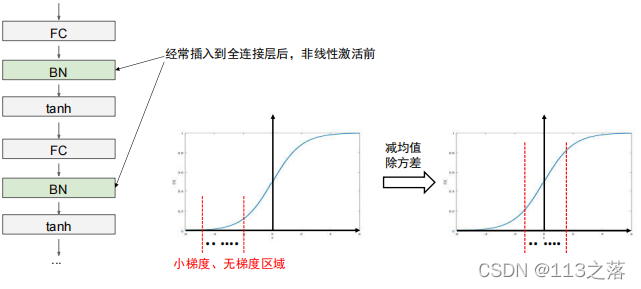
3.欠擬合與過擬合
欠擬合:是指模型描述能力太弱,以至于不能很好地學習到資料中的規律,產生欠擬合的原因通常是模型過于簡單,
過擬合:是指學習時選擇的模型所包含的引數過多,以至于出現這一模型對已知資料預測的很好,但對未知資料預測得很差的現象,這種情況下模型可能只是記住了訓練集資料,而不是學習到了資料特征,
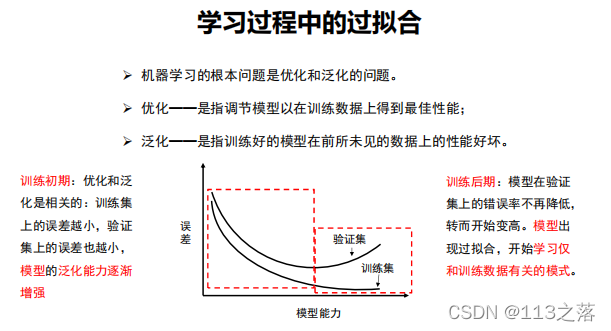
應對過擬合
最優方案——獲取更多的訓練資料
次優方案——調節模型允許存盤的資訊量或者對模型允許存盤的資訊加以約束,該類方法也稱為正則化,
- 調節模型大小
- 約束模型權重,即權重正則化(常用的有L1、L2正則化)
- 隨機失活(Dr opout)
權重正則化

隨機失活(Dropout)
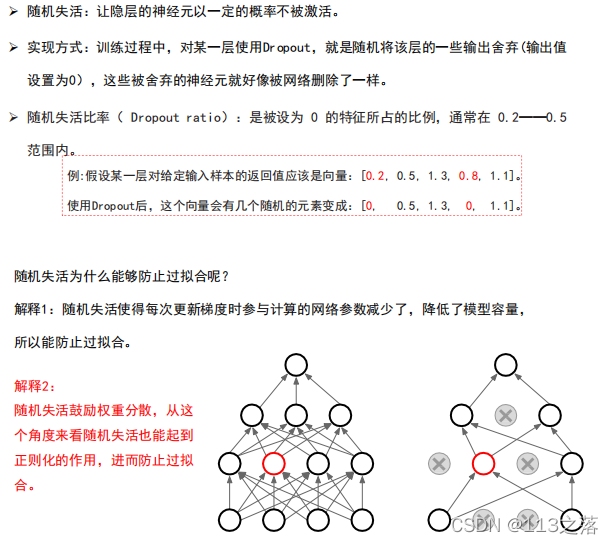
4.超引數調優
超引數
- 網路結構——隱層神經元個數,網路層數,非線性單元選擇等
- 優化相關——學習率、dr opout比率、正則項強度等
學習率設定

超引數優化方法
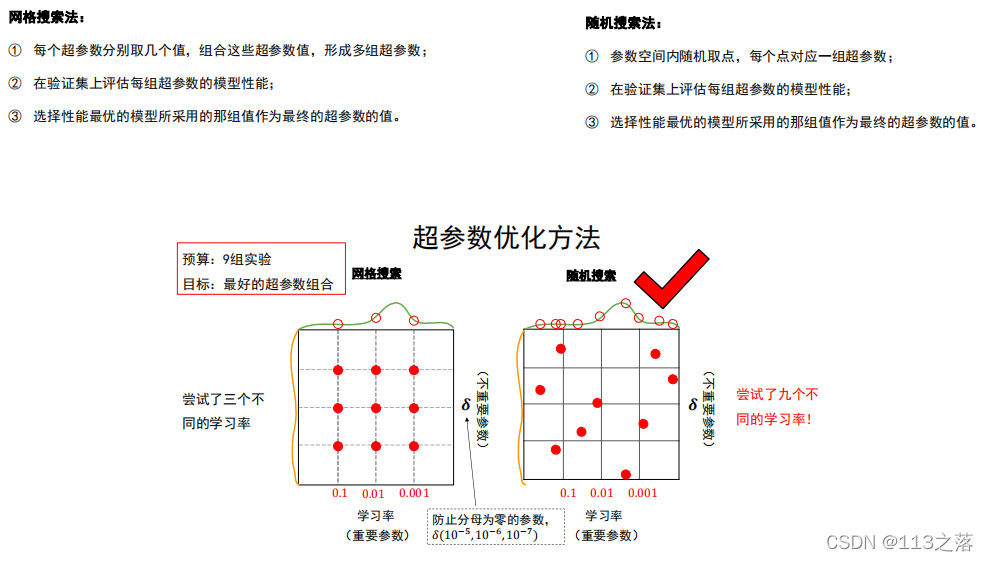
超引數搜索策略

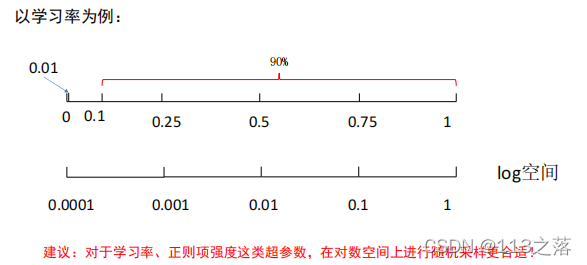
超引數標尺空間
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438065.html
標籤:AI