【openVINO+paddle】CPU部署新冠肺炎CT影像分類識別與病害分割
在這個專案中是我在看到一位大佬代碼生成器的專案文章時想要嘗試開發的一個專案,主要是想要在飛槳上通過Cla與Seg(分類和分割)模型對CT影像進行處理,然后將他們匯出onnx模型下載到自己的設備上,通過openVINO轉化為IR模型后,能夠在CPU上就能夠實作對新冠肺炎CT圖片進行處理,
這里我會提供所有的資料和已經跑通的代碼,我已經把我的源代碼和相關資料資料全部上傳到百度aistudio上,你可以直接在下面的鏈接搜索到:
https://aistudio.baidu.com/aistudio/projectdetail/3460633
因為考慮到OpenVINO這部分比較簡潔,這篇文章先展示CPU OpenVINO上的效果,然后再展示如何在飛槳上進行模型和匯出,
先看OpenVINO的效果圖:
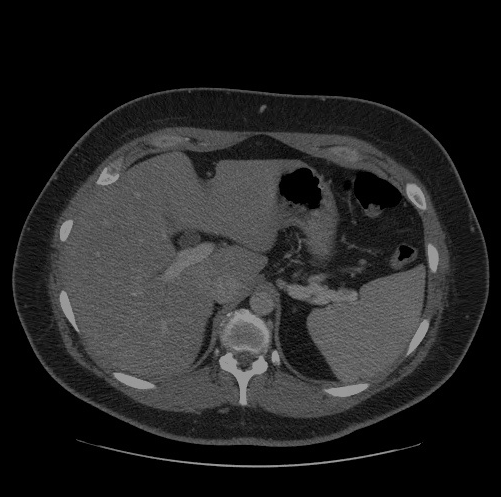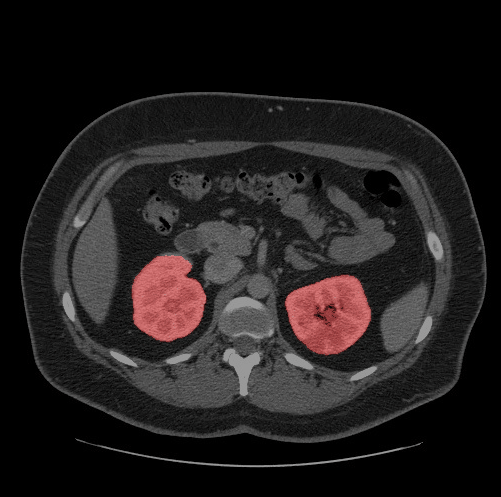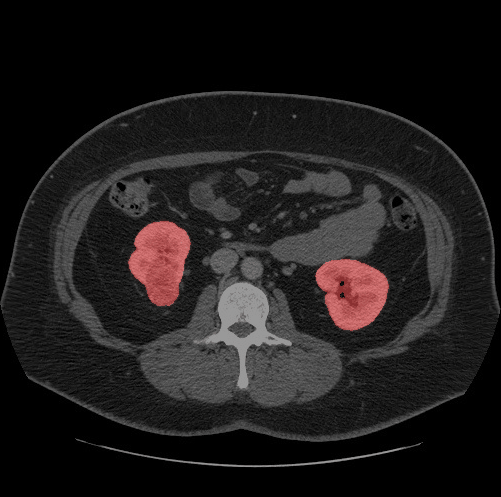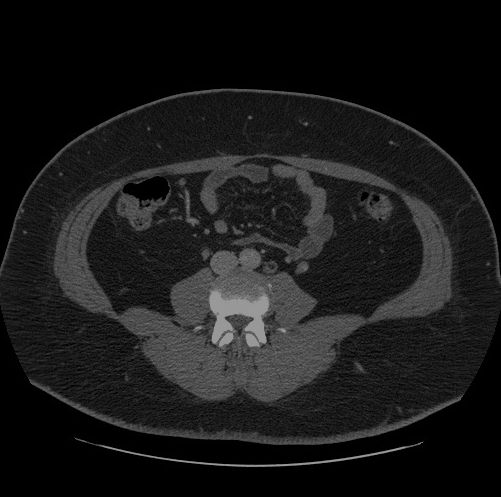
OpenVINO進行推理
這里直接提供IR模型,下面會教你在飛槳訓練如何匯出ONNX模型并轉化為IR模型,你可以在這個鏈接下載到模型鏈接
你只需要下載下來放到和自己的jupyter notebook上即可,
首先你需要引入所需要的庫,這里涉及到Open VINO的notebook安裝,這個可以參考我的另一篇博客查看OpenVINO的notebook以及環境配置,這里可以先看這個代碼,不算太難,
首先import所需要的庫
import os
import sys
import zipfile
from pathlib import Path
from openvino.inference_engine import IECore
sys.path.append("../utils")
from models.custom_segmentation import SegmentationModel
from notebook_utils import benchmark_model, download_file, show_live_inference
這里如果已經下載好鏈接中的模型,你就將這個模型的路徑配置到雙引號中,將IR_PATH設定為"pretrained_model/unet44.xml",
MODEL_PATH = "pretrained_model/quantized_unet_kits19.xml"
我們需要呼叫好所需的硬體,不僅可以使用CPU,還可以使用GPU等,
ie = IECore()
device = "MULTI:CPU,GPU" if "GPU" in ie.available_devices else "CPU"
為了測量模型推理性能,這里使用了OpenVINO的推理性能測量工具Benchmark Tool,你可以直接在note book上用命令! benchmark_app or %sx benchmark_app來啟動,這里我們直接使用Notebook Utils中的包裝器函式,
benchmark_model(model_path=MODEL_PATH, device=device, seconds=15)
下載和準備資料
這里的資料集直接提供了一個鏈接來下載我們的資料集,注意這里不是訓練,而是簡單地下載一個小小的訓練集,因為這里如果路徑下沒有就可以直接下載,
BASEDIR = Path("kits19_frames_1")
CASE = 117
case_path = BASEDIR / f"case_{CASE:05d}"
if not case_path.exists():
filename = download_file(
f"https://storage.openvinotoolkit.org/data/test_data/openvino_notebooks/kits19/case_{CASE:05d}.zip"
)
with zipfile.ZipFile(filename, "r") as zip_ref:
zip_ref.extractall(path=BASEDIR)
os.remove(filename) # remove zipfile
print(f"Downloaded and extracted data for case_{CASE:05d}")
else:
print(f"Data for case_{CASE:05d} exists")
顯示生活推理
為了在筆記本上顯示實時推理,我們使用了OpenVINO推理引擎的異步處理的特點,(推理有多種方式,異步同步可以見我的博客那個OPENVINO的課程下)
我們使用Notebook Utils中的show_live_inference函式來顯示實時推理的引數,這個函式使用Open Model Zoo的AsyncPipeline和Model API來執行異步推理,當對指定CT掃描的推理完成后,在結果圖上打出包括預處理和顯示在內的總時間和吞吐量(fps),
ie = IECore()
segmentation_model = SegmentationModel(ie=ie, model_path=Path(MODEL_PATH), sigmoid=True)
image_paths = sorted(case_path.glob("imaging_frames/*jpg"))
print(f"{case_path.name}, {len(image_paths)} images")
進行推理
這里我們運行show live_inference函式,該函式將影像分割加載到指定的設備、加載影像、執行推理,并實時地在影像中加載的幀上顯示結果,
device = "MULTI:CPU,GPU" if "GPU" in ie.available_devices else "CPU"
show_live_inference(
ie=ie, image_paths=image_paths, model=segmentation_model, device=device
)
如果中間有一些不會的地方可以看下這期間參考的一些大佬專案與技術檔案,
- https://aistudio.baidu.com/aistudio/projectdetail/3459413
- https://aistudio.baidu.com/aistudio/projectdetail/3460443?forkThirdPart=1
- https://aistudio.baidu.com/aistudio/projectdetail/3460337?contributionType=1
- https://aistudio.baidu.com/aistudio/projectdetail/3461846
- https://aistudio.baidu.com/aistudio/projectdetail/3460268?forkThirdPart=1
- https://aistudio.baidu.com/aistudio/projectdetail/3460317?contributionType=1
資料集獲取
這個就是用來分類的圖片,下面這張圖片是新冠肺炎患者的肺部CT圖,第二張圖片時正常人體的CT圖片,下部有很明顯的不同,
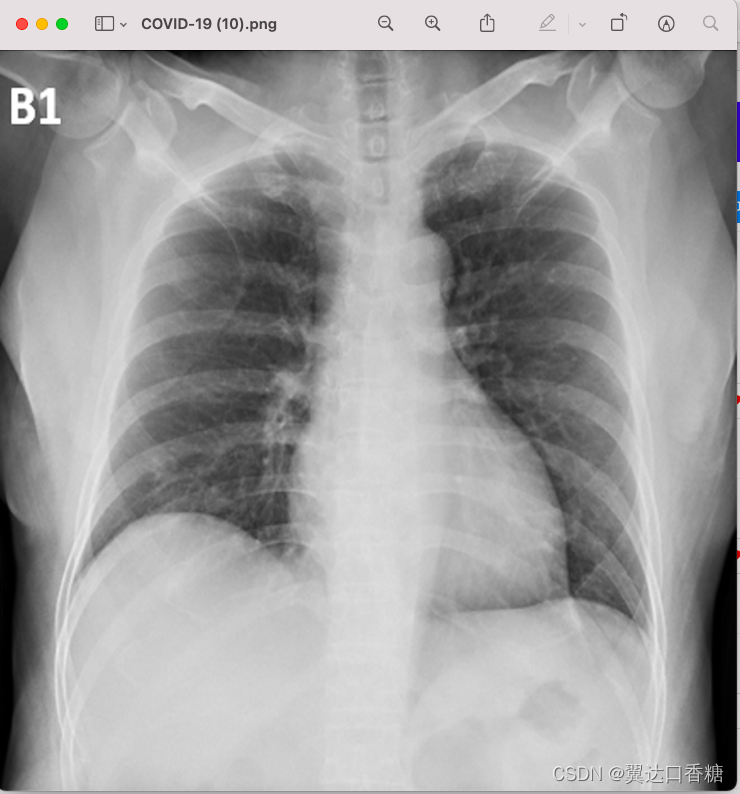
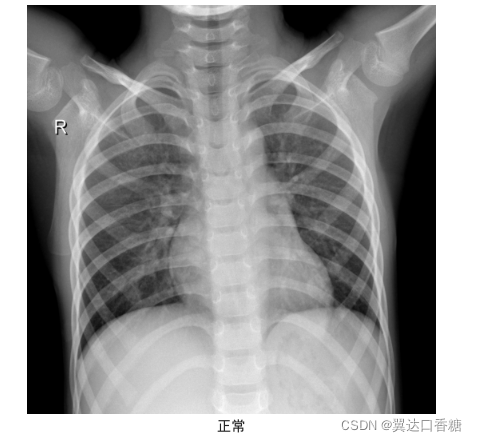
使用的資料集是 covid19-radiography-database,下面是資料的鏈接,COVID-19 RADIOGRAPHY DATABASE組合了意大利,Ieee8023和40余篇論文中的CT掃描,形成了一個有219張新冠病例,1341張正常掃描和1345張肺炎掃描的資料集,點開資料集直接參考,
https://aistudio.baidu.com/aistudio/datasetdetail/34241
資料自帶的醫學免責宣告: 97% 僅為實驗資料集上的結果,任何臨床使用的演算法需要在實際使用環境下進行實驗,本模型分類結果不可作為臨床診療依據,
這里用的資料集是 covid19-ct-scans,資料集包含Ieee8023收集的20組新冠掃描,并對其進行了左右肺和感染區的標注,下面是標注的示例,
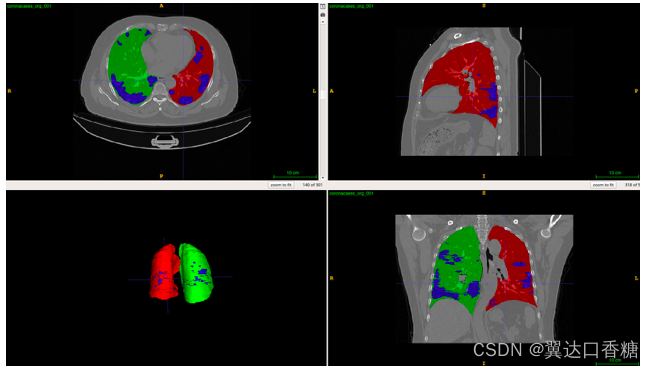
下面是資料的鏈接,只需要直接下載或者直接參考到自己aistudio中即可,
https://aistudio.baidu.com/aistudio/datasetdetail/34221
資料的醫學免責宣告: 任何臨床使用的演算法需要在實際使用環境下進行測驗,本模型結果不可作為臨床診療依據,
paddlecla-新冠CT分類模型訓練與匯出
1、資料集預處理
運行下面的代碼解壓資料集,一定要注意一點是,在解壓后會得到三個txt檔案在data目錄下,是和我們創建的image同一個目錄的,因為我們這個專案是要解壓兩個資料集,所以在結束第一個模型訓練后要這個三個txt檔案刪掉,如果你使用的是aistudio,你可以去查看一下~/data/images 目錄下有三個檔案夾,COVID-19,Viral Pneumonia和NORMAL,分別存放著三個類別的影像,
!mkdir /home/aistudio/data/images
!unzip -q /home/aistudio/data/data34241/covid19-combo.zip -d /home/aistudio/data/images
!mv /home/aistudio/data/images/'COVID-19 Radiography Database'/* /home/aistudio/data/images
!rm -rf /home/aistudio/data/images/'COVID-19 Radiography Database'
!ls ~/data/images
PaddleClas還需要提供一個資料串列檔案,里面每條資料按照 “檔案路徑 類別” 的格式標記,以供后續訓練,同時還要要做的是把資料分組,你需要訓練、評估和測驗都需要資料集,代碼如下
%cd ~
import os
base_dir = "/home/aistudio/data/images/" # CT圖片所在路徑
img_dirs = ["COVID-19", "NORMAL", "Viral Pneumonia"] # 三類CT圖片檔案夾名
file_names = ["train_list.txt", "val_list.txt", "test_list.txt"]
splits = [0, 0.6, 0.8, 1] # 按照 6 2 2 的比例對資料進行分組
for split_ind, file_name in enumerate(file_names):
with open(os.path.join("./data", file_name), "w") as f:
for type_ind, img_dir in enumerate(img_dirs):
imgs = os.listdir(os.path.join(base_dir, img_dir) )
for ind in range( int(splits[split_ind]* len(imgs)), int(splits[split_ind + 1] * len(imgs)) ):
print("{}|{}".format(img_dir + "/" + imgs[ind], type_ind), file = f)
檔案串列制作完成后可以用head查看一下前10行,
! head /home/aistudio/data/train_list.txt
2、paddleclas配置
我把飛槳的一個壓縮包已經上傳到了平臺上,可以直接點開我的專案下載解壓就行,這個其實就是git從飛槳下載的代碼包,但是經過裁剪不到150M,方便傳輸,解壓后你需要運行第二行代碼,用來進行環境初始化的,其實你可以打開看看,里面寫著一些需要安裝的依賴,
!unzip -q pdclas.zip
%cd pdclas
!pip install -r requirements.txt
接下里我是要利用GPU進行模型訓練,所以在訓練前需要初始化環境
!python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
3、模型訓練
下面就到了模型訓練這一個關鍵一步,用PaddleClas訓練模型需要撰寫config檔案,這個檔案是對訓練步驟的細節進行定義,比如說epochs要多少,batch size要多少,這里可以根據你的硬體需求修改這個covid-2.yaml組態檔,如果檔案丟失也可以復制下面的代碼,但是一定要注意的是,我提供的檔案由于我是使用32G記憶體的顯卡,所以我的檔案中的batch_size:給到了16,同時為了獲取精確度高達95%以上的模型,我的組態檔是epoch是15步,訓練時長是半個小時左右,
mode: 'train'
ARCHITECTURE:
# 使用的模型結構,可以參照 pdclas/config 下其他模型結構的cofig檔案修改模型名稱
# 比如 ResNet101
name: 'ResNet50_vd'
pretrained_model: "" # 通常使用預訓練模型遷移能在小資料集上取得好的效果,但是預訓練模型都是針對自然影像,因此沒有使用
model_save_dir: "./output/"
classes_num: 3
total_images: 2905
save_interval: 1
validate: True
valid_interval: 1
epochs: 20
topk: 2
image_shape: [3, 1024, 1024]
LEARNING_RATE:
function: 'Cosine'
params:
lr: 0.00375
OPTIMIZER:
function: 'Momentum'
params:
momentum: 0.9
regularizer:
function: 'L2'
factor: 0.000001
TRAIN:
batch_size: 4 # 訓練程序中一個batch的大小,如果你有幸分到32g顯卡這個引數最高開到16
num_workers: 4
file_list: "/home/aistudio/data/train_list.txt"
data_dir: "/home/aistudio/data/images/"
delimiter: "|"
shuffle_seed: 0
transforms:
- DecodeImage:
to_rgb: True
to_np: False
channel_first: False
- RandFlipImage:
flip_code: 1
- NormalizeImage:
scale: 1./255.
- ToCHWImage:
VALID:
batch_size: 20
num_workers: 4
file_list: "/home/aistudio/data/val_list.txt"
data_dir: "/home/aistudio/data/images/"
delimiter: "|"
shuffle_seed: 0
transforms:
- DecodeImage:
to_rgb: True
to_np: False
channel_first: False
- ResizeImage:
resize_short: 1024
- NormalizeImage:
scale: 1.0/255.0
- ToCHWImage:
接下來開始訓練,一般pdclas是在命令列環境下使用的,這里需要注意的是啟動訓練之前需要設定一個環境變數,代碼如下,值得注意的是,如果出現報錯說到這個paddle.enable_static()的話,你需要順著路徑打開這個檔案,比如說train.py和export.py(匯出那里),在上方補充下面這兩段代碼,
import paddle
paddle.enable_static()
%cd ~/pdclas/
import os
os.environ['PYTHONPATH']="/home/aistudio/pdclas"
!python -m paddle.distributed.launch --selected_gpus="0" tools/train.py -c ../covid-2.yaml
4、模型匯出
訓練好這是提前指定的存盤路徑,如果你沒有更改的話可以運行下面的代碼查看好的模型,
!ls ~/pdclas/output/ResNet50_vd
通過pdclas中提供的模型轉換腳本將訓練模型轉換為推理模型,可以看到轉換之后生成了兩個檔案,model是模型結構,params是模型權重,這里要提一下Paddle框架保存的權重檔案分為兩種:支持前向推理和反向梯度的訓練模型 和 只支持前向推理的推理模型,二者的區別是推理模型針對推理速度和顯存做了優化,裁剪了一些只在訓練程序中才需要的tensor,降低顯存占用,并進行了一些類似層融合,kernel選擇的速度優化,ppcls在訓練程序中保存的模型屬于訓練模型,在這個程序我們一般使用推理模型比較方便去匯出onnx模型,第二個也要考慮到推理模型體量比較小方便傳輸,
!python tools/export_model.py --m=ResNet50_vd --p=output/ResNet50_vd/best_model_in_epoch_0/ppcls --o=../inference
!ls -lh /home/aistudio/inference/
這里我回到原路來展示一下現在我的檔案夾,是這個專案在飛槳這一側的所有檔案了,%cd ~是為了回到根目錄等會要進行推理,
%cd ~/
!ls
你可以使用匯出的模型對任意一張資料集的圖片進行推理,對照上面生成訓練檔案時的腳本,新冠類別為0,正常類別為1,其他肺炎類別為2,一般這里的分類都是這個患者是新冠肺炎患者,概率為百分百,
!python /home/aistudio/pdclas/tools/infer/predict.py --use_gpu=0 -i="/home/aistudio/COVID-19 (10).png" -m=/home/aistudio/inference/model -p=/home/aistudio/inference/params
由于我的環境安裝在了paddleSeg這部分了,所以這里先留著到你下面匯出了分割模型再回來導這個,這樣子就不會出現報錯,
!paddle2onnx \
--model_dir inference/ \
--model_filename model \
--params_filename params \
--save_file model_1.onnx \
--opset_version 12
新冠CT分割部分與onnx匯出
1、資料集預處理
安裝 nibabel 庫用于讀取 nii 格式資料
!pip install --upgrade nibabel -i https://mirror.baidu.com/pypi/simple
對資料集進行解壓
%cd ~/data/data34221/
!unzip -q -d .. 20_ncov_scan.zip # 掃描資料
!unzip -q -d ../Infection_Mask Infection_Mask.zip # 感染病灶分割標簽
!unzip -qd ../Lung_Mask Lung_Mask.zip # 左右肺分割標簽
# !unzip -qd ../Lung_Infection Lung_Infection.zip # 合并肺部和感染病灶標簽,專案中沒有用上
!ls ~/data/20_ncov_scan
上面可以看到解壓出了20組掃描,PaddleSeg框架只接受圖片格式的輸入,因此我們需要對nii格式的CT掃描進行一點預處理,將他們轉換為圖片,此外在這個程序中我們將掃描資料 clip 到 [-512, 512] 的范圍,防止強度過大或過小的噪點對訓練產生影響,
import os
import nibabel as nib
import numpy as np
from tqdm import tqdm
import cv2
def listdir(path):
dirs = os.listdir(path)
dirs.sort() # 掃描和標簽的檔案名不完全相同,對兩個目錄下的所有檔案進行排序可以保證二者能匹配上
return dirs
scan_dir = "/home/aistudio/data/20_ncov_scan" # CT掃描資料路徑
label_dir = "/home/aistudio/data/Infection_Mask" # 病灶分割標簽所在路徑
output_dir = "/home/aistudio/data/prep"
scan_output = os.path.join(output_dir, "image") # CT圖片輸出路徑
label_output = os.path.join(output_dir, "annotation") # 標簽圖片輸出路徑
if not os.path.exists(scan_output):
os.makedirs(scan_output)
if not os.path.exists(label_output):
os.makedirs(label_output)
wl, wh = (-512, 512) # 對CT進行視窗化的強度范圍
scan_fnames = listdir(scan_dir)
label_fnames = listdir(label_dir)
for case_ind in tqdm( range(len(scan_fnames)) ):
scan_fname = scan_fnames[case_ind]
label_fname = label_fnames[case_ind]
scanf = nib.load(os.path.join(scan_dir, scan_fname)) # 使用nibabel庫讀入資料
scan = scanf.get_fdata()
labelf = nib.load(os.path.join(label_dir, label_fname))
label = labelf.get_fdata()
scan = np.rot90(scan) # 對讀入資料的方向進行矯正,逆時針旋轉90度
label = np.rot90(label)
# 視窗化操作,將范圍轉換到 0~255,便于存入圖片
scan = scan.clip(wl, wh).astype("float16")
scan = ( (scan - wl)/(wh - wl) * 256)
for sli_ind in range(label.shape[2]):
scan_slice_path = os.path.join(scan_output, "{}-{}.png".format(scan_fname.rstrip(".nii.gz"), sli_ind ) )
label_slice_path = os.path.join(label_output, "{}-{}.png".format(scan_fname.rstrip(".nii.gz"), sli_ind ) )
cv2.imwrite(scan_slice_path, scan[:,:,sli_ind])
cv2.imwrite(label_slice_path, label[:,:,sli_ind])
print("圖片轉換完成")
! ls ~/data/prep/image -l | wc -l # 可以看到共生成了3500多張圖片
這里一定要注意再注意,由于我們這個專案解壓了兩個資料集,并且需要生成的檔案是在同一個路徑下,所以你需要data三個檔案洗掉后再執行接下來的操作,資料預處理完后,PaddleSeg需要我們為訓練集,驗證集和測驗集分別提供一個檔案串列 txt,下面代碼的實際功能是將所有訓練資料的路徑按照三個集合的劃分比例寫入三個txt檔案,
import os
data_base_dir = "/home/aistudio/data/prep"
scan_folder = "image"
label_folder = "annotation"
txt_path = "/home/aistudio/data/"
split = [0, 0.7, 0.9, 1.0] # 訓練,驗證和測驗集的劃分比例為 7:2:1
list_names = ["train_list.txt", "val_list.txt", "test_list.txt"]
curr_type = 0
img_count = len(os.listdir( os.path.join(data_base_dir, scan_folder ) ) )
split = [int(x * img_count) for x in split]
f = open(os.path.join(txt_path, list_names[curr_type]), "w")
for ind, slice_name in enumerate(os.listdir( os.path.join(data_base_dir, scan_folder)) ):
if ind < img_count - 1 and ind == split[curr_type + 1]:
curr_type += 1
f.close()
f = open(os.path.join(txt_path, list_names[curr_type]), "w")
print("{}|{}".format(os.path.join(scan_folder, slice_name), os.path.join(label_folder, slice_name)), file=f)
f.close()
# 可以通過 head 命令看一下生成的結果
!head ~/data/train_list.txt
2、paddleSeg配置
這里解壓一下提供的飛槳分割代碼檔案,其實你也可以通過git下載,這個檔案已經上傳到專案中了
%cd /home/aistudio
!unzip paddleSeg.zip
這一步和上面一步是一樣的,如果你已經初始化了GPU的環境就可以不用再執行了,
!python -m pip install paddlepaddle-gpu==2.1.3.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html
這個需要執行,初始化分割的環境
!pip install -r paddleSeg/requirements.txt
3、模型訓練
如果運行代碼報錯后出現了paddle.enable_static()這個字樣,你需要打開訓練檔案trai.py加入下面代碼,
import paddle
paddle.enable_static()
在這里給出了一根檔案,我把我自己的組態檔也上傳到了專案中,因為我需要高精度模型并且我使用的是32G的顯卡,所以我的引數會和下面有所不同,epoch給到18,BATCH_SIZE給到20.
# 資料集配置
DATASET:
DATA_DIR: "/home/aistudio/data/prep" # 資料基路徑,這個路徑和檔案串列中的路徑 join 成實際的檔案路徑
NUM_CLASSES: 2 # 分割分為病灶和不是病灶兩類
TRAIN_FILE_LIST: "/home/aistudio/data/train_list.txt" # 訓練,驗證和測驗集的檔案串列路徑
VAL_FILE_LIST: "/home/aistudio/data/val_list.txt"
TEST_FILE_LIST: "/home/aistudio/data/test_list.txt"
SEPARATOR: "|" # 檔案串列中用 | 分割訓練資料和標簽路徑
IMAGE_TYPE: "gray" # 使用灰度圖,單通道進行訓練
# 預訓練模型配置
MODEL:
MODEL_NAME: "unet" # 使用unet網路結構,可選的網路結構包括 deeplabv3p, unet, icnet,pspnet,hrnet
DEFAULT_NORM_TYPE: "bn"
# 其他配置
TRAIN_CROP_SIZE: (512, 512) # 訓練輸入資料大小
EVAL_CROP_SIZE: (512, 512)
AUG:
AUG_METHOD: "unpadding"
FIX_RESIZE_SIZE: (512, 512)
MIRROR: True # 左右鏡像資料增強
BATCH_SIZE: 8 # 如果你有幸分到32g顯卡,這個引數最高可以開到大概 20
TRAIN:
MODEL_SAVE_DIR: "./saved_model/unet_covid/"
SNAPSHOT_EPOCH: 1
TEST:
TEST_MODEL: "./saved_model/unet_covid/final"
SOLVER:
NUM_EPOCHS: 20 # 訓練的時間較長,為了便于執行下面的代碼這里只寫了 1 個epoch,大概在15~20個epoch可以做到 85% 左右的準確率
LR: 0.001
LR_POLICY: "poly"
OPTIMIZER: "adam"
開始訓練
%cd ~/paddleSeg
!python pdseg/train.py --cfg ~/covid.yaml --use_gpu --use_mpio --do_eval --use_vdl --vdl_log_dir ~/log
4、模型匯出
匯出代碼,如果還是出現報錯就打開這個匯出檔案,然后添加上面的兩段代碼
!python pdseg/export_model.py --cfg ~/covid.yaml TEST.TEST_MODEL ./saved_model/unet_covid/final/
安裝paddle2onnx和他們的相關工具
!pip install pycocotools paddle2onnx
!pip install onnx==1.9.0
從GitHub下載好paddle2onnx的代碼檔案
%cd ~/
!git clone https://github.com/paddlepaddle/paddle2onnx --depth 1
初始化環境
!cd ~/paddle2onnx/ && python setup.py install
%cd ~/paddleSeg/
!ls
在這里我們匯出這個我們分割模型的onnx模型,你可以指定匯出的路徑,然后下載到自己的電腦上,
!paddle2onnx \
--model_dir freeze_model \
--model_filename __model__ \
--params_filename __params__ \
--save_file model.onnx \
--opset_version 12
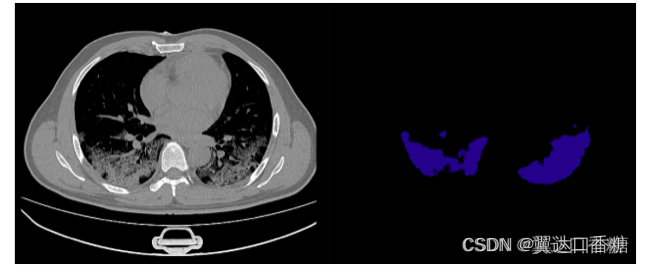
當然,雖然我們的主要任務是匯出ONNX模型,你也可以推理一下這個模型,你可以得到患者的肺部的分割影像
!python infer.py --conf=/home/aistudio/infer.yaml --input_dir=/home/aistudio/inference --image_dir="/home/aistudio/"
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438066.html
標籤:AI