目錄
- 1、OLTP、OLAP和HTAP
- 1.1 OLTP
- 1.2 OLAP
- 1.2.1 OLAP分類
- 1.3 HTAP
- 2、TiDB簡介
- 3、TiDB架構
- 4、優勢
- 5、核心特性
- 5.1 水平擴展
- 5.2 高可用
- 5.2.1 TiDB
- 5.2.2 PD
- 5.2.3 TiKV
- 6、核心原理
- 6.1 存盤原理
- 6.1.1 Key-Value
- 6.1.2 RocksDB
- 6.1.3 Raft
- 6.1.4 Region
- 6.1.5 MVCC
- 6.1.6 Percolator
- 6.2 計算原理
- 6.2.1 關系模型到 Key-Value 模型的映射
- 6.2.2 元資訊管理
- 6.2.3 分布式 SQL運算
- 6.2.4 SQL 層架構
- 6.3 調度原理
- 6.3.1 調度的基本操作
- 6.3.2 資訊收集
- 6.3.3 調度策略
- 7、TiDB與SQL的兼容性
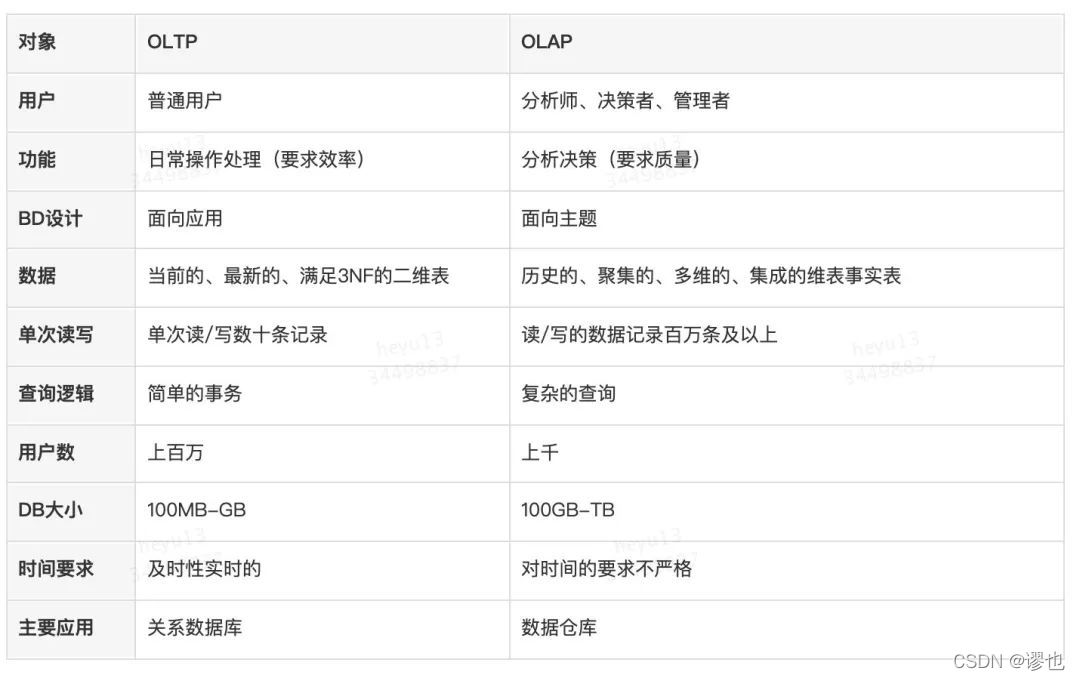
1、OLTP、OLAP和HTAP
1.1 OLTP
? OLTP(on-line transaction processing),聯機事務處理,對資料的「增刪改」
1.2 OLAP
? OLAP(On-Line Analytical Processing),聯機分析處理,對資料的「查詢」
1.2.1 OLAP分類
ROLAP與MOLAP
-
ROLAP關系型聯機分析處理
-
傳統關系型資料庫、MPP分布式資料庫、基于Hadoop的Spark/Impala
-
能同時連接明細資料和匯總資料,實時根據用戶提出的需求對資料進行計算后回傳給用戶,所以用戶使用相對比較靈活,可以隨意選擇維度組合來進行實時計算
-
當計算的資料量達到一定級別或并發數達到一定級別的時候,一定會出現性能問題
-
-
MOLAP多維聯機分析處理
- Cognos,SSAS,Kylin
- 預先將客戶的需求計算好以結果的形式存下來,當命中需求后回傳非常快(適合常見固定的分析場景),同等資源下支持的資料體量更大,支持的并發更多
- 當表的維度越多,越復雜,其所需的磁盤存盤空間則越大,構建cube也需要一定的時間
? OLTP所產生的業務資料分散在不同的業務系統中,而OLAP往往需要將不同的業務資料集中到一起進行統一綜合的分析,這時候就需要根據業務分析需求做對應的資料清洗后存盤在資料倉庫中,然后由資料倉庫來統一提供OLAP分析,
1.3 HTAP
? HTAP是混合 OLTP 和 OLAP 業務同時處理的系統,它打破了事務處理和分析之間的“墻”,它支持更多的資訊和“實時業務”的決策
優勢:
- 資料不需要從操作型資料庫匯入到決策類系統;
- 操作事務,實時地對分析業務可見;
- 上鉆下取等分析操作,時刻操作最新的資料;
- 減少對副本的要求
2、TiDB簡介
TiDB 是 PingCAP 公司自主設計、研發的開源分布式關系型資料庫,是一款同時支持在線事務處理與在線分析處理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式資料庫產品,具備水平擴容或者縮容、金融級高可用、實時 HTAP、云原生的分布式資料庫、兼容 MySQL 5.7 協議和 MySQL 生態等重要特性,目標是為用戶提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解決方案,TiDB 適合高可用、強一致要求較高、資料規模較大等各種應用場景,
3、TiDB架構
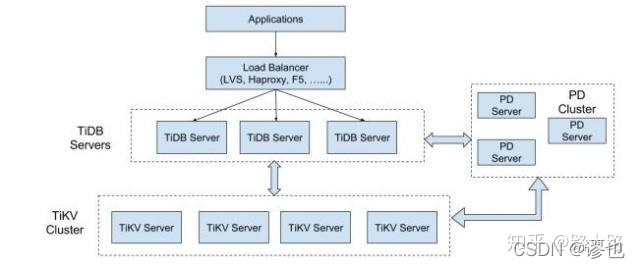
TiDB Server
? TiDB Server 負責接收 SQL 請求,處理 SQL 相關的邏輯,并通過 PD 找到存盤計算所需資料的 TiKV 地址,與 TiKV 互動獲取資料,最侄訓傳結果, TiDB Server 是無狀態的,其本身并不存盤資料,只負責計算,可以無限水平擴展,可以通過負載均衡組件(如LVS、HAProxy 或 F5)對外提供統一的接入地址,
PD Server
? Placement Driver (簡稱 PD) 是整個集群的管理模塊,其主要作業有三個: 一是存盤集群的元資訊(某個 Key 存盤在哪個 TiKV 節點);二是對 TiKV 集群進行調度和負載均衡(如資料的遷移、Raft group leader 的遷移等);三是分配全域唯一且遞增的事務 ID, PD 是一個集群,需要部署奇數個節點,一般線上推薦至少部署 3 個節點,
TiKV Server
? TiKV Server 負責存盤資料,從外部看 TiKV 是一個分布式的提供事務的 Key-Value 存盤引擎,存盤資料的基本單位是 Region,每個 Region 負責存盤一個 Key Range (從 StartKey 到 EndKey 的左閉右開區間)的資料,每個 TiKV 節點會負責多個 Region ,TiKV 使用 「Raft」 協議做復制,保持資料的一致性和容災,副本以 Region 為單位進行管理,不同節點上的多個 Region 構成一個 Raft Group,互為副本,資料在多個 TiKV 之間的負載均衡由 PD 調度,這里也是以 Region 為單位進行調度,
4、優勢
- 高度兼容 MySQL
大多數情況下,無需修改代碼即可從 MySQL 輕松遷移至 TiDB,分庫分表后的 MySQL 集群亦可通過 TiDB 工具進行實時遷移, - 水平彈性擴展
通過簡單地增加新節點即可實作 TiDB 的水平擴展,按需擴展吞吐或存盤,輕松應對高并發、海量資料場景, - 分布式事務
TiDB 100% 支持標準的 ACID 事務,無論是一個地方的幾個節點,還是跨多個資料中心的多個節點, - 真正金融級高可用
相比于傳統主從 (M-S) 復制方案,基于 Raft 的多數派選舉協議可以提供金融級的 100% 資料強一致性保證,且在不丟失大多數副本的前提下,可以實作故障的自動恢復 (auto-failover),無需人工介入, - 一站式 HTAP 解決方案
TiDB 作為典型的 OLTP 行存資料庫,同時兼具強大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP解決方案,一份存盤同時處理OLTP & OLAP(OLAP、OLTP的介紹和比較 )無需傳統繁瑣的 ETL 程序, - 云原生 SQL 資料庫
TiDB 是為云而設計的資料庫,同 Kubernetes (十分鐘帶你理解Kubernetes核心概念 )深度耦合,支持公有云、私有云和混合云,使部署、配置和維護變得十分簡單,
TiDB 的設計目標是 100% 的 OLTP 場景和 80% 的 OLAP 場景,更復雜的 OLAP 分析可以通過 TiSpark 專案來完成, TiDB 對業務沒有任何侵入性,能優雅的替換傳統的資料庫中間件、資料庫分庫分表等 Sharding 方案,同時它也讓開發運維人員不用關注資料庫 Scale 的細節問題,專注于業務開發,極大的提升研發的生產力,
5、核心特性
5.1 水平擴展
無限水平擴展是 TiDB 的一大特點,這里說的水平擴展包括兩方面:計算能力和存盤能力,
? TiDB Server 負責處理 SQL 請求,隨著業務的增長,可以簡單的添加 TiDB Server 節點,提高整體的處理能力,提供更高的吞吐,
? TiKV 負責存盤資料,隨著資料量的增長,可以部署更多的 TiKV Server 節點解決資料 Scale 的問題,
? PD 會在 TiKV 節點之間以 Region 為單位做調度,將部分資料遷移到新加的節點上,所以在業務的早期,可以只部署少量的服務實體(推薦至少部署 3 個 TiKV, 3 個 PD,2 個 TiDB),隨著業務量的增長,按照需求添加 TiKV 或者 TiDB 實體,
5.2 高可用
高可用是 TiDB 的另一大特點,TiDB/TiKV/PD 這三個組件都能容忍部分實體失效,不影響整個集群的可用性,下面分別說明這三個組件的可用性、單個實體失效后的后果以及如何恢復,
5.2.1 TiDB
TiDB 是無狀態的,推薦至少部署兩個實體,前端通過負載均衡組件對外提供服務,當單個實體失效時,會影響正在這個實體上進行的 Session,從應用的角度看,會出現單次請求失敗的情況,重新連接后即可繼續獲得服務,單個實體失效后,可以重啟這個實體或者部署一個新的實體,
5.2.2 PD
PD 是一個集群,通過 Raft 協議保持資料的一致性,單個實體失效時,如果這個實體不是 Raft 的 leader,那么服務完全不受影響;如果這個實體是 Raft 的 leader,會重新選出新的 Raft leader,自動恢復服務,PD 在選舉的程序中無法對外提供服務,這個時間大約是3秒鐘,推薦至少部署三個 PD 實體,單個實體失效后,重啟這個實體或者添加新的實體,
5.2.3 TiKV
TiKV 是一個集群,通過 Raft 協議(raft一致性哈演算法以及Raft 為什么是更易理解的分布式一致性演算法 )保持資料的一致性(副本數量可配置,默認保存三副本),并通過 PD 做負載均衡調度,
? 單個節點失效時,會影響這個節點上存盤的所有 Region,對于 Region 中的 Leader 結點,會中斷服務,等待重新選舉;對于 Region 中的 Follower 節點,不會影響服務,當某個 TiKV 節點失效,并且在一段時間內(默認 30 分鐘)無法恢復,PD 會將其上的資料遷移到其他的 TiKV 節點上,
6、核心原理
6.1 存盤原理
6.1.1 Key-Value
? TiDB選用的是Key-Value作為存盤模型,并且提供有序遍歷的方法,在這個巨大的Map中,Key按照Byte舒張壓總的原始二進制位元位比較順序排列,所以我們可以Seek到某一個Key的位置,然后不斷呼叫Next方法以遞增的順序獲取比這個Key大的Key-Value,
6.1.2 RocksDB
TiDB選用的是RocksDB作為存盤引擎,而不是直接向磁盤上寫資料,RocksDB是一個高性能的單機存盤引擎(可以認為是一個單機的Key-Value Map),由Facebook的團隊在做持續的優化,
6.1.3 Raft
TiDB選用Raft協議來做資料復制,保證副本的一致性,
資料的寫入是通過Raft的介面寫入,然后再通過RocksDB存盤到磁盤上,
Raft 是一個一致性協議,提供幾個重要的功能:
- Leader 選舉
- 成員變更
- 日志復制
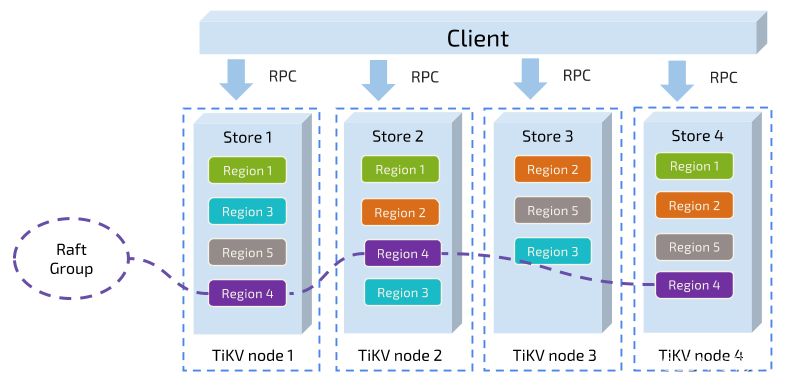
6.1.4 Region
? 對于一個KV系統,將資料分散在多臺機器上有兩種典型方案
- 按照 Key 做 Hash,根據 Hash 值選擇對應的存盤節點
- 分 Range,某一段連續的 Key 都保存在一個存盤節點上
? TiDB采用的是第二種方式,將整個 Key-Value 空間分成很多段,每一段是一系列連續的 Key,我們將每一段叫做一個 Region,并且我們會盡量保持每個 Region 中保存的資料不超過一定的大小(這個大小可以配置,目前默認是 96mb),每一個 Region 都可以用 StartKey 到 EndKey 這樣一個左閉右開區間來描述,
? 將資料劃分為Region后:
- 以 Region 為單位,將資料分散在集群中所有的節點上,并且盡量保證每個節點上服務的 Region 數量差不多
- 以 Region 為單位做 Raft 的復制和成員管理,一個 Region 的多個 Replica 會保存在不同的節點上,構成一個 Raft Group,其中一個 Replica 會作為這個 Group 的 Leader,其他的 Replica 作為 Follower,所有的讀和寫都是通過 Leader 進行,再由 Leader 復制給 Follower,
6.1.5 MVCC
MVCC即多版本控制,當兩個Client同時修改一個Key的Value時,如果沒有MVCC,就需要對資料進行上鎖,在分布式的情況下很可能會帶來性能和死鎖問題,
TiDB實作MVCC的方式是通過在key后面添加version來實作的,對于同一個Key的多個版本,TiDB把版本號大的放在前面,版本號小的放在后面,當用戶通過Key+Version獲取Value時,可以直接定位到第一個大于等于這個Key-Version的位置,
6.1.6 Percolator
TiDB采用 Percolator 作為事務模型,并作了大量的優化,TiKV的事務采用樂觀鎖,在事務的執行程序中,不會檢測寫寫沖突,只有在提交程序中,才會做沖突檢測,沖突雙方較早完成提交的會寫入成功,另一方會嘗試重新執行整個事務,
在寫入沖突不嚴重的情況下,這種模型的性能會很好,但如果存在大量的寫入沖突,性能就會變得很差,
6.2 計算原理
6.2.1 關系模型到 Key-Value 模型的映射
對于一個 Table 來說,需要存盤的資料包括三部分:
- 表的元資訊
- Table 中的 Row
- 索引資料
? TiDB 面向的首要目標是 OLTP 業務,這類業務需要支持快速地讀取、保存、修改、洗掉一行資料,所以采用行存是比較合適的,
? 對于 Index,TiDB 不止需要支持 Primary Index,還需要支持 Secondary Index,Index 的作用的輔助查詢,提升查詢性能,以及保證某些 Constraint,查詢的時候有兩種模式,一種是點查,比如通過 Primary Key 或者 Unique Key 的等值條件進行查詢;另一種是 Range 查詢,Index 還分為 Unique Index 和 非 Unique Index,這兩種都需要支持,
TiDB 對每個表分配一個「 TableID」,每一個索引都會分配一個 「IndexID」,每一行分配一個 「RowID」(如果表有整數型的 Primary Key,那么會用 Primary Key 的值當做 RowID),其中 TableID 在整個集群內唯一,IndexID/RowID 在表內唯一,這些 ID 都是 int64 型別,
每行資料
Key: tablePrefix{tableID}_recordPrefixSep{rowID}
Value: [col1, col2, col3, col4]
Unique Index
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue
Value: rowID
非 Unique Index:可能有多行資料的 ColumnsValue是一樣的,所以再加上rowID使其唯一
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue_rowID
Value: null
其中 Key 的 Prefix都是特定的字串常量,用于在 KV 空間內區分其他資料,
Memcomparable:
保證編碼前和編碼后的比較關系不變的方案,對于任何型別的值,兩個物件編碼前的原始型別比較結果,和編碼成 byte 陣列后的比較結果保持一致,采用這種編碼后,一個表的所有 Row 資料就會按照 RowID 的順序排列在 TiKV 的 Key 空間中,某一個 Index 的資料也會按照 Index 的 ColumnValue 順序排列在 Key 空間內,
6.2.2 元資訊管理
Database/Table 都有元資訊,也就是其定義以及各項屬性,每個 Database/Table 都被分配了一個唯一的 ID,這個 ID 作為唯一標識,并且在編碼為 Key-Value 時,這個 ID 都會編碼到 Key 中,再加上 m_前綴,這樣可以構造出一個 Key,Value 中存盤的是序列化后的元資訊,
6.2.3 分布式 SQL運算
將 SQL 查詢映射為對 KV 的查詢,再通過 KV 介面獲取對應的資料,最后執行各種計算,首先我們需要將計算盡量靠近存盤節點,以避免大量的 RPC 呼叫,其次,我們需要將 Filter 也下推到存盤節點進行計算,這樣只需要回傳有效的行,避免無意義的網路傳輸,最后,我們可以將聚合函式、GroupBy 也下推到存盤節點,進行預聚合,每個節點只需要回傳一個 Count 值即可,再由 tidb-server 將 Count 值 Sum 起來,
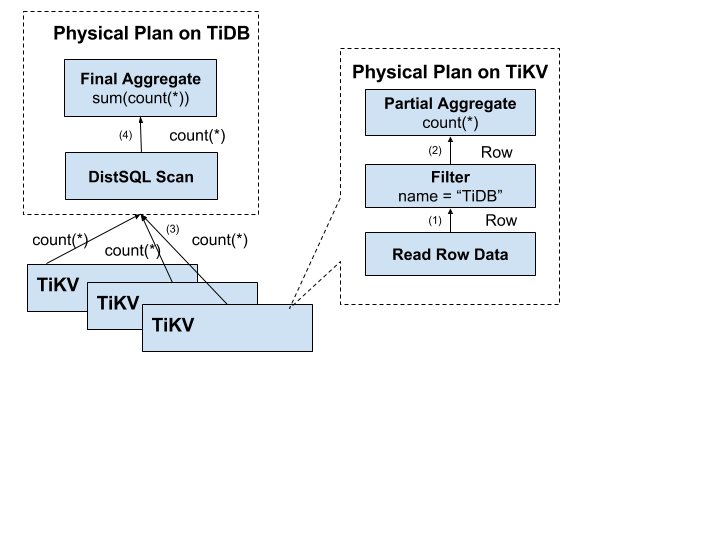
6.2.4 SQL 層架構
用戶的 SQL 請求會直接或者通過 Load Balancer 發送到 tidb-server,tidb-server 會決議 MySQL Protocol Packet,獲取請求內容,然后做語法決議、查詢計劃制定和優化、執行查詢計劃獲取和處理資料,資料全部存盤在 TiKV 集群中,所以在這個程序中 tidb-server 需要和 tikv-server 互動,獲取資料,最后 tidb-server 需要將查詢結果回傳給用戶,
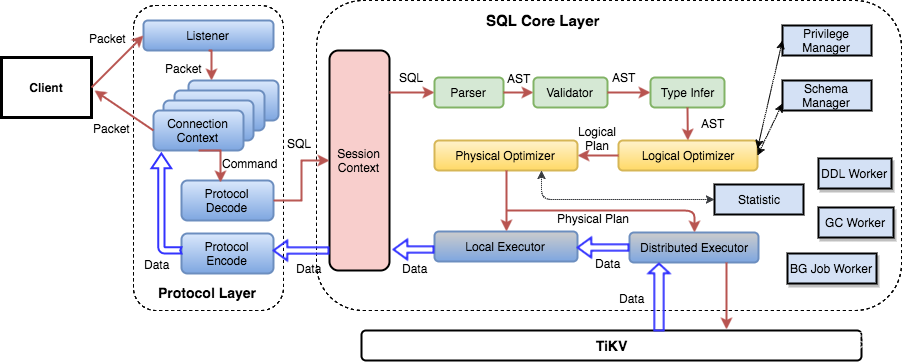
6.3 調度原理
作為一個分布式高可用存盤系統,必須滿足的需求,包括四種:
- 副本數量不能多也不能少
- 副本需要分布在不同的機器上
- 新加節點后,可以將其他節點上的副本遷移過來
- 節點下線后,需要將該節點的資料遷移走
作為一個良好的分布式系統,需要優化的地方,包括:
- 維持整個集群的 Leader 分布均勻
- 維持每個節點的儲存容量均勻
- 維持訪問熱點分布均勻
- 控制 Balance 的速度,避免影響在線服務
- 管理節點狀態,包括手動上線/下線節點,以及自動下線失效節點
6.3.1 調度的基本操作
-
增加一個 Replica
-
洗掉一個 Replica
-
將 Leader 角色在一個 Raft Group 的不同 Replica 之間 transfer
剛好 Raft 協議能夠滿足這三種需求,通過 AddReplica、RemoveReplica、TransferLeader 這三個命令,可以支撐上述三種基本操作,
6.3.2 資訊收集
調度依賴于整個集群資訊的收集,包括每個 TiKV 節點的狀態以及每個 Region 的狀態,
每個 TiKV 節點會定期向 PD 匯報節點的整體資訊
TiKV 節點(Store)與 PD 之間存在心跳包,一方面 PD 通過心跳包檢測每個 Store 是否存活,以及是否有新加入的 Store;另一方面,心跳包中也會攜帶這個 Store 的狀態資訊 ,主要包括:
- 總磁盤容量
- 可用磁盤容量
- 承載的 Region 數量
- 資料寫入速度
- 發送/接受的 Snapshot 數量(Replica 之間可能會通過 Snapshot 同步資料)
- 是否過載
- 標簽資訊(標簽是具備層級關系的一系列 Tag)
每個 Raft Group 的 Leader 會定期向 PD 匯報資訊
每個 Raft Group 的 Leader 和 PD 之間存在心跳包,用于匯報這個 Region 的狀態 ,主要包括下面幾點資訊:
-
Leader 的位置
-
Followers 的位置
-
掉線 Replica 的個數
-
資料寫入/讀取的速度
PD 不斷的通過這兩類心跳訊息收集整個集群的資訊,再以這些資訊作為決策的依據,除此之外,PD 還可以通過管理介面接受額外的資訊,用來做更準確的決策,比如當某個 Store 的心跳包中斷的時候,PD 并不能判斷這個節點是臨時失效還是永久失效,只能經過一段時間的等待(默認是 30 分鐘),如果一直沒有心跳包,就認為是 Store 已經下線,再決定需要將這個 Store 上面的 Region 都調度走,
但是有的時候,是運維人員主動將某臺機器下線,這個時候,可以通過 PD 的管理介面通知 PD 該 Store 不可用,PD 就可以馬上判斷需要將這個 Store 上面的 Region 都調度走,
6.3.3 調度策略
一個 Region 的 Replica 數量正確
當 PD 通過某個 Region Leader 的心跳包發現這個 Region 的 Replica 數量不滿足要求時,需要通過 Add/Remove Replica 操作調整 Replica 數量,出現這種情況的可能原因是:
- 某個節點掉線,上面的資料全部丟失,導致一些 Region 的 Replica 數量不足
- 某個掉線節點又恢復服務,自動接入集群,這樣之前已經補足了 Replica 的 Region 的 Replica 數量多過,需要洗掉某個 Replica
- 管理員調整了副本策略,修改了 max-replicas的配置
一個 Raft Group 中的多個 Replica 不在同一個位置
在一般情況下,PD 只會保證多個 Replica 不落在一個節點上,以避免單個節點失效導致多個 Replica 丟失,在實際部署中,還可能出現下面這些需求:
-
多個節點部署在同一臺物理機器上
-
TiKV 節點分布在多個機架上,希望單個機架掉電時,也能保證系統可用性
-
TiKV 節點分布在多個 IDC 中,希望單個機房掉電時,也能保證系統可用
這些需求本質上都是某一個節點具備共同的位置屬性,構成一個最小的容錯單元,我們希望這個單元內部不會存在一個 Region 的多個 Replica,這個時候,可以給節點配置 lables 并且通過在 PD 上配置 location-labels 來指明哪些 lable 是位置標識,需要在 Replica 分配的時候盡量保證不會有一個 Region 的多個 Replica 所在結點有相同的位置標識,
副本在 Store 之間的分布均勻分配
每個副本中存盤的資料容量上限是固定的,維持每個節點上面,副本數量的均衡,會使得總體的負載更均衡,
Leader 數量在 Store 之間均勻分配
Raft 協議要讀取和寫入都通過 Leader 進行,所以計算的負載主要在 Leader 上面,PD 會盡可能將 Leader 在節點間分散開,
訪問熱點數量在 Store 之間均勻分配
每個 Store 以及 Region Leader 在上報資訊時攜帶了當前訪問負載的資訊,比如 Key 的讀取/寫入速度,PD 會檢測出訪問熱點,且將其在節點之間分散開,
各個 Store 的存盤空間占用大致相等
每個 Store 啟動的時候都會指定一個 Capacity 引數,表明這個 Store 的存盤空間上限,PD 在做調度的時候,會考慮節點的存盤空間剩余量,
控制調度速度,避免影響在線服務
調度操作需要耗費 CPU、記憶體、磁盤 IO 以及網路帶寬,我們需要避免對線上服務造成太大影響,PD 會對當前正在進行的運算元量進行控制,默認的速度控制是比較保守的,如果希望加快調度(比如已經停服務升級,增加新節點,希望盡快調度),那么可以通過 pd-ctl 手動加快調度速度,
支持手動下線節點
當通過 pd-ctl 手動下線節點后,PD 會在一定的速率控制下,將節點上的資料調度走,當調度完成后,就會將這個節點置為下線狀態,
7、TiDB與SQL的兼容性
? TiDB 支持包括跨行事務,JOIN 及子查詢在內的絕大多數 MySQL 的語法,一些 MySQL 語法在 TiDB 中可以決議通過,但是不會做任何后續的處理,
不支持的特性:
- 存盤程序
- 視圖
- 觸發器
- 自定義函式
- 外鍵約束
- 全文索引
- 空間索引
- 非 UTF8 字符集
參考鏈接:
https://www.zhihu.com/question/24110442/answer/851671343
https://blog.csdn.net/weixin_34112030/article/details/92512973
https://zhuanlan.zhihu.com/p/71073707
https://docs.pingcap.com/zh/tidb/stable
如有不對,煩請指出,感謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438085.html
標籤:其他