🌿今天我們來了解一下flink中的幾個重要基礎概念:time、watermark、state,這是flink流處理中實作資料流執行速度快和結果正確的要點,對往期內容感興趣的同學可以看下面👇:
- 鏈接: Flink學習專輯.
🌰其實在前面的章節中,我們也介紹了一些時間、狀態的概念,但不夠深入,本篇博客將從flink的運行機制上說明這些概念在流處理框架中的作用,
目錄
- 1. Time
- 2. Watermark
- 2.1 Watermark的作用
- 2.2 Watermark的特點
- 2.3 Watermark的案例
- 2.3 Watermark的設定
- 3. State
- 3.1 狀態的定義
- 3.2 狀態的分類
- 3.1.1 算子狀態(Operator State)
- 3.1.2 鍵控狀態(Keyed State)
- 3.3 狀態后端(State Backends)
- 4. 總結
- 5. 參考文章
1. Time
flink的時間語意主要分為3種:
- Event Time: 事件時間,它通常由事件中的時間戳描述,例如采集的
日志資料中,每一條日志都會記錄自己的生成時間 - Ingestion Time:進入時間,是指資料進入flink的事件
- Processing Time:操作時間,是每一個執行基于時間操作的算子的本地系統時間,與機器相關,默認的時間屬性就是 Processing Time
一般來說,絕大一部分業務都會采用 Event Time,如果Event Time無法使用,才會使用Ingestion Time和Processing Time,如果我們重視時間真實發生的時間或者要保證資料恢復前和恢復后保持一致,那么我們需要用Event Time作為時間標準,如果我們對事件的準確性要求不高,但對運行速度要求很高時,我們就可以選擇Processing Time,
2. Watermark
我們一般采用Event Time模式處理流資料,這就代表資料的時間戳來源于資料里的時間,但資料在進行傳輸、磁區等的操作,會使得資料亂序到達flink,導致計算不正確,
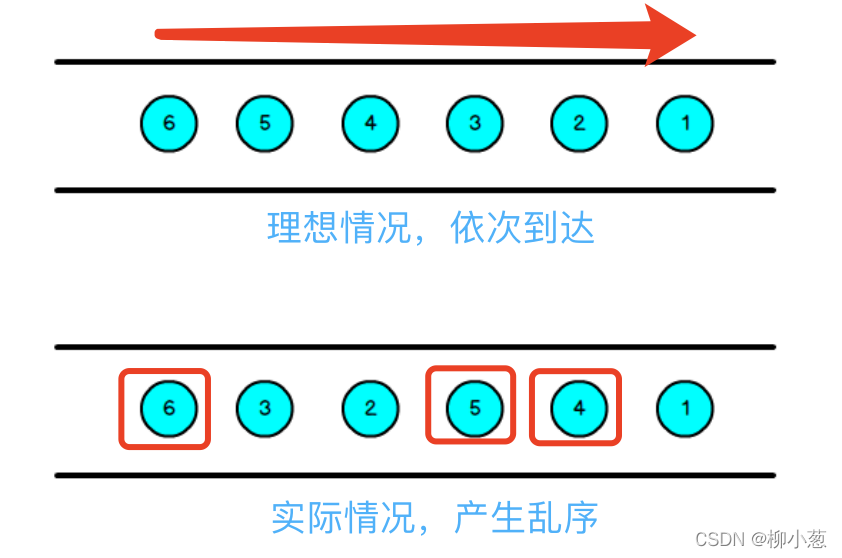
于是,便有了watermark這個概念,用來避免亂序資料帶來的時間不正確,
2.1 Watermark的作用
- Watermark 是一種衡量 Event Time 進展的機制,
- Watermark 是用于處理亂序事件的,而正確的處理亂序事件,通常用Watermark 機制結合 window 來實作,
- 資料流中的 Watermark 用于表示 timestamp 小于 Watermark 的資料,都已經到達了,因此,window 的執行也是由 Watermark 觸發的,
- Watermark 可以理解成一個延遲觸發機制,我們可以設定 Watermark 的延時時長 t,每次系統會校驗已經到達的資料中最大maxEventTime,然后認定 eventTime小于 maxEventTime - t 的所有資料都已經到達,如果有視窗的停止時間等于maxEventTime – t,那么這個視窗被觸發執行,
2.2 Watermark的特點
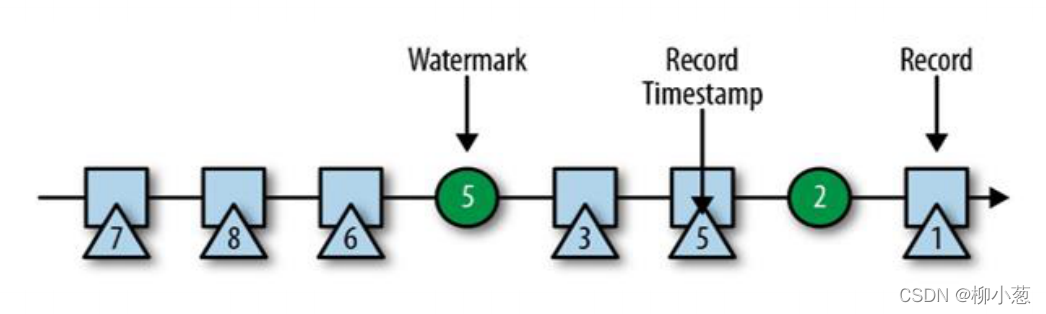
- watermark 是一條特殊的資料記錄
- watermark 必須單調遞增,以確保任務的事件時間時鐘在向前推進,而不是在后退
- watermark 與資料的時間戳相關
2.3 Watermark的案例
如圖,下面有一組亂序資料流,watermark=2,視窗大小為5:

- Watermark=maxEventTime - 2
- 每來一個資料都會計算一次Watermark,一旦Watermark 比當前未觸發的視窗的停止時間要晚,那么就會觸發相應視窗的執行,
- 如果運行程序中無法獲取新的資料時間戳,那么沒有被觸發的視窗將永遠都不被觸發,
2.3 Watermark的設定
- 在 Flink 中,watermark 由應用程式開發人員生成,這通常需要對相應的領域有一定的了解
- 如果watermark設定的延遲太久,收到結果的速度可能就會很慢,解決辦法是在水位線到達之前輸出一個近似結果
- 而如果watermark到達得太早,則可能收到錯誤結果,不過 Flink 處理遲到資料的機制可以解決這個問題
3. State
3.1 狀態的定義
我們先來看張圖:
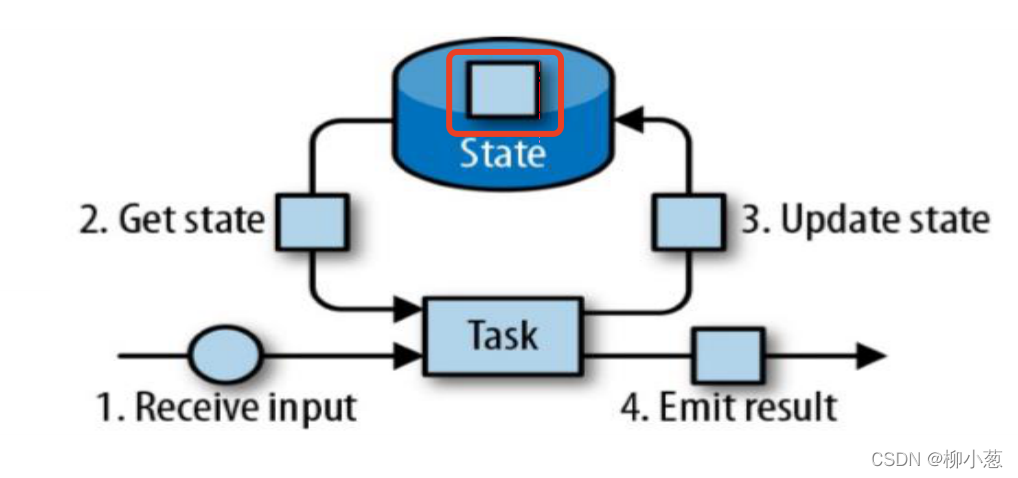
在流式計算框架中,對于簡單的map、filter、flatmap這樣簡單的算子,我們的資料只需要來一條處理一條,處理程序不需要用到狀態,而像reduce(),count(),sum()這樣的算子,在處理資料時,雖然也是來一條處理一條,但是處理程序中需要獲取之前的狀態,根據之前的狀態和剛輸入的資料來計算新的計算結果,
- 由一個任務維護,并且用來計算某個結果的所有資料,都屬于這個任務的狀態,
- 可以認為狀態就是一個本地變數(放在記憶體中),可以被任務的業務邏輯訪問,
- Flink 會進行狀態管理,包括狀態一致性、故障處理以及高效存盤和訪問,以便開發人員可以專注于應用程式的邏輯,
3.2 狀態的分類
- 在 Flink 中,狀態始終與特定算子相關聯
- 為了使運行時的 Flink 了解算子的狀態,算子需要預先注冊其狀態
3.1.1 算子狀態(Operator State)
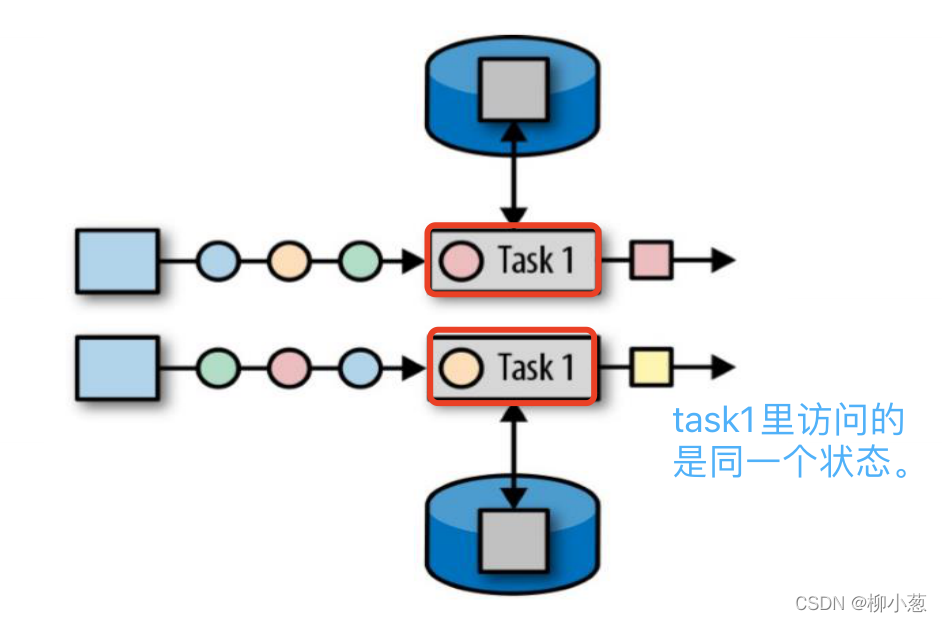
所謂算子狀態,就是算子狀態的作用范圍限定為算子任務,在同一個磁區,訪問的狀態都是同一個狀態,特點如下:
- 算子狀態的作用范圍限定為算子任務,由同一并行任務所處理的所有資料都可以訪問到相同的狀態
- 狀態對于同一子任務而言是共享的
- 算子狀態不能由相同或不同算子的另一個子任務訪問
算子狀態有以下幾種:
- 串列狀態(List state):將狀態表示為一組資料的串列
- 聯合串列狀態(Union list state):也將狀態表示為資料的串列,它與常規串列狀態的區別在于,在發生故障時,或者從保存點(savepoint)啟動應用程式時如何恢復
- 廣播狀態(Broadcast state):如果一個算子有多項任務,而它的每項任務狀態又都相同,那么這種特殊情況最適合應用廣播狀態,
3.1.2 鍵控狀態(Keyed State)
鍵控狀態是指根據資料流的key值來訪問狀態,特點如下:
- 鍵控狀態是根據輸入資料流中定義的鍵(key)來維護和訪問的
- Flink 為每個 key 維護一個狀態實體,并將具有相同鍵的所有資料,都磁區到同一個算子任務中,這個任務會維護和處理這個 key 對應的狀態
- 當任務處理一條資料時,它會自動將狀態的訪問范圍限定為當前資料的 key
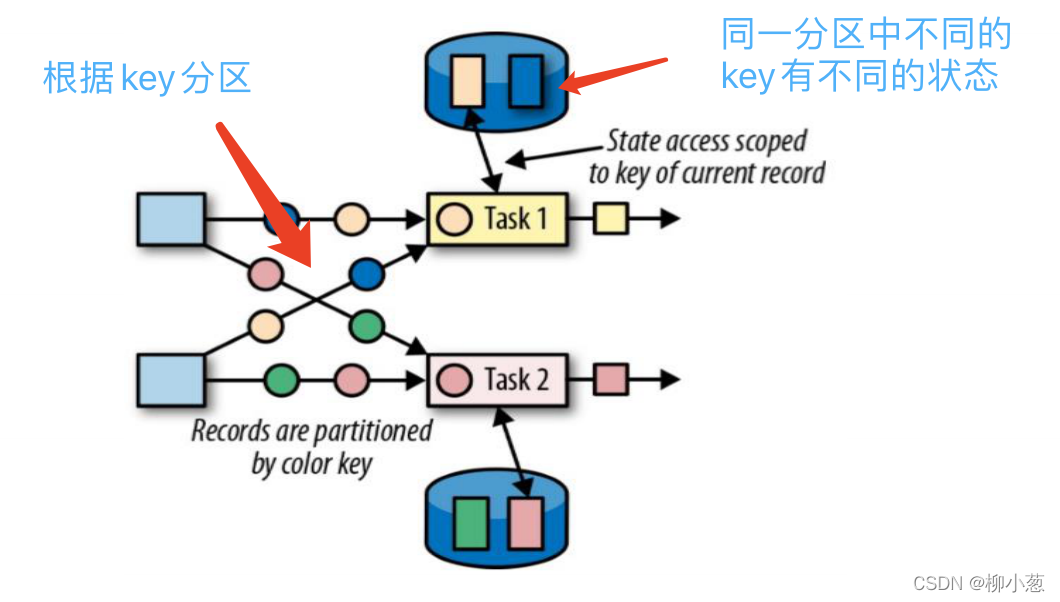
如圖:根據key值進行磁區操作,相同key的值在一個磁區,不同key的值也在一個磁區,但狀態是根據key值維護的,即同一個磁區的相同的key訪問的是同一個key,
鍵控狀態有以下幾種:
- 值狀態(Value state): 將狀態表示為單個的值
- 串列狀態(List state):將狀態表示為一組資料的串列
- 映射狀態(Map state):將狀態表示為一組 Key-Value 對
- 聚合狀態(Reducing state & Aggregating State):將狀態表示為一個用于聚合操作的串列
3.3 狀態后端(State Backends)
定義:狀態的存盤、訪問以及維護,由一個可插入的組件決定,這個組件就叫做狀態后端(state backend),狀態后端主要負責兩件事:本地的狀態管理,以及將檢查點(checkpoint)狀態寫入遠程存盤
狀態后端端種類:
- MemoryStateBackend
記憶體級的狀態后端,會將鍵控狀態作為記憶體中的物件進行管理,將它們存盤在TaskManager 的 JVM 堆上,而將 checkpoint 存盤在 JobManager 的記憶體中,特點:快速、低延遲,但不穩定,
- FsStateBackend
將 checkpoint 存到遠程的持久化檔案系統(FileSystem)上,而對于本地狀態,跟 MemoryStateBackend 一樣,也會存在 TaskManager 的 JVM 堆上,同時擁有記憶體級的本地訪問速度,和更好的容錯保證,
- RocksDBStateBackend
將所有狀態序列化后,存入本地的 RocksDB 中存盤,
4. 總結
今天詳細介紹了flink中time、watermark、state的原理和程式運行中的主要作用,為后續更好地了解flink容錯機制和狀態一致性保證做鋪墊,
5. 參考文章
《尚硅谷Java版Flink》
《Flink入門與實戰》
《PyDocs》(pyflink官方檔案)
《Kafka權威指南》
《Apache Flink 必知必會》
《Apache Flink 零基礎入門》
《Flink 基礎教程》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438673.html
標籤:其他
上一篇:Caused by: java.lang.IllegalArgumentException: Cannot grow BufferHolder by size 1752 because the siz
下一篇:手把手教你搭建HADOOP集群