準備作業:
準備三臺虛擬機,關閉防火墻,修改他們的主機名,第一臺虛擬機為master 剩下兩臺分別是slave1和slave2,修改hosts檔案 修改他們的主機映射,三臺進行免密操作,
基礎配置:
修改主機名
永久修改:vim /etc/hostname
重啟 restart
零時修改: hostnamectl set-hostname name
重繪 bash
關閉防火墻,配置主機映射
1.判斷防火墻是否關閉 systemctl status firewalld
2.關閉防火墻 systemctl stop firewalld ps:我們只需要關閉防火墻即可,三臺都要關閉
3.開啟 systemctl start firewalld
修改host檔案
vim /etc/hosts
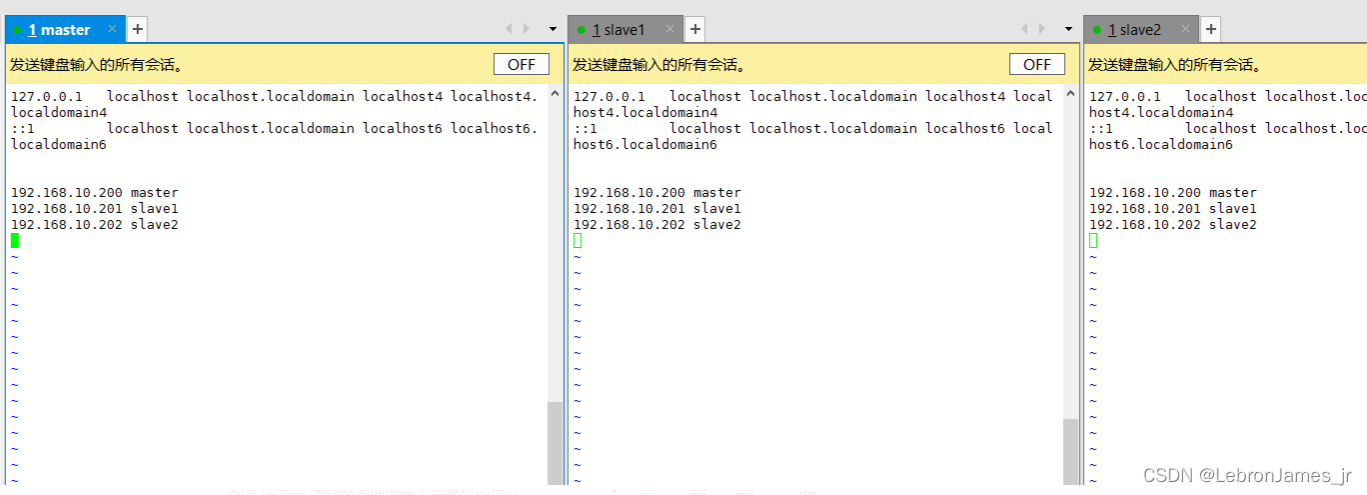
ip地址填你們自己的 上面的圖的ip地址是我的,
免密登入:
ssh-keygen 生成公鑰之后三次回車
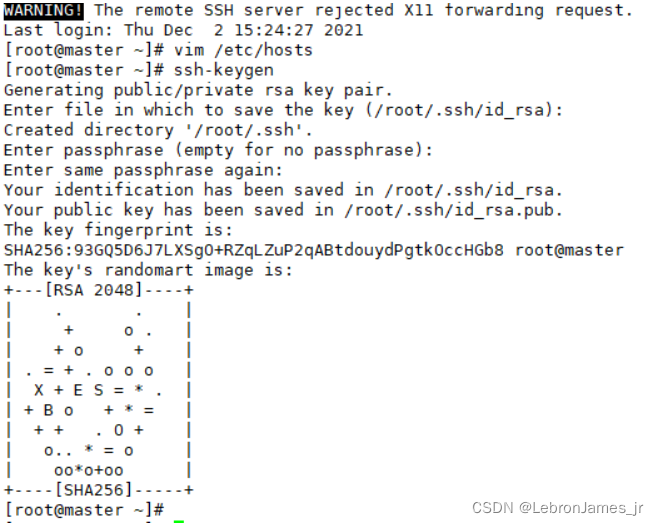
出現這個表示秘鑰生成成功
進行配置免密登入:
ssh-copy-id master #對master進行免密
ssh-copy-id slave1 #對slave1進行免密
ssh-copy-id slave2 #對slave2進行免密
shh localhost #內回環
如果顯示無法找到hostname 就去hosts檔案看一下是不是自己的單詞或者ip寫錯了
或者可以直接使用ssh-copy-id (192.xx.xx.xxx)ip地址 #對指定虛擬機進行免密 第一步 安裝JDK
首先解壓檔案jdk壓縮包到指定目錄
tar -zxvf 壓縮包名字 -C 解壓路徑
配置系統環境變數
vim /etc/profile
配置代碼
JAVA_HOME=/usr/java/jdk1.8.0_221
CLASSPATH=$JAVA_HOME/lib
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME CLASSPATH PATH分發給slave1 slave2-
分發命令:
scp -r /分發的檔案夾路徑地址 分發ip地址或者主機名:/上一級路徑地址
示例代碼:
scp -r /usr/java/ slave1:/usr/
scp -r /usr/java/ slave2:/usr/
分發系統變數
scp -r /etc/profile/ slave1:/etc/
scp -r /etc/profile/ slave2:/etc/JDK分發過去之后,環境變數也要記得分發過去,
在另外兩個節點
source /etc/profile
之后查看是否配置成功
java -version
出現版本號 則配置成功
HADOOP集群搭建:
解壓檔案jdk壓縮包到指定路徑
示例代碼: tar -zxvf hadoop-2.7.7.tar.gz -C /usr/hadoop/
配置hadoop系統環境變數
vim /etc/profile
配置系統環境變數代碼
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.7
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
上面是我的hadoop安裝地址 HADOOP_HOME的安裝路徑需要替換成你自己hadoop安裝目錄source /etc/profile
查看服務
hadoop version
來到組態檔目錄下
cd /usr/hadoop/hadoop-2.7.7/etc/hadoop/
cd 進入你安裝的hadoop的目錄/etc/hadoop/
然后可以ls 查看下面的檔案
1.編輯hadoop-env.sh檔案
往里面添加java_home就行了,可以在環境變數里面復制過來 /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_221
2.vim yarn-evn.sh
同樣添加java_home進去
export JAVA_HOME=/usr/java/jdk1.8.0_221
3.設定全域引數,指定NN的IP為master,埠為9000
vim core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.7.7/hdfs/tmp</value>
</property>4.設定HDFS引數
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoopData/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoopData/data</value>
</property>
</configuration>5.配置yarn核心引數'
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- Site specific YARN configuration properties -->
</configuration>6 vim mapred-site.xml 這個檔案只有模板檔案
需要cp mapred-site.xml.template mapred-site.xml
然后編輯剛剛cp過的檔案
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>7.編輯slaves檔案
往里面添加另外兩個虛擬機的主機名,如果主機名沒有配置好可以輸入另外兩臺的ip地址
slave1
slave28.編輯master檔案
添加主節點虛擬機的名字進去就好了,
master9.分發集群 ,系統環境變數到slave1 slave2
ps:分發hadoop過去 同時也要分發環境變數過去,另外兩臺別忘記source一下,
10.初始化hadoop 在master節點
初始化命令為: hadoop namenode -format
11.啟動集群 查看節點
start-all.sh
然后可以輸入jps命令 查看節點 看看是否啟動成功,
可以在瀏覽器輸入
192.xxx.xxx.xx (你的master節點的ip地址):/50070 進入web頁面
示例代碼:192.168.10.100:50070
如果進不去 則是沒有關閉防火墻,或者節點沒有開啟,節點開不起來可以重新輸入啟動命令,如果還是起不來,則要去檢查hadoop的組態檔是否寫正確,這東西熟能生巧,多搭建就好了,嘿嘿,到此教程結束了,小編第一次發教程可能寫的不是太好,請多多擔待,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438674.html
標籤:其他