📢📢📢📣📣📣
哈嘍!大家好,我是【一心同學】,一位上進心十足的【Java領域博主】!😜😜😜
?【一心同學】的寫作風格:喜歡用【通俗易懂】的文筆去講解每一個知識點,而不喜歡用【高大上】的官方陳述,
?【一心同學】博客的領域是【面向后端技術】的學習,未來會持續更新更多的【后端技術】以及【學習心得】,
?如果有對【后端技術】感興趣的【小可愛】,歡迎關注【一心同學】💞💞💞
??????感謝各位大可愛小可愛!??????
目錄
一、Elasticsearch介紹
1.1 概述
1.2 搜索引擎是什么?
1.3 全文檢索是什么?
二、ES特點
三、ES概念
3.1 基本概念
3.1.1 索引(index)
3.1.2 型別(type)
3.1.3 檔案(document)
3.1.4 映射(mapping)
3.1.5 倒排索引
3.2 ES集群核心概念
3.2.1 集群(cluster)
3.2.2 節點(node)
3.2.3 分片(shard)
3.2.4 副本(replica)
四、應用場景
🌴 場景一:搜索服務
🌵 典型場景
🔥 主要特性
🚀 相關公司
🌴 場景二:日志實時分析
🌵 典型場景
🔥 主要特性
🚀 相關公司
🌴 場景三:商業智能BI
🌵 典型場景
🔥 主要特性
🚀 相關公司
小結
一、Elasticsearch介紹
1.1 概述
Elasticsearch簡稱ES,是一個高擴展、開源、分布式的全文檢索和分析引擎,它可以準實時地快速存盤、搜索、分析海量的資料,而且ES本身擴展性很好,既可以擴展到上百臺服務器,處理PB級別(大資料時代)的資料,服務大公司,也可以運行在單機上,服務小公司,
據國際權威的資料庫產品評測機構DB Engines的統計,在2016年1月,Elasticsearch已超過Solr等,成為排名第一的搜索引擎類應用,

1.2 搜索引擎是什么?
所謂搜索引擎,就是根據用戶需求與一定演算法,運用特定策略從互聯網檢索出制定資訊反饋給用戶的一門檢索技術,例如我們在淘寶進行購物時,當我們輸入關鍵字“衣服”,那么淘寶就會給我們回傳各種型別的衣服(男裝/女裝),實作這個功能的背后就是搜索引擎的功勞,

1.3 全文檢索是什么?
全文檢索是指計算機索引程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程式就根據事先建立的索引進行查找,并將查找的結果反饋給用戶的檢索方式,這個程序類似于通過字典中的檢索字表查字的程序,
全文檢索的方式主要有兩種:
(1)按字檢索:指對于文章中的每一個字都建立索引,檢索時將詞分解為字的組合,
(2)按詞檢索:指對文章中的詞,即語意單位建立索引,檢索時按詞檢索,并且可以處理同義項等,
二、ES特點
(1)分布式:橫向擴展非常靈活
(2)高度的可伸縮性 :可以搭建大型的分布式集群,處理PB級的資料服務于大公司,也可以運行在單機上,服務于小公司
(3)高可用:容錯機制,自動發現新的或失敗的節點,重組和重新平衡資料
(4)全文檢索:基于lucene的強大的全文檢索能力
(5)模式自由:ES的動態mapping機制可以自動檢測資料的結構和型別,創建索引并使資料可搜索
(6)開箱即用:對用戶而言開箱即用,非常簡單,作為中小型的應用,直接三分鐘部署ES,就可以作為生產環境系統來使用了,
三、ES概念
3.1 基本概念
ES中有幾個基本概念:索引(index)、型別(type)、檔案(document)、映射(mapping)等,我們將這幾個概念與傳統的關系型資料庫中的庫、表、行、列等概念進行對比,如下表:
| RDBS | ES |
| 資料庫(database) | 索引(index) |
| 表(table) | 型別(type)(ES6.0之后被廢棄,es7中完全洗掉) |
| 表結構(schema) | 映射(mapping) |
| 行(row) | 檔案(document) |
| 列(column) | 欄位(field) |
| 索引 | 反向索引 |
| SQL | 查詢DSL |
| SELECT * FROM table | GET http://..... |
| UPDATE table SET | PUT http://...... |
| DELETE | DELETE http://...... |
3.1.1 索引(index)
索引是ES的一個邏輯存盤,對應關系型資料庫中的庫,ES可以把索引資料存放到服務器中,也可以sharding(分片)后存盤到多臺服務器上,每個索引有一個或多個分片,每個分片可以有多個副本,
3.1.2 型別(type)
ES中,一個索引可以存盤多個用于不同用途的物件,可以通過型別來區分索引中的不同物件,對應關系型資料庫中表的概念,
3.1.3 檔案(document)
存盤在ES中的主要物體叫檔案,可以理解為關系型資料庫中表的一行資料記錄,每個檔案由多個欄位(field)組成,區別于關系型資料庫的是,ES是一個非結構化的資料庫,每個檔案可以有不同的欄位,并且有一個唯一標識,
由于Elasticsearch是面向檔案的,那么就意味著索引和搜索資料的最小單位是檔案, ES中,檔案有幾個重要屬性:
(1)自我包含: 一篇檔案同時包含欄位和對應的值,也就是同時包含key:value !
(2)層次型:,一個檔案中包含自檔案,復雜的邏輯物體就是這么來的! {就是一 個json物件! fastjson進行自動轉換!}
(3)靈活的結構:檔案不依賴預先定義的模式,我們知道關系型資料庫中,要提前定義欄位才能使用,在elasticsearch中,對于欄位是非常靈活的,有時候,我們可以忽略該欄位,或者動態的添加一個新的欄位,
3.1.4 映射(mapping)
mapping是對索引庫中的索引欄位及其資料型別進行定義,類似于關系型資料庫中的表結構,ES默認動態創建索引和索引型別的mapping,這就像是關系型資料中的,無需定義表機構,更不用指定欄位的資料型別,同時我們也可以手動指定mapping型別,
3.1.5 倒排索引
倒排索引也叫反向索引,有反向索引必有正向索引,通俗來講,正向索引是通過key找value,反向索引則是通過value找key,
倒排索引操作步驟:
(1)先將檔案中包含的關鍵字全部提取出來
(2)然后再將關鍵字與檔案的對應關系保存起來
(3)最后對關鍵字本身做索引排序,
這樣在用戶檢索關鍵字時, 可以先查找關鍵字索引,在通過關鍵字與檔案的對應關系查找到所在的檔案,
如下面的兩個檔案:
檔案1: I love elasticsearch
檔案2: I love logstash他們對應的倒排索引為:
("√" 表示檔案中包含這個關鍵字)
| 序號 | 關鍵字 | 檔案1 | 檔案2 |
| 1 | I | √ | √ |
| 2 | love | √ | √ |
| 3 | elasticsearch | √ | |
| 4 | logstash | √ |
現在,我們試圖搜索 love elasticsearch,只需要查看包含每個詞條的檔案
| 關鍵字 | 檔案1 | 檔案2 |
|---|---|---|
| love | √ | √ |
| elasticsearch | √ | x |
| total | 2 | 1 |
兩個檔案都匹配,但是第一個檔案比第二個匹配程度更高,如果沒有別的條件,現在,這兩個包含關鍵字的檔案都將回傳,
3.2 ES集群核心概念
3.2.1 集群(cluster)
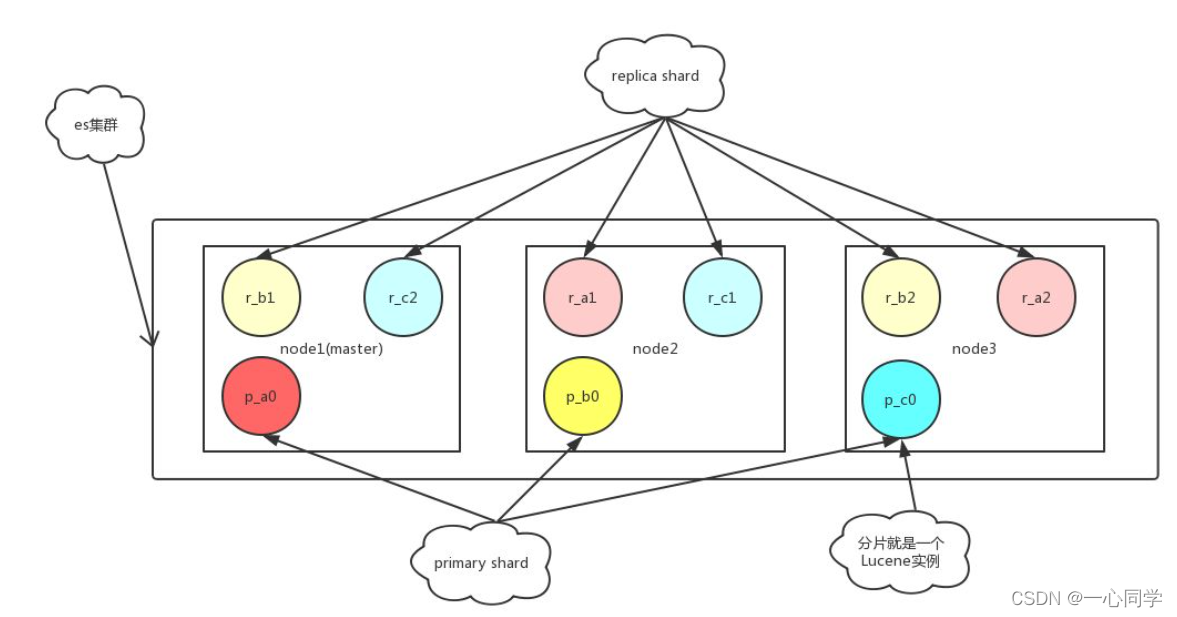
集群由許多結點Node組成,其中一個為主節點,這個主節點是可以通過選舉產生的,主從節點是對于集群內部來說的,ES的一個概念就是去中心化,字面上理解就是無中心節點,這是對于集群外部來說的,因為從外部來看ES集群,在邏輯上是個整體,你與任何一個節點的通信和與整個ES集群通信是等價的,
3.2.2 節點(node)
一個es實體即為一個節點,一臺機器可以有多個節點,正常使用下每個實體都會部署在不同的機器上,
ES的組態檔中可以通過node.master、 node.data 來設定節點型別:
node.master: true/false 表示節點是否具有成為主節點的資格
node.data: true/false 表示節點是否為存盤資料
node節點的組合方式:
主節點+資料節點: 默認方式,節點既可以作為主節點,又存盤資料
資料節點: 節點只存盤資料,不參與主節點選舉
客戶端節點: 不會成為主節點,也不存儲資料,主要針對海量請求時進行負載均衡
3.2.3 分片(shard)
概述:
代表索引分片,如果我們的索引資料量很大,超過硬體存放單個檔案的限制,就會影響查詢請求的速度,ES引入了分片技術,可以把一個完整的索引分成多個分片,一個分片本身就是一個完成的搜索引擎,檔案存盤在分片中,而分片會被分配到集群中的各個節點中,隨著集群的擴大和縮小,ES會自動的將分片在節點之間進行遷移,以保證集群能保持一種平衡,
這樣的好處是可以把一個大索引拆分成多個,分布到不同的節點上,構成分布式搜索,分片的數量只能在索引創建前指定,并且索引創建后不能更改,
特點:
(1)ES的一個索引可以包含多個分片(shard);
(2)每一個分片(shard)都是一個最小的作業單元,承載部分資料;
(3)每個shard都是一個lucene實體,有完整的簡歷索引和處理請求的能力;
(4)增減節點時,shard會自動在nodes中負載均衡;
(5)一個檔案只能完整的存放在一個shard上
(6)分片的數量只能在索引創建前指定,并且索引創建后不能更改,如一個索引中含有shard的數量,默認值為5,在索引創建后這個值是不能被更改的,
(7)每一個shard關聯的副本分片(replica shard)的數量,默認值為1,這個設定在任何時候都可以修改,
優點:
(1)水平分割和擴展我們存放的內容索引;
(2)分發和并行跨碎片操作提高性能/吞吐量;
3.2.4 副本(replica)
代表索引副本,ES可以設定多個索引的副本,副本的作用如下:
(1)提高系統的容錯性,當某個節點某個分片損壞或丟失時可以從副本中恢復,
(2)提高ES的查詢效率,ES會自動對搜索請求進行負載均衡,
四、應用場景
🌴 場景一:搜索服務
🌵 典型場景
儀表盤搜索
電子商務
手機應用搜索
地理位置搜索
🔥 主要特性
高性能:高并發、低延遲的搜索體驗
強相關:自定義打分、排序機制
高可用:機房、機架感知,異地容災
🚀 相關公司
騰訊健康碼、騰訊檔案全文檢索、攜程、拼多多、蘑菇街、滴滴、今日頭條、貝殼找房…….
🌴 場景二:日志實時分析
🌵 典型場景
業務日志:用戶行為日志、應用日志
狀態日志:慢查詢、例外探測
系統日志:debug、info、warn、error、fatal
🔥 主要特性
實時性:從日志產生到可訪問,秒級
全文搜索:基于倒排索引,支持靈活的搜索分析
互動式分析:萬億級日志,搜索秒級回應
🚀 相關公司
日志易
🌴 場景三:商業智能BI
🌵 典型場景
電子商務、移動應用、廣告媒體等業務都需要借助資料分析和資料挖掘來輔助商業決策,而規模龐大的業務資料對資料的統計分析造成了很大的挑戰,
🔥 主要特性
ES 擁有結構化查詢的能力,支持復雜的過濾和聚合統計功能,
幫助客戶對海量資料進行高效地個性化統計分析、發現問題與機會、輔助商業決策,讓資料產生真正的價值,
🚀 相關公司
睿思BI
小結
以上就是【一心同學】對【Elasticsearch】的介紹,也帶大家去理解了ES中的各種【基本概念】和ES在我們生活中的【應用場景】,相信大家現在對ES已經不再陌生了,而在接下來的博客中,【一心同學】將會向為大家繼續講解【ES的操作】,
如果這篇【文章】有幫助到你,希望可以給【一心同學】點個贊👍,創作不易,相比官方的陳述,我更喜歡用【通俗易懂】的文筆去講解每一個知識點,如果有對【后端技術】感興趣的小可愛,也歡迎關注?????? 【一心同學】??????,我將會給你帶來巨大的【識訓與驚喜】💕💕!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/438675.html
標籤:其他
上一篇:手把手教你搭建HADOOP集群