文章目錄
- 一、前言
- 二、Kafka四個核心API
- 三、kafka stream
- 3.1 Kafka Streams概述
- 3.2 為什么要有Kafka Streams
- 3.3 單詞統計案例
- 四、kafka interceptor
- 4.1 攔截器原理
- 4.2 攔截器案例
- 4.2.1 需求
- 4.2.2 案例實操
- 4.2.3 測驗
- 4.3 kafka自定義磁區
- 4.4 springboot集成kafka
- 四、尾聲
一、前言
本文主要講解kafka stream和kafka interceptor,kafka stream是一個實時的流客戶端,可以從kafka-server某個topic取資料,也可以從發送資料到kafka-server某個topic,只要kafka-stream之后一直運行不停止,就可以一次建立連接,永遠取kafka互動,工程中,只要集成了kafka stream的Java程式可以實時取到指定input-topic上的訊息物體,且可以將訊息加工之后,實時地將訊息發送到output-topic,
kafka interceptor是一個在發送訊息之前的攔截器,可以修改這個訊息/記錄的topic、partition、key、value、timestamp五個屬性,而且攔截器還可以知道此訊息是否發送成功,
kafka partition類似攔截器,也是在發送訊息之前設定,可以自定義訊息發送到哪個partition,springboot集成kafka和集成其他中間件一樣,基本上匯入pom依賴,配置好application.yaml檔案,然后配置@Configuration修飾就好了,
本文源代碼:kafka stream與interceptor、自定義partition、springboot集成kafka
二、Kafka四個核心API
第一篇博文中(解開Kafka神秘的面紗(一):kafka架構與應用場景),介紹過Kafka最重要的四個核心API是Producer API、Consumer API、Streams API、Connector API,四者的關系如下圖:
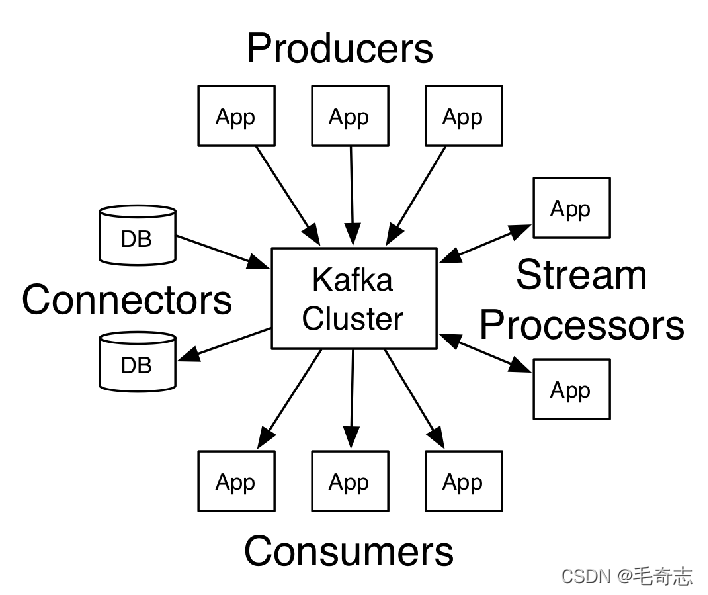
Producer API、Consumer API就是生產者和消費者,很容易理解,Connector API主要側重kafka可以和其他資料源互動(各種關系型資料庫和非關系型資料庫),比較簡單,本文介紹的是Streams API,主要包括stream和interceptor兩個部分,就是上圖右邊的stream和processors,
kafka開發中,針對四種核心api,涉及到kafka的三個依賴存根,
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.1.1</version>
</dependency>
這是kafka核心包2.1.1是kafka的版本,2.13是這個kafka所依賴的scala版本,
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.1</version>
</dependency>
這個是kafka客戶端包,主要封裝了producer consumer兩個api,
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.1.1</version>
</dependency>
這個是streams依賴,主要封裝了stream interceptor依賴,
三、kafka stream
3.1 Kafka Streams概述
Kafka Streams是一個客戶端庫,用于構建任務關鍵型實時應用程式和微服務,其中輸入輸出資料存盤在Kafka集群中,Kafka Streams結合了在客戶端撰寫和部署標準Java和Scala應用程式的簡單性以及Kafka服務器端集群技術的優勢,使這些應用程式具有高度可擴展性,彈性,容錯性,分布式等等,Kafka Streams具有如下特點:
(1) 功能強大:高擴展性,彈性,容錯
(2) 輕量級:無需專門的集群,一個庫,而不是框架
(3) 完全集成:100%的Kafka 0.10.0版本兼容,易于集成到現有的應用程式
(4) 實時性:毫秒級延遲、并非微批處理、視窗允許亂序資料、允許遲到資料
3.2 為什么要有Kafka Streams
為什么要引入kafka stream?因為kafka是一個流式存盤系統(這里的流不要理解為Java IO流),每個訊息由 index+value+timestamp 構成,但是不能直接用cat命令查看,如圖:

因為是流式存盤,如果想要在程式看到訊息物體,需要使用kafka stream;而且之前kafka消費者是對生產者生產的訊息直接消費,生產者生產什么樣的訊息,消費者就消費什么樣的訊息,如下圖:

現在,如果有了kafka stream,不僅可以在程式中拿到訊息物體,還可以在程式對訊息加工之后,在交給消費者消費,
即之前是 kafka創建一個topic,然后生產者向這個topic發送訊息,消費者從這個topic取訊息,生產者生產什么訊息,什么訊息就存到topic的partition上,然后消費者原封不動的將指定名稱的topic上面的訊息取下來(kafka上訊息不會洗掉,只是移動offset,默認七天后洗掉),
現在是創建兩個topic,input-topic和output-topic,并提供一個集成了kafka stream的Java程式,從input-topic取資料,然后加工資料,將加工好的資料放到output-topic上,最后啟動生產者向 input-topic 上發送訊息,啟動消費者取 output-topic 上的訊息,既然是從 output-topic 上取,取到的當然是經過 kafka stream 程式加工之后的訊息,
eg: 之前rabbitmq訊息是可以直接看到,但是現在kafka流式存盤不行,
3.3 單詞統計案例
以下是WordCountDemo示例代碼的要點(為了方便閱讀,使用的是java8 lambda運算式),
第一步:啟動zk和kafka
./zkServer.sh start
./bin/kafka-server-start.sh config/server.properties
第二步:準備輸入主題并啟動生產者
創建名為streams-plaintext-input的輸入主題和名為streams-wordcount-output的輸出主題:
創建一個輸入topic
./bin/kafka-topics.sh --create --bootstrap-server 192.168.100.120:9092 --topic stream-plaintext-input --partitions 1 --replication-factor 1
創建一個輸出topic并啟用壓縮,因為輸出流是更改日志流
./bin/kafka-topics.sh --create --bootstrap-server 192.168.100.120:9092 --topic stream-wordcount-output --partitions 1 --replication-factor 1 --config cleanup.policy=compact
使用相同的kafka-topics工具描述創建的主題:
./bin/kafka-topics.sh --zookeeper 192.168.100.120:2181 --describe
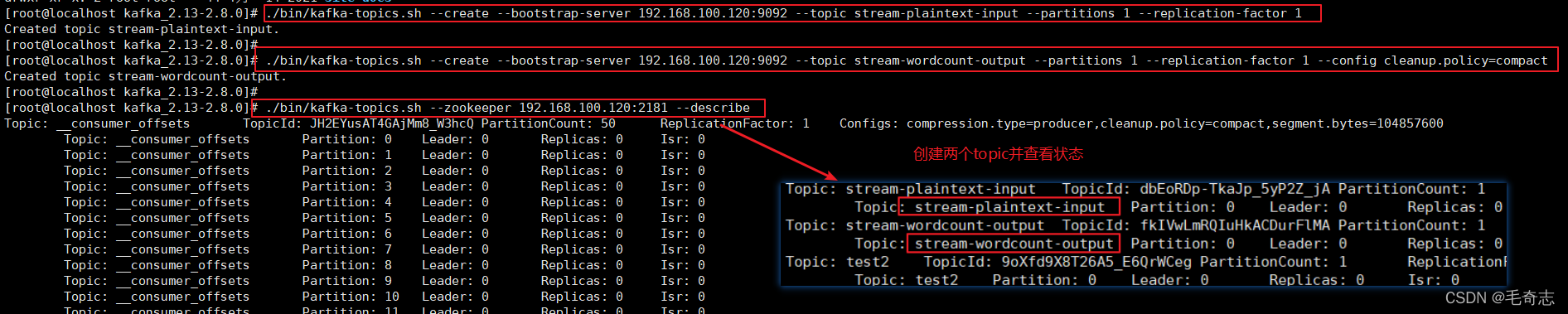
也可以直接查看兩個topic是否創建好了
./bin/kafka-topics.sh --bootstrap-server 192.168.100.120:9092 --list
第三步:啟動Wordcount應用程式
./bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示應用程式將從輸入主題stream-plaintext-input讀取,對每個讀取訊息執行WordCount演算法的計算,并將其當前結果連續寫入輸出主題streams-wordcount-output,
注意:在kafka解壓目錄的libs包目錄下,這里存在一個 kafka-stream-examples-2.8.0.jar,這個jar包就是kafka官方提供的一個演示kafka stream的examples,如下圖:

這個jar包解壓之后,里面有一個 org.apache.kafka.streams.examples.wordcount.WordCountDemo 類,這個類的作用是對生產者發送的訊息統計,這個類監聽的生產者topic是streams-plaintext-input,消費者topic是 streams-wordcount-output,如下


直接在centos上運行 ./bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo 這個程式有時候會連不上 127.0.0.1:9092 本機kafka,我們可以將 kafka-stream-examples-2.8.0.jar 在自己電腦上解壓,將 WordCountDemo 類單獨拿出來,放在idea上運行,如下:
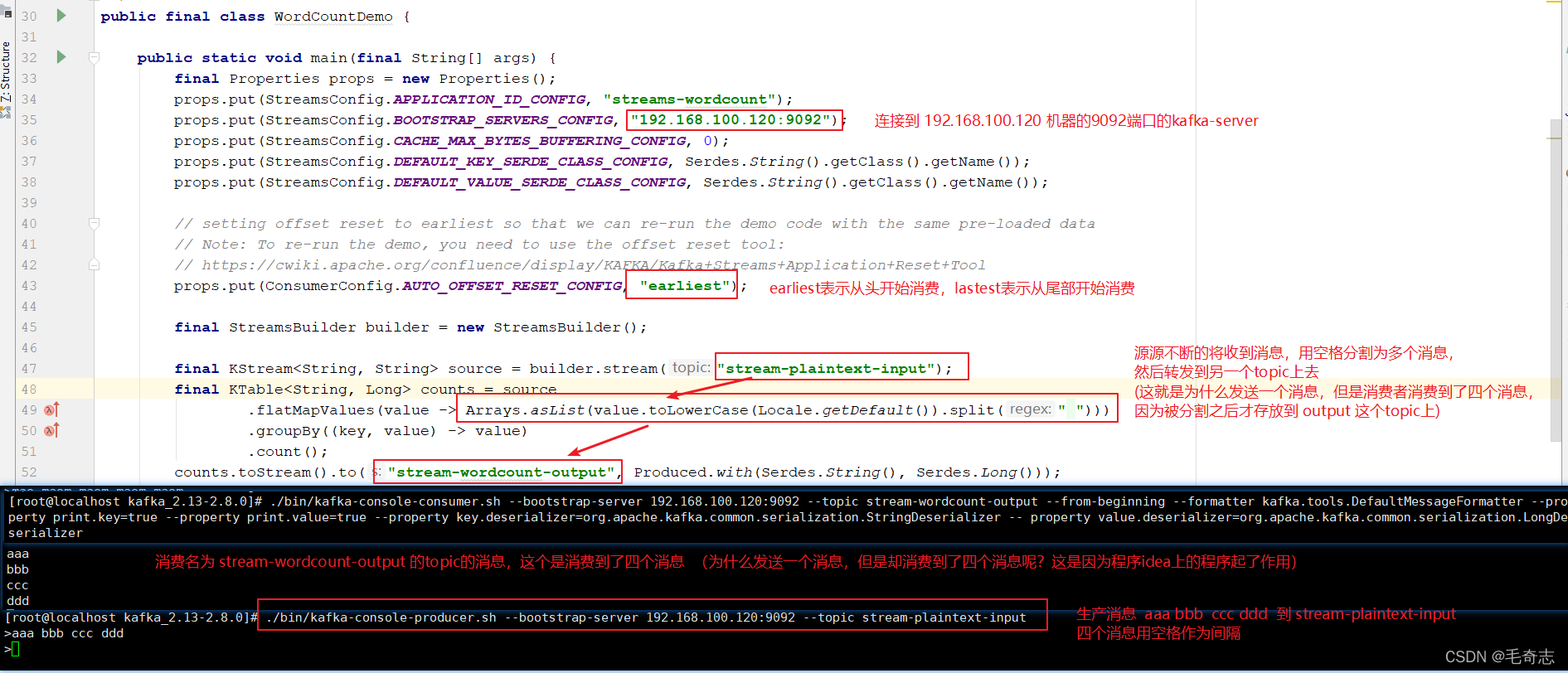
第四步:啟動生產者和消費者
啟動生產者:./bin/kafka-console-producer.sh --bootstrap-server 192.168.100.120:9092 --topic stream-plaintext-input
啟動消費者:./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.120:9092 --topic stream-wordcount-output --from-beginning --formatter kafka.tools.DefaultMessageFormatter --property print.key=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer -- property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
運行結果:
四、kafka interceptor
4.1 攔截器原理
Producer攔截器(interceptor)是在Kafka 0.10版本被引入的,主要用于實作clients端的定制化控制邏輯,攔截器只是對于producer而言(一定不是針對consumer而言的,當訊息已經到了消費階段,這個訊息早就存放到kafka-server了),interceptor使得用戶在訊息發送前以及producer回呼邏輯前有機會對訊息做一些定制化需求,比如修改訊息等,
同時,producer允許用戶指定多個interceptor按序作用于同一條訊息從而形成一個攔截鏈(interceptor chain),Intercetpor的實作介面是org.apache.kafka.clients.producer.ProducerInterceptor,如下:
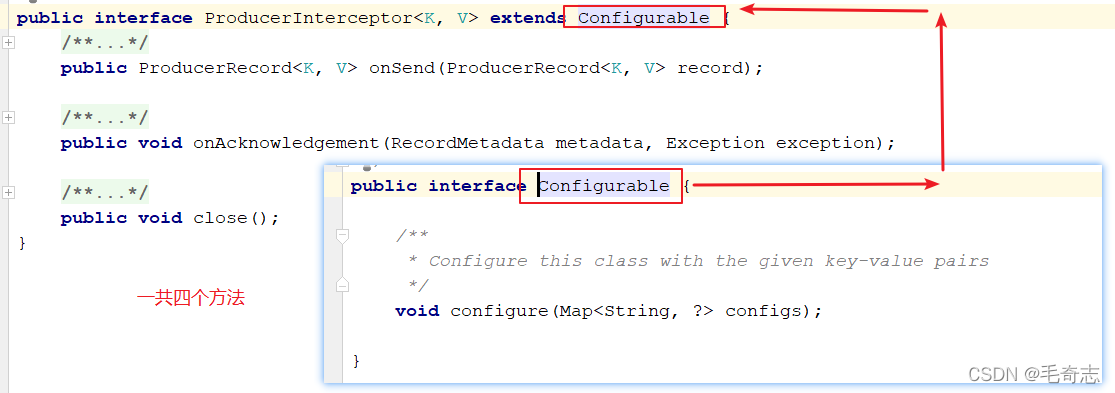
解釋上面四個方法:
(1)configure(configs):獲取配置資訊和初始化資料時呼叫,
(2)onSend(ProducerRecord):該方法封裝進KafkaProducer.send方法中,即它運行在用戶主執行緒中,Producer 確保在訊息被序列化以及計算磁區前呼叫該方法,用戶可以在該方法中對訊息做任何操作,包括topic partition index value timestamp但最好保證不要修改訊息所屬的topic和磁區partition,否則會影響目標磁區的計算,
(3)onAcknowledgement(RecordMetadata, Exception):該方法會在訊息被應答或訊息發送失敗時呼叫,并且通常都是在producer回呼邏輯觸發之前,onAcknowledgement運行在producer的IO執行緒中,因此不要在該方法中放入很重的邏輯,否則會拖慢producer的訊息發送效率,
(4)close:該方法用來關閉interceptor,主要用于執行一些資源清理作業,
如前所述,interceptor可能被運行在多個執行緒中,因此在具體實作時用戶需要自行確保執行緒安全,另外倘若指定了多個interceptor,則producer將按照指定順序呼叫它們,并僅僅是捕獲每個interceptor可能拋出的例外記錄到錯誤日志中而非在向上傳遞,這在使用程序中要特別留意,
interceptor和stream區別:stream是取input-topic的資料,加工資料之后,無法將加工之后的資料重新插入到input-topic中去,只能放到另一個output-topic中去,但是,有了interceptor之后,可以取input-topic的資料,加工資料之后,再將加工之后的資料重新插入到input-topic中去,而且,還可以定制化訊息存放在某個partition,比如,可以將partition-0的訊息拿出來,放到partition-1中去,
4.2 攔截器案例
4.2.1 需求
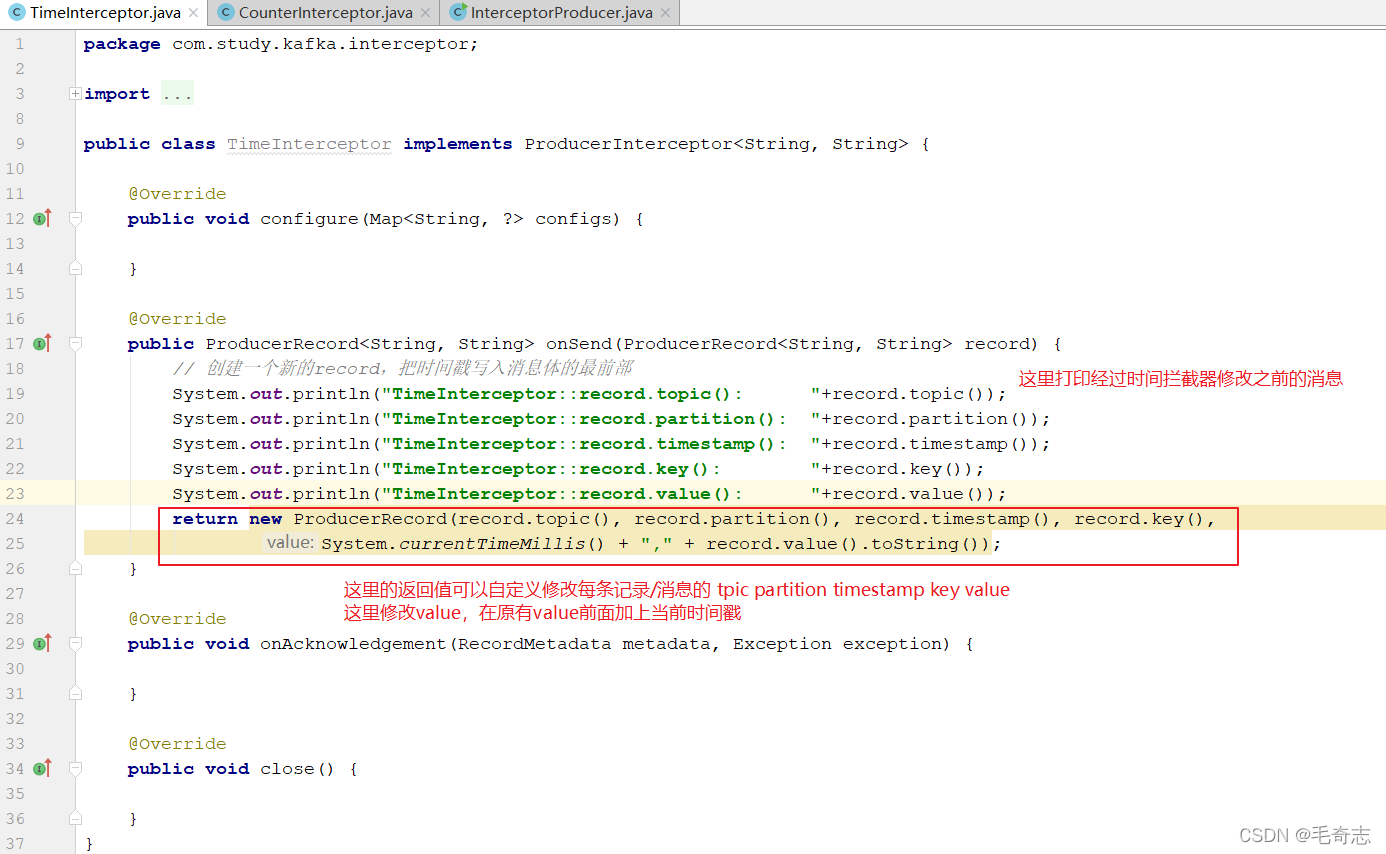
需求:實作一個簡單的雙interceptor組成的攔截鏈,第一個interceptor會在訊息發送前將時間戳資訊加到訊息value的最前部;第二個interceptor會在訊息發送后更新成功發送訊息數或失敗發送訊息數,即

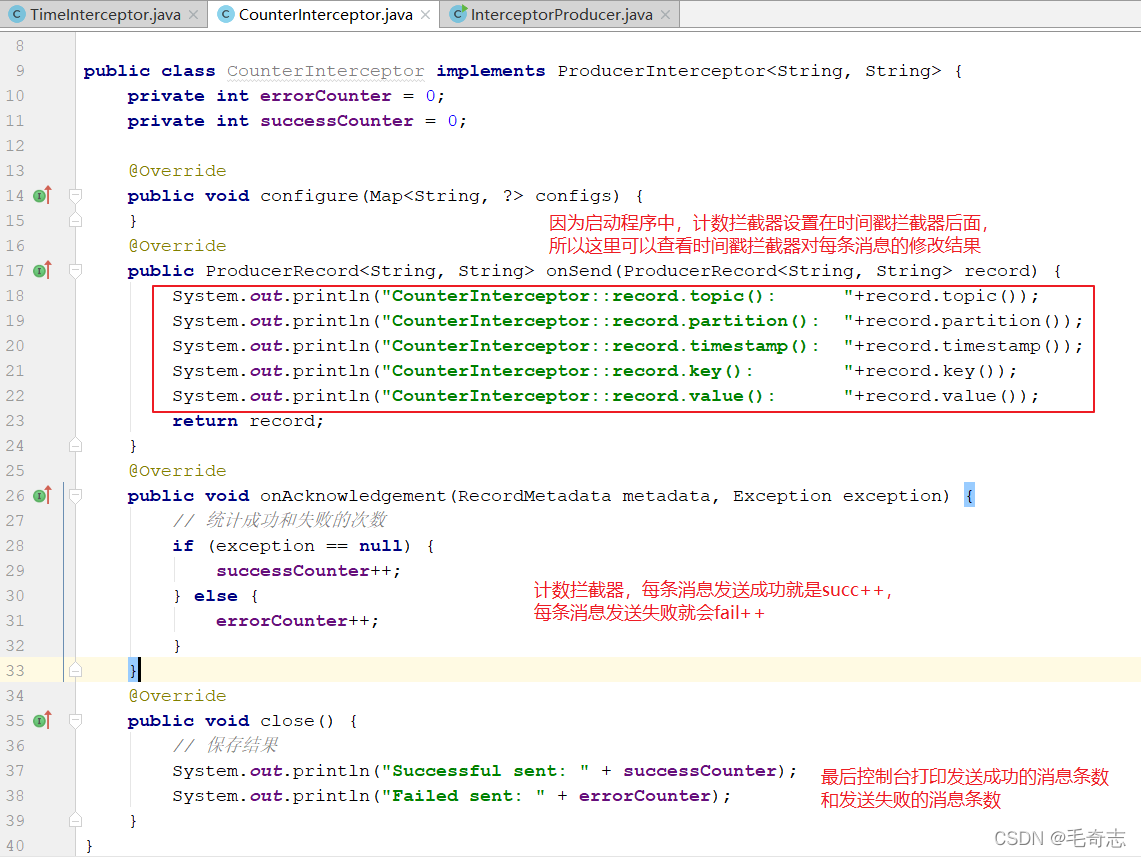
每條訊息先到TimeInterceptor,然后再到CountInterceptor,最后在發送出去,
4.2.2 案例實操
涉及的類包括三個,兩個攔截器和一個主程式
第一個程式:時間戳攔截器
public class TimeInterceptor implements ProducerInterceptor<String, String>
第二個程式:計數攔截器,統計發送訊息成功和發送失敗訊息數,并在producer關閉時列印這兩個計數器
public class CounterInterceptor implements ProducerInterceptor<String, String>
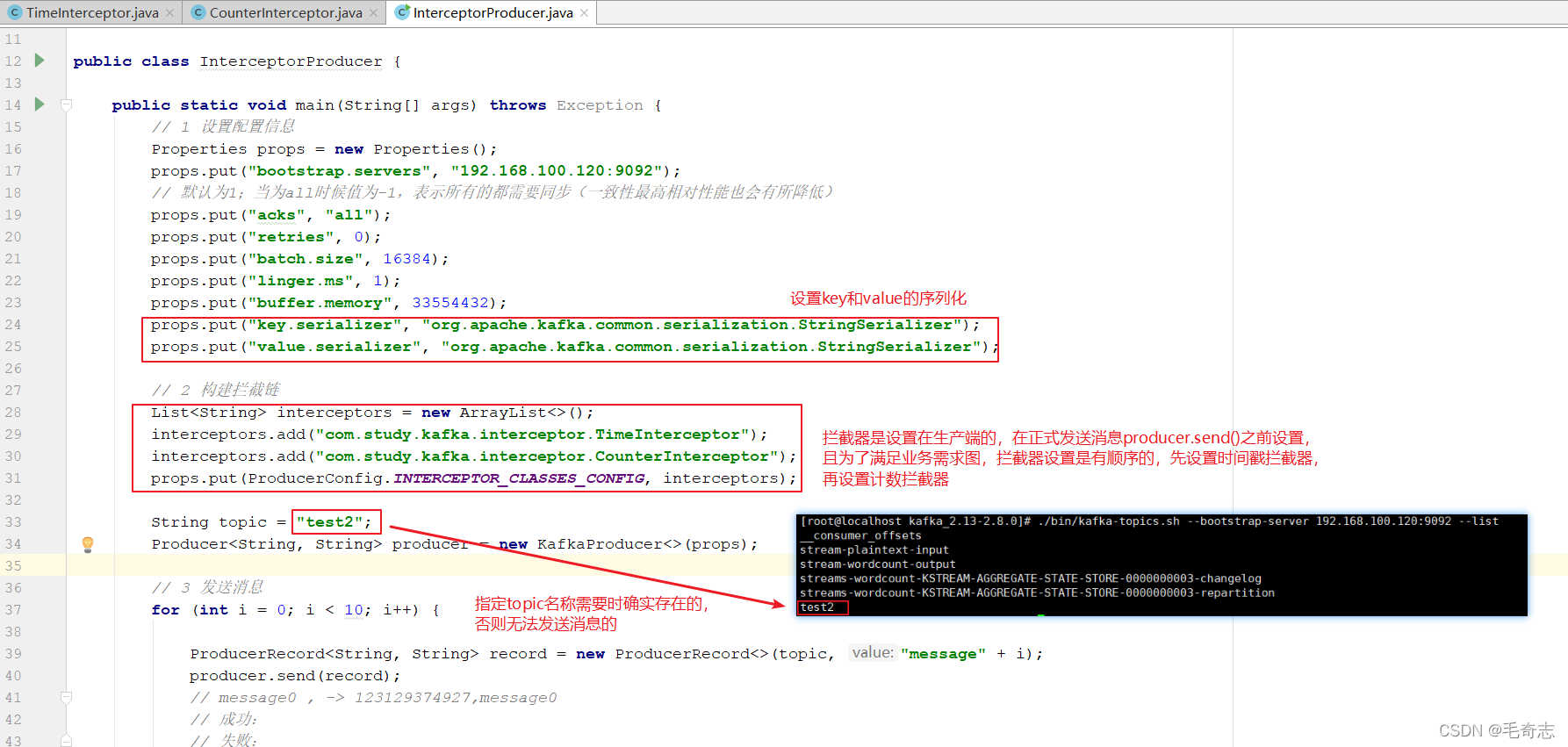
第三個程式:producer主程式
public class InterceptorProducer
4.2.3 測驗
第一步:運行客戶端InterceptorProducer主程式
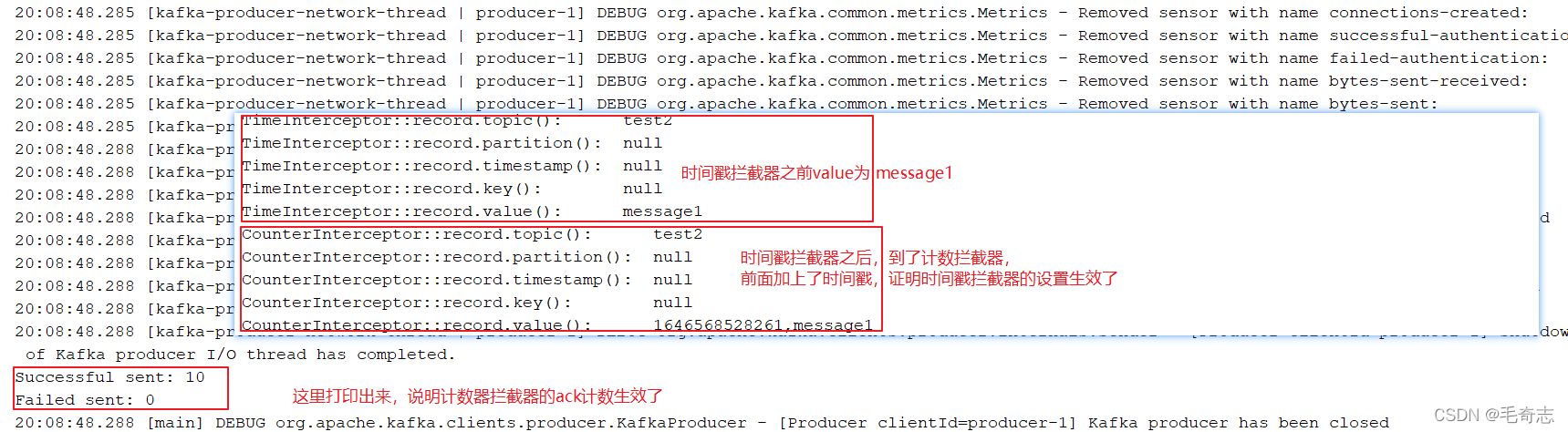
第二步:在kafka上啟動消費者
./bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.120:9092 --topic test2 --from-beginning

4.3 kafka自定義磁區
自定義磁區和interceptor一樣,也是生產端的,就是指定key的訊息發送到某個partition,
如果一個topic擁有多個磁區,但是,訊息被發送給kafka的時候,只是指定了topic的名稱,就是這條訊息應該發送給哪個topic,訊息消費也是指定topic的,partition這個概念是對客戶端透明的,客戶端生產訊息和消費訊息都不會涉及到,
那么,當一個topic擁有多個磁區,某條訊息具體存放到哪個partition上面呢?kafka有自己的默認規則,這個默認規則就在原始碼 DefaultPartitioner 類里面,如下圖:
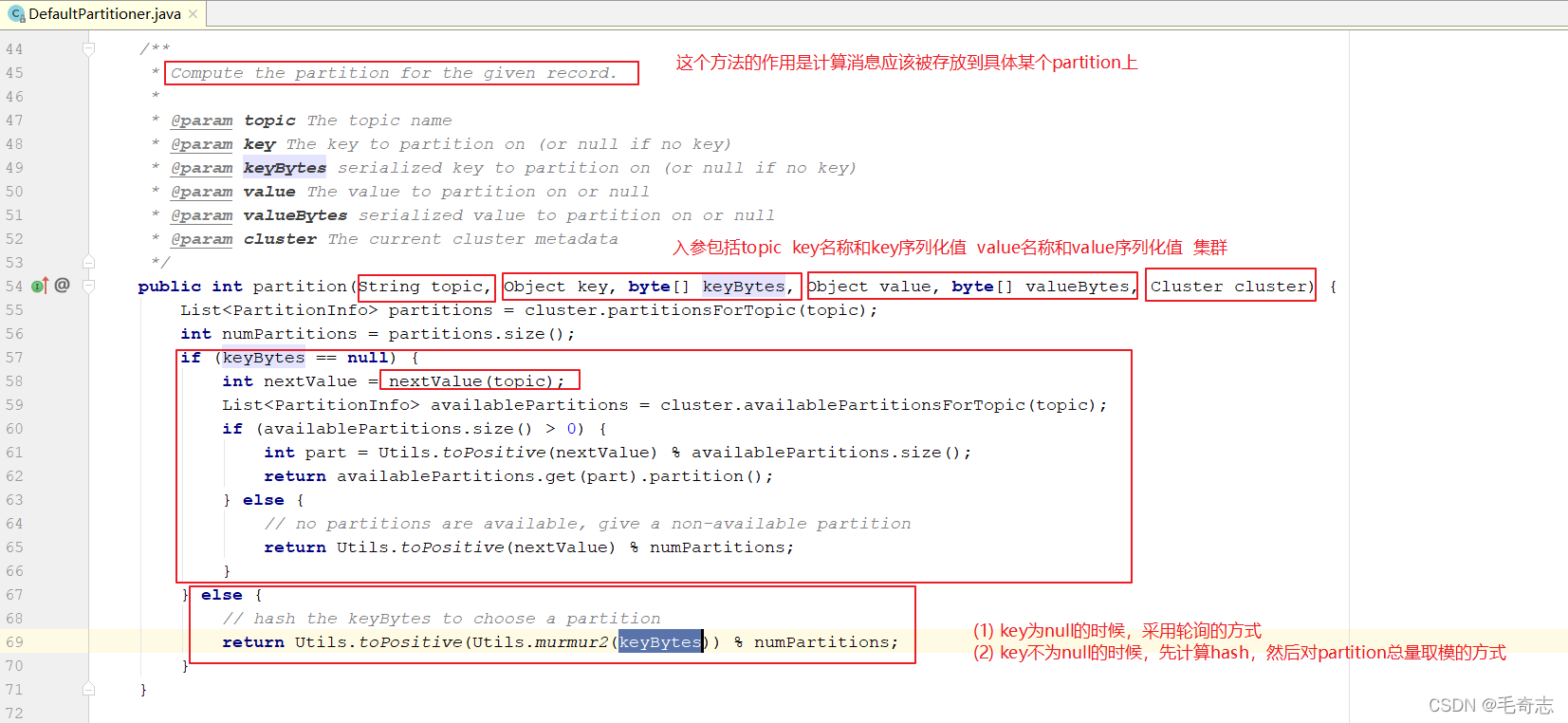
好了,現在我們可以實作Partitioner介面得到一個自定義的MyPartitioner類,然后
新建一個topic,名為test3,擁有三個partition
./bin/kafka-topics.sh --create --topic test3 --bootstrap-server 192.168.100.120:9092 --partitions 3 --replication-factor 1
./bin/kafka-topics.sh --bootstrap-server 192.168.100.120:9092 --list
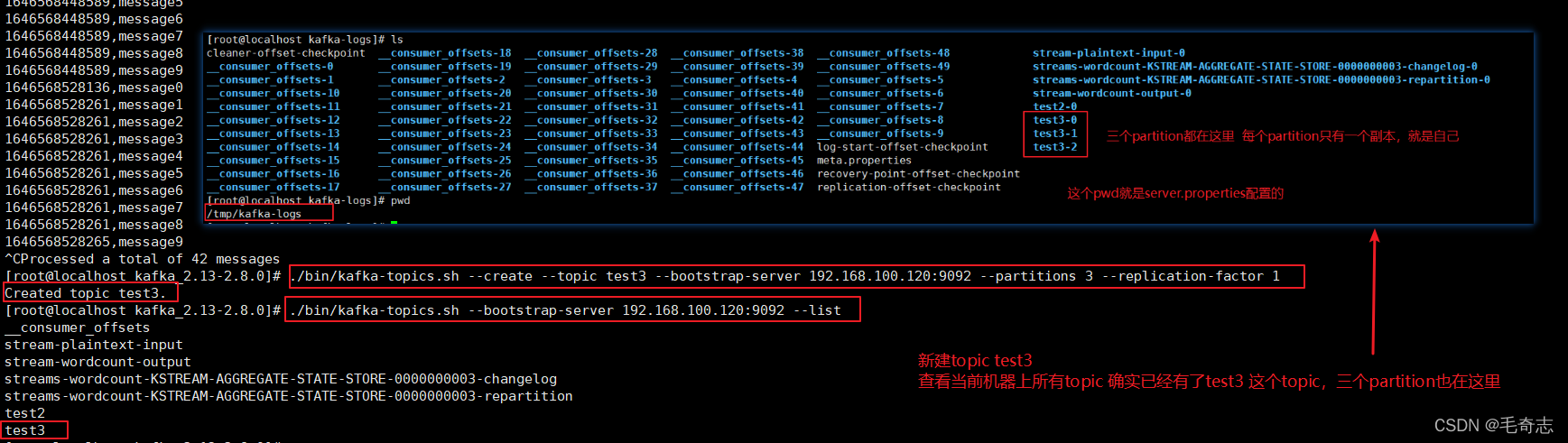
運行成功,自定義partition為1,10條訊息都發送到了1上面去了
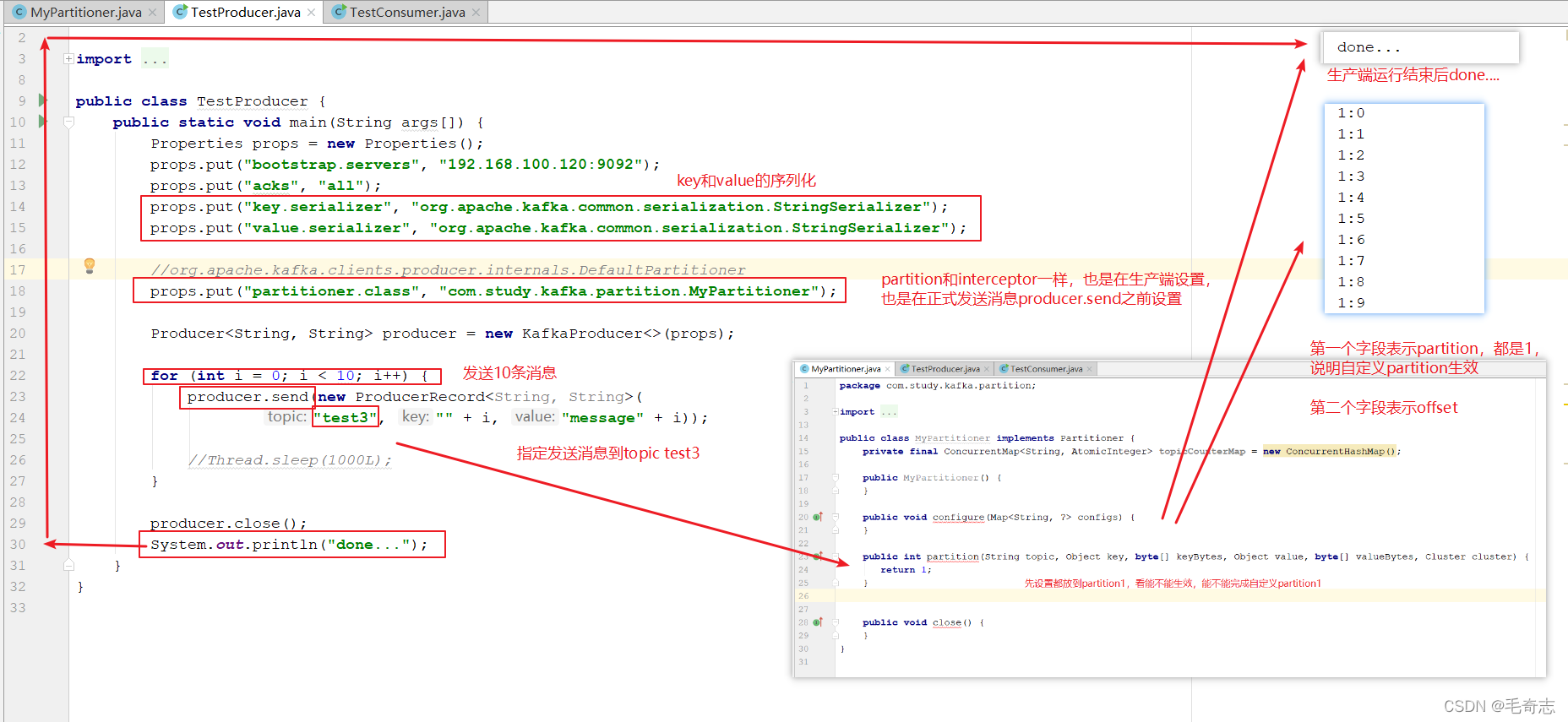
eg: interceptor 和 partion 都是生產端,所以都是在生產代碼里面修改,
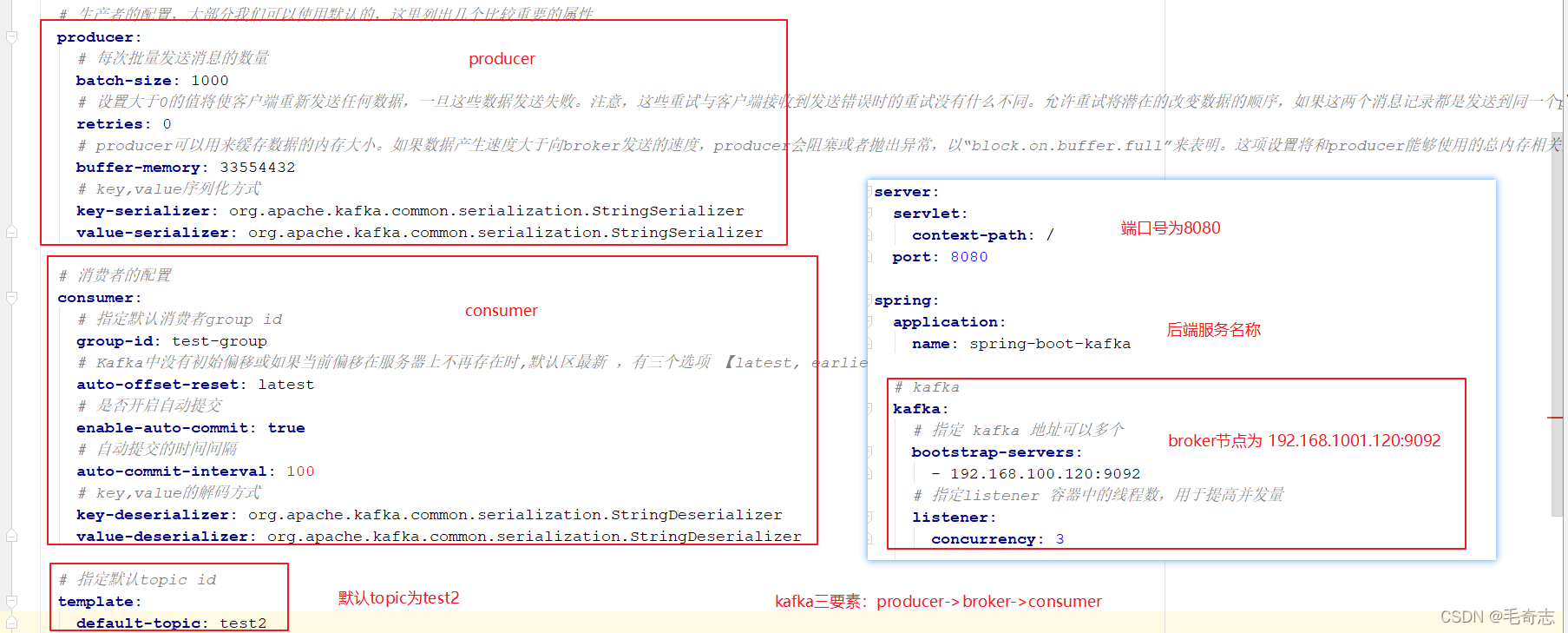
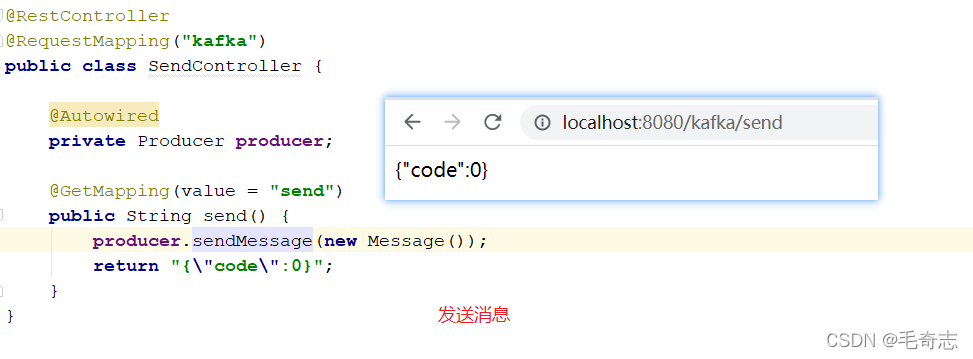
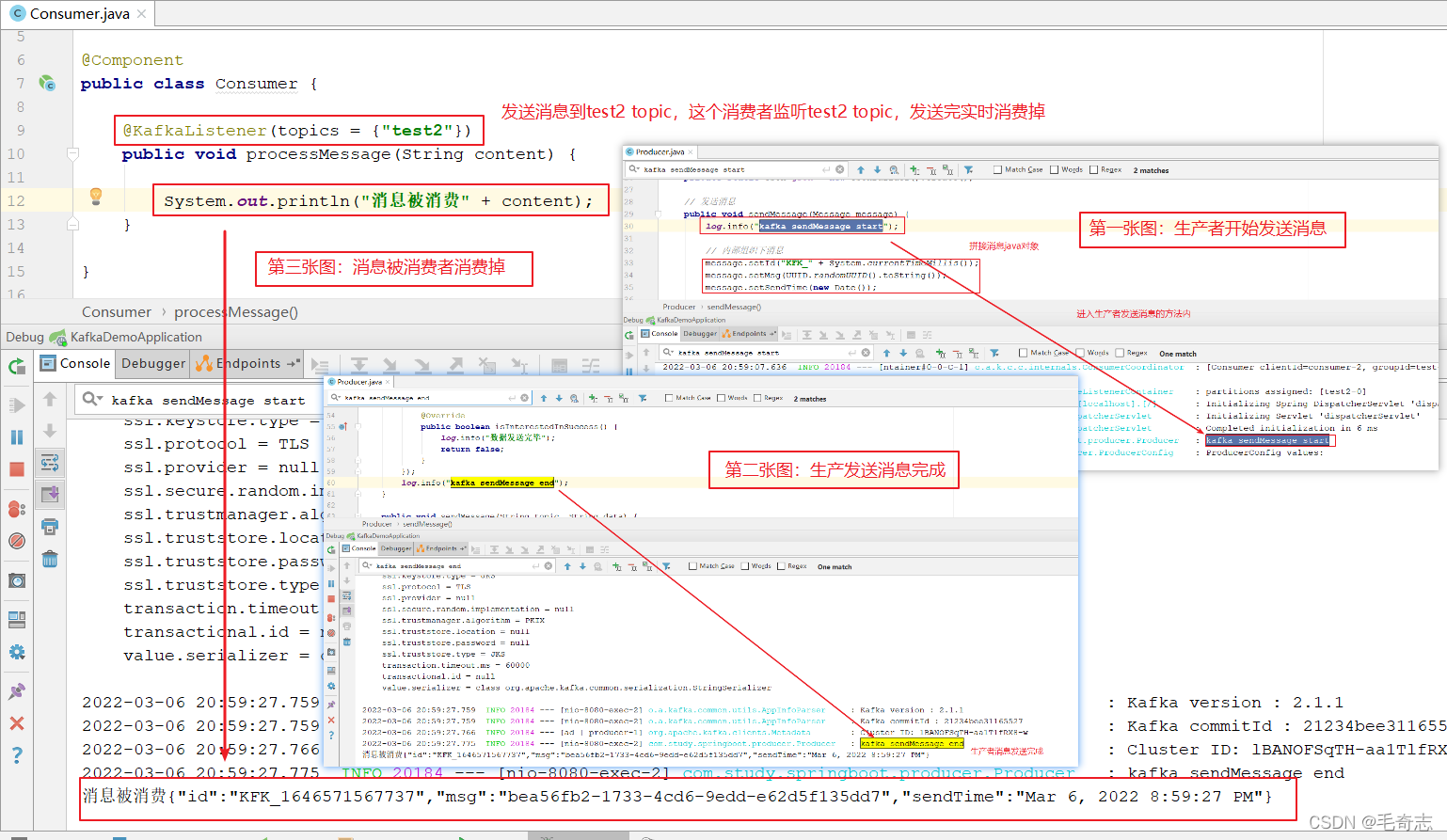
4.4 springboot集成kafka
四、尾聲
本文主要介紹了kafka stream和kafka interceptor,
天天打碼,天天進步!!
本文源代碼:kafka stream與interceptor、自定義partition、springboot集成kafka
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/439240.html
標籤:其他