文章目錄
- 0 專案背景
- 1 專案明細
- 1.1 資料的來源及明細
- 1.2 專案目的
- 1.3 專案思路
- 2、資料預處理
- 2.1 資料匯入
- 2.2 資料預處理
- 2.3 日期與時間格式化
- 2.4 洗掉例外值
- 3、資料分析
- 3.1 資料整體情況
- 3.2 用戶行為轉化
- 3.3 用戶復購率和跳失率
- 3.4 用戶時間習慣
- 3.4.1 日期維度用戶行為習慣
- 3.4.2 時間維度用戶行為習慣
- 3.5 用戶商品偏好類別
- 3.6 用戶價值層度
- 3.6.1 R維度評分
- 3.6.2 F維度評分
- 3.6.3 RF 維度綜合評分進行用戶價值分層
- 4、結論及應對方法
0 專案背景
練手專案: 當今電商行業的運營模式需要針對用戶的喜好程度或用戶習慣進行相應的策略性改變,而策略的來源則是通過對用戶的顯式反饋或是隱式反饋進行用戶行為分析,進一步為用戶提供個性化、差異化的的服務,最終達到營收率提升的目的,
1 專案明細
1.1 資料的來源及明細
UserBehavior是阿里巴巴提供的一個淘寶用戶行為資料集,資料來源請戳

UserBehavior.csv
本資料集包含了2017年11月25日至2017年12月3日之間,有行為的約一百萬隨機用戶的所有行為(行為包括點擊、購買、加購、喜歡),資料集的組織形式和MovieLens-20M類似,即資料集的每一行表示一條用戶行為,由用戶ID、商品ID、商品類目ID、行為型別和時間戳組成,并以逗號分隔,關于資料集中每一列的詳細描述如下:

注意到,用戶行為型別共有四種,它們分別是:

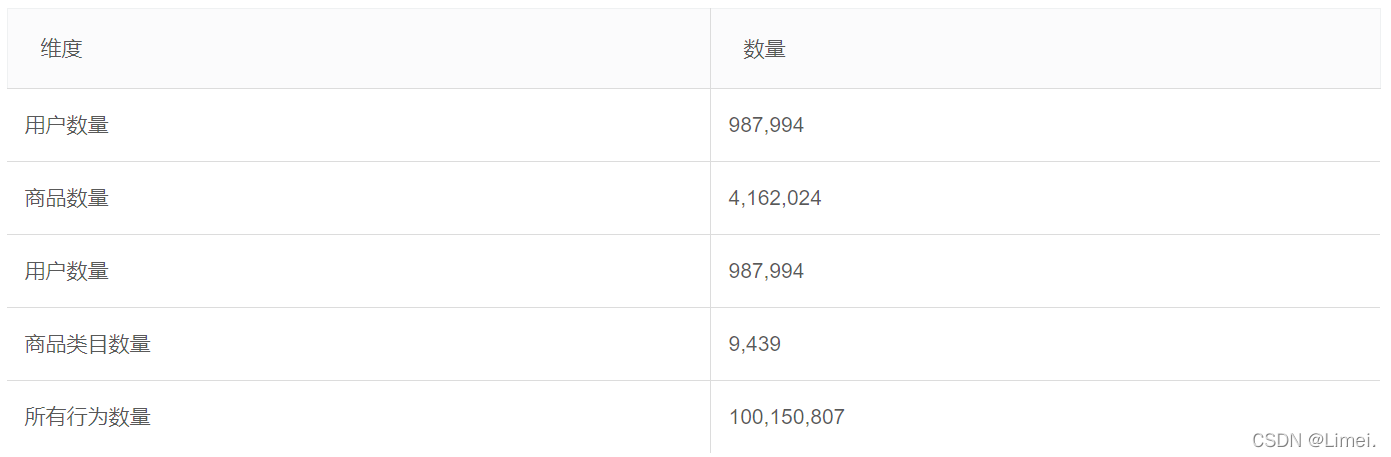
關于資料集大小的一些說明如下:
1.2 專案目的
選取1000000(100w)個隱式反饋資料集中找到用戶行為的一些“規律”,并通過這些“規律”進行漏斗模型,RFM模型分析得到對用戶有針對性的電商營銷方式,
1.3 專案思路
2、資料預處理
此次專案使用的是 Navicat Premium資料庫管理工具連接Mysql 8.0,進行對UserBehavior.csv 資料集的處理
2.1 資料匯入
方法一:在Navicat里面根據指示直接匯入資料表,點這里~
方法二:代碼匯入
# 創建一個表userbehaviour用來存放資料,資料型別根據官方檔案設定
create table userbehaviour(
userID int,
itemID int,
categoryID int,
bahaviortype text,
timestamp int
);
# 寫入檔案路徑
load data infile "D:\tianchi\UserBehavior.csv"
into table userbehavior
fields terminated by ','
lines terminated by '\n';
匯入csv檔案資料執行提示錯誤(ERROR 1290),如果你也出現這個問題,這里貼上解決方案噢(通俗易懂)
資料量太大,這里只截取前100w的資料用作分析啦:
# 查看前10行資料
SELECT * FROM `userbehaviour` limit 10;
# 查看資料集的大小
SELECT
count( DISTINCT u.userID ) '用戶數量',
count( u.itemID ) '商品數量',
count( u.categoryID ) '商品類目數量',
count( u.behaviour ) '所有行為數量'
FROM
userbehaviour u;

2.2 資料預處理
資料查重及處理
# 展示重復資料
SELECT * FROM userbehaviour as u
WHERE (u.userID,u.itemID,u.categoryID,u.behaviour,u.TIMESTAMP)
IN
(SELECT * FROM userbehaviour
GROUP BY userID,itemID,categoryID,behaviour,TIMESTAMP
HAVING count(*) > 1);
# 資料量過大,要運行很久
缺失值查找與處理
# 查看資料的缺失值
SELECT
count( userID ),
count( itemID ),
count( categoryID ),
count( behaviour ),
count( TIMESTAMP )
FROM
userbehaviour;

沒有缺失值,太好了 ^ _ ^
2.3 日期與時間格式化
# 時間格式轉化
# 添加日期date | 時間hour 欄位
ALTER TABLE userbehaviour
ADD hour VARCHAR ( 2 ),
ADD date VARCHAR ( 10 );
# 往欄位date、hour中匯入資料,調整time時間戳格式
UPDATE userbehaviour set date = FROM_UNIXTIME(TIMESTAMP,"%Y-%m-%d");
UPDATE userbehaviour set hour = FROM_UNIXTIME(TIMESTAMP,"%H");
函式:FROM_UNIXTIME
作用:將MYSQL中以INT(11)存盤的時間以"YYYY-MM-DD"格式來顯示,
語法:FROM_UNIXTIME(unix_timestamp,format)函式,具體戳這~
# 修改TIMESTAMP欄位的存盤空間
ALTER TABLE userbehaviour
MODIFY COLUMN TIMESTAMP VARCHAR(255);
# 轉變時間戳的格式
UPDATE userbehaviour set TIMESTAMP = FROM_UNIXTIME(TIMESTAMP);
UPDATE userbehaviour set TIMESTAMP = SUBSTRING_INDEX(TIMESTAMP,'.',1);
修改后:

SUBSTRING_INDEX( ) 函式的使用,戳這~
2.4 洗掉例外值
# 查看日期的最大值與最小值,看是否有例外值
select max(date), min(date) from userbehaviour;

沒有例外值哈哈,如果有例外值,可以通過執行以下代碼洗掉例外值噢
# 篩選出日期在2017年11月25日 ——— 2017年12月3日之外的資料
SELECT count(*) FROM
userbehaviour
WHERE date < '2017-11-25'
or date > '2017-12-03';
# 剔除不在日期區間的資料
DELETE FROM userbehaviour
WHERE date < '2017-11-25'
OR date > '2017-12-03';
經過預處理后,資料集還剩…
#查看還剩多少
SELECT
count( DISTINCT u.userID ) '用戶數量',
count( u.itemID ) '商品數量',
count( u.categoryID ) '商品類目數量',
count( u.behaviour ) '所有行為數量'
FROM
userbehaviour u;

//是的,經過預處理后資料量沒有變…因為,源資料已經很干凈了T_T(偷笑),當作練習啦!
3、資料分析
資料預處理終于搞定了!!接下來我們進入正式的分析吧!
3.1 資料整體情況
# 總體UV(Unique visitor)、PV(Page View)、人均瀏覽數、成交量
SELECT
count( DISTINCT userID ) 'UV 獨立訪客量',
SUM( CASE WHEN behaviour = 'pv' THEN 1 ELSE 0 END ) 'PV 頁面瀏覽量',
SUM( CASE WHEN behaviour = 'pv' THEN 1 ELSE 0 END ) / count( DISTINCT userID ) 'PV 人均瀏覽量',
SUM( CASE WHEN behaviour = 'buy' THEN 1 ELSE 0 END ) 'BY成交量'
FROM
userbehaviour;

總體UV、PV、人均瀏覽次數、成交量
# 日均UV(Unique visitor)、PV(Page View)、人均瀏覽數、成交量
SELECT
date,
count( DISTINCT userID ) 'UV 獨立訪客量',
SUM( CASE WHEN behaviour = 'pv' THEN 1 ELSE 0 END ) 'PV 頁面瀏覽量',
SUM( CASE WHEN behaviour = 'pv' THEN 1 ELSE 0 END ) / count( DISTINCT userID ) 'PV 人均瀏覽量',
SUM( CASE WHEN behaviour = 'buy' THEN 1 ELSE 0 END ) 'BY成交量'
FROM
userbehaviour
GROUP BY
date;
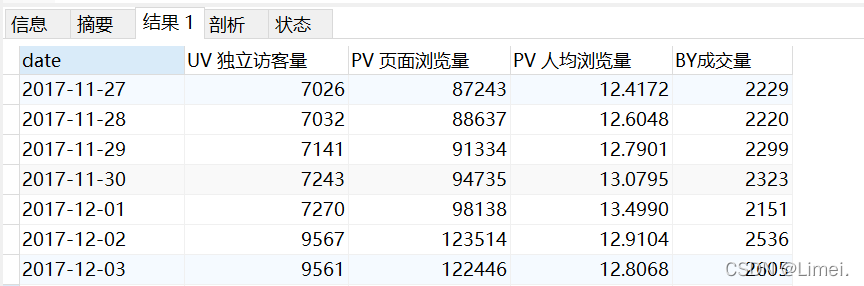
日均UV、PV、人均瀏覽次數、成交量
3.2 用戶行為轉化
# 總用戶行為轉化
# 漏斗模型
SELECT
behaviour '行為型別',
count(*) '行為數量'
FROM
userbehaviour
GROUP BY
behaviour
ORDER BY
行為數量 DESC;
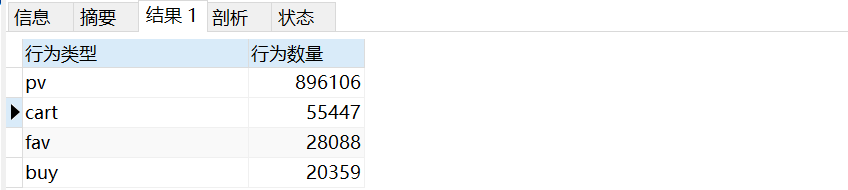
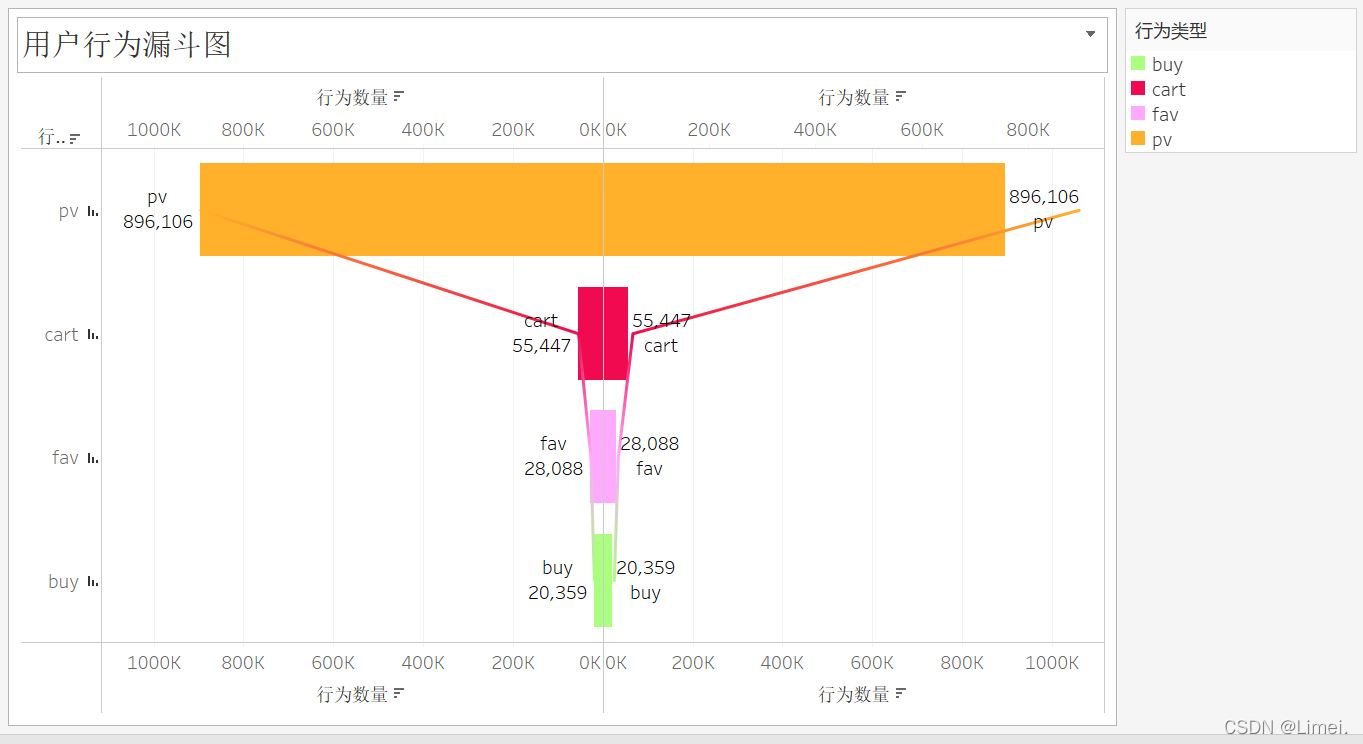
總用戶行為漏斗圖,瀏覽行為轉化為加購、收藏、購買的轉化率逐級降低,
計算轉化率:
# 分析每種情況下的轉化率
CREATE VIEW user_p AS
SELECT userID,itemID,
sum( CASE WHEN behaviour = 'pv' THEN 1 ELSE 0 END ) AS click,
sum( CASE WHEN behaviour = 'fav' THEN 1 ELSE 0 END ) AS favor,
sum( CASE WHEN behaviour = 'buy' THEN 1 ELSE 0 END ) AS buy,
sum( CASE WHEN behaviour = 'cart' THEN 1 ELSE 0 END ) AS buycar
FROM
userbehaviour
GROUP BY
userID,
itemID;
下面我就不貼運行結果圖啦,直接將得出的結果寫在備注了,
# 總的點擊(瀏覽)量 : 896106
SELECT sum(click) 點擊量 FROM user_p;
# 有瀏覽+購買的數量 :9845
SELECT sum( buy ) '瀏覽+購買'
FROM user_p
WHERE
click > 0
AND buy > 0
AND favor = 0
AND buycar = 0;
# 有瀏覽+加購的數量 : 23999
SELECT sum( buycar ) '瀏覽+加購'
FROM user_p
WHERE
click > 0
AND buy = 0
AND favor = 0
AND buycar > 0;
# 有瀏覽+收藏的數量 : 9973
SELECT sum( favor ) '瀏覽+收藏'
FROM user_p
WHERE
click > 0
AND buy = 0
AND favor > 0
AND buycar = 0;
# 有瀏覽+流失的數量 : 789133
SELECT sum( click ) '瀏覽+流失'
FROM user_p
WHERE
click > 0
AND buy = 0
AND favor = 0
AND buycar = 0;
# 有瀏覽+加購+購買的數量 : 2876
SELECT sum( buy ) '瀏覽+加購+購買'
FROM user_p
WHERE
click > 0
AND buy > 0
AND favor = 0
AND buycar > 0;
# 有瀏覽+收藏+購買的數量 : 942
SELECT sum( buy ) '瀏覽+收藏+購買'
FROM user_p
WHERE
click > 0
AND buy > 0
AND favor > 0
AND buycar = 0;
# 有瀏覽+加購+收藏的數量 : 678
SELECT sum( favor )+ sum( buy )
FROM user_p
WHERE
click > 0
AND buy = 0
AND favor > 0
AND buycar > 0;
# 有瀏覽+加購+收藏+購買的數量 : 289
SELECT sum( favor )+ sum( buy ) '瀏覽+加購+收藏+購買'
FROM user_p
WHERE
click > 0
AND buy > 0
AND favor > 0
AND buycar > 0;
總點擊(瀏覽)量:896106
| 轉換型別 | 轉換量 | 轉換率 |
|---|---|---|
| 瀏覽–>加購 | 23999 | 2.68% |
| 瀏覽–>收藏 | 9973 | 1.11% |
| 瀏覽–>購買 | 9845 | 1.10% |
| 瀏覽–>流失 | 789133 | 88.06% |
瀏覽+加購 :23999
| 轉換型別 | 轉換量 | 轉換率 |
|---|---|---|
| 瀏覽+加購–>購買 | 2876 | 11.98% |
瀏覽+收藏 :9973
| 轉換型別 | 轉換量 | 轉換率 |
|---|---|---|
| 瀏覽+收藏–>購買 | 942 | 9.44% |
瀏覽+收藏+加購 :678
| 轉換型別 | 轉換量 | 轉換率 |
|---|---|---|
| 瀏覽+收藏+加購–>購買 | 289 | 42.63% |
從以上結果說明:
1、用戶從瀏覽到購買的轉化率只有1.10%
2、用戶從瀏覽后加入購物車再購買的轉化率有9.44%
3、用戶從瀏覽后收藏再購買的轉化率有11.98%
4、用戶從瀏覽后加入購物車和收藏再購買的轉化率高達42.63%
5、用戶瀏覽頁面后什么也沒干即用戶流失率有88.06%
進一步分析:
1、從用戶瀏覽后加購以及收藏的行為后轉化率提升了約10倍,以及同時有收藏加購行為的轉化率更是直接提升了高達42倍可以看出,加購或收藏以及加購收藏的行為會提升交易成交量,因此我們可以從產品的互動界面、營銷機制等方面提高用戶收藏、加購的行為,進而提升交易量,
2、用戶的流失率太高,有88.06%,即用戶花了很多時間去瀏覽商品,卻沒有加購、收藏、購買的行為,猜測可能是推薦的商品并不符合用戶的需求,因為如果推薦的商品是用戶喜歡的,自然會下單,因此我們做一個假設檢驗,看看是否是推薦系統的“鍋”,
提出假設: 推薦系統不給力,推薦的商品不是用戶想要的
分析思路: 通過查看點擊(瀏覽)量前20的商品ID以及購買量前20的商品ID,看重復值的概率有多大(即查看瀏覽量多的是不是下單多的,如果是,說明推薦的是用戶需要的,如果不是,說明推薦系統不給力)
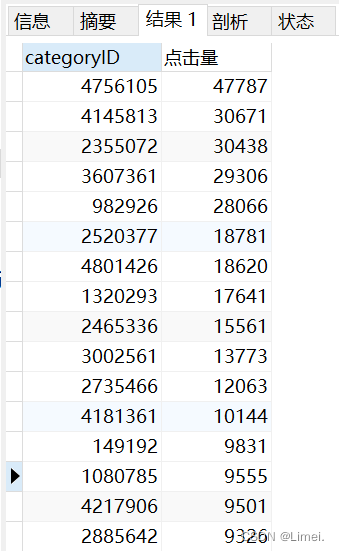
1、點擊(瀏覽)量前20的商品類別
# 瀏覽點擊量前20的商品ID及點擊次數
CREATE VIEW click AS
SELECT categoryID,count( categoryID ) AS 點擊量
FROM userbehaviour
WHERE behaviour = 'pv'
GROUP BY categoryID
ORDER BY
點擊量 DESC
LIMIT 20;
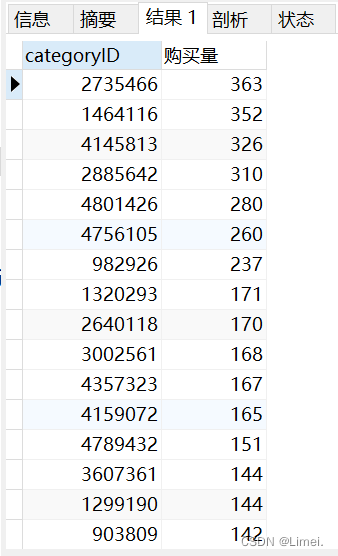
2、購買量前20的商品類別
# 購買量前20的商品類別ID及購買量
CREATE VIEW buy AS
SELECT categoryID,count( categoryID ) AS 購買量
FROM userbehaviour
WHERE behaviour = 'buy'
GROUP BY categoryID
ORDER BY
購買量 DESC
LIMIT 20;
3、查看點擊量前20的商品類別ID與購買量前20的商品類別ID的重復值
# 查看點擊量前20的商品類別ID 以及購買量前20的商品類別ID 是相同的商品類別ID
SELECT buy.categoryID
FROM buy JOIN click ON click.categoryID = buy.categoryID;
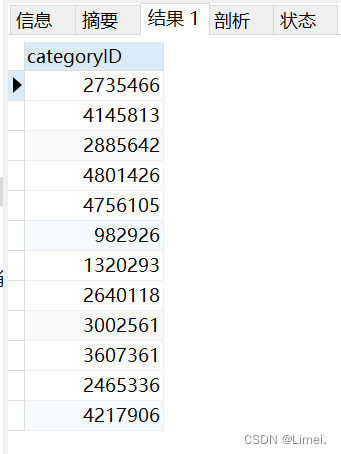
很明顯,我們似乎錯怪了推薦系統!購買量前20的商品類別中有12種商品都是點擊量前20里面的,說明我們推薦系統展示的商品是和我們用戶的需求相關的
(不要懷疑淘寶的推薦系統了,不然我怎么每次打開淘寶推薦的都是我想要的,然后瘋狂“剁手”…T^T)
番外: 那是不是商家砸多點錢提升產品的曝光率,他們的商品就會賣得越好呢!?(興奮)
(思考狀…應該不是絕對的,你曝光的再多不是我要的我也不會點?
4、既然點擊量和購買量前20的商品類別有如此高的重合性,還會是什么原因導致用戶流失率這么高呢?
接下來我們對每個商品進行細分,看下曝光的具體商品和購買的商品是否有相關性
4.1 計算點擊量前10的商品的購買量
# 瀏覽量前10的商品
CREATE VIEW dianji AS
SELECT itemID,count( itemID ) 點擊次數
FROM userbehaviour
WHERE behaviour = 'pv'
GROUP BY itemID
ORDER BY
點擊次數 DESC
LIMIT 10;
# 計算點擊量前10的商品的購買量
select * from
(SELECT itemID,count(behaviour) as 購買量
from userbehaviour
where behaviour = 'buy'
group by itemID ) as a
where itemID in (SELECT itemID FROM dianji);
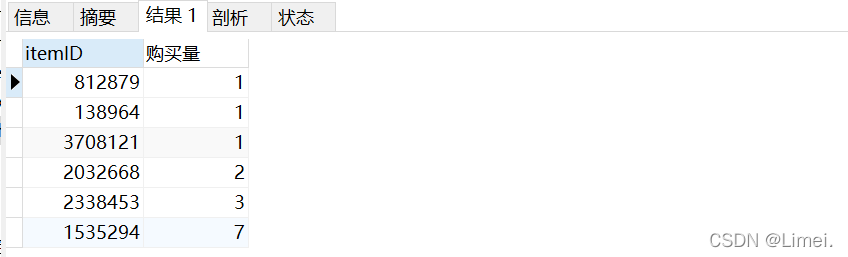
4.2 計算購買量前10的商品的點擊量
# 購買量前10的商品
CREATE VIEW goumai AS
SELECT itemID,count( itemID ) 購買次數
FROM userbehaviour
WHERE behaviour = 'buy'
GROUP BY itemID
ORDER BY
購買次數 DESC
LIMIT 10;
# 計算購買量前10的商品的點擊量
select * from
(SELECT itemID,count(behaviour) as 點擊量
from userbehaviour
where behaviour = 'pv'
group by itemID ) as a
where itemID in (SELECT itemID FROM goumai);
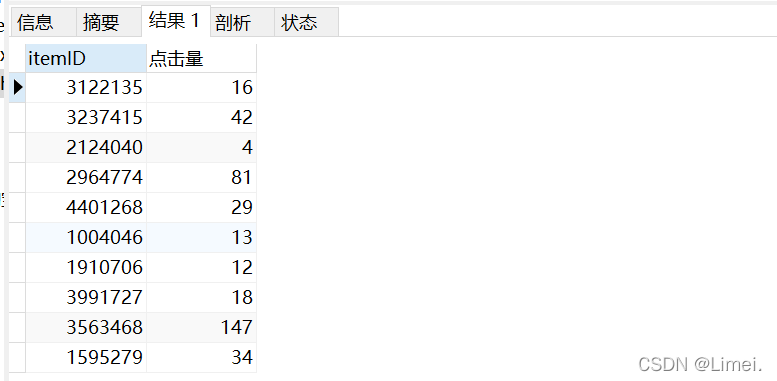
4.3 查看點擊量前10與購買量前100的商品ID 是否有重復值
# 查看點擊量前10與購買量前100的商品ID 是否有重復值
SELECT goumai.itemID
FROM goumai JOIN dianji ON goumai.itemID = dianji.itemID;

分析:
1、瀏覽量Top10的商品的購買量很少,有些甚至沒有,也就是說,平臺給與的流量顧客的點擊是高的,但是產品所產生的銷售沒有,由于電商業務是以銷售為導向的,所以這些商品并不適合沖量銷售,不應當給予過多的流量支持,
2、反觀購買量這邊,瀏覽量都是比較低的,并且和前面瀏覽量TOP10里沒有一個重復的商品ID,也就是說高瀏覽和高購買是兩類不同的商品,
4.4 結論
1、推薦的商品顧客并不喜歡購買,由于高瀏覽量并沒有帶來購買,所以轉化率低,
2、我們發現3122135、3237415、2124040這三類商品購買量比較高,在高需求量的基礎上我們考慮淘寶調整推送機制,增加對這幾類商品的推送,以滿足用戶需求,
4.5 對措
1.優化推薦機制,把更多流量給到顧客愿意購買的商品
2.通過更好的商品推薦,頁面互動,積分會員等功能等降低流失率
3.引導加購,可以加強營銷機制引導顧客加購,比如加購物車聯系客服領優惠券
3.3 用戶復購率和跳失率
1、復購率
# 復購率
SELECT SUM(case when buy_amount > 1 THEN 1 ELSE 0 END) '復購人數',
COUNT(userID) '已購人數',
SUM(case when buy_amount > 1 THEN 1 ELSE 0 END) / COUNT(userID) '復購率'
FROM
(SELECT userID,count(behaviour) buy_amount
FROM userbehaviour
WHERE behaviour = 'buy'
GROUP BY userID) as a;

復購率在0.6621,淘寶用戶粘性較高
2、跳失人數
# 跳失人數
SELECT count(*) '跳失人數'
FROM userbehaviour
GROUP BY userID
HAVING count(behaviour) = 1;

跳失人數為0,用戶對于淘寶的體驗普遍很好
3.4 用戶時間習慣
3.4.1 日期維度用戶行為習慣
# 用戶時間習慣
# 日期維度分析用戶行為
SELECT date,count(DISTINCT userID) '用戶數',
SUM(case when behaviour = 'pv' then 1 else 0 end) '瀏覽數',
SUM(case when behaviour = 'cart' then 1 else 0 end) '加購數',
SUM(case when behaviour = 'fav' then 1 else 0 end) '收藏數',
SUM(case when behaviour = 'buy' then 1 else 0 end) '成交數'
FROM userbehaviour
GROUP BY date
ORDER BY date;
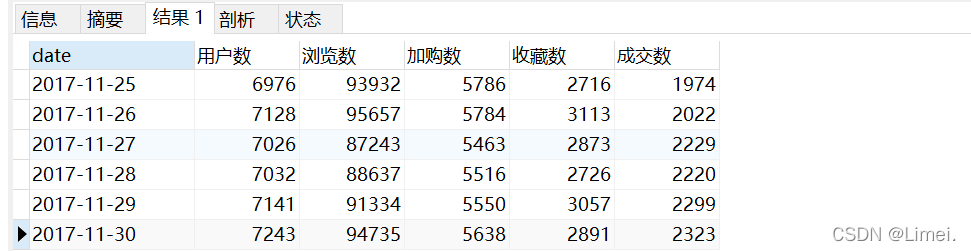
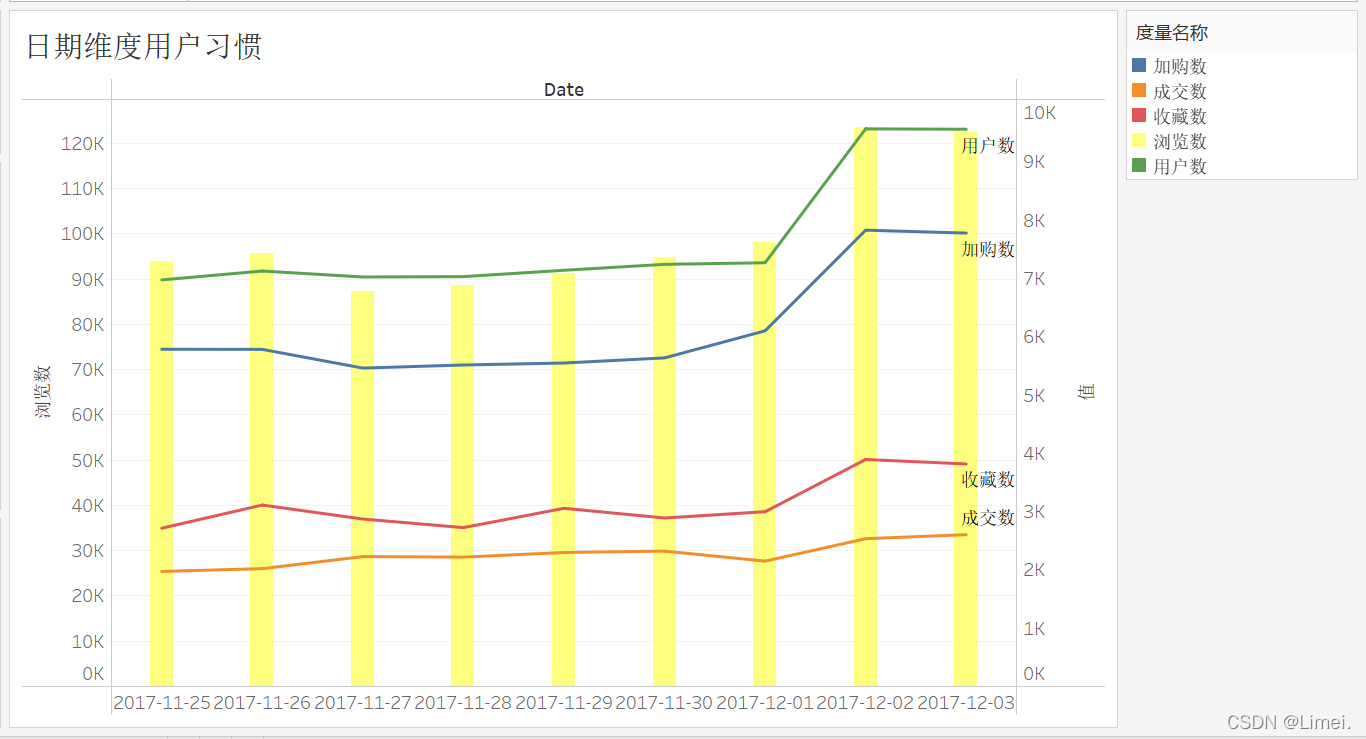
11月25日、11月26日和12月2日、12月3日分別都為周六、日,從圖中可以看出周末期間和作業日期間用戶活躍度沒有太大起伏,對于12月2日和12月3日的猜想:
雙12活動的預熱引起了用戶活躍度的上升
3.4.2 時間維度用戶行為習慣
提出假設: 用戶在一天中晚上休息時間點擊量會上升
# 時間維度分析用戶行為
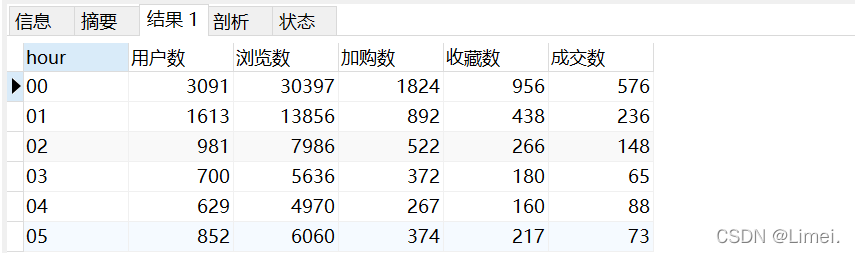
SELECT hour,count(DISTINCT userID) '用戶數',
SUM(case when behaviour = 'pv' then 1 else 0 end) '瀏覽數',
SUM(case when behaviour = 'cart' then 1 else 0 end) '加購數',
SUM(case when behaviour = 'fav' then 1 else 0 end) '收藏數',
SUM(case when behaviour = 'buy' then 1 else 0 end) '成交數'
FROM userbehaviour
GROUP BY hour
ORDER BY hour;
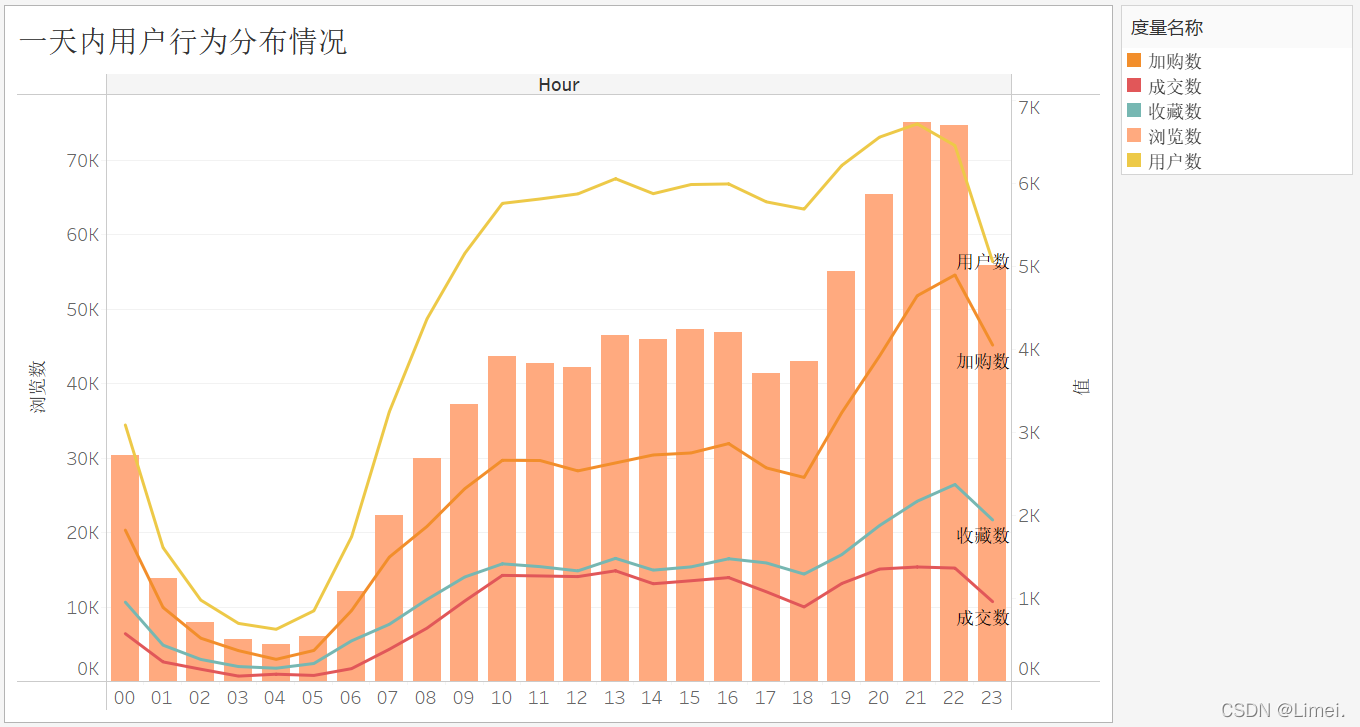
4時-10時 活躍度上升至穩定值
10時-19時 活躍度趨于穩定
19時-23時 活躍度上升至最高值(重點)
23時-次日4時 活躍度都呈下降趨勢直至最小值(注意點)
用戶的活躍度還是跟日常生活作息規律息息相關的
3.5 用戶商品偏好類別
# 用戶商品偏好類
# 瀏覽行TOP25
SELECT itemID '商品ID',count(behaviour) '瀏覽次數',ROW_NUMBER() over(ORDER BY count(behaviour) DESC) '排名'
from userbehaviour
WHERE behaviour = 'pv'
GROUP BY itemID
ORDER BY count(behaviour) DESC
LIMIT 25;
# 購買行TOP25
SELECT itemID '商品ID',count(behaviour) '瀏覽次數',ROW_NUMBER() over(ORDER BY count(behaviour) DESC) '排名'
from userbehaviour
WHERE behaviour = 'buy'
GROUP BY itemID
ORDER BY count(behaviour) DESC
LIMIT 25;
# 加購行TOP25
SELECT itemID '商品ID',count(behaviour) '瀏覽次數',ROW_NUMBER() over(ORDER BY count(behaviour) DESC) '排名'
from userbehaviour
WHERE behaviour = 'cart'
GROUP BY itemID
ORDER BY count(behaviour) DESC
LIMIT 25;
# 收藏行TOP25
SELECT itemID '商品ID',count(behaviour) '瀏覽次數',ROW_NUMBER() over(ORDER BY count(behaviour) DESC) '排名'
from userbehaviour
WHERE behaviour = 'fav'
GROUP BY itemID
ORDER BY count(behaviour) DESC
LIMIT 25;
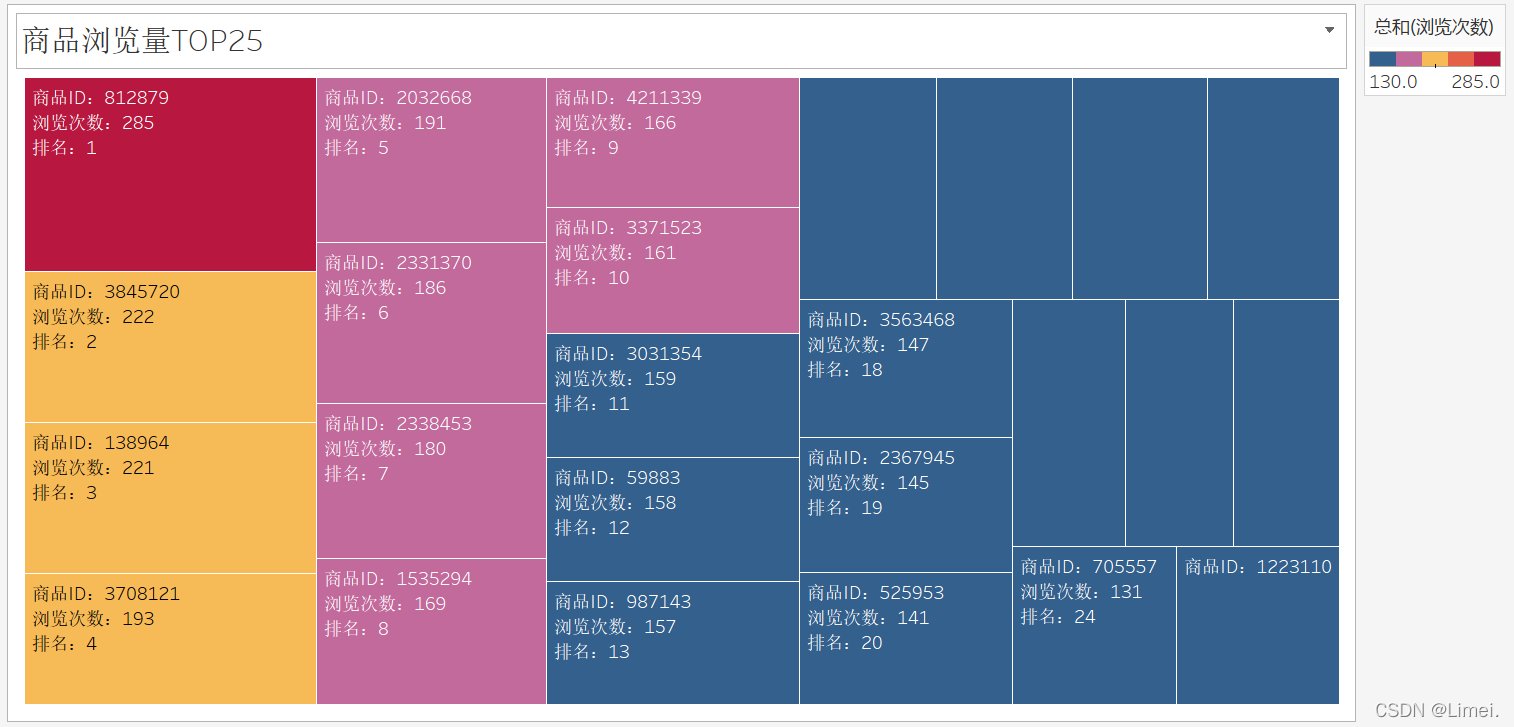
商品瀏覽TOP25

商品加購TOP25
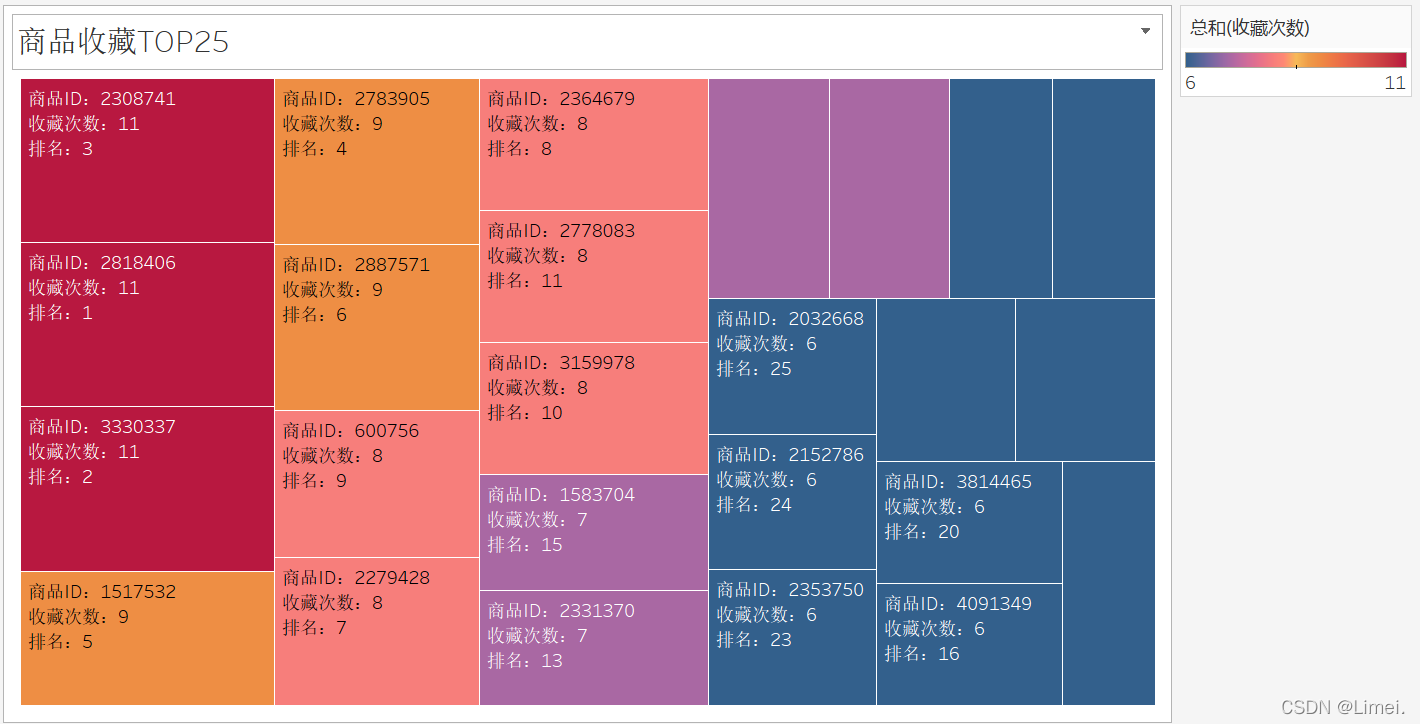
商品收藏TOP25
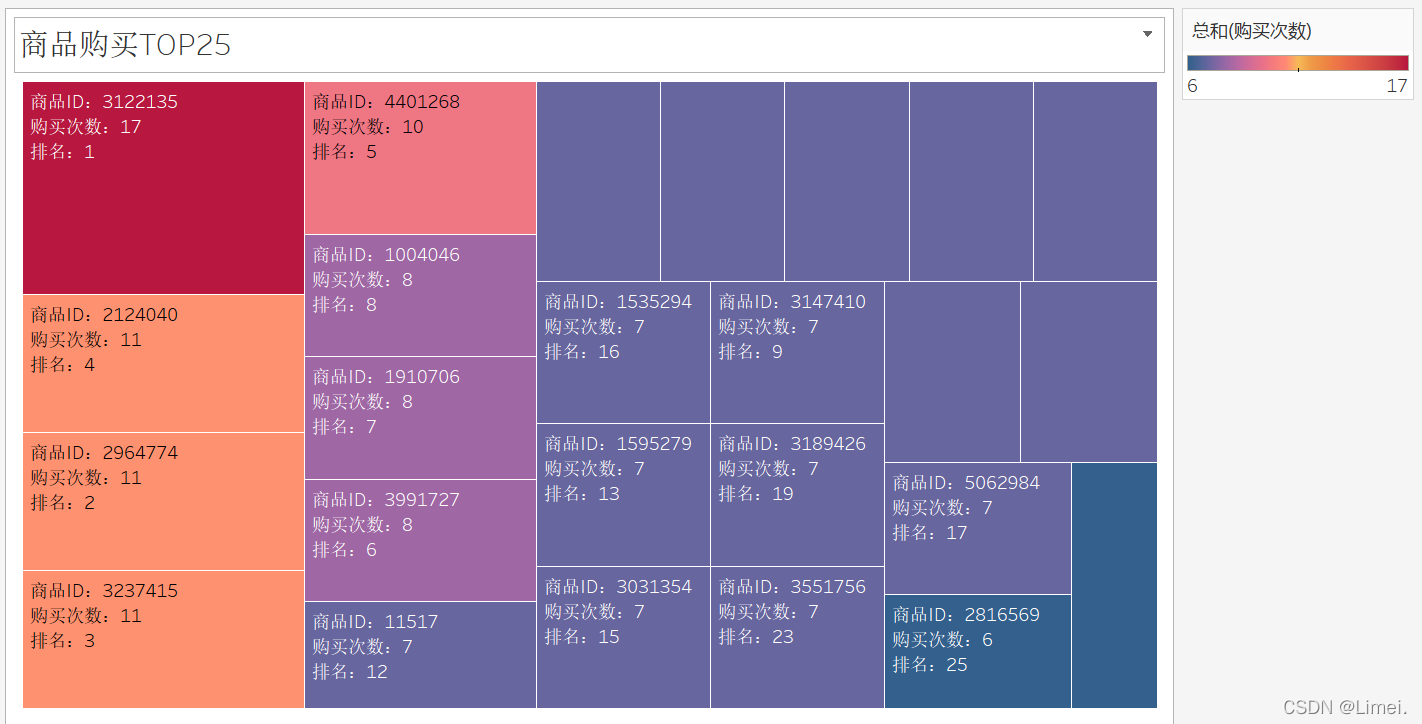
商品購買TOP25
3.6 用戶價值層度
RFM 模型介紹:RFM是3個指標的縮寫,最近一次消費時間間隔(Recency),消費頻率(Frequency),消費金額(Monetary),通過這3個指標對用戶分類,詳細介紹
由于源資料并沒有設計金額量的維度,所以此處無法對M維度進行具體分析,由此針對RF維度對用戶行為進行分析
3.6.1 R維度評分
# R 維度評分
# 創建R維度視圖
CREATE VIEW r_value AS
SELECT userID,min(gap) R
from (
SELECT userID,DATEDIFF('2017-12-04',date) gap
FROM userbehaviour
WHERE behaviour = 'buy'
) as a
GROUP BY userID;
# 進行R維度打分
SELECT userID '用戶ID',R '最近消費時間間隔',
(case when R BETWEEN 0 and 2 then 3
WHEN R BETWEEN 3 and 5 then 2
ELSE 1 END) as 'R維度評分'
FROM r_value;
DATEDIFF()函式的用法,戳這~
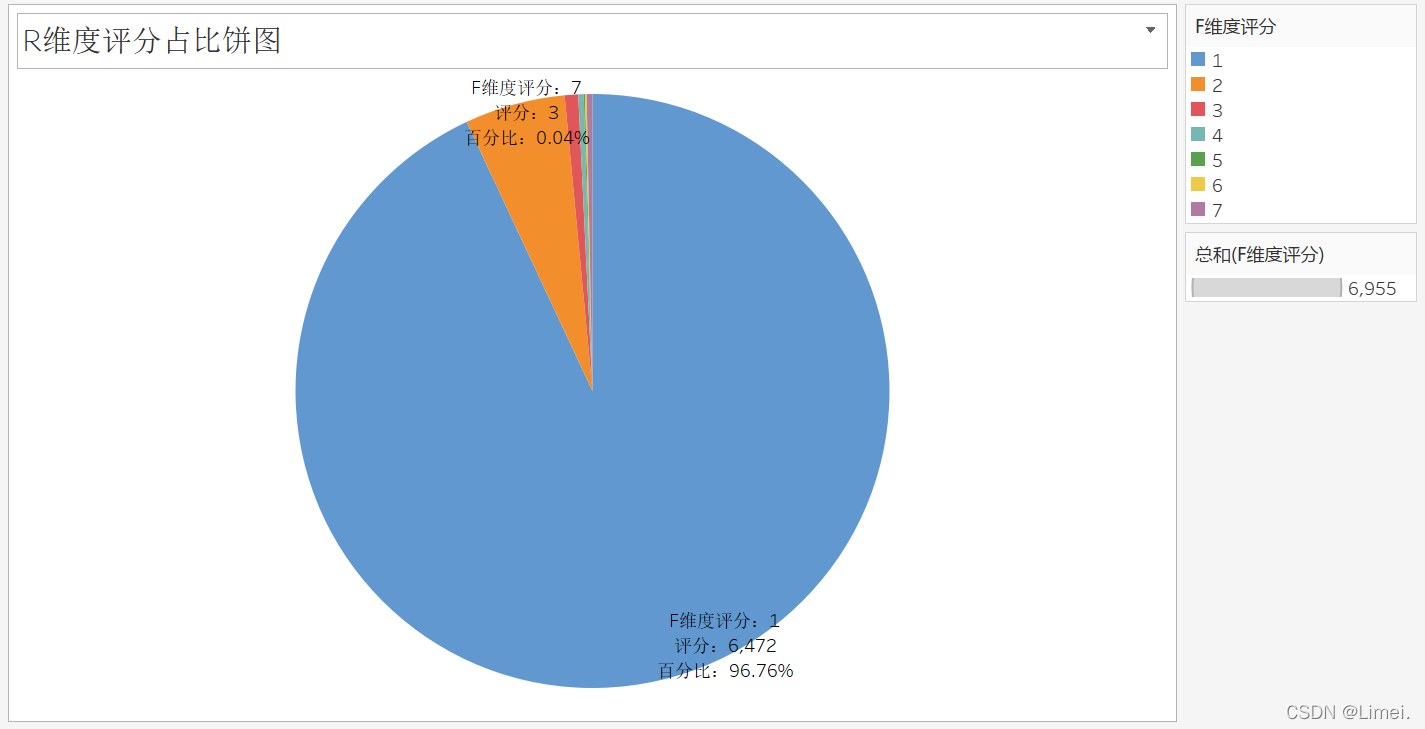
R維度評分占比餅圖:
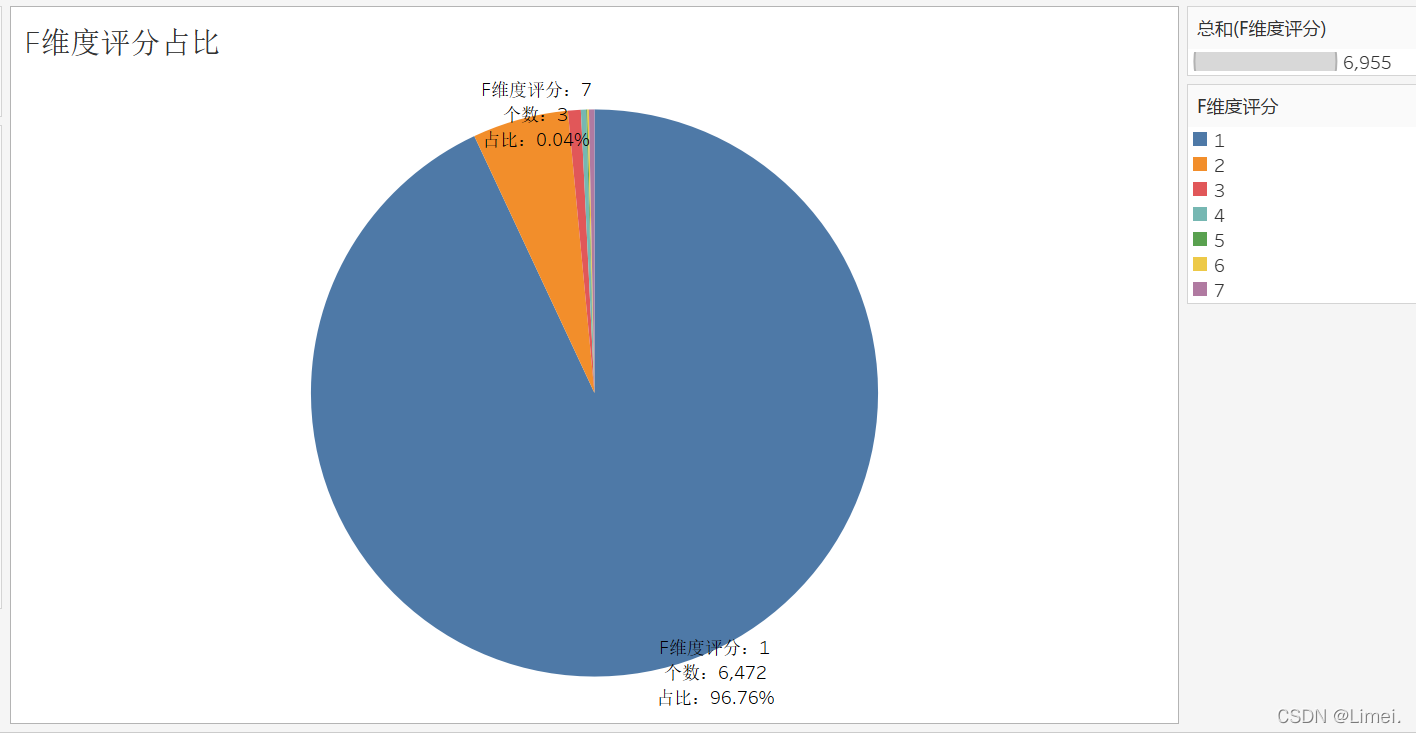
3.6.2 F維度評分
# F維度分析
# 創建F維度視圖
CREATE VIEW f_value AS
SELECT userID,count(behaviour) as F
FROM userbehaviour
WHERE behaviour = 'buy'
GROUP BY userID;
# 進行F維度打分
SELECT userID,F,(case when F BETWEEN 1 and 9 then 1
WHEN F BETWEEN 10 AND 19 THEN 2
WHEN F BETWEEN 20 AND 29 THEN 3
WHEN F BETWEEN 30 AND 39 THEN 4
WHEN F BETWEEN 40 AND 49 THEN 5
WHEN F BETWEEN 50 AND 59 THEN 6
ELSE 7 END) 'F維度評分'
FROM f_value;
F維度評分占比餅圖:
3.6.3 RF 維度綜合評分進行用戶價值分層
# RF綜合打分視圖
# 進行R維度打分
CREATE VIEW r_score AS
SELECT userID ,R ,
(case when R BETWEEN 0 and 2 then 3
WHEN R BETWEEN 3 and 5 then 2
ELSE 1 END) as R_Score
FROM r_value;
# 進行F維度打分
CREATE VIEW f_score AS
SELECT userID,F,(case when F BETWEEN 1 and 9 then 1
WHEN F BETWEEN 10 AND 19 THEN 2
WHEN F BETWEEN 20 AND 29 THEN 3
WHEN F BETWEEN 30 AND 39 THEN 4
WHEN F BETWEEN 40 AND 49 THEN 5
WHEN F BETWEEN 50 AND 59 THEN 6
ELSE 7 END) F_Score
FROM f_value;
# RF綜合打分
CREATE VIEW rf_score AS
SELECT a.userID '用戶ID',a.R_Score 'R維度評分',b.F_Score 'F維度評分', a.R_Score + b.F_Score 'RF維度綜合評分'
FROM r_score a JOIN f_score b ON a.userID = b.userID;
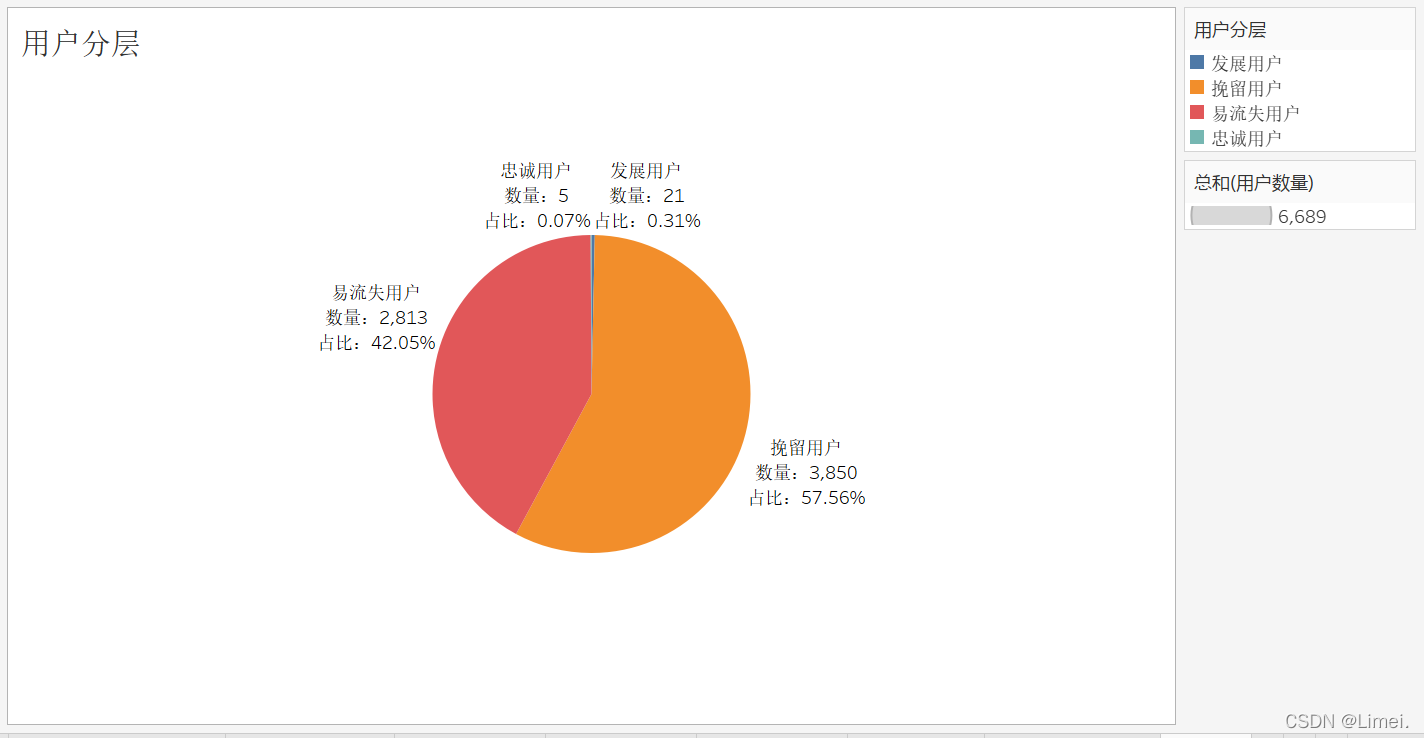
RF維度綜合用戶評分:
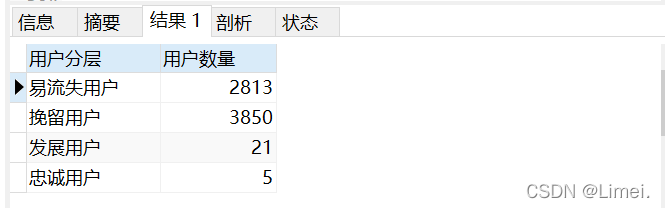
# RF維度綜合用戶評分
SELECT (CASE when RF維度綜合評分 BETWEEN 2 AND 3 then '易流失用戶'
when RF維度綜合評分 BETWEEN 4 AND 5 then '挽留用戶'
when RF維度綜合評分 BETWEEN 6 AND 7 then '發展用戶'
ELSE '忠誠用戶' END ) '用戶分層',count(*) '用戶數量'
FROM rf_score
GROUP BY 用戶分層;
分析:
1、將R維度評分+F維度評分=RF綜合評分的指標,
| 客戶分類 | 評分 |
|---|---|
| 易流失用戶 | 2-3分 |
| 挽留用戶 | 4-5分 |
| 發展用戶 | 6-7分 |
| 忠誠用戶 | 7分以上 |
2、大部分用戶集中在易流失用戶和挽留用戶上
對措:
| 客戶分類 | 表現 | 措施 |
|---|---|---|
| 易流失用戶 | 消費時間距離近,消費頻率低 | 提高消費頻率 |
| 挽留用戶 | 消費時間距離遠,消費頻率低 | 聯系用戶,調查挽回 |
| 發展用戶 | 消費時間距離遠,消費頻率高 | 郵箱推送,app提醒,促銷 |
| 忠誠用戶 | 消費時間距離近,消費頻率高 | 提高vip服務 |
4、結論及應對方法
結論:
1、 流量高的商品并不是購買量高的商品,高流量的商品購買量低導致了整體的流量轉化率低,也就是推薦展示的邏輯并沒有以銷售為導向,
2、從用戶行為路徑中發現,用戶瀏覽后直接購買的轉化率較低,而通過加購,收藏等行為后購買的轉化率會提升,故需要引導顧客積極加購或者收藏,且對比轉化率后發現加購物車所帶來的轉化是最好的,
3、用戶主要集中在易流失用戶和挽留用戶,兩者加總占用戶數的99.61%
建議:
1、建議演算法部門優先展示購買量TOP10的商品類給顧客,例如3122135、3237415、2124040等,如果說瀏覽量高的商品是新品或者近期主推的商品,是否可以考慮和TOP10購買的商品按照類目合理搭配銷售,提升轉化率和連帶率,
2、需積極引導顧客加購物車或者收藏寶貝,對于界面設計部門是考慮如何互動能夠讓顧客更愿意點擊,對于運營部門,可以設定機制引導,例如加購聯系客服送5元無門檻優惠券,加購送小樣贈品等的機制來引導,
3、淘寶的用戶搜尋商品的時間段主要在下午6點至晚上11點,也就是大多數人下班后休息的時間,建議運營部門在這個時間段多策劃一些營銷活動,提高轉換率,比如商家可以進行直播帶貨,
4、對于重要發展用戶,其消費頻率低,但最近消費距離現在時間較短,因此要想辦法提高他的消費頻率,通過CRM的紅包發放、會員權益獎勵、短信提醒優惠等方式提升消費頻率,
5、對于重要挽留用戶,最近消費時間距離現在較遠、消費頻率低,這種用戶有即將流失的危險,建議通過APP推送、短信和郵件等形式發放有償問卷主動聯系用戶,調查清楚哪里出了問題,制定相應的挽回策略,
參考博文:[1]https://blog.csdn.net/Kobe123brant/article/details/116863804
[2]https://blog.csdn.net/weixin_40244969/article/details/109908414
[3]https://zhuanlan.zhihu.com/p/121530969
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/439241.html
標籤:其他