D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. Vojnovic, “QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding,” Advances in Neural Information Processing Systems, vol. 30, 2017, Accessed: Jul. 31, 2021. [Online]. Available: https://proceedings.neurips.cc/paper/2017/hash/6c340f25839e6acdc73414517203f5f0-Abstract.html
作為量化SGD系列三部曲的第二篇,本篇文章是從單機學習到聯邦學習的一個重要過渡,在前人的基礎上重點進行了理論分析的完善,成為了量化領域繞不開的經典文獻,
簡介
相較于上一篇IBM的文章,本文考慮用梯度量化來改善并行SGD計算中的通信傳輸問題,并重點研究了通信帶寬和收斂時間的關系(precision-variance trade-off),具體而言,根據information-theoretic lower bounds,當調整每次迭代中傳輸的位元數時,梯度方差會發生改變,從而進行收斂性分析,實驗結果表明在用ResNet-152訓練ImageNet時能帶來1.8倍的速率提升,
觀點
- QSGD基于兩個演算法思想
- 保留原始統計性質的隨機量化(來源于量化SGD的實驗性質)
- 對量化后梯度的整數部分有損編碼(進一步降低位元數)
- 減少通信開銷往往會降低收斂速率,因此多訓練帶來的額外通信次數值不值,是神經網路量化傳輸需要考慮的重點
- 可以把量化看作一個零均值的噪聲,只是它碰巧能夠讓傳輸更加有效
- 卷積層比其他層更容易遭受量化帶來的性能下降,因此在量化方面,完成視覺任務的網路可能比深度回圈網路獲益更少
理論
-
方差對于SGD收斂性的影響
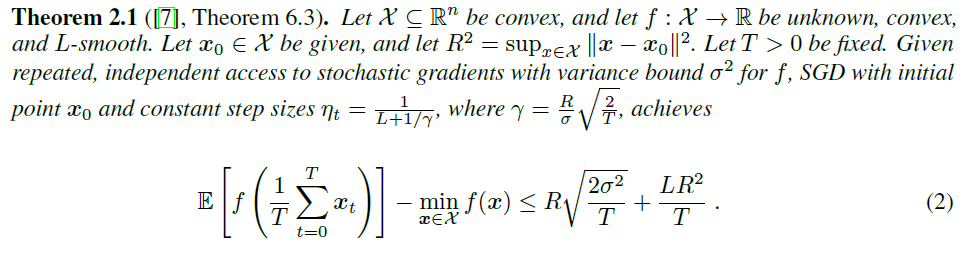
mini-batch操作可以看作是減少方差的一個方法,當第一項主導的時候,由于方差減少到了\(\sigma^2 /m\),因此收斂所需的迭代次數變為\(1/T\)
-
無損的parallel SGD就是一種mini batch,因此將??定理換一種寫法(其實就是寫成不等式右邊趨于零時),得到收斂所需迭代次數與方差的關系

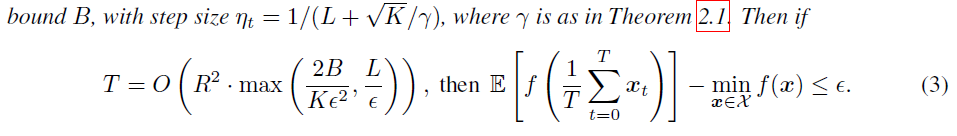
通常第一項會主導迭代次數,因此結論:收斂所需的迭代次數與隨機梯度的二階方差界\(B\)成線性關系
-
隨機量化與編碼
-
隨機量化
量化水平數量\(s\)(沒有包含0),量化水平在\([0,1]\)均勻分布,構造的目的為:1)preserves the value in expectation;2)introduce minimal variance,

- 對于向量中的每個分量單獨量化
- 進行\(|v_i|/\|v\|_2\)操作后能保證每個分量都落在\([0,1]\)區間內,從而轉化為\([0,1]\)上的量化
- 最終的上下取值概率之比就是量化點到上下量化水平的距離之比
好像和投影距離是等價的?
如此量化后有良好的統計特性(在這個量化值下有最小的方差)

-
編碼
Elias integer encoding,基本思想是大的整數出現的頻率會更低,因此回圈的編碼第一個非零元素的位置
將整數轉變為二進制序列,編碼后的長度為\(|\operatorname{Elias}(k)|=\log k+\log \log k+\ldots+1 \leq(1+o(1)) \log k+1\)
可得在給定量化方差界\(\left(\|v\|_{2}, \sigma, \zeta\right)\)后,需要傳輸的位元數上界為
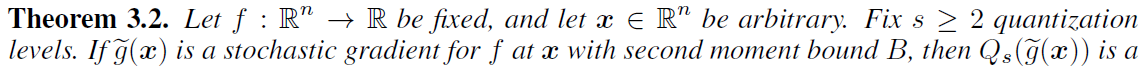
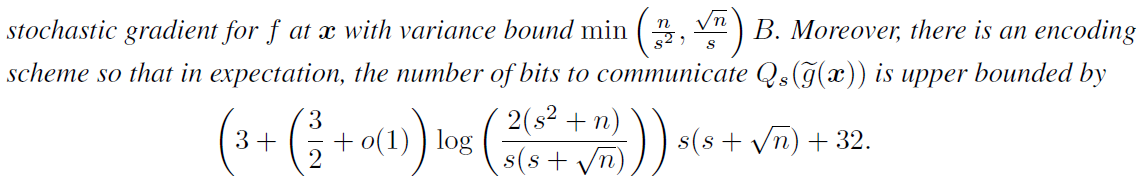
注:此時1bit傳輸作為\(s=1\)的稀疏特例
-
-
將??兩個定理合并后的結果如下,由于QSGD計算的是介面變數方差,因此可以很便利地結合到各種與方差相關的隨機梯度分析框架中,
-
Smooth convex QSGD
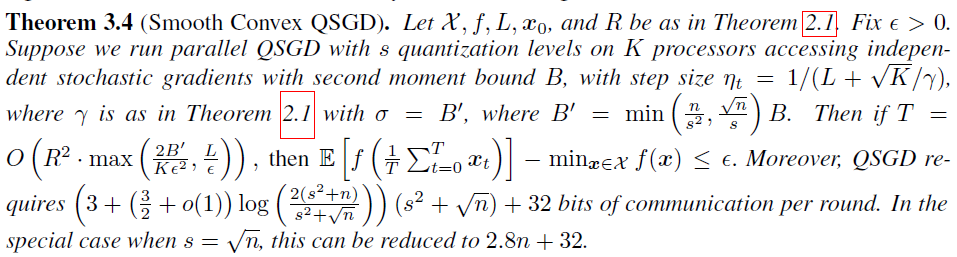
-
Smooth non-convex

-
-
QSGD在實際應用中的兩個變種
- 將一個向量進一步分為若干bucket來量化,顯然bucket size越大方差越大
- 在向量scaling的時候選用最大分量值而不是向量的二范數
實驗
-
全精度SGD傳\(32n\)位元,QSGD最少可以只傳\(2.8n+32\)位元,在兩倍迭代次數下,可以帶來節約\(5.7\)倍的帶寬
-
實驗結果
-
性能上幾乎超越了大模型
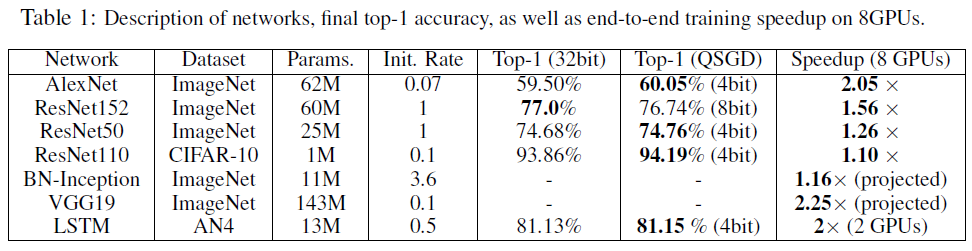
- 要用大模型才有量化的價值
We will not quantize small gradient matrices (< 10K elements), since the computational cost of quantizing them significantly exceeds the reduction in communication.
-
計算和通信的開銷
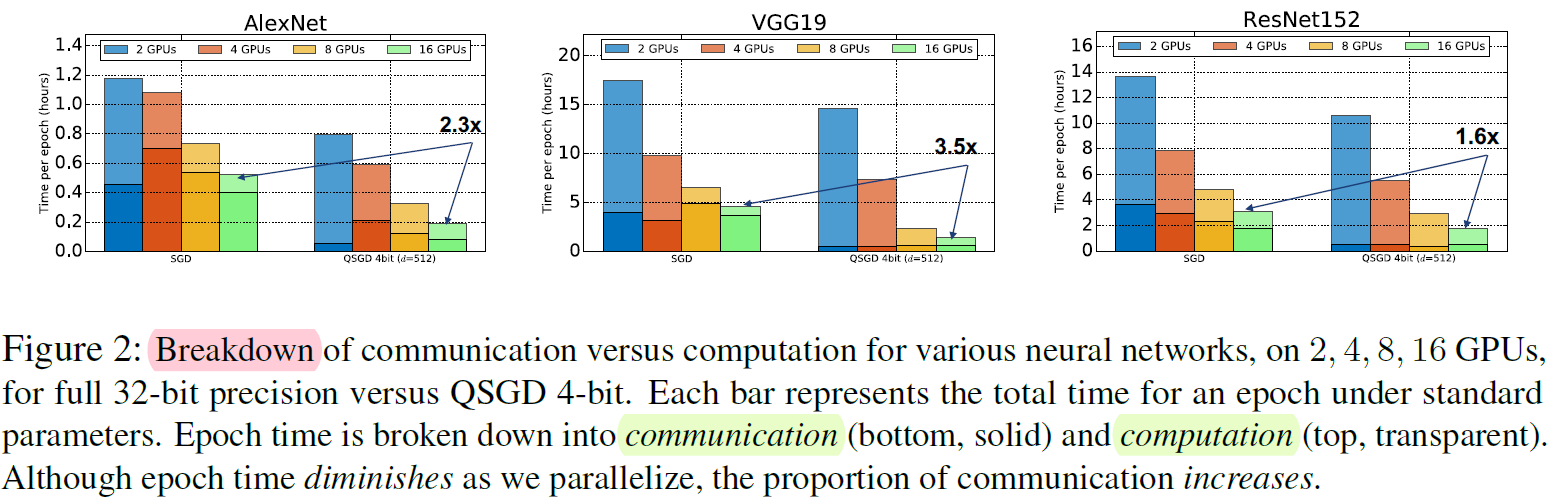
- 增加并行后主要耗時在通信上
-
-
實驗部分還沒有完全搞懂(比如protocol部分、GPU的并行)
借鑒
- 文章在QSGD的基礎上,從stochastic variance-reduced variant角度又繼續分析QSVRG,覆寫到了指數收斂速率,也就是通過添加新技術來說明原始方法的擴展性,
- 這篇文章的基礎是communication complexity lower bound of DME,因此建立傳輸位元數和方差的關系是直接拿過來的,而方差和收斂性的分析也是常用的,因此在承認DME的基礎上很容易得到tight bound,
- 這篇文章的寫作并不算優秀,但是內容十分solid和extensive,絕對是經典之作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/440414.html
標籤:其他