1. EM演算法的基本思想
我們在應用中所面對的資料有時是缺損的/觀測不完全的[1][2],我們將資料分為:
- 可觀測資料,用\(Y\)表示;
- 缺失資料,用\(Z\)表示;
- 完全資料,用\(X=(Y, Z)\)表示,
我們嘗試直接對可觀測資料做極大似然估計:
\[L(\theta | Y)=P(Y|\theta) \]但是這樣的似然函式可能非常復雜,我們發現完全資料的似然,即
\[L(\theta | Y, Z)=P(Y, Z|\theta) \]估計的難度要小得多,
除此之外對條件概率分布\(P(Z |Y, \theta)\)進行估計的難度也要小得多,
EM演算法的基本思想是通過\(P(Y,Z|\theta)\)和\(P(Z |Y, \theta)\)這兩個容易進行估計的分布來估計\(P(Y|\theta)\),
事實上,在應用中缺失資料\(Z\)常常并不是真實存在,而是人為造出來的(為了方便概率分布的估計),我們此時將缺失資料\(Z\)稱為隱含資料(latent data),
2. EM演算法框架與解釋
2.1 演算法框架
EM演算法不是單指一個演算法,而是指一種演算法設計思想,它是一類演算法的框架,它通過迭代求對數似然函式\(\text{log}L(\theta | Y)=\text{log}P(Y|\theta)\)的極大似然估計,每次迭代包含兩步:E步,求期望;M步,求極大化,下面是EM演算法的描述:

2.2 演算法推導
那為什么EM演算法的E步會求 \(\sum_Z \text{log} P(Y,Z|\theta)P(Z | Y, \theta^{(t)})\)這樣一個期望呢?
我們知道,可觀測資料\(Y\)是給定的,我們原本想對\(\text{log} P(Y |\theta)\)做極大似然估計,而我們可以進一步得到
\[\begin{aligned} \text{log} P(Y |\theta) &=\text{log}\sum_ZP(Y, Z|\theta)P(Z|\theta) \\ &= \text{log}\sum_Z \frac{P(Y, Z|\theta)}{q(Z)}q(Z)P(Z|\theta)\\ &\geqslant \sum_Z \text{log}[\frac{P(Y, Z|\theta)}{q(Z)}q(Z)] P(Z|\theta)(由\text{log}凹函式和\text{Jensen}不等式) \end{aligned} \]其中\(q(Z)\)為不等于0的關于\(Z\)的某個分布,不等式可以看做是一個找下界的程序,
在我們這個情境下設\(q(Z)=P(Z|Y,\theta^{(t)})\),就得到了下界為
\[\sum_Z \text{log}[\frac{P(Y, Z|\theta)P(Z|Y, \theta^{(t)})}{P(Z|Y, \theta^{(t)})}]P(Z|\theta) \]將\(\text{log}\)函式內的部分展開為
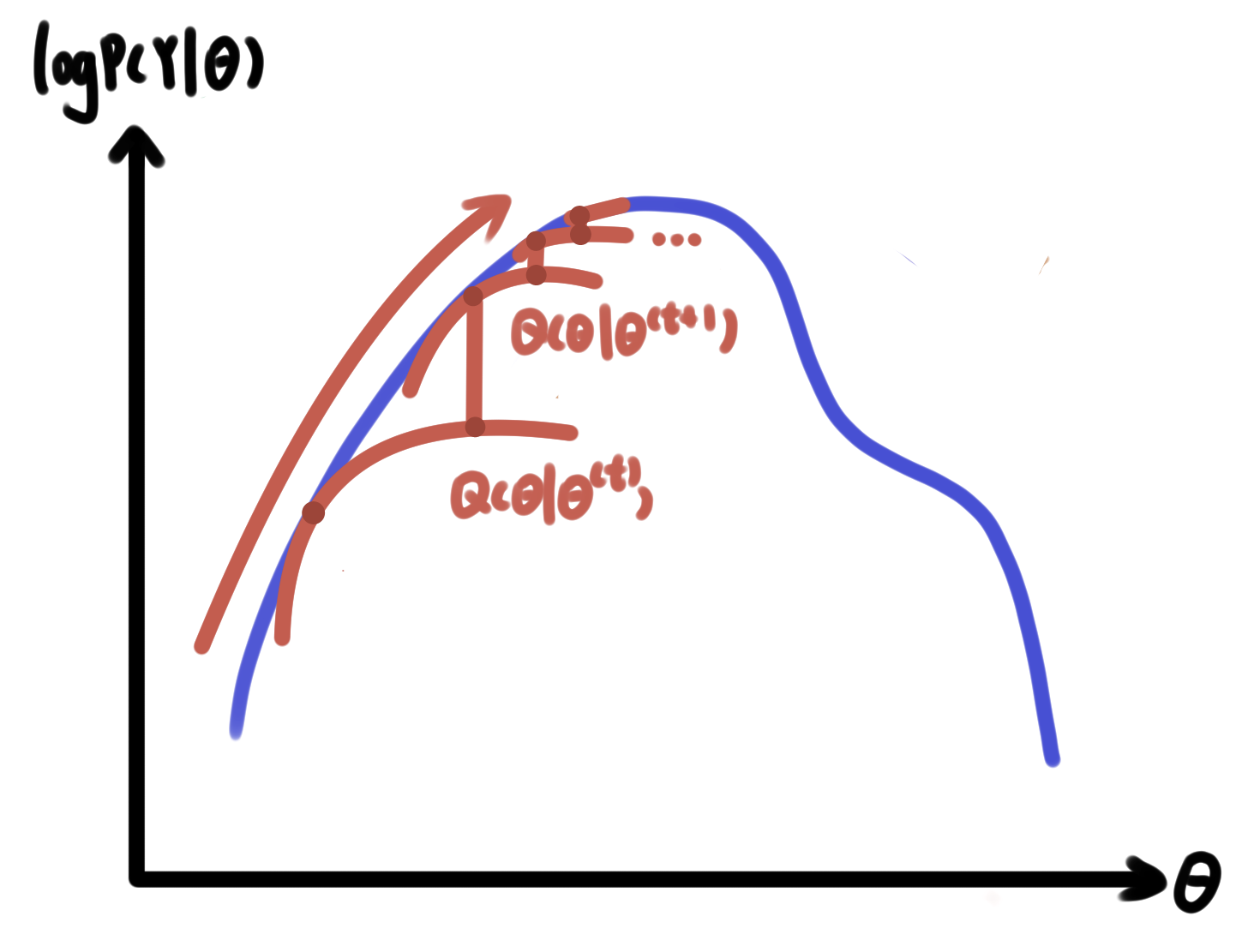
\[\sum_Z \left( \text{log}P(Y, Z|\theta)P(Z|Y, \theta^{(t))})-\text{log}P(Z|Y, \theta^{(t)}) \right) P(Z|\theta) \]而\(P(Z|Y, \theta^{(t)})\)相對于\(\theta\)是常數不用管,而前一項\(\sum_Z \text{log} P(Y,Z|\theta)P(Z | Y, \theta^{(t)})\)就是我們的\(Q\)函式,
因此我們可以說\(Q\)函式在每次迭代中去逼近\(\text{log} P(Y |\theta)\)的下界,多次迭代極大化\(Q\)函式就能起到極大化\(\text{log} P(Y |\theta)\)的效果,
EM演算法不斷逼近函式下界的程序可以形象化解釋為下圖:
3. EM演算法在高斯混合模型(GMM)中的應用
3.1 模型背景
在高斯混合聚類模型中,我們假設\(d\)維樣本空間中的觀測資料樣本點\(\bm{y}\)服從高斯混合分布[3][4]
\[p(\bm{y}|\bf{\Theta})= \sum_{k=1}^K\alpha_k \phi(\bm{y}|\bm{u}_k, \bf{\Sigma}_k) \]其中\(\phi(\bm{y}|\bm{u}_k, \bf{\Sigma}_k)\)為多元高斯分布
\[\phi(\bm{y}|\bm{u}_k, \bf{\Sigma}_k)= \frac{1}{(2\pi)^{\frac{d}{2}}|\bf{\Sigma}|^{\frac{1}{2}}}e^{-\frac{1}{2}(\bm{y}-\bm{u})^T\bf{\Sigma}^{-1}(\bm{y}-\bm{u})} \]且有\(\alpha_k > 0\),\(\sum_{k=1}^K\alpha_k=1\),
高斯混合分布可以形象化地由下圖表示:
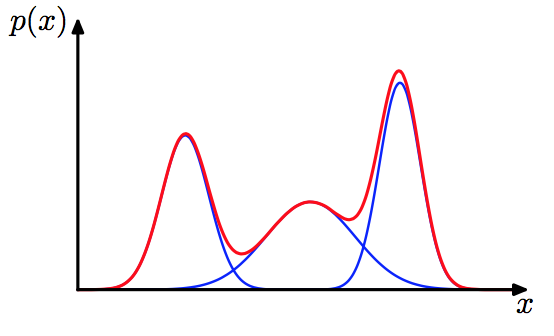
我們假設樣本的生成程序由高斯混合分布給出:首先,選擇高斯混合成分,其中\(\alpha_k\)為選擇第\(k\)個混合成分的概率;然后根據選擇的混合成分的概率密度函式進行采樣,從而生成相應的樣本,
3.2 高斯混合聚類演算法推導
我們令隨機變數\(C_i\in \{1,2,...,K\}\)表示樣本\(\bm{y}_i\)的高斯混合成分,而這個\(C_i\)也就對應了我們打算將樣本\(\bm{y}_i\)聚為第幾類,它的取值就是我們的聚類演算法要求的,我們的模型需要按照貝葉斯定理估計\(C_i\)的后驗分布
\[\begin{aligned} p(C_i=k | \bm{y}_i) & =\frac{p(C_i = k)p(\bm{y}_i|C_i = k) }{p(\bm{y}_i |\bf{\Theta})} \\ & = \frac{\alpha_k \phi(\bm{y}|\bm{u}_k, \bf{\Sigma}_k)}{\sum_{k=1}^K\alpha_k \phi(\bm{y}|\bm{u}_k, \bf{\Sigma}_k)} \end{aligned} \]則我們按照以下法則確定樣本\(\bm{y}_i\)被劃分為的簇標記\(c_i^*\):
\[ c_i^* = \underset{k\in\{1,2...,K\}}{\text{argmax}}p(C_i=k | \bm{y}_i) \]我們前面提到按照貝葉斯定理估計概率分布\(p(C_i=k | \bm{y}_i)\),但我們需要先確定資料生成分布\(p(\bm{y}_i |\bf{\Theta})\)中的引數\(\bf{\Theta} = \{(\alpha_k, \bm{u}_k, \bf{\Sigma}_k)|1\leqslant k \leqslant K\}\),這時就可以套用我們前面的EM演算法了,
我們設\(\bm{y}_i\)為可觀測資料,\(\bm{z}_{i}=(z_{i1}, z_{i2},..., z_{iK})^T\)(one-hot向量,表示樣本\(i\)的聚類結果)為未觀測資料,\(\bm{x}=(\bm{y_i}, \bm{z}_{i})\)為完全資料,
按照EM演算法的流程走:
(1) \(\text{E}\)步,即寫出\(Q\)函式
\[\begin{aligned} Q(\bf{\Theta}|\bf{\Theta}^{(t)}) & =\mathbb{E}_\bm{z}[\text{log} \space p(\bm{y},\bm{z}|\bf{\Theta})|\bm{y}, \bf{\Theta}^{(t)}] \end{aligned} \]我么需要先寫出完全資料的對數似然函式:
\[\begin{aligned} \text{log}\space p(\bm{y},\bm{z}|\bf{\Theta}) & = \text{log} \prod_{i=1}^N p(\bm{y}_i, \bm{z}_i | \bf{\Theta}) \\ &= \text{log} \prod_{k=1}^K\prod_{i=1}^N[\alpha_k \phi(\bm{y}_i|\bm{\mu}_k, \bf{\Sigma}_k)]^{z_{ik}} \\ &= \text{log} \left(\prod_k^K \alpha_k^{n_k} \prod_{i=1}^N \phi(\bm{y}_i|\bm{\mu}_k, \bf{\Sigma}_k)^{z_{ik}} \right) \\ & = \sum_{k=1}^K \left(n_k\text{log}\alpha_k + \sum_{i=1}^Nz_{ik} \text{log} \phi(\bm{y}_i|\bm{\mu}_k, \bf{\Sigma}_k)\right) \end{aligned} \]然后按照Q函式的定義求條件期望得:
\[\begin{aligned} Q(\bf{\Theta}|\bf{\Theta}^{(t)}) & =\mathbb{E}_\bm{z}\left[\sum_{k=1}^K \left( n_k\text{log}\alpha_k + \sum_{i=1}^Nz_{ik} \text{log} \phi(\bm{y}_i|\bm{\mu}_k, \bf{\Sigma}_k)\right)|\bm{y}, \bf{\Theta}^{(t)}\right] \\ & = \sum_{k=1}^K \left( \sum_{i=1}^N\mathbb{E}(z_{ik}|\bm{y}, \bf{\Theta}^{(t)})\text{log}\alpha_k + \sum_{i=1}^N\mathbb{E}(z_{ik}|\bm{y}, \bf{\Theta}^{(t)})\text{log}\phi(\bm{y}_i|\bm{\mu}_k, \bf{\Sigma}_k)\right) \end{aligned} \]這里\(\mathbb{E}(z_{ik}|\bm{y}, \bf{\Theta}^{(t)})\)就等于我們前面用貝葉斯定理求的 \(p(C_i=k | \bm{y}_i)\),我們將其簡寫為\(\hat{z}_{ik}\),進一步將\(Q\)
函式寫為:
(2) \(\text{M}\)步,求極大化\(Q\)函式的新一輪迭代引數
我們只需將上式分別對\(\bm{\mu}_k\)、\(\bf{\Sigma_k}\), \(\alpha_k\)(滿足\(\sum_{k=1}^K\alpha_k = 1\))求偏導并令其等于0,可得到:
\[\begin{aligned} \bm{\mu}_k^{(t+1)} &=\frac{\sum_{i=1}^N\hat{z}_{ik}\bm{y}_i}{\sum_{i=1}^N\hat{z}_{ik}} \\ \bf{\Sigma}_k^{(t+1)} &=\frac{\sum_{i=1}^N\hat{z}_{ik}(\bm{y}_i - \bm{\mu}_k)(\bm{y}_i - \bm{\mu}_k)^T}{\sum_{i=1}^N\hat{z}_{ik}} \\ \alpha^{(t+1)}_k &= \frac{\sum_{i=1}^N\hat{z}_{ik}}{N} \end{aligned} \]3.3 高斯混合聚類演算法描述
演算法描述如下所示:

參考
- [1] 李航. 統計學習方法(第2版)[M]. 清華大學出版社, 2019.
- [2] 周志華. 機器學習[M]. 清華大學出版社, 2016.
- [3] Calder K. Statistical inference[J]. New York: Holt, 1953.
- [4] 張志華《統計機器學習》在線視頻36-EM演算法1: https://www.bilibili.com/video/BV1rW411N7tD?p=36
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/440415.html
標籤:其他
上一篇:【論文考古】量化SGD QSGD: Communication-Efficient SGD via Gradient Quantization and Encoding
下一篇:【面經】Java面試問答題