作者:拂衣
什么是性能壓測可觀測
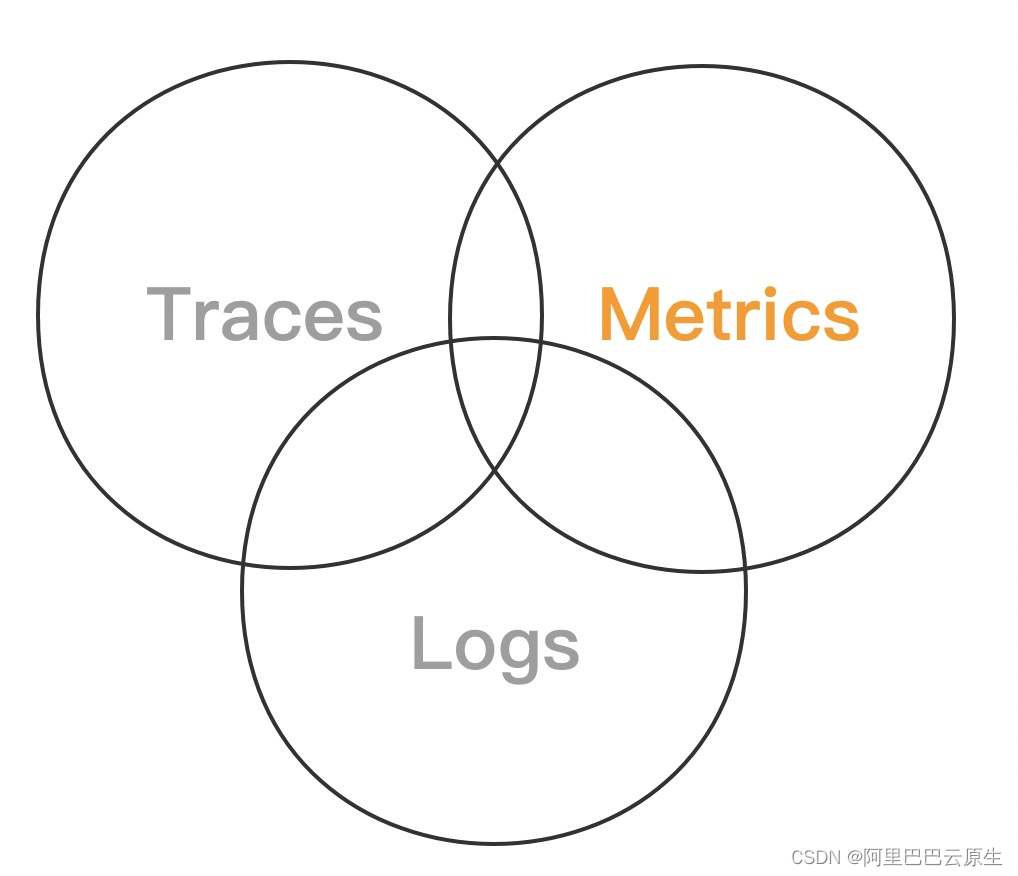
可觀測性包括 Metrics、Traces、Logs3 個維度,可觀測能力幫助我們在復雜的分布式系統中快速排查、定位問題,是分布式系統中必不可少的運維工具,
在性能壓測領域中,可觀測能力更為重要,除了有助于定位性能問題,其中Metrics性能指標更直接決定了壓測是否通過,對系統上線有決定性左右,具體如下:
? Metrics,監控指標
系統性能指標,包括請求成功率、系統吞吐量、回應時長
資源性能指標,衡量系統軟硬體資源使用情況,配合系統性能指標,觀察系統資源水位
? Logs,日志
施壓引擎日志,觀察施壓引擎是否健康,壓測腳本執行是否有報錯
采樣日志,采樣記錄 API 的請求和回應詳情,輔助排查壓測程序中的一些出錯請求的引數是否正常,并通過回應詳情,查看完整的錯誤資訊
? Traces,分布式鏈路追蹤用于性能問題診斷階段,通過追蹤請求在系統中的呼叫鏈路,
定位報錯 API 的報錯系統和報錯堆疊,快速定位性能問題點
本篇闡述如何使用 Prometheus 實作性能壓測 Metrics 的可觀測性,
壓測監控的核心指標
系統性能指標
壓測監控最重要的 3 個指標:請求成功率、服務吞吐量(TPS)、請求回應時長(RT),這 3 個指標任意一個出現拐點,都可以認為系統已達到性能瓶頸,
這里特別說明下回應時長,對于這個指標,用平均值來判斷很有誤導性,因為一個系統的回應時長并不是平均分布的,往往會出現長尾現象,表現為一部分用戶請求的回應時間特別長,但整體平均回應時間符合預期,這樣其實是影響了一部分用戶的體驗,不應該判斷為測驗通過,因此對于回應時長,常用 99、95、90 分位值來判斷系統回應時長是否達標,
另外,如果需要觀察請求回應時長的分布細節,可以補充請求建聯時長(Connect Time)、等待回應時長(Idle Time)等指標,
資源性能指標
壓測程序中,對系統硬體、中間件、資料庫資源的監控也很重要,包括但不限于:
? CPU 使用率
? 記憶體使用率
? 磁盤吞吐量
? 網路吞吐量
? 資料庫連接數
? 快取命中率
... ...
詳細可見《測驗指標》[1]一文,
施壓機性能指標
壓測鏈路中,施壓機性能是容易被忽略的一環,為了保證施壓機不是整個壓測鏈路的性能瓶頸,需要關注如下施壓機性能指標:
? 壓測行程的記憶體使用量
? 施壓機 CPU 使用率,Load1、Load5 負載指標
? 基于 JVM 的壓測引擎,需要關注垃圾回收次數、垃圾回收時長
為什么用 Prometheus 做壓測監控
開源壓測工具如 JMeter 本身支持簡單的系統性能監控指標,如:請求成功率、系統吞吐量、回應時長等,但是對于大規模分布式壓測來說,開源壓測工具的原生監控有如下不足:
-
監控指標不夠全面,一般只包含了基礎的系統性能指標,只能用于判斷壓測是否通過,但是如果壓測不通過,需要排查、定位問題時,如分析一個 API 的 99 分位建聯時長,原生監控指標就無法實作,
-
聚合時效性不能保證
-
無法支持大規模分布式的監控資料聚合
-
監控指標不支持按時間軸回溯
綜上,在大規模分布式壓測中,不推薦使用開源壓測工具的原生監控,
下面對比 2 種開源的監控方案:
方案一:Zabbix
Zabbix 是早期開源的分布式監控系統,支持 MySQL 或 PostgreSQL 關系型資料庫作為資料源,
對于系統性能監控,需要施壓機提供秒級的監控指標,每秒高并發的監控指標寫入,使關系型資料庫成為了監控系統的瓶頸,
對于資源性能監控,Zabbix 對物理機、虛擬機的指標很全面,但是對容器、彈性計算的監控支持還不夠,
方案二:Prometheus
Prometheus 使用時序資料庫作為資料源,相比傳統關系型資料庫,讀寫性能大大提高,對于施壓機大量的秒級監控資料上報的場景,性能表現良好,
對于資源性能監控,Prometheus 更適用于云資源的監控,尤其對 Kubernates 和容器的監控非常全面,對使用云原生技術的用戶,上手更簡單,
總結下來,Prometheus 相較 Zabbix,更適合于壓測中高并發監控指標的采集和聚合,并且更適用于云資源的監控,且易于擴展,
當然,使用成熟的云產品也是一個很好選擇,如壓測工具 PTS[2]+可觀測工具 ARMS[3],就是一組黃金搭檔,PTS 提供壓測時的系統性能指標,ARMS 提供資源監控和整體可觀測的能力,一站式解決壓測可觀測的問題,
怎么使用 Prometheus 實作壓測監控
開源 JMeter 改造
Prometheus 是拉資料模型,因此需要壓測引擎暴露 HTTP 服務,供 Prometheus 獲取各壓測指標,
JMeter 提供了插件機制,可以自定義插件來擴展 Prometheus 監控能力,在自定插件中,需要擴展 JMeter 的 BackendListener,讓在采樣器執行完成時,更新每個壓測指標,如成功請求數、失敗請求數、請求回應時長,并將各壓測指標在記憶體中保存,在 Prometheus 拉資料時,通過 HTTP 服務暴露出去,整體結構如下:
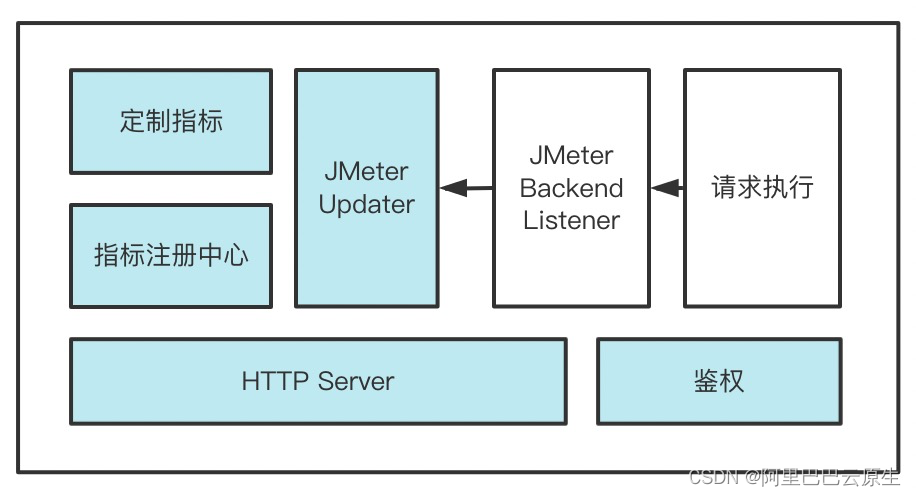
JMeter 自定義插件需要改造的點:
-
增加指標注冊中心
-
擴展 Prometheus 指標更新器
-
實作自定義 JMeter BackendListener,在采樣器執行結束后,呼叫 Prometheus 更新器
-
實作 HTTP Server,如果有安全需要,補充鑒權邏輯
PTS 壓測工具
性能測驗 PTS(Performance Testing Service)是一款阿里云 SaaS 化的性能測驗工具,PTS支持自研壓測引擎,同時支持開源 JMeter 壓測,在 PTS 上開放壓測指標到 Prometheus,無需開發自定義插件來改造引擎,只需 3 步白屏化操作即可,
具體步驟如下:
-
PTS 壓測的高級設定中,打開【Prometheus】開關
-
壓測開始后,在【監控匯出】一鍵復制 Prometheus 配置
-
自建的 Prometheus 中粘貼并熱加載此配置,即可生效
詳細參考:《如何將 PTS 壓測的指標資料輸出到 Prometheus》[4]
快速搭建 Grafana 監控大盤
PTS 提供了官方 Grafana 大盤模板[5],支持一鍵匯入監控大盤,并可以靈活編輯和擴展,滿足您的定制監控需求,
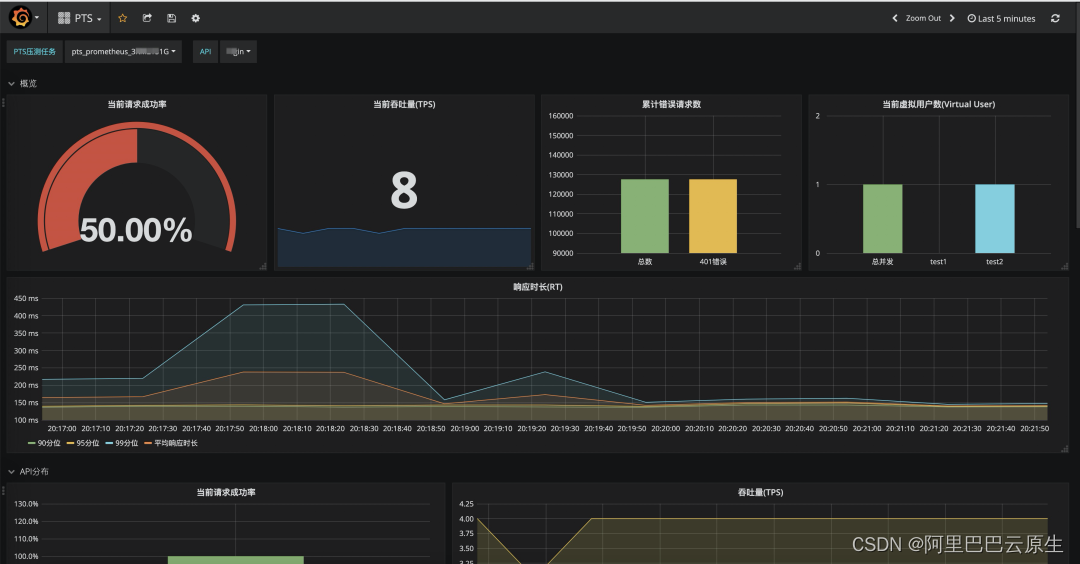
本大盤提供了全域請求成功率,系統吞吐量(TPS),99、95、90 分位回應時長,以及按錯誤狀態碼聚合的錯誤請求數等資料,
在 API 分布專欄中,可以直觀的對比各 API 的監控指標,快速定位性能短板 API,
在 API 詳情專欄中,可以查看單個 API 的詳細指標,準確定位性能瓶頸,
另外,大盤還提供了施壓機的JVM垃圾回收監控指標,可以輔助判斷施壓機是否是壓測鏈路中的性能瓶頸,
匯入步驟如下:
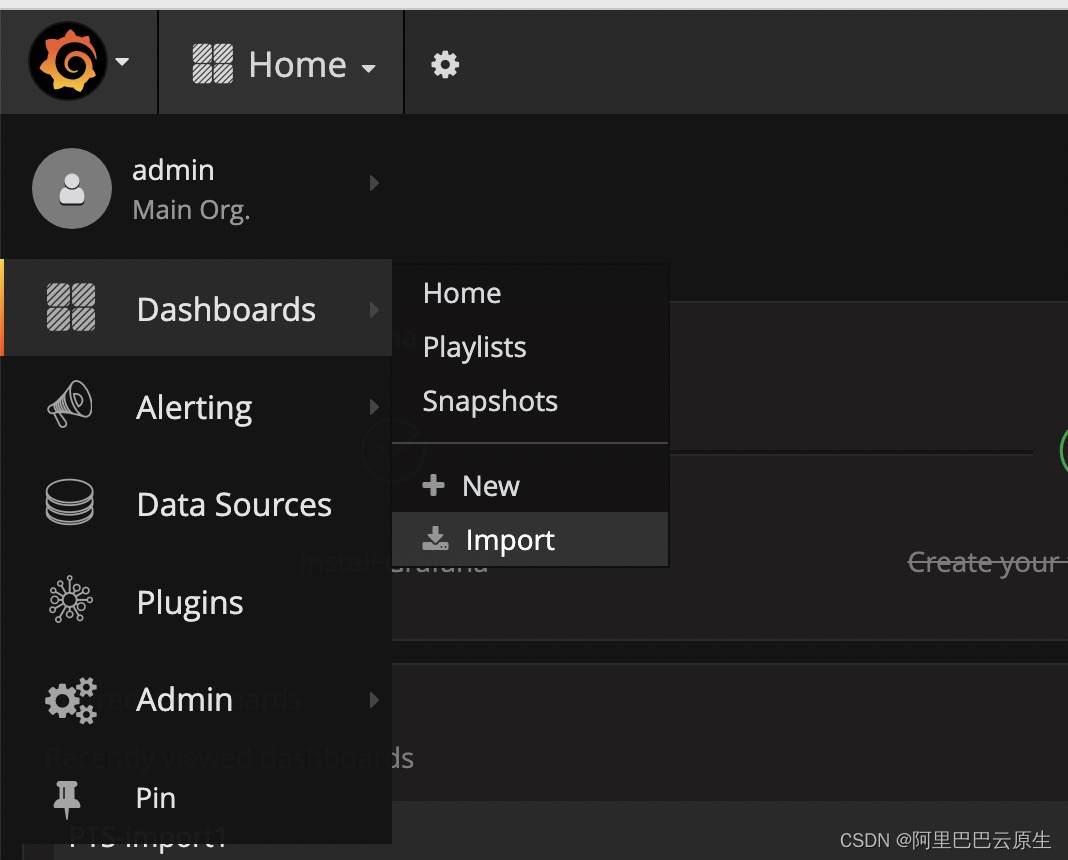
步驟一
在選單欄,點擊 Dashboard 下的 import:
步驟二
填寫 PTS Dashboard 的 id:15981
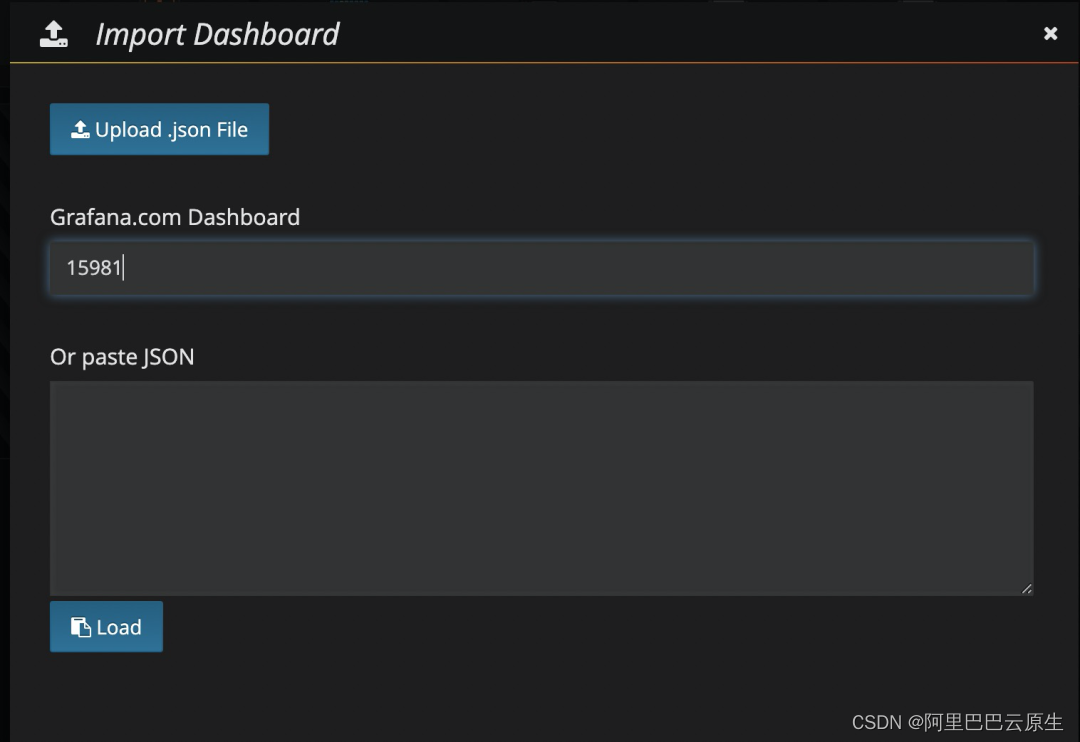
在 Prometheus 選擇您已有的資料源,本示例中資料源名為 Prometheus,選中后,單擊 Import 匯入
步驟三
匯入后,在左上角【PTS 壓測任務】,選擇需要監控的壓測任務,即可看到當前監控大盤,
此任務名對應 PTS 控制臺在監控匯出-Prometheus 配置中的 jobname,
總結
本文闡述了
-
什么是性能測驗可觀測
-
為什么用 Prometheus 做壓測性能指標監控
-
如何使用開源 JMeter 和云上 PTS 實作基于 Prometheus 的壓測監控
PTS 壓測監控匯出 Prometheus 功能,目前免費公測中,歡迎使用,
同時,PTS 全新售賣方式來襲,基礎版價格直降 50%!百萬并發價格只需 6200!更有新用戶 0.99 體驗版、VPC 壓測專屬版,歡迎大家選購!

相關鏈接
[1] 測驗指標
https://help.aliyun.com/document_detail/29338.html
[2] 壓測工具 PTS
https://www.aliyun.com/product/pts
[3] 可觀測工具 ARMS
https://www.aliyun.com/product/arms
[4] 如何將 PTS 壓測的指標資料輸出到 Prometheus
https://help.aliyun.com/document_detail/416784.html
[5]官方 Grafana 大盤模板
https://grafana.com/grafana/dashboards/15981
發布云原生技術最新資訊、匯集云原生技術最全內容,定期舉辦云原生活動、直播,阿里產品及用戶最佳實踐發布,與你并肩探索云原生技術點滴,分享你需要的云原生內容,
關注【阿里巴巴云原生】公眾號,獲取更多云原生實時資訊!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/455602.html
標籤:其他
上一篇:靜態鏈路聚合方案
下一篇:什么是機器學習的特征工程?【資料集特征抽取(字典,文本TF-Idf)、特征預處理(標準化,歸一化)、特征降維(低方差,相關系數,PCA)】