1 、線性回歸
1.1 線性回歸應用場景
- 房價預測
- 銷售額度預測
- 金融:貸款額度預測、利用線性回歸以及系數分析因子
1.2 什么是線性回歸
1.2.1定義與公式
線性回歸(Linear regression)是利用回歸方程(函式)對一個或多個自變數(特征值)和因變數(目標值)之間關系進行建模的一種分析方式,
- 特點:只有一個自變數的情況稱為單變數回歸,大于一個自變數情況的叫做多元回歸
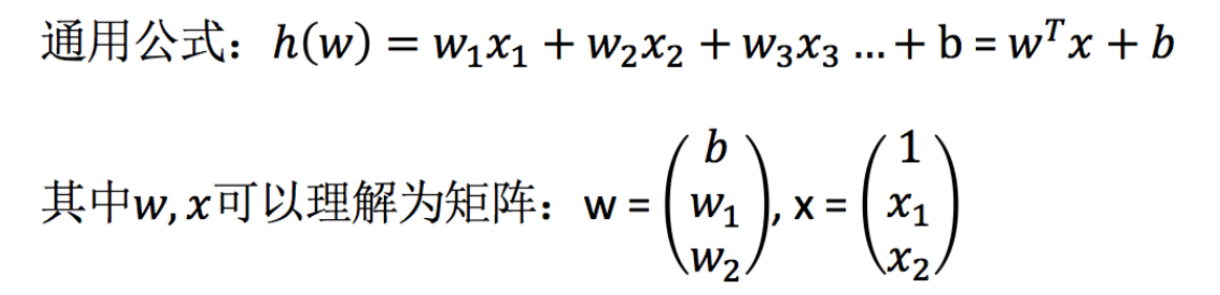
那么怎么理解呢?我們來看幾個例子
- 期末成績:0.7×考試成績+0.3×平時成績
- 房子價格 = 0.02×中心區域的距離 + 0.04×城市一訊訓氮濃度 + (-0.12×自住房平均房價) + 0.254×城鎮犯罪率
上面兩個例子,我們看到特征值與目標值之間建立的一個關系,這個可以理解為回歸方程,
1.3 線性回歸的損失和優化原理
假設剛才的房子例子,真實的資料之間存在這樣的關系
真實關系:真實房子價格 = 0.02×中心區域的距離 + 0.04×城市一訊訓氮濃度 + (-0.12×自住房平均房價) + 0.254×城鎮犯罪率
那么現在呢,我們隨意指定一個關系(猜測)
隨機指定關系:預測房子價格 = 0.25×中心區域的距離 + 0.14×城市一訊訓氮濃度 + 0.42×自住房平均房價 + 0.34×城鎮犯罪率
這兩個關系肯定是存在誤差的,那么我們怎么表示這個誤差并且衡量優化呢?
1.3.1 損失函式
最小二乘法
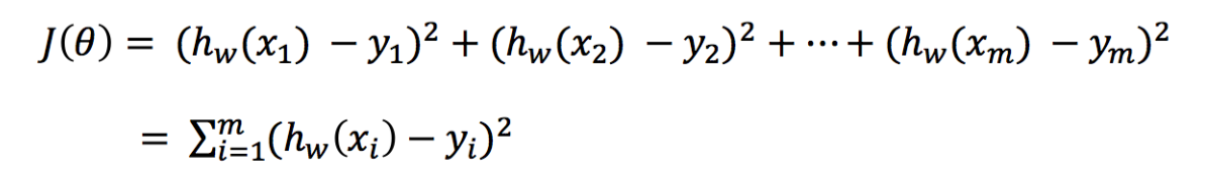
- y_i為第i個訓練樣本的真實值
- h(x_i)為第i個訓練樣本特征值組合預測函式
如何去減少這個損失,使我們預測的更加準確些?既然存在了這個損失,我們一直說機器學習有自動學習的功能,在線性回歸這里更是能夠體現,這里可以通過一些優化方法去優化(其實是數學當中的求導功能)回歸的總損失!!!
1.3.2 優化演算法---正規方程
如何去求模型當中的W,使得損失最小?(目的是找到最小損失對應的W值)
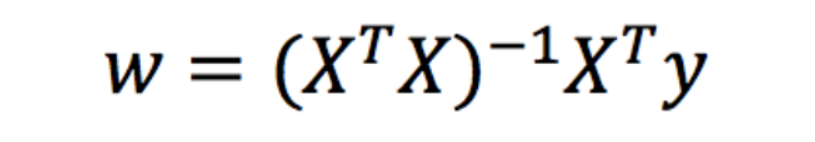
理解:X為特征值矩陣,y為目標值矩陣,直接求到最好的結果
缺點:當特征過多過復雜時,求解速度太慢并且得不到結果
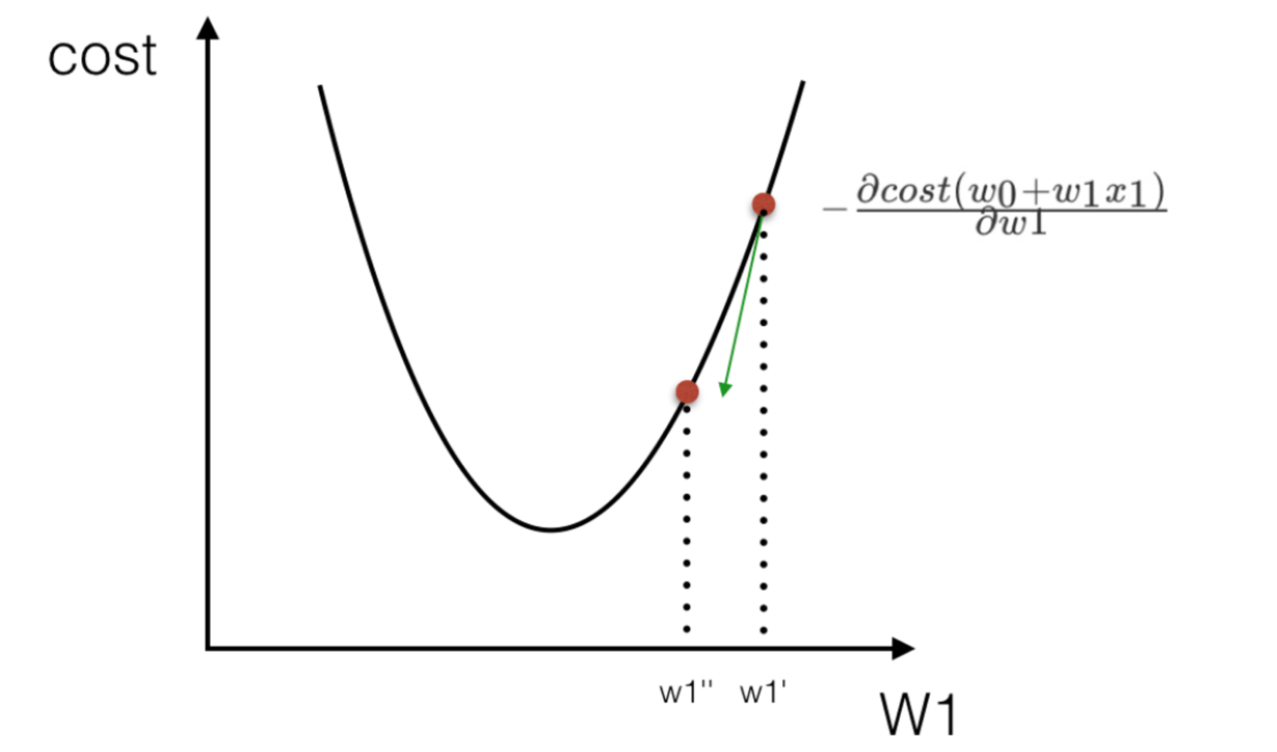
1.3.2 優化演算法---梯度下降
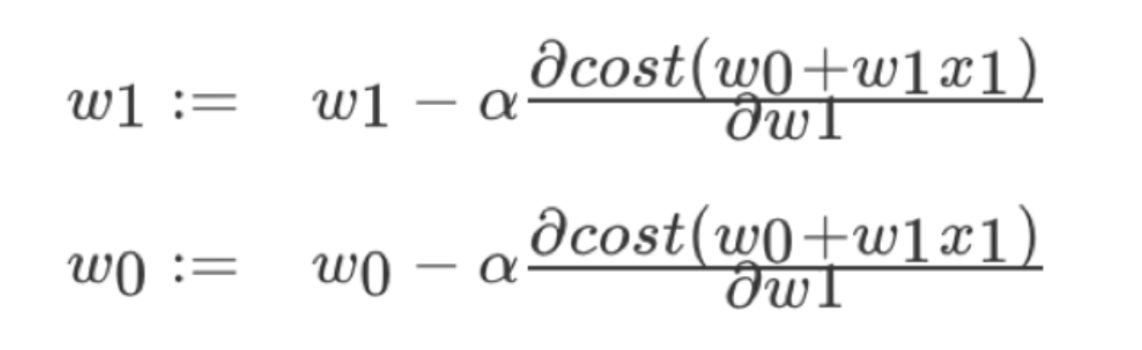
理解:α為學習速率,需要手動指定(超引數),α旁邊的整體表示方向
沿著這個函式下降的方向找,最后就能找到山谷的最低點,然后更新W值
使用:面對訓練資料規模十分龐大的任務 ,能夠找到較好的結果
1.4 線性回歸API
- sklearn.linear_model.LinearRegression(fit_intercept=True)
- 通過正規方程優化
- fit_intercept:是否計算偏置
- LinearRegression.coef_:回歸系數
- LinearRegression.intercept_:偏置
- sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
- SGDRegressor類實作了隨機梯度下降學習,它支持不同的loss函式和正則化懲罰項來擬合線性回歸模型,
- loss:損失型別
- loss=”squared_loss”: 普通最小二乘法
- fit_intercept:是否計算偏置
- learning_rate : string, optional
- 學習率填充
- 'constant': eta = eta0
- 'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
- 'invscaling': eta = eta0 / pow(t, power_t)
- power_t=0.25:存在父類當中
- 對于一個常數值的學習率來說,可以使用learning_rate=’constant’ ,并使用eta0來指定學習率,
- SGDRegressor.coef_:回歸系數
- SGDRegressor.intercept_:偏置
1.5 回歸性能評估
均方誤差(Mean Squared Error)MSE)評價機制:
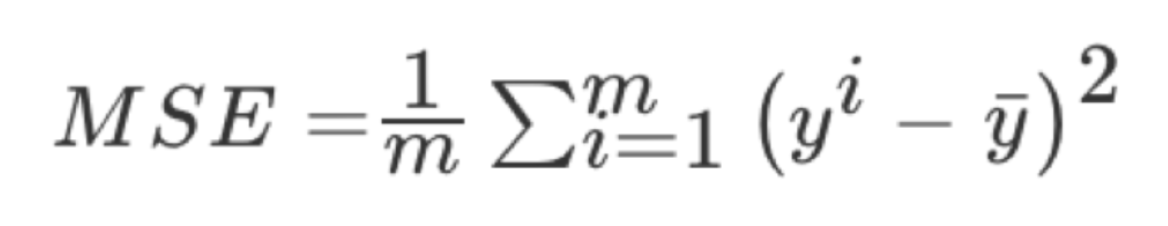
注:y^i為預測值,ˉy為真實值
- sklearn.metrics.mean_squared_error(y_true, y_pred)
- 均方誤差回歸損失
- y_true:真實值
- y_pred:預測值
- return:浮點數結果
1.6 案例(正規方程的優化方法對波士頓房價進行預測)
def linear1():
"""
正規方程的優化方法對波士頓房價進行預測
:return:
"""
# 1)獲取資料
boston = load_boston()
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)預估器
"""
通過正規方程優化
fit_intercept:是否計算偏置
LinearRegression.coef_:回歸系數
LinearRegression.intercept_:偏置
"""
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5)得出模型
print("正規方程-權重系數為:\n", estimator.coef_)
print("正規方程-偏置為:\n", estimator.intercept_)
# 6)模型評估
y_predict = estimator.predict(x_test)
print("預測房價:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("正規方程-均方誤差為:\n", error)
return None
1.7 案例(梯度下降的優化方法對波士頓房價進行預測)
def linear2():
"""
梯度下降的優化方法對波士頓房價進行預測
:return:
"""
# 1)獲取資料
boston = load_boston()
print("特征數量:\n", boston.data.shape)
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(boston.data, boston.target, random_state=22)
# 3)標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)預估器
"""
sklearn.linear_model.SGDRegressor(loss="squared_loss", fit_intercept=True, learning_rate ='invscaling', eta0=0.01)
學習率填充
'constant': eta = eta0
'optimal': eta = 1.0 / (alpha * (t + t0)) [default]
'invscaling': eta = eta0 / pow(t, power_t)
power_t=0.25:存在父類當中
對于一個常數值的學習率來說,可以使用learning_rate=’constant’ ,并使用eta0來指定學習率,
"""
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=10000, penalty="l1")
estimator.fit(x_train, y_train)
# 5)得出模型
print("梯度下降-權重系數為:\n", estimator.coef_)
print("梯度下降-偏置為:\n", estimator.intercept_)
# 6)模型評估
y_predict = estimator.predict(x_test)
print("預測房價:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("梯度下降-均方誤差為:\n", error)
return None
2、欠擬合與過擬合
2.1 什么是過擬合與欠擬合
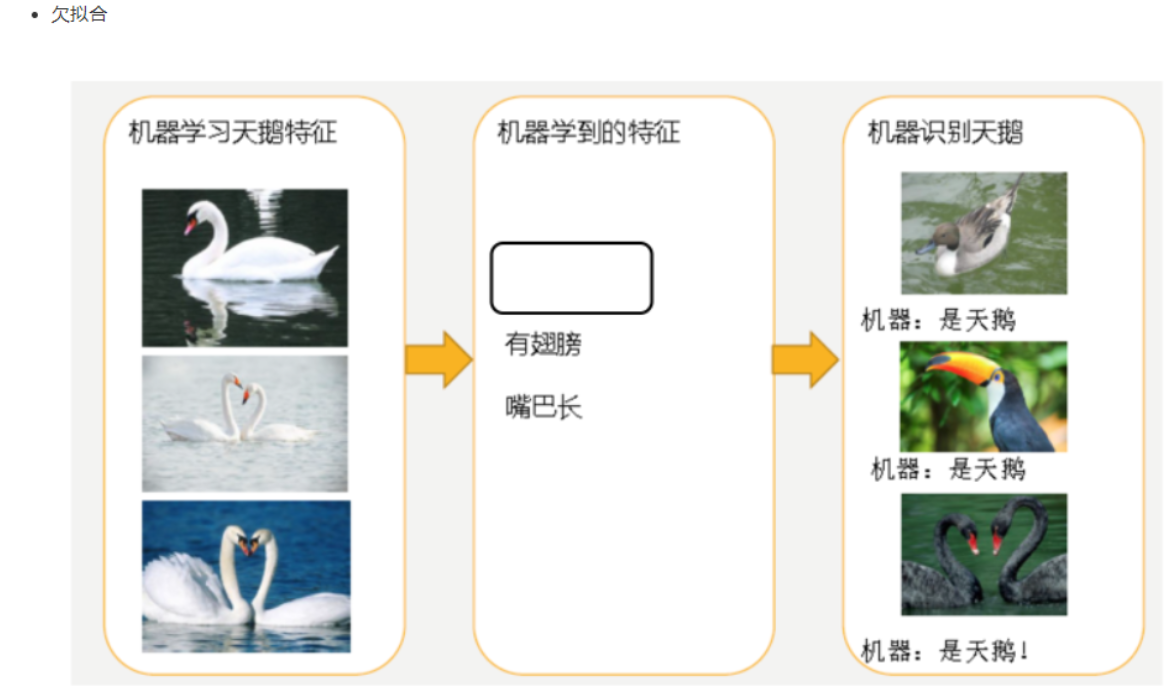
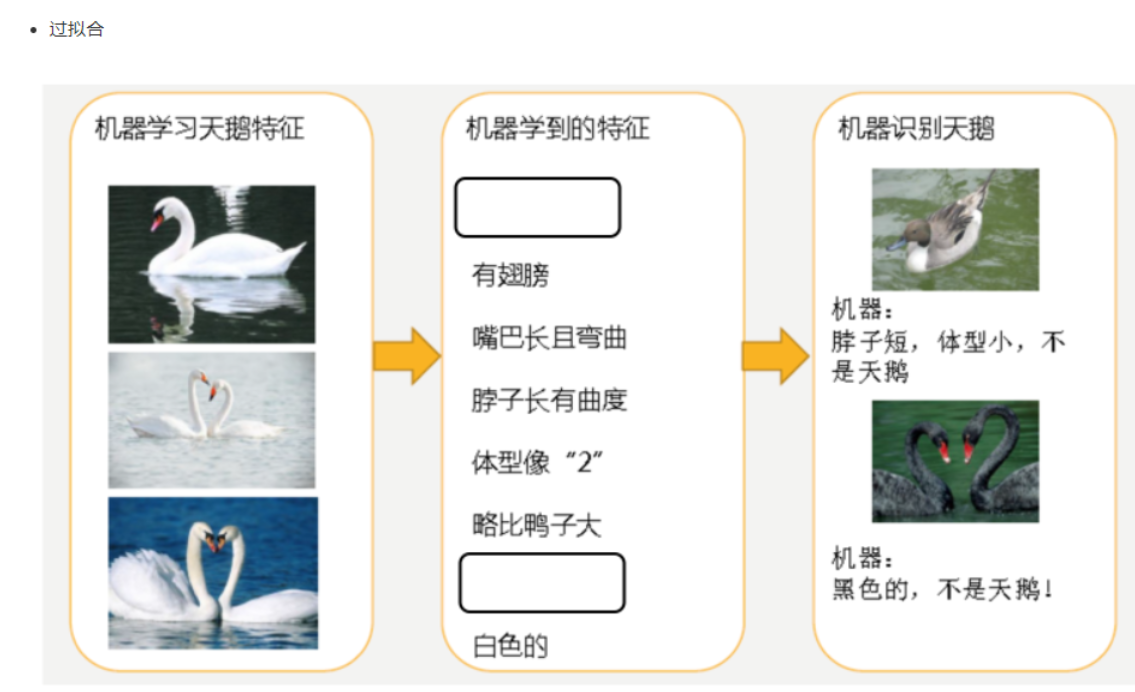
- 分析
- 第一種情況:因為機器學習到的天鵝特征太少了,導致區分標準太粗糙,不能準確識別出天鵝,
- 第二種情況:機器已經基本能區別天鵝和其他動物了,然后,很不巧已有的天鵝圖片全是白天鵝的,于是機器經過學習后,會認為天鵝的羽毛都是白的,以后看到羽毛是黑的天鵝就會認為那不是天鵝,
2.1.1 定義
- 過擬合:一個假設在訓練資料上能夠獲得比其他假設更好的擬合, 但是在測驗資料集上卻不能很好地擬合資料,此時認為這個假設出現了過擬合的現象,(模型過于復雜)
- 欠擬合:一個假設在訓練資料上不能獲得更好的擬合,并且在測驗資料集上也不能很好地擬合資料,此時認為這個假設出現了欠擬合的現象,(模型過于簡單)
2.1.2 原因和解決辦法
- 欠擬合原因以及解決辦法
- 原因:學習到資料的特征過少
- 解決辦法:增加資料的特征數量
- 過擬合原因以及解決辦法
- 原因:原始特征過多,存在一些嘈雜特征, 模型過于復雜是因為模型嘗試去兼顧各個測驗資料點
- 解決辦法:
- 正則化
2.2 正則化類別
- L2正則化
- 作用:可以使得其中一些W的都很小,都接近于0,削弱某個特征的影響
- 優點:越小的引數說明模型越簡單,越簡單的模型則越不容易產生過擬合現象
- Ridge回歸
- L1正則化
- 作用:可以使得其中一些W的值直接為0,洗掉這個特征的影響
- LASSO回歸
3、帶有L2正則化的線性回歸-嶺回歸
3.1 嶺回歸API
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver="auto", normalize=False)
- 具有L2正則化的線性回歸
- alpha:正則化力度,也叫 λ
- λ取值:0~1 1~10
- solver:會根據資料自動選擇優化方法
- sag:如果資料集、特征都比較大,選擇該隨機梯度下降優化
- normalize:資料是否進行標準化
- normalize=False:可以在fit之前呼叫preprocessing.StandardScaler標準化資料
- Ridge.coef_:回歸權重
- Ridge.intercept_:回歸偏置
Ridge方法相當于SGDRegressor(penalty='l2', loss="squared_loss")
只不過SGDRegressor實作了一個普通的隨機梯度下降學習,推薦使用Ridge(實作了SAG隨機梯度下降)
- sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
- 具有l2正則化的線性回歸,可以進行交叉驗證
- coef_:回歸系數
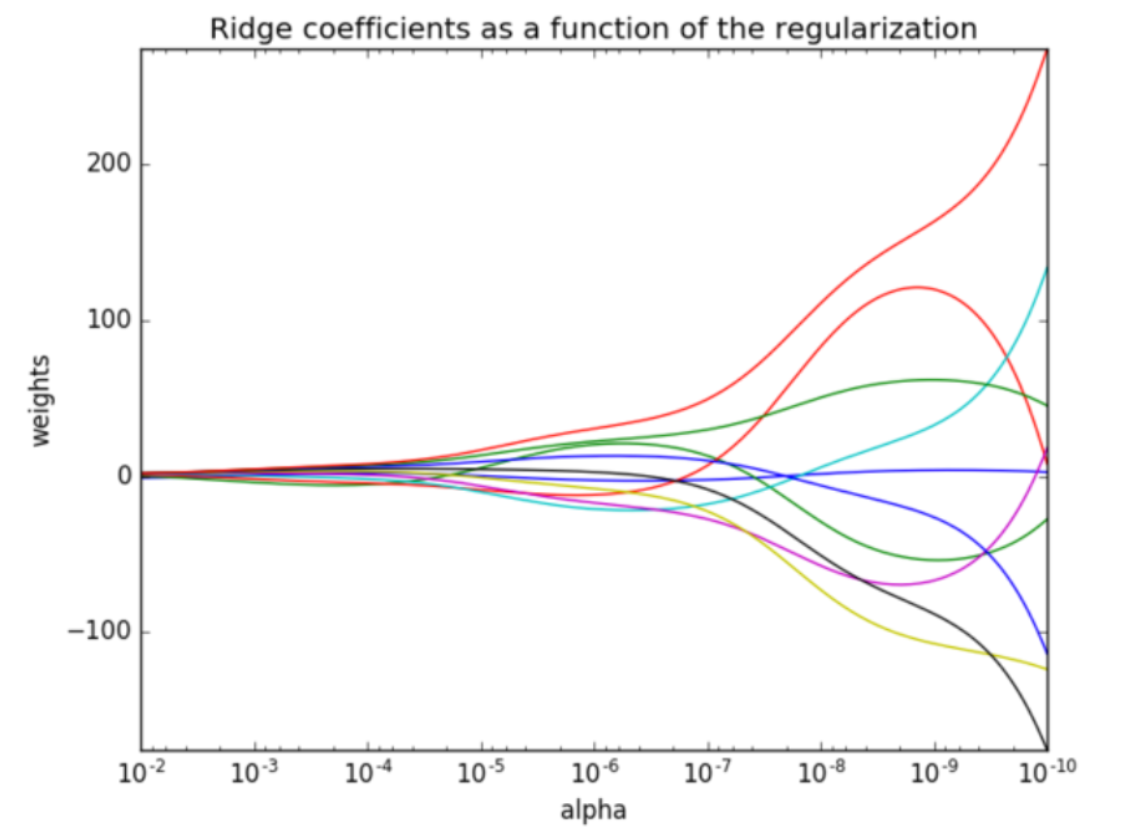
- 正則化力度越大,權重系數會越小
- 正則化力度越小,權重系數會越大
注:參考了黑馬程式員相關資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/456181.html
標籤:其他