1、K-近鄰演算法(KNN)
1.1 定義
(KNN,K-NearestNeighbor)
如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,
1.2 距離公式
兩個樣本的距離可以通過如下公式計算,又叫歐式距離,
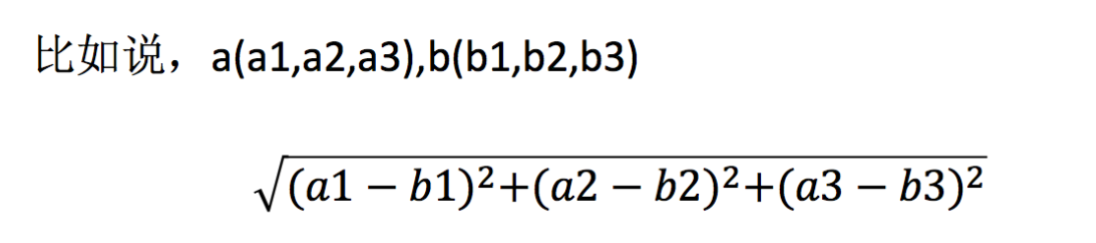
簡單理解這個演算法:
這個演算法是用來給特征值分類的,是屬于有監督學習的領域,根據不斷計算特征值和有目標值的特征值的距離來判斷某個樣本是否屬于某個目標值,
可以理解為根據你的鄰居來判斷你屬于哪個類別,
1.3 API
- sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:int,可選(默認= 5),k_neighbors查詢默認使用的鄰居數
- algorithm:{‘auto’,‘ball_tree’,‘kd_tree’,‘brute’},可選用于計算最近鄰居的演算法:‘ball_tree’將會使用 BallTree,‘kd_tree’將使用 KDTree,‘auto’將嘗試根據傳遞給fit方法的值來決定最合適的演算法, (不同實作方式影響效率)
- 其中的你指定的鄰居個數實際上是指的當演算法計算完一個樣本的特征值距離所有其他樣本的目標值的距離之后,會根據距離的大小排序,而你的指定的這個引數就是取前多少個值作為判定依據,
- 比如說你指定鄰居是5那么如果5個鄰居里3個是愛情片,那么可以說這個樣本屬于愛情片,
1.4 案例(預測簽到位置)
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
import pandas as pd
def knncls():
"""
K近鄰演算法預測入住位置類別
row_id,x,y,accuracy,time,place_id
用戶ID,坐標x,坐標y,準確度,時間,位置ID
:return:
"""
# 一、處理資料以及特征工程
# 1、讀取收,縮小資料的范圍
data = https://www.cnblogs.com/rainbow-1/archive/2022/04/05/pd.read_csv("./train.csv")
# 資料邏輯篩選操作 df.query()
data = https://www.cnblogs.com/rainbow-1/archive/2022/04/05/data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75")
# 洗掉time這一列特征
data = https://www.cnblogs.com/rainbow-1/archive/2022/04/05/data.drop(['time'], axis=1)
print(data)
# 洗掉入住次數少于三次位置
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = https://www.cnblogs.com/rainbow-1/archive/2022/04/05/data[data['place_id'].isin(tf.place_id)]
# 3、取出特征值和目標值
y = data['place_id']
# y = data[['place_id']]
x = data.drop(['place_id', 'row_id'], axis=1)
# 4、資料分割與特征工程?
# (1)、資料分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
# (2)、標準化
std = StandardScaler()
# 隊訓練集進行標準化操作
x_train = std.fit_transform(x_train)
print(x_train)
# 進行測驗集的標準化操作
x_test = std.fit_transform(x_test)
# 二、演算法的輸入訓練預測
# K值:演算法傳入引數不定的值 理論上:k = 根號(樣本數)
# K值:后面會使用引數調優方法,去輪流試出最好的引數[1,3,5,10,20,100,200]
knn = KNeighborsClassifier(n_neighbors=1)
# 呼叫fit()
knn.fit(x_train, y_train)
# 預測測驗資料集,得出準確率
y_predict = knn.predict(x_test)
print("預測測驗集類別:", y_predict)
print("準確率為:", knn.score(x_test, y_test))
return None
if __name__ == '__main__':
print()
回傳結果:
row_id x y accuracy place_id
600 600 1.2214 2.7023 17 6683426742
957 957 1.1832 2.6891 58 6683426742
4345 4345 1.1935 2.6550 11 6889790653
4735 4735 1.1452 2.6074 49 6822359752
5580 5580 1.0089 2.7287 19 1527921905
... ... ... ... ... ...
29100203 29100203 1.0129 2.6775 12 3312463746
29108443 29108443 1.1474 2.6840 36 3533177779
29109993 29109993 1.0240 2.7238 62 6424972551
29111539 29111539 1.2032 2.6796 87 3533177779
29112154 29112154 1.1070 2.5419 178 4932578245
[17710 rows x 5 columns]
[[-0.39289714 -1.20169649 0.03123826]
[-0.52988735 0.71519711 -0.08049297]
[ 0.84001481 0.82113447 -0.73225846]
...
[-0.64878452 -0.59040929 -0.20153513]
[-1.37250642 -1.33053923 -0.44361946]
[-0.11503962 -1.30477068 -0.22946794]]
預測測驗集類別: [4932578245 3312463746 8048985799 ... 1285051622 2199223958 6780386626]
準確率為: 0.4034672970843184
Process finished with exit code 0
knn.fit(x_train, y_train)
用x_train, y_train訓練模型
模型訓練好之后
y_predict = knn.predict(x_test)
呼叫預測方法預測x_test的結果
計算準確率
print("準確率為:", knn.score(x_test, y_test))
補充估計器estimator作業流程
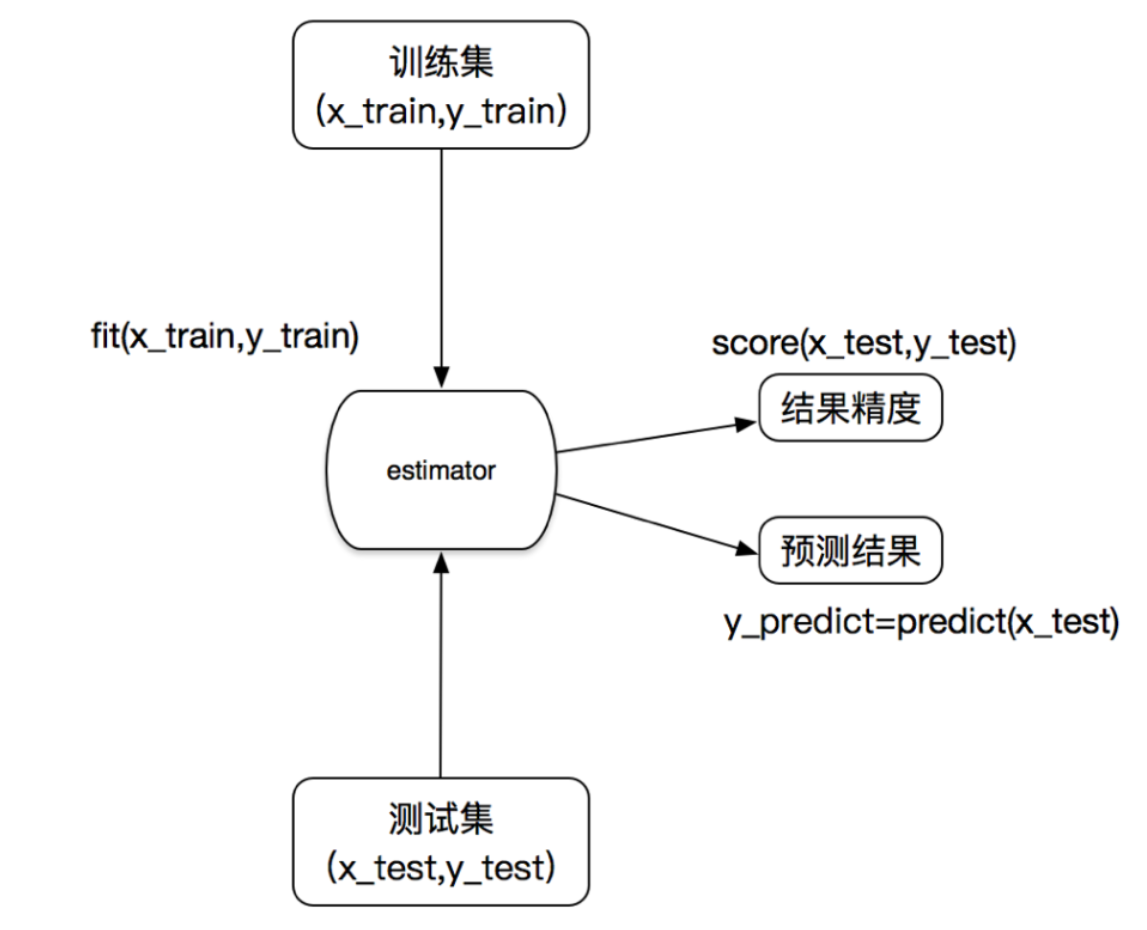
準確率: 分類演算法的評估之一
- 1、k值取多大?有什么影響?
k值取很小:容易受到例外點的影響,比如說有例外的鄰居出現在你旁邊,那么你的計算結果就會很大程度地受其影響,
k值取很大:受到樣本均衡的問題,k值過大相當于選的參考鄰居太多了,以至于不知道選哪一個作為標準才好,
- 2、性能問題?
距離計算,時間復雜度高
小結:
- 優點:
- 簡單,易于理解,易于實作,無需訓練
- 缺點:
- 懶惰演算法,對測驗樣本分類時的計算量大,記憶體開銷大
- 必須指定K值,K值選擇不當則分類精度不能保證
- 使用場景:小資料場景,幾千~幾萬樣本,具體場景具體業務去測驗
2、交叉驗證(cross validation)
交叉驗證:將拿到的訓練資料,分為訓練和驗證集,以下圖為例:將資料分成4份,其中一份作為驗證集,然后經過4次(組)的測驗,每次都更換不同的驗證集,即得到4組模型的結果,取平均值作為最終結果,又稱4折交叉驗證,
2.1 分析
我們之前知道資料分為訓練集和測驗集,但是為了讓從訓練得到模型結果更加準確,做以下處理
- 訓練集:訓練集+驗證集
- 測驗集:測驗集

2.2 超引數搜索-網格搜索(Grid Search)
通常情況下,有很多引數是需要手動指定的(如k-近鄰演算法中的K值),這種叫超引數,但是手動程序繁雜,所以需要對模型預設幾種超引陣列合,每組超引數都采用交叉驗證來進行評估,最后選出最優引陣列合建立模型,
- sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 對估計器的指定引數值進行詳盡搜索
- estimator:估計器物件
- param_grid:估計器引數(dict){“n_neighbors”:[1,3,5]}
- cv:指定幾折交叉驗證
- fit:輸入訓練資料
- score:準確率
- 結果分析:
- bestscore:在交叉驗證中驗證的最好結果_
- bestestimator:最好的引數模型
- cvresults:每次交叉驗證后的驗證集準確率結果和訓練集準確率結果
簡單理解:就是在訓練的時候隨機選一組資料做自身驗證,然后去比較哪次的結果好一些,就選這個訓練的模型作為結果!
2.3 案例(KNN演算法---鳶尾花分類)
def knn_iris_gscv():
"""
用KNN演算法對鳶尾花進行分類,添加網格搜索和交叉驗證
:return:
"""
# 1)獲取資料
iris = load_iris()
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)特征工程:標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)KNN演算法預估器
estimator = KNeighborsClassifier()
# 加入網格搜索與交叉驗證
# 引數準備 n可能的取值 用字典表示 cv = ? 表示幾折交叉驗證
param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10)
estimator.fit(x_train, y_train)
# 5)模型評估
# 方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)
# 方法2:計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)
# 最佳引數:best_params_
print("最佳引數:\n", estimator.best_params_)
# 最佳結果:best_score_
print("最佳結果:\n", estimator.best_score_)
# 最佳估計器:best_estimator_
print("最佳估計器:\n", estimator.best_estimator_)
# 交叉驗證結果:cv_results_
print("交叉驗證結果:\n", estimator.cv_results_)
return None
回傳結果:
y_predict:
[0 2 1 2 1 1 1 2 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 2 0 0 1 1 1 0 0
0]
直接比對真實值和預測值:
[ True True True True True True True True True True True True
True True True True True True False True True True True True
True True True True True True True True True True True True
True True]
準確率為:
0.9736842105263158
最佳引數:
{'n_neighbors': 3}
最佳結果:
0.9553030303030303
最佳估計器:
KNeighborsClassifier(n_neighbors=3)
交叉驗證結果:
{'mean_fit_time': array([0.00059769, 0.0005955 , 0.00069804, 0.00039876, 0.00049932,
0.00039904]), 'std_fit_time': array([0.00048802, 0.00048625, 0.00063848, 0.00048837, 0.00049932,
0.00048872]), 'mean_score_time': array([0.00144098, 0.00109758, 0.00109758, 0.00089834, 0.00109644,
0.00089748]), 'std_score_time': array([0.00047056, 0.00030139, 0.00029901, 0.0005389 , 0.00029947,
0.00029916]), 'param_n_neighbors': masked_array(data=https://www.cnblogs.com/rainbow-1/archive/2022/04/05/[1, 3, 5, 7, 9, 11],
mask=[False, False, False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 1}, {'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}, {'n_neighbors': 11}], 'split0_test_score': array([0.91666667, 0.91666667, 1. , 1. , 0.91666667,
0.91666667]), 'split1_test_score': array([1., 1., 1., 1., 1., 1.]), 'split2_test_score': array([0.90909091, 0.90909091, 0.90909091, 0.90909091, 0.90909091,
0.90909091]), 'split3_test_score': array([0.90909091, 1. , 0.90909091, 0.90909091, 0.90909091,
1. ]), 'split4_test_score': array([1., 1., 1., 1., 1., 1.]), 'split5_test_score': array([0.90909091, 0.90909091, 0.90909091, 0.90909091, 0.90909091,
0.90909091]), 'split6_test_score': array([0.90909091, 0.90909091, 0.90909091, 1. , 1. ,
1. ]), 'split7_test_score': array([0.90909091, 0.90909091, 0.81818182, 0.81818182, 0.81818182,
0.81818182]), 'split8_test_score': array([1., 1., 1., 1., 1., 1.]), 'split9_test_score': array([1., 1., 1., 1., 1., 1.]), 'mean_test_score': array([0.94621212, 0.95530303, 0.94545455, 0.95454545, 0.94621212,
0.95530303]), 'std_test_score': array([0.04397204, 0.0447483 , 0.06030227, 0.06098367, 0.05988683,
0.0604591 ]), 'rank_test_score': array([4, 1, 6, 3, 4, 1])}
3、樸素貝葉斯演算法
垃圾郵件分類:
3.1 貝葉斯公式

公式分為三個部分:
- P(C):每個檔案類別的概率(某檔案類別數/總檔案數量)
- P(W│C):給定類別下特征(被預測檔案中出現的詞)的概率
- 計算方法:P(F1│C)=Ni/N (訓練檔案中去計算)
- Ni為該F1詞在C類別所有檔案中出現的次數
- N為所屬類別C下的檔案所有詞出現的次數和
- 計算方法:P(F1│C)=Ni/N (訓練檔案中去計算)
- P(F1,F2,…) 預測檔案中每個詞的概率

樸素貝葉斯即假定所有的特征值之間相互獨立
3.2 檔案分類計算
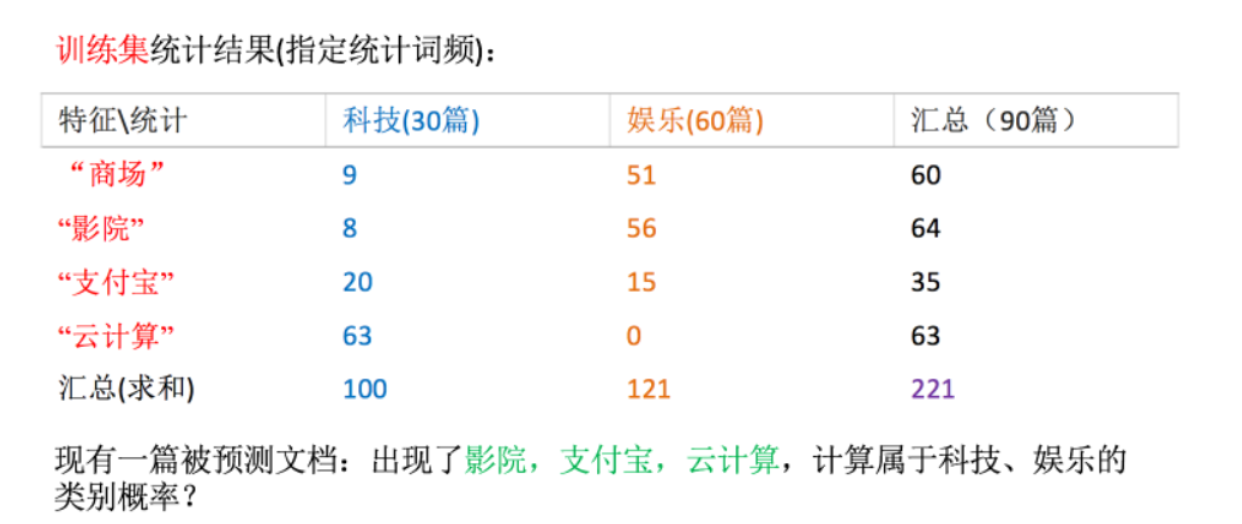
科技:P(科技|影院,支付寶,云計算) = ??(影院,支付寶,云計算|科技)?P(科技)=(8/100)?(20/100)?(63/100)?(30/90) = 0.00456109
娛樂:P(娛樂|影院,支付寶,云計算) = ??(影院,支付寶,云計算|娛樂)?P(娛樂)=(56/121)?(15/121)?(0/121)?(60/90) = 0
為了不出現概率為0的情況
3.3 拉普拉斯平滑系數
目的:防止計算出的分類概率為0

P(娛樂|影院,支付寶,云計算) =P(影院,支付寶,云計算|娛樂)P(娛樂) =P(影院|娛樂)*P(支付寶|娛樂)*P(云計算|娛樂)P(娛樂)=(56+1/121+4)(15+1/121+4)(0+1/121+1*4)(60/90) = 0.00002
3.4 案例(新聞分類)
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 樸素貝葉斯分類
- alpha:拉普拉斯平滑系數
def nb_news():
"""
用樸素貝葉斯演算法對新聞進行分類
:return:
"""
# 1)獲取資料
news = fetch_20newsgroups(subset="all")
print("特征值名字:\n ",news["DESCR"])
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)樸素貝葉斯演算法預估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型評估
# 方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)
# 方法2:計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)
return None
回傳結果:
y_predict:
[14 1 14 ... 12 6 5]
直接比對真實值和預測值:
[ True True True ... True True False]
準確率為:
0.8423174872665535
小結:
- 優點:
- 樸素貝葉斯模型發源于古典數學理論,有穩定的分類效率,
- 對缺失資料不太敏感,演算法也比較簡單,常用于文本分類,
- 分類準確度高,速度快
- 缺點:
- 由于使用了樣本屬性獨立性的假設,所以如果特征屬性有關聯時其效果不好
4、決策樹
4.1 認識決策樹
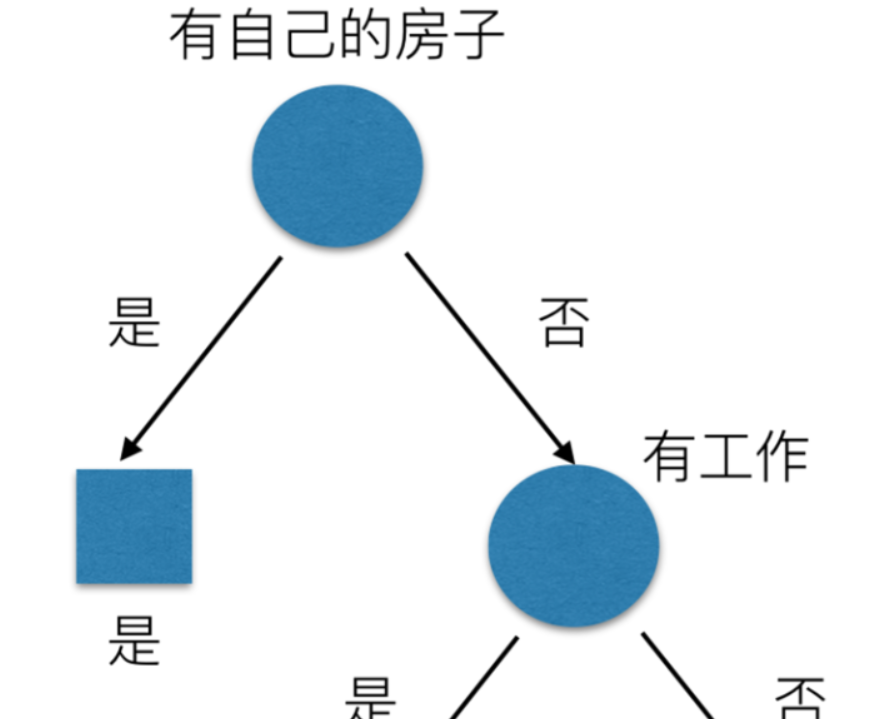
決策樹思想的來源非常樸素,程式設計中的條件分支結構就是if-then結構,最早的決策樹就是利用這類結構分割資料的一種分類學習方法,
決策樹分類原理
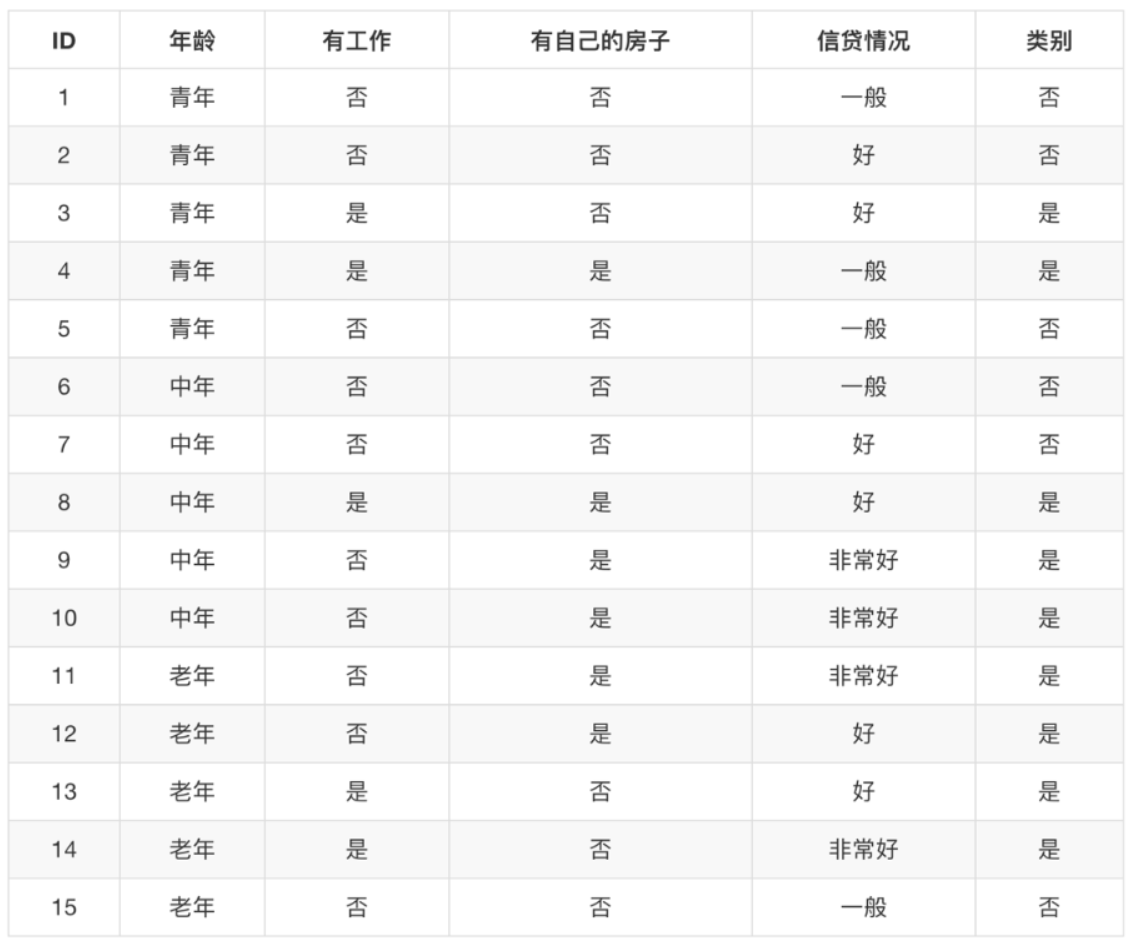
銀行貸款資料:
4.2 資訊熵
- H的專業術語稱之為資訊熵,單位為位元,
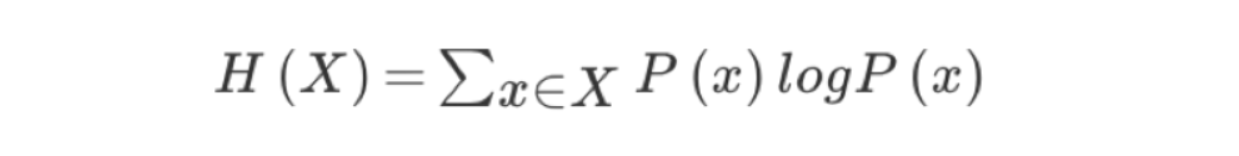
- 資訊和消除不確定性是相聯系的
當我們得到的額外資訊(球隊歷史比賽情況等等)越多的話,那么我們猜測的代價越小(猜測的不確定性減小)
當你獲取各個資訊的概率都不變(且都是相同的百分之50 也就是成立或者不成立 )的時候,資訊熵是一定的,只要獲取資訊的概率發生變化(比如其中某條資訊成立的概率變成了百分之60,不成立的概率變成百分之40),那么新的資訊熵的值一定會大于剛剛計算的值,
問題: 回到我們前面的貸款案例,怎么去劃分?可以利用當得知某個特征(比如是否有房子)之后,我們能夠減少的不確定性大小,越大我們可以認為這個特征很重要,那怎么去衡量減少的不確定性大小呢?
4.3 決策樹的劃分依據之一---資訊增益
特征A對訓練資料集D的資訊增益g(D,A),定義為集合D的資訊熵H(D)與特征A給定條件下D的資訊條件熵H(D|A)之差,即公式為:

? 注:資訊增益表示得知特征X的資訊的不確定性減少的程度使得類Y的資訊熵減少的程度
得知某特征之后資訊的不確定性就會減少,那么資訊增益就表示這個新資訊的加入會給這個分類的最終資訊熵帶來多大的減少程度,如果帶來的效益越大,說明這條資訊越有價值,
比如上面的銀行貸款案例:
1、g(D, 年齡) = H(D) -H(D|年齡) = 0.971-[5/15H(青年)+5/15H(中年)+5/15H(老年]
2、H(D) = -(6/15log(6/15)+9/15log(9/15))=0.971
3、H(青年) = -(3/5log(3/5) +2/5log(2/5))
H(中年)=-(3/5log(3/5) +2/5log(2/5))
H(老年)=-(4/5og(4/5)+1/5log(1/5))
我們以A1、A2、A3、A4代表年齡、有作業、有自己的房子和貸款情況,最終計算的結果g(D, A1) = 0.313, g(D, A2) = 0.324, g(D, A3) = 0.420,g(D, A4) = 0.363,所以我們選擇A3(A3最大,最有價值,所以放在樹的前面)作為劃分的第一個特征,這樣我們就可以一棵樹慢慢建立,
4.4 決策樹的三種演算法實作
- ID3
- 資訊增益 最大的準則
- C4.5
- 資訊增益比 最大的準則
- CART
- 分類樹: 基尼系數 最小的準則 在sklearn中可以選擇劃分的默認原則
- 優勢:劃分更加細致(從后面例子的樹顯示來理解)
案例(用決策樹對鳶尾花進行分類)
- class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- 決策樹分類器
- criterion:默認是’gini’系數,也可以選擇資訊增益的熵’entropy’
- max_depth:樹的深度大小
- random_state:亂數種子
- 其中會有些超引數:max_depth:樹的深度大小
- 其它超引數我們會結合隨機森林講解
def decision_iris():
"""
用決策樹對鳶尾花進行分類
:return:
"""
# 1)獲取資料集
iris = load_iris()
# 2)劃分資料集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)決策樹預估器
"""
決策樹分類器
criterion:默認是’gini’系數,也可以選擇資訊增益的熵’entropy’
max_depth:樹的深度大小
random_state:亂數種子
"""
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train)
# 4)模型評估
# 方法1:直接比對真實值和預測值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比對真實值和預測值:\n", y_test == y_predict)
# 方法2:計算準確率
score = estimator.score(x_test, y_test)
print("準確率為:\n", score)
# 可視化決策樹
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
return None
回傳結果:
y_predict:
[0 2 1 2 1 1 1 1 1 0 2 1 2 2 0 2 1 1 1 1 0 2 0 1 2 0 2 2 2 1 0 0 1 1 1 0 0
0]
直接比對真實值和預測值:
[ True True True True True True True False True True True True
True True True True True True False True True True True True
True True True True True False True True True True True True
True True]
準確率為:
0.9210526315789473
小結:
- 優點:
- 簡單的理解和解釋,樹木可視化,
- 缺點:
- 決策樹學習者可以創建不能很好地推廣資料的過于復雜的樹,這被稱為過擬合,
- 改進:
- 減枝cart演算法(決策樹API當中已經實作,隨機森林引數調優有相關介紹)
- 隨機森林
注:企業重要決策,由于決策樹很好的分析能力,在決策程序應用較多, 可以選擇特征
5、隨機森林
5.1 什么是集成學習方法
集成學習通過建立幾個模型組合的來解決單一預測問題,它的作業原理是生成多個分類器/模型,各自獨立地學習和作出預測,這些預測最后結合成組合預測,因此優于任何一個單分類的做出預測,
5.2 什么是隨機森林
在機器學習中,隨機森林是一個包含多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別的眾數而定,
- 例如, 如果你訓練了5個樹, 其中有4個樹的結果是True, 1個數的結果是False, 那么最終投票結果就是True
5.3 隨機森林原理程序
學習演算法根據下列演算法而建造每棵樹:
-
用N來表示訓練用例(樣本)的個數,M表示特征數目,
- 1、一次隨機選出一個樣本,重復N次, (有可能出現重復的樣本)
- 2、隨機去選出m個特征, m <<M,建立決策樹
-
采取bootstrap抽樣
什么是BootStrap抽樣?
-
bootstrap 獨立的
-
-
為什么要隨機抽樣訓練集?
- 如果不進行隨機抽樣,每棵樹的訓練集都一樣,那么最終訓練出的樹分類結果也是完全一樣的
-
為什么要有放回地抽樣?
- 如果不是有放回的抽樣,那么每棵樹的訓練樣本都是不同的,都是沒有交集的,這樣每棵樹都是“有偏的”,都是絕對“片面的”(當然這樣說可能不對),也就是說每棵樹訓練出來都是有很大的差異的;而隨機森林最后分類取決于多棵樹(弱分類器)的投票表決,
5.4 隨機森林API
-
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- 隨機森林分類器
- n_estimators:integer,optional(default = 10)森林里的樹木數量120,200,300,500,800,1200
- criteria:string,可選(default =“gini”)分割特征的測量方法
- max_depth:integer或None,可選(默認=無)樹的最大深度 5,8,15,25,30
- max_features="auto”,每個決策樹的最大特征數量
- If "auto", then
max_features=sqrt(n_features). - If "sqrt", then
max_features=sqrt(n_features)(same as "auto"). - If "log2", then
max_features=log2(n_features). - If None, then
max_features=n_features.
- If "auto", then
- bootstrap:boolean,optional(default = True)是否在構建樹時使用放回抽樣
- min_samples_split:節點劃分最少樣本數
- min_samples_leaf:葉子節點的最小樣本數
-
超引數:n_estimator, max_depth, min_samples_split,min_samples_leaf
# 隨機森林去進行預測
rf = RandomForestClassifier()
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
# 超引數調優
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("隨機森林預測的準確率為:", gc.score(x_test, y_test))
小結:
- 在當前所有演算法中,具有極好的準確率
- 能夠有效地運行在大資料集上,處理具有高維特征的輸入樣本,而且不需要降維
- 能夠評估各個特征在分類問題上的重要性
幾個問題:
1、資料集的結構是什么?
答案: 特征值+ 目標值
2、機器學習演算法分成哪些類別? 如何分類
答案:
根據是否有目標值分為
-
監督學習
-
非監督學習
根據目標值的資料型別
-
目標值為離散值就是分類問題
-
目標值為連續值就是回歸問題
3、什么是標準化? 和歸一化相比有什么優點?
答案: 標準化是通過對原始資料進行變換把資料變換到均值為0,方差為1范圍內
優點: 少量例外點, 不影響平均值和方差, 對轉換影響小
注:參考了黑馬程式員相關資料,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/456183.html
標籤:其他
上一篇:什么是機器學習回歸演算法?【線性回歸、正規方程、梯度下降、正則化、欠擬合和過擬合、嶺回歸】
下一篇:分類演算法-邏輯回歸與二分類