無監督學習-K-means演算法
1、 什么是無監督學習
- 一家廣告平臺需要根據相似的人口學特征和購買習慣將美國人口分成不同的小組,以便廣告客戶可以通過有關聯的廣告接觸到他們的目標客戶,
- Airbnb 需要將自己的房屋清單分組成不同的社區,以便用戶能更輕松地查閱這些清單,
- 一個資料科學團隊需要降低一個大型資料集的維度的數量,以便簡化建模和降低檔案大小,
我們可以怎樣最有用地對其進行歸納和分組?我們可以怎樣以一種壓縮格式有效地表征資料?這都是無監督學習的目標,之所以稱之為無監督,是因為這是從無標簽的資料開始學習的,
2、 無監督學習包含演算法
- 聚類
- K-means(K均值聚類)
- 降維
- PCA
3、 K-means原理
我們先來看一下一個K-means的聚類效果圖
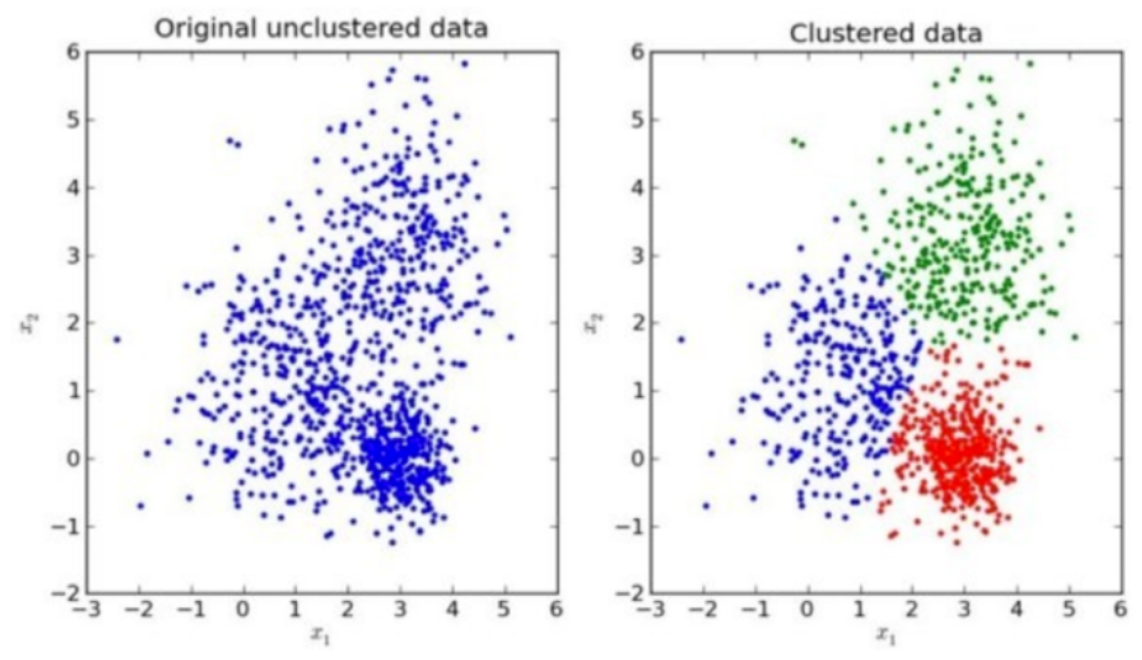
3.1 K-means聚類步驟
- 1、隨機設定K個特征空間內的點作為初始的聚類中心
- 2、對于其他每個點計算到K個中心的距離,未知的點選擇最近的一個聚類中心點作為標記類別
- 3、接著對著標記的聚類中心之后,重新計算出每個聚類的新中心點(平均值)
- 4、如果計算得出的新中心點與原中心點一樣,那么結束,否則重新進行第二步程序
4、K-meansAPI
- sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
- k-means聚類
- n_clusters:開始的聚類中心數量 比如 n_clusters=4
- init:初始化方法,默認為'k-means ++’
- labels_:默認標記的型別,可以和真實值比較(不是值比較)
5、 案例:k-means對Instacart Market用戶聚類
5.1 分析
- 1、降維之后的資料
- 2、k-means聚類
- 3、聚類結果顯示
5.2 代碼
# 取500個用戶進行測驗
# 如果b_i>>a_i:趨近于1效果越好, b_i<<a_i:趨近于-1,效果不好,輪廓系數的值是介于 [-1,1] ,越趨近于1代表內聚度和分離度都相對較優,
cust = data[:500]
km = KMeans(n_clusters=4)
km.fit(cust)
pre = km.predict(cust)
print(silhouette_score(cust, pre))
回傳結果:
0.466014214896049
問題:如何去評估聚類的效果呢?
6、Kmeans性能評估指標
6.1 輪廓系數
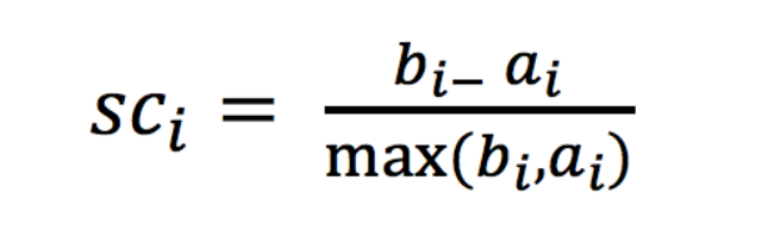
注:對于每個點i 為已聚類資料中的樣本 ,b_i 為i 到其它族群的所有樣本的距離最小值,a_i 為i 到本身簇的距離平均值,最終計算出所有的樣本點的輪廓系數平均值
6.2 輪廓系數值分析
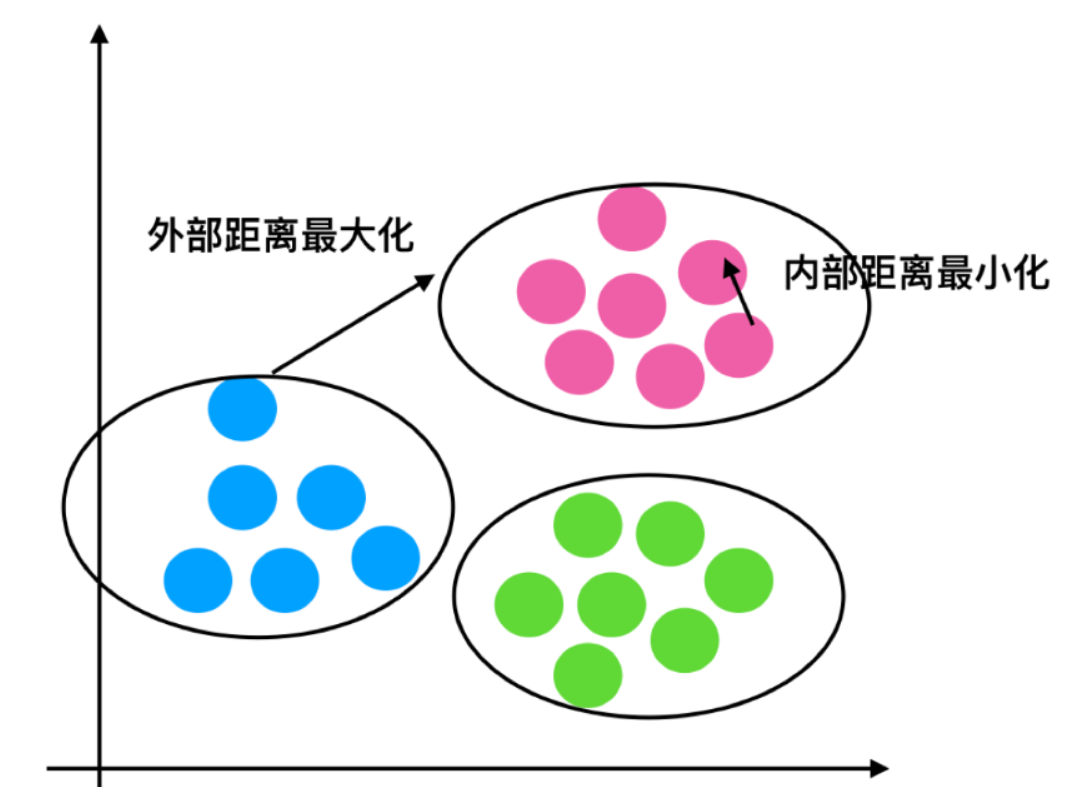
- 分析程序(我們以一個藍1點為例)
- 1、計算出藍1離本身族群所有點的距離的平均值a_i
- 2、藍1到其它兩個族群的距離計算出平均值紅平均,綠平均,取最小的那個距離作為b_i
- 根據公式:極端值考慮:如果b_i >>a_i: 那么公式結果趨近于1;如果a_i>>>b_i: 那么公式結果趨近于-1
6.3 結論
如果b_i>>a_i:趨近于1效果越好, b_i<<a_i:趨近于-1,效果不好,輪廓系數的值是介于 [-1,1] ,越趨近于1代表內聚度和分離度都相對較優,
6.4 輪廓系數API
- sklearn.metrics.silhouette_score(X, labels)
- 計算所有樣本的平均輪廓系數
- X:特征值
- labels:被聚類標記的目標值
6.5 用戶聚類結果評估
silhouette_score(cust, pre)
7、K-means總結
- 特點分析:采用迭代式演算法,直觀易懂并且非常實用
- 缺點:容易收斂到區域最優解(多次聚類)
注意:聚類一般做在分類之前
案例:
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# 1、獲取資料集
# ·商品資訊- products.csv:
# Fields:product_id, product_name, aisle_id, department_id
# ·訂單與商品資訊- order_products__prior.csv:
# Fields:order_id, product_id, add_to_cart_order, reordered
# ·用戶的訂單資訊- orders.csv:
# Fields:order_id, user_id,eval_set, order_number,order_dow, order_hour_of_day, days_since_prior_order
# ·商品所屬具體物品類別- aisles.csv:
# Fields:aisle_id, aisle
from sklearn.metrics import silhouette_score
products = pd.read_csv("../instacart/products.csv")
order_products = pd.read_csv("../instacart/order_products__prior.csv")
orders = pd.read_csv("../instacart/orders.csv")
aisles = pd.read_csv("../instacart/aisles.csv")
# 2、合并表,將user_id和aisle放在一張表上
# 1)合并orders和order_products on=order_id tab1:order_id, product_id, user_id
tab1 = pd.merge(orders, order_products, on=["order_id", "order_id"])
# 2)合并tab1和products on=product_id tab2:aisle_id
tab2 = pd.merge(tab1, products, on=["product_id", "product_id"])
# 3)合并tab2和aisles on=aisle_id tab3:user_id, aisle
tab3 = pd.merge(tab2, aisles, on=["aisle_id", "aisle_id"])
# 3、交叉表處理,把user_id和aisle進行分組
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
# 4、主成分分析的方法進行降維
# 1)實體化一個轉換器類PCA
transfer = PCA(n_components=0.95)
# 2)fit_transform
data = https://www.cnblogs.com/rainbow-1/archive/2022/04/05/transfer.fit_transform(table)
print(data.shape)
# 取500個用戶進行測驗
# 如果b_i>>a_i:趨近于1效果越好, b_i<回傳結果:
(206209, 44)
0.466014214896049
幾個問題:
1、線性回歸的引數求解的方法是什么?
答案: 正規方程和梯度下降
2、什么是過擬合? 原因有哪些?
答案: 過擬合就是訓練誤差很小,但是測驗誤差很大
原因有: 樣本偏差, 模型過于復雜
3、分類問題, 回歸問題, 聚類問題的評估方法分別是什么?
答案: 分類問題的評估方法是準確率, 精確率和召回率
回歸問題的評估方法是均方差
聚類問題的評估方法是輪廓系數
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/456186.html
標籤:其他
上一篇:分類演算法-邏輯回歸與二分類
下一篇:記一節有關密碼學承諾的課