摘要:本文詳細介紹基于支持向量機的影像分類系統,給出MATLAB的演算法介紹及界面設計程序,在界面中可點擊選擇圖片或帶圖片的檔案夾,系統自動對所涉及圖片進行識別分類,可選擇自己訓練的模型進行分類;另外系統設計了模型訓練功能,可在界面上選擇訓練資料集的檔案夾和少量選擇設定,系統便可以自動進行模型訓練,適合不同的自定義資料集;演算法部分的特征提取程序采用方向梯度直方圖(HOG)特征,分類程序采用性能優異的核支持向量機(SVM)演算法,系統界面清新美觀,文中包含完整的代碼檔案及資料集,開箱即用,適合新手朋友學習參考,
目錄- 前言
- 1. 效果演示
- 2. Caltech 101資料集
- 3. HOG特征提取
- 4. 訓練和評估模型
- 5. 測驗模型
- 下載鏈接
- 結束語
?點擊跳轉至文末所有涉及的完整代碼檔案下載頁?
完整資源下載鏈接:https://mianbaoduo.com/o/bread/mbd-YpiTl5ht
代碼介紹及演示視頻鏈接:https://www.bilibili.com/video/BV1V44y1M7mC/(正在更新中,歡迎關注博主B站視頻)
前言
當前機器學習的演算法已經獲得應用,對于經典的支持向量機(SVM)演算法,其有著實作簡單、解釋性較強、性能優越的特點,如今支持向量機的研究力度并沒有減退,選擇何種演算法應該取決于具體的機器學習任務,對于多類別的影像分類任務,支持向量機或許是一個不錯的選擇,本文介紹的代碼可以實作較高的分類測驗準確率,所以想借此為大家提供一個學習的Demo共同交流,
思路是先基于核支持向量機(SVM)演算法開發一個能夠根據圖片內容進行分類的腳本,所用到的資料集可以是當前公開的分類圖片資料集,也可以是自行從網路上爬取的,除了演算法實作,為了便于展示和訓練,我們利用MATLAB的APP設計工具開發一個GUI系統界面,能夠滿足我們選擇模型、圖片、檔案夾路徑的需求,初始界面如上圖所示,另外由于自行設定的資料集可能經常調整,所以相應的代碼也需要調整,所以這里把資料集的調整考慮進去,設計了可選擇訓練資料集、設定訓練引數的功能,其界面如下圖所示,
本文給出了MATLAB實作的完整代碼供大家參考,有基礎的讀者可按照文中的介紹復現出完整程式;對于想獲取全部資料集及程式檔案的朋友,可以點擊提供的下載鏈接獲取可直接運行的代碼,原創不易,還請多多支持了,如本文對您有所幫助,敬請點贊、收藏、關注!
1. 效果演示
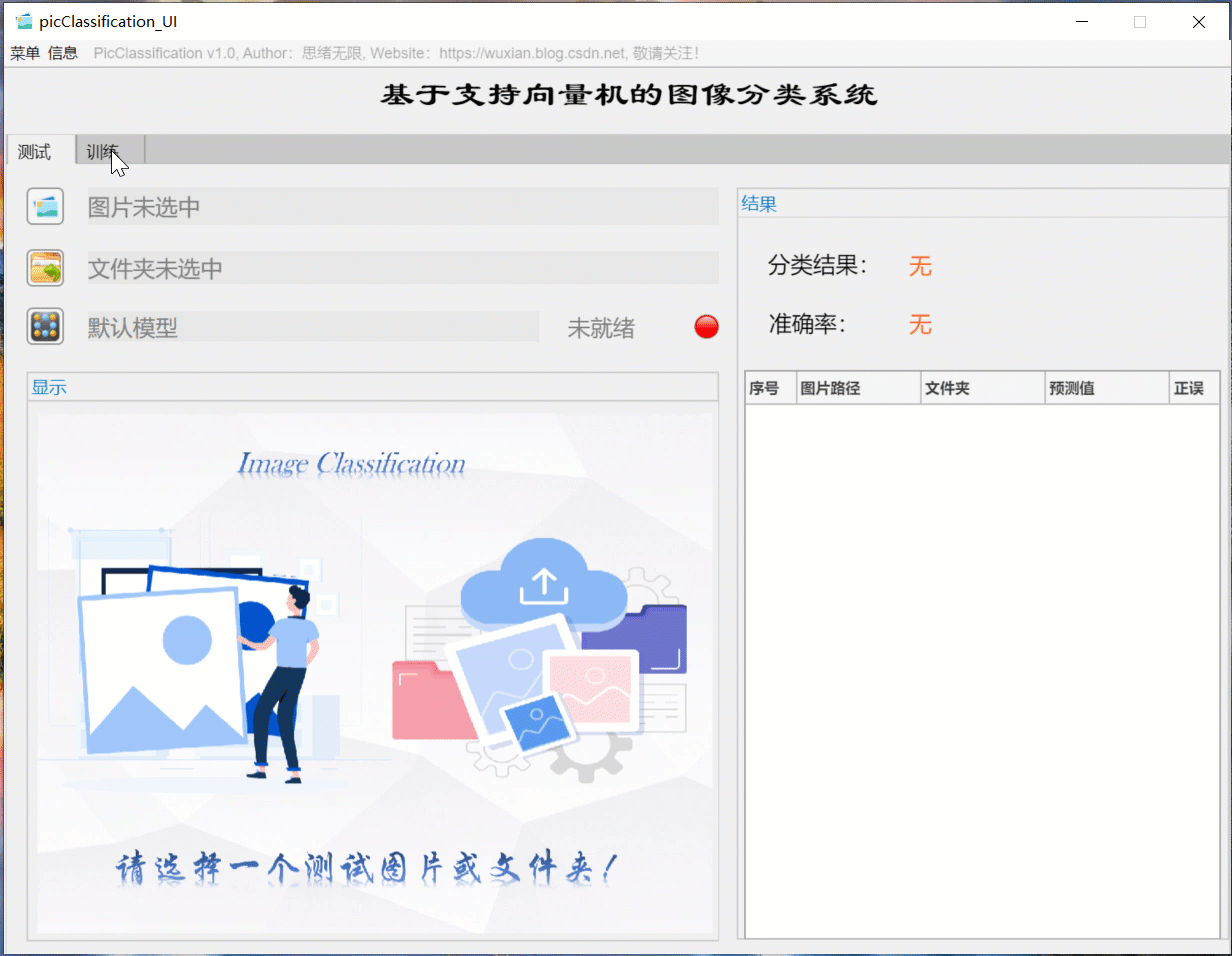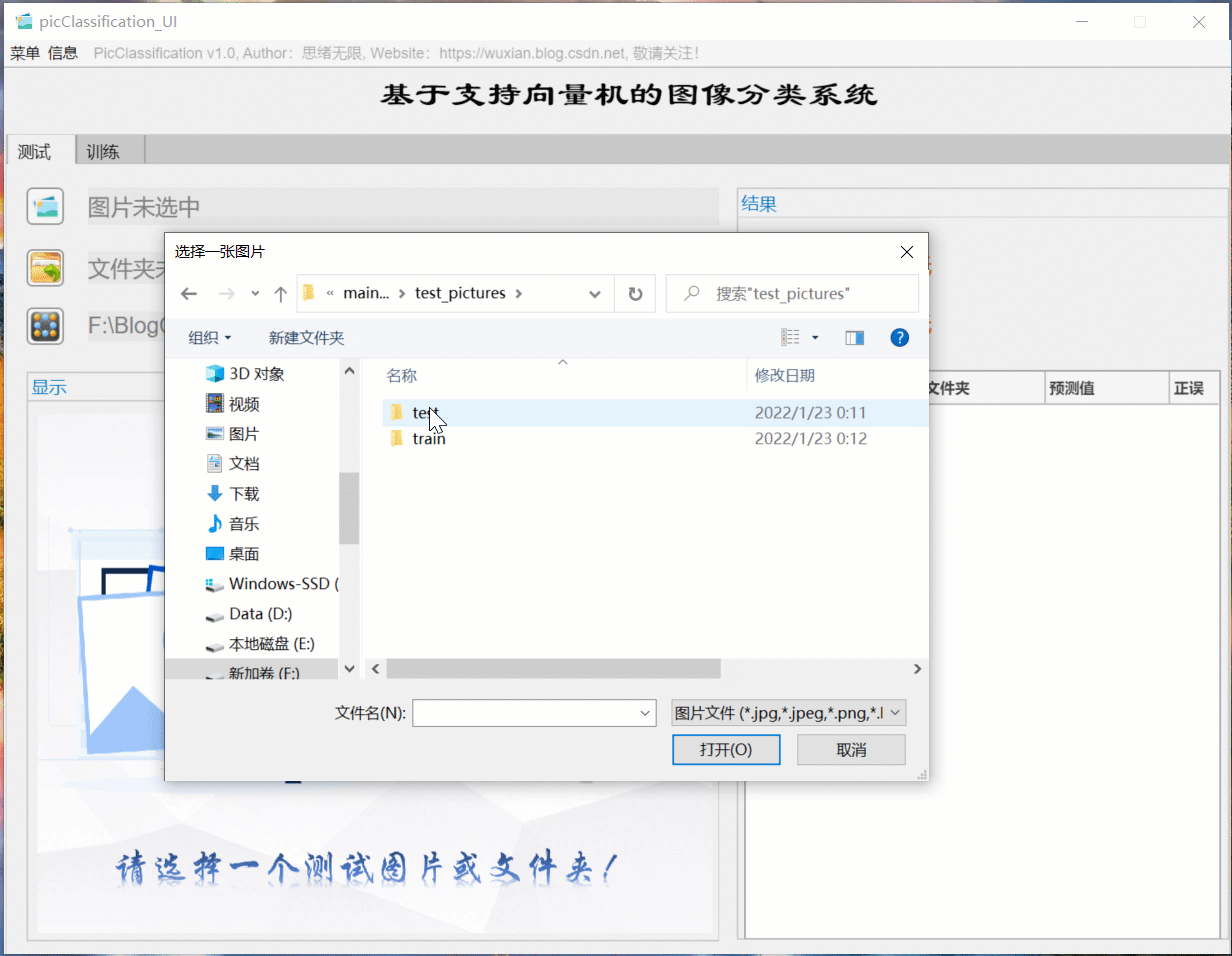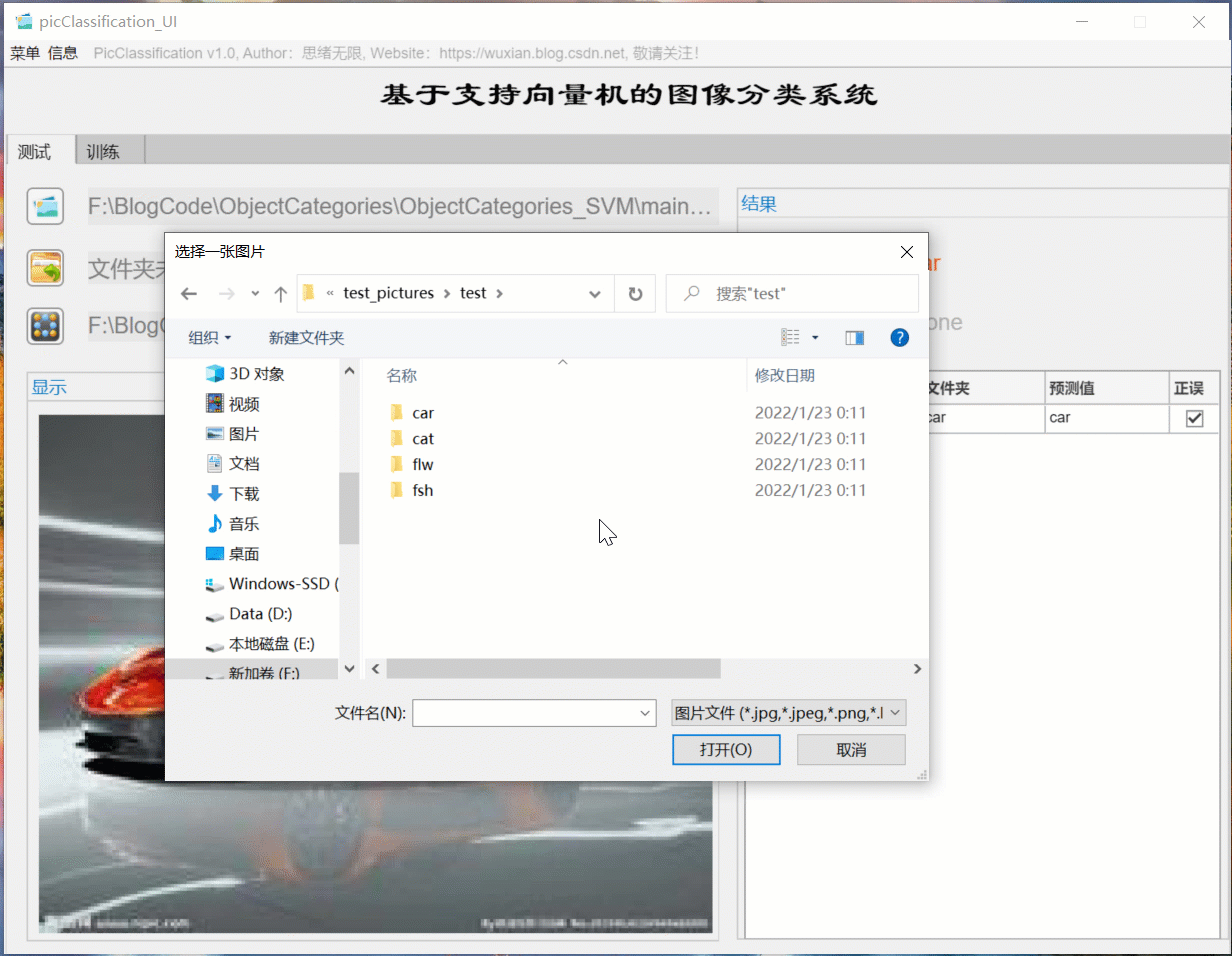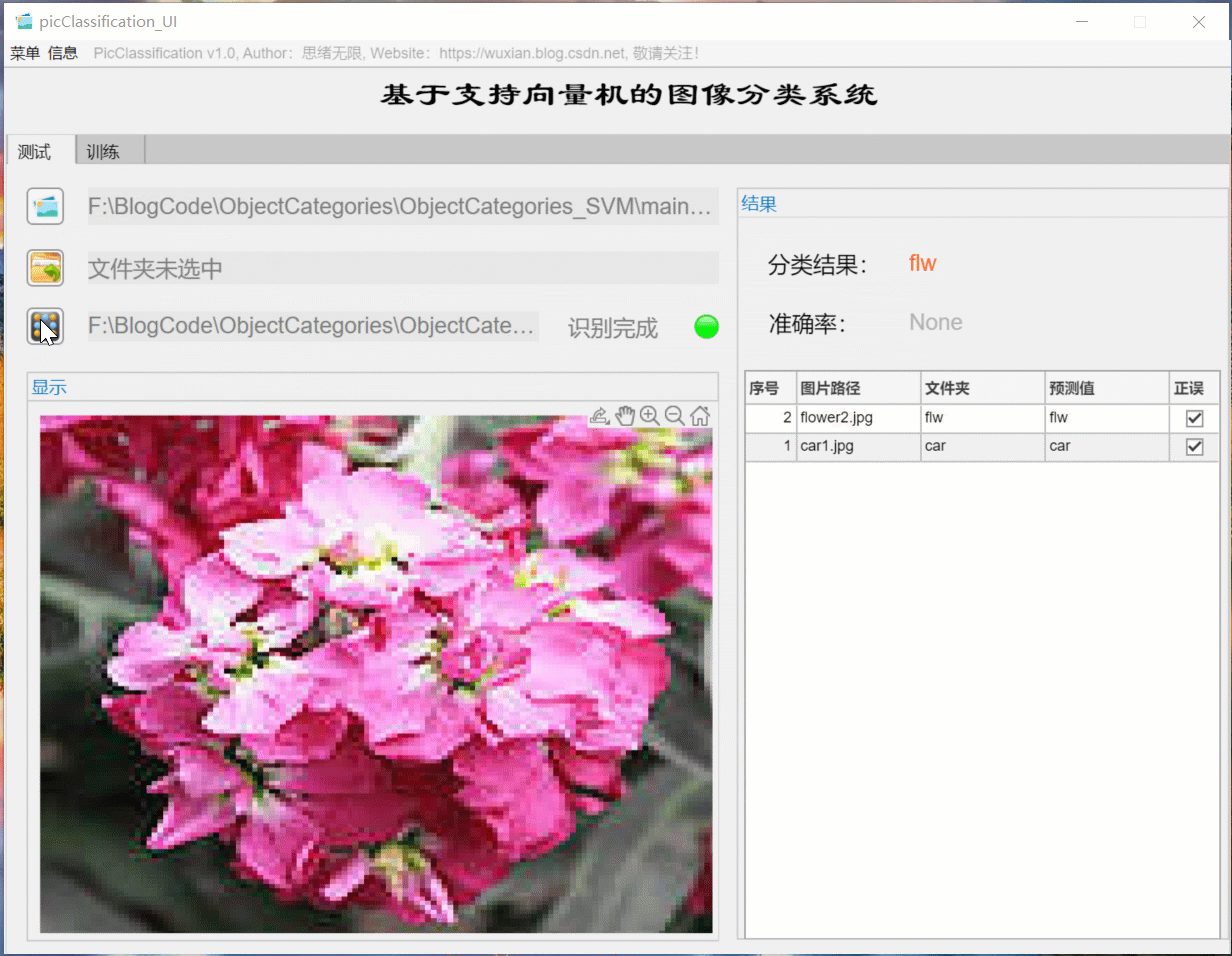
(一)選擇模型+選擇圖片+歷史記錄
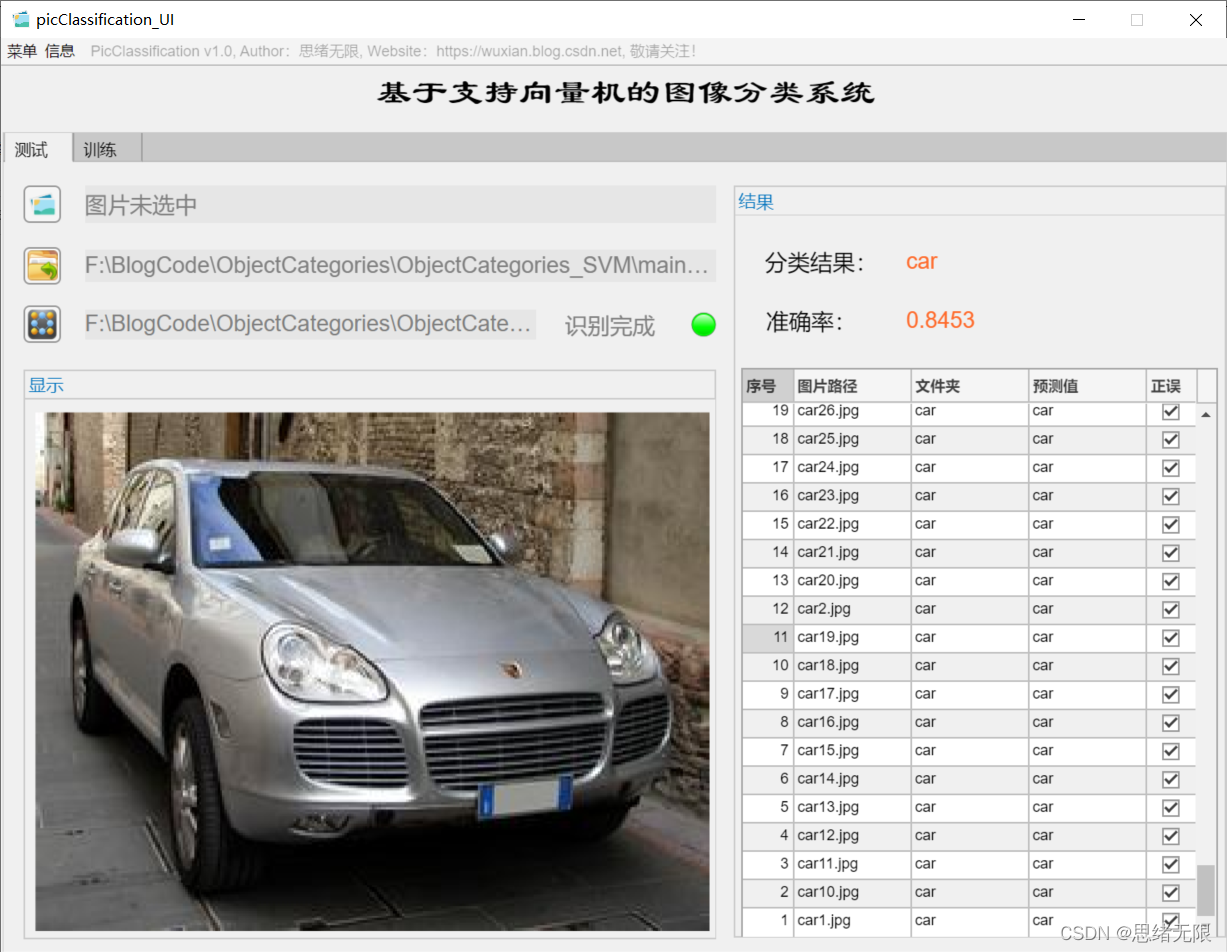
首先還是用動圖先展示一下效果,進入軟體界面后,點擊模型選擇按鈕即可彈出檔案選擇視窗,可選擇自行訓練的模型檔案;然后同樣點擊圖片選擇按鈕,可以選擇一張需要測驗的圖片,點擊確認后,模型則自動識別圖片內容,并給出預測的結果;結果會被記錄在右側的表格中,可供再次查看確認,本功能的界面展示如下圖所示:
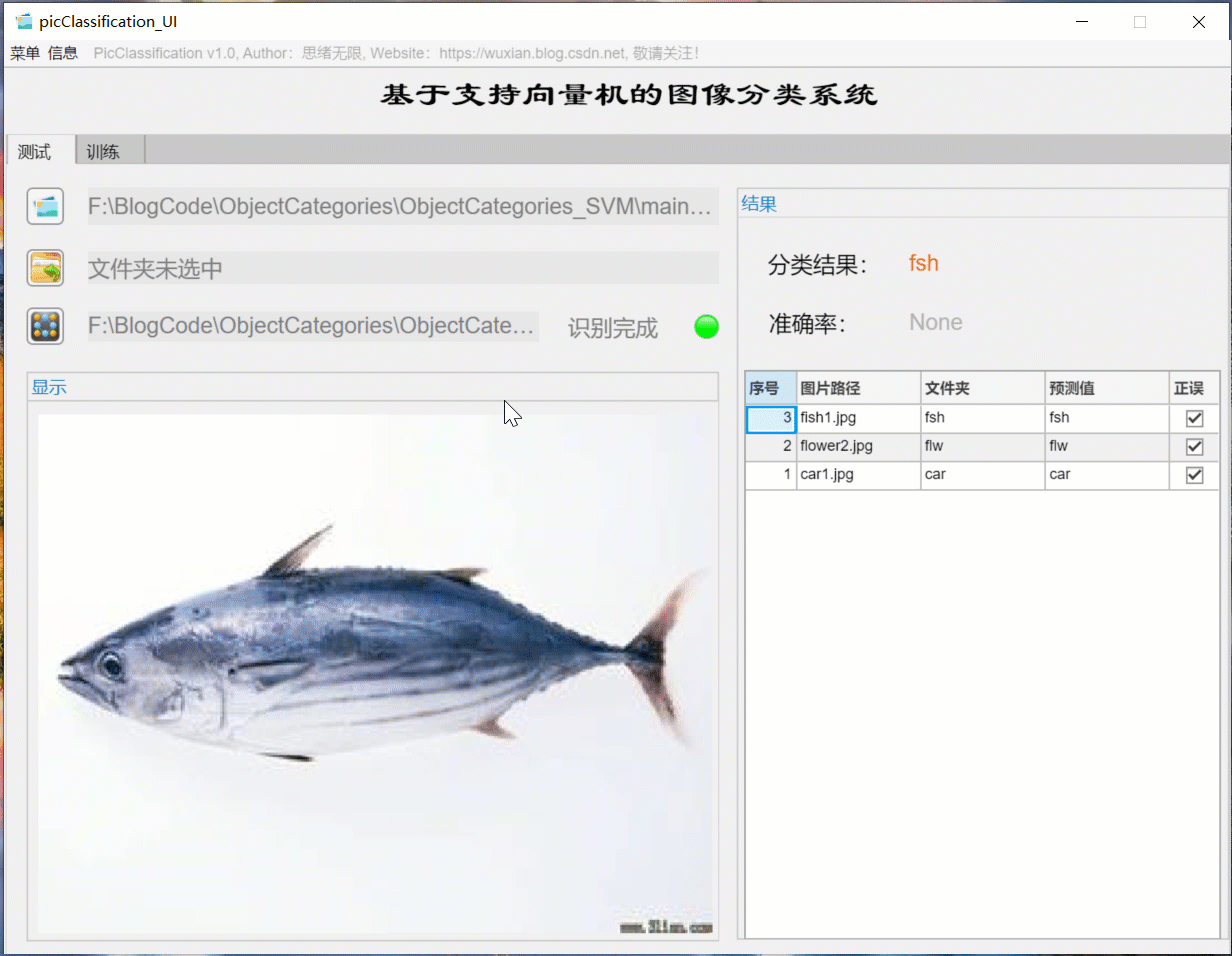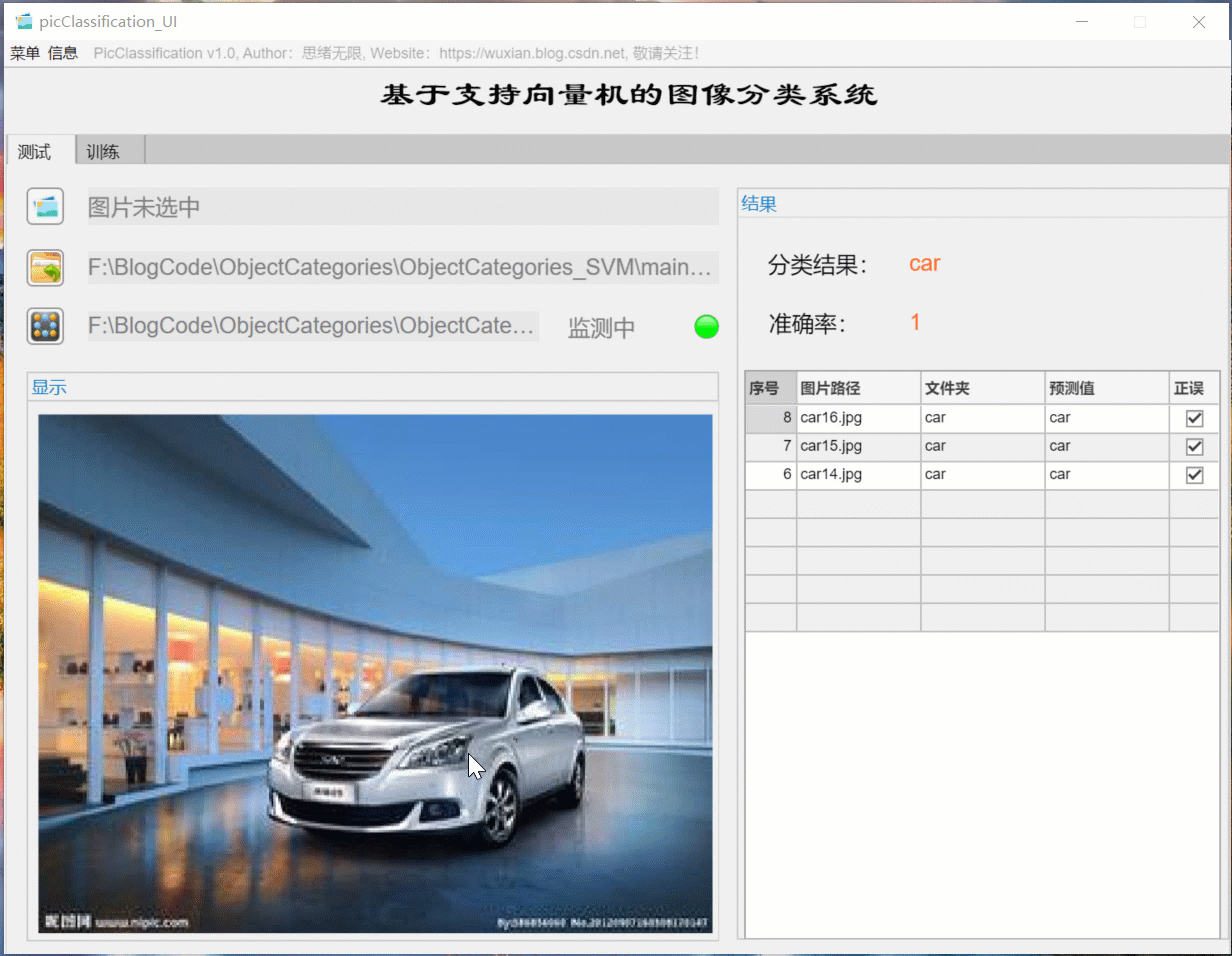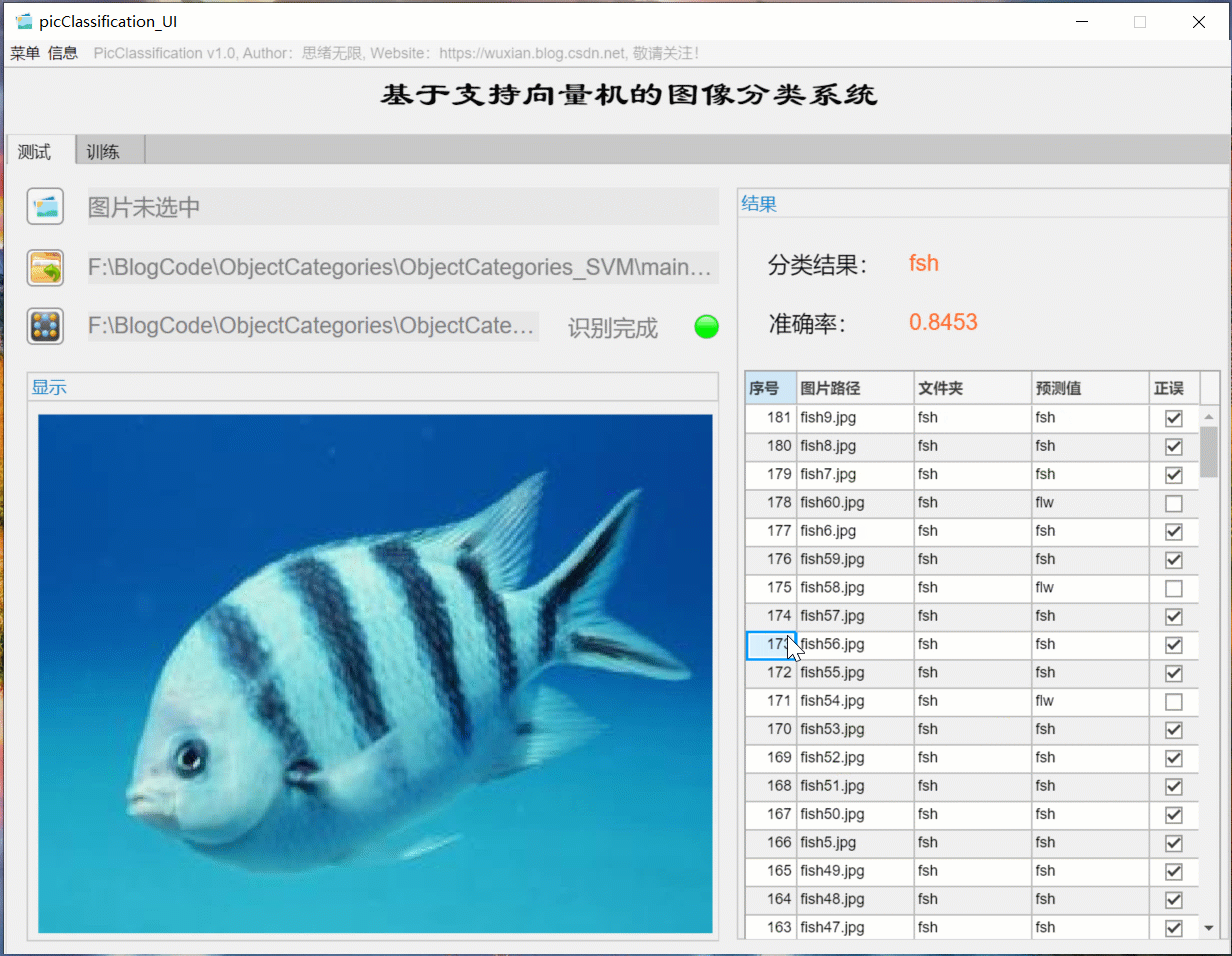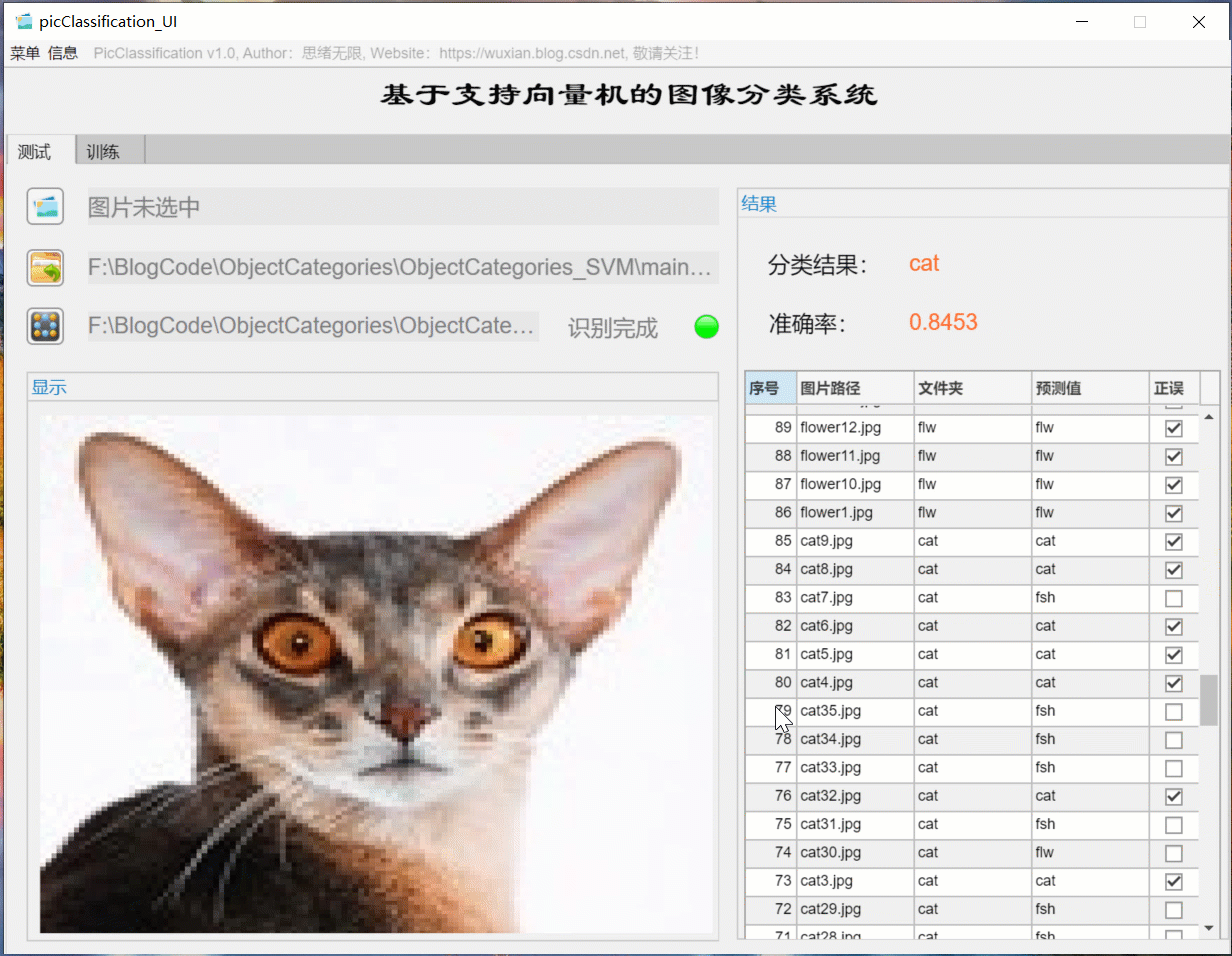
(二)批量圖片識別+分類結果展示
對于需要批量識別的情況,可選擇界面中的檔案夾按鈕,選擇一個待測驗的圖片檔案夾,系統自動識別檔案夾下的檔案并進行分類識別,在此程序中識別結果展示在右側,包括分類結果、準確率、圖片的歷史記錄,用戶可點擊右側的結果記錄表格中的對應序號,回看圖片以及對應的識別結果,該部分演示如下圖所示:
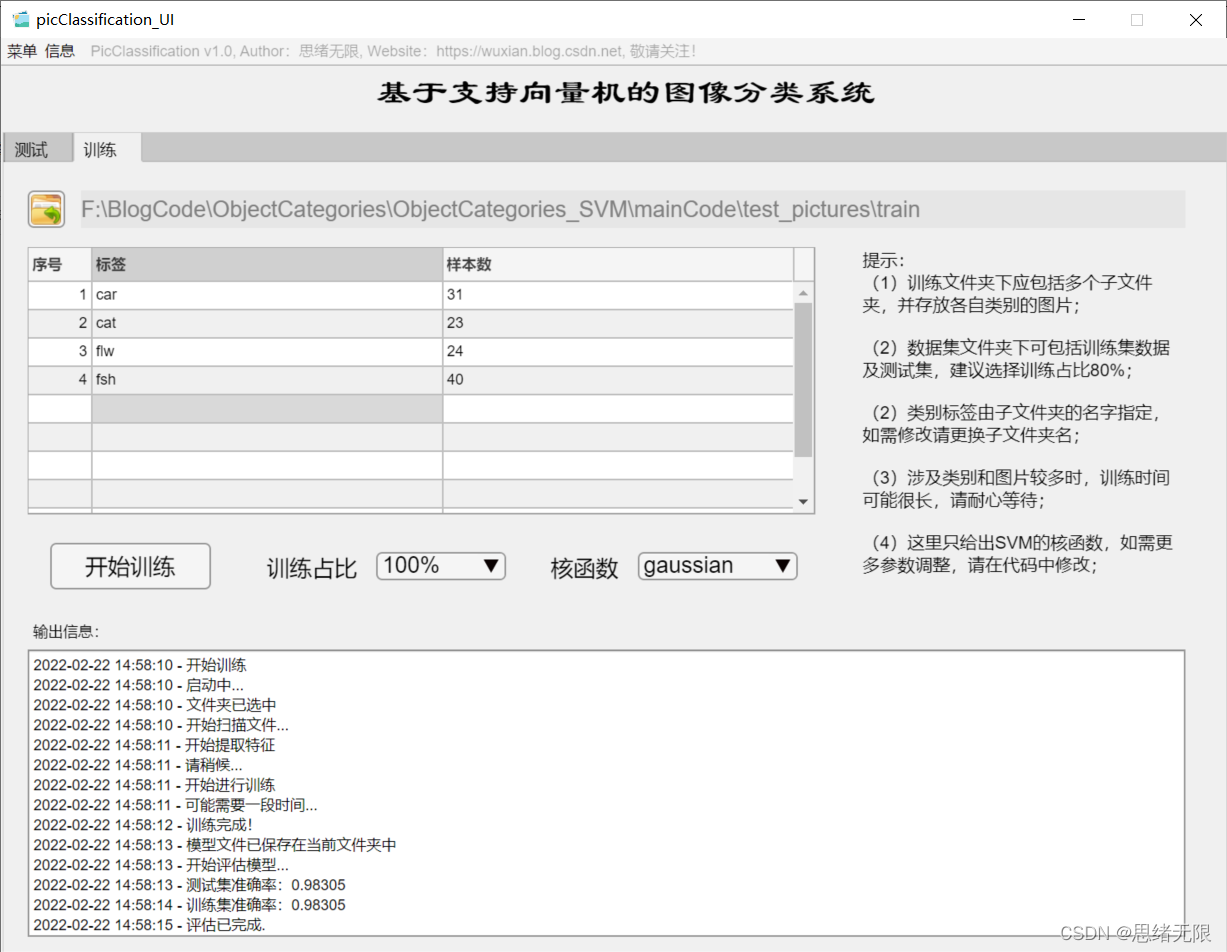
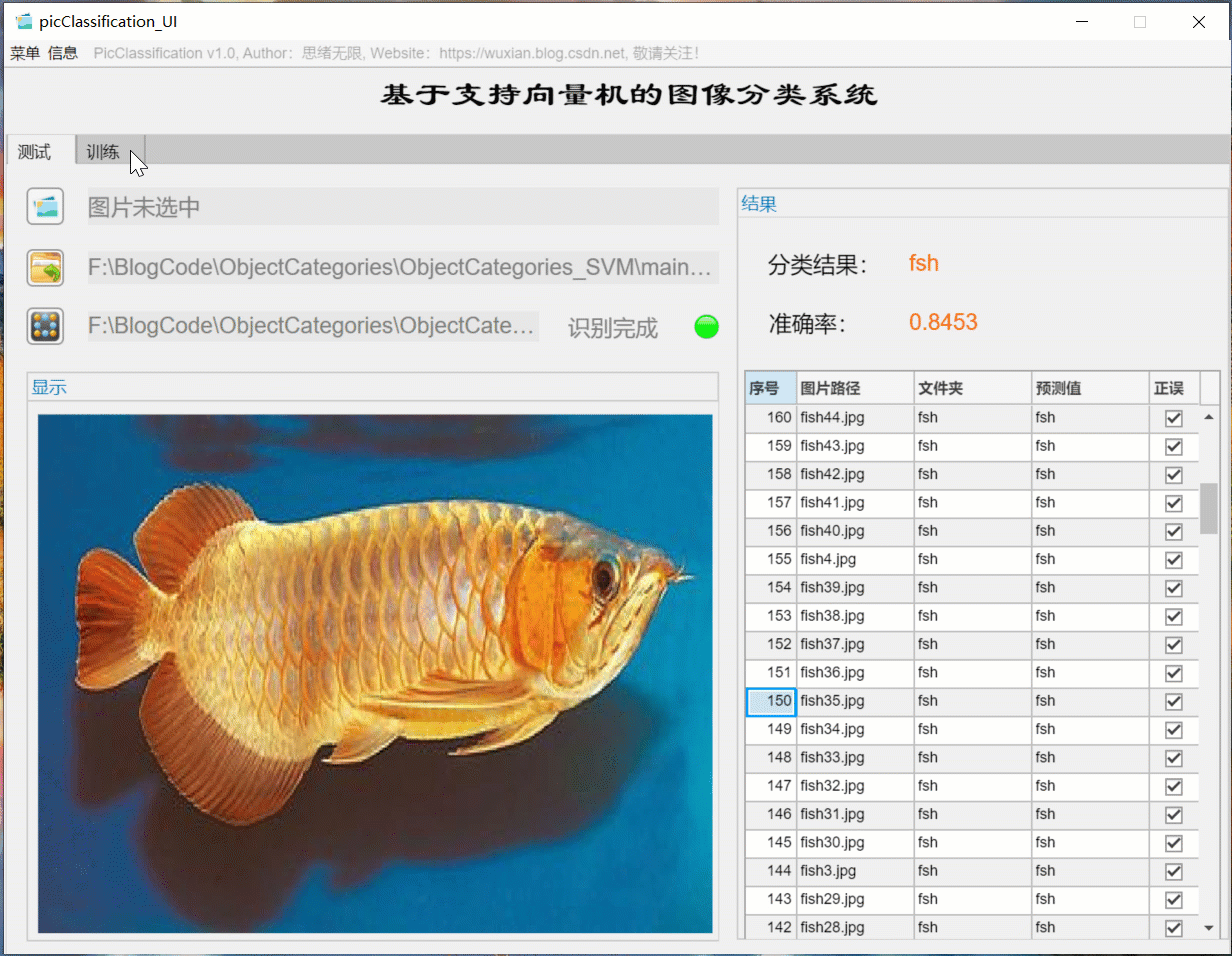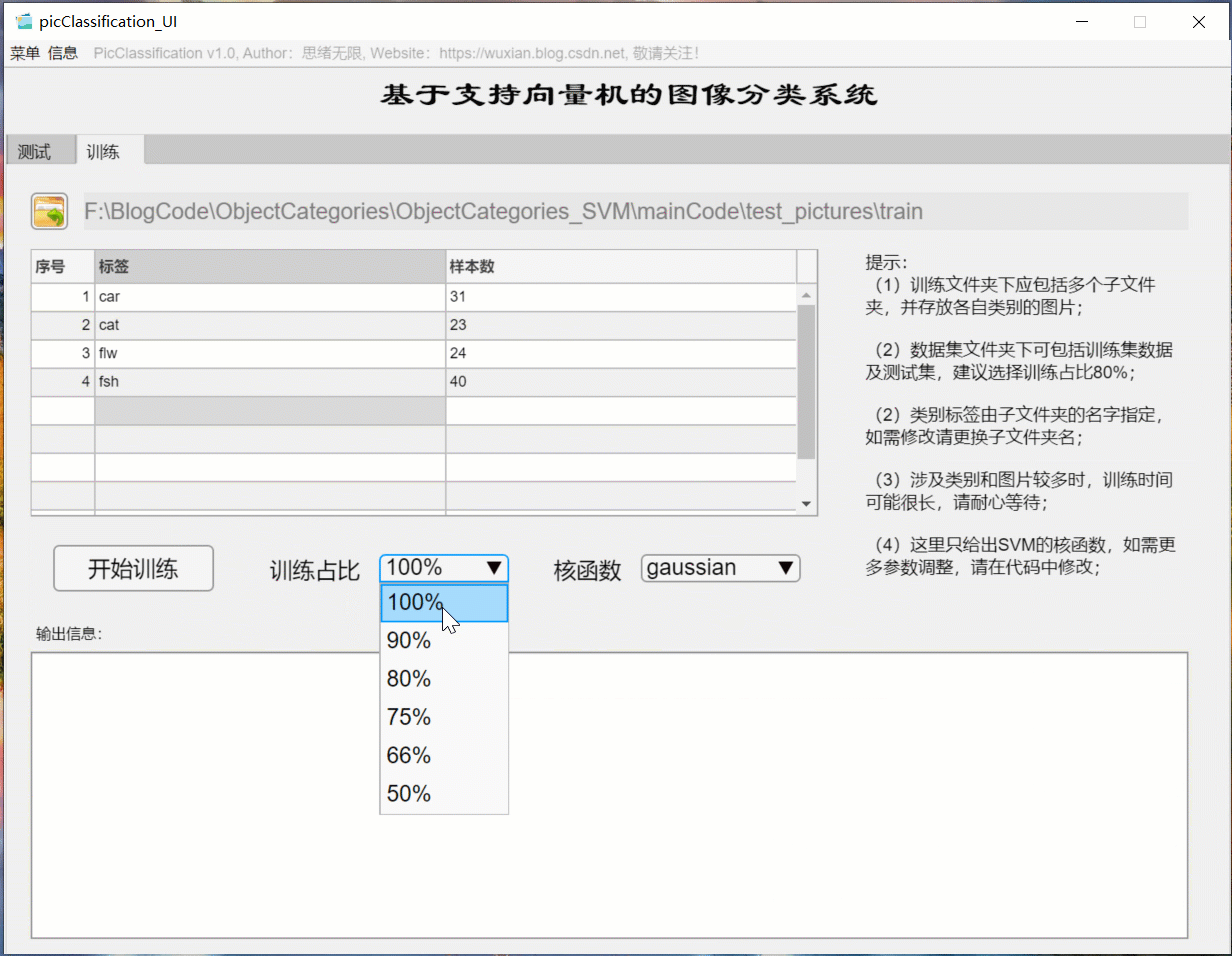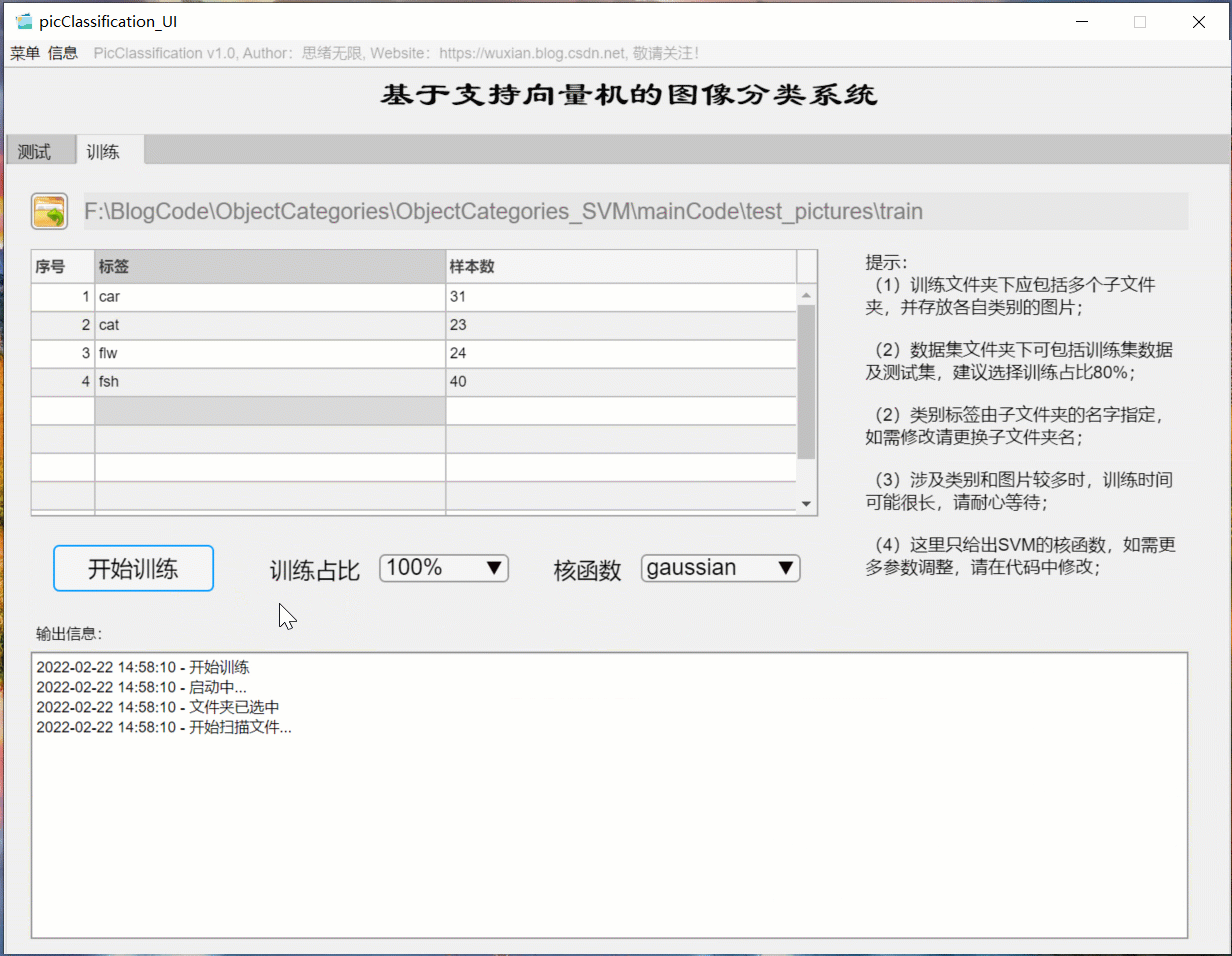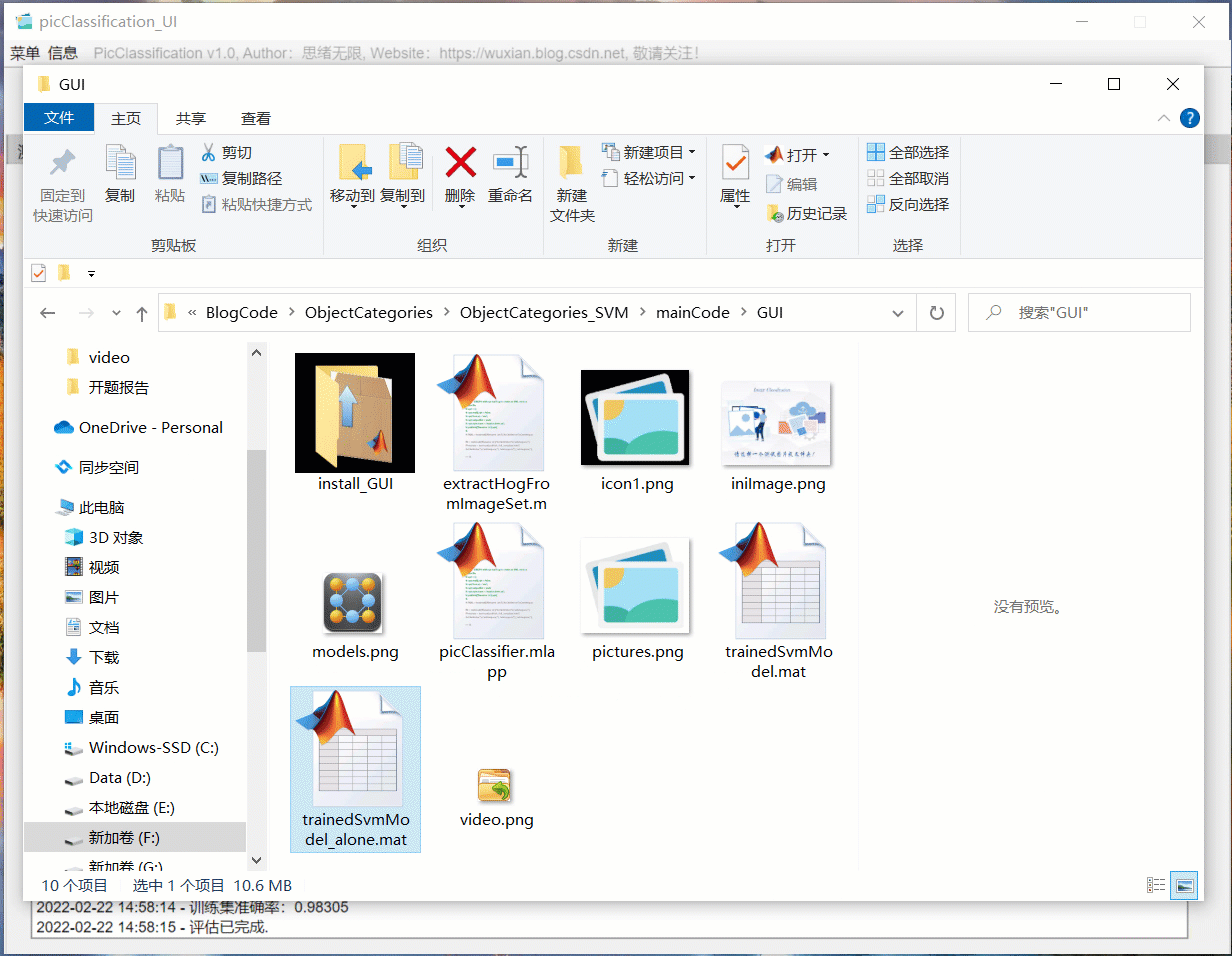
(三)自定義模型訓練+引數設定+自動訓練
如果想更換資料集并重新訓練模型,這時只需要點擊“訓練”選項卡,可切換至訓練界面,如下圖所示,可選擇一個自定義的圖片檔案夾,該檔案夾下包含多個以類別命名的子檔案夾,系統自動將檔案夾的名字作為每一類的標簽,并將讀取的結果顯示在界面中,可以選擇訓練占比和核函式的訓練設定,點擊“開始訓練”即可自動進行訓練,訓練的程序資訊顯示在界面上,最終可以得到訓練測驗集準確率,以及各類別的混淆矩陣結果,模型自動保存在當前檔案夾下供后續選擇,
2. Caltech 101資料集
提到分類任務的資料集很容易想到ImageNet,它無疑是個巨大的訓練圖庫,對于我們自行訓練和測驗其實是非常費力的事情(除非你擁有高端設備),所以我并不推薦在學習階段就使用,至于早前不少論文中廣泛使用的CIFAR10 / CIFAR100以及MNIST資料集,它們的尺寸過小,且本身任務比較簡單,目前已不在普遍使用(水論文除外),所以這里我們選擇的資料集是更貼近真實情況的Caltech 101資料集,也是當前非常流行的資料集,
Caltech-101 Dataset是由 101 個類別的物件圖片組成的資料集,它主要用于目標識別和影像分類,官網地址為https://www.vision.caltech.edu/Image_Datasets/Caltech101/,該資料集不同類別有 40 至 800 張圖片,每張圖片的大小在 300 * 200 像素,且資料集的發布者均已標注對應的目標以供使用,該資料集由加州理工學院的李菲菲、馬克安德烈托和 Marc’Aurelio Ranzato 于 2003 年 9 月收集,相關論文有《Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories》、《One-Shot learning of object categories》等,

下載完成后的資料集檔案如上圖所示,解壓后即可看到其中包含101個子檔案夾,每個檔案夾對應一個類別的圖片,檔案夾的名字表示對應的標簽,由于該資料集檔案數目較大,這里選取其中的10類如下圖所示,將這幾個檔案夾復制到新建的檔案夾進行實驗,最終確定所用的資料集,
資料集準備完畢,現在可以通過檔案夾讀取圖片了,在MATLAB中可使用imageDatastore函式方便地批量讀取圖片集,它通過遞回掃描檔案夾目錄,將每個檔案夾名稱自動作為影像的標簽,該部分代碼如下:
clear
clc
rng default % 保證結果運行一致
mpath = matlab.desktop.editor.getActiveFilename; % 程式所在目錄
[pathstr,~]=fileparts(mpath);
cd(pathstr); % 自動切換至程式所在目錄
imgDir = fullfile("../10_ObjectCategories/");
% imageDatastore遞回掃描目錄,將每個檔案夾名稱自動作為影像的標簽
dataSet = imageDatastore(imgDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
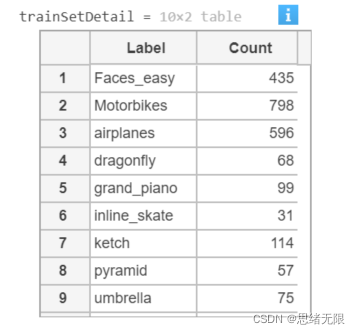
至此讀取到的資料集被存放在dataSet變數中,可以簡單查看訓練和測驗集每類標簽的樣本個數,顯示代碼如下:
trainSetDetail = countEachLabel(dataSet) % 訓練資料
執行以上代碼運行結果如下:
這里展示一下讀取到的圖片,代碼如下所示:
figure
imshow(dataSet.Files{520});
執行該代碼可以看到如下的運行結果:

這里我們劃分訓練和測驗資料集,使用留一法將80%的資料用于訓練,剩余的資料用于模型測驗,將訓練和測驗檔案保存在trainSet.Files及testSet.Files變數中,對應的標簽則存在Label中,該部分代碼如下:
indices = crossvalind('Kfold',dataSet.Labels,5); % 進行交叉驗證劃分
t=1;
test=(indices == t);
train=~test;
% 訓練資料集
trainSet.Files = dataSet.Files(train);
trainSet.Labels = dataSet.Labels(train);
% 測驗資料集
testSet.Files = dataSet.Files(test);
testSet.Labels = dataSet.Labels(test);
至此完成資料集的讀取和劃分作業,接下來進行特征提取步驟,
3. HOG特征提取
真正用于訓練分類器的資料并不是原始圖片資料,而是先經過特征提取后得到的特征向量,這里使用的特征型別是HOG,也就是方向梯度直方圖,所以這里重要的一點是正確提取出HOG特征,extractHOGFeatures是MATLAB自帶的HOG特征提取函式,該函式不僅可以有效提取特征,還可以回傳特征的可視化結果以方便展示,該部分代碼如下:
cellSize = [4 4];
img = readimage(dataSet, 23);
img = rgb2gray(img); % 灰度化圖片
img = imbinarize(img);
img = imresize(img, [100 100]);
[hog_4x4, vis4x4] = extractHOGFeatures(img,'CellSize',[4 4]);
hogFeatureSize = length(hog_4x4);
% 提取HOG特征
tStart = tic;
[trainFeatures, trainLabels] = extractHogFromImageSet(trainSet, hogFeatureSize, cellSize); % 訓練集特征提取
[testFeatures, testLabels] = extractHogFromImageSet(testSet, hogFeatureSize, cellSize); % 測驗集特征提取
tEnd = toc(tStart);
fprintf('提取特征所用時間:%.2f秒\n', tEnd);
以上代碼首先進行圖片灰度化、二值化、尺寸調整等預處理操作,然后呼叫extractHogFromImageSet函式提取訓練和測驗集的HOG特征,由于圖片數量眾多,提取特征程序尚需一定時間,這里對訓練集、測驗集提取程序進行計時,因計算機算力不同,執行時間可能會不一致,最終列印特征提取所用的時間,
提取特征所用的時間:18.73秒
4. 訓練和評估模型
下面我們使用以上提取的HOG特征構建支持向量機模型,利用提取的訓練集特征進行訓練,首先利用templateSVM函式構建支持向量機模板引數,選擇gaussian核函式,執行標準化處理資料,顯示訓練程序;利用fitcecoc函式執行訓練程序,其代碼如下,
% 訓練支持向量機
t = templateSVM('SaveSupportVectors',true, 'Standardize', true, 'KernelFunction','gaussian', ...
'KernelScale', 'auto','Verbose', 0); % 利用polynomial核函式, 標準化處理資料,顯示訓練程序(verbose取0時取消顯示)
tStart = tic; % 計時開始
classifier = fitcecoc(trainFeatures, trainLabels, 'Learner', t); % 訓練SVM模型
tEnd = toc(tStart);
fprintf('訓練模型所用時間:%.2f秒\n', tEnd);
等待訓練完成,我們可以使用訓練好的分類器進行預測,這里先利用測驗集評估模型并計算分類評價指標,對測驗集進行預測的代碼如下:
tStart = tic;
% 對測驗資料集進行預測
predictedLabels = predict(classifier, testFeatures);
tEnd = toc(tStart);
fprintf('模型對測驗集進行預測所用時間:%.2f秒\n', tEnd);
運行結果如下:
模型對測驗集進行預測所用時間:5.75秒
得到了預測結果,可以使用混淆矩陣評估結果,以下代碼首先計算混淆矩陣結果,然后將結果列印出來:
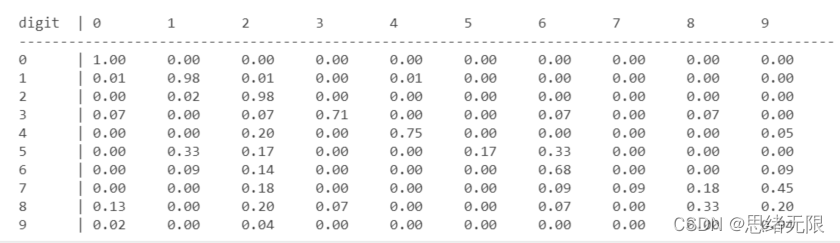
分類準確率可以通過以下代碼進行計算:
accuracy = sum(predictedLabels == testLabels) / numel(testLabels);
fprintf('模型在測驗集上的準確率:%.0f%%\n', accuracy*100);
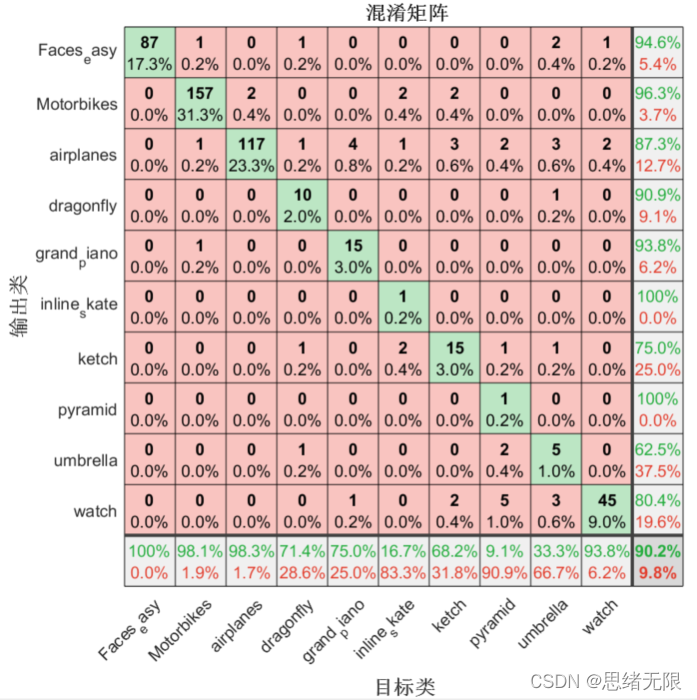
以上代碼顯示了混淆矩陣的結果,但可能還不夠直觀,下面繪制混淆矩陣圖幫助更好了解模型性能:
% 繪制混淆矩陣圖
plotconfusion(testLabels, predictedLabels);
運行代碼后顯示混淆矩陣圖如下圖所示,每行對角線上的網格(綠色網格)處顯示了某類樣本預測正確的數目及其占比,右下角網格表示分類的準確率,可以看出該分類器具有90.2%的總體分類準確率,
為了便于后續測驗,這里保存模型檔案,其代碼如下:
save('trainedSvmModel.mat','classifier');
5. 測驗模型
這里我們選取幾張圖片進行測驗,以便對模型的效果有個更直觀的感受,這部分代碼如下所示:
clear
clc
rng default % 保證結果運行一致
img_test_1 = imread("../10_ObjectCategories/airplanes/image_0137.jpg");
img_test_2 = imread("../10_ObjectCategories/dragonfly/image_0001.jpg");
img_test_3 = imread("../10_ObjectCategories/inline_skate/image_0003.jpg");
img_test_4 = imread("../10_ObjectCategories/ketch/image_0005.jpg");
img_test_5 = imread("../10_ObjectCategories/Motorbikes/image_0006.jpg");
img_test_6 = imread("../10_ObjectCategories/umbrella/image_0010.jpg");
讀取圖片后,首先利用imshow函式將幾張圖片顯示出來,采用subplot函式劃分圖片坐標軸區域,以便將6張圖片展示出來:
figure;
subplot(2, 3, 1); imshow(img_test_1);
subplot(2, 3, 2); imshow(img_test_2);
subplot(2, 3, 3); imshow(img_test_3);
subplot(2, 3, 4); imshow(img_test_4);
subplot(2, 3, 5); imshow(img_test_5);
subplot(2, 3, 6); imshow(img_test_6);
執行以上代碼,運行結果如下圖所示:

與上一章類似,首先提取HOG特征,這里將提取到的特征進行可視化展示,并將其與原始圖片進行對比,其代碼如下:
img = rgb2gray(img_test_1);
img = imbinarize(img);
% img = imresize(img, [100 100]);
[hog_1, vis_1] = extractHOGFeatures(img,'CellSize',[4 4]);
figure
subplot(2,1,1);
imshow(img_test_1)
title("原始影像")
subplot(2, 1, 2)
plot(vis_1);
title("特征影像")
運行以上代碼,特征提取的影像運行結果如下圖所示:

接下來我們載入前面訓練好的模型,對讀取到的圖片進行預測并顯示結果,值得注意的是,每張圖片在預測前的預處理作業,這里通過代碼將灰度化、二值化、HOG特征的結果可視化在同一個繪圖視窗中,其代碼如下:
load("trainedSvmModel.mat", "classifier");
img_gray = rgb2gray(img_test_4);
img_bin = imbinarize(img_gray);
img = imresize(img_bin, [100 100]);
[hog_4, vis_4] = extractHOGFeatures(img,'CellSize',[4 4]);
% 對測驗資料集進行預測
fea_4 = extractHOGFeatures(img,'CellSize',[4 4]);
predictedLabels = predict(classifier, fea_4);
fprintf("預測結果:%s",predictedLabels);
figure
subplot(2,2,1)
imshow(img_test_4);
title(["預測結果:", char(predictedLabels)])
subplot(2,2,2)
imshow(img_gray);
subplot(2,2,3)
imshow(img_bin);
subplot(2,2,4)
plot(vis_4)
運行以上代碼,顯示結果如下:

下載鏈接
若您想獲得博文中涉及的實作完整全部程式檔案(包括資料集,m, UI檔案等,如下圖),這里已打包上傳至博主的面包多平臺和CSDN下載資源,本資源已上傳至面包多網站和CSDN下載資源頻道,可以點擊以下鏈接獲取,已將所有涉及的檔案同時打包到里面,點擊即可運行,完整檔案截圖如下:
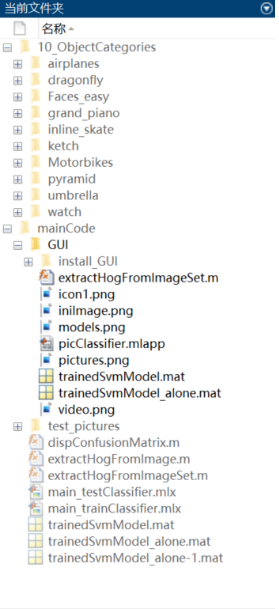
在檔案夾下的資源顯示如下:
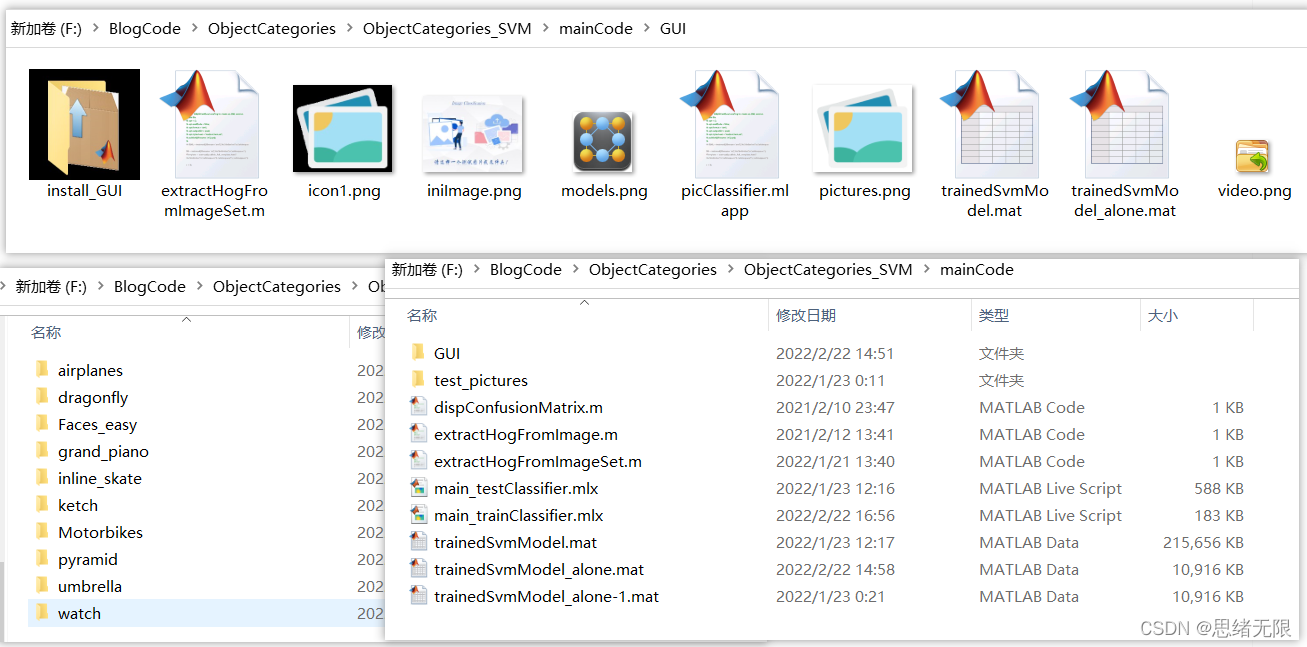
注意:本資源已經過除錯通過,下載后可通過MATLAB R2021b運行;訓練主程式為main_trainClassifier.mlx,測驗程式可運行main_testClassifier.mlx,要使用GUI界面請運行picClassifier.mlapp檔案;其它程式檔案大部分為函式而非可直接運行的腳本,使用時請勿直接點擊運行!???
完整資源下載鏈接1:博主在面包多網站上的完整資源下載頁
完整資源下載鏈接2:https://mianbaoduo.com/o/bread/mbd-YpiTl5ht
注:以上兩個鏈接為面包多平臺下載鏈接,CSDN下載資源頻道下載鏈接稍后上傳,
結束語
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,
用心整理知識,只出精品博文轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458552.html
標籤:其他
上一篇:虎牙實時計算平臺服務的SLA之路