- 表情識別資料集
- 搭建表情識別的模型
- 資料增強的批量訓練
- 系統UI界面的實作
點擊跳轉至文末博文涉及的全部檔案下載頁
下載鏈接:博主在面包多網站上的完整資源下載頁
人臉表情識別介紹與演示視頻鏈接:https://www.bilibili.com/video/BV18C4y1H7mH/
1. 前言
在這個人工智能成為超級大熱門的時代,人臉表情識別已成為其中的一項研究熱點,而卷積神經網路、深度信念網路和多層感知器等相關演算法在人臉面部表情識別領域的運用最為廣泛,面部的表情中包含了太多的資訊,輕微的表情變化都會反映出人心理的變化,可想而知如果機器能敏銳地識別人臉中表達的情感該是多么令人興奮的事,
學習和研究了挺久的深度學習,偶然看到IEEE上面一篇質量很高的文章,里面介紹的是利用深度神經網路實作的面部表情識別,研讀下來讓我深受啟發,于是自己動手做了這個專案,如今SCI論文已投稿,這里特此將前期作業作個總結,希望能給類似作業的朋友帶來一點幫助,由于論文尚未公開,這里使用的是已有的模型——如今CNN的主流框架之mini_XCEPTION,該模型性能也已是不錯的了,論文中改進的更高性能模型尚不便給出,后面會分享給大家,敬請關注,
2. 表情識別資料集
目前,現有的公開的人臉表情資料集比較少,并且數量級比較小,比較有名的廣泛用于人臉表情識別系統的資料集Extended Cohn-Kanada (CK+)是由P.Lucy收集的,CK+資料集包含123 個物件的327 個被標記的表情圖片序列,共分為正常、生氣、蔑視、厭惡、恐懼、開心和傷心七種表情,對于每一個圖片序列,只有最后一幀被提供了表情標簽,所以共有327 個影像被標記,為了增加資料,我們把每個視頻序列的最后三幀影像作為訓練樣本,這樣CK+資料總共被標記的有981 張圖片,這個資料庫是人臉表情識別中比較流行的一個資料庫,很多文章都會用到這個資料做測驗,可通過下面的鏈接下載,
官網鏈接:The Extended Cohn-Kanade Dataset(CK+)
網盤鏈接:百度網盤下載(提取碼:8r15)

Kaggle是Kaggle人臉表情分析比賽提供的一個資料集,該資料集含28709 張訓練樣本,3859 張驗證資料集和3859 張測驗樣本,共35887 張包含生氣、厭惡、恐懼、高興、悲傷、驚訝和正常七種類別的影像,影像解析度為48×48,該資料集中的影像大都在平面和非平面上有旋轉,并且很多影像都有手、頭發和圍巾等的遮擋物的遮擋,該資料庫是2013年Kaggle比賽的資料,由于這個資料庫大多是從網路爬蟲下載的,存在一定的誤差性,這個資料庫的人為準確率是65%±5%,
官網鏈接:FER2013
網盤鏈接:百度網盤下載(提取碼:t7xj)

由于FER2013資料集資料更加齊全,同時更加符合實際生活的場景,所以這里主要選取FER2013訓練和測驗模型,為了防止網路過快地過擬合,可以人為的做一些影像變換,例如翻轉,旋轉,切割等,上述操作稱為資料增強,資料操作還有另一大好處是擴大資料庫的資料量,使得訓練的網路魯棒性更強,下載資料集保存在fer2013的檔案夾下,為了對資料集進行處理,采用如下代碼載入和進行圖片預處理:
import pandas as pd
import cv2
import numpy as np
dataset_path = 'fer2013/fer2013/fer2013.csv' # 檔案保存位置
image_size=(48,48) # 圖片大小
# 載入資料
def load_fer2013():
data = https://www.cnblogs.com/sixuwuxian/archive/2022/04/19/pd.read_csv(dataset_path)
pixels = data['pixels'].tolist()
width, height = 48, 48
faces = []
for pixel_sequence in pixels:
face = [int(pixel) for pixel in pixel_sequence.split(' ')]
face = np.asarray(face).reshape(width, height)
face = cv2.resize(face.astype('uint8'),image_size)
faces.append(face.astype('float32'))
faces = np.asarray(faces)
faces = np.expand_dims(faces, -1)
emotions = pd.get_dummies(data['emotion']).as_matrix()
return faces, emotions
# 將資料歸一化
def preprocess_input(x, v2=True):
x = x.astype('float32')
x = x / 255.0
if v2:
x = x - 0.5
x = x * 2.0
return x
載入資料后將資料集劃分為訓練集和測驗集,在程式中呼叫上面的函式代碼如下:
from load_and_process import load_fer2013
from load_and_process import preprocess_input
from sklearn.model_selection import train_test_split
# 載入資料集
faces, emotions = load_fer2013()
faces = preprocess_input(faces)
num_samples, num_classes = emotions.shape
# 劃分訓練、測驗集
xtrain, xtest,ytrain,ytest = train_test_split(faces, emotions,test_size=0.2,shuffle=True)
3. 搭建表情識別的模型
接下來就是搭建表情識別的模型了,這里用到的是CNN的主流框架之mini_XCEPTION,XCEPTION是Google繼Inception后提出的對Inception v3的另一種改進,主要是采用深度可分離的卷積(depthwise separable convolution)來替換原來Inception v3中的卷積操作,XCEPTION的網路結構在ImageNet資料集(Inception v3的設計解決目標)上略優于Inception v3,并且在包含3.5億個影像甚至更大的影像分類資料集上明顯優于Inception v3,而兩個結構保持了相同數目的引數,性能增益來自于更加有效地使用模型引數,詳細可參考論文:Xception: Deep Learning with Depthwise Separable Convolutions,論文Real-time Convolutional Neural Networks for Emotion and Gender Classification等,
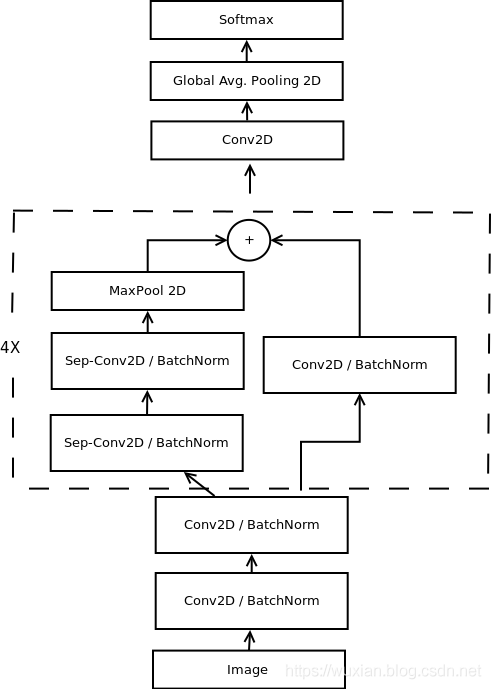
既然這樣的網路能獲得更好結果又是主流,那當然有必要作為對比演算法實作以下了,這里博主模型這部分的代碼參考了GitHub:https://github.com/oarriaga/face_classification中的模型(其他地方也能找到這個模型的類似代碼),模型框圖如上圖所示,其代碼如下:
def mini_XCEPTION(input_shape, num_classes, l2_regularization=0.01):
regularization = l2(l2_regularization)
# base
img_input = Input(input_shape)
x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,
use_bias=False)(img_input)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# module 1
residual = Conv2D(16, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(16, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(16, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
# module 2
residual = Conv2D(32, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(32, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(32, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
# module 3
residual = Conv2D(64, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(64, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(64, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
# module 4
residual = Conv2D(128, (1, 1), strides=(2, 2),
padding='same', use_bias=False)(x)
residual = BatchNormalization()(residual)
x = SeparableConv2D(128, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = SeparableConv2D(128, (3, 3), padding='same',
kernel_regularizer=regularization,
use_bias=False)(x)
x = BatchNormalization()(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = layers.add([x, residual])
x = Conv2D(num_classes, (3, 3),
#kernel_regularizer=regularization,
padding='same')(x)
x = GlobalAveragePooling2D()(x)
output = Activation('softmax',name='predictions')(x)
model = Model(img_input, output)
return model
4. 資料增強的批量訓練
神經網路的訓練需要大量的資料,資料的量決定了網路模型可以達到的高度,網路模型盡量地逼近這個高度,然而對于人臉表情的資料來說,都只存在少量的資料Extended Cohn-Kanada (CK+)的資料量是遠遠不夠的,并且CK+多是比較夸張的資料,Kaggle Fer2013資料集也不過只有3萬多資料量,而且有很多遮擋、角度等外界影響因素,既然收集資料要花費很大的人力物力,那么我們就用技術解決這個問題,為避免重復開發首先還是看看有沒有寫好的庫,博主又通讀了遍Keras官方檔案,其中ImageDataGenerator的圖片生成器就可完成這一目標,
為了盡量利用我們有限的訓練資料,我們將通過一系列隨機變換堆資料進行提升,這樣我們的模型將看不到任何兩張完全相同的圖片,這有利于我們抑制過擬合,使得模型的泛化能力更好,在Keras中,這個步驟可以通過keras.preprocessing.image.ImageGenerator來實作,這個類使你可以:在訓練程序中,設定要施行的隨機變換通過.flow或.flow_from_directory(directory)方法實體化一個針對影像batch的生成器,這些生成器可以被用作keras模型相關方法的輸入,如fit_generator,evaluate_generator和predict_generator,——Keras官方檔案
ImageDataGenerator()是一個圖片生成器,同時也可以在batch中對資料進行增強,擴充資料集大小(比如進行旋轉,變形,歸一化等),增強模型的泛化能力,結合前面的模型和資料訓練部分的代碼如下:
"""
Description: 訓練人臉表情識別程式
"""
from keras.callbacks import CSVLogger, ModelCheckpoint, EarlyStopping
from keras.callbacks import ReduceLROnPlateau
from keras.preprocessing.image import ImageDataGenerator
from load_and_process import load_fer2013
from load_and_process import preprocess_input
from models.cnn import mini_XCEPTION
from sklearn.model_selection import train_test_split
# 引數
batch_size = 32
num_epochs = 10000
input_shape = (48, 48, 1)
validation_split = .2
verbose = 1
num_classes = 7
patience = 50
base_path = 'models/'
# 構建模型
model = mini_XCEPTION(input_shape, num_classes)
model.compile(optimizer='adam', # 優化器采用adam
loss='categorical_crossentropy', # 多分類的對數損失函式
metrics=['accuracy'])
model.summary()
# 定義回呼函式 Callbacks 用于訓練程序
log_file_path = base_path + '_emotion_training.log'
csv_logger = CSVLogger(log_file_path, append=False)
early_stop = EarlyStopping('val_loss', patience=patience)
reduce_lr = ReduceLROnPlateau('val_loss', factor=0.1,
patience=int(patience/4),
verbose=1)
# 模型位置及命名
trained_models_path = base_path + '_mini_XCEPTION'
model_names = trained_models_path + '.{epoch:02d}-{val_acc:.2f}.hdf5'
# 定義模型權重位置、命名等
model_checkpoint = ModelCheckpoint(model_names,
'val_loss', verbose=1,
save_best_only=True)
callbacks = [model_checkpoint, csv_logger, early_stop, reduce_lr]
# 載入資料集
faces, emotions = load_fer2013()
faces = preprocess_input(faces)
num_samples, num_classes = emotions.shape
# 劃分訓練、測驗集
xtrain, xtest,ytrain,ytest = train_test_split(faces, emotions,test_size=0.2,shuffle=True)
# 圖片產生器,在批量中對資料進行增強,擴充資料集大小
data_generator = ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=10,
width_shift_range=0.1,
height_shift_range=0.1,
zoom_range=.1,
horizontal_flip=True)
# 利用資料增強進行訓練
model.fit_generator(data_generator.flow(xtrain, ytrain, batch_size),
steps_per_epoch=len(xtrain) / batch_size,
epochs=num_epochs,
verbose=1, callbacks=callbacks,
validation_data=https://www.cnblogs.com/sixuwuxian/archive/2022/04/19/(xtest,ytest))
以上代碼中設定了訓練時的結果輸出,在訓練結束后會將訓練的模型保存為hdf5檔案到自己指定的檔案夾下,由于資料量大模型的訓練時間會比較長,建議使用GPU加速,訓練結束后測驗得到混淆矩陣如下:
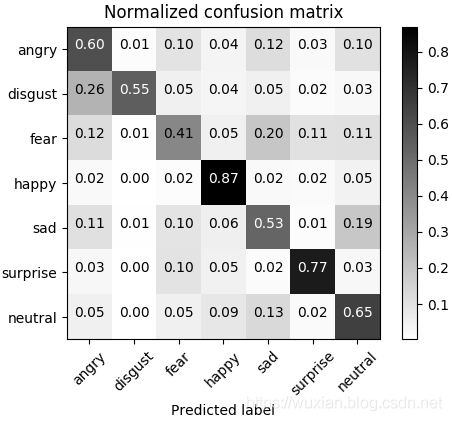
訓練的模型綜合在FER2013資料集上的分類準確率為66%,后續調整之后達到了70%,算是中等偏上水平,其實并非模型不好而是在資料預處理、超引數的選取上有很大的可提升空間,當然也可使用其他的模型,譬如可參考論文:Extended deep neural network for facial emotion recognition,大家可自行研究,這里就不多介紹了,
5. 系統UI界面的實作
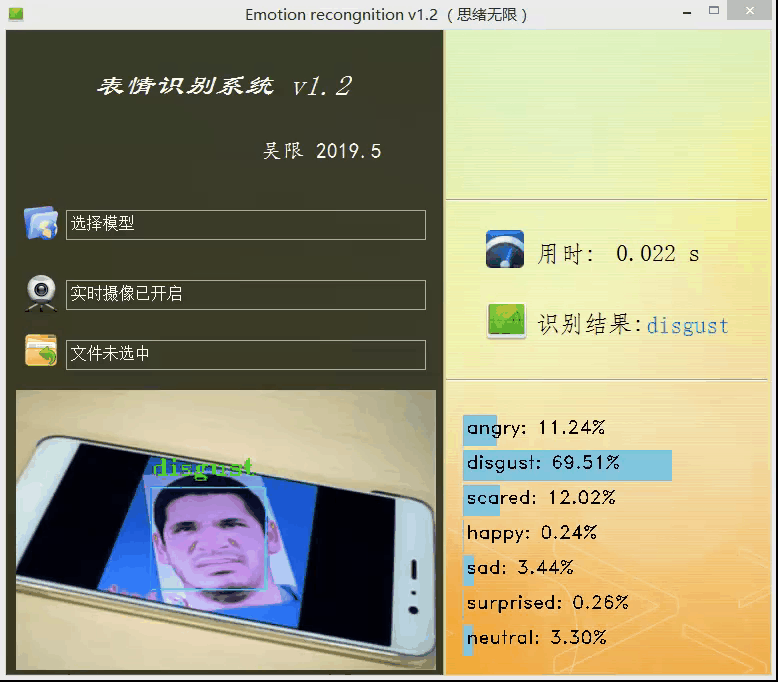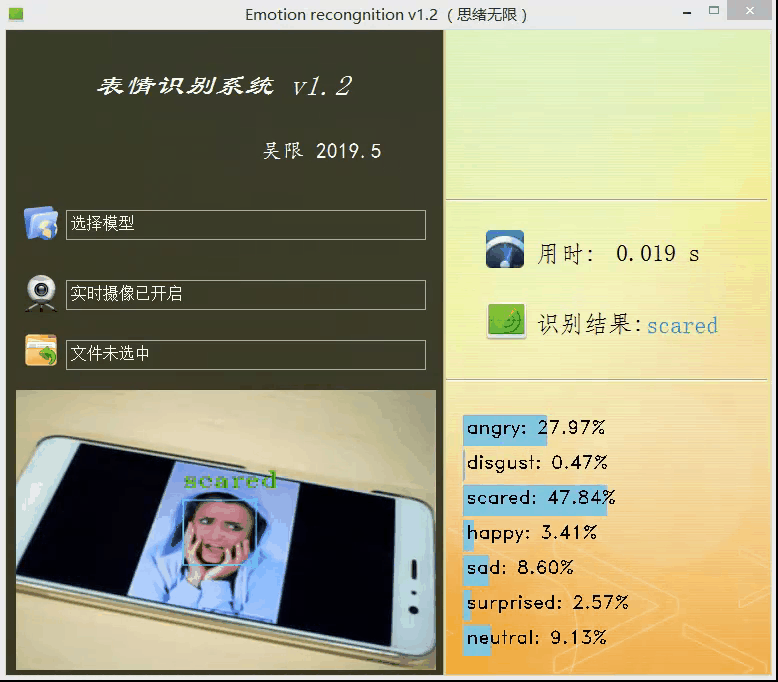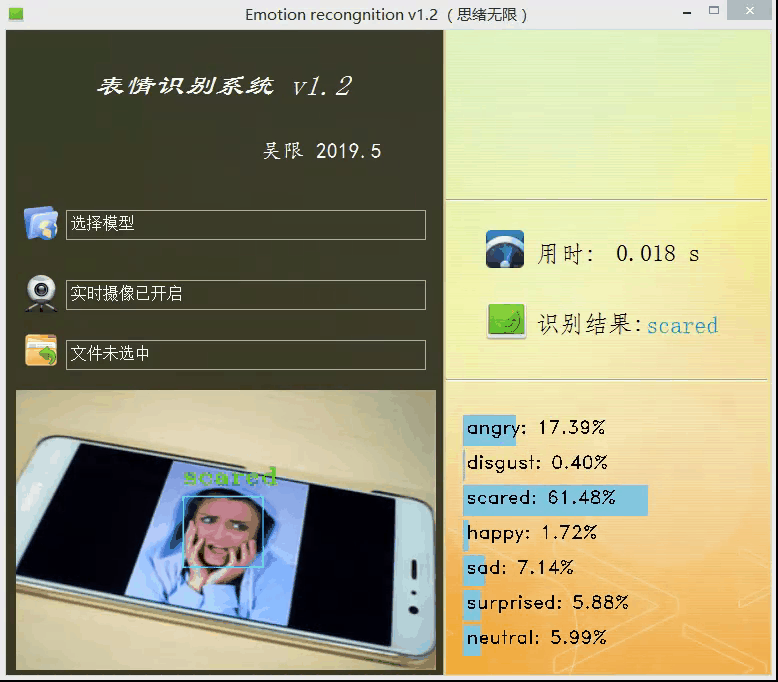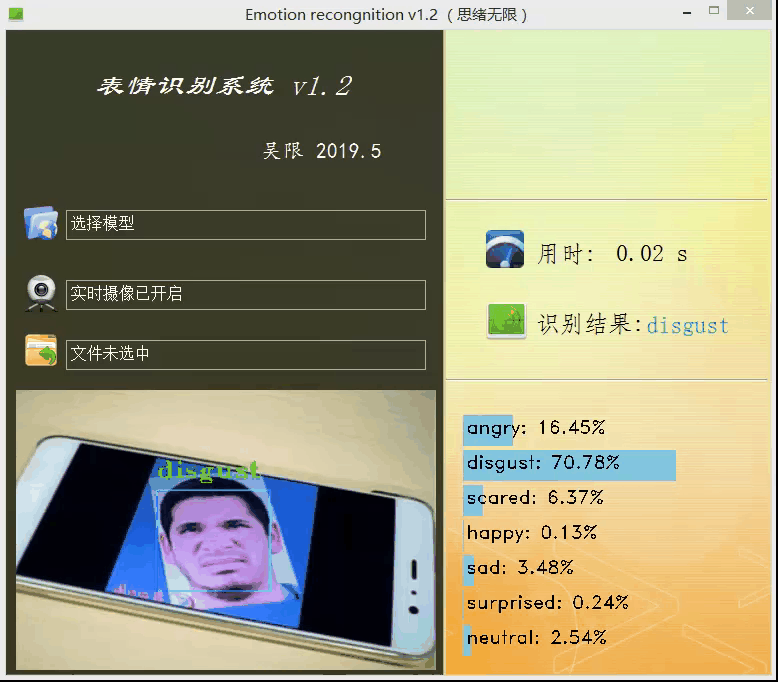
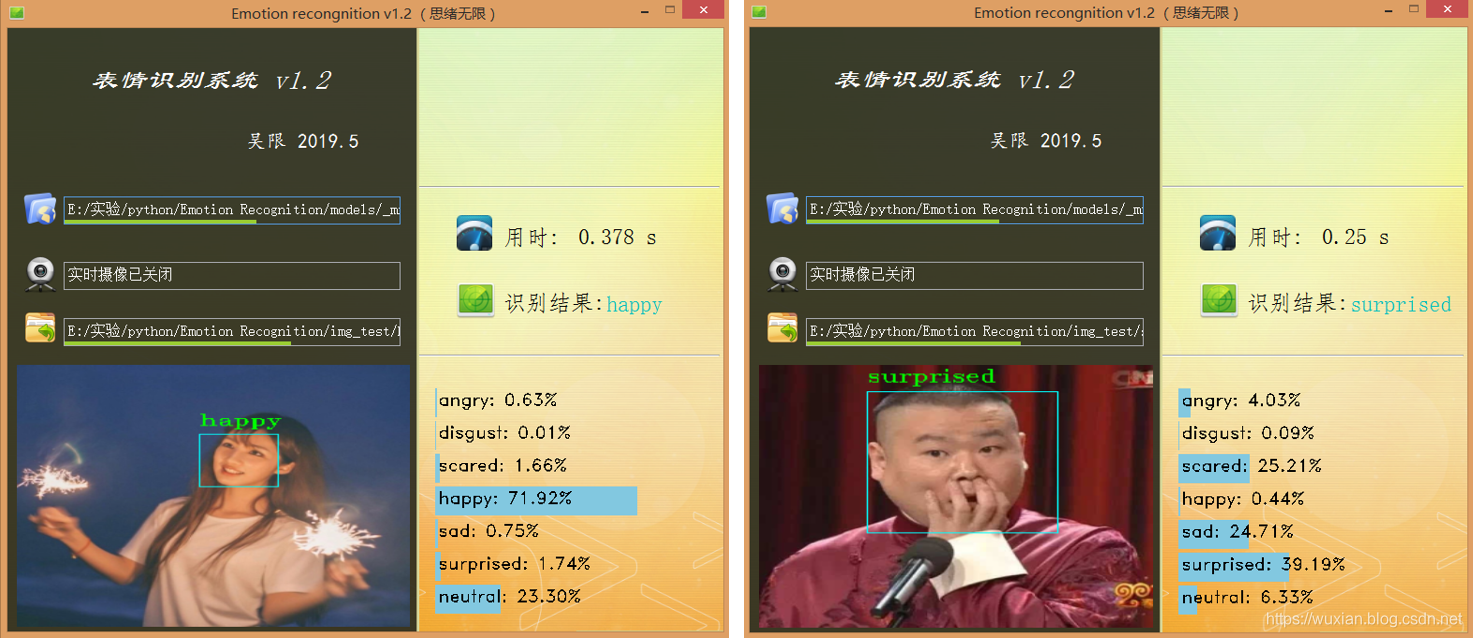
上面的模型訓練好了,但對于我們來說它的作用就只是知道了其準確率還行,其實深度學習的目的最重要還是應用,是時候用上面的模型做點酷酷的東西了,可不可以用上面的模型識別下自己表達的情緒呢?不如做個系統調取攝像頭對實時畫面中的表情進行識別并顯示識別結果,既能可視化的檢測模型的實用性能,同時使得整個專案生動有趣激發自己的創造性,當你向別人介紹你的專案時也顯得高大上,這里采用PyQt5進行設計,首先看一下最后的效果圖,運行后的界面如下:
設計功能:一、可選擇模型檔案后基于該模型進行識別;二、打開攝像頭識別實時畫面中的人臉表情;三、選擇一張人臉圖片,對其中的表情進行識別,選擇一張圖片測驗識別效果,如下圖所示:
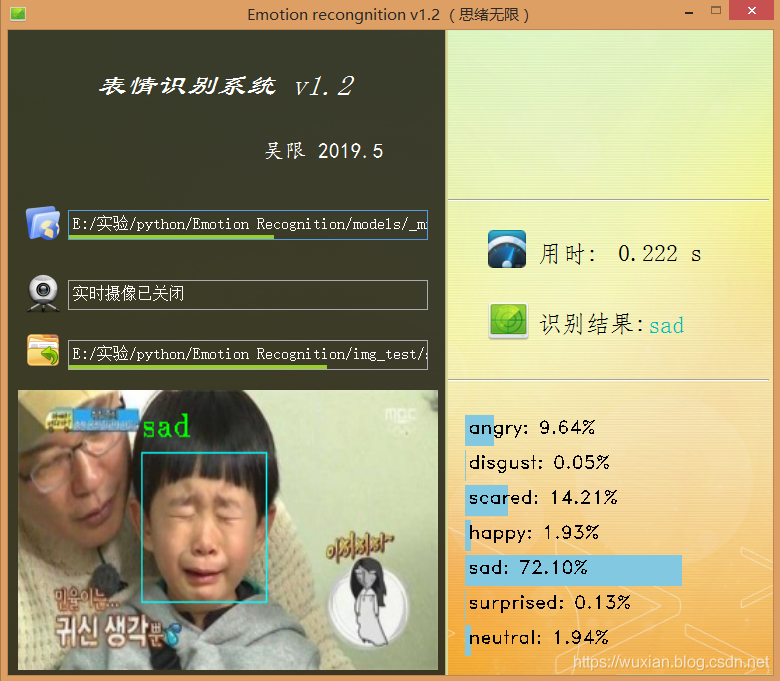
博主對UI界面的要求是可以簡單但顏值必須高,必須高,實用簡約高顏值是我奉行的標準,以上的界面幾經修改才有了上面的效果,當然博主的目的并不單純的想秀,而是借此做一個測驗模型的系統,可以選擇模型、訓練測驗集等以便界面化地對后面的模型進行各種測驗評估,生成用于論文的特定結果資料圖或表格等,這個測驗系統后面有機會分享給大家,
系統UI界面的實作這部分又設計PyQt5的許多內容,在這一篇博文中介紹恐怕尾大不掉,效果也不好,所以更多的細節內容將在后面的博文中介紹,敬請期待!有需要的朋友可通過下面的鏈接下載這部分的檔案,
【下載鏈接】
若您想獲得博文中涉及的實作完整全部程式檔案(包括資料集,py, UI檔案等,如下圖),這里已打包上傳至博主的面包多下載資源中,檔案下載鏈接如下:
資料鏈接:訓練用到的資料集(提取碼:t7xj)
本資源已上傳至面包多網站,可以點擊以下鏈接獲取,已將資料集同時打包到里面,點擊即可運行,完整檔案下載鏈接如下:
完整資源下載鏈接:博主在面包多網站上的完整資源下載頁
【運行程式須知】
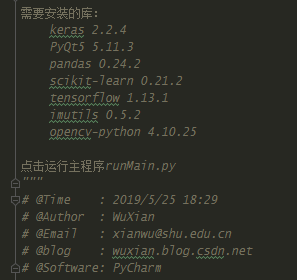
要安裝的庫如上圖(以上是博主安裝的版本),如您想直接運行界面程式,只需在下載鏈接1中的檔案后,運行runMain.py程式,
如您想重新訓練模型,下載鏈接1中的檔案后,運行前請下載鏈接2中的資料集解壓到的csv檔案放到 fer2013\fer2013 的檔案夾下,運行train_emotion_classifier.py程式即可重新訓練,
詳細安裝教程:人臉表情識別系統介紹——離線環境配置篇
【公眾號獲取】
本人微信公眾號已創建,掃描以下二維碼并關注公眾號“AI技術研究與分享”,后臺回復“ER20190609”獲取,

5. 結束語
由于博主能力有限,博文中提及的方法與代碼即使經過測驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,
大家的點贊和關注是博主最大的動力,博主所有博文中的代碼檔案都可分享給您,如果您想要獲取博文中的完整代碼檔案,可通過C幣或積分下載,沒有C幣或積分的朋友可在關注、點贊博文后提供郵箱,我會在第一時間發送給您,博主后面會有更多的分享,敬請關注哦!
參考文獻:
[1] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
[2] Arriaga O, Valdenegro-Toro M, Pl?ger P. Real-time convolutional neural networks for emotion and gender classification[J]. arXiv preprint arXiv:1710.07557, 2017.
[3] Jain D K, Shamsolmoali P, Sehdev P. Extended deep neural network for facial emotion recognition[J]. Pattern Recognition Letters, 2019, 120: 69-74.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458553.html
標籤:其他