摘要:本文對機器學習中的UCI資料集進行介紹,帶你從UCI資料集官網出發一步步深入認識資料集,并就下載的原始資料詳細講解了不同型別的資料集整理如何通程序式進行整理,為了方便使用,博文中附上了包括資料集整理及資料預處理在內的所有代碼及處理好的資料集,同時對代碼進行了解釋,其要點如下:
- UCI資料集介紹
- 不同資料集的整理程式
- 148個整理好的資料集與對應程式
\(\color{#4285f4}{點}\color{#ea4335}{擊}\color{#fbbc05}{跳}\color{#4285f4}{轉}\color{#34a853}{至}\color{#ea4335}{博}\color{#4285f4}{文}\color{#ea4335}{涉}\color{#fbbc05}{及}\color{#4285f4}{的}\color{#34a853}{全}\color{#ea4335}{部}\color{#fbbc05}{文}\color{#4285f4}{件}\color{#34a853}{下}\color{#ea4335}{載}\color{#fbbc05}{頁}\)
下載鏈接:博主在面包多網站上的完整資源下載頁
前言
UCI資料集作為機器學習演算法比較中的絕對經典經常出現在大多數論文或研究中,為了驗證機器學習演算法性能,UCI資料集通常用作為通用資料集,但官網提供的原始資料可能有格式不一致、缺失資料、包含特殊字符等問題,通常不能直接用于演算法程式中,資料集的查找、下載、整理等可能會給初學者帶來一定困擾,

對于資料集的查找整理確實是件費時費力的事情,是不是總有“論文就一篇,資料找半天”的問題?這里就來探討下資料集整理的那些事,其實早前作者就寫了一篇關于UCI資料集處理的博文:UCI資料集整理(附論文常用資料集)介紹了如何用程式整理資料集,這里會更加深入地介紹不同型別的資料集處理方法及資料預處理,本文較長建議結合右側的目錄閱讀,
1.UCI資料集介紹
這一節先從UCI資料集官網出發介紹資料集的屬性、格式等資訊,在我的博文:UCI資料集整理(附論文常用資料集)中也有部分介紹,對資料集熟悉或想看資料處理代碼干貨的朋友也可以直接跳轉至下一節,下面先看一下對UCI資料集的介紹,
1.1 UCI資料集官網介紹
UCI(University of California Irvine)資料集是美國加州大學歐文分校提出的一種適合模式識別和機器學習方向的開源資料集,很多學者選擇使用UCI上的資料集來驗證自己所提演算法的正確性,博文寫作時已擁有488個資料集,資料集還在不斷擴充中,這些資料集主要分為二值分類問題、多分類問題以及回歸擬合問題,UCI資料集提供了各個資料集的上主要屬性,可以根據自己提出的各類演算法在其資料集上做實驗結果論證,證明自己所提演算法的合理性,
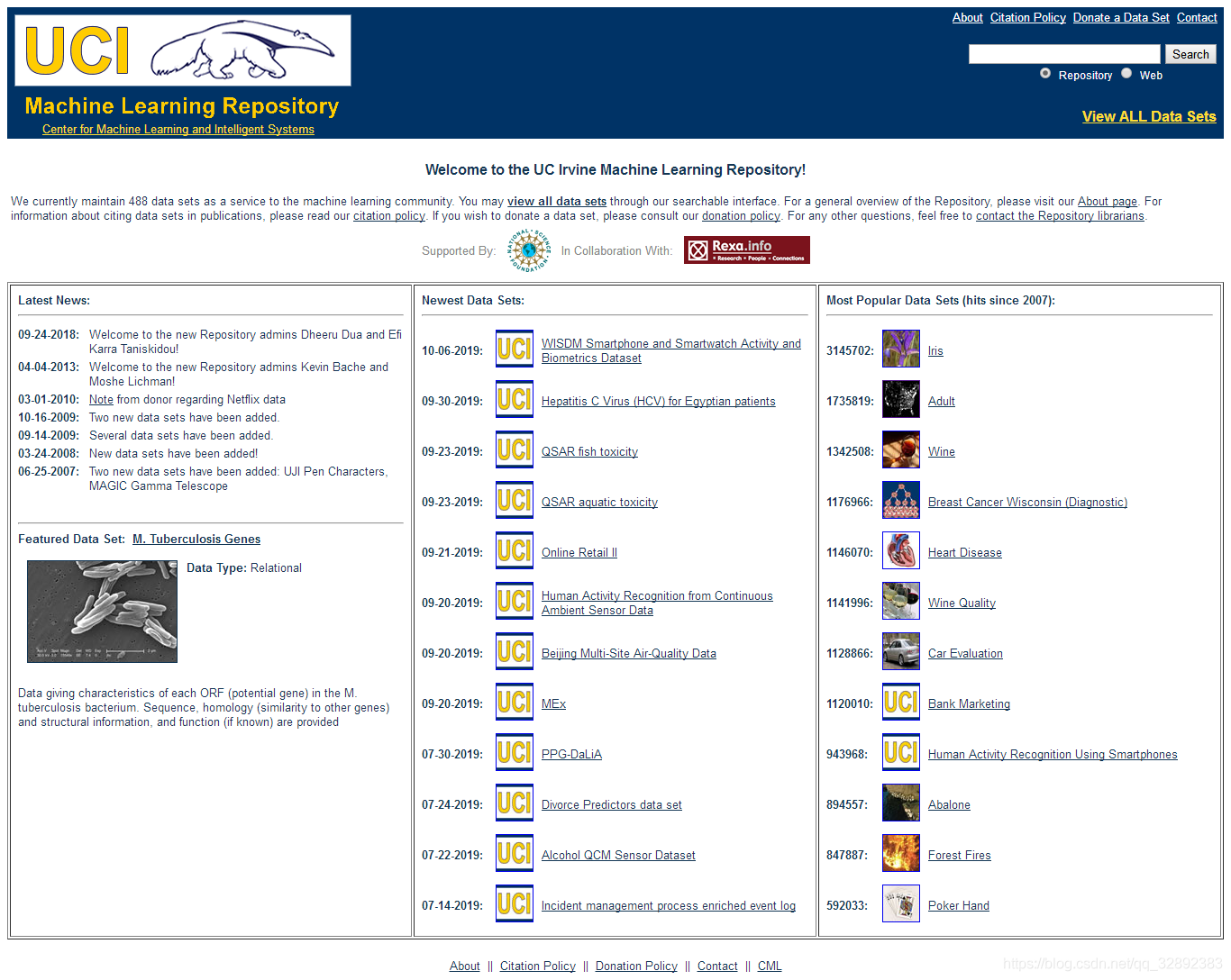
UCI資料集官網地址:https://archive.ics.uci.edu/ml/index.php
UCI資料集資料地址:https://archive.ics.uci.edu/ml/datasets.php
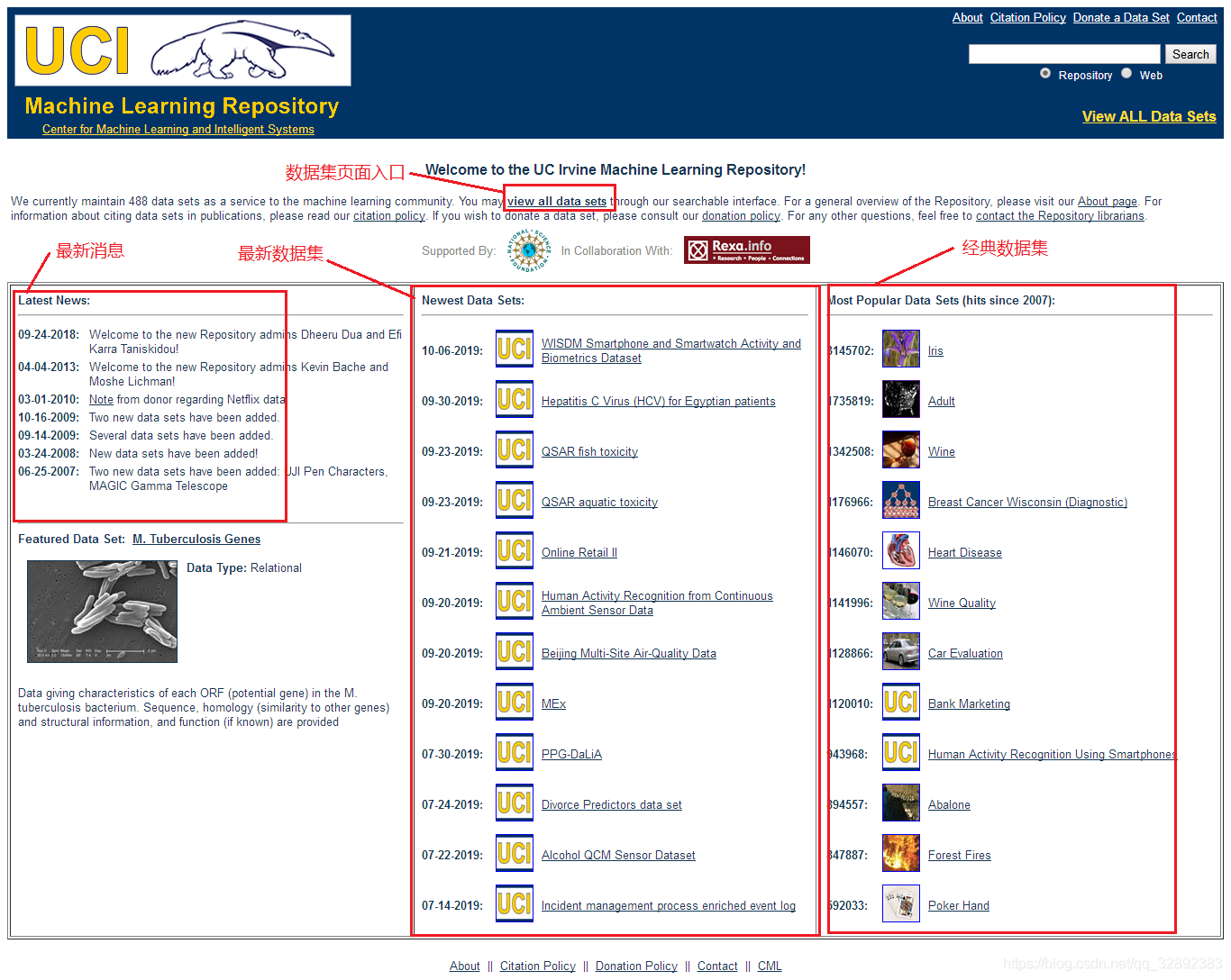
我在下圖所示的UCI資料集官網截圖中對其頁面主要部分進行了標注,可以看出主頁中主要包括了資料集頁面入口、最新資料集、經典資料集及資料集的最近訊息等,資料集頁面入口提供了進入官網查看全部資料集的鏈接,為了方便用戶查找在「最新資料集」和「經典資料集」區域整理了最新收錄以及參考最多的幾個資料集,如果只是簡單測驗下代碼,直接點擊頁面上提供的資料集鏈接下載幾個資料集就可以了,如果還需要更多資料集那就進入資料集頁面入口,該頁面發布有全部的資料集,
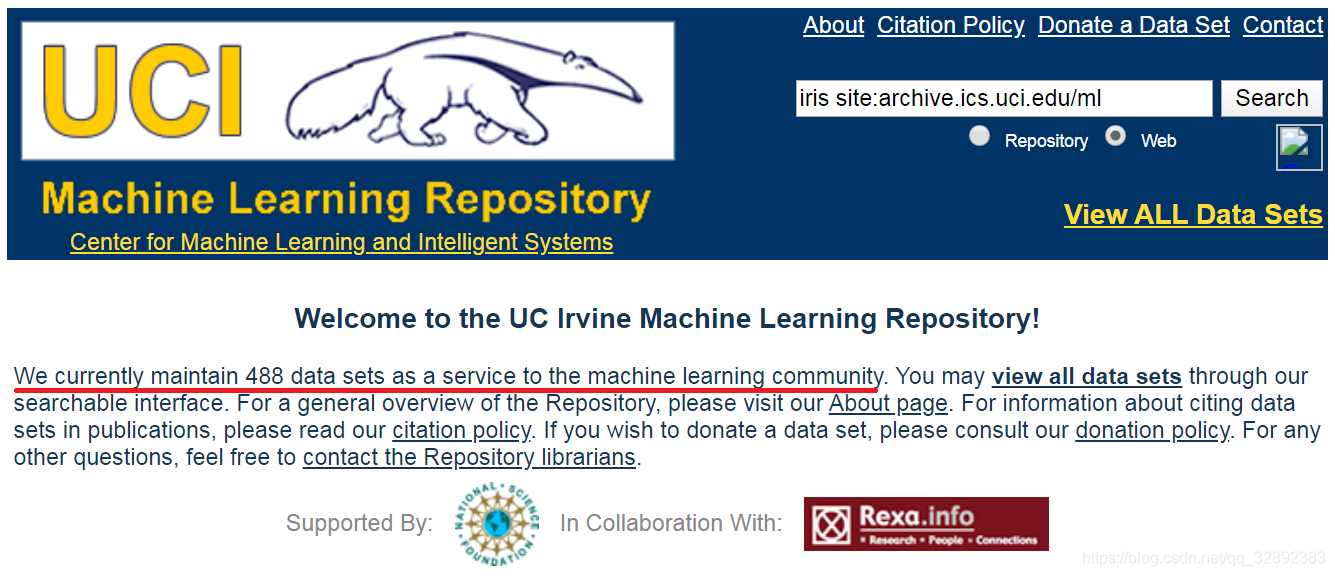
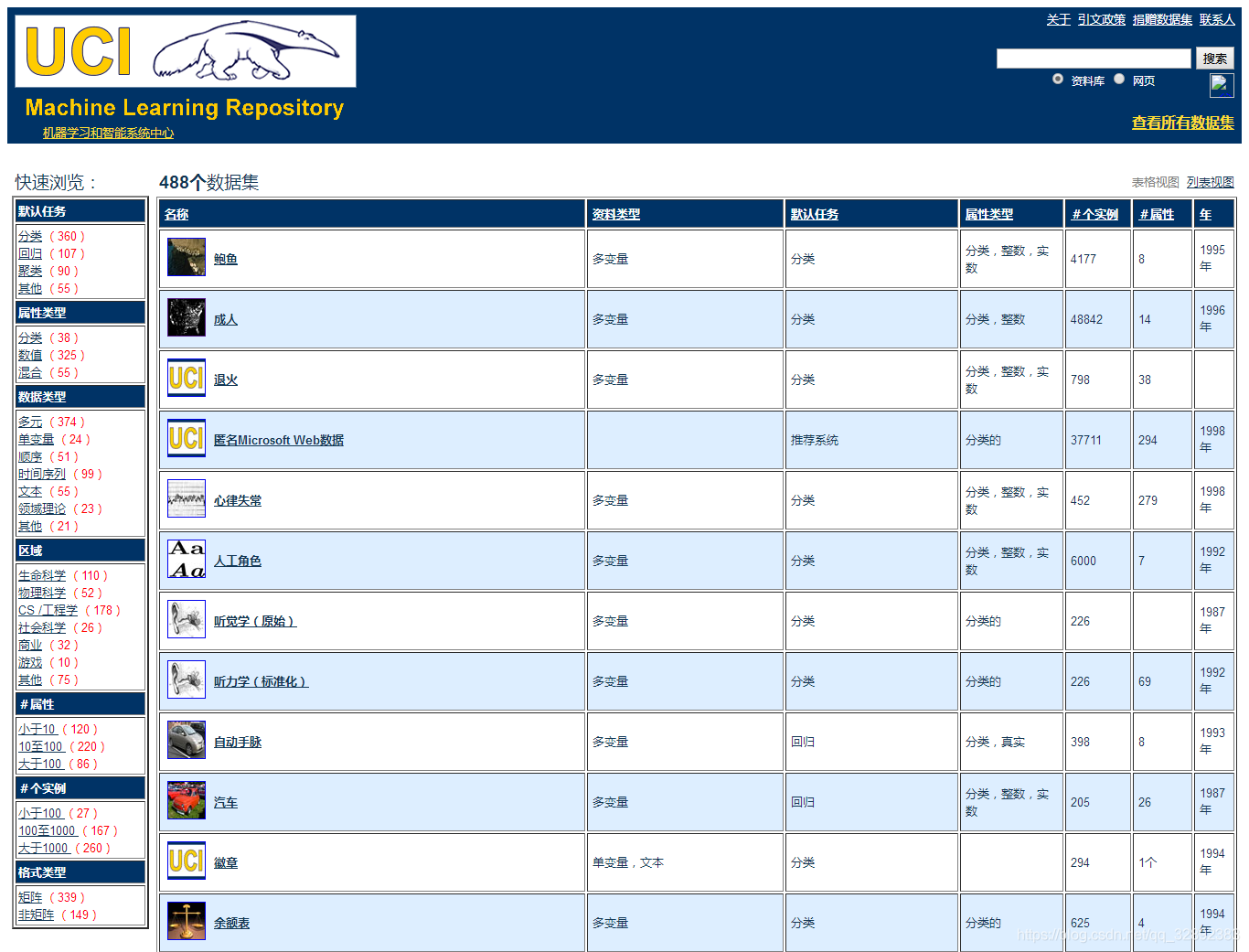
下圖(圖中頁面已翻譯)所示的全部資料集頁面是一個按型別排列的資料表,可以按照資料集名稱、任務型別、屬性型別、資料型別等進行排列查找,點擊想要的資料集鏈接可進入該資料集詳情頁,值得注意的是,右上角有一個搜索框,用戶可以通過輸入資料集名字搜索資料集,不過比較可惜親測下來該搜索在沒有外網VPN的加持下可能不能打開網頁 (當然不能用的還有搜資料集的利器——谷歌資料集搜索),
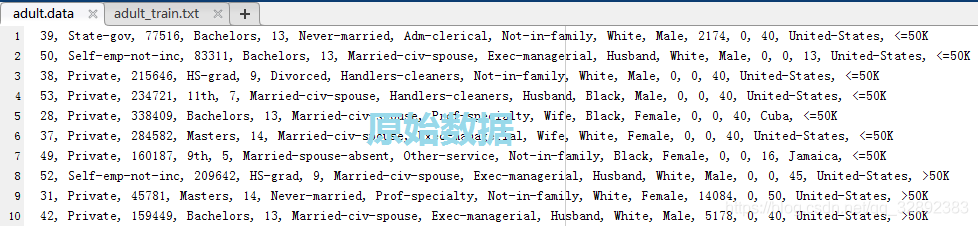
現在以官網資料集頁面中的Adult(成年人收入)資料集為例,介紹以下資料集詳情頁面,點擊鏈接進入Adult資料集頁面,頁面主要情況如下圖1.1.1所示,對于需要特別關注的地方我已經用紅色標記,主要包括資料集下載頁面鏈接、資料集說明下載鏈接、資料量、屬性數、是否確實資料及屬性資訊,當然其他的資訊不可說沒有必要,當我們要選用某個資料集進行測驗時,了解更多的相關資訊有助于更好根據資料情況對演算法做出調整,頁面最后面的相關論文和參考文獻也能幫助了解專業情況,
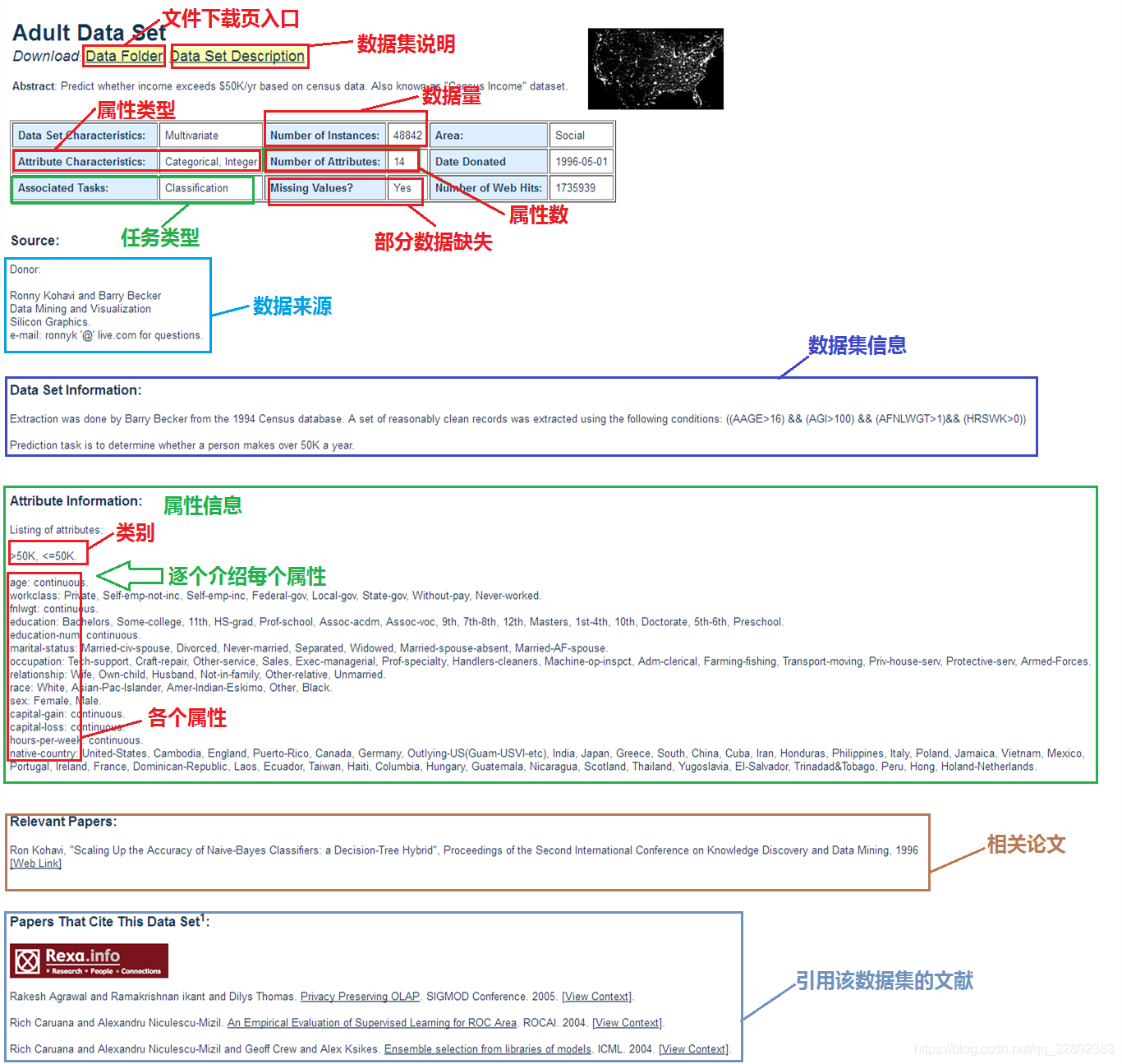
這里對上面提及的幾個重要部分做個簡介:
- 資料量(Number of Instances):或稱實體數,表示資料集有多少行資料,
- 屬性數(Number of Attributes):表示資料集每行有多少個特征屬性,決定了資料集復雜程度,
- 屬性資訊(Attribute Information):這里介紹了資料集的分類類別,及每個屬性表示的意義,例如上圖資料集中介紹了成年人收入的兩種分類類別:> 50K, <= 50K,屬性情況:年齡、作業類別、教育程度等14個屬性,
- 是否缺失資料(Missing Values):這體現了資料集中是否有某些資料缺失,如有缺失,則應特別注意在資料處理時需要補充資料或洗掉無效資料,
- 屬性型別(Attribute Characteristics):一般有Categorical(類別型), Integer(整數型), Real(實數型)這三種,值得注意的是,如果這一欄中有Categorical型表示該資料集中可能會包含字串,處理資料時需要用對應數字代替,
1.2 資料集檔案認識

如上圖所示,點擊Data Folder進入Adult資料集檔案下載目錄頁面,可以看到該資料集的檔案目錄如下圖所示,點擊下載鏈接即可下載該資料集,Adult資料集已經劃分好訓練和測驗資料集(一般的資料集未劃分則只有一個資料檔案),所以這里需要分別下載下圖所示的兩處檔案,如下在鏈接上右鍵,點擊“鏈接另存為”即可下載檔案,
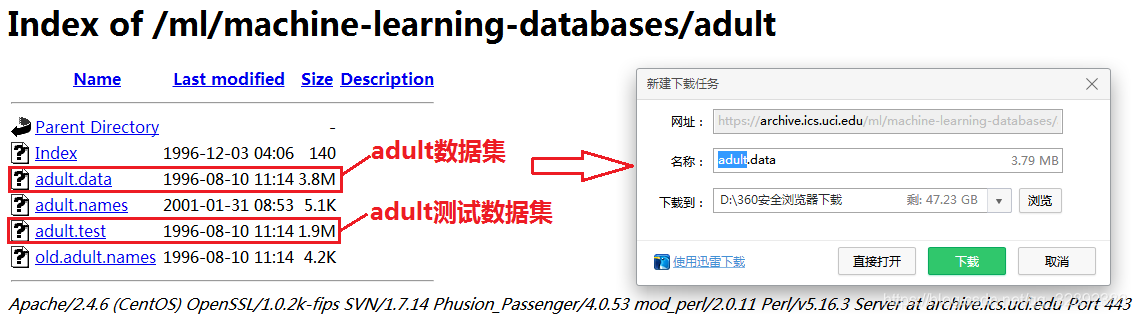
上面下載的檔案格式型別為data型,該檔案在MATLAB中可以直接打開(也可以右擊選擇打開方式為記事本打開),打開的檔案內容如下圖(加的紅線分割左側為屬性,右側為標記):

可以看到檔案中的資料中既有英文字串又有整數,果然同前面介紹頁中的“屬性型別”顯示的那樣為Categorical型和Integer性,剛學習的朋友可能不太能明白這一堆資料里面到底是些什么,這一堆奇怪的資料真的能被演算法直接計算嗎?其實在上面一小節中已經有所提及,前面我們看到Adult資料集詳情頁面中“Attribute Information(屬性資訊)”那一欄(如圖1.2.2)介紹的該資料集的類別有兩個:> 50K, <= 50K,也就是收入超過50K和不超過50K兩類,這說明每行最后面的那一欄是就標簽,這實際是一個二分類任務的資料集,每行前面的14個資料分別是年齡、作業類別、教育程度等14個屬性,如下圖1.2.2:

再仔細看圖1.2.1中的資料,結合圖1.2.2可以知道每行的第一個屬性表示的是年齡,它是個連續的整數型資料,而第二個屬性為作業類別,它是一個英文字串表示的字符型離散值,在整個資料集中這一屬性實際可能取值是:Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked這幾個作業類別,也就是前面說的Categorical型,同樣的還有第4,6,7...個屬性表示的教育程度、婚姻狀況、職業等等,這為我們后面用程式整理資料集提供了思路,既然是有限類別的,那我們就可以用類似1,2,3...這樣的數字代替對應的英文字串從而轉化為一個純數字的資料檔案供演算法程式使用了,后面一章將詳細介紹,
前面的圖1.2.1中展示的是資料集前12行的資料,但如果我們再仔細瀏覽后面的資料還有一些值得注意的地方,如下圖1.2.3標記的第15行資料,

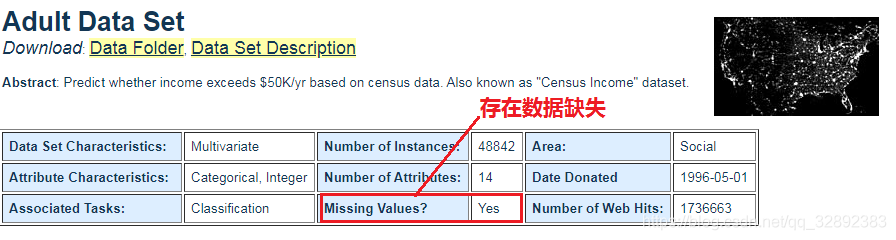
該行資料的第14個屬性表示為“?”意味著該處資料缺失,也就是國籍不詳(第14個屬性表示國籍),此外還有其他少數的幾行有部分資料缺失,這和前面圖1.1.1中的描述的“存在資料缺失”相符,資料缺失在機器學習中也很常見,因為資料的采集程序可能比較復雜,有些資料缺失在所難免,對于缺失的資料我們要做的也很簡單,那就是“補上還能用的資料,或者刪掉無效的資料”就可以了,下一章會詳細講述,
1.3 不同型別的UCI資料集
上面兩個小節以Adult資料集為例從頭到尾介紹了一遍如何認識和理解資料集檔案中的資料,讀者應該對UCI資料集有了一個基本認識,其實Adult資料集算是一個比較“復雜麻煩”的資料集了,大多的資料集不會有那么多英文字符和資料缺失,大多的資料集屬性為數字,類別標簽可能是數字或英文字符,資料也比較完整是無需我們處理缺失資料的,在我的博文《UCI資料集整理(附論文常用資料集)》中也有介紹,有興趣的可以點過去看一下,之所以說得這么復雜是因為這個資料集幾乎包含了UCI資料集中的所有可能的“麻煩問題”,接下來簡單列舉總結下UCI資料集檔案中資料的幾種型別,這將決定了我們后面采用怎樣的方式整理資料集,
為了后面敘述方便,原諒我不太專業地根據檔案中的資料是否部分包含英文字符、是否為純數字、是否缺失資料將其分為三個難度:“純數字、無缺失”,“部分英文字符、無缺失”,“部分or全部英文字符、有缺失”來分別介紹,當然還有“純數字、有缺失”等組合,但是也可以參考第三種對缺失的處理方式,為了避免重復敘述這里就省略了,這三種情況的代表資料集有Glass資料集、Abalone資料集及Adult資料集,三個資料集的部分資料截圖如下:
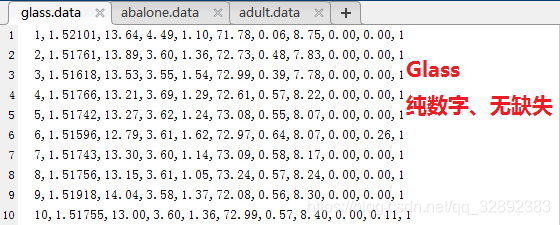
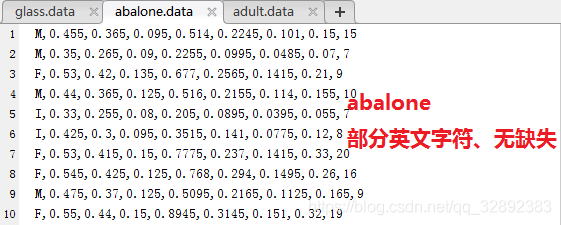

上面的三個資料集建議讀者按照前面兩小節的方法對照每個資料集詳情頁面上的介紹再研究一下,對于這三個資料集的介紹這里就不一一展開了,下面一節將以這三個資料集的整理為例講述如何通程序式整理這三種資料集檔案,
2. 不同資料集的整理
這一節就上節提到的UCI資料集中常見三種檔案資料型別如何通程序式整理進行詳細介紹,首先之所以需要整理資料集,是因為我們下載的UCI資料集檔案常常可能含有英文字串、缺失資料、存在無效資料等問題或者下載下來的資料集檔案格式不一致導致我們無法通過統一的程式使用它,那么什么樣的資料格式是我們想要的呢?
還是以Adult資料集為例,其中的英文字符需要換成對應的數字表示,缺失的資料需要補充,另外資料集的分類標記:> 50K, <= 50K分別用數字> 0, 1代替并由最后一列移至首位(標記一般在資料首位,也可以放在末尾),Adult資料集的原始資料檔案與整理完成后的資料檔案對比如下圖所示:
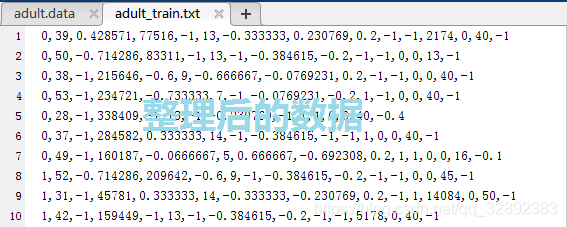
很明顯整理后的資料干凈整潔、易于讀取,而且在部分屬性特征上更加適合機器學習演算法處理,其中每行資料的第一個數字為分類標記,類似圖2.2正是我們需要的資料格式,為了統一使用方便,博文中的資料集都整理為這種形式,接下來從易到難分別介紹“純數字、無缺失”,“部分英文字符、無缺失”,“部分or全部英文字符、有缺失”三種情況下的資料如何通程序式整理,以下部分全部采用\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)編程實作,
2.1 “純數字、無缺失”資料集
以Glass資料集為例,首先在Glass資料集下載頁下載Glass原始資料集,其資料檔案部分資料如下圖所示,其特點為純數字,無缺失和特殊資料因此無需特殊處理技巧,由Glass資料集詳情頁上的介紹,該資料集為一個分類數為6,屬性數為9的資料集,
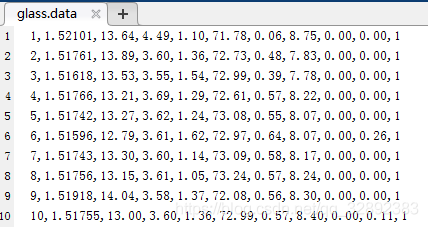
在下載的資料檔案存放路徑處新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程式,創建一個命名為main.m的檔案,并在編輯器鍵入如下代碼:
% glass
% author: wuxian, website: https://wuxian.blog.csdn.net
clear;
clc;
data_name = 'glass';
fprintf('開始處理資料集: %s ...\n', data_name);
n_entradas= 9; % 屬性數
n_clases= 6; % 類別數
n_patrons(1)= 214; % 資料量(行數)
n_fich= 1;
fich{1}= 'glass.data'; % 檔案路徑名
n_max= max(n_patrons);
x = zeros(n_fich, n_max, n_entradas); % 用于存放提取出的屬性資料
cl= zeros(n_fich, n_max); % 用于存放資料標簽
n_patrons_total = sum(n_patrons); % 用于顯示進度
n_iter=0;
for i_fich=1:n_fich
f=fopen(fich{i_fich}, 'r'); % 打開檔案
if -1==f
error('打開資料檔案出錯 %s\n', fich{i_fich});
end
for i=1:n_patrons(i_fich) % 回圈對每行資料進行處理
n_iter=n_iter+1;
fprintf('%5.1f%%\r', 100*n_iter/n_patrons_total); % 顯示處理進度
fscanf(f,'%i',1); % 第一個數字為序號,無需記錄
for j = 1:n_entradas
temp=fscanf(f, ',%f',1); % 讀取下一個資料,以逗號分隔
x(i_fich,i,j) = temp; % 保存一個數值到x
end
t=fscanf(f,',%i',1);
if t >= 5 % 原資料標記中沒有5,所以后面標號需要-1
t = t - 1;
end
cl(i_fich,i) = t - 1; % 原標記從1開始,改為從0開始
end
fclose(f);% 關閉檔案
end
%% 處理完成,保存檔案
fprintf('現在保存資料檔案...\n')
data = https://www.cnblogs.com/sixuwuxian/archive/2022/04/19/squeeze(x); % 資料
label = cl';% 標簽
dataSet = [label,data];
dir_path=['./預處理完成/',data_name];
if exist('./預處理完成/','dir')==0 %該檔案夾不存在,則直接創建
mkdir('./預處理完成/');
end
saveData(dataSet,dir_path); % 保存檔案至檔案夾
fprintf('預處理完成\n')
%% 子函式,用于保存txt/data/mat三種型別檔案
function saveData(DataSet,fileName)
% author:wuxian
% DataSet:整理好的資料集
% fileName:資料集的名字
%% Data為整理好的資料集矩陣
mat_name = [fileName,'.mat'];
save(mat_name, 'DataSet') % 保存.mat檔案
data_name = [fileName,'.data'];
save(data_name,'DataSet','-ASCII'); % 保存data檔案
% 保存txt檔案
txt_name = [fileName,'.txt'];
f=fopen(txt_name,'w');
[m,n]=size(DataSet);
for i=1:m
for j=1:n
if j==n
if i~=m
fprintf(f,'%g \n',DataSet(i,j));
else
fprintf(f,'%g',DataSet(i,j));
end
else
fprintf(f,'%g,',DataSet(i,j));
end
end
end
fclose(f);
% save iris.txt -ascii Iris
% dlmwrite('iris.txt',Iris);
end
以上程式代碼的思路是提取每行中每個資料的屬性和標簽分別保存到與x, cl兩個矩陣中,然后通過呼叫子函式saveData( )保存資料為txt, data, mat格式檔案,資料提取的程序是通過遍歷每行資料,利用fscanf( )函式逐個讀取每個逗號分隔的資料,最后在第52行將得到的屬性和標簽合并成一個矩陣并將標簽放在第一列,運行程式后整理好的檔案將保存在“預處理完成”的檔案夾中,保存的檔案及整理后的資料如下:
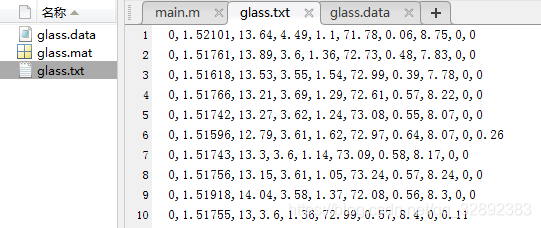
以上整理好的資料集第一列為標簽(取值有0, 1, 2, 3, 4, 5),其余列為屬性并與原資料集一致,
2.2 “部分英文字符、無缺失”資料集
相比前一小節中純數字的原始資料集,最為常見的資料恐怕還是部分帶一些英文字符的了,有些資料集的某些特征取值為有限個數的離散值,例如Abalone資料集,從Abalone資料集下載頁下載該資料集,打開部分資料如下圖所示:
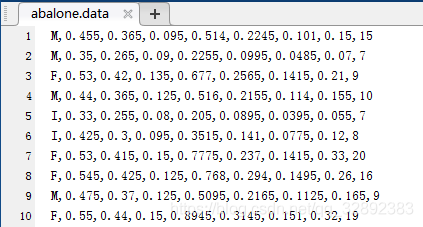
從上圖資料中可以看出只有第一列的屬性為英文字符,其它屬性都是數字,根據Abalone資料集詳情頁上的介紹,該資料集的第一列屬性是鮑魚的性別,有雄性(M)、雌性(F)及幼期(I)三個取值,所以這里需將第一個屬性中的英文字符“M, F, I”分別用數字“-1, 0, 1”代替,
另外該資料集要預測的物理量是鮑魚的年齡,原始資料集年齡那一列資料(最后一列)實際為連續取值,在該資料集的“屬性資訊”中有介紹到該資料集既可以作為連續值預測也可以用于分類任務,所以這里在處理Abalone資料集的標簽時需要將連續數值離散化,我們可以根據鮑魚年齡age的取值分為:“\(age<9, 9<age<11, age>11\)”三類,分別用數字“-1, 0, 1”表示,這是針對這一單個資料集而言的,如果資料集標簽本身就是可以直接用于分類的,就無需進行離散化了,
按照上面的分析,處理這種資料集時我們只需替換第一列英文字符并將最后一列的標簽離散化,在下載的資料檔案存放路徑處新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程式,創建一個命名為main.m的檔案,并在編輯器鍵入如下代碼:
%% abalone
% author: wuxian, website: https://wuxian.blog.csdn.net
clear;
clc;
data_name = 'abalone';
fprintf(['處理資料集: ',data_name,'abalone 原始資料 ...\n']);
fich= [data_name,'.data'];
n_entradas= 8; % 屬性數
n_clases= 3; % 分類數
n_fich= 1; % 資料集個數
n_patrons= 4177; % 資料量(行數)
x = zeros(n_patrons, n_entradas); % 用于存放提取出的屬性資料
cl= zeros(1, n_patrons);% 用于存放資料標簽
f=fopen(fich, 'r');% 打開檔案
if -1==f
error('打開檔案出錯 %s\n', fich);
end
for i=1:n_patrons % 回圈對每行資料進行處理
fprintf('%5.1f%%\r', 100*i/n_patrons(1));% 顯示處理進度
t = fscanf(f, '%c', 1); % 讀取一個字符資料
switch t % 將對應字符替換為數字
case 'M'
x(i,1)=-1;
case 'F'
x(i,1)=0;
case 'I'
x(i,1)=1;
end
for j=2:n_entradas
fscanf(f,'%c',1); % 中間有分隔符,后移1個位置
x(i,j) = fscanf(f,'%f', 1);% 依次讀取這一行所有屬性
end
fscanf(f,'%c',1);
t = fscanf(f,'%i', 1); % 讀取最后的標記值
% 根據范圍將連續的標記值離散化為三類
if t < 9
cl(1,i)=0;
elseif t < 11
cl(1,i)=1;
else
cl(1,i)=2;
end
fscanf(f,'%c',1);
end
fclose(f);
%% 處理完成,保存檔案
fprintf('現在保存資料檔案...\n')
data = https://www.cnblogs.com/sixuwuxian/archive/2022/04/19/x; % 資料
label = cl';% 標簽
dataSet = [label,data];
dir_path=['./預處理完成/',data_name];
if exist('./預處理完成/','dir')==0 %該檔案夾不存在,則直接創建
mkdir('./預處理完成/');
end
saveData(dataSet,dir_path); % 保存檔案至檔案夾
fprintf('預處理完成\n')
%% 子函式,用于保存txt/data/mat三種型別檔案
function saveData(DataSet,fileName)
% DataSet:整理好的資料集
% fileName:資料集的名字
%% Data為整理好的資料集矩陣
mat_name = [fileName,'.mat'];
save(mat_name, 'DataSet') % 保存.mat檔案
data_name = [fileName,'.data'];
save(data_name,'DataSet','-ASCII'); % 保存data檔案
% 保存txt檔案
txt_name = [fileName,'.txt'];
f=fopen(txt_name,'w');
[m,n]=size(DataSet);
for i=1:m
for j=1:n
if j==n
if i~=m
fprintf(f,'%g \n',DataSet(i,j));
else
fprintf(f,'%g',DataSet(i,j));
end
else
fprintf(f,'%g,',DataSet(i,j));
end
end
end
fclose(f);
% save iris.txt -ascii Iris
% dlmwrite('iris.txt',Iris);
end
和前面整理的思路類似,這里還是使用x, cl兩個矩陣保存從原始檔案中提取的屬性和標簽,其中讀取每個數值點采用回圈呼叫fscanf( )函式逐個移動檔案指標的方式讀取,將提取的資料屬性保存在x矩陣中,代碼第25-33行讀取出第一個屬性值并根據它的取值不同分別對x的第一個元素賦不同的數字,代碼第41-49行讀取最后一列數值,并根據其值的取值范圍將其劃分為三個標簽值的其中一個,至于各資料點之間的逗號分割符,程式中使用fscanf( )函式移動指標到下一個資料位置而并未賦值到變數中,從而跳過了逗號分隔符,如代碼第36,40,50行,運行以上代碼,得到整理完成的資料檔案及部分資料截圖如下:
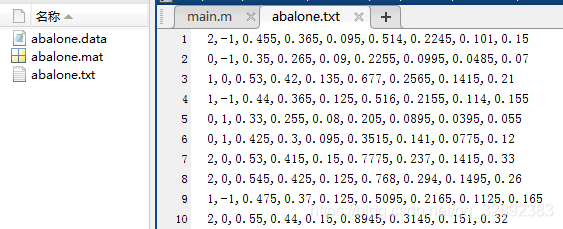
以上整理好的資料集第一列為標簽(取值有0, 1, 2),其余列為屬性,第一個屬性已處理為數字(取值有-1, 0, 1)
2.3 “部分英文字符、有缺失”資料集
經過前面兩個例子的介紹我們再來看一個更加復雜點的資料集型別即除了有英文字符還有缺失資料的部分,以Adult資料集為例,這個資料集前面已多有介紹,改資料集有劃分好的訓練集和測驗集,所以從Adult的Data Folder下載adult.data和adult.test兩個資料檔案,部分資料如下圖:

字符型離散值轉化為數值型:我們可以將某個需要轉化為數值型的字符型屬性的全部可能取值存放在一個元胞陣列中并記取值個數為\(n\),而轉化后的數值范圍一般取\([-1, 1]\),所以我們在\([-1, 1]\)的取值范圍內平均取\(n\)個實數\(\{-1, \frac{3-n}{n-1}, ..., \frac{2k-1-n}{n-1}, ...,\frac{n-3}{n-1}, 1\}, k=1,2,3, ...,n-1, n\)用來代替這些字符型屬性,比方說Adult原始資料的第2個屬性表示作業型別有'Private', 'Self-emp-not-inc', 'Self-emp-inc', 'Federal-gov', 'Local-gov', 'State-gov', 'Without-pay', 'Never-worked'將被分別替換為數值\(-1, -\frac{5}{7}, -\frac{3}{7}, -\frac{1}{7}, \frac{1}{7}, \frac{3}{7}, \frac{5}{7}, 1\),在程式中比對字串然后可按以上公式順序賦值為相應的數值,
缺失資料處理:對于缺失資料的處理其實作在并沒有一個很好的解決方式,一般來說缺失的資料點較少時可以直接刪去,較常見的是采用該屬性的均值、中值或眾數來填充缺失,當然也可以直接補充為某些特定值,直接刪去資料會導致資料量減少,而均值填補主要用于連續資料的缺失,這里的資料集屬性大多為離散量,使用均值并不是一個很好的方法,以上方法大家可以分別嘗試一下,這里直接對缺失的資料補充特定值0處理,
在下載的資料檔案存放路徑處新建\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程式,創建一個命名為main.m的檔案,并在編輯器鍵入如下代碼:
%% adult
% author:wx website:https://wuxian.blog.csdn.net
clear;
clc;
data_name = 'adult';% 資料集名
fprintf('lendo problema adult...\n');
n_entradas= 14; % 屬性數
n_clases= 2; % 分類數
n_fich= 2; % 檔案數,含有訓練和測驗集
fich{1}= 'adult.data';% 訓練資料路徑
n_patrons(1)= 32561; % 訓練集資料量
fich{2}= 'adult.test'; % 測驗資料路徑
n_patrons(2)= 16281; % 測驗資料量
n_max= max(n_patrons);
x = zeros(n_fich, n_max, n_entradas); % 屬性資料
cl= zeros(n_fich, n_max); % 標簽
discreta = [0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1]; % 1表示該位置的屬性需要將字符型離散值轉化為數值型
% 字符型離散值的所有取值
workclass = {'Private', 'Self-emp-not-inc', 'Self-emp-inc', 'Federal-gov', 'Local-gov', 'State-gov', 'Without-pay', 'Never-worked'};
education = {'Bachelors', 'Some-college', '11th', 'HS-grad', 'Prof-school', 'Assoc-acdm', 'Assoc-voc', '9th', '7th-8th', '12th', 'Masters', '1st-4th', '10th', 'Doctorate', '5th-6th', 'Preschool'};
marital = {'Married-civ-spouse', 'Divorced', 'Never-married', 'Separated', 'Widowed', 'Married-spouse-absent', 'Married-AF-spouse'};
occupation = {'Tech-support', 'Craft-repair', 'Other-service', 'Sales', 'Exec-managerial', 'Prof-specialty', 'Handlers-cleaners', 'Machine-op-inspct', 'Adm-clerical', 'Farming-fishing', 'Transport-moving', 'Priv-house-serv', 'Protective-serv', 'Armed-Forces'};
relationship = {'Wife', 'Own-child', 'Husband', 'Not-in-family', 'Other-relative', 'Unmarried'};
race = {'White', 'Asian-Pac-Islander', 'Amer-Indian-Eskimo', 'Other', 'Black'};
sex = {'Male', 'Female'};
country = {'United-States', 'Cambodia', 'England', 'Puerto-Rico', 'Canada', 'Germany', 'Outlying-US(Guam-USVI-etc)', 'India', 'Japan', 'Greece', 'South', 'China', 'Cuba', 'Iran', 'Honduras', 'Philippines', 'Italy', 'Poland', 'Jamaica', 'Vietnam', 'Mexico', 'Portugal', 'Ireland', 'France', 'Dominican-Republic', 'Laos', 'Ecuador', 'Taiwan', 'Haiti', 'Columbia', 'Hungary', 'Guatemala', 'Nicaragua', 'Scotland', 'Thailand', 'Yugoslavia', 'El-Salvador', 'Trinadad&Tobago', 'Peru', 'Hong', 'Holand-Netherlands'};
% 字符型離散值的所有取值個數
n_workclass=8;
n_education=16;
n_marital=7;
n_occupation=14;
n_relationship=6;
n_race=5;
n_sex=2;
n_country=41;
for i_fich = 1:n_fich
f=fopen(fich{i_fich}, 'r');
if -1==f
error('打開資料檔案出錯 %s\n', fich{i_fich});
end
for i=1:n_patrons(i_fich)
fprintf('%5.1f%%\r', 100*i/n_patrons(i_fich)); % 顯示進度
for j = 1:n_entradas
if discreta(j)==1
s = fscanf(f,'%s',1);
s = s(1:end-1); % 去掉字串末尾的逗號
if strcmp(s, '?') % 對于缺失值補0
x(i_fich,i,j)=0;
else
% 確定具體的屬性位置并賦相應變數
if j==2
n = n_workclass; p=workclass;
elseif j==4
n = n_education; p=education;
elseif j==6
n = n_marital; p=marital;
elseif j==7
n = n_occupation; p=occupation;
elseif j==8
n = n_relationship; p=relationship;
elseif j==9
n = n_race; p=race;
elseif j==10
n = n_sex; p=sex;
elseif j==14
n = n_country; p=country;
end
% 根據讀取的字符值按排列順序轉化為-1到1之間的分數值
a = 2/(n-1); b= (1+n)/(1-n);
for k=1:n
if strcmp(s, p(k))
x(i_fich,i,j) = a*k + b;
break
end
end
end
else % 為0的位置(原資料就是數值型)直接讀取原資料
temp = fscanf(f,'%g',1);
x(i_fich,i,j) = temp;
fscanf(f,'%c',1);
end
end
s = fscanf(f,'%s',1);
% 將標簽轉化為數值型(0,1)
if strcmp(s, '<=50K')||strcmp(s, '<=50K.')
cl(i_fich,i)=0;
elseif strcmp(s, '>50K')||strcmp(s, '>50K.')
cl(i_fich,i)=1;
else
error('類別標簽 %s 讀取出錯\n', s)
end
end
fclose(f);
end
%% 處理完成,保存檔案
fprintf('現在保存資料檔案...\n')
dir_path=['./預處理完成/',data_name];
if exist('./預處理完成/','dir')==0 %該檔案夾不存在,則直接創建
mkdir('./預處理完成/');
end
data_train = squeeze(x(1,1:n_patrons(1),:)); % 資料
label_train = squeeze(cl(1,1:n_patrons(1)))';% 標簽
dataSet_train = [label_train, data_train];
saveData(dataSet_train,[dir_path,'_train']); % 保存檔案至檔案夾
data_test = squeeze(x(2,1:n_patrons(2),:)); % 資料
label_test = squeeze(cl(2,1:n_patrons(2)))';% 標簽
dataSet_test = [label_test,data_test];
saveData(dataSet_test,[dir_path,'_test']);
fprintf('預處理完成\n')
%% 子函式,用于保存txt/data/mat三種型別檔案
function saveData(DataSet,fileName)
% DataSet:整理好的資料集
% fileName:資料集的名字
%% Data為整理好的資料集矩陣
mat_name = [fileName,'.mat'];
save(mat_name, 'DataSet') % 保存.mat檔案
data_name = [fileName,'.data'];
save(data_name,'DataSet','-ASCII'); % 保存data檔案
% 保存txt檔案
txt_name = [fileName,'.txt'];
f=fopen(txt_name,'w');
[m,n]=size(DataSet);
for i=1:m
for j=1:n
if j==n
if i~=m
fprintf(f,'%g \n',DataSet(i,j));
else
fprintf(f,'%g',DataSet(i,j));
end
else
fprintf(f,'%g,',DataSet(i,j));
end
end
end
fclose(f);
% save iris.txt -ascii Iris
% dlmwrite('iris.txt',Iris);
end
這里代碼在前面一個的基礎上做了改進,對于原檔案屬性是數值型的直接讀取到x矩陣中,對于字符型的屬性按照順序對應為[-1, 1]上的離散數值,運行以上代碼,得到整理完成的資料檔案及部分資料截圖如下:
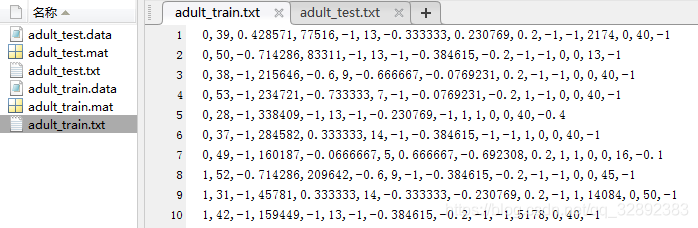
以上整理好的資料集第一列為標簽(取值有0, 1),其余列為屬性,其中的字符型屬性已處理為數值型,
至此不同資料集的整理程式就介紹到這里了,UCI資料集數量眾多,雖然沒有統一的整理代碼但經過這三個例子大家可以參考修改整理自己需要的資料集了,如果您有更好的整理方法歡迎在下方留言哦,
3. 148個整理好的資料集與對應程式
博主在三年的機器學習學習和研究中已累計整理了148個論文和研究中常用的UCI資料集,后面還會繼續整理更多資料集并更新下載資源,查找、下載和整理資料集是件費時費力的事情,完整整理好足夠論文或研究學習中需要的資料集可能會花費好多天甚至數周的時間,為了減少重復整理資料的繁冗作業,這里博主將自己整理好的148個UCI資料集分享給大家,其中每個檔案夾中都包含了以下內容:
- 從官網下載的完整原始資料檔案
- 整理資料集、歸一化及劃分訓練測驗資料集的完整\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\)程式檔案
- 整理完成后的資料集檔案
您可以直接使用里面整理好的資料集檔案,也可以修改或重新運行整理的程式代碼,整理好的148個UCI資料集截圖如下:
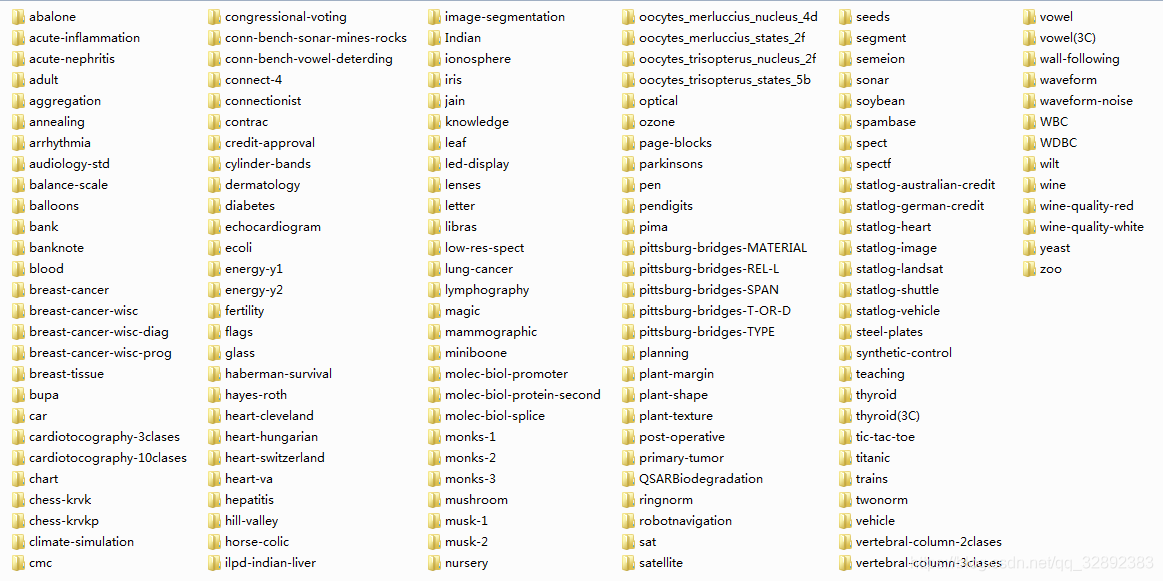
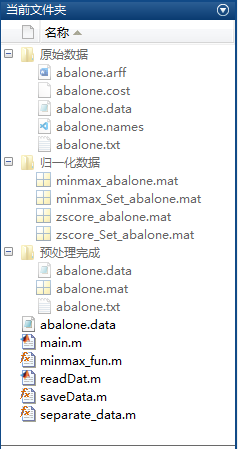
檔案中的所有程式代碼均在\(\color{#4285f4}{M}\color{#ea4335}{a}\color{#fbbc05}{t}\color{#4285f4}{l}\color{#34a853}{a}\color{#ea4335}{b}\) R2016b中測驗運行通過,整理的好資料集也是經過檢查和自行使用過的,每個子檔案夾里面的檔案內容截圖如下,下面提供了下載鏈接歡迎前去下載,
【資源獲取】
若您想獲得博文中介紹的整理Glass資料集、Abalone資料集及Adult資料集涉及的完整程式檔案(包含三個資料的原始檔案、整理資料集程式代碼檔案及整理好的檔案)掃描以下二維碼并關注公眾號“AI技術研究與分享”,后臺回復“UC20200223”獲取,

【148個整理好的UCI資料集下載】
為大家提供優質的資源是博主一直堅持的動力,若您想獲得上述介紹的148個整理好的UCI資料集(已包含本文中介紹的三個資料集),可以點擊如下鏈接到博主的面包多網頁上下載,面包多網站可以直接點擊解鎖,完成后可解鎖頁面下方的下載鏈接圖示,點擊即可下載,
下載鏈接:博主在面包多網站上的完整資源下載頁
結束語
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,
用心整理知識,只出精品博文轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458666.html
標籤:其他
上一篇:HTTP:聊一聊HTTPS
下一篇:容器基礎-隔離與限制