容器其實是一種沙盒技術,顧名思義,沙盒就是能夠像一個集裝箱一樣,把你的應用“裝”起來的技術,
這樣,應用與應用之間,就因為有了邊界而不至于相互干擾;
而被裝進集裝箱的應用,也可以被方便地搬來搬去,
這不就是 PaaS 最理想的狀態嘛,
"程式"被執行起來,它就從磁盤上的二進制檔案,變成了計算機記憶體中的資料、暫存器里的值、堆疊中的指令、被打開的檔案,以及各種設備的狀態資訊的一個集合,
像這樣一個程式運行起來后的計算機執行環境的總和,就是:行程
容器技術的核心功能,就是通過約束和修改行程的動態表現,從而為其創造出一個“邊界”,
對于 Docker 等大多數 Linux 容器來說,Cgroups 技術是用來制造約束的主要手段,而 Namespace 技術則是用來修改行程視圖的主要方法
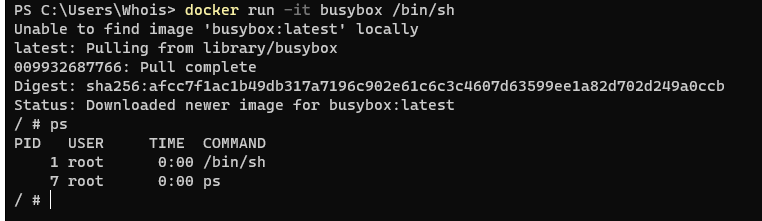
在docker容器中執行ps命令,可以看到我們在 Docker 里最開始執行的 /bin/sh,
就是這個容器內部的第 1 號行程(PID=1),
而這個容器里一共只有兩個行程在運行,
這就意味著,前面執行的 /bin/sh,以及我們剛剛執行的 ps,
已經被 Docker 隔離在了一個跟宿主機完全不同的世界當中
在宿主機中執行/bin/sh如下,PID是1536
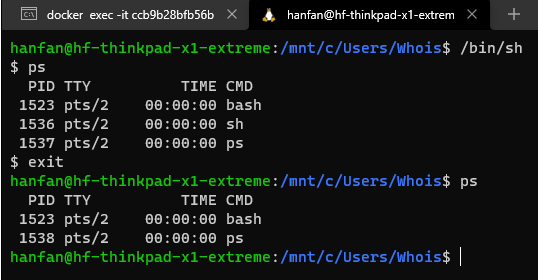
這種機制,其實就是對被隔離應用的行程空間做了手腳,使得這些行程只能看到重新計算過的行程編號,比如 PID=1,
可實際上,他們在宿主機的作業系統里,還是原來的第 1536號行程,
這種技術,就是 Linux 里面的 Namespace 機制,
在 Linux 系統中創建行程的系統呼叫是 clone(),比如:
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
這個系統呼叫就會為我們創建一個新的行程,并且回傳它的行程號 pid,
當我們用 clone() 系統呼叫創建一個新行程時,就可以在引數中指定 CLONE_NEWPID 引數,比如
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
除了我們剛剛用到的 PID Namespace,Linux 作業系統還提供了 Mount、UTS、IPC、Network 和 User 這些 Namespace,用來對各種不同的行程背景關系進行“障眼法”操作,
比如,Mount Namespace,用于讓被隔離行程只看到當前 Namespace 里的掛載點資訊;Network Namespace,用于讓被隔離行程看到當前 Namespace 里的網路設備和配置,
就是 Linux 容器最基本的實作原理了,
所以說,容器,其實是一種特殊的行程而已,
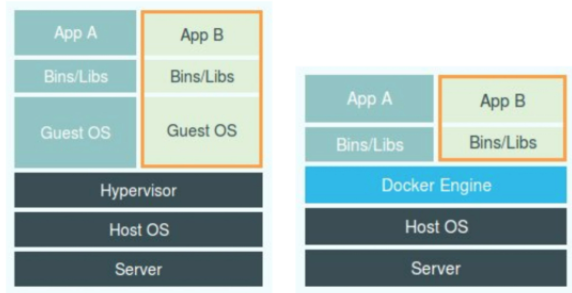
在理解了 Namespace 的作業方式之后,你就會明白,跟真實存在的虛擬機不同,
在使用 Docker 的時候,并沒有一個真正的“Docker 容器”運行在宿主機里面,
Docker 專案幫助用戶啟動的,還是原來的應用行程,
只不過在創建這些行程時,Docker 為它們加上了各種各樣的 Namespace 引數,
這些行程就會覺得自己是各自 PID Namespace 里的第 1 號行程,
只能看到各自 Mount Namespace 里掛載的目錄和檔案,
只能訪問到各自 Network Namespace 里的網路設備,
就仿佛運行在一個個“容器”里面,
基于 Linux Namespace 的隔離機制相比于虛擬化技術也有很多不足之處,其中最主要的問題就是:隔離得不徹底,
首先,既然容器只是運行在宿主機上的一種特殊的行程,那么多個容器之間使用的就還是同一個宿主機的作業系統內核,
在 Linux 內核中,有很多資源和物件是不能被 Namespace 化的,最典型的例子就是:時間,
如果在一個容器中修改了系統時間,那么整個宿主機的時間都會被修改,
Linux Cgroups 就是 Linux 內核中用來為行程設定資源限制的一個重要功能,Linux Cgroups 的全稱是 Linux Control Group,它最主要的作用,就是限制一個行程組能夠使用的資源上限,包括 CPU、記憶體、磁盤、網路帶寬等等,
Cgroups 的每一個子系統都有其獨有的資源限制能力,比如:
blkio,為???塊???設???備???設???定???I/O 限???制,一般用于磁盤等設備;
cpuset,為行程分配單獨的 CPU 核和對應的記憶體節點;
memory,為行程設定記憶體使用的限制,
Linux Cgroups 的設計還是比較易用的,簡單粗暴地理解呢,它就是一個子系統目錄加上一組資源限制檔案的組合,
而對于 Docker 等 Linux 容器專案來說,它們只需要在每個子系統下面,為每個容器創建一個控制組(即創建一個新目錄),然后在啟動容器行程之后,把這個行程的 PID 填寫到對應控制組的 tasks 檔案中就可以了,
而至于在這些控制組下面的資源檔案里填上什么值,就靠用戶執行 docker run 時的引數指定了,比如這樣一條命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在啟動這個容器后,我們可以通過看 Cgroups 檔案系統下,CPU 子系統中,
“docker”這個控制組里的資源限制檔案的內容來確認:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
這就意味著這個 Docker 容器,只能使用到 20% 的 CPU 帶寬,
容器是一個“單行程”模型
由于一個容器的本質就是一個行程,用戶的應用行程實際上就是容器里 PID=1 的行程,也是其他后續創建的所有行程的父行程,
這就意味著,在一個容器中,你沒辦法同時運行兩個不同的應用,除非你能事先找到一個公共的 PID=1 的程式來充當兩個不同應用的父行程,
這也是為什么很多人都會用 systemd 或者 supervisord 這樣的軟體來代替應用本身作為容器的啟動行程
Docker 專案來說,它最核心的原理實際上就是為待創建的用戶行程:
啟用 Linux Namespace 配置;
設定指定的 Cgroups 引數;
切換行程的根目錄(Change Root),
總結:
1、虛擬機 是硬體隔離,因為hypervisor 虛擬一系列硬體資源
2、容器是 行程級隔離,依靠NameSpace 機制實作行程間的隔離
3、容器的資源限制,依靠Linux Cgroups,它就是限制一個行程組能夠使用的資源上限,包括 CPU、記憶體、磁盤、網路帶寬等等,
4、容器只是運行在宿主機上的一種特殊的行程,那么多個容器之間使用的就還是同一個宿主機的作業系統內核,
5、通過exec在容器中執行啟動的后臺行程,實際不受docker控制(回收和生命周期),只有PID=1的受控制,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/458667.html
標籤:其他