一、聚集索引
定義:資料行的物理順序與列值(一般是主鍵的那一列)的 邏輯順序相同,一個表中只能擁有一個聚集索引,
注: 1、由于物理排列方式與聚集索引的順序相同,所以也就只能建立一個聚集索引了,
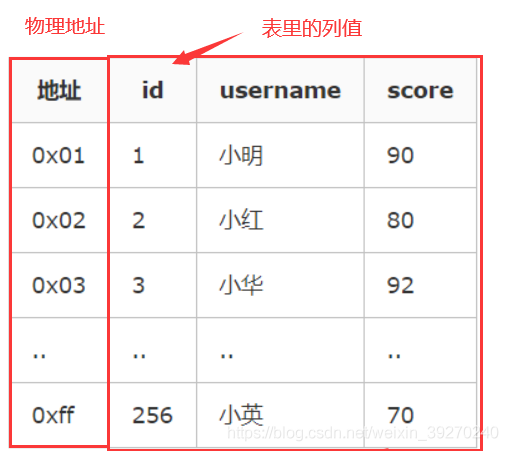
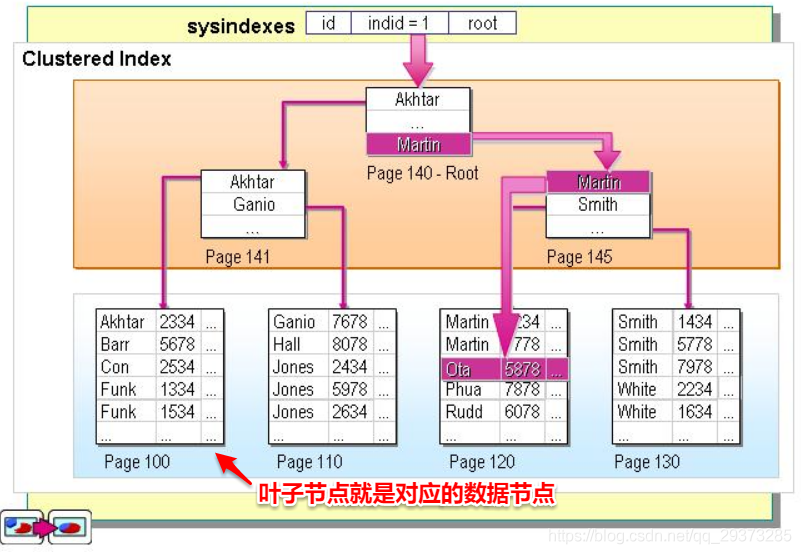
2、從下圖可以看出聚集索引的好處了,索引的 葉子節點就是對應的資料節點,可以直接獲取到對應的全部列的資料,而非聚集索引在索引沒有覆寫到對應的列的時候需要進行二次查詢,后面會詳細講,因此在查詢方面聚集索引的速度往往會更占優勢,
3、如果不創建索引,系統會自動創建一個隱含列作為表的聚集索引,
4、SQL Sever默認主鍵為聚集索引,也可以指定為非聚集索引,而MySQL里主鍵就是聚集索引
二、非聚集索引
定義:該索引中索引的邏輯順序與磁盤上行的物理存盤順序不同,一個表中可以擁有多個非聚集索引,
注: 1、其實按照定義,除了聚集索引以外的索引都是非聚集索引,只是人們想細分一下非聚集索引,分成普通索引,唯一索引,全文索引,如果非要把非聚集索引類比成現實生活中的東西,那么非聚集索引就像新華字典的偏旁字典,他結構順序與實際存放順序不一定一致,
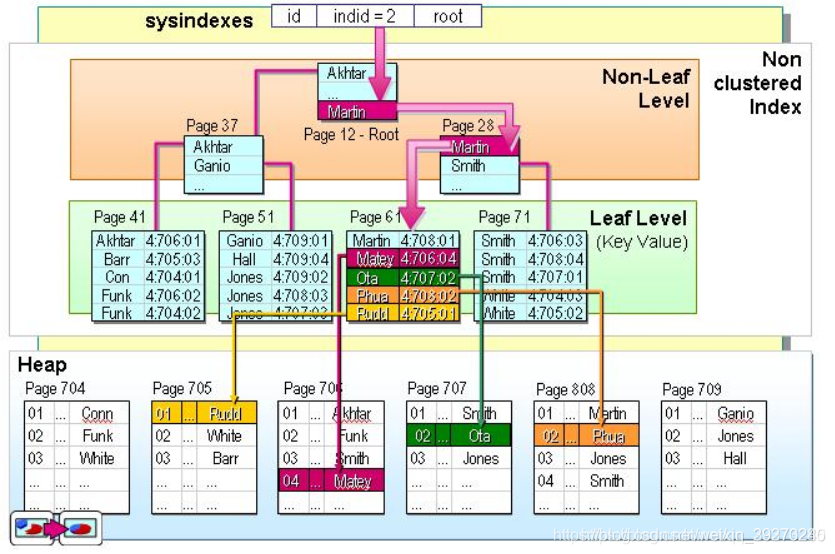
2、非聚集索引葉節點仍然是索引節點,只是有一個指標指向對應的資料塊,此如果使用非聚集索引查詢,而查詢列中包含了其他該索引沒有覆寫的列,那么他還要進行第二次的查詢,查詢節點上對應的資料行的資料,
3、使用以下陳述句進行查詢,不需要進行二次查詢,直接就可以從非聚集索引的節點里面就可以獲取到查詢列的資料,
select id, username from t1 where username = '小明'
select username from t1 where username = '小明'
4、但是使用以下陳述句進行查詢,就需要二次的查詢去獲取原資料行的score:
select username, score from t1 where username = '小明'
5、可以看的出二次查詢所花費的查詢開銷占比很大,達到50%,
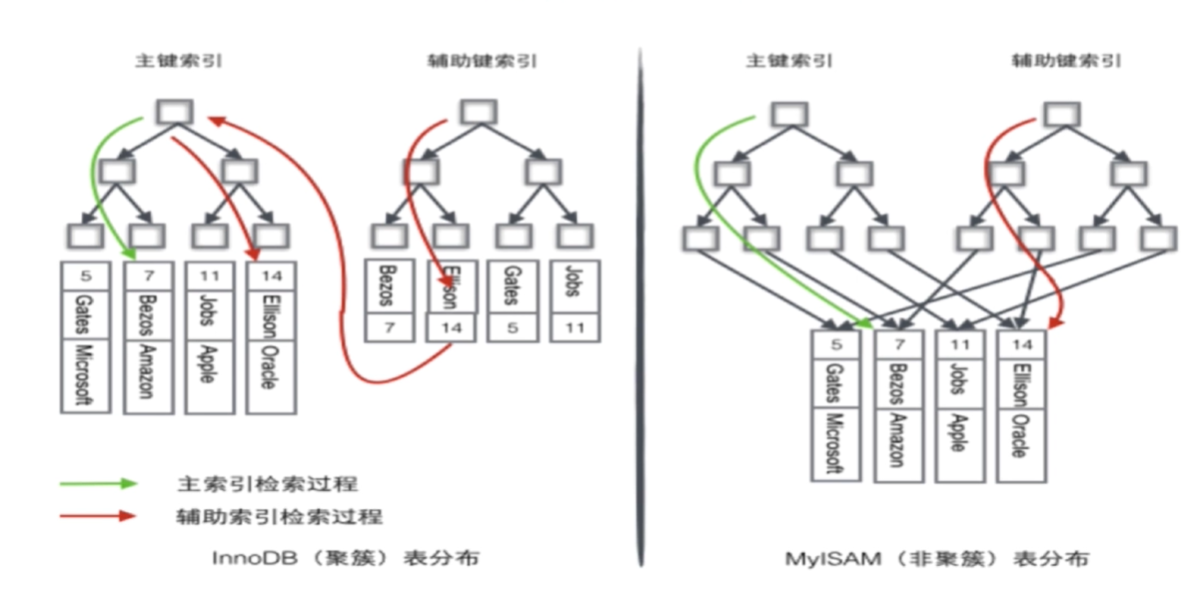
6、聚集索引與非聚集索引區別原理圖如下(如果有看不懂可以在評論區留言)
三、根本區別
1、區別:資料行的物理順序與表的某個列值的邏輯順序是否一致,
2、使用示例證明:
第一步:創建表和插入相關測驗資料
create database IndexDemo
go
use IndexDemo
go
create table ABC
(
A int not null,
B char(10),
C varchar(10)
)
go
insert into ABC select 1,'B','C'
union select 5,'B','C'
union select 7,'B','C'
union select 9,'B','C'
go select * from abc
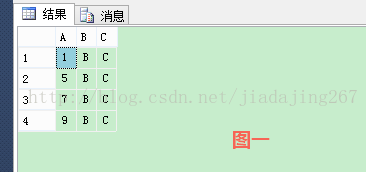
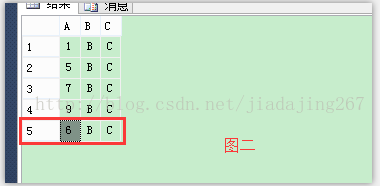
第二步:插入一條資料
insert into abc values('6','B','C')
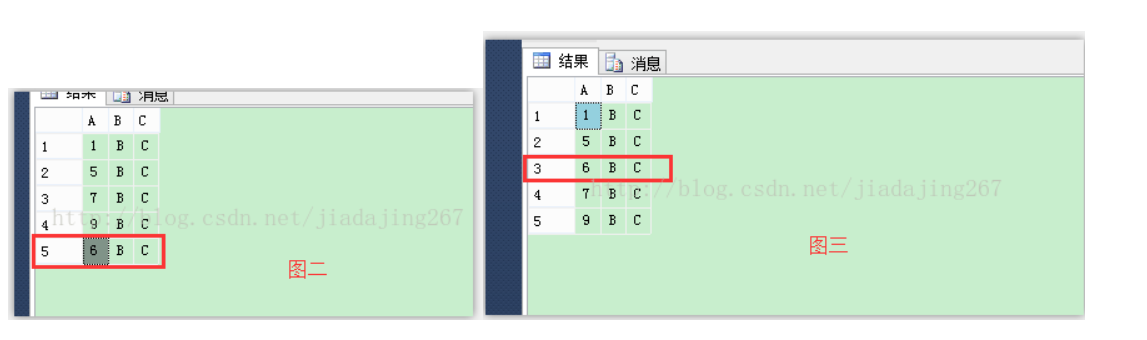
第三步:創建聚集索引(注意:排列變成有序)
create clustered index CLU_ABC on abc(A)
第四步:洗掉聚集索引(注意:排列變成無序)
drop index abc.CLU_ABC
第五步:非聚集索引,添加新的記錄,查看表順序,如圖四,并沒有影響表的順序
create nonclustered index NONCLU_ABC on abc(A)
insert into abc values('4','B','C')

備注:這是小編第一次這么認真的去寫一篇博客,很多地方都是參考其他博主的文章,取其精華,去其糟粕,如有侵權請及時聯系小編
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/46268.html
標籤:其他
上一篇:通信搜網程序梳理
下一篇:MySQL基本操作