演講摘錄 On the Nature of Data Science
演講簡介
Jeffrey David Ullman(1942年11月22日-),美國計算機科學家,斯坦福大學名譽教授,他關于編譯器(各種版本被稱為綠龍書)、計算理論(也被稱為灰姑娘書)、資料結構和資料庫的教科書被認為是各自領域的標準,他和他的長期合作者Alfred Aho是2020年圖靈獎的獲得者,一般被認為是計算機科學的最高榮譽,(摘自維基百科)
本演講為KDD2021 Keynotes Talk的最后一場演講,
演講內容摘錄
演講聚焦于資料科學分別于機器學習和統計學之間的關系,以使聽眾更了解資料科學的本質,
從本世紀第一個十年的資料挖掘或知識發現,到第二個十年的大資料,再到如今的資料科學,該領域的宗旨未曾改變,即:將速度最快、規模最大的硬體設備和速度最快的演算法以及最高效的程式結合起來解決商業和科學領域的問題,

演講者認為資料科學是資料庫系統研究自然進化的產物,
同時,演講者指出,想要在資料科學領域有所作為需要掌握計算機科學的核心并在處理大量資料上有所專長,
演講者通過駁斥Drew Conway的韋恩圖、并給出自己的韋恩圖來表示資料科學與其他領域的關系,資料科學是計算機科學和其他專業領域結合部,其中涉及到了機器學習,但不限于機器學習,此外,在資料科學角度,數學和統計學并不直接影響專業領域,而是通過計算機領域的演算法等對其產生間接影響,
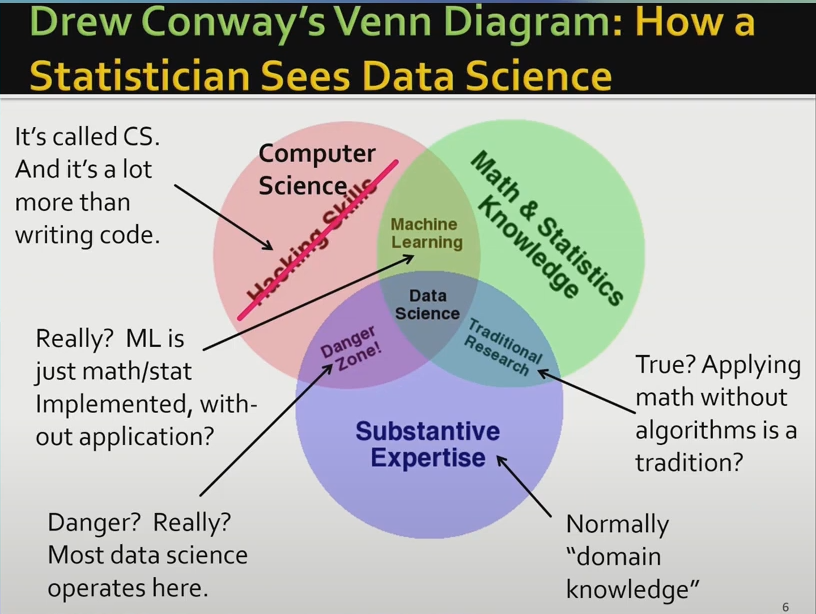
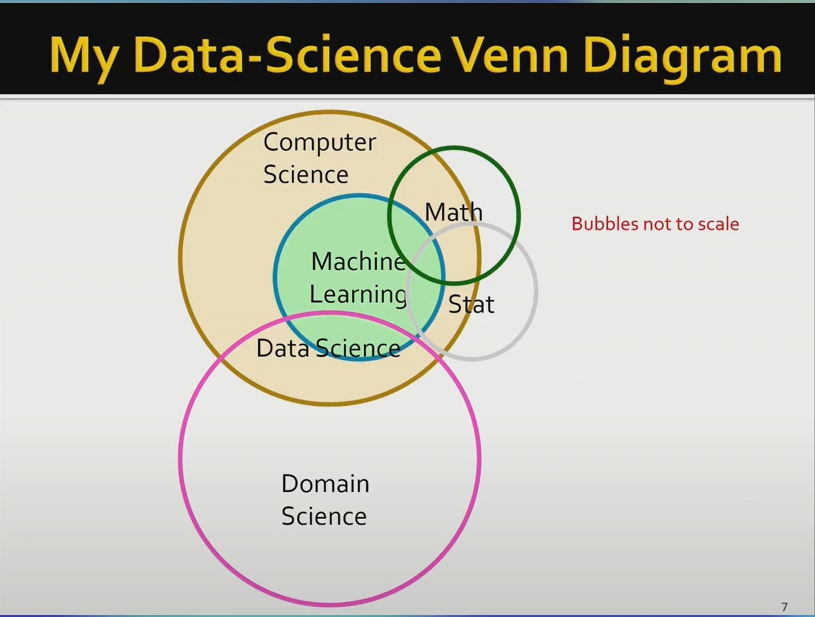
與統計學相比,資料科學總體上是一門實驗性學科,在資料科學家往往通過實作、運行某一演算法或模型來驗證某一方法的正確性,而不是通過分析推導避免模型出錯,因此,對于資料科學來說,判斷錯誤的標準和改進方法比理論上的分析更重要,
與機器學習相比,并不是所有的資料科學問題是通過建立模型解決的,比如Locality-Sensitive Hashing和Approximate Counting等(演講者這里推薦了一本名為“Mining of Massive Dataset”的書),同時,方法的可解釋性在某些領域非常重要比如保險公司估計保費,
何時使用機器學習:
- 問題需要通過建模解決
- 不需要對結果進行解釋
- 缺少對問題相關領域的認識
結論
- 資料科學是計算機科學許多分支自然演化的結果,尤其是其中通過處理大型資料集幫助科學或產業發展的方面,
- 統計學者尤其獨到之處,但過于關注分析資料,對于解決實際問題不夠關注,
- 機器學習是資料科學的重要部分,但遠不是資料科學的全部,

注:本文為演講摘錄,所有內容和圖片均選自演講內容,歡迎各位討論,謝謝
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/466010.html
標籤:其他
下一篇:Redis