本文試圖概括Semantic SLAM的主要思路和近年作業,?期更新,
但因水平有限,若有錯漏,感謝指正,
(更好的公式顯示效果,可關注博客側邊的公眾號)
Semantic SLAM
簡介
至今為止,主流的 SLAM 方案 [1] 多是基于處于像素層級的特征點,更具體地,它們往往只能用角點或邊緣來提取路標,與之不同的是,人類通過物體在影像中的運動來推測相機的運動,而非特定像素點,
Semantic SLAM 是研究者試圖利用物體資訊的方案,其在Deep Learning的推動下有了較大的發展,成為了相對獨立的分支,就方法(非設備)而言,其在整個SLAM領域所處位置如下圖:
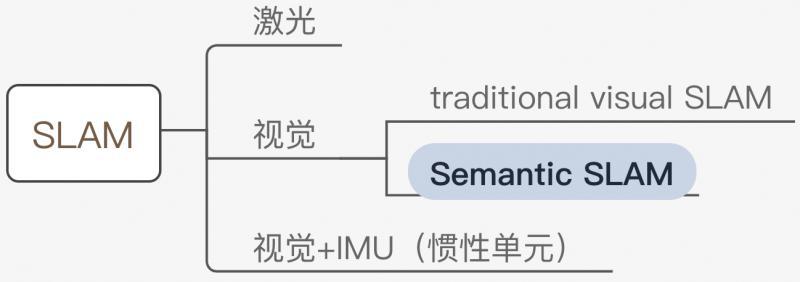
目前而言,所謂 Semantic 是將基于神經網路的語意分割、目標檢測、實體分割等技術用于 SLAM 中,多用于特征點選取、相機位姿估計,更廣泛地說,端到端的影像到位姿、從分割結果建標記點云、場景識別、提特征、做回環檢測等使用了神經網路的方法都可稱為 Semantic SLAM [2],
語意和 SLAM 的結合的體現有以下兩點 [3]:
-
SLAM 幫助語意,
檢測和分割任務都需要大量的訓練資料,在 SLAM 中,由于我們可以估計相機的運動,那么各個物體在影像中位置的變化也可以被預測出來,產生大量的新資料為語意任務提供更多優化條件,且節省人工標定的成本,
-
語意幫助 SLAM,
一方面,語意分割把運動程序中的每一張圖片都帶上語意標簽,隨后傳統 SLAM 將帶標簽的像素映射到3D空間中,就能得到一個帶有標簽的地圖,這提供了高層次的地圖,有利于機器人自主理解和人機互動,
另一方面,語意資訊亦可為回環檢測、Bundle Adjustment 帶來更多的優化條件,提高定位精度,
僅實作前者的作業往往稱為 Semantic Mapping,后者才認為是真正的 Semantic SLAM,
發展方向
分別從 Semantic Mapping 和 Real Semantic SLAM 兩方面,介紹一些主要思路,
Semantic Mapping
這類作業要求特征點是 dense 或 semi-dense 的(否則 Mapping 無意義),因此往往用 RGB-D 的 SLAM 方案,亦或是單目相機的 semi-dense LSD-SLAM 方案 [4],
有兩種 Mapping 方式:
-
將2D影像的語意分割結果,即帶標簽的像素,映射到3D點云中,
研究人員嘗試讓 SLAM 所得的資訊(特別是相機位姿),能夠提高語意分割的性能,其中一種是使用 SemanticFusion [5] 的 Recursive Bayes 方法:根據 SLAM 對像素點運動的估計,當前幀的像素的語意分類概率 與 前一幀舊位置上的分類概率相乘作為最終概率,即像素的概率會沿著各幀累乘,因而增強語意分割的結果,
這一方法被基于單目相機的作業 [6] 沿用,整體框架描述如下,
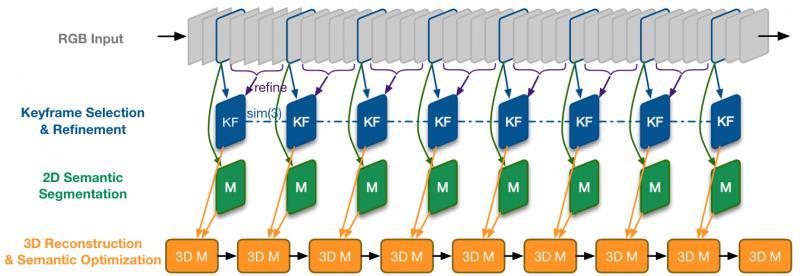
LSD-SLAM + DeepLab-v2 (語意分割)
流程:輸入 -> 選關鍵幀并 refine(非關鍵幀用于增強深度估計)-> 2D語意分割 -> 語意優化+3D重建
① 為保證速度,僅對關鍵幀來進行語意分割,
② 其他幀用 small-baseline stereo comparisons [7] 對關鍵幀做深度估計的優化
③ 使用 Recursive Bayes 增強語意分割
④ 3D重建的優化使用條件隨機場(CRF),同 SemanticFusion
-
第二種 Mapping 方式則以 Object 為單位構建地圖 [8][9],相比于一堆標記了類別的 voxel,包含一個個物體的語意地圖,將更有價值,
此部分的重點在于如何做資料關聯(Data Association),即跟蹤已識別 Object 和發現新 Object,以 [8] 為例描述如下,
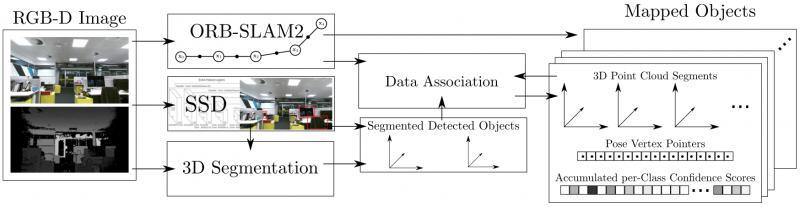
使用 RGB-D 和 ORB-SLAM2 可構建一個 dense 的點云,
對于關鍵幀,SSD 檢測出多個 Object,應用無監督的3D分割方法 [10] 為每一個 Object 分配點云序列,并存盤起來,
資料關聯:得到一組分割結果(Object, 對應點云)后,據點云重心的歐式距離,在找出最接近的一組候選 Object,如果超過 50% 的點對的距離小于一個閾值(文中 2cm),就認為是匹配到的 Object,否則認為是新 Object,存盤下來,
匹配為同一 Object 的兩個點云,直接累加分類概率(置信度),這和上文提到的 Recursive Bayes 方法很像,即利用 SLAM 提供的物體多角度資訊,增強分割結果,
(注:本文的 Related Work 寫得很好)
Real Semantic SLAM
此部分為本文的重點,相對來說,真正的 Semantic SLAM (即語意建圖和 SLAM 定位相互促進)發展較晚(基本是2017年后),
在 Bundle Adjustment (BA) 方法中,我們同時優化相機位姿和 3D 坐標位置,使得重投影到 2D 影像的像素點與實際觀測(多個相機,多個特征點)的總誤差最小,
那么如何將語意資訊融合進來呢?
-
思路一:同個 3D 點重投影之后,應保持語意一致,
這又是重投影優化問題,可以加入到 BA 公式中加強優化目標,關鍵是如何量化重投影誤差,就好像傳統 BA 的重投影誤差通過與實際觀測的像素距離來量化,
ICRA 2017 的著名作業 Probabilistic Data Association for Semantic SLAM [11] 使用了此思路,其量化重投影誤差的方法在于:使用概率模型計算出來的物體中心,重投影到影像上,應該接近檢測框的中心,而資料關聯(到底要接近哪個檢測框中心),由一組權重決定,最后 “BA” 和 “權重更新” 通過 EM 演算法交替優化,
ECCV 2018 上的作業 VSO [12] 與之類似,重投影誤差通過與目標類別的語意區域的遠近來量化,有幾個細節比較巧妙,下面展開說明,

如上圖所示,(a) 為語意分割圖,(b) 為類別 “Car” 的區域,在(c) (d) 中,根據與 Car 區域的距離,概率值從1 (紅) 變為 0 (藍), 其他類別如Tree,也會產生此概率分布圖,
其中 距離 到 概率 的轉化,利用了下方的高斯分布,(c) (d) 的不同是方差
導致的,這是在為量化重投影誤差做準備,對于一個空間點P(擁有坐標
)來說,重投影之后計算得到一個概率:
其中
計算了重投影的結果
與類別 c 區域的最近距離,最后得到的
用于計算重投影誤差:
權重
的存在是為了解決資料關聯,即空間點P應該以哪一個類別的區域為目標,
,其由多個相機下的
值累乘,即多個角度觀測投票決定,
會加到普通的 BA 優化公式中,使用 EM 演算法進行優化,E 步更新權重
,而 M 步優化三維點P坐標和相機位姿(普通的 BA 程序),
個人理解,之所以使用高斯分布,是因為其函式有“驟降”之處,那么方差
可以起到決定閾值的作用,讓距離超過閾值的類別區域更快得到一個小權重
,多個相機的投票下,資料關聯很快就能穩定下來,可以加速優化,
(為簡化說明,上述公式已被簡化,去除了對于多個相機、空間點的索引,詳見原文)
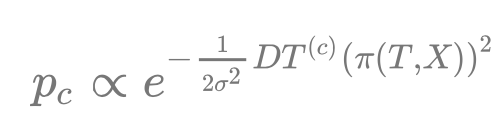
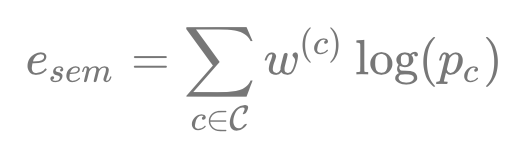
-
思路二:從語意資訊可以推斷出動態區域,
傳統 SLAM 方法幾乎都是假設當前場景是靜態的,當面對含有運動物體的場景時,運動物體上的特征點將對相機位姿估計產生巨大的偏差,面對這一困難的主要解決方式是去掉這些動態的特征點,而語意分割十分適合找出這些動態區域,
語意分割有兩個特點,一是把平面區域的許多像素點聯系起來,二是給區域帶上了分類標簽,
前者有利于確定物體是否真的在運動,因為單個特征點的偏移并不能確定運動的發生(可能是 SLAM 系統一直存在的觀測噪聲),若是一群有關聯的特征點普遍發生了較大的偏移,就可以斷定為是動態的,
后者有利于預判物體是否會運動,比如標簽是人的區域幾乎是動態的,而墻壁則可斷定是靜態的(甚至不用去計算偏移),
IROS 2018 的 DS-SLAM [13] 基于第一個特點,以區域為單位判斷是否動態,而一些作業如 [14] 僅利用了第二個特點,較為暴力地直接排除某些區域(天空,車)的特征點,
把這兩個特點都用上的是 ICRA 2019 的作業 [15], 簡述如下,
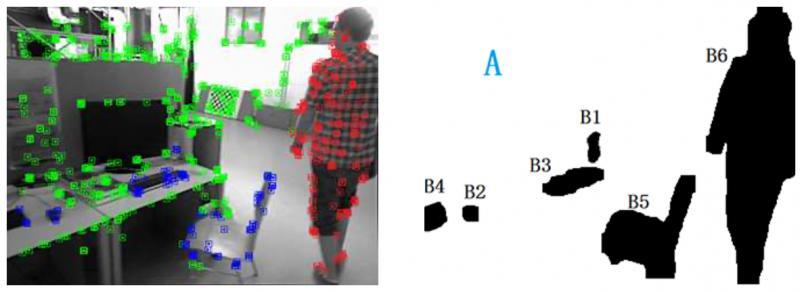
利用語意分割,將一些類別(
)區域定義為背景(綠色),其他類別(
)區域定義為可移動物體,
接下來使用運動判定,以區分可移動物體當前是靜止(藍色)還是運動(紅色)的,
運動判定的規則如下:對于某一語意區域內,過往估計的特征點的 3D 位置,投影到當前的新影像上,重投影位置若和對應特征點的歐式距離大于一定閾值,則定義為移動點,如果該區域移動點的比例大于一定閾值則判定為移動區域,
-
思路三:語意資訊提供的物體級別的描述,擁有季節(光線)不變性,
這一思路可以用在如何用已有的 3D 地圖定位,
傳統的特征點(擁有描述子),在多變的環境下十分不魯棒,容易跟丟,而語意分割的結果,相對而言是穩定的,此外,若以物體級別來做定位(拿語意標簽來匹配地圖),更符合人類直覺,
ICRA 2018 和 2019 的作業 [16] [17] 使用了本思路,
-
思路四:待總結
更好的閱讀效果、更多相關內容可關注公眾號 【小林同學的腦回路】
或訪問lac.allyoucare.cn
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/47671.html
標籤:其他
上一篇:通俗易懂DenseNet
下一篇:智能客服機器人-語意分析服務