一、背景
網上有很多排序演算法的總結,整理的一目了然,惹人喜愛,但關于決策樹的相關博文,普遍存在以下問題
1)歸納程度不足,深度不夠
2)總結點不足,有些疑問找不到答案
3)照抄現有書籍上的公式和推導程序
于是想到自己整理一篇關于決策樹的文章,同時也加深自己的理解
二、正文
首先,不說話,直接上圖
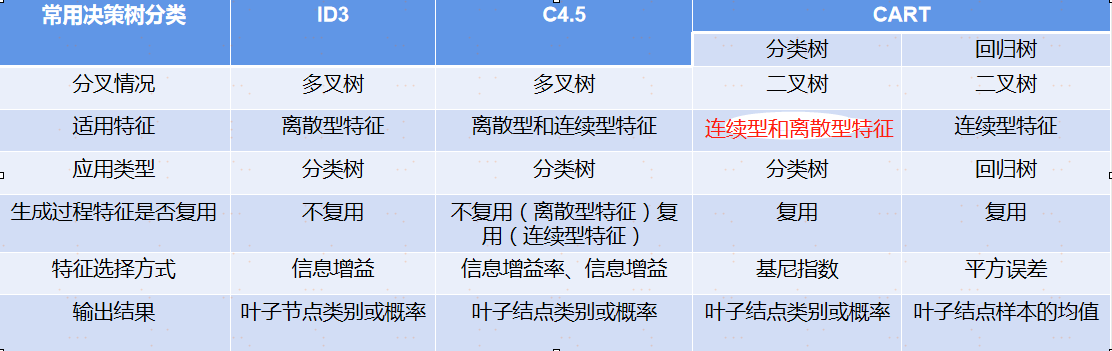
在解釋上圖之前,首先宣告,本文盡可能避免公式的羅列(想看的可以翻書或者搜相關博文),盡量用自然語言(人話)去解釋相關的概念,
要理解決策樹之前,要理解如下幾個概念:
1、概率,符號表示為p, p(x)代表隨機事件x發生的概率,比如x代表天氣情況,就有天氣晴朗的概率和下雨的概率
2、資訊量, 符號表示為h,h(x)代表隨機事件x發生這件事包含多少資訊量,h(x) = -logp(x),我們看到概率越小,資訊量越大;舉個例子,我們經常調侃某句話或者某張圖的資訊量有點大,在看這段話或這張圖的時候你腦海中肯定閃過的是各種污污的小概率事件
3、熵,物理和化學中的概念,代表一個系統的混亂程度,熵越大,混亂程度越大,比如水蒸氣的熵>水的熵>冰的熵
4、資訊熵,符號表示為H, H(x)代表各種x所有可能取值的資訊量的期望(可以粗糙地理解為資訊量的平均值,實際為加權平均),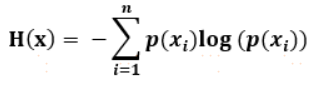 ,衡量事件x的確定程度,資訊熵越大代表事件的可能性越多,越不確定,比如明天下雨和晴天的概率均為0.5,也就是不確定性最大的情況,這時資訊熵為log2;當明天下雨的概率為1時,確定性最大,資訊熵為0,
,衡量事件x的確定程度,資訊熵越大代表事件的可能性越多,越不確定,比如明天下雨和晴天的概率均為0.5,也就是不確定性最大的情況,這時資訊熵為log2;當明天下雨的概率為1時,確定性最大,資訊熵為0,
5、條件熵,即為隨機事件x發生的條件下y事件的資訊熵的期望,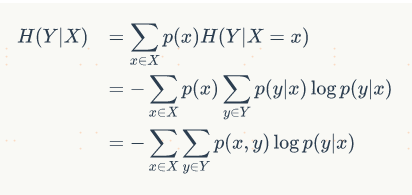 ,也即表示在已知隨機變數X的條件下隨機變數Y的不確定性的期望,強調的是隨機事件x對隨機事件y的不確定性的影響,比如隨機事件y包括今天下雨或者晴天兩種情況,隨機事件x包括昨天晚上下雨或者晴天的兩天情況;如果昨天晚上下雨,今天下雨的概率會增大,確定性會增加;如果昨晚晴天,今天晴天的概率會增加,確定性也會增加;所以考慮昨晚的天氣情況x時,y的不確定性(條件熵)會減少,
,也即表示在已知隨機變數X的條件下隨機變數Y的不確定性的期望,強調的是隨機事件x對隨機事件y的不確定性的影響,比如隨機事件y包括今天下雨或者晴天兩種情況,隨機事件x包括昨天晚上下雨或者晴天的兩天情況;如果昨天晚上下雨,今天下雨的概率會增大,確定性會增加;如果昨晚晴天,今天晴天的概率會增加,確定性也會增加;所以考慮昨晚的天氣情況x時,y的不確定性(條件熵)會減少,
6、資訊增益(互資訊),隨機變數y的資訊熵減去考慮隨機變數x的y的條件熵,即為資訊增益;衡量在考慮隨機變數x的情況下y的不確定性減少的程度,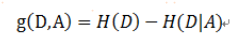
7、資訊增益率,資訊增益率的存在意義在于彌補資訊增益的應用缺陷,資訊增益主要用于幫助選擇某個能夠最大程度減少目標變數不確定性的特征(隨機變數),考慮極端情況,當選擇唯一id這種隨機變數時,會導致條件熵為0,資訊增益最大,但這種情況沒有任何泛化意義,所以需要對類似的情況進行懲罰,從而幫助我們做出更合理的選擇,所以 資訊增益率=資訊增益/懲罰項,正好考慮到上述極端情況下我們選擇的隨機變數x的資訊熵最大,所以懲罰項選擇隨機變數x的資訊熵,最后公式為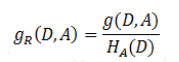
8、Gini(基尼)指數,從另一個角度衡量隨機變數的不確定性,可以這樣理解,隨機事件x發生的概率為p,然后根據該概率對隨機事件x進行預測,猜錯的可能性為1-p,而對隨機事件x的所有可能的猜錯期望即為基尼指數,即系統越混亂越不確定,猜錯的可能性的期望越高,基尼指數越高,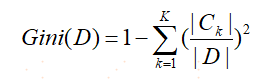 ,(也可以理解為隨機抽取兩個樣本,它們屬于不同類別的概率)
,(也可以理解為隨機抽取兩個樣本,它們屬于不同類別的概率)
在詳細說明每種決策樹之前,我覺得有必要去理解一下決策樹是什么:
1、編碼角度,決策樹是一系列if-else規則,他能通過一系列決策對樣本進行處理并輸出結果;它和硬編碼一樣可以做到對集合中樣本的不重不漏地處理,而且通過學習演算法得到決策樹,相比人為硬編碼不易出錯,所以我覺得以后開發工程師的基本技術堆疊里不僅要包括資料結構與演算法,還要包括機器學習,
2、概率論角度,決策樹展示了目標變數y在給定特征條件下的條件概率分布,
在構造決策樹的程序中,主要有三大步驟:
1、特征選擇
2、決策樹的生成(包含預剪枝)
3、決策樹的剪枝(后剪枝)
下面我們分別針對三種常用的決策樹進行介紹,他們分別為
1、ID3
2、C4.5
3、CART
2.1 ID3決策樹
2.1.1 特征選擇
應用場景:分類
依賴指標:資訊熵、條件熵、資訊增益
1、計算待分類樣本的資訊熵
2、計算某個特征條件下的條件熵
3、計算資訊增益,選擇最大資訊增益對應的特征作為當前劃分依據
4、對子節點,遞回進行特征選擇,待選擇特征集去除了上一步已選擇過的特征,即某個特征在從根到某個葉子結點的路徑上不會重復出現
2.1.2 決策樹的生成
輸入:訓練資料集D, 特征集A,閾值e,決策樹的最大深度n,作為葉子結點要小于的樣本數量m
輸出:決策樹T
1)若D中所有實體屬于同一類,則T為單結點樹,并將該類作為該結點的類標記,回傳T
2)若A為空集,則T為單結點樹,并將D中實體樹最大的類作為該結點的類標記,回傳T
3)否則,計算A中各特征對D的資訊增益,選擇資訊增益最大的特征Ag
4)(預剪枝)如果Ag的資訊增益小于閾值e,則置T為單結點樹,并將D中實體樹最大的類作為該結點的類標記,回傳T
5)否則,對Ag的每一可能取值ai, 依Ag=ai將D分割為若干非空子集Di,將Di中實體樹最大的類作為標記,構建子結點,由結點及其子結點構成樹T, 回傳T
6)對第i個子結點,以Di為訓練集,以A-{Ag}為特征集,遞回地呼叫(1)~(5)步,如果子結點的深度等于n或者子結點的樣本數量小于m,則將該子結點作為葉子結點,停止遞回呼叫,得到子樹Ti,回傳Ti
2.1.3 決策樹的剪枝
決策樹的生成是采用啟發式演算法(類似貪婪演算法),每一步做出最優選擇,實作的是區域最優,結果就是容易過擬合,因為模型記住了很多訓練資料集特有的細節,這些細節會降低模型泛化的能力
決策樹的剪枝采用的是最優化演算法,明確整棵決策樹(全域)的損失函式或代價函式(損失函式+結構風險正則化)進行迭代優化
代價函式如下:
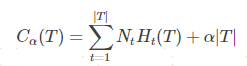
其中t代表某個葉子結點,Nt表示該葉子結點對應的樣本數量,Ht表示該結點的經驗熵(資訊熵),|T|表示模型的復雜度,α控制正則化的強度
這里的Nt可以理解為權重,畢竟如果兩個葉子結點的經驗熵相同,包含子結點數量更多的那個結點對總體混亂程度的貢獻更大,
輸入:生成演算法產生的決策樹T,正則化引數α
輸出:修剪后的子樹Tα
1)計算每個結點的經驗熵
2)遞回地從樹的葉節點向上回縮
3)如果回縮后的損失函式小于等于回縮前的,則進行剪枝
4)回傳第二步呼叫,知道不能繼續為止,得到剪枝后的決策樹
2.2 C4.5決策樹
C4.5樹是基于ID3樹的改進,具體表現為兩點
1)特征選擇不僅使用資訊增益,而且還考慮資訊增益率,具體原因請看文章開頭關于資訊增益和資訊增益率的介紹(很多資料單純地說用資訊增益率替代了資訊增益,這是不準確的)
2)增加了對連續變數(特征)的支持(這一點很多資料沒有講,尤其是沒有講如何處理連續變數)
下面我們就講一下C4.5決策樹對特征的處理,
1)對于離散特征(分類或者順序特征),該決策樹采用N叉樹的方式,對于每一個特征取值分出一個子結點,和ID3處理方式相同
2)對于連續型特征,采用二分法,
1、首先將樣本按照該特征大小進行排序
2、每兩個相鄰特征值取平均值,將該平均值作為分裂點進行樣本劃分
3、計算每種劃分所對應的資訊增益,選取資訊增益最大的分裂點作為最終二分的分裂點
4、計算所有特征的資訊增益率和資訊增益,先選取資訊增益高于平均值的特征,再選取資訊增益率最大的特征作為當前劃分依據
3)劃分后的樣本不再保留其原有值,而用布林值代替,
這里有兩個問題需要解釋:
Q1:為什么連續特征的最佳分裂點選取使用資訊增益而非資訊增益率?
因為同一個特征下,最終的結果確定是二分,這種相對的比較,也就不存在資訊增益自身的缺陷(傾向于選擇情況更多的特征,現在情況只有兩種)
Q2:為什么最佳特征的選擇先考慮資訊增益再考慮資訊增益率?
首先,資訊增益傾向于選擇可取值數量較多的變數,資訊增益率傾向于選擇可取值數較少的變數(有點兒矯枉過正),所以采用啟發式演算法,先選取資訊增益高于平均值的特征,再選取資訊增益率最大的特征作為當前劃分依據
2.3 CART樹(分類樹)
2.3.1 特征選擇
使用最小化基尼指數,具體來講,
1)對所有特征的所有可能切分點進行基尼指數計算
2)選擇基尼指數最小的特征+切分點組合
2.3.2 決策樹的生成
輸入:訓練資料集D,停止計算的條件(預剪枝條件,參考ID3決策樹)
輸出:CART決策樹
根據訓練資料集,從根節點開始,遞回地對每個結點進行以下操作:
1)設結點的訓練資料集為D,計算現有特征對該資料集的基尼指數,此時,對每一個特征A,對其可能取的每個值a(對于大量連續變數計算代價過高,可以選擇分類發生變化的點),根據樣本點對A=a的測驗為‘是’或‘否’,將D分割成D1和D2兩部分![]() ,根據
,根據![]() 計算A=a時的基尼指數,
計算A=a時的基尼指數,
2)在所有可能的特征A以及他們所有可能的切分點a中,選擇基尼指數最小的特征及其對應的切分點作為最優特征與最優切分點,依最優特征與最優切分點,從現結點生成兩個子結點,將訓練資料集依特征分配到兩個子結點中去,
3)對兩個子結點遞回地呼叫(1)(2),直至滿足停止條件
4)生成決策樹
2.3.3 決策樹的剪枝
CART的剪枝這里不詳細講解了,總體而言就兩個程序
1)根據生成的完整決策樹,計算每個內部結點對應的損失函式增加量,然后砍去損失函式增加最多的結點,生成新樹
2)對新樹遞回呼叫第一步,生成更多的新樹,構成樹集合
3)通過驗證集選擇最佳的決策樹
上圖

注意第六步中應該回傳步驟3,這是一個錯誤,該圖片摘自李航的《統計學習方法》
2.4 CART樹(回歸樹)
2.4.1 特征選擇
根據平方誤差最小化準則
1)對每個特征進行排序,依次選擇不同的切分點對樣本進行切分
2)計算切分后子結點中樣本的值與與樣本均值的平方誤差和,選擇平方誤差和最小的切分點和左右子結點平方誤差和最小的特征
3)對子結點遞回進行1、2步
2.4.2 決策樹生成

2.4.3 決策樹的剪枝
和CART(分類樹)的剪枝幾乎相同,不同點在于損失函式由基尼指數變為了最小二乘,
3、補充
1、關于決策樹的具體輸出結果問題
A:拿sklearn關于決策樹的API來講,對于分類樹,既可以用predict()方法直接獲得分類的結果,也可以用predict_prob()獲得樣本屬于某個類別的概率
2、關于整個預測流程是怎樣的?
A:首先通過訓練資料集訓練出了決策樹,包括決策樹的結構和結點,且根據訓練樣本分配到每個葉子結點的數量計算出了每個葉子結點對應的所屬類別的概率(好多資料只提到了葉子結點對應了該節點所屬類別最多的樣本對應的類別),然后待預測樣本只需要根據所訓練出的決策樹走到決策樹的某個葉子結點,輸出該結點早就計算好的分類類別或者某個類別的概率即可(回歸樹則輸出該結點對應訓練樣本的平均值),
3、關于特征值復用的問題
周志華的《機器學習》一書中講到連續特征可以復用,但沒有對此作出解釋,我的推測為,因為連續特征的可選擇切分點會有n個(大于1)情況,所以一個連續特征被使用一次之后(選擇了某個切分點),他所包含的資訊并沒有被完全利用,仍有潛在的價值(其他切分點的資訊可能對接下來的訓練你有所貢獻),據此,我也推測CART不僅對連續特征可以復用,針對離散特征(可能的切分情況大于1時),特征也可以復用,
4、關于樣本缺失值處理的問題
具體來講是兩個子問題
4.1:對于某個特征a,如何選擇a的切分點?
A:計算時只考慮a不為空的樣本
4.2:在特征a處,如果某個樣本的特征a為空,如何對樣本進行劃分?
A:將樣本同時劃入所有子結點,但要包含權重,權重值為所劃入結點的樣本所占父結點樣本的比例*樣本的權重(一般情況下所有樣本的權重初始化相等)
Finished!
感徑訓是沒有做到通俗易懂啊,,,little sad
參考資料:
1、李航-統計學習方法
2、葫蘆娃-百面機器學習
3、周志華-機器學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/47701.html
標籤:其他