目錄
- Resnet要解決的是什么問題
- Residual Block的設計
- ResNet 網路結構
- error surface對比
- Residual Block的分析與改進
- 小結
- 參考
博客:博客園 | CSDN | blog
Resnet要解決的是什么問題
ResNets要解決的是深度神經網路的“退化”問題,
什么是“退化”?
我們知道,對淺層網路逐漸疊加layers,模型在訓練集和測驗集上的性能會變好,因為模型復雜度更高了,表達能力更強了,可以對潛在的映射關系擬合得更好,而“退化”指的是,給網路疊加更多的層后,性能卻快速下降的情況,
訓練集上的性能下降,可以排除過擬合,BN層的引入也基本解決了plain net的梯度消失和梯度爆炸問題,如果不是過擬合以及梯度消失導致的,那原因是什么?
按道理,給網路疊加更多層,淺層網路的解空間是包含在深層網路的解空間中的,深層網路的解空間至少存在不差于淺層網路的解,因為只需將增加的層變成恒等映射,其他層的權重原封不動copy淺層網路,就可以獲得與淺層網路同樣的性能,更好的解明明存在,為什么找不到?找到的反而是更差的解?
顯然,這是個優化問題,反映出結構相似的模型,其優化難度是不一樣的,且難度的增長并不是線性的,越深的模型越難以優化,
有兩種解決思路,一種是調整求解方法,比如更好的初始化、更好的梯度下降演算法等;另一種是調整模型結構,讓模型更易于優化——改變模型結構實際上是改變了error surface的形態,
ResNet的作者從后者入手,探求更好的模型結構,將堆疊的幾層layer稱之為一個block,對于某個block,其可以擬合的函式為\(F(x)\),如果期望的潛在映射為\(H(x)\),與其讓\(F(x)\) 直接學習潛在的映射,不如去學習殘差\(H(x) - x\),即\(F(x) := H(x) - x\),這樣原本的前向路徑上就變成了\(F(x) + x\),用\(F(x)+x\)來擬合\(H(x)\),作者認為這樣可能更易于優化,因為相比于讓\(F(x)\)學習成恒等映射,讓\(F(x)\)學習成0要更加容易——后者通過L2正則就可以輕松實作,這樣,對于冗余的block,只需\(F(x)\rightarrow 0\)就可以得到恒等映射,性能不減,
Instead of hoping each few stacked layers directly fit a desired underlying mapping, we explicitly let these layers fit a residual mapping. Formally, denoting the desired underlying mapping as \(H(x)\), we let the stacked nonlinear layers fit another mapping of \(F(x) := H(x) - x\). The original mapping is recast into \(F(x)+x\). We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping. To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers.
—— from Deep Residual Learning for Image Recognition
下面的問題就變成了\(F(x)+x\) 該怎么設計了,
Residual Block的設計
\(F(x)+x\)構成的block稱之為Residual Block,即殘差塊,如下圖所示,多個相似的Residual Block串聯構成ResNet,
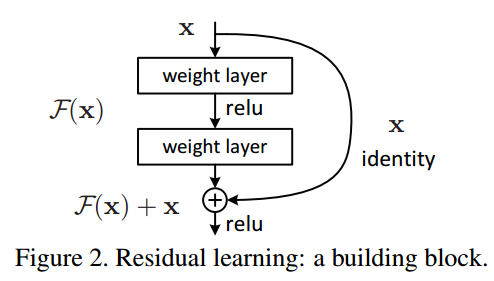
一個殘差塊有2條路徑\(F(x)\)和\(x\),\(F(x)\)路徑擬合殘差,不妨稱之為殘差路徑,\(x\)路徑為identity mapping恒等映射,稱之為”shortcut”,圖中的\(\oplus\)為element-wise addition,要求參與運算的\(F(x)\)和\(x\)的尺寸要相同,所以,隨之而來的問題是,
- 殘差路徑如何設計?
- shortcut路徑如何設計?
- Residual Block之間怎么連接?
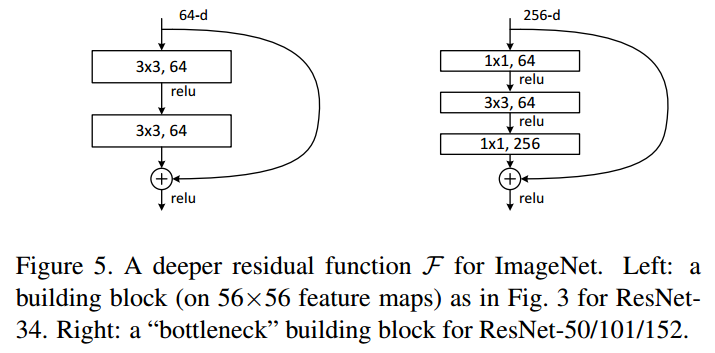
在原論文中,殘差路徑可以大致分成2種,一種有bottleneck結構,即下圖右中的\(1\times 1\) 卷積層,用于先降維再升維,主要出于降低計算復雜度的現實考慮,稱之為“bottleneck block”,另一種沒有bottleneck結構,如下圖左所示,稱之為“basic block”,basic block由2個\(3\times 3\)卷積層構成,bottleneck block由\(1\times 1\)
shortcut路徑大致也可以分成2種,取決于殘差路徑是否改變了feature map數量和尺寸,一種是將輸入\(x\)原封不動地輸出,另一種則需要經過\(1\times 1\)卷積來升維 or/and 降采樣,主要作用是將輸出與\(F(x)\)路徑的輸出保持shape一致,對網路性能的提升并不明顯,兩種結構如下圖所示,
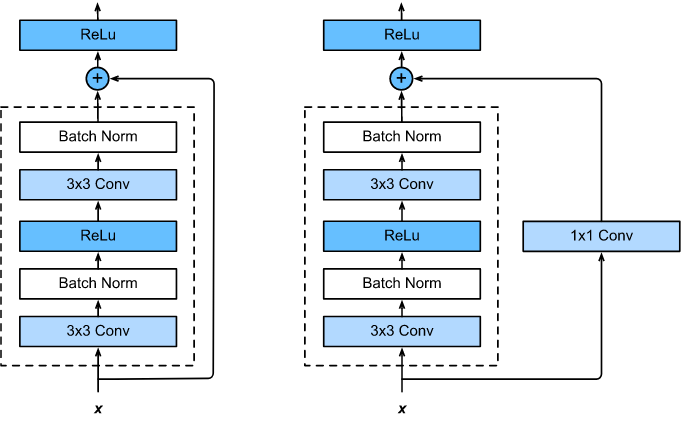
至于Residual Block之間的銜接,在原論文中,\(F(x)+x\)經過\(ReLU\)后直接作為下一個block的輸入\(x\),
對于\(F(x)\)路徑、shortcut路徑以及block之間的銜接,在論文Identity Mappings in Deep Residual Networks中有更進一步的研究,具體在文章后面討論,
ResNet 網路結構
ResNet為多個Residual Block的串聯,下面直觀看一下ResNet-34與34-layer plain net和VGG的對比,以及堆疊不同數量Residual Block得到的不同ResNet,
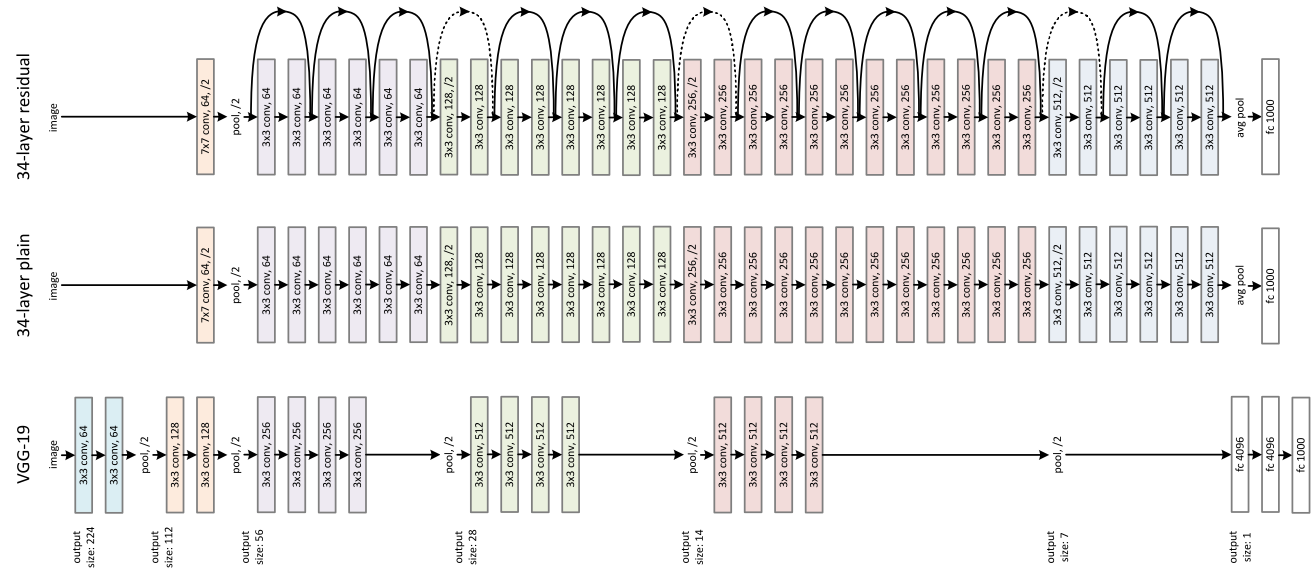
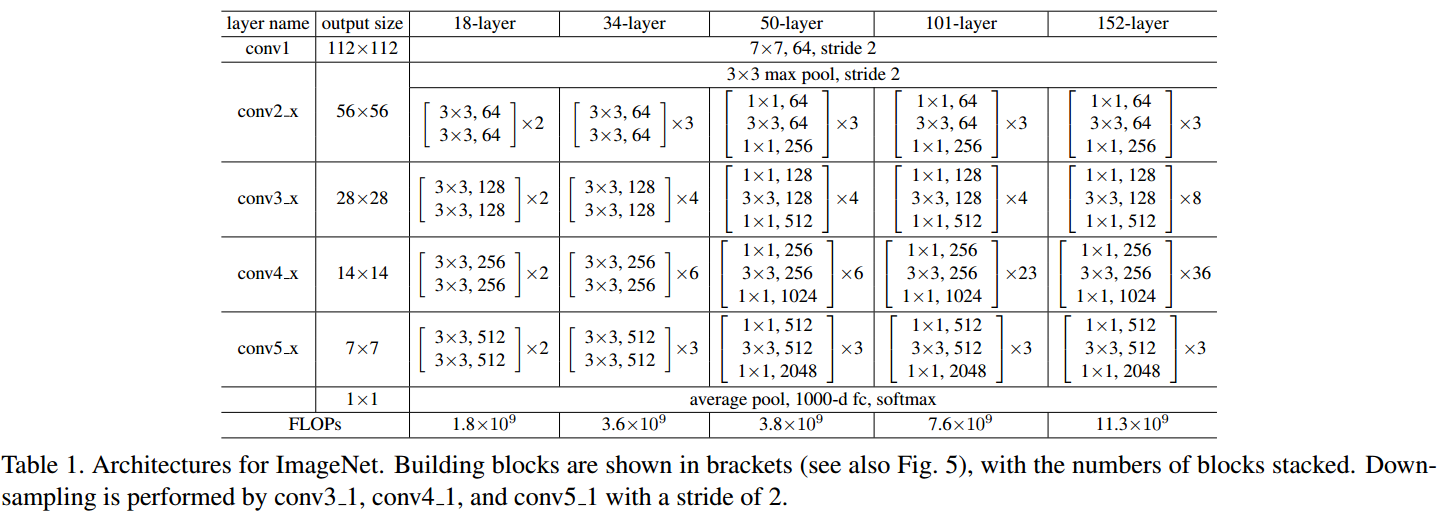
ResNet的設計有如下特點:
- 與plain net相比,ResNet多了很多“旁路”,即shortcut路徑,其首尾圈出的layers構成一個Residual Block;
- ResNet中,所有的Residual Block都沒有pooling層,降采樣是通過conv的stride實作的;
- 分別在conv3_1、conv4_1和conv5_1 Residual Block,降采樣1倍,同時feature map數量增加1倍,如圖中虛線劃定的block;
- 通過Average Pooling得到最終的特征,而不是通過全連接層;
- 每個卷積層之后都緊接著BatchNorm layer,為了簡化,圖中并沒有標出;
ResNet結構非常容易修改和擴展,通過調整block內的channel數量以及堆疊的block數量,就可以很容易地調整網路的寬度和深度,來得到不同表達能力的網路,而不用過多地擔心網路的“退化”問題,只要訓練資料足夠,逐步加深網路,就可以獲得更好的性能表現,
下面為網路的性能對比,
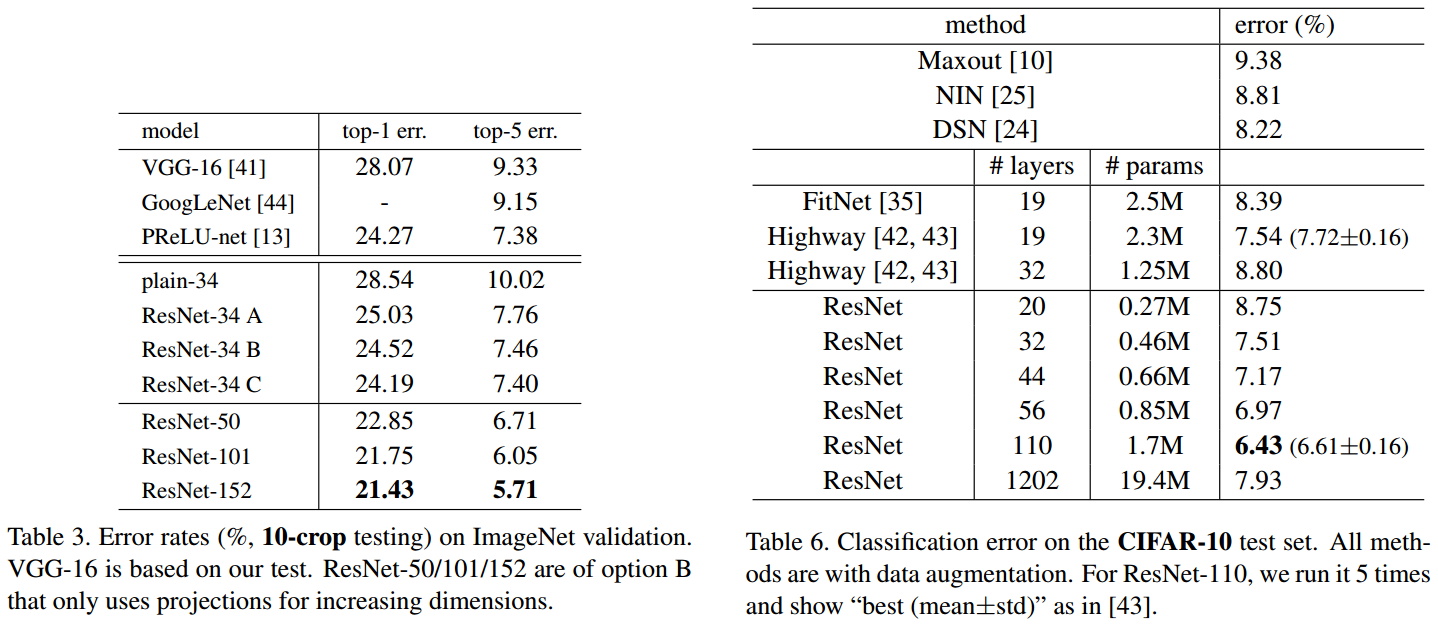
error surface對比
上面的實驗說明,不斷地增加ResNet的深度,甚至增加到1000層以上,也沒有發生“退化”,可見Residual Block的有效性,ResNet的動機在于認為擬合殘差比直接擬合潛在映射更容易優化,下面通過繪制error surface直觀感受一下shortcut路徑的作用,圖片截自Loss Visualization,
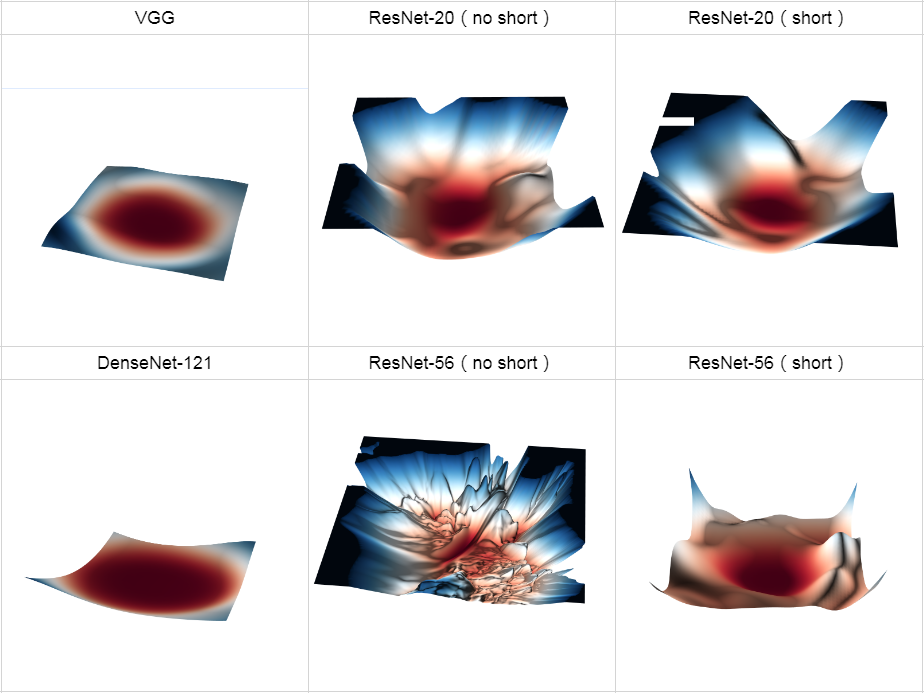
可以發現:
- ResNet-20(no short)淺層plain net的error surface還沒有很復雜,優化也會很困難,但是增加到56層后復雜程度極度上升,對于plain net,隨著深度增加,error surface 迅速“惡化”;
- 引入shortcut后,error suface變得平滑很多,梯度的可預測性變得更好,顯然更容易優化;
Residual Block的分析與改進
論文Identity Mappings in Deep Residual Networks進一步研究ResNet,通過ResNet反向傳播的理論分析以及調整Residual Block的結構,得到了新的結構,如下
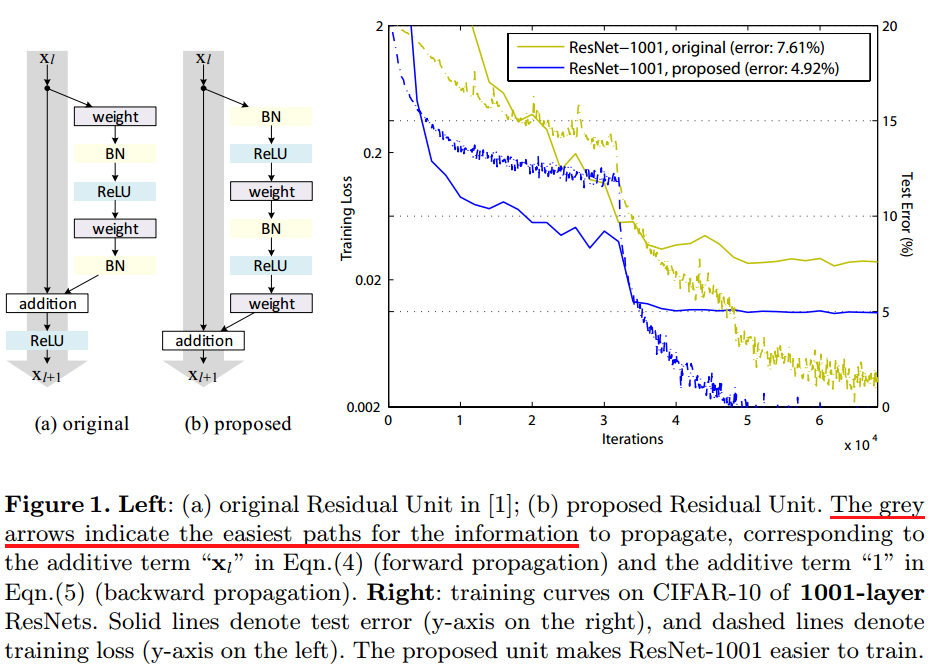
注意,這里的視角與之前不同,這里將shortcut路徑視為主干路徑,將殘差路徑視為旁路,
新提出的Residual Block結構,具有更強的泛化能力,能更好地避免“退化”,堆疊大于1000層后,性能仍在變好,具體的變化在于
- 通過保持shortcut路徑的“純凈”,可以讓資訊在前向傳播和反向傳播中平滑傳遞,這點十分重要,為此,如無必要,不引入\(1\times 1\)卷積等操作,同時將上圖灰色路徑上的ReLU移到了\(F(x)\)路徑上,
- 在殘差路徑上,將BN和ReLU統一放在weight前作為pre-activation,獲得了“Ease of optimization”以及“Reducing overfitting”的效果,
下面具體解釋一下,
令\(h(x_l)\)為shortcut路徑上的變換,\(f\)為addition之后的變換,原Residual Block中\(f=ReLU\),當\(h\)和\(f\)均為恒等映射時,可以得到任意兩層\(x_L\)和\(x_l\)之間的關系,此時資訊可以在\(x_l\)和\(x_L\)間無損直達,如下前向傳播中的\(x_l\)以及反向傳播中的\(1\),
\[\begin{aligned}\mathbf{y}_{l}&= h\left(\mathbf{x}_{l}\right)+\mathcal{F}\left(\mathbf{x}_{l}, \mathcal{W}_{l}\right) \\ \mathbf{x}_{l+1}&=f\left(\mathbf{y}_{l}\right) \\\mathbf{x}_{l+1}&=\mathbf{x}_{l}+\mathcal{F}\left(\mathbf{x}_{l}, \mathcal{W}_{l}\right) \\\mathbf{x}_{L}&=\mathbf{x}_{l}+\sum_{i=l}^{L-1} \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right) \\\frac{\partial \mathcal{E}}{\partial \mathbf{x}_{l}}=\frac{\partial \mathcal{E}}{\partial \mathbf{x}_{L}} \frac{\partial \mathbf{x}_{L}}{\partial \mathbf{x}_{l}}&=\frac{\partial \mathcal{E}}{\partial \mathbf{x}_{L}}\left(1+\frac{\partial}{\partial \mathbf{x}_{l}} \sum_{i=l}^{L-1} \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right)\right)\end{aligned} \]
反向傳播中的這個\(1\)具有一個很好的性質,任意兩層間的反向傳播,這一項都是\(1\),可以有效地避免梯度消失和梯度爆炸,如果\(h\)和\(f\)不是恒等映射,就會讓這一項變得復雜,若是令其為一個大于或小于1的scale因子,反向傳播連乘后就可能導致梯度爆炸或消失,層數越多越明顯,這也是ResNet比highway network性能好的原因,需要注意的是,BN層解決了plain net的梯度消失和爆炸,這里的1可以避免short cut 路徑上的梯度消失和爆炸,
shortcut路徑將反向傳播由連乘形式變為加法形式,讓網路最終的損失在反向傳播時可以無損直達每一個block,也意味著每個block的權重更新都部分地直接作用在最終的損失上,看上面前向傳播的公式,可以看到某種ensemble形式,資訊雖然可以在任意兩層之間直達,但這種直達其實是隱含的,對某個block而言,它只能看到加法的結果,而不知道加法中每個加數是多數,從資訊通路上講尚不徹底——由此也誕生了DenseNet,
對于殘差路徑的改進,作者進行了不同的對比實驗,最終得到了將BN和ReLU統一放在weight前的full pre-activation結構,

小結
ResNet的動機在于解決“退化”問題,殘差塊的設計讓學習恒等映射變得容易,即使堆疊了過量的block,ResNet可以讓冗余的block學習成恒等映射,性能也不會下降,所以,網路的“實際深度”是在訓練程序中決定的,即ResNet具有某種深度自適應的能力,
深度自適應能解釋不會“退化”,但為什么可以更好?
通過可視化error surface,我們看到了shortcut的平滑作用,但這只是結果,背后的根由是什么?
也許徹底搞懂ResNet還需要進一步地研究,但已有很多不同的理解角度,
- 微分方程的角度,A Proposal on Machine Learning via Dynamical Systems
- ensemble的角度,Residual Networks Behave Like Ensembles of Relatively Shallow Networks
- 資訊/梯度通路的角度,Identity Mappings in Deep Residual Networks
- 類比泰勒展開、類比小波……
通過不同側面嘗試解釋,能獲得對ResNet更深刻更全面的認識,限于篇幅,本文不再展開,以上,
PS:實際是筆者還沒整理出清晰完整的思路(逃
參考
- paper: Deep Residual Learning for Image Recognition
- paper: Identity Mappings in Deep Residual Networks
- Loss Visualization
- blog: ResNet, torchvision, bottlenecks, and layers not as they seem
- code: pytorch-resnet
- Residual Networks (ResNet)
- code: resnet-1k-layers/resnet-pre-act.lua
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/49915.html
標籤:其他
上一篇:AB實驗人群定向HTE模型5 - Meta Learner
下一篇:淺析word2vec(一)