1 word2vec
在自然語言處理的大部分任務中,需要將大量文本資料傳入計算機中,用以資訊發掘以便后續作業,但是目前計算機所能處理的只能是數值,無法直接分析文本,因此,將原有的文本資料轉換為數值資料成為了自然語言處理任務的關鍵一環,
Word2vec,為一群用來產生詞向量的相關模型,這些模型為淺層雙層的神經網路,用來訓練以重新建構語言學之詞文本, ————維基百科
簡單來說,word2vec的系列模型可以將文字(此處特指中文字符)轉換成向量,比如“我愛中國”這句話,經過模型處理后,可能會變為以下4個向量:
(0.12,0.45,-0.3,0.44),(0.2,0.6,0.7,0.9),(-0.76,0.53,0.88,-0.31),(0.47,0.92,0.66,0.89),
這種向量稱為詞向量(對中文而言也可以稱作字向量),后續對"我愛中國"的處理便可以轉為對以上4個詞向量的處理,
那么這種轉換是如何完成的,這就要談及word2vec中的兩個經典模型:skip-grams和CBOW,CBOW下次再講,本文主要介紹skip-grams.
關于skip-grams的詳細說明,諸位可以參考網頁:https://becominghuman.ai/how-does-word2vecs-skip-gram-work-f92e0525def4
2 模型特點
skip-grams的作業方法與其它模型略有差別,詞向量的獲取并不是通過輸入一個字到skip-grams中再從模型中輸出一個向量,相反,只要將skip-grams模型訓練完成后,所有參與訓練的字就已經獲得了自己的詞向量;換句話說,所有的詞向量已經作為模型的可訓引數儲存在模型自身,想要得到某個字的詞向量,只需依照某種規則從模型引數中提取即可,所以模型的訓練階段至關重要,
3 訓練程序
3.1 獲取訓練樣本
模型的訓練思路大體如下:初始先給每個字隨機分配一個詞向量,然后選定一字作為中心字,取一個固定的長度,在原始語料中獲得訓練樣本,如下圖所示:
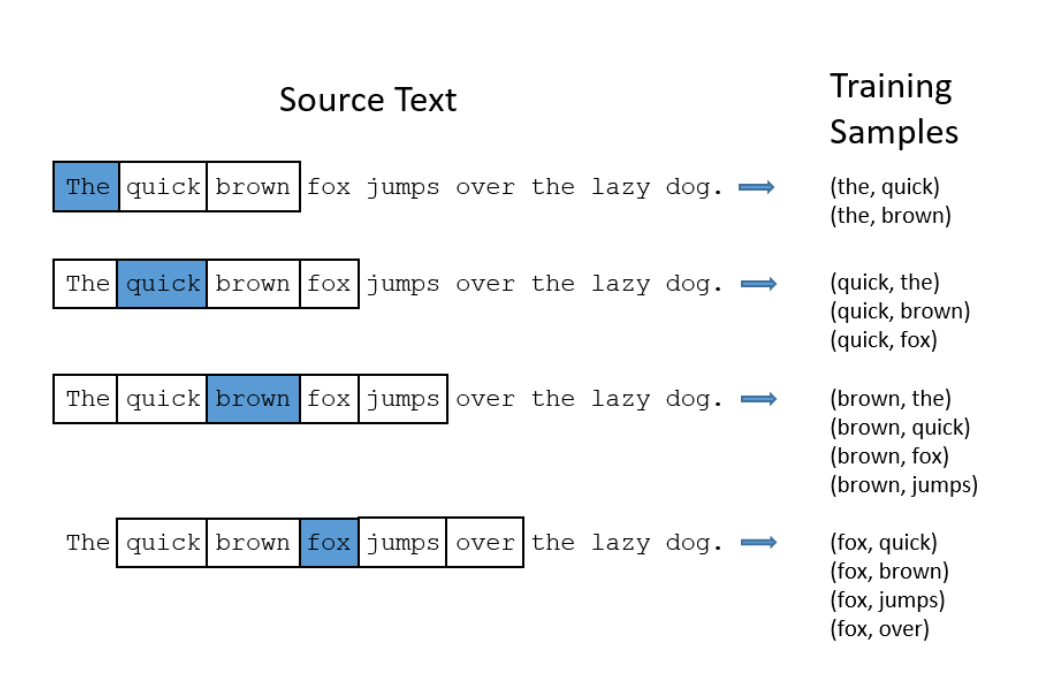
3.2 統計頻率
統計背景關系字出現在中心字周圍的頻率,作為該字與中心字共存的概率,
3.3 模型引數調整
在給定的詞向量的基礎上,依次計算每個字與中心字共存的概率大小,多數情況下,這與上一步實際統計出來的有所差異,所以要調整模型引數,使得概率分布更符合實際情況,對引數的調整就是對詞向量的調整,如此進行若干次后,以至于每個字都有機會作為中心字參與訓練,引數訓練完成后,則每個字對應的詞向量已經得到,
4 備注
模型訓練完成后,每個字通常會有兩個詞向量與之對應,一個是該字作為中心字時的詞向量,一個是該字作為其它字的背景關系字時的詞向量,一般選取前者代表該字最終的詞向量,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/49917.html
標籤:其他
上一篇:ResNet詳解與分析