在分類問題中常用到交叉熵損失函式 CrossEntropyLoss,有時候還能看到NLLLoss損失,兩個損失是有關聯的,
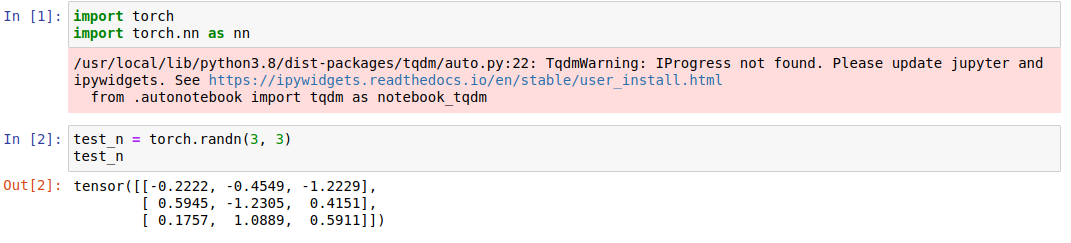
1、首先,隨機生成一個3 * 3的 tensor,假設該張量 test_n 是我們的神經網路的輸出,一行相當于一個樣本的預測結果,如下:
2、使用Softmax處理生成的tensor,這里要對每行元素進行操作,dim=1是對每行的元素進行操作(也就是沿著列增加的方向),dim=0是對每列的元素進行操作(也就是沿著行增加的方向),

3、接著對處理得到的tensor求對數,Softmax處理后的數值都在0~1之間,所以取 ln對數之后值域(-∞,0)
假設我們的目標是 target = torch.tensor([2, 0, 1]),我們希望 target的 label 所對應的概率越大越好(在對數影像中越接近X軸的1),
那么對數值的絕對值就要越小(在對數影像中越接近Y軸的0),2是第一行中要取數值的索引,0是第二行要取數值的索引,1是第三行要取數值的索引,

對取出來的數值取絕對值后,再求平均值,該平均值就是要優化的損失,越小越好,
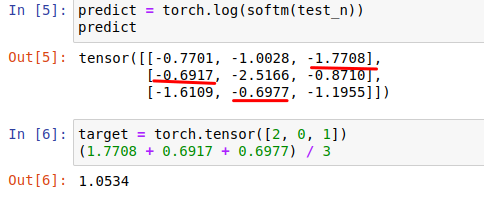
使用NLLLoss來驗證下,和上述解釋相符,

而CrossEntropyLoss損失函式是Softmax + Log + NLLLoss這些操作合并起來的,直接將神經網路的輸出test_n和target作為輸入進行計算,

Enjoy it!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/499635.html
標籤:其他