摘要:本期我們來深入講解網路模型推理場景下,具體怎么做,
本文分享自華為云社區《【CANN檔案速遞09期】應用開發之推理場景》,作者: 昇騰CANN ,
我們知道,使用AscendCL介面開發應用時,典型場景包括網路模型推理、單算子執行等,本期我們來深入講解網路模型推理場景下,具體怎么做,
首先,我們得先了解下,使用AscendCL時,經常會提到的“資料型別的操作介面” ,這是什么呢?為啥會存在?
在C/C++中,對用戶開放的資料型別通常以Struct結構體方式定義、以宣告變數的方式使用,但這種方式一旦結構體要增加成員引數,用戶的代碼就涉及兼容性問題,不便于維護,因此AscendCL對用戶開放的資料型別,均以介面的方式操作該資料型別,例如,呼叫某個資料型別的Create介面創建該資料型別、呼叫Get介面獲取資料型別內引數值、呼叫Set介面設定資料型別內的引數值、呼叫Destroy介面銷毀該資料型別,用戶無需關注定義資料型別的結構體長什么樣,這樣即使后續資料型別需擴展,只需增加該資料型別的操作介面即可,也不會引起兼容性問題,
所以,總結下,“資料型別的操作介面”就是創建資料型別、Get/Set資料型別中的引數值、銷毀資料型別的一系列介面,存在的最大好處就是減少兼容性問題,
接下來,進入我們今天的主題,怎么用AscendCL的介面開發網路模型推理場景下的應用,
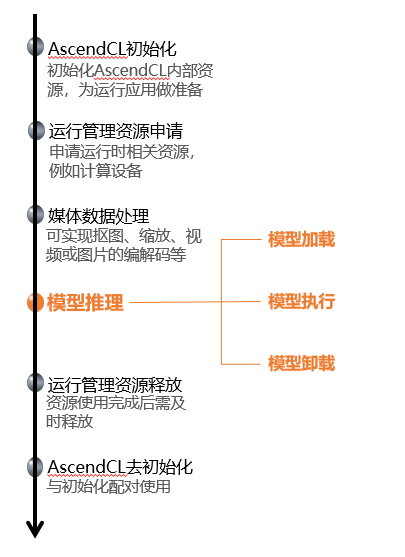
01 AscendCL初始化與去初始化
使用AscendCL介面開發應用時,必須先初始化AscendCL ,否則可能會導致后續系統內部資源初始化出錯,進而導致其它業務例外,在初始化時,還支持以下跟推理相關的可配置項(例如,性能相關的采集資訊配置),以json格式的組態檔傳入AscendCL初始化介面,如果當前的默認配置已滿足需求(例如,默認不開啟性能相關的采集資訊配置),無需修改,可向AscendCL初始化介面中傳入NULL,或者可將組態檔配置為空json串(即組態檔中只有{}),
有初始化就有去初始化,在確定完成了AscendCL的所有呼叫之后,或者行程退出之前,需呼叫AscendCL介面實作AscendCL去初始化,

02 運行管理資源申請與釋放
運行管理資源包括Device、Context、Stream、Event等,此處重點介紹Device、Context、Stream,其基本概念如下圖所示 ,
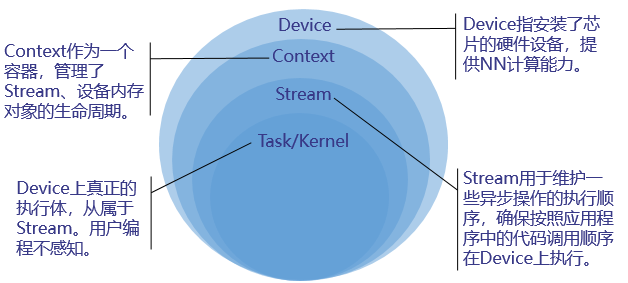
您需要按順序依次申請如下運行管理資源:Device、Context、Stream,確保可以使用這些資源執行運算、管理任務,所有資料處理都結束后,需要按順序依次釋放運行管理資源:Stream、Context、Device,
在申請運行管理資源時,Context、Stream支持隱式創建和顯式創建兩種申請方式,


03 媒體資料處理
如果模型對輸入圖片的寬高要求與用戶提供的源圖不一致,AscendCL提供了媒體資料處理的介面,可實作摳圖、縮放、格式轉換、視頻或圖片的編解碼等,將源圖裁剪成符合模型的要求,后續期刊中會展開說明這個功能,本期著重介紹模型推理的部分,以輸入圖片滿足模型的要求為例,
04 模型加載
模型推理場景下,必須要有適配昇騰AI處理器的離線模型(*.om檔案),我們可以使用ATC(Ascend Tensor Compiler)來構建模型,如果模型推理涉及動態Batch、動態解析度等特性,需在構建模型增加相關配置,怎么使用ATC來構建模型,在往期檔案速遞中有介紹,可拖動到文末查閱,
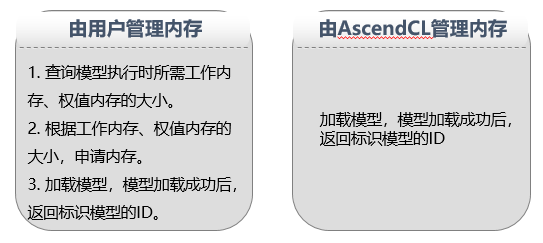
有了模型,就可以開始加載了,當前AscendCL支持以下幾種方式加載模型:
? 從*.om檔案中加載模型資料,由AscendCL管理記憶體
? 從*.om檔案中加載模型資料,由用戶自行管理記憶體
? 從記憶體中加載模型資料,由AscendCL管理記憶體
? 從記憶體中加載模型資料,由用戶自行管理記憶體
由用戶自行管理記憶體時,需關注作業記憶體、權值記憶體,作業記憶體用于存放模型執行程序中的臨時資料,權值記憶體用于存放權值資料,這個時候,是不是有疑問了,我怎么知道作業記憶體、權值記憶體需要多大?不用擔心,AscendCL不僅提供了加載模型的介面,同時也提供了“根據模型檔案獲取模型執行時所需的作業記憶體和權值記憶體大小”的介面,方便用戶使用 ,

05 模型執行
在呼叫AscendCL介面進行模型推理時,模型推理有輸入、輸出資料,輸入、輸出資料需要按照AscendCL規定的資料型別存放,相關資料型別如下:
? 使用aclmdlDesc型別的資料描述模型基本資訊(例如輸入/輸出的個數、名稱、資料型別、Format、維度資訊等),
模型加載成功后,用戶可根據模型的ID,呼叫該資料型別下的操作介面獲取該模型的描述資訊,進而從模型的描述資訊中獲取模型輸入/輸出的個數、記憶體大小、維度資訊、Format、資料型別等資訊,
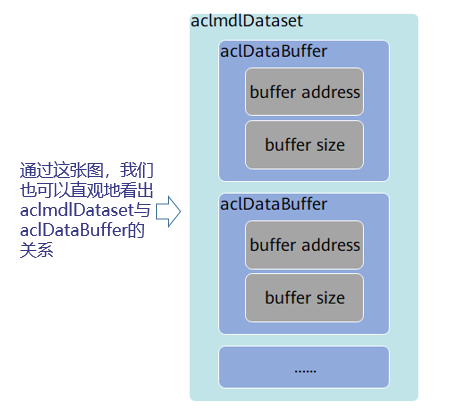
? 使用aclDataBuffer型別的資料來描述每個輸入/輸出的記憶體地址、記憶體大小,
呼叫aclDataBuffer型別下的操作介面獲取記憶體地址、記憶體大小等,便于向記憶體中存放輸入資料、獲取輸出資料,
? 使用aclmdlDataset型別的資料描述模型的輸入/輸出資料,
模型可能存在多個輸入、多個輸出,呼叫aclmdlDataset型別的操作介面添加多個aclDataBuffer型別的資料,

準備好模型執行所需的輸入、輸出資料型別后,存放好模型執行的輸入資料后,可以執行模型推理了,如果模型的輸入涉及動態Batch、動態解析度等特性,則在模型執行前,還需要呼叫AscendCL介面告訴模型本次執行時需要用的Batch數、解析度等,
當前AscendCL支持同步模型執行、異步模型執行兩種方式,這里說的同步、異步是站在呼叫者和執行者的角度,
? 若呼叫模型執行的介面后需等待推理完成再回傳,則表示同步的,當用戶呼叫同步模型執行介面后,可直接從該介面的輸出引數中獲取模型執行的結果資料,如果需要推理的輸入資料量很大,同步模型執行時,需要等所有資料都處理完成后,才能獲取推理的結果資料,
? 若呼叫模型執行的介面后不等待推理完成完成再回傳,則表示異步的,當用戶呼叫異步模型執行介面時,需指定Stream( Stream用于維護一些異步操作的執行順序,確保按照應用程式中的代碼呼叫順序在Device上執行),另外,還需呼叫aclrtSynchronizeStream介面阻塞程式運行,直到指定Stream中的所有任務都完成,才可以獲取推理的結果資料,如果需要推理的輸入資料量很大,異步模型執行時,AscendCL提供了Callback機制,觸發回呼函式,在指定時間內一旦有推理的結果資料,就獲取出來,達到分批獲取推理結果資料的目的,提高效率,

推理結束后,如果需要獲取并進一步處理推理結果資料,則由用戶自行編碼實作,最后,別忘了,我們還要銷毀aclmdlDataset、aclDataBuffer等資料型別,釋放相關記憶體,防止記憶體泄露,
06 模型卸載
在模型推理結束后,還需要通過aclmdlUnload介面卸載模型,并銷毀aclmdlDesc型別的模型描述資訊、釋放模型運行的作業記憶體和權值記憶體,

07 更多介紹
了解更詳細的內容,登錄昇騰社區,在開發者檔案中心(https://www.hiascend.com/document)閱讀相關檔案:
昇騰CANN檔案中心致力于為開發者提供更優質的內容和更便捷的開發體驗,助力CANN開發者共建AI生態,任何意見和建議都可以在昇騰社區反饋,您的每一份關注都是我們前進的動力,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/504434.html
標籤:其他
上一篇:滑動視窗