作者|Yogeeshwari S
編譯|VK
來源|Towards Data Science
我很高興與大家分享我的機器學習和深度學習經驗,同時我們將在一個Kaggle競賽得到解決方案,學習程序的分析也是非常直觀,具有娛樂性和挑戰性,希望這個博客最終能給讀者一些有用的學習幫助,
目錄
-
業務問題
-
誤差度量
-
機器學習和深度學習在我們的問題中的應用
-
資料來源
-
探索性資料分析-EDA
-
現有方法
-
資料準備
-
模型說明
-
結果
-
我對改善RMSLE的嘗試
-
未來的作業
-
GitHub存盤庫
-
參考參考

1.業務問題
Mercari是一家在日本和美國運營的電子商務公司,其主要產品是Mercari marketplace的應用程式,人們可以使用智能手機輕松地出售或購買物品,
應用程式的用戶可以自由選擇價格,同時列出商品,然而,這里的風險更高,因為如果價格表與市場價格相比過高或過低,消費者和客戶都會處于虧損狀態,上述問題的解決方案是自動推薦商品價格,因此,最大的社區購物應用程式希望向賣家提供價格建議,
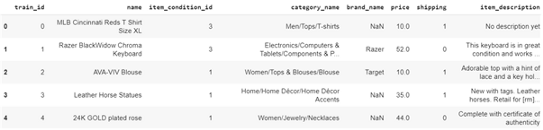
目前的問題是預測任何給定產品的價格,這說明這是一個回歸問題,訓練資料中的特征包括物品的train_id, name, item_condition_id, category_name, brand_name, price, shipping, item_description,
除了目標變數價格之外,我們在測驗資料中擁有所有其他特征,這些特征不僅是離散的和連續的,而且包含賣家提供的商品的文字描述,例如,女性配飾產品的文字說明如下:

我們可以看到,這兩種產品的售價不同,第一種售價16美元,第二種售價9美元,
因此,這里的挑戰是,我們需要建立一個模型,根據上圖所示的描述,以及產品名稱、品牌名稱、商品狀況等,來預測產品的正確價格,
2.誤差度量
這個問題的誤差度量是均方根對數誤差(RMSLE),請參閱此博客以了解有關度量的更多資訊
https://medium.com/analytics-vidhya/root-mean-square-log-error-rmse-vs-rmlse-935c6cc1802a
度量計算公式如下圖所示:

RMSLE計算代碼如下:
def rmsle_compute(y_true, y_pred):
#https://www.kaggle.com/gspmoreira/cnn-glove-single-model-private-lb-0-41117-35th
assert len(y_true) == len(y_pred)
score = np.sqrt(np.mean(np.power(np.log1p(y_pred) - np.log1p(y_true), 2)))
return score
3.機器學習和深度學習在我們的問題中的應用
在這個人工智能(AI)時代,當我們想到AI的時候,有兩個流行詞分別是機器學習和深度學習,我們發現人工智能無處不在,它們現在是人類生活的一部分,無論是通勤(例如出租車預訂)、醫療診斷、個人助理(如Siri、Alexa)、欺詐檢測、犯罪偵查、在線客戶支持、產品推薦、自動駕駛汽車,等等,利用先進的機器學習和深度學習演算法,任何型別的預測問題都可以解決,
我們的問題是獨特的,因為它是一個基于自然語言處理(NLP)的回歸任務,NLP的第一步是將文本表示為數字,即將文本轉換為數字向量表示,以構造回歸函式,
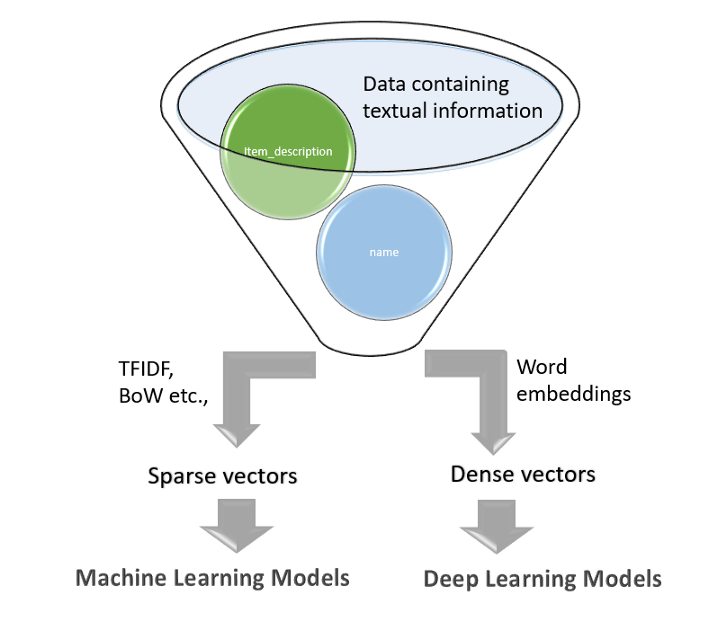
解決價格預測問題的一種方法是利用向量化技術,如TF-IDF、BoW,并構建固定大小的稀疏向量表示,這些表示將被經典的機器學習演算法(例如簡單線性回歸器、基于樹的回歸器等)使用,
另一種方法是使用深層NLP體系結構(例如CNN、LSTM、GRU或它們的組合),這些體系結構可以獨立學習特征,可以得到密集向量,在當前的分析中,我們正在研究這兩種方法,
4.資料來源
這個分析的資料集來自Kaggle,一個流行的在線社區或者資料科學家的資料平臺,

了解資料
訓練集由140多萬件產品組成,第二階段測驗集由340多萬件產品組成,
列出訓練/測驗資料中的欄位名:
- train_id 或者test_id — 串列的唯一id
- name — 賣方提供的產品名稱,請注意,為避免資料泄漏,此欄位中的價格被洗掉并表示為[rm]
- item_condition_id — 這里賣家提供物品條件
- category_name — 每個物品的類別串列
- brand_name — 每個商品所屬的相應品牌
- price — 這是我們的目標變數,以美元表示(不在測驗集中)
- shipping — 1,如果運費由賣方支付,否則為0
- item_description — 此處給出了每個物品的描述,價格被洗掉并表示為[rm]
以下資料的部分截圖:
5.探索性資料分析-EDA
EDA是資料科學程序中的一個重要步驟,是一種統計方法,通常使用可視化方法從資料集中獲得更多的見解,在深入研究EDA之前,讓我們快速查看資料以了解更多資訊,下面是檢查空值的代碼段:
print(train.isnull().sum())
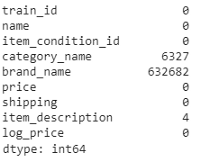
從上面的輸出中,我們發現三列,即類別名稱(category name)、品牌名稱(brand name)和物品描述(item description)攜帶空值,其中,品牌名稱包含了很多缺失的值(~632k),列類別名稱包含~6.3k個空值,而物品描述只有4個空值,讓我們稍后在創建模型時再處理它們,現在我們逐個深入研究EDA特性,
5.1 類別名稱的單變數分析
訓練資料集中共有1287個類別,下面是用于計數的代碼段:
category_count = train['category_name'].value_counts()

類別計數圖如下所示:
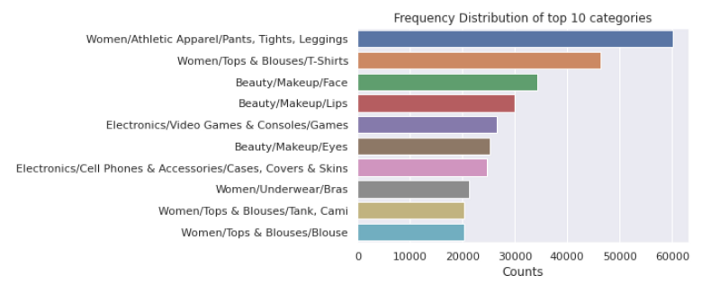
上面的條形圖顯示了出現頻率最高的10個類別,人們會注意到,女裝在所有群體中占據著制高點,
每個類別名稱由3個子部分組成,用“/”分隔,并有主類別/子類別1/子類別2名稱,重要的是要將它們分開,并將它們作為新的特征包含進來,這樣我們的模型就能做出更好的預測,
劃分類別
在我們的分析中,我們使用以下函式將每個類別的名稱劃分為主類別、子類別1、子類別2,
def split_categories(category):
'''
函式在資料集中劃分類別列并創建3個新列:
'main_category','sub_cat_1','sub_cat_2'
'''
try:
sub_cat_1,sub_cat_2,sub_cat_3 = category.split("/")
return sub_cat_1,sub_cat_2,sub_cat_3
except:
return ("No label","No label","No label")
def create_split_categories(data):
'''
使用split_categories函式創建3個新列的函式
: 'main_category','sub_cat_1','sub_cat_2'
'''
#https://medium.com/analytics-vidhya/mercari-price-suggestion-challenge-a-machine-learning-regression-case-study-9d776d5293a0
data['main_category'],data['sub_cat_1'],data['sub_cat_2']=zip(*data['category_name'].\
apply(lambda x: split_categories(x)))
此外,使用下面的代碼行計算三列中每個列中的類別數:
main_category_count_te = test['main_category'].value_counts()
sub_1_count_te = test['sub_cat_1'].value_counts()
sub_2_count_te = test['sub_cat_2'].value_counts()
上述分析表明,訓練資料中有11個主要類別,這些類別又分為114個子類別(子類別1),這些子類別又被進一步分配到865個特定類別(子類別2),繪制類別的代碼如下所示:
def plot_categories(category,title):
'''
這個函式接受一個類別和標題作為輸入,并繪制條形圖,
'''
#https://seaborn.pydata.org/generated/seaborn.barplot.html
sns.set(style="darkgrid")
sns.barplot(x=category[:10].values, y=category[:10].index)
plt.title(title)
plt.xlabel('Counts', fontsize=12)
plt.show()
#https://www.datacamp.com/community/tutorials/categorical-data
plot_categories(category_count,"Frequency Distribution of top 10 categories")
拆分后該類別每列前10項的條形圖如下:
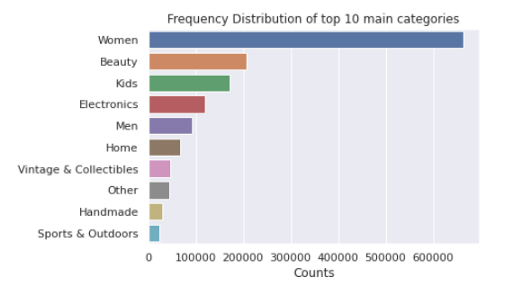
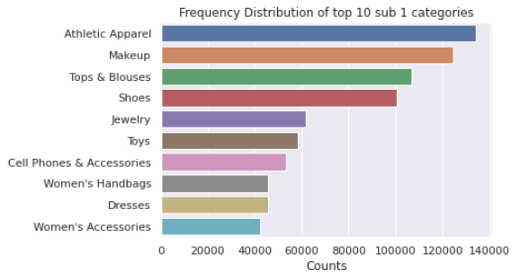
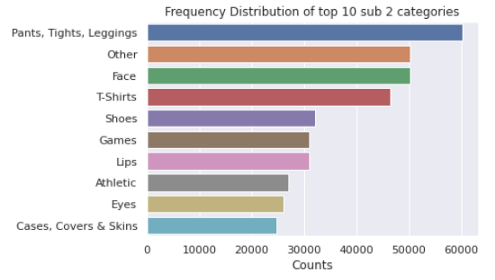
5.2品牌名稱的單變數分析
共有4807個品牌,其中最常出現的前10個品牌如下圖所示:
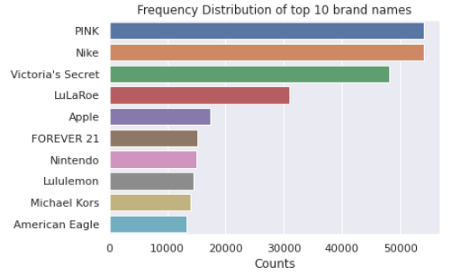
繪圖代碼在這里:
#https://www.datacamp.com/community/tutorials/categorical-data
sns.barplot(x=brand_count[:10].values, y=brand_count[:10].index)
plt.title('Frequency Distribution of top 10 brand names')
plt.xlabel('Counts', fontsize=12)
plt.show()
值得注意的是PINK 和NIKE 品牌,緊隨其后的是維多利亞的秘密,
5.3價格單變數分析
由于價格是數值的,所以我們使用describe()函式來查看摘要,下面是代碼片段:
train.price.describe()
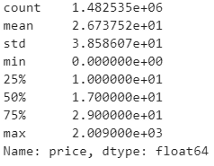
任何產品的最高價格為2009美元,最低價格為0,還應注意的是,75%的產品價格低于29美元,50%的產品價格低于17美元,而25%的產品價格低于10美元,平均價格區間為26.7美元,
價格變數分布
目標的分布
plt.title("Distribution of Price variable")
plt.xlabel("Price(USD)")
plt.ylabel("No. of products")
plt.hist(train['price'],bins=30)
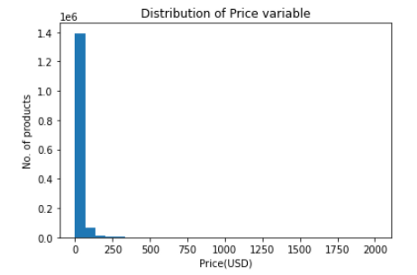
價格特征遵循右偏分布,如上圖所示,正如這里所討論的,由于分布的另一側的點,傾斜分布會導致較高的均方誤差(MSE)值,如果資料是正態分布,則MSE就不會那么大,
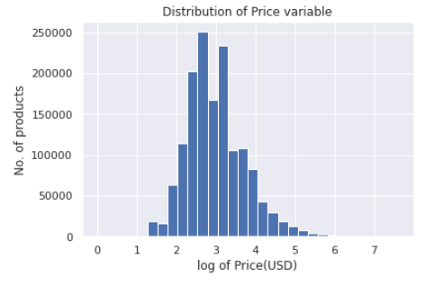
因此,對price特征進行log轉換是不可避免的,如果資料是正態分布的,那么模型的性能也會更好(參見這里),這是通過以下代碼片段完成的:
def log_price(price):
return np.log1p(price)
下圖為對數轉換后的價格變數圖,
5.4物品描述的單變數分析
我們正在繪制詞云以了解描述中常見的單詞,對應的代碼段,圖如下:
word_counter = Counter(train['item_description'])
most_common_words = word_counter.most_common(500)
#https://www.geeksforgeeks.org/generating-word-cloud-python/
# 創建并生成一個詞云影像:
stopwords = get_stop_words('en')
#https://github.com/Alir3z4/python-stop-words/issues/19
stopwords.extend(['rm'])
wordcloud = WordCloud(stopwords=stopwords,background_color="white").generate(str(most_common_words))
# 顯示生成的影像:
plt.figure(figsize=(10,15))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title("Word cloud generated from the item_descriptions\n")
plt.axis("off")
plt.show()

從上面的單詞cloud中,我們可以注意到在我們的item_description中經常出現的單詞,
描述的字數
單獨的文本描述可能是這個問題(參考)的一個重要特征,即對于機器學習模型,并且將有助于嵌入深度學習模型的程序,
train['description_wc'] = [len(str(i).split()) for i in train['item_description']]
為了進一步研究該特征,我們繪制了如下所示的箱線圖和分布圖,下面是代碼:
箱線圖
sns.boxplot(train['description_wc'],orient='v')
plt.title("Box plot of description word count")
plt.xlabel("item_description")
plt.ylabel("No. of words")
plt.show()
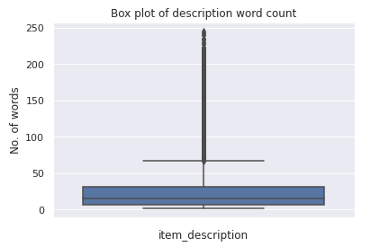
我們可以注意到,大多數描述包含大約少于40個單詞,
分布圖
plt.figure(figsize=(10,3))
sns.distplot(train['description_wc'], hist=False)
plt.title('Plot of the word count for each item description')
plt.xlabel('Number of words in each description')
plt.show()
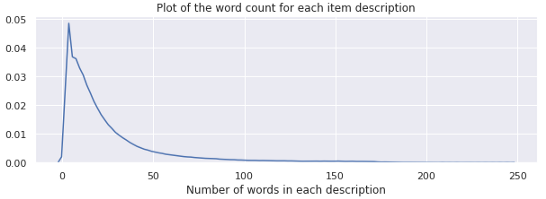
描述字數的密度圖是右偏的,
統計資料摘要
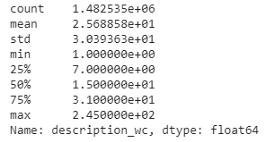
Summary stats表明item_description的最小長度為1,而最大長度為245,平均長度約為25個單詞,少數描述比較長,而大多數描述包含不到40個單詞,正如我們在箱線圖中看到的那樣,
5.5物品條件的單變數分析
離散特征item_condition_id 的范圍是1到5,該特征具有順序性,1的物品是“最好的”,條件5的物品是“最差的”,item_condition_id的條形圖如下所示:
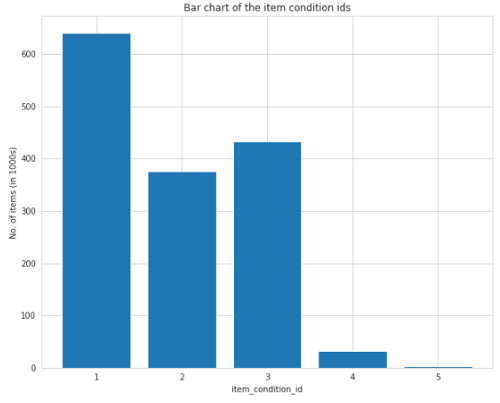
大多數待售商品狀況良好,如上圖所示,因此,條件1的物品較高,其次是條件3和2,而條件4和5的物品較低,
5.6雙變數分析
了解目標變數與其他特征的關聯型別將有助于特征工程,因此,將價格變數與其他兩個變數進行比較,
價格與運費
和往常一樣,圖表有助于我們更好地理解事物,代碼和繪圖如下所示:
#https://seaborn.pydata.org/generated/seaborn.boxplot.html
ax = sns.boxplot(x=train['shipping'],y=train['log_price'],palette="Set3",hue=train['shipping'])
handles, _ = ax.get_legend_handles_labels()
ax.legend(handles, ["seller pays", "Buyer pays"])
plt.title('Price distribution', fontsize=15)
plt.show()
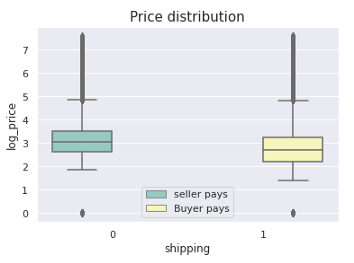
我們可以觀察到,當商品價格較高時,賣方支付運費,反之亦然,
價格與描述長度
我們上面所做的兩個變數的繪圖,
plt.scatter(train['description_wc'],train['price'],alpha=0.4)
plt.title("Price Vs Description length")
plt.xlabel("Description length")
plt.ylabel("Price(USD)")
plt.show()
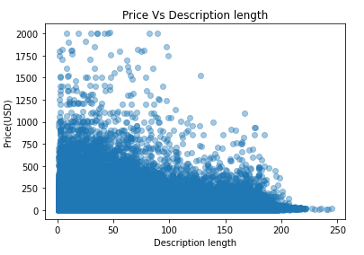
值得注意的是,描述長度較短的商品價格往往高于描述長度較長的商品,
6.現有方法
有一些博客和論文已經使用簡單的機器學習或深度學習方法提出了解決方案,我們將簡要介紹其中一些:
MLP
Pawel和Konstantin以他們驚人的解決方案贏得了這場比賽,他們使用了一種基于前饋神經網路的方法,即一種簡單的MLP,它可以有效地處理稀疏特征,
他們所執行的一些預處理技巧包括對分類列進行一次one-hot編碼、使用PorterStemmer進行詞干分析、BoW-1,2-grams(帶和不帶TF-IDF)、將不同欄位(如名稱、品牌名稱和物品描述)串聯到單個欄位中,他們的最終得分是0.37:https://www.kaggle.com/lopuhin/mercari-golf-0-3875-cv-in-75-loc-1900-s
CNN
在本研究中,作者使用了CNN架構,結合max-pooling,分別對名稱和物品描述進行向量化,他使用預訓練好的GloVE向量進行詞嵌入,嵌入是在名稱和物品描述中得到的,一些有用的技巧是在最后一個全連接層之前使用跳躍連接并且進行一些離散特征的連接,以及使用了詞嵌入的平均池層,作者通過一個單一的深度學習模型取得了0.41的驚人成績:https://www.kaggle.com/gspmoreira/cnn-glove-single-model-private-lb-0-41117-35th
LGBM + Ridge
在這里,作者應用了一個基于樹的梯度提升框架LightGBM,以實作更快的訓練和更高的效率,該研究還使用了一種簡單、快速的嶺回歸模型進行訓練,一些特色技術包括:使用CountVectorizer對name和category_name列進行向量化,TfidfVectorizer用于item_description,dummy 變數創建用于item_condition_id和shipping_id,以及LabelBinarizer用于品牌名,兩個模型合二為一后,作者得到了0.44分:https://www.kaggle.com/tunguz/more-effective-ridge-lgbm-script-lb-0-44823
GRU+2 Ridge
在這項研究中,作者使用RNN、Ridge和RidgeCV構建了一個關聯模型,其RMSLE約為0.427,這里應用的一些有用的技巧包括使用GRU層實作文本特征,為RNN訓練采用早停策略,在兩個epoch使用小批量大小,以及用于嶺回歸模型的超過300k個特征:https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755#RNN-Model
7.資料準備
清理資料
根據這一參考資料,Mercari網站上的最低價格為3美元,因此,在我們的訓練資料中,我們保留價格高于3美元的物品,下面顯示的是相同的代碼段:
#https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755
train = train.drop(train[(train.price < 3.0)].index)
處理空值/缺失值
從EDA中,我們知道3列,即category_name, brand_name, 和item_description包含空值,因此,我們用適當的值來代替它們,我們使用以下函式執行此操作:
def fill_nan(dataset):
'''
函式填充各列中的NaN值
'''
dataset["item_description"].fillna("No description yet",inplace=True)
dataset["brand_name"].fillna("missing",inplace=True)
dataset["category_name"].fillna("missing",inplace=True)
訓練測驗集拆分
在我們的分析中,價格是目標變數y,基于誤差函式來評估回歸模型的擬合度是很重要的,我們需要對y進行觀察和預測,訓練資料分為訓練集和測驗集,
對于基本線性回歸模型,測驗集包含10%的資料,對于深度學習模型,測驗集包含總資料的20%,
縮放目標變數
目標變數的標準化是使用sklearn的StandardScaler函式,預處理如下圖所示:
global y_scalar
y_scalar = StandardScaler()
y_train = y_scalar.fit_transform(log_price(X_train['price']).values.reshape(-1, 1))
y_test = y_scalar.transform(log_price(X_test['price']).values.reshape(-1, 1))
由于我們的目標變數是使用上述函式進行標準化的,所以在計算誤差度量之前,將預測進行逆變換是很重要的,這是通過使用以下函式來完成的:
def scale_back(x):
'''
函式對縮放值進行逆變換
'''
x= np.expm1(y_scalar.inverse_transform(x.reshape(-1,1))[:,0])
return x
8.模型說明
讓我們詳細介紹機器學習和深度學習管道,
8.1機器學習管道

在這一分析中,自然語言處理的概念,如BoW,TFIDF等被用來向量化文本的機器學習回歸模型,
構建特征
在執行EDA時,我們添加了四個新特征,即通過拆分列category生成三個新列,并從item_description中添加文本描述的字數,另外,我們根據名稱文本的長度再創建一個列,所以,我們有五個新特征,
我們的資料集包括離散特征、數字特征和文本特征,必須對離散特征進行編碼,并將文本特征向量化,以創建模型使用的特征矩陣,
離散特征編碼
我們使用sci工具包中的CountVectorizer函式對離散特征(如category_name, main_category,sub_cat_1,sub_cat_2,brand_name)進行one-hot編碼,并使用get_dummies()函式對shipping_id 和item_condition_id 進行編碼,其代碼如下:
def one_hot_encode(train,test):
'''
函式對離散列進行one-hot編碼
'''
vectorizer = CountVectorizer(token_pattern='.+')
vectorizer = vectorizer.fit(train['category_name'].values) # 只在訓練資料上擬合
column_cat = vectorizer.transform(test['category_name'].values)
#向量化main_category列
vectorizer = vectorizer.fit(train['main_category'].values) # 只在訓練資料上擬合
column_mc = vectorizer.transform(test['main_category'].values)
#向量化sub_cat_1列
vectorizer = vectorizer.fit(train['sub_cat_1'].values) # 只在訓練資料上擬合
column_sb1 = vectorizer.transform(test['sub_cat_1'].values)
#向量化sub_cat_2列
vectorizer = vectorizer.fit(train['sub_cat_2'].values) # 只在訓練資料上擬合
column_sb2 = vectorizer.transform(test['sub_cat_2'].values)
#向量化brand列
vectorizer = vectorizer.fit(train['brand_name'].astype(str)) # 只在訓練資料上擬合
brand_encodes = vectorizer.transform(test['brand_name'].astype(str))
print("created OHE columns for main_category,sub_cat_1,sub_cat_2\n")
print(column_cat.shape)
print(column_mc.shape)
print(column_sb1.shape)
print(column_sb2.shape)
print(brand_encodes.shape)
print("="*100)
return column_cat,column_mc,column_sb1,column_sb2,brand_encodes
def get_dummies_item_id_shipping(df):
df['item_condition_id'] = df["item_condition_id"].astype("category")
df['shipping'] = df["shipping"].astype("category")
item_id_shipping = csr_matrix(pd.get_dummies(df[['item_condition_id', 'shipping']],\
sparse=True).values)
return item_id_shipping
文本特征向量化
我們分別使用BoW(用uni-和bi-grams)和TFIDF(用uni-、bi-和tri-grams)對文本特征名稱和條目描述進行編碼,其函式如下:
def vectorizer(train,test,column,no_of_features,n_range,vector_type):
'''
函式使用TFIDF/BoW對文本進行向量化
'''
if str(vector_type) == 'bow':
vectorizer = CountVectorizer(ngram_range=n_range,max_features=no_of_features).fit(train[column]) #擬合
else:
vectorizer = TfidfVectorizer(ngram_range=n_range, max_features=no_of_features).fit(train[column]) # 只在訓練資料上擬合
# 我們使用vectorizer將文本轉換為矢量
transformed_text = vectorizer.transform(tqdm(test[column]))
###############################
print("After vectorizations")
print(transformed_text.shape)
print("="*100)
return transformed_text
使用上述函式的代碼如下:
X_train_bow_name = vectorizer(X_train,X_train,'name',100000,(1,2),'bow')
X_test_bow_name = vectorizer(X_train,X_test,'name',100000,(1,2),'bow')
X_train_tfidf_desc = vectorizer(X_train,X_train,'item_description',100000,(1,3),'tfidf')
X_test_tfidf_desc = vectorizer(X_train,X_test,'item_description',100000,(1,3),'tfidf')
特征矩陣
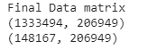
最后的矩陣是通過將所有編碼特征(包括離散特征和文本特征)以及兩個數字特征(即文本描述的字數和名稱)串聯起來生成的,參考代碼如下:
x_train_set = hstack((X_train_bow_name,X_train_tfidf_desc,tr_cat,X_train['wc_name'].values.reshape(-1,1),X_train['wc_desc'].values.reshape(-1,1))).tocsr()
x_test_set = hstack((X_test_bow_name,X_test_tfidf_desc,te_cat,X_test['wc_name'].values.reshape(-1,1),X_test['wc_desc'].values.reshape(-1,1))).tocsr()
最終生成的矩陣包含206k多個特征,事實上,這有很多特征,
首次選擇模型
為這個問題選擇一個合適的演算法可能是一項艱巨的任務,尤其是對初學者來說,

我們學習根據資料維度、線性度、訓練時間、問題型別等來選擇演算法,如這里所討論的,
在我們的分析中,我們首先實驗簡單的線性模型,如線性回歸,支持向量回歸,對于這兩個模型,我們選擇了來自scikit-learn的SGDRegressor ,接下來,我們訓練嶺回歸,
我們使用以下函式使用GridSearchCV超引數調整所有模型的引數:
def hyperparameter_tuning_random(x,y,model_estimator,param_dict,cv_no):
start = time.time()
hyper_tuned = GridSearchCV(estimator = model_estimator, param_grid = param_dict,\
return_train_score=True, scoring = 'neg_mean_squared_error',\
cv = cv_no, \
verbose=2, n_jobs = -1)
hyper_tuned.fit(x,y)
print("\n######################################################################\n")
print ('Time taken for hyperparameter tuning is {} sec\n'.format(time.time()-start))
print('The best parameters_: {}'.format(hyper_tuned.best_params_))
return hyper_tuned.best_params_
線性回歸
線性回歸的目的是減少預測與實際資料之間的誤差,我們使用帶有“squared_loss”和超引數調整的SGDregressor 訓練簡單線性回歸模型,下面顯示了代碼:
#超引數調優
parameters = {'alpha':[10**x for x in range(-10, 7)],
}
model_lr_reg = SGDRegressor(loss = "squared_loss",fit_intercept=False,l1_ratio=0.6)
best_parameters_lr = hyperparameter_tuning_random(x_train_set,y_train,model_lr_reg,parameters,3)
model_lr_best_param = SGDRegressor(loss = "squared_loss",alpha = best_parameters_lr['alpha'],\
fit_intercept=False)
model_lr_best_param.fit(x_train_set,y_train)
y_train_pred = model_lr_best_param.predict(x_train_set)
y_test_pred = model_lr_best_param.predict(x_test_set)
在我們的測驗資料中,這個簡單的模型得出了最佳α=0.001的RMSLE為0.513,
SVR:
支持向量回歸(SVR)是指用不超過ε的值來預測偏離實際資料的函式,我們使用SGDRegressor訓練一個SVR,“epsilon_unsensitive”作為損失,alphas作為超引數,根據我們的測驗資料,該模型產生了α=0.0001的RMSLE為0.632,在我們的例子中,簡單的線性回歸比支持向量機的性能要好得多,SVR代碼如下:
#超引數調優
parameters_svr = {'alpha':[10**x for x in range(-4, 4)]}
model_svr = SGDRegressor(loss = "epsilon_insensitive",fit_intercept=False)
best_parameters_svr = hyperparameter_tuning_random(x_train_set,y_train,model_svr,parameters_svr,3)
model_svr_best_param = SGDRegressor(loss = "epsilon_insensitive",alpha = 0.0001,\
fit_intercept=False)
model_svr_best_param.fit(x_train_set,y_train[:,0])
y_train_pred_svr = model_svr_best_param.predict(x_train_set)
y_test_pred_svr = model_svr_best_param.predict(x_test_set)
嶺回歸
嶺回歸是線性回歸的近親,通過L2范數給出一些正則化來防止過度擬合,我們在線性模型下使用scikit-learn的Ridge得到了很好的擬合,α=6.0的RMSLE為0.490,下面是具有超引數調整的Ridge模型代碼:
#超引數調優
parameters_ridge = {'alpha':[0.0001,0.001,0.01,0.1,1.0,2.0,4.0,5.0,6.0]}
model_ridge = Ridge(
solver='auto', fit_intercept=True,
max_iter=100, normalize=False, tol=0.05, random_state = 1,
)
rs_ridge = hyperparameter_tuning_random(x_train_set,y_train,model_ridge,parameters_ridge,3)
ridge_model = Ridge(
solver='auto', fit_intercept=True,
max_iter=100, normalize=False, tol=0.05, alpha=6.0,random_state = 1,
)
ridge_model.fit(x_train_set, y_train)
RidgeCV
它是一個交叉驗證估計器,可以自動選擇最佳超引數,換言之,具有內置交叉驗證的嶺回歸,對于我們的問題,這比Ridge表現得更好,我們構建了RidgeCV模型,根據我們的測驗資料,alpha6.0的RMSLE為0.442,代碼如下:
from sklearn.linear_model import RidgeCV
print("Fitting Ridge model on training examples...")
ridge_modelCV = RidgeCV(
fit_intercept=True, alphas=[6.0],
normalize=False, cv = 2, scoring='neg_mean_squared_error',
)
ridge_modelCV.fit(x_train_set1, y_train)
preds_ridgeCV = ridge_modelCV.predict(x_test_set1)
我們可以觀察到RidgeCV表現得最好,為了進一步提高分數,我們正在探索使用深度學習來解決這個問題
8.2深度學習
遞回神經網路(RNN)擅長處理序列資料資訊,我們使用門控遞回單元(GRU),它是一種新型的RNN,訓練速度更快,
從GRU中,我們在name, item_description列獲取文本特征向量,對于其他類別欄位,我們使用嵌入后再展平向量,所有這些共同構成了我們的深度學習模型的80維特征向量,

嵌入
除了訓練測驗的劃分,深度學習(DL)管道的資料準備遵循與ML管道相同的例程,如前所述,DL管道需要密集向量,而神經網路嵌入是將離散變數表示為密集向量的有效方法
標識化和填充
嵌入層要求輸入是整數編碼的,因此,我們使用Tokenizer API對文本資料進行編碼,下面是代碼片段:
def tokenize_text(train,test,column):
#參考AAIC課程
global t
t = Tokenizer()
t.fit_on_texts(train[column].str.lower())
vocab_size = len(t.word_index) + 1
#對檔案進行整數編碼
encoded_text_tr = t.texts_to_sequences(train[column].str.lower())
encoded_text_te = t.texts_to_sequences(test[column].str.lower())
return encoded_text_tr,encoded_text_te,vocab_size
標識化后的樣本描述資料截圖如下:

在標識化之后,我們填充序列,名稱和描述文本的長度不同,Keras希望輸入序列的長度相同,我們計算超出特定范圍的資料點的百分比,以確定填充的長度,
下面顯示了選擇描述文本填充長度的代碼:
print("% of sequence containing len > 160 is")
len(X_train[X_train.wc_desc > 160])/X_train.shape[0]*100

從上面的影像我們可以看到長度在160以上的點的百分比為0.7,即<1%,因此我們用160填充描述文本,類似地,我們計算name列,得到10,對應的代碼片段如下所示:
print("% of name containing len > 10 is")
len(X_train[X_train.wc_name > 10])/X_train.shape[0]*100

此外,我們對離散變數進行編碼,代碼片段如下:
def rank_category(dataset,column_name):
'''這個函式接受列名,并回傳具有排名后類別'''
counter = dataset[column_name].value_counts().index.values
total = list(dataset[column_name])
ranked_cat = {}
for i in range(1,len(counter)+1):
ranked_cat.update({counter[i-1] : i})
return ranked_cat,len(counter)
def encode_ranked_category(train,test,column):
'''
這個函式呼叫rank_category函式并回傳已編碼的列 '''
train[column] = train[column].astype('category')
test[column] = test[column].astype('category')
cat_list = list(train[column].unique())
ranked_cat_tr,count = rank_category(train,column)
encoded_col_tr = []
encoded_col_te = []
for category in train[column]:
encoded_col_tr.append(ranked_cat_tr[category])
for category in test[column]:
if category in cat_list:
encoded_col_te.append(ranked_cat_tr[category])
else:
encoded_col_te.append(0)
encoded_col_tr = np.asarray(encoded_col_tr)
encoded_col_te = np.asarray(encoded_col_te)
return encoded_col_tr,encoded_col_te,count
注意:所有的嵌入都是和模型本身一起學習的,
整個資料準備管道以及編碼、標識化和填充都由以下函式執行:
def data_gru(train,test):
global max_length,desc_size,name_size
encoded_brand_tr,encoded_brand_te,brand_len = encode_ranked_category(train,test,'brand_name')
encoded_main_cat_tr,encoded_main_cat_te,main_cat_len = encode_ranked_category(train,test,'main_category')
encoded_sub_cat_1_tr,encoded_sub_cat_1_te,sub_cat1_len = encode_ranked_category(train,test,'sub_cat_1')
encoded_sub_cat_2_tr,encoded_sub_cat_2_te,sub_cat2_len = encode_ranked_category(train,test,'sub_cat_2')
tokenized_desc_tr,tokenized_desc_te,desc_size = tokenize_text(train,test,'item_description')
tokenized_name_tr,tokenized_name_te,name_size = tokenize_text(train,test,'name')
max_length = 160
desc_tr_padded = pad_sequences(tokenized_desc_tr, maxlen=max_length, padding='post')
desc_te_padded = pad_sequences(tokenized_desc_te, maxlen=max_length, padding='post')
del tokenized_desc_tr,tokenized_desc_te
name_tr_padded = pad_sequences(tokenized_name_tr, maxlen=10, padding='post')
name_te_padded = pad_sequences(tokenized_name_te, maxlen=10, padding='post')
del tokenized_name_tr,tokenized_name_te
gc.collect()
train_inputs = [name_tr_padded,desc_tr_padded,encoded_brand_tr.reshape(-1,1),\
encoded_main_cat_tr.reshape(-1,1),encoded_sub_cat_1_tr.reshape(-1,1),\
encoded_sub_cat_2_tr.reshape(-1,1),train['shipping'],\
train['item_condition_id'],train['wc_desc'],\
train['wc_name']]
test_inputs = [name_te_padded,desc_te_padded,encoded_brand_te.reshape(-1,1),\
encoded_main_cat_te.reshape(-1,1),encoded_sub_cat_1_te.reshape(-1,1),\
encoded_sub_cat_2_te.reshape(-1,1),test['shipping'],\
test['item_condition_id'],test['wc_desc'],\
test['wc_name']]
item_condition_counter = train['item_condition_id'].value_counts().index.values
list_var = [brand_len,main_cat_len,sub_cat1_len,sub_cat2_len,len(item_condition_counter)]
return train_inputs,test_inputs,list_var
網路體系結構
對當前網路設計的分析正是受到了這個的啟發(https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755#RNN-Model),此外,我們在這個框架中對Dropout層和batch-normalization層進行了實驗,以下是構建我們網路的代碼片段:
def construct_GRU(train,var_list,drop_out_list):
#name的GRU輸入層
input_name = tf.keras.layers.Input(shape=(10,), name='name')
embedding_name = tf.keras.layers.Embedding(name_size, 20)(input_name)
gru_name = tf.keras.layers.GRU(8)(embedding_name)
#description的GRU輸入層
input_desc = tf.keras.layers.Input(shape=(max_length,), name='desc')
embedding_desc = tf.keras.layers.Embedding(desc_size, 60)(input_desc)
gru_desc = tf.keras.layers.GRU(16)(embedding_desc)
#input layer for brand_name的輸入層
input_brand = tf.keras.layers.Input(shape=(1,), name='brand')
embedding_brand = tf.keras.layers.Embedding(var_list[0] + 1, 10)(input_brand)
flatten1 = tf.keras.layers.Flatten()(embedding_brand)
#main_category的輸入層
input_cat = tf.keras.layers.Input(shape=(1,), name='main_cat')
Embed_cat = tf.keras.layers.Embedding(var_list[1] + 1, \
10,input_length=1)(input_cat)
flatten2 = tf.keras.layers.Flatten()(Embed_cat)
#sub_cat_1的輸入層
input_subcat1 = tf.keras.layers.Input(shape=(1,), name='subcat1')
Embed_subcat1 = tf.keras.layers.Embedding(var_list[2] + 1, \
10,input_length=1)(input_subcat1)
flatten3 = tf.keras.layers.Flatten()(Embed_subcat1)
#sub_cat_2的輸入層
input_subcat2 = tf.keras.layers.Input(shape=(1,), name='subcat2')
Embed_subcat2 = tf.keras.layers.Embedding(var_list[3] + 1, \
10,input_length=1)(input_subcat2)
flatten4 = tf.keras.layers.Flatten()(Embed_subcat2)
#shipping的輸入層
input_shipping = tf.keras.layers.Input(shape=(1,), name='shipping')
#item_condition_id的輸入層
input_item = tf.keras.layers.Input(shape=(1,), name='item_condition_id')
Embed_item = tf.keras.layers.Embedding(var_list[4] + 1, \
5,input_length=1)(input_item)
flatten5 = tf.keras.layers.Flatten()(Embed_item)
#數字特征的輸入層
desc_len_input = tf.keras.layers.Input(shape=(1,), name='description_length')
desc_len_embd = tf.keras.layers.Embedding(DESC_LEN,5)(desc_len_input)
flatten6 = tf.keras.layers.Flatten()(desc_len_embd)
#name_len的輸入層
name_len_input = tf.keras.layers.Input(shape=(1,), name='name_length')
name_len_embd = tf.keras.layers.Embedding(NAME_LEN,5)(name_len_input)
flatten7 = tf.keras.layers.Flatten()(name_len_embd)
# 級聯
concat_layer = tf.keras.layers.concatenate(inputs=[gru_name,gru_desc,flatten1,flatten2,flatten3,flatten4,input_shipping,flatten5,\
flatten6,flatten7],name="concatenate")
#全連接層
Dense_layer1 = tf.keras.layers.Dense(units=512,activation='relu',kernel_initializer='he_normal',\
name="Dense_l")(concat_layer)
dropout_1 = tf.keras.layers.Dropout(drop_out_list[0],name='dropout_1')(Dense_layer1)
batch_n1 = tf.keras.layers.BatchNormalization()(dropout_1)
Dense_layer2 = tf.keras.layers.Dense(units=128,activation='relu',kernel_initializer='he_normal',\
name="Dense_2")(batch_n1)
dropout_2 = tf.keras.layers.Dropout(drop_out_list[1],name='dropout_2')(Dense_layer2)
batch_n2 = tf.keras.layers.BatchNormalization()(dropout_2)
Dense_layer3 = tf.keras.layers.Dense(units=128,activation='relu',kernel_initializer='he_normal',\
name="Dense_3")(batch_n2)
dropout_3 = tf.keras.layers.Dropout(drop_out_list[2],name='dropout_3')(Dense_layer3)
Dense_layer4 = tf.keras.layers.Dense(units=64,activation='relu',kernel_initializer='he_normal',\
name="Dense_4")(dropout_3)
dropout_4 = tf.keras.layers.Dropout(drop_out_list[3],name='dropout_4')(Dense_layer4)
#輸出層
final_output = tf.keras.layers.Dense(units=1,activation='linear',name='output_layer')(dropout_4)
model = tf.keras.Model(inputs=[input_name,input_desc,input_brand,input_cat,input_subcat1,input_subcat2,\
input_shipping,input_item,desc_len_input,name_len_input],
outputs=[final_output])
#我們指定了模型的輸入和輸出
print(model.summary())
img_path = "GRU_model_2_lr.png"
plot_model(model, to_file=img_path, show_shapes=True, show_layer_names=True)
return model
下面是我們的網路:
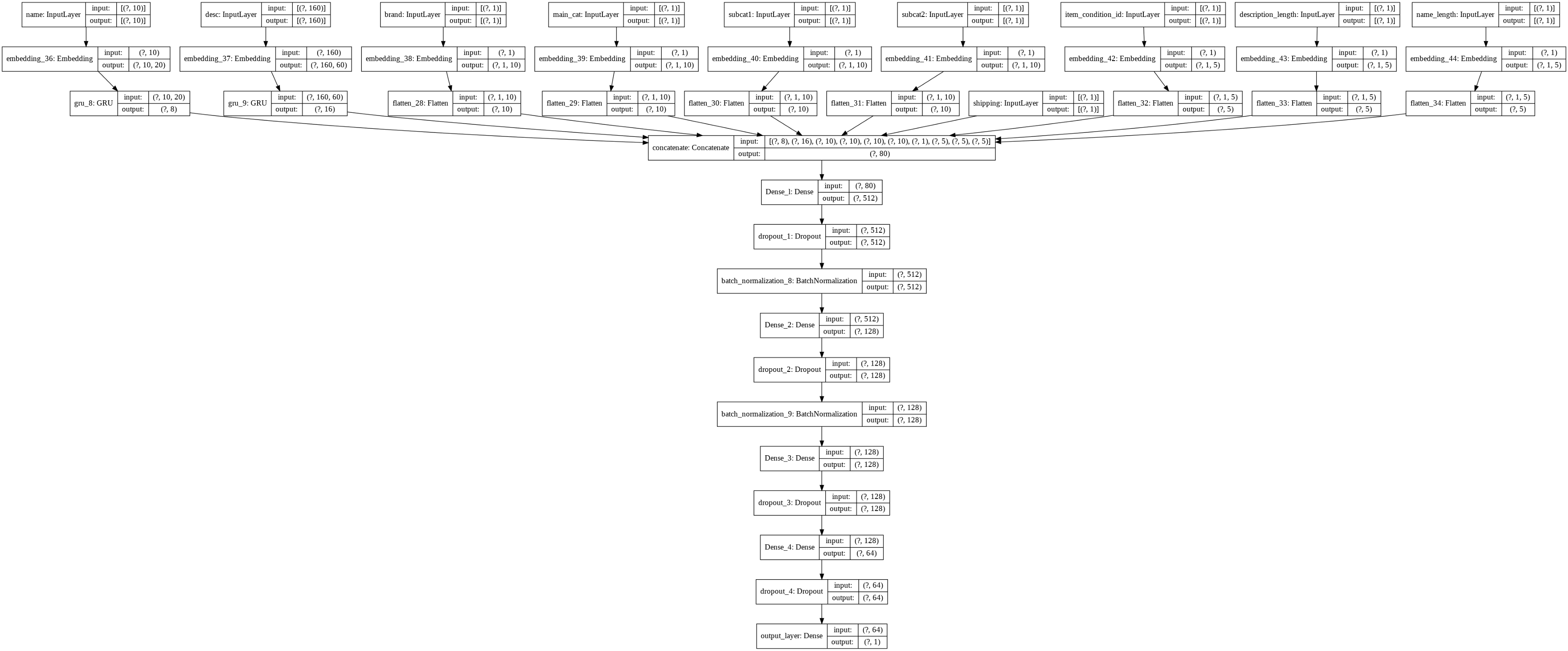
深度學習模型
共訓練了四個不同Dropout和學習率的模型,每個網路由四個Dropout層組成,對于每一層,我們嘗試對所有模型使用不同的Dropout率(有關詳細資訊,請參閱結果),
訓練
對于訓練模型1和模型2,我們使用具有默認學習率的Adam優化器,此外,這些模型被訓練為3個epoch,batch量大小加倍,模型1和模型2的試驗資料的RMSLE分別為0.436和0.441,模型訓練說明如下:

模型3和4使用Adam優化器和預定學習率進行訓練,batch大小為1024個,對于epoch 1和2,學習率為0.005,對于最后一個epoch,我們將其降低到0.001,模型4的訓練如下:
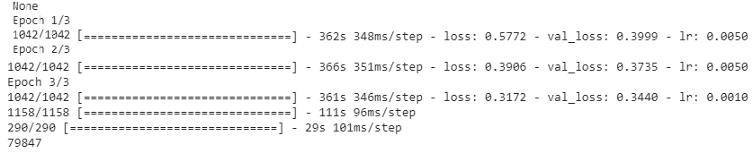
模型平均集成
模型平均是一種降低神經網路高方差的集成學習技術,在當前的分析中,我們對在不同條件下訓練的模型進行集成,這些模型的正則化程度不同,每一款模型的訓練時間約為30至35分鐘,考慮到訓練時間,我們只包含了兩個模型,因此,在四個模型中,創建了兩個模型組,即一個來自模型1和模型2,實作后RMSLE 0.433,另一個來自模型3和4,RMSLE為0.429
集成模型1和2的代碼如下所示:
#https://machinelearningmastery.com/model-averaging-ensemble-for-deep-learning-neural-networks/
y_hats = np.array([preds_m1_te,te_preds_m2]) #making an array out of all the predictions
# 平均集成
mean_preds = np.mean(y_hats, axis=0)
print("RMSLE on test: {}".format(rmsle_compute(X_test['price'],scale_back(mean_preds))))
我們觀察到模型3和4的集成表現最好,
最終模型
為了獲得Kaggle的最終分數,我們現在在Kaggle中進行訓練,我們建立了兩個模型相同的模型模型3和4進行裝配,下面展示的是在Kaggle訓練過的模型的截圖:
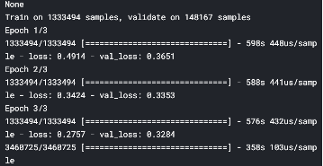
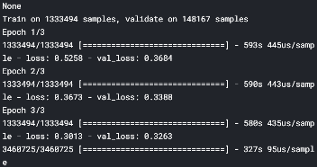
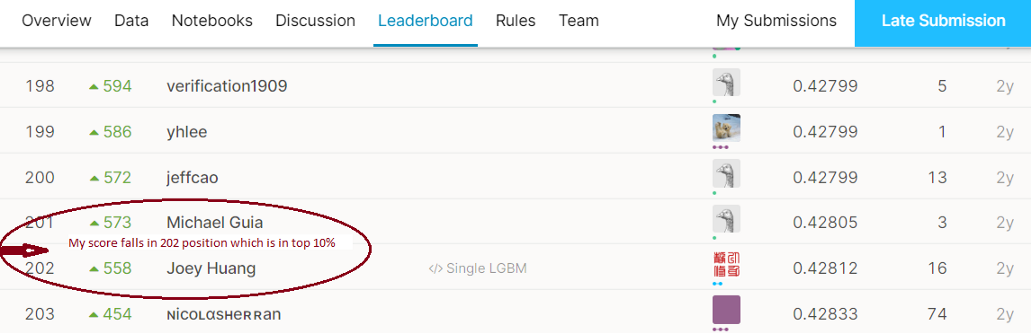
對這兩個模型的平均模型在我們的最終測驗資料(包含約340萬個產品)中產生0.428的Kaggle分數,因此,我們的得分排名前10%,
9.結果
以下是模型輸出的摘要截圖:
機器學習管道的輸出:

深度學習管道的輸出:

集成模型的輸出
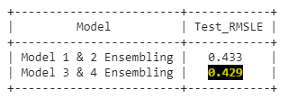
Kaggle提交分數:

10.改善RMSLE的嘗試
提高我們得分的策略如下:
-
不去除停用詞:這個問題的一個關鍵是洗掉停用詞會影響RMSLE分數,保留停用詞可以提高分數,
-
考慮到更多的文本特征用于模型構建:我們總共得到206k個特征,其中包括僅從文本資料中提取的200k個特征,在這個問題中,更加重視文本資訊可以提高分數,
-
bigram和Tri-gram:在NLP中,如果我們打算在向量化程序中添加一些語意,通常會包含n-gram,如bigram、Tri-gram等,
-
根據價格過濾資料:Mercari不允許發布低于3美元的商品,因此,那些產品價格低于3美元的是錯誤的,洗掉它們將有助于模型的性能更好,
-
小批量和少epoch的模型訓練:使用1024的batch和更好的學習率調度程式提高了分數
-
整合兩個神經網路模型:這一策略是目前研究所獨有的,它將領先者的得分推得更高,我們通過訓練兩個神經網路模型并建立它們的集成來進行預測分析,
11.未來作業
可以通過探索以下選項來提高分數:
-
使用多層感知器是解決這一問題的常用方法
-
利用CNN與RNN結合處理文本資料
-
添加更多GRU層或進一步微調
這些是我們隨后將要探討的一些可能性,
12.GitHub存盤庫
請參考我的GitHub存盤庫查看完整代碼:https://github.com/syogeeshwari/Mercari_price_prediction
13.參考參考
-
https://github.com/pjankiewicz/mercarisolution/blob/master/presentation/build/yandex.pdf
-
https://www.kaggle.com/valkling/mercari-rnn-2ridge-models-with-notes-0-42755
-
https://medium.com/analytics-vidhya/mercari-price-suggestion-challenge-66500ac1f88a
-
https://medium.com/analytics-vidhya/mercari-price-suggestion-challenge-a-machine-learning-regression-case-study-9d776d5293a0
-
https://machinelearningmastery.com/ensemble-methods-for-deep-learning-neural-networks/
-
https://machinelearningmastery.com/model-averaging-ensemble-for-deep-learning-neural-networks/
-
https://medium.com/unstructured/how-i-lost-a-silver-medal-in-kaggles-mercari-price-suggestion-challenge-using-cnns-and-tensorflow-4013660fcded
-
https://www.appliedaicourse.com/course/11/Applied-Machine-learning-course
原文鏈接:https://towardsdatascience.com/pricing-objects-in-mercari-machine-learning-deep-learning-perspectives-6aa80514b2c8
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/50542.html
標籤:其他
上一篇:一個4-5年行業游戲經驗的去面試,如果你是主程或技術總監,你會大致問哪些問題呢?
下一篇:InputField鍵盤問題