1 專案簡介
【參考】鳶尾花分類
【背景】
假設有一名植物學愛好者對她發現的鳶尾花的品種很感興趣,她收集了每朵鳶尾花的一些測量資料:花瓣的長度和寬度以及花萼的長度和寬度,所有測量結果的單位都是厘米,她還有一些鳶尾花的測量資料,這些花之前已經被植物學專家鑒定為屬于setosa、versicolor或virginica三個品種之一,對于這些測量資料,她可以確定每朵鳶尾花所屬的品種,
【目標】構建一個機器學習模型,可以從上述已知品種的鳶尾花測量資料,從而預測新鳶尾花的品種
【分析】監督學習問題;分類問題;
【拓展】
- 類別:可能輸出(鳶尾花的不同品種)
- 標簽:單個資料點的預期輸出
- 樣本:機器學習中的個體
- 特征:樣本屬性
【補充】from...import...可能造成命名污染,不推薦過多使用
1.1 初識資料
【關鍵詞】Bunch物件;load_iris;
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print('Keys of iris dataset: \n{}'.format(iris_dataset.keys()))
Keys of iris dataset:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
【DESCR】其對應的值是資料集的簡要說明
print(iris_dataset['DESCR']+'\n')
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%[email protected])
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
【target_names】其對應的值是一個字串陣列,包含我們要預測的話的品種
print('Target names: {}'.format(iris_dataset['target_names']))
Target names: ['setosa' 'versicolor' 'virginica']
【feature_names】其對應的值是一個字串列,對資料的每個特征進行了說明
print('Feature names: \n{}'.format(iris_dataset['feature_names']))
Feature names:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
【data】其里面是花萼長度、花萼寬度、花瓣長度、花瓣寬度,格式為Numpy陣列
- data陣列的每一行對應一朵花,列代表每朵花的四個測驗資料
- data陣列的形狀是樣本數與特征數的乘積
print('Type of data: {}'.format(type(iris_dataset['data'])))
Type of data: <class 'numpy.ndarray'>
print('Shape of data: {}'.format(iris_dataset['data'].shape))
Shape of data: (150, 4)
print('First five rows of data:\n{}'.format(iris_dataset['data'][:5]))
First five rows of data:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
【target】一維陣列,每朵花對應其中一個資料,品種被轉換成0到2的整數
- 0 setosa
- 1 versicolor
- 2 virginica
print('Target:\n{}'.format(iris_dataset['target']))
Target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
1.2 訓練資料與測驗資料
【train_test_split】利用偽亂數生成器將資料集打亂,確保測驗集有所有類別的資料
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
for Xy in list(zip(X_train, y_train))[:10]:
print(Xy)
(array([5.9, 3. , 4.2, 1.5]), 1)
(array([5.8, 2.6, 4. , 1.2]), 1)
(array([6.8, 3. , 5.5, 2.1]), 2)
(array([4.7, 3.2, 1.3, 0.2]), 0)
(array([6.9, 3.1, 5.1, 2.3]), 2)
(array([5. , 3.5, 1.6, 0.6]), 0)
(array([5.4, 3.7, 1.5, 0.2]), 0)
(array([5. , 2. , 3.5, 1. ]), 1)
(array([6.5, 3. , 5.5, 1.8]), 2)
(array([6.7, 3.3, 5.7, 2.5]), 2)
【shape】查看訓練集與測驗集的大小
print('X_train shape: {}'.format(X_train.shape))
print('y_train shape: {}'.format(y_train.shape))
print()
print('X_test shape: {}'.format(X_test.shape))
print('y_test shape: {}'.format(y_test.shape))
X_train shape: (112, 4)
y_train shape: (112,)
X_test shape: (38, 4)
y_test shape: (38,)
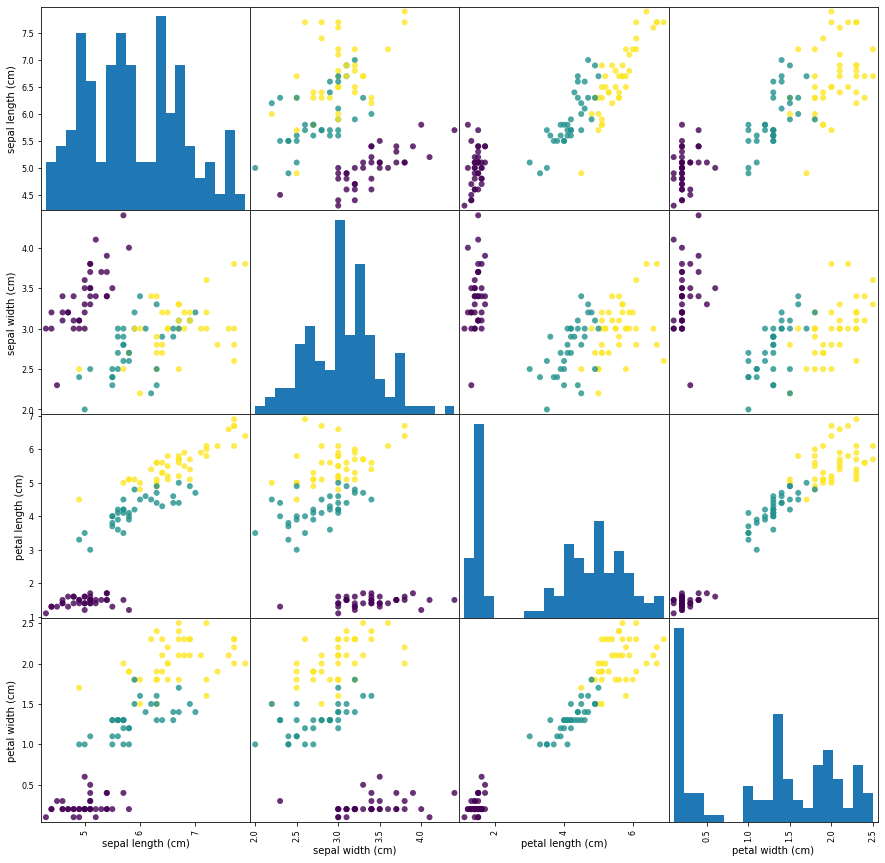
1.3 觀察資料
【目的】找出例外值和特殊值(也許是資料單位不統一)
【方法】可視化(如繪制散點圖、散點圖矩陣)
import pandas as pd
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
grr = pd.plotting.scatter_matrix(
iris_dataframe, c=y_train, figsize=(15,15), marker='o',
hist_kwds={'bins':20}, alpha=0.8)
2 構建模型:KNN演算法
【概述】
- k-近鄰演算法采用測量不同特征值之間距離的方法進行分類
- k的含義:尋找訓練集中與新資料最近的k個資料點
【補充】scikit-learn中所有機器學習模型都在各自類中實作
2.1 使用KNeighborsClassfier類的fit方法
import sklearn.neighbors as skln
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_dataset = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
knn = skln.KNeighborsClassifier(n_neighbors=1)
print(knn.fit(X_train, y_train))
KNeighborsClassifier(n_neighbors=1)
2.2 預測新資料
【事件】我們在野外發現了一朵鳶尾花,花萼長5cm 寬2.9,花瓣長1cm 寬0.2cm,這朵鳶尾花是哪種品種捏?
【警告】這朵花的測驗資料轉化為二維numpy陣列的第一行,請記住scikit-learn的輸入資料必須是二維陣列
import numpy as np
X_new = np.array([[5,2.9, 1,0.2]]) # 這是個二維numpy陣列
print('X_new.shape: {}'.format(X_new.shape))
X_new.shape: (1, 4)
【初試】模型說這朵鳶尾花的標簽為0,叫做setosa,它說是就是?驗證模型的可信度也是十分重要的
from sklearn.datasets import load_iris
iris_dataset = load_iris()
prediction = knn.predict(X_new)
print('Prediction: {}'.format(prediction))
print('Predicted target_name: {}'.format(iris_dataset['target_names'][prediction]))
Prediction: [0]
Predicted target_name: ['setosa']
2.3 評估模型
【任務】我們可以計算品種預測正確的花所占的比例衡量模型的準確度
【提示】測驗集:開始作業
y_pred = knn.predict(X_test)
print('Test_set predictions:\n{}'.format(y_pred))
print('Test_set score: {:.2f}'.format(np.mean(y_pred==y_test)))
Test_set predictions:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]
Test_set score: 0.97
【補充】KNeighborsClassifier類的score方法計算測驗集的精度
print('Test_set score: {:.2f}'.format(knn.score(X_test, y_test)))
Test_set score: 0.97
【冷靜分析】0.97意味著這個模型中有97%的資料是正確的,也就是說,對于之前輸入的新資料,我有97%的把握認為模式猜得對
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/506142.html
標籤:其他