摘要:回圈神經網路(RNN)可是在語音識別、自然語言處理等其他領域中引起了變革!
本文分享自華為云社區《【MindSpore易點通】深度學習系列-回圈神經網路上篇》,作者:Skytier
回圈神經網路(RNN)可是在語音識別、自然語言處理等其他領域中引起了變革!
1 應用場景
回圈神經網路(RNN)其實就是序列模型,我們先來看看其應用場景,

在語音識別時,給定了一個輸入音頻片段X ,并要求輸出對應的文字記錄Y ,這里的輸入和輸出資料都是序列模型,輸入X是一個按時播放的音頻片段,輸出Y是一系列文字,
音樂生成問題也是一樣,輸出資料Y是序列,而輸入資料X可以是空集,也可以是個單一的整數(代表音符),
而系列模型在DNA序列分析中也十分有用,DNA可以用A、C、G、T四個字母來表示,所以給定一段DNA序列,你能夠標記出哪部分是匹配某種蛋白質的嗎?
以上所有類似問題都可以被稱作使用標簽資料(X,Y)作為訓練集的監督學習,輸入資料X或者輸出資料Y是序列,即使兩者都是序列也有資料長度不同的問題,
2 模型構建
比如建立一個序列模型,它的輸入陳述句是這樣的:“Sam Li and Tom date on Tuesday.”,然后模型是可以自動識別句中人名位置的命名物體識別模型,可以用來查找不同型別的文本中的人名、公司名、時間、地點、國家名和貨幣名等等,
假定輸入資料x,序列模型的輸出y,使得輸入的每個單詞都對應一個輸出值,同時y還需要表明輸入的單詞是否是人名的一部分,
首先輸入陳述句是7個單詞組成的時序序列,所以最侄訓有7個特征集x:x<1>,x<2>,...,x<7>,同時可以索引其序列中的位置,Tx表示輸出序列的長度,這里Tx=7,
同理,輸出資料也是一樣,分別對應y<1>,y<2>,...,y<7>,Ty表示輸出序列的長度,

那么問題來了,首先我們需要準備一個比較大的詞典庫,可能該庫里的第一個單詞是a,and出現在第367個位置上,Sam是在7459這個位置,Tom則在8674,
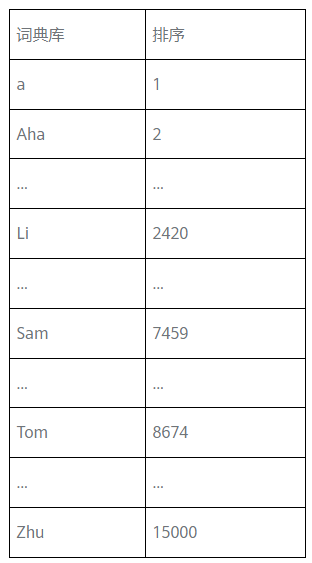
那么我們就可以在這個詞典庫的基礎上遍歷訓練集,
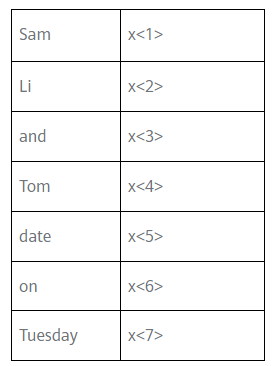
那么也就是說,Sam由x<1>表示,其是一個第7459行是1,其余值都是0的向量;Li由x<2>表示,其是一個第2420行是1,其余值都是0的向量,
通常我們稱這種x指代句子里的任意詞為one-hot向量,只有一個值是1,其余值都是0,所以整句話中我們會有7個one-hot向量,用序列模型在X和Y目標輸出之間學習建立一個映射關系,
PS:如果遇到了一個在你詞表中的單詞,可以創建一個Unknow Word的偽造單詞,用<UNK>作為標記,
3 模型解釋
通常情況下,我們會首先選取標準的神經網路,輸入7個one-hot向量,經過一些隱藏層,最侄訓輸出7個值為0或1的項,表明每個輸入單詞是否是人名的一部分,
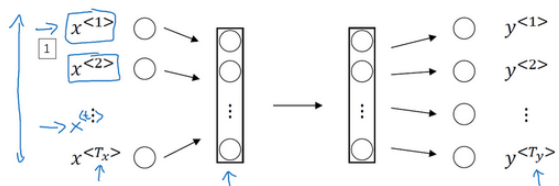
但最后我們總會遇到這樣的問題:
1.輸入和輸出資料的長度并不完全一致,即使采用填充(pad)或零填充(zero pad)使每個輸入陳述句都達到最大長度,但最后的運算式會很奇怪,
2.簡單的神經網路并不會共享從文本的不同位置上學到的特征,因為我們希望,如果首次學習的時候我們已經知道了Tom是人名,那么當Tom出現在其他位置時,其并不能夠自動識別,因此也不能夠減少模型中引數的數量,
那么回圈神經網路為啥會比普通的神經網路更加出眾呢?
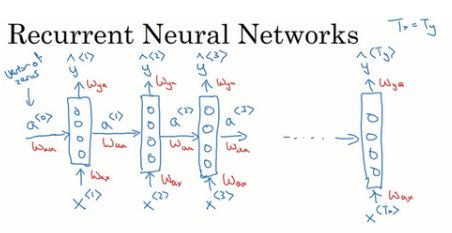

另外回圈神經網路是從左向右掃描資料,同時每個時間步的引數也是共享的,用Wax來表示從x<1>到隱藏層的連接的一系列引數,每個時間步使用的都是相同的Wax引數,而激活值是由引數Waa決定的,輸出結果由Way決定,
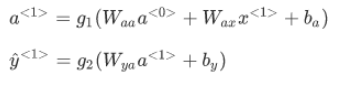
先輸入零向量a<0>,接著進行前向傳播程序,計算激活值a<1>,然后再計算y<1>,
更普遍來說,在t時刻:
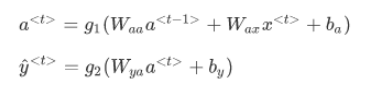
為了更加簡化一點,定義Wa:
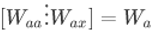
,假設a是100維的,x是10,000維的,那么Waa是(100,100)維的矩陣,Wax是(100,10000)維,Wa為(100,10100),
同樣,假定
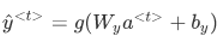
,Wy表明它是計算y型別的量的權重矩陣,而Wa和ba則表示這些引數是用來計算激活值的,
RNN前向傳播示意圖:

點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509182.html
標籤:其他
上一篇:帶你體驗給黑白照片上色
下一篇:《Spatial-Spectral T ransformer for Hyperspectral Image Classification》論文筆記