論文題目《Spatial-Spectral T ransformer for Hyperspectral Image Classification》
論文作者:Xin He 1 , Yushi Chen 1,* and Zhouhan Lin 2
論文發表年份:2021
模型簡稱:SST
發表期刊:Remote Sensing
Motivation
基于cnn的方法具有空間特征提取的優點,但它們難以處理帶有序列的資料,且不善于建模遠程依賴關系,而HSI的光譜是一種序列資料,通常包含數百個波段,因此,cnn很難很好地處理HSI,另一方面,基于注意機制的Transformer模型已經證明了它在處理順序資料方面的優勢,為了解決在長距離捕獲HSI中序列光譜關系的問題,本研究采用Transformer對HSI進行分類,具體而言,本研究提出了一種新的HSI分類框架——空間-光譜轉換器(SST),
Contribution
(1)提出了一種改進的DenseTransformer,它利用密集連接來解決Transformer中的梯度消失問題,
(2)將CNN、DenseTransformer和多層感知器(MLP)相結合,提出了一種新的HSI分類框架,即spatial-spectral Transformer (SST),在該SST中,利用精心設計的CNN提取HSI的空間特征,利用DenseTransformer捕獲HSI的序列光譜關系,利用MLP完成分類任務,
(3)進一步提出了動態特征增強(feature augmentation)方法,以緩解過擬合問題,從而更好地推廣模型,并將其加入到SST中,形成一種新的HSI分類方法(即SST- FA),
(4)提出了一種新的分類框架,即transferring spatial-spectral Transformer(T-SST),以進一步提高HSI分類的性能,提出的T-SST使用預先訓練的大型資料集上的類VGG模型作為SST中使用的CNN的初始化,因此,在有限訓練樣本的情況下,提高了HSI分類精度,
(5)最后,為了緩解過擬合問題,提高分類精度,將標簽平滑引入到基于Transformer的分類中,將標簽平滑與T-SST相結合,形成了一種新的HSI分類方法T-SST-L,
Method
(1)Spatial-Spectral Transformer(SST)
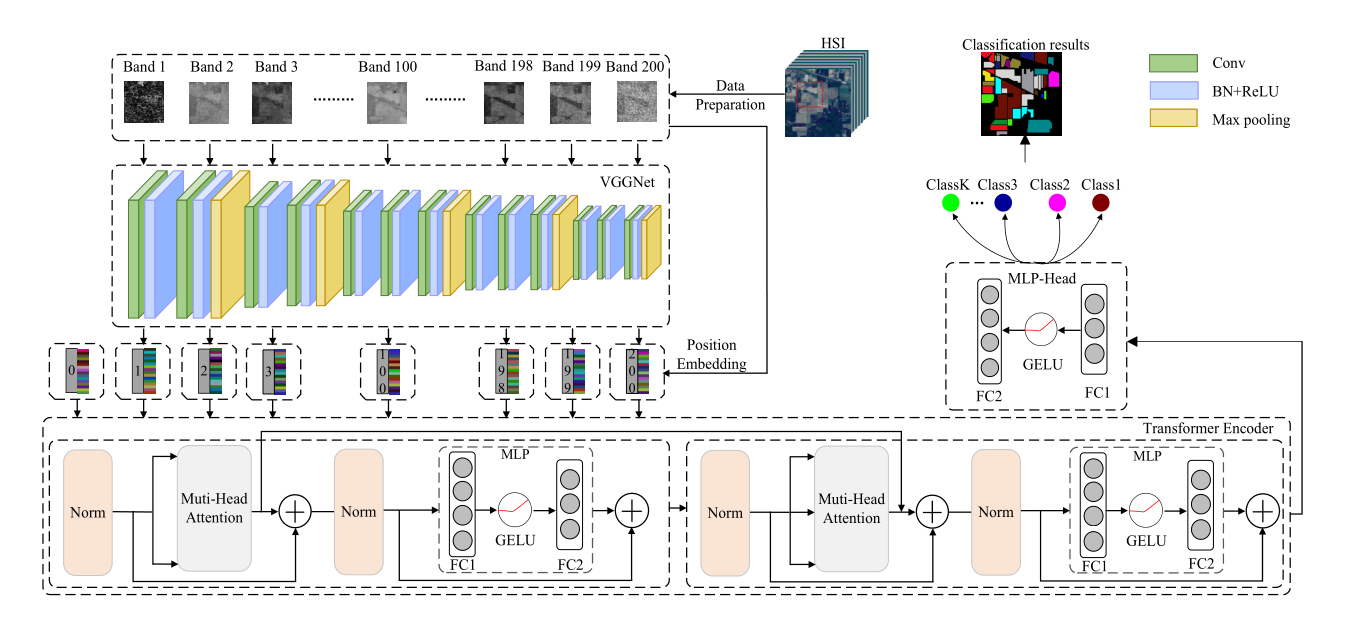
①VGG部分:本文使用改進的VGGNet(2D-CNN)分別提取每個波段的特征(主要提取空間特征),并將提取的特征輸入到Transformer中去學習長程依賴,在進入Transformer之前首先要對最后一層CNN提取的特征做位置編碼,以捕獲不同波段的位置資訊,
②Transformer部分:Transformer編碼器共包含d個編碼器塊,每個編碼器塊由一個多頭注意和一個MLP層組成,并加上層歸一化和殘差連接,Transformer編碼器的目的是通過根據全域背景關系資訊對每個波段進行編碼來捕獲所有n個HSI波段之間的相互作用,注意力的輸出定義如下:
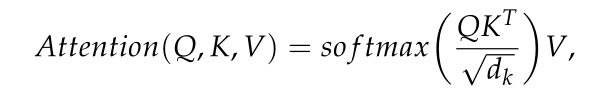 Note: d_k:防止未來求softmax梯度消失,
Note: d_k:防止未來求softmax梯度消失,
下圖是為緩解梯度消失問題和增進特征傳播改進的Transformer示意圖(DenseTransformer)
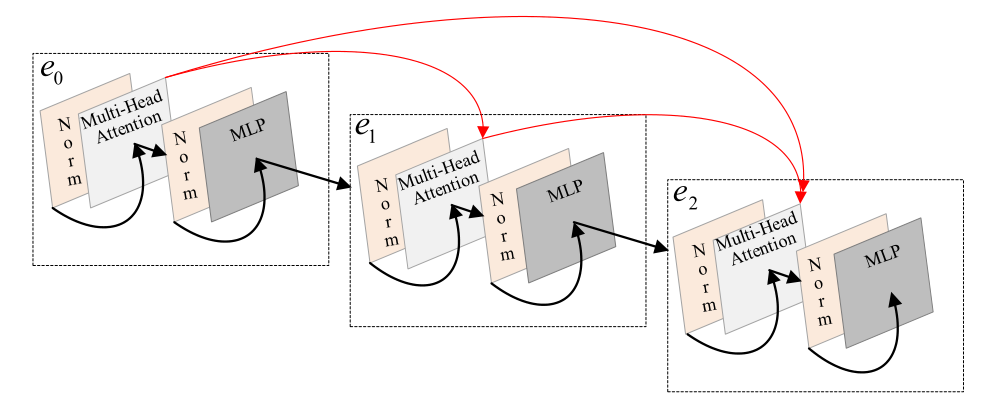
Note: 此處改進與DenseNet 特征復用類似,
③MLP部分:MLP的體系結構包括兩個具有GELU操作的完全連接層,其中最后一個完全連接層(即softmax層)旨在生成HSI分類的最終結果,對于一個輸入向量R,輸入屬于i類的概率可以估計如下:
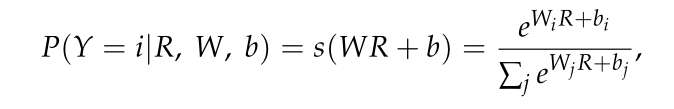
(2)SST-FA(SST+Feature Augmentation)
動態特征增強(正則化方法):由于VGG提取的空間特征維數較高(即512維),容易對Transformer模型進行過擬合,提出SST-FA 利用mask來避免過擬合問題,首先在特征中隨機選擇一個坐標,然后在坐標周圍放置一個掩碼,它決定將多少特征設定為零,注意,坐標在訓練期間動態地改變w.r.t. epoch,這確保Transformer模型接收到不同的特征,
(3)Transferring Spatial-Spectral Transformer(T-SST)
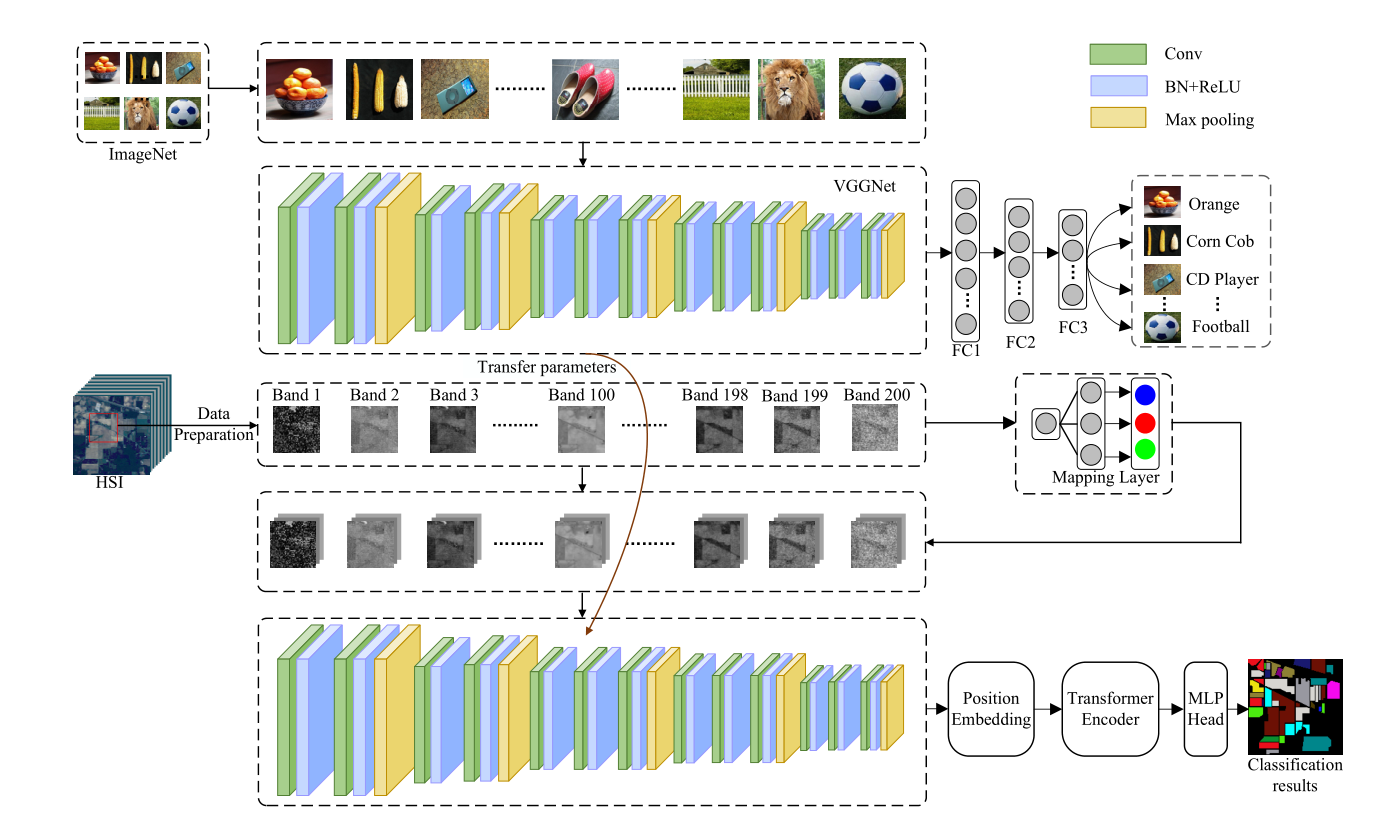
為了解決訓練樣本有限的問題,將遷移學習與SST相結合(原VGG模型經過預訓練后再進行HSI特征提取),以提高目標任務的分類性能, 分類程序分為基于遷移CNN的空間特征提取、基于Transformer的空間光譜特征提取和基于MLP的分類,就是利用VGGNet在ImageNet資料集上學到的權重初始化HSI分類的網路,然后對HSI分類任務上的權重進行微調,因為前幾層通常提取底層特征(即斑點、角和邊緣),而底層特征通常在影像分類任務中是常見的,
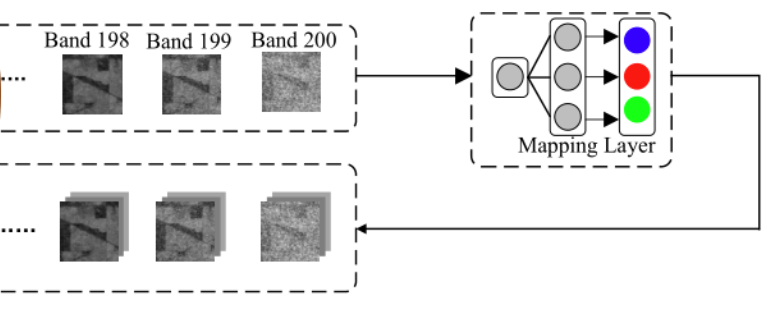
兩個資料集的異構問題:因為大規模資料集(即源資料集)有三個通道,而HSI(即目標資料集)包含數百個通道,為了解決異構遷移學習帶來的問題,使用映射層來處理兩個資料集的通道數(即波段數)不同的問題,VGG的輸入則由原來ImageNet的RGB三通道圖片轉變為HSI的單波段patch輸入,那么需要把HSI單波段patch通過Mapping Layer映射為類似RGB三通道的patch,這樣就與預訓練網路的輸入結構相同了,具體的映射方式原為只給了一個式子(O∈RW×H、O' ∈ RW×H×3、α ∈ R3×1):O' = O × α
(4)]T-SST-L(T-SST + Label Smoothing)
為了解決T-SST中的過擬合問題,引入了標簽平滑,ex:在分類中,每個訓練樣本x都有對應的標簽y∈{1,2,…C},C是類的數量,δk,y表示離散的狄拉克函式,當k = y時等于1,否則為0,
yk = δk,y
如果我們將所有的真實標簽都指定為“硬標簽”(即δk,y),則模型將努力將標簽的預測分布推向硬標簽,此外,如果適當地平滑標記,即在δk,y的零點上分配微小的概率質量,就可以有效地緩解這種情況,直觀地說,這是因為模型對其預測過于自信,因此,標簽平滑的機制就是來使模型不那么自信,從而獲得更好的性能,標簽平滑使原標簽yk變為y'k,定義如下:ε是平滑因子,
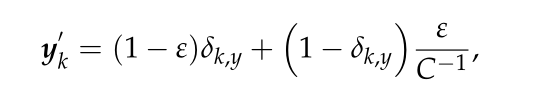
標簽平滑機制通過簡化模型來學習每個訓練樣本的全概率標簽,可以以簡單的形式緩解過擬合問題,提高模型的泛化能力,
Experimental Result
實驗首先介紹了對VGGNet改進的細節引數及網路結構,隨后對多頭注意力頭數、模型深度、標簽平滑因子引數做了實驗,當分別設定2、2、0.9時,效果最好,
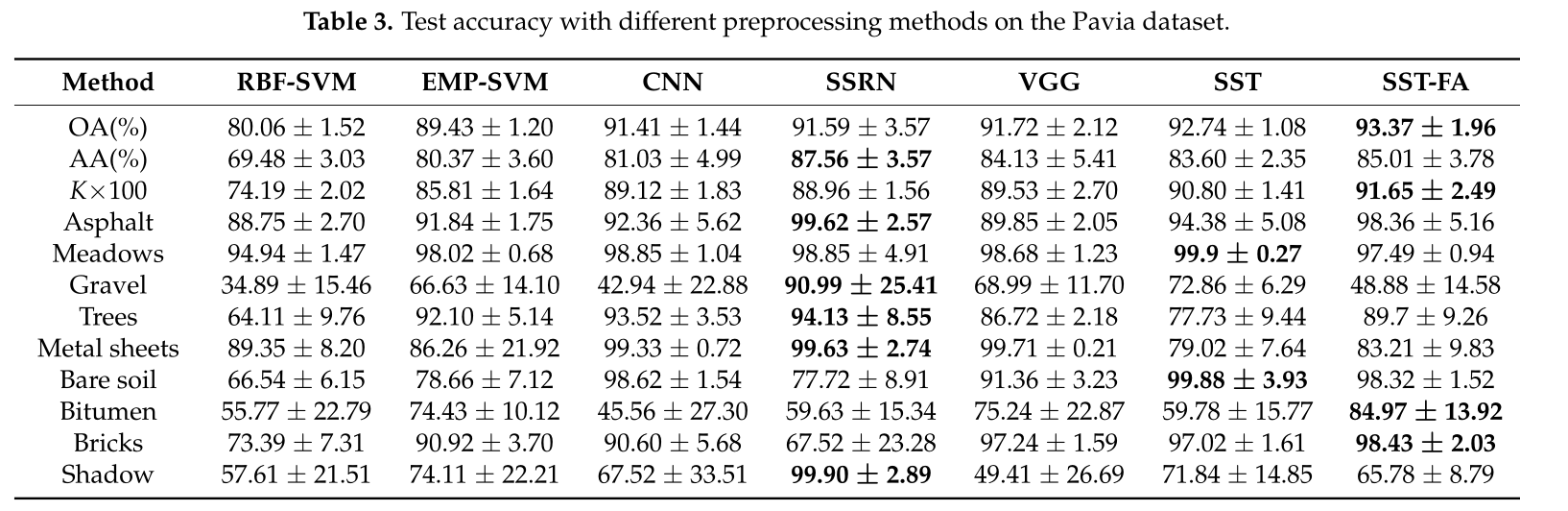
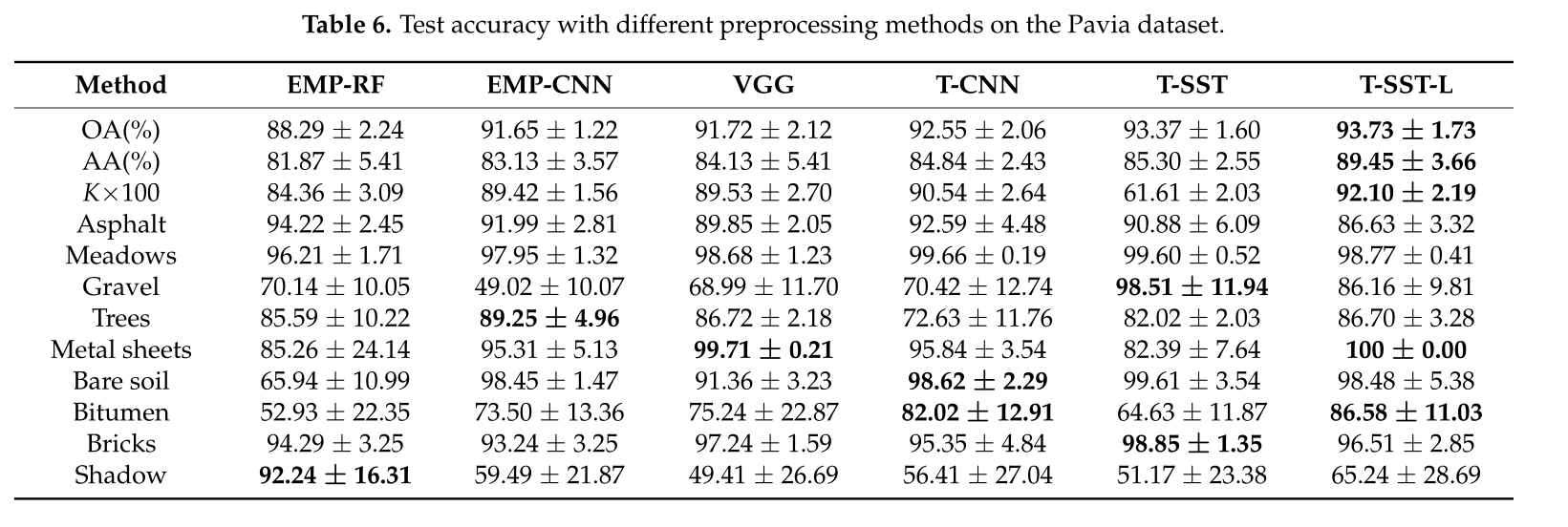
SST與SST-FA及其它網路做對比(Pavia):
T-SST與T-SST-L及其它網路做對比(Pavia):
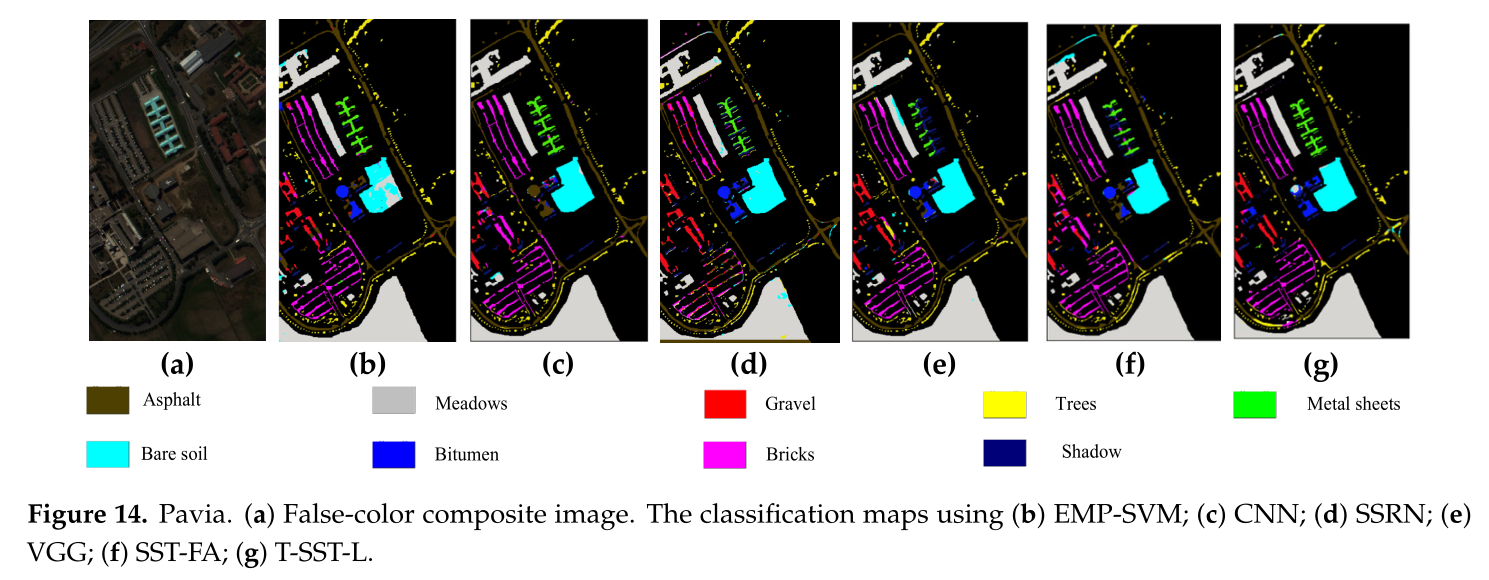
可視化類圖比較(Pavia):
運行時間比較:

Conclusion
提出了DenseTransformer,該方法利用密集連接來緩解Transformer訓練中的梯度消失問題,本文提出的基于SST的HSI分類方法,充分利用CNN獲取二維patch的空間特征,并充分利用DenseTransformer獲取譜域的長距離關系,此外,為了解決過擬合問題,提出了SST-FA,以Mask部分特征的形式訓練,提出的T-SST結合了遷移學習和SST,進一步提高了分類性能,為了在ImageNet資料集上使用預訓練的模型,設計了一個異構映射層,用于將模型從源域(即ImageNet資料集)映射到目標域(即HSI),在基于Transformer的HSI分類中,標簽平滑是一種有效的正則化方法,與SST、SST- FA、T-SST等方法相比,提出的T-SST-L具有更高的性能,基于Transformer的HSI分類還處于早期階段,在今后的作業中,我們可以利用Transformer的各種改進,為HSI的精確分類開辟新的視窗,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/509183.html
標籤:其他
上一篇:一文了解回圈神經網路
下一篇:帶你體驗給黑白照片上色