本系列強化學習內容來源自對David Silver課程的學習 課程鏈接http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
之前接觸過RL(Reinforcement Learning) 并且在組會學習輪講里講過一次Policy Gradient,但是由于基礎概念不清,雖然當時懂了 但隨后很快就忘,,雖然現在寫這個系列有些晚(沒有好好跟上知識潮流o(╥﹏╥)o),但希望能夠系統的重新學一遍RL,達到遇到問題能夠自動想RL的解決方法的程度,,
目錄
1. 基礎概念
1.1 強化學習為何重要
1.2 agent和environment
1.3 agent的組成和分類
2. Markov Decision Process(MDP)
2.1 Markov Reward Process(MRP)
2.2 Markov Decision Process(MDP)
2.3 Optimal Policy求最優解
2.4 Partial Observable Markov Decision Process(POMDP)
一、 基礎概念
強化學習為何重要?
因為它的原理 在所有學科中都有應用(下圖左),DeepMind與哈佛大學最新研究也證明,人腦中存在“分布強化學習”,獎勵為多巴胺(表示surprise的信號),并且,RL和監督/無監督學習一起構成機器學習(下圖右),它的“supervisor”是一個會延遲反應的cumulative reward(總回報),
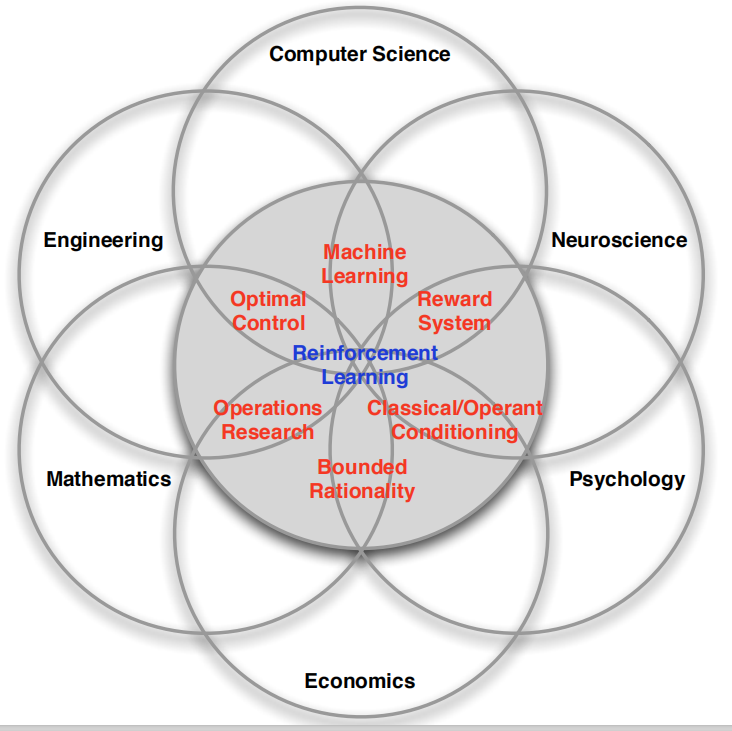
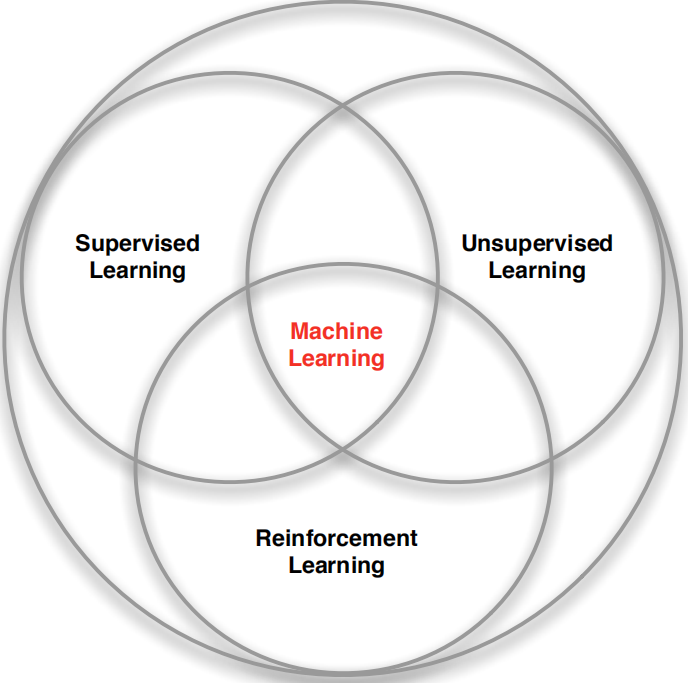
強化學習程序:
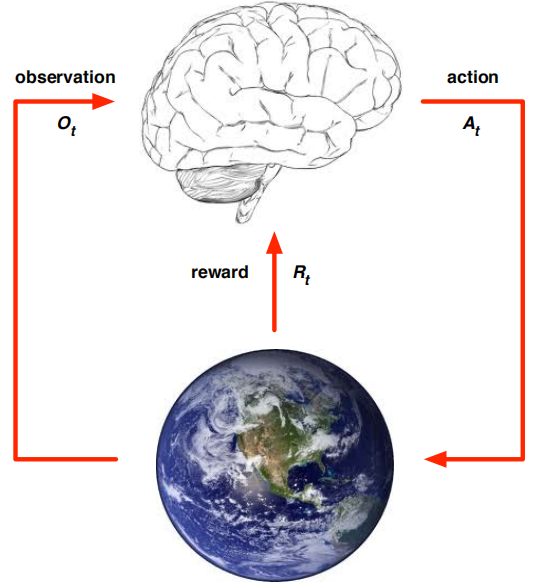
主要包含Agent和Environment兩個主體,RL的程序在它們中展開(下圖左):某時刻t,Agent觀測環境Ot、根據自己所知的回報Rt、產生動作At,Environment接收到At后、時間前進成t+1、環境變換Ot+1、回報更新Rt+1,這個程序式列就叫history![]() ,某個時刻狀態 就叫State(分成Set和Sat),
,某個時刻狀態 就叫State(分成Set和Sat),
Sat可以通過Ht得出(Sat=f(Ht)),并且如果P[St+1|St] = P[St+1|S1,...,St],即得到了St后可以把之前的history都丟掉 當前狀態只與前一狀態有關,狀態St就是Markov的,
Set不一定可知,如果fully observable可知 則:Ot=Sat=Set,這是一個Markov decision process(MDP),也是課程的大部分內容;如果partial observable部分可知 則:Sat != Set, 這是一個Partial observable MDP(POMDP),此時agent必須要構建自己狀態的表達,可以是來自history![]() , 可以是對環境的預測
, 可以是對環境的預測![]() ,可以是RNN
,可以是RNN![]() ,,,
,,,
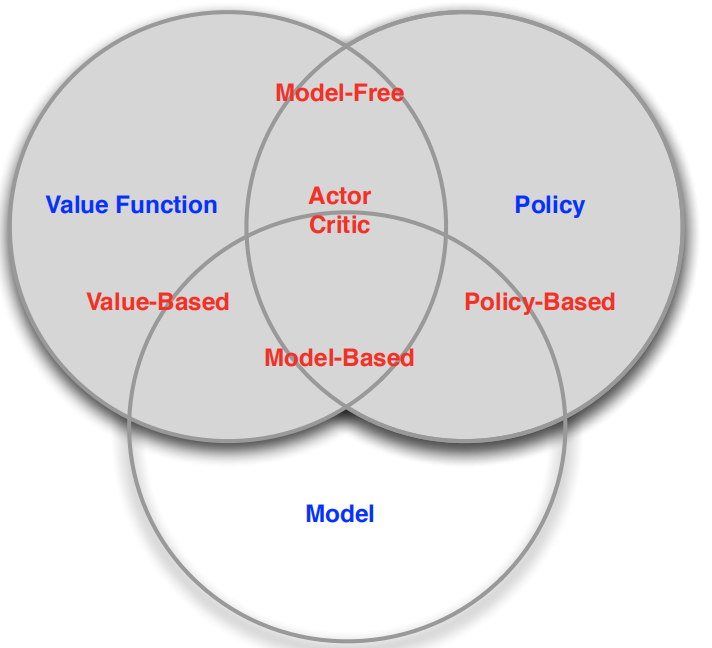
Agent的組成和分類:
Agent可能包含以下一個或者多個部件:policy,value function,model,
所以agent可以分成多類(上圖右),對于policy和value function這兩個來說,用policy - Policy Based,用value function - Value Based,都用 - Actor Critic,對于model來說,有model - Model Based,沒有model - Model Free,
那么它們各自是什么呢?
policy和value function都可以達到決定在當前state下產生什么行為action的效果,policy(記π)是函式(包括deterministic:相同s相同a — a=π(s), 和stochastic:顯示此s下出現某a的可能性 — π(a|s)=P[At = a | St = s]), value function是每個state的未來回報預測 即![]() ,這樣就能選擇action使其達到更優的state,
,這樣就能選擇action使其達到更優的state,
而model是agent對于環境下一步做什么的預測,包含下一步狀態的預測P和對于immediate reward的預測R,
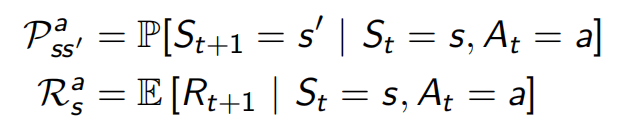
這樣,agent通過不斷和環境的互動,提升自己做決策的能力,squential decision making程序中有兩個基本問題,environment如果一開始unknown 則是RL,如果一開始known 則是planning,一個常用的強化學習問題解決思路是,先學習環境如何作業得到一個模型,然后利用這個模型進行規劃,
強化學習也是一個不斷試錯的程序(trial-and-error learning),從而可以將這個學習程序分成exploration(探索更多environment資訊)和exploitation(利用已有資訊最大化reward)兩部分,
也可以分成prediction和control兩部分,prediction是預測按照當前policy走會有什么結果,control是更近一層,在多個policy中選取total reward最大的一個最優policy,
二、Markov Decision Process(MDP)
MDP之所以重要,是因為幾乎所有RL問題都可以轉換為MDP的格式<S,A,P,R,γ>,即一個時刻的狀態,幾乎可以完全集成整個歷史程序的資訊,Markov性上面寫過P[St+1|St] = P[St+1|S1,..., St],
在學MDP前,最基本的是Markov Process(Chain),<S,P>組成,S是有限狀態集,P是狀態轉移概率矩陣![]() (見下圖),每一行的概率和為1,
(見下圖),每一行的概率和為1,
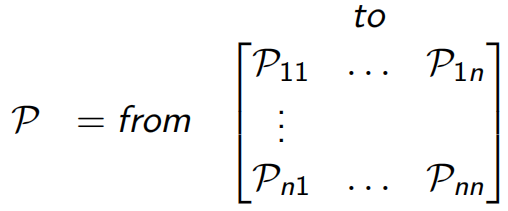
Markov Reward Process(MRP)
需要注意的是MRP和MDP的區別,MRP由<S,P,R,γ>組成,加了policy π后MRP格式改變成![]() ,與馬爾科夫鏈相比,多了一個基于狀態的回報函式R和一個∈[0,1]的discount factor γ(經濟學上翻譯作貼現系數),
,與馬爾科夫鏈相比,多了一個基于狀態的回報函式R和一個∈[0,1]的discount factor γ(經濟學上翻譯作貼現系數),
回報函式![]() ,是當前狀態所獲得的回報的數學期望(類似于取平均值),前面寫過RL中t+1是在agent做出action后發生的,仍舊是當前狀態下,即意思是不管在這個狀態下做什么action,Rs=Rt+1都一定的,
,是當前狀態所獲得的回報的數學期望(類似于取平均值),前面寫過RL中t+1是在agent做出action后發生的,仍舊是當前狀態下,即意思是不管在這個狀態下做什么action,Rs=Rt+1都一定的,
γ是一個未來對現在影響的數學上的表達,γ=0,完全短視不考慮未來,γ=1,undiscount未來的所有狀態都考慮,γ的加入主要是因為一是會削弱MP中環的影響,二是模型對未來的估計不一定準確,
所以總的discounted的回報Gt,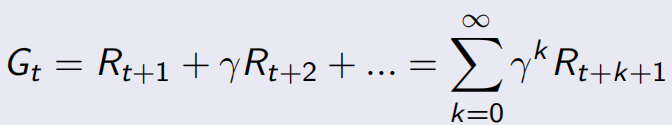 ,這里是求和的是在t時刻隨機采樣產生的一系列狀態點,
,這里是求和的是在t時刻隨機采樣產生的一系列狀態點,
根據Gt,value function可以換一種寫法![]() ,類似于采樣所有s狀態下的Gt取平均值,
,類似于采樣所有s狀態下的Gt取平均值,
后來Bellman看到這個value function表達又做了化簡(下圖),即可以將value function看做immediate回報Rt+1和下一個狀態的價值discount后的和,這就是Bellman Equation貝爾曼方程,可以寫成![]() 的格式(v=R+γPv),此時是線性的可以解出
的格式(v=R+γPv),此時是線性的可以解出![]() ,求解復雜度O(n3),可以用線性規劃和Temporal-Difference Learning等方法解,
,求解復雜度O(n3),可以用線性規劃和Temporal-Difference Learning等方法解,
Bellman Equation推導: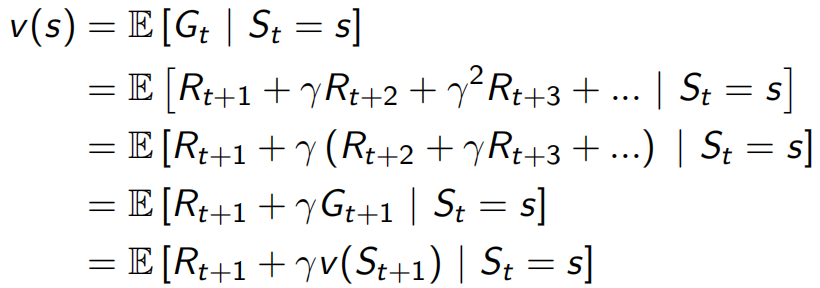
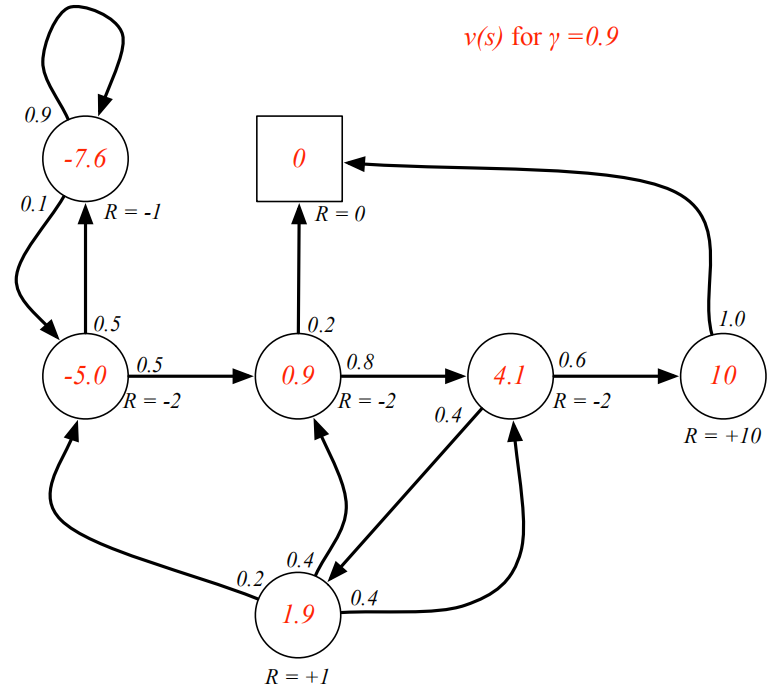
舉例如下圖的MP程序圖中,每個節點就表示當前狀態s,里面數字是v(s),比如v(s)=4.1的節點,求法是0.6*(-2+0.9*10)+0.4*(-2+0.9*1.9)=4.084,并且4.084≈4.1說明此時已經達到self-consistant狀態,
Markov Decision Process(MDP)
馬爾可夫決策程序相較于MRP多引入了action動作的因素,MDP的格式<S,A,P,R,γ>,從此P和R都加入了a的影響(見下圖左),加了policy π(a | s)后,變成更一般的形式(見下圖右):
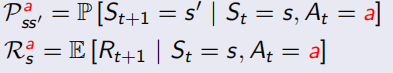
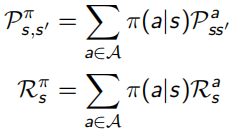
并且除了之前的state-value function V(s),還加入了action-value function q(s, a)表示在狀態s下采取動作a會得到什么回報:
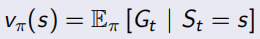
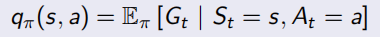
Bellman同樣對這兩個value function做了化簡,化簡后的結果稱為Bellman Expectation Equation:
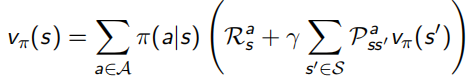
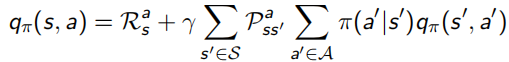
其中,![]() ,是線性的,所以可以求解出
,是線性的,所以可以求解出 ![]()
Bellman Expectation Equation推導程序(上下兩式子結合起來看):
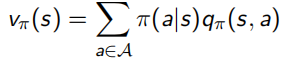
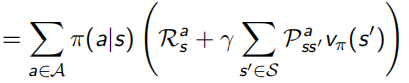
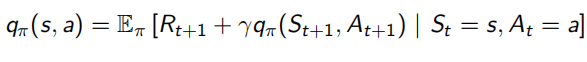
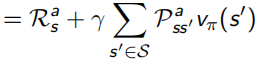
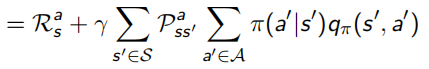
比如在下面這個例子中,7.4這個節點的v(s)更新方法如下 —— 現在已經self-consistant,每個action默認概率相同,
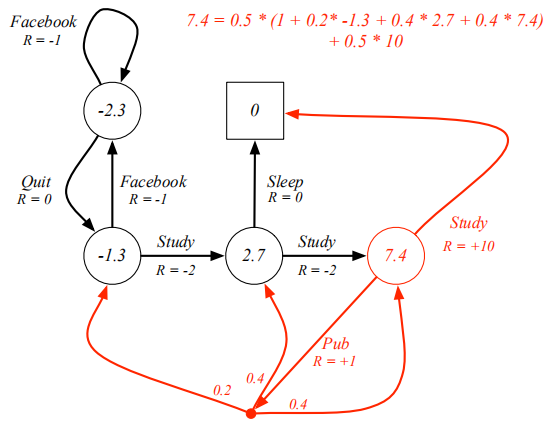
Optimal policy求最優解
通過這些設定,就可以進行最優策略的求解,即control,多個policy中選取最優的一個,可以看做下面的式子,
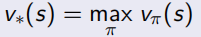
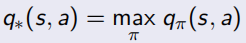
當最優的action-value function得知后,就可以知道當前狀態下應該選哪個action,從而直接求出最優策略,相當于只要知道了action-value function 就什么都知道了:
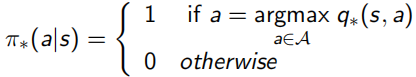
這里Bellman又出現了,他化簡上面對value function求解的式子,得到了一個更明了的表示叫做Bellman Optimality Equation:
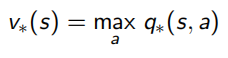
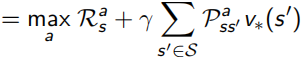
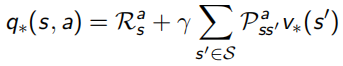
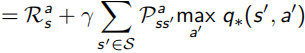
意思是使用這個Bellman Optimality Equation,就可以得到state-value和action-value兩個函式最優解,從而獲得整個問題的最優策略,問題就能解決啦,
可惜的是,由于程序中涉及max,方程變得不可導了,因此求解的方法有value/policy iteration,Q-learning,SARSA等方法,將在之后的文章中介紹,
Partial Observable Markov Decision Process(POMDP)
部分可觀測的馬爾可夫決策程序,POMDP由<S, A, O, P, R, Z, γ>組成,其中O表示觀測到的序列,Z是觀測到的函式,如下面所示,Belief state b(h)是基于history h的狀態概率分布,這里t時刻的history Ht = A0, O1, R1, ..., At-1, Ot, Rt,雖然很復雜,可是更現實啊,

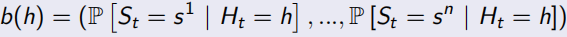
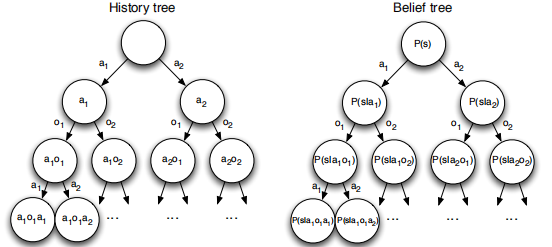
POMDP可以被分解成history tree和belief tree,如下圖:
但是更詳細的內容課程里也沒有介紹,之后感興趣的話會專門補充的,,,,
總而言之,本文主要介紹了強化學習的基本思路程序,和問題的最優解是怎么尋找的,之后會繼續寫出尋找問題最優解的具體技術支持,嗯,,一定要堅持寫下去啊?( 'ω' )? ! 學習使我快樂,總結使我識訓\(^o^)/,黑黑
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/51625.html
標籤:其他
上一篇:手寫數字識別——利用keras高層API快速搭建并優化網路模型
下一篇:【強化學習RL】model-free的prediction和control — MC, TD(λ), SARSA, Q-learning等