本系列強化學習內容來源自對David Silver課程的學習 課程鏈接http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html
在上一文介紹了RL基礎概念和MDP后,本文介紹了在model-free情況下(即不知道回報Rs和狀態轉移矩陣Pss'),如何進行prediction,即預測當前policy的state-value function v(s)從而得知此policy的好壞,和進行control,即找出最優policy(即求出q*(s, a),這樣π*(a|s)就可以立刻知道了),
在prediction部分中,介紹了Monto Carlo(MC),TD(0),TD(λ)三種抽樣(sample)估計方法,這里λ的現實意義是隨機sample一個state,考慮其之后多少個state的價值,當λ=0即TD(0)時,只考慮下一個狀態;λ=1 時幾乎等同MC,考慮T-1個后續狀態即到整個episode序列結束;λ∈(0,1)時為TD(λ),可以表示考慮后續非這兩個極端狀態的中間部分,即考慮后面n∈(1, T-1)個狀態,同時,prediction程序又分為online update和offline update兩部分,即使用當前π獲得下一個狀態的回報v(s')和優化policy π是否同時進行,
在control部分中,介紹了如何尋找最優策略的方法,即找到q*(s, a),分成on-policy和off-policy兩部分,即沒有或者是參考了別人的策略(比如機器人通過觀察人的行為提出更好的行為),在on-policy部分,介紹了MC control、SARSA、SARSA(λ)三種方法,off-policy部分介紹了Q-learning的方法,
具體都會在下面正文介紹,
目錄:
一、model-free的prediction
1. Monto Carlo(MC) Learning
2. Temporal-Difference TD(0)
3. TD(λ)
二、model-free的control
1. on-policy的Monto Carlo(MC) control
2. on-policy的Temporal-Difference(TD) Learning - SARSA和SARSA(λ)
3. off-policy的Q-learning
一、model-free的prediction
Prediction 部分的內容,全部都不涉及action,因為是衡量當前policy的好壞,只需要估計出每個狀態的state-value function v(s)即可,上一文中介紹了使用Bellman Expectation Equation求得某個狀態v(s)的數學期望,可以用動態規劃DP進行遍歷全部狀態求得,但是這樣的效率是非常低的,下面介紹了兩種用sample采樣的方法獲取v(s),
1. Monto Carlo(MC) Learning
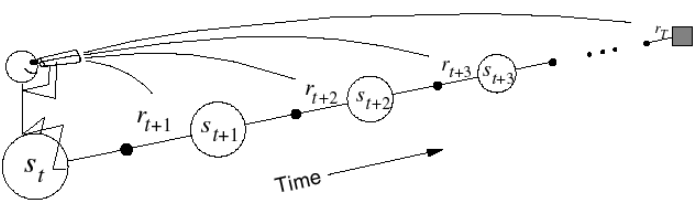
Monto Carlo是一個經常會遇到的詞,它的核心思想是從狀態st出發隨機采樣sample至獲得很多個完整序列,可以獲得完整序列的實際收益,從而取平均值就是v(st),需要注意的是,MC只能用于terminate的序列(complete)中,
在MC sample的程序中,每個狀態點值函式![]() ,每次遍歷N(s)+=1,S(s)為總回報每次S(s)+=Gt,這里Gt表示第t次采樣獲得的回報,這樣當
,每次遍歷N(s)+=1,S(s)為總回報每次S(s)+=Gt,這里Gt表示第t次采樣獲得的回報,這樣當![]() 時,
時,![]() ,所求的平均值V(s)就接近真實值Vπ(s),在獲得完整序列的程序中,很可能會遇到環,即一個狀態點經過多次,對此MC有兩種處理方法,first step(只在第一次經過時N(s)+=1)和every step(每次經過這個點都N(s)+=1),
,所求的平均值V(s)就接近真實值Vπ(s),在獲得完整序列的程序中,很可能會遇到環,即一個狀態點經過多次,對此MC有兩種處理方法,first step(只在第一次經過時N(s)+=1)和every step(每次經過這個點都N(s)+=1),
V(s)可以看做所有經過s的回報求和后取平均值產生,但是這個平均值計算不僅可以先求和再做除法,還可以通過在已有的平均值上加一點差值獲得,就是下面左式的形式,已有的平均值為V(St),此次采樣獲得的回報為Gt,同當前平均值的差值為(Gt - V(St)),但這樣來看,需要一直維護一個N(s)計數器,可是,真正平均值優化時只需要知道一個優化的方向即可,所以用一個(0,1)常數α來代替1/N(St),即下面右式的形式, α的現實意義是一個遺忘系數,即適當程度以往古老的采樣結果,不需要對所有sample出的序列都記得很清楚,
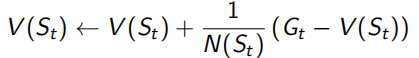
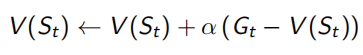
2. Temporal-Difference TD(0)
Monto Carlo采樣有一個很明顯的缺點,就是必須要sample出完整的序列才能觀測出這個序列得到的回報是多少,但是TD(0)這種方法就不需要,它利用Bellman Equation,當前狀態收益只和及時回報Rt+1和下一狀態收益有關(如下式),紅色部分為TD target,α右邊括號內為TD error,所以TD(0)只sample出下一個狀態點St+1,用已有的policy計算出Rt+1和V(St+1),這種用已知來做估計的方法叫做bootstrapping(updates a guess towards a guess),而MC是觀測的實際值取平均,是沒有bootstrapping的,由于TD(0)只需要sample出下一個狀態St+1,所以可以用于non-terminate序列中(incomplete),
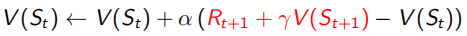
同MC比較,TD(0)采用已有policy預測出TD error,和MC的實際值相比有更大的偏差,但是TD(0)只需要sample出下一個狀態序列而不是MC的完整序列,所以TF(0)預測獲得的方差比MC小,
具體對v(s)的計算舉例如下,進行8次sample,不考慮discount factor γ,下圖獲得的V(A)和V(B)分別是什么?
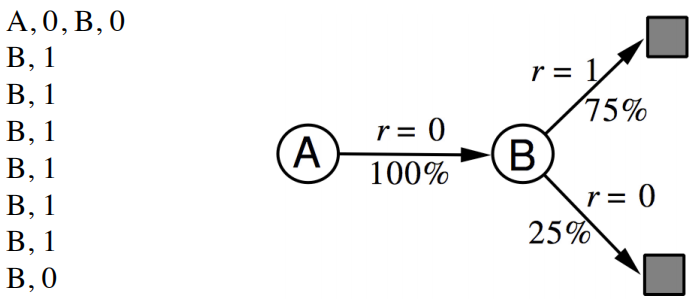
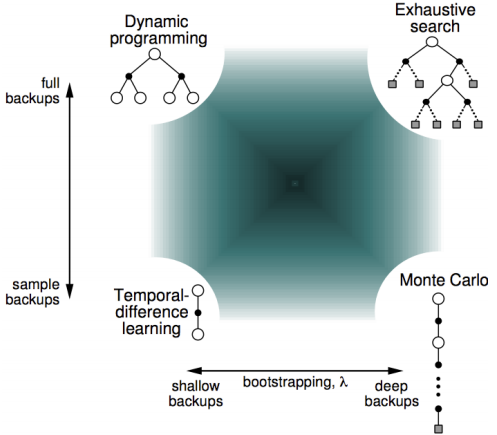
可以看出,無論是TD還是MC,v(B)都是取平均值計算出來的0.75;但是通過MC算出的V(A)是0,因為A只有一次sample結果是0,TD(0)算出來的是0.75,因為A的下一個狀態是B且V(B)=0.75, r=0,這一點來看,TD演算法更能夠利用Markov特性;TD(0)只sample下一個狀態點的結果,而不需要每次sample都要等到最終序列結束出結果,所以比MC更高效;但是由于是bootstrapping方法,受初始化值影響更大,擬合性也不如MC好,下圖顯示了計算期望全部遍歷的動態規劃DP演算法,sample采樣下一個狀態TD(0)演算法,和sample出完整序列T-1個狀態的MC演算法相互間的關系,但是在1和T-1之間的諸多點,也可以sample考慮,這就是更一般的表達TD(λ),
3. TD(λ)
這里λ是一個∈[0,1]的實數,它決定了需要采樣之后的多少個狀態點St+n,n從1到無窮大的簡略表達如下左式,Gt(n)表示采樣到St+n時獲得的回報,那么如何綜合一下Gt(1)到Gt(n)的回報呢,這里給每一個Gt乘了一個系數(1-λ)λ^(n-1),由于∑λ^n = 1/(1-λ),所以右式的∑=1,
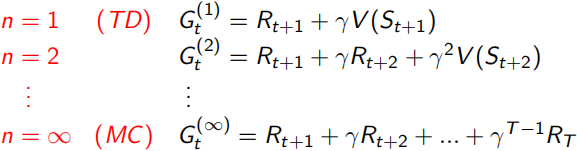
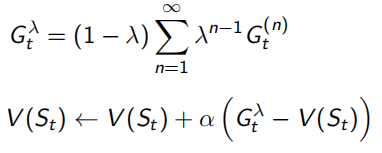
這里Gtλ的系數表示如下圖所示,曲線下方的面積和為1,可以看出,每次權重都會削減成原來的λ倍(λ∈[0,1]),這樣很靠后的狀態權重就逐漸減小,可以達到減小λ減小n的效果,這里控制系數的實數λ就可以控制n,比如λ=0時,與TD(0)的函式表達相同,表示再往后采樣一個狀態St+1,λ=1時,每次不削減,表示采樣到最后相當于MC,
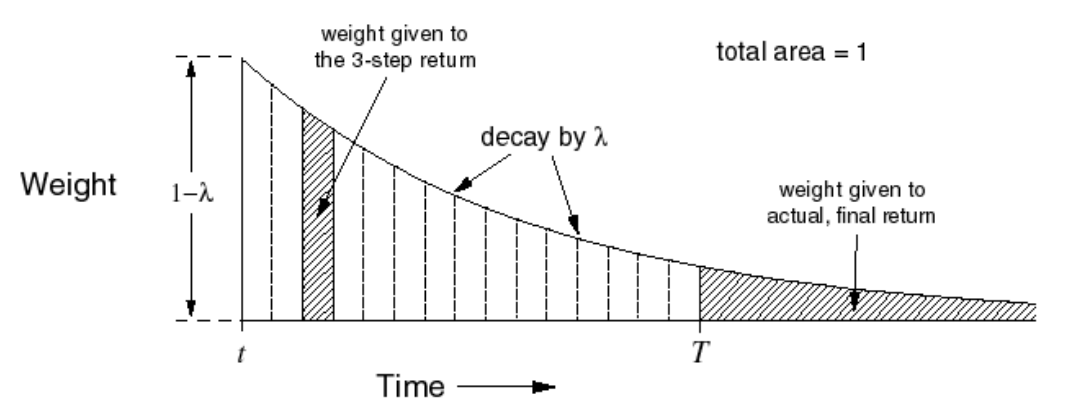
Temporal-Difference的sample分成了forward-view(下圖左)和backward-view(下圖右)兩部分,forward-view就是剛剛敘述的往后sample n個狀態點(受λ控制),是看未來的回報的 ,類似于MC只能用于complete的序列,backward-view卻可以用在incomplete的序列上,只需在sample的程序中,每一步更新都維護一個Eligibility Trace,記錄這個未完畢序列的資訊,最后成為對平均值更新的權重,
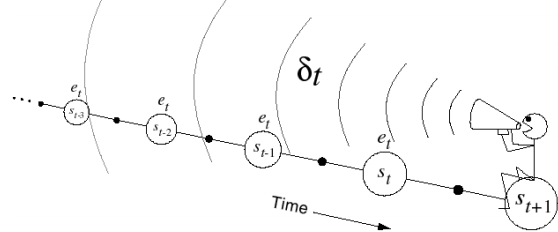
這里的Eligibility Trace(下面左式),類似于青蛙跳井,每跳一下會升高,不跳的話就逐漸掉下去,既結合了frequency heuristic(跳幾下),又結合了recency heuristic(什么時候跳的),而這里的“跳”,就相當于經過狀態所求點s,這樣backward-view的值函式更新就可以寫成下面右式的形式,當λ=0時,只有在經過s時Et(s)才為1,下面右式 結果同TD(0)表達相同;當λ=1時,整個序列中的每一個狀態點有eligibility trace值會被考慮,可以看做MC,每次值函式的更新既參考了TD-error(![]() )又參考了eligibility trace Et(s),
)又參考了eligibility trace Et(s),
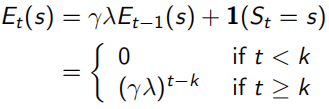
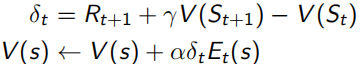
Eligible Trace的函式可以看做如下的表示,縱軸表示積累的值橫軸表示時間,| 表示遇到狀態s的時刻點:

當λ=0,只在當前狀態做更新,下圖左式完全等同于TD(0)的下圖右式:
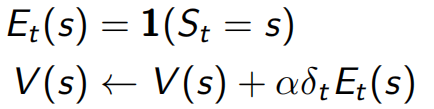
![]()
同時,TD(1)完全等同于MC(every-visit),下面式子可以看出,λ=1時,Et(s)=γ^t-k,連續的TD error求和,為![]() ,即可看作一直sample出完整序列T-1的MC error,
,即可看作一直sample出完整序列T-1的MC error,
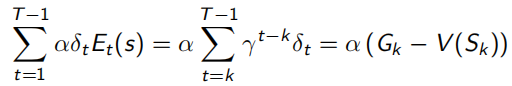
當序列環境是offline update時,即所有sample程序中不改變policy,forward-view和backward-view相同(見下式,左邊可以化簡到右邊的形式),并且TD error可以化為λ-error的形式,
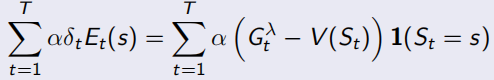
![]()
當序列環境是online update時,即邊sample邊優化policy,backward-view就會一直累積一個error,如下,所以如果訪問s多次,這個error就會變得很大,
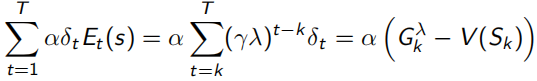
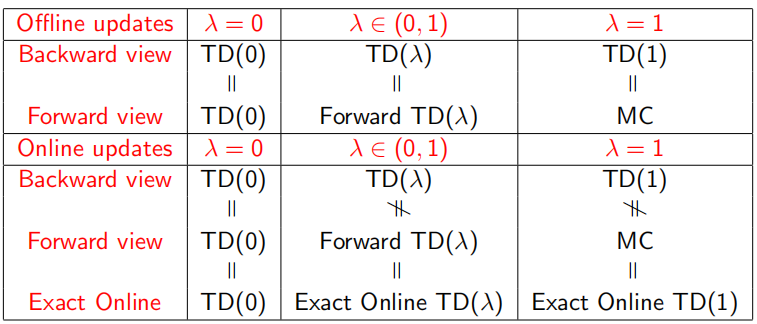
總結的一個表格如下:
二、model-free的control
這里on-policy可以看做“learn on the job”,即對自己行為的反思優化;off-policy可以看做“look over someone‘s shoulder’”,即通過觀察其他agent的行為提出優化,
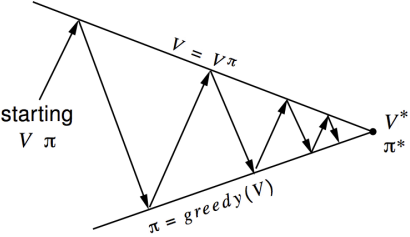
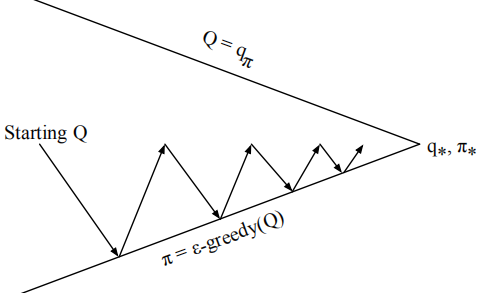
在尋找最優policy程序中,可以看做policy evaluation和policy improvement兩部分,一種最基礎的貪心演算法做improvement如下圖,每次V通過當前策略π做evaluation,之后策略π再greedy找尋更優的值函式對應狀態,這樣可以保證v和π最終都向最優V*和π*收斂,
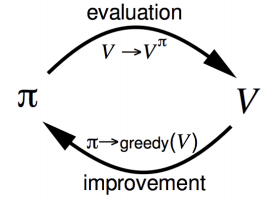
下面介紹的幾種方法都是基于這個evaluation和improvement框架進行展開,只不過是model-free的,沒有狀態轉移矩陣P的相關值無法進行![]() 的推導,所以只能用action-value函式q(s, a),通過
的推導,所以只能用action-value函式q(s, a),通過![]() 對policy進行優化,
對policy進行優化,
并且,對于下面介紹的sample方法進行policy evaluation來說,單純用greedy演算法并不準確,因為很可能某狀態在一個action下會有更高回報,可是正好沒有sample到這個更高回報值,該條路徑就會被忽略,陷入區域最優解,所以這里又提出使用ε-greedy代替絕對的greedy演算法(ε∈[0,1]),變得更soft,每次1-ε概率選擇所知最優的action,ε在所有action集合中隨機選擇,如下面左式,下面右式證明可得,采用ε-greedy獲得的Vπ'(s)≥Vπ(s),整體向更優策略方向走,
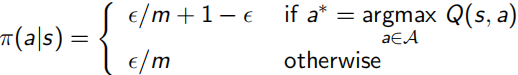
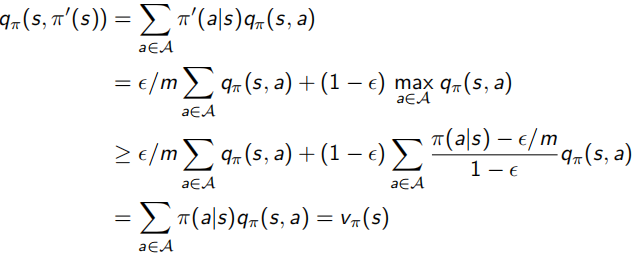
很簡單的方法,但可以explore更大的state space,獲得更全域的最優解,
1. on-policy的Monto Carlo(MC) control
采用MC方法估計action-value function,然后使用ε-greedy做策略優化,但這里在原始MC control基礎上可以做優化,即每次不需要估計出很精確的qπ,只需要Q ≈ qπ即可,再在Q上做優化,仍舊是朝向著最優q*的方向前進的,
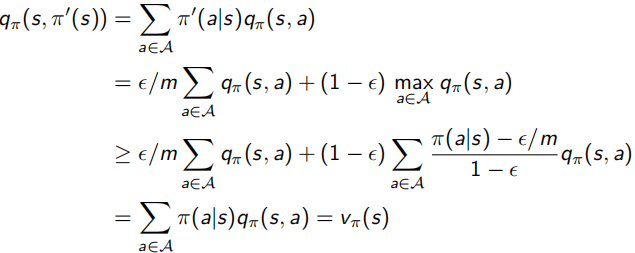
坑代填,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/51634.html
標籤:其他
下一篇:L1和L2:損失函式和正則化