Principal component analysis(PCA)
中文就是主成成分分析,在學數學建模的時候將這分為了評價類的方法(我實在是很難看出來,在機器學習中是屬于無監督學習降維方法的一種線性降維方法,
舉一個最簡單的栗子(下圖,二維的資料降到一維,就得找到一條直線將所有的點都投影到該直線上,這條直線需要滿足的條件就是投影在這條直線上的所有點的方差最大,減少資訊的損失,
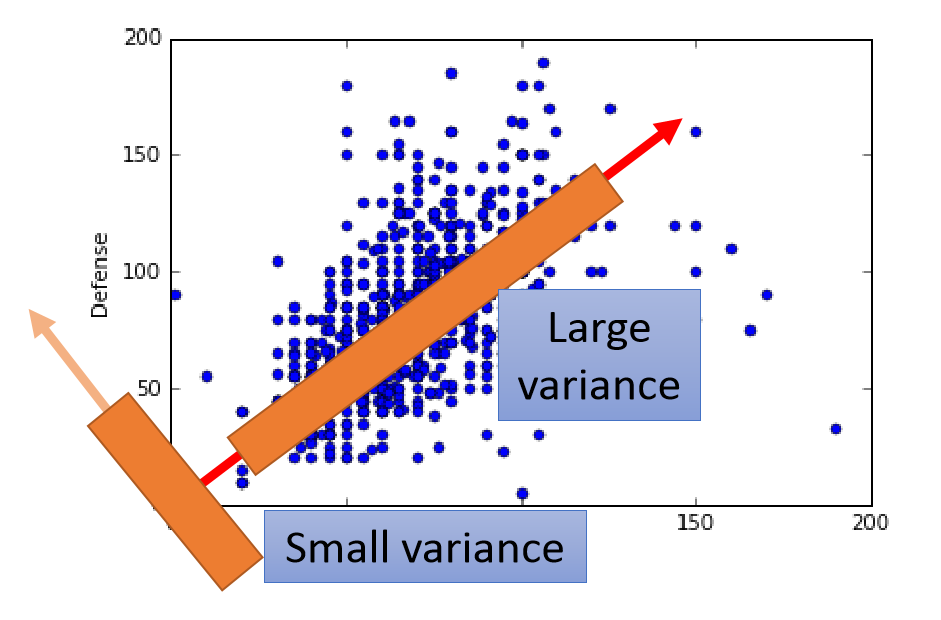
PCA主要用于當資料的維度過高或者不同維度的資料之間存在相關的關系,造成了機器學習性能的下降的問題,這個時候PCA就是要將高維特征轉化為獨立性較高的低維特征,降低特征之間的相關性,
Math of warning!
\(X_{nxm}\):n維特征的資料,\(Z_{kxm}\):k維特征的資料,PCA技術就是要找到一組\(W_{kxn}\)使得\(Z=W\cdot X\),同時\(Maximize(\sum_i^kVar(Z_i))\),\(Z_i\)表示第i-D下的投影,
-
第一步 將X降到\(Z_1,Z_2\)上
\(Z_1=W_1\cdot X\)
\(Var(Z_1)=\frac{1}{m}\sum_{j=1}^m(Z_{1j}-\overline{Z_1})^2\),\(|W_1|=1\)投影但是不影響大小
\(Z_2=W_2\cdot X\)
\(Var(Z_2)=\frac{1}{m}\sum_{j=1}^m(Z_{2j}-\overline{Z_2})^2\),\(|W_2|=1\)投影但是不影響大小,但是為了是方差最大或者說使特征之間的相關性最低,\(W_1\cdot W_2=0\)
PS:如果不加這個條件的話\(W_1==W_2\) -
第二步 求解\(Var(Z_1),Var(Z_2)\)
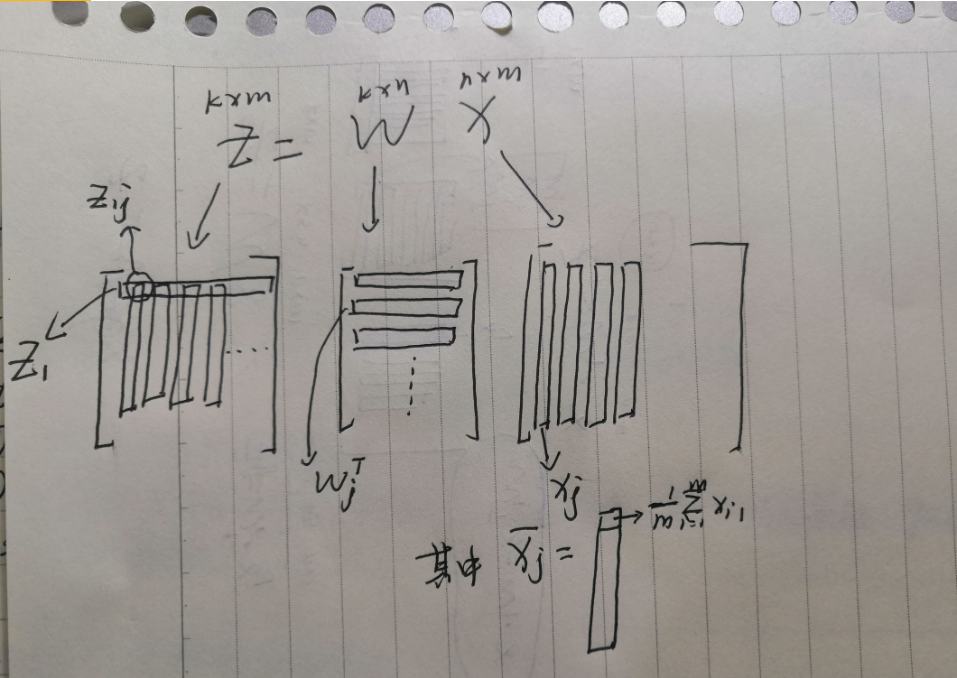
PS:注意這里加\(\cdot\)是向量積,不加的是矩陣乘法(坑
-
\(Z_{1j}=W_1\cdot X_j,\overline{Z_1}=\frac{1}{m}\sum_{j=1}^mZ_{1j}=\frac{1}{m}\sum_{j=1}^mW_1\cdot X_j=W_1\cdot \overline{X_j}\)
-
\(Var(Z_1)=\frac{1}{m}\sum_{j=1}^m(W_1\cdot X_j-W_1\cdot \overline{X_j})^2=\frac{1}{m}\sum_{j=1}^m[W_1\cdot (X_j-\overline{X_j})]^2=W_1^T[\frac{1}{m}\sum_{j=1}^m(X_j-\overline{X_j})(X_j-\overline{X_j})^T]W_1=W_1^TCov(X)W_1=W_1^TSW_1,S=Cov(X)\)
-
接下來是最大化\(Var(Z_1)\),存在Constraint:\(|W_1|=1,W_1.TW_1-1=0\),利用拉格朗日算子法
\(g(W_1)=W_1^TSW_1-\alpha(W_1.TW_1-1)\)
\(\forall i<=m, \frac{\partial g(W_1)}{\partial W_{1i}}=0\rightarrow SW_1-\alpha W_1=0\) 可知\(W_1\)是S的特征向量,\(\alpha\)是S的特征值
\(Var(Z_1)=W_1^TSW_1=W_1^T\alpha W_1=\alpha W_1^TW_1=\alpha\),要是方差最大則\(\alpha\)是S的最大特征值,\(W_1\)為所對應的特征向量, -
按照相同的思路來最大化\(Var(Z_2)\),存在constraints:\(W_2^TW_2-1=0,W_1^TW_2=0\)
\(g(W_2)=W_2^TSW_2-\alpha(W_2^TW_2-1)-\beta(W_2^TW_1)\)
\(\forall i<=m, \frac{\partial g(W_2)}{\partial W_{2i}}=0\)
\(\rightarrow SW_2-\alpha W_2-\beta W_1=0 \rightarrow W_1^TSW_2-\alpha W_1^TW_2-\beta W_1^TW_1=0\)
\(\rightarrow \beta=W_1^TSW_2=(W_1^TSW_2)^T=W_2^TSW_1=W_2^T\lambda W_1=\lambda W_2^TW_1=0\)
因為\(\beta=0\)所以\(SW_2=\alpha W_2\),同理可知\(W_1\)是S的特征向量,\(\alpha\)是S的特征值
\(Var(Z_2)=W_2^TSW_2=\alpha\),要想方差最大且滿足約束條件(隱含條件S是Symmetric的,特征向量是正交的),則\(\alpha\)是第二大的特征值且\(W_2\)是對應的特征向量,
- 第三步 得出結論
降至不同空間維度上保存的資訊量的大小是降維所用S的特征向量所對應的特征值的大小決定的
Conclusions
1、因為S一定是實對稱矩陣,則經過對S的奇異值分解以后\(S=Q\sum Q^T\),\(\sum\)是一個對角線為S的特征值的矩陣,Q是特征值對應的特征列向量矩陣,從Q中抽取特征值最大的對應的特征列向量就可以進行降維,并且通過特征值算出簡單的資訊損失情況,
import numpy as np
U,S,V=np.linalg.svd(S)
人生此處,絕對樂觀
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/51660.html
標籤:其他