筆記轉載于GitHub專案:https://github.com/NLP-LOVE/Introduction-NLP
4. 隱馬爾可夫模型與序列標注
第3章的n元語法模型從詞語接續的流暢度出發,為全切分詞網中的二元接續打分,進而利用維特比演算法求解似然概率最大的路徑,這種詞語級別的模型無法應對 OOV(Out of Vocabulary,即未登錄詞) 問題: 00V在最初的全切分階段就已經不可能進人詞網了,更何談召回,
例如下面一句:
頭上戴著束發嵌寶紫金冠,齊眉勒著二龍搶珠金抹額
加粗的就是相對陌生的新詞,之前的分詞演算法識別不出,但人類確可以,是因為讀者能夠識別“戴著”,這些構詞法能讓人類擁有動態組詞的能力,我們需要更細粒度的模型,比詞語更細粒度的就是字符,
具體說來,只要將每個漢字組詞時所處的位置(首尾等)作為標簽,則中文分詞就轉化為給定漢字序列找出標簽序列的問題,一般而言,由字構詞是序列標注模型的一種應用, 在所有“序列標注”模型中,隱馬爾可夫模型是最基礎的一種,
4.1 序列標注問題
序列標注指的是給定一個序列 \(x=x_1x_2...x_n\),找出序列中每個元素對應標簽 \(y=y_1y_2...y_n\) 的問題,其中,y 所有可能的取值集合稱為標注集,比如,輸入一個自然數序列,輸出它們的奇偶性,
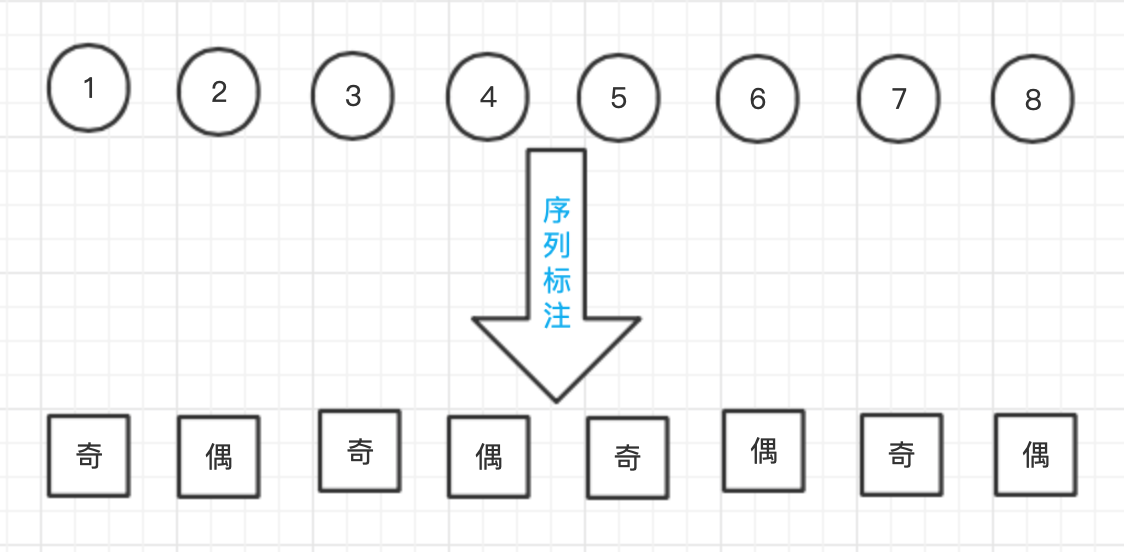
求解序列標注問題的模型一般稱為序列標注器,通常由模型從一個標注資料集 \(\{X,Y\}=\{(x^{(i)},y^{(i)})\},i=1,...,K\) 中學習相關知識后再進行預測,再NLP問題中,x 通常是字符或詞語,而 y 則是待預測的組詞角色或詞性等標簽,中文分詞、詞性標注以及命名物體識別,都可以轉化為序列標注問題,
-
序列標注與中文分詞
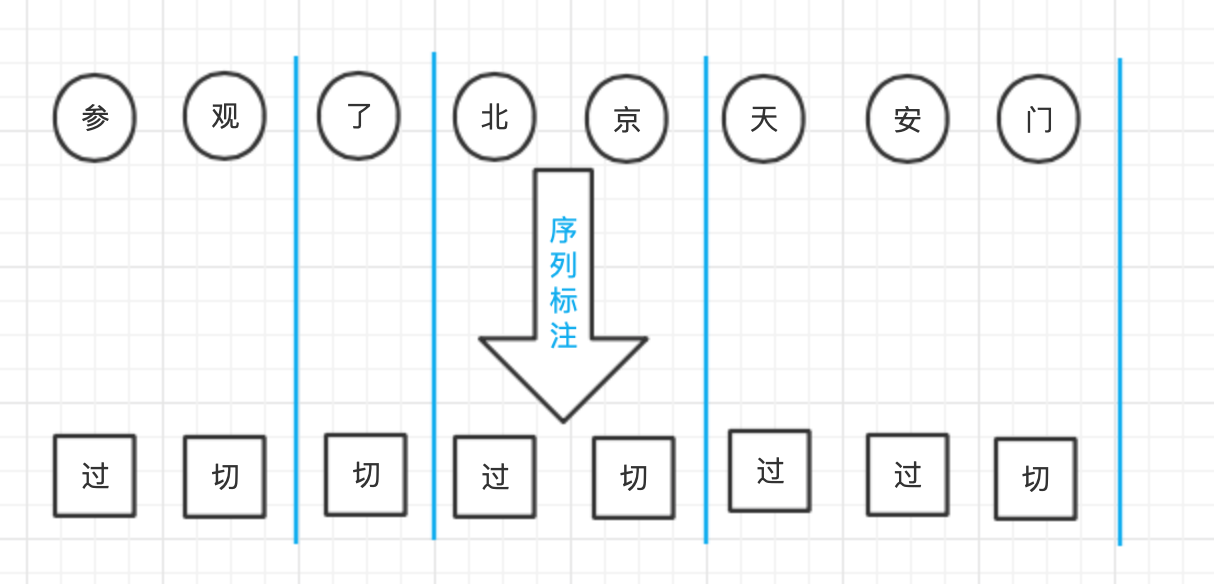
考慮一個字符序列(字串) x,想象切詞器真的是在拿刀切割字串,如此,中文分詞轉化為標注集{切,過}的序列標注問題,
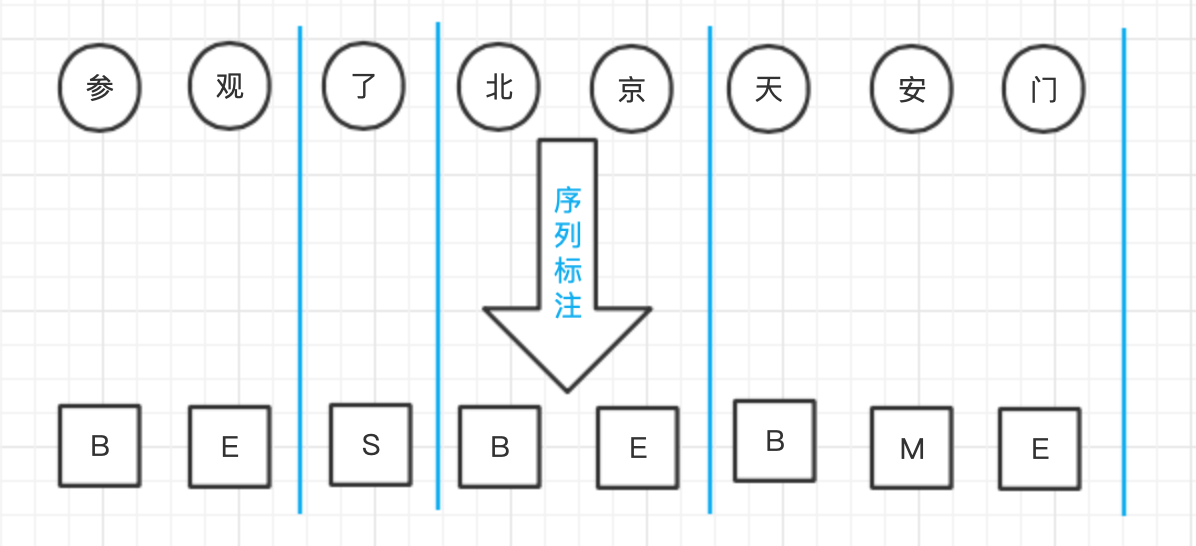
分詞標注集并非只有一種,為了捕捉漢字分別作為詞語收尾(Begin、End)、詞中(Middle)以及單字成詞(Single)時不同的成詞概率,人們提出了{B,M,E,S}這種最流行的標注集,
-
序列標注與詞性標注
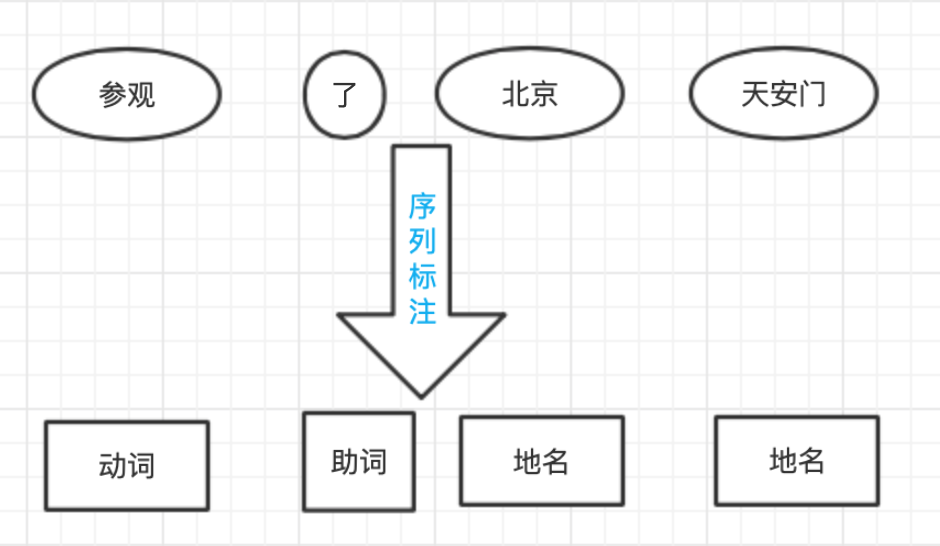
詞性標注任務是一個天然的序列標注問題:x 是單詞序列,y 是相應的詞性序列,需要綜合考慮前后的單詞與詞性才能決定當前單詞的詞性,
-
序列標注與命名物體識別
所謂命名物體,指的是現實存在的物體,比如人名、地名和機構名,命名物體是 OOV 的主要組成部分,
考慮到字符級別中文分詞和詞語級別命名物體識別有著類似的特點,都是組合短單位形成長單位的問題,所以命名物體識別可以復用BMES標注集,并沿用中文分詞的邏輯,只不過標注的物件由字符變為單詞而已,唯一不同的是,命名物體識別還需要確定物體所屬的類別,這個額外的要求依然是個標注問題,可以通過將命名物體類別附著到BMES標簽來達到目的,比如,構成地名的單詞標注為“B/M/E/S-地名”,以此類推,對于那些不構成命名物體的單詞,則統-標注為O ( Outside), 即復合詞之外,
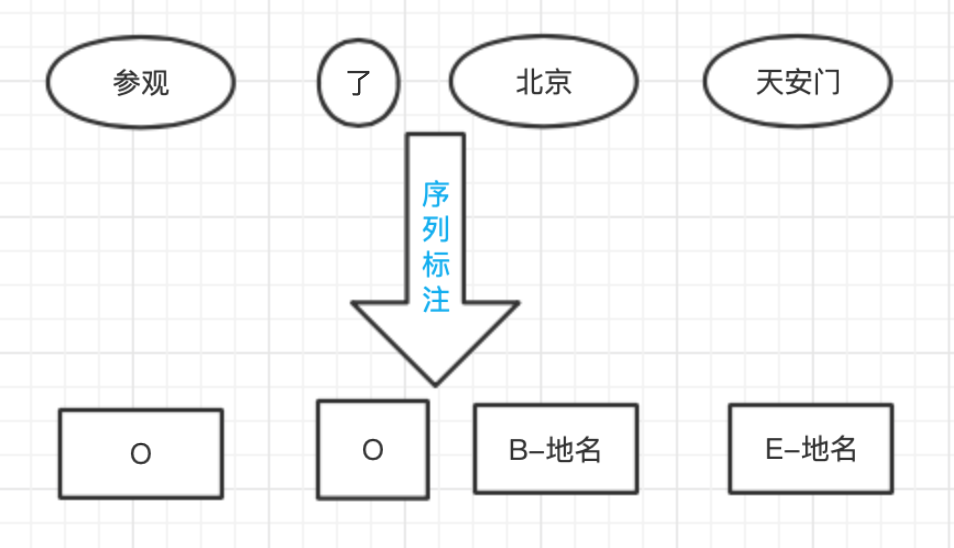
總之,序列標注問題是NLP中最常見的問題之一,許多應用任務都可以變換思路,轉化為序列標注來解決,所以一個準確的序列標注模型非常重要,直接關系到NLP系統的準確率,機器學習領域為NLP提供了許多標注模型,本著循序漸進的原則,本章介紹其中最基礎的一個隱馬爾可夫模型,
4.2 隱馬爾可夫模型
隱馬爾可夫模型( Hidden Markov Model, HMM)是描述兩個時序序列聯合分布 p(x,y) 的概率模型: x 序列外界可見(外界指的是觀測者),稱為觀測序列(obsevation sequence); y 序列外界不可見,稱為狀態序列(state sequence),比如觀測 x 為單詞,狀態 y 為詞性,我們需要根據單詞序列去猜測它們的詞性,隱馬爾可夫模型之所以稱為“隱”,是因為從外界來看,狀
態序列(例如詞性)隱藏不可見,是待求的因變數,從這個角度來講,人們也稱狀態為隱狀態(hidden state),而稱觀測為顯狀態( visible state),隱馬爾可夫模型之所以稱為“馬爾可夫模型”,”是因為它滿足馬爾可夫假設,
-
從馬爾可夫假設到隱馬爾可夫模型
馬爾可夫假設:每個事件的發生概率只取決于前一個事件,
馬爾可夫鏈:將滿足馬爾可夫假設的連續多個事件串聯起來,就構成了馬爾可夫鏈,
如果把事件具象為單詞,那么馬爾可夫模型就具象為二元語法模型,
隱馬爾可夫模型:它的馬爾可夫假設作用于狀態序列,
假設 ① 當前狀態 Yt 僅僅依賴于前一個狀態 Yt-1, 連續多個狀態構成隱馬爾可夫鏈 y,有了隱馬爾可夫鏈,如何與觀測序列 x 建立聯系呢?
隱馬爾可夫模型做了第二個假設: ② 任意時刻的觀測 x 只依賴于該時刻的狀態 Yt,與其他時刻的狀態或觀測獨立無關,如果用箭頭表示事件的依賴關系(箭頭終點是結果,依賴于起點的因緣),則隱馬爾可夫模型可以表示為下圖所示
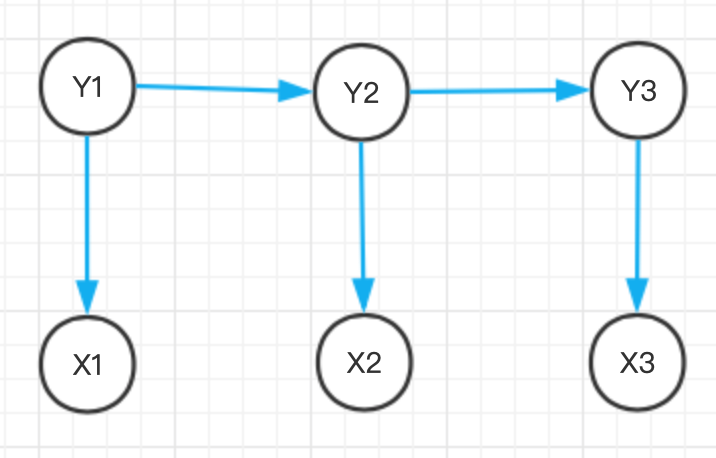
狀態與觀測之間的依賴關系確定之后,隱馬爾可夫模型利用三個要素來模擬時序序列的發生程序----即初始狀態概率向量、狀態轉移概率矩陣和發射概率矩陣,
-
初始狀態概率向量
系統啟動時進入的第一個狀態 Y1 稱為初始狀態,假設 y 有 N 種可能的取值,那么 Y1 就是一個獨立的離散型隨機變數,由 P(y1 | π) 描述,其中
\[\pi=\left(\pi_{1}, \cdots, \pi_{N}\right)^{\mathrm{T}}, 0 \leqslant \pi_{i} \leqslant 1, \sum_{i=1}^{N} \pi_{i}=1 \]
是概率分布的引數向量,稱為初始狀態概率向量,
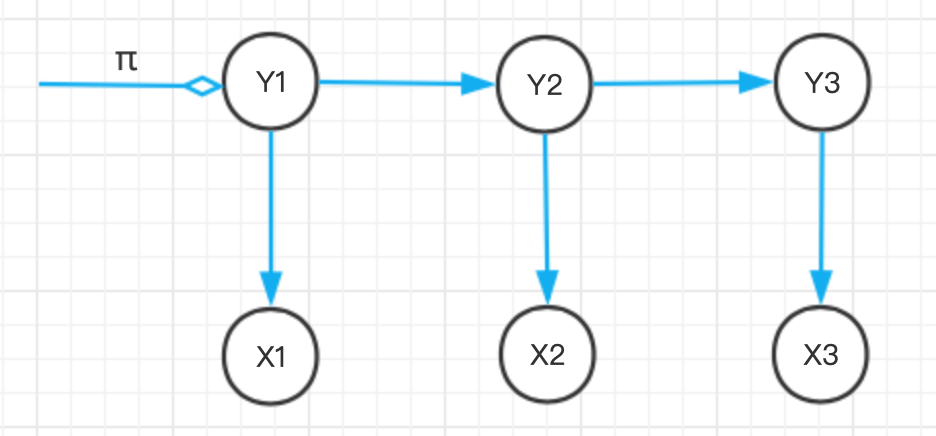
給定 π ,初始狀態 Y1 的取值分布就確定了,比如采用{B,M,E,S}標注集時概率如下:
\[p(y_1=B)=0.7\\ p(y_1=M)=0\\ p(y_1=E)=0\\ p(y_1=S)=0.3 \]
那么此時隱馬爾可夫模型的初始狀態概率向量為 π=[0.7,0,0,0.3],注意,句子第一個詞是單字的可能性要小一些,
-
狀態轉移矩陣
Yt 如何轉移到 Yt+1 呢?根據馬爾可夫假設,t+1 時的狀態僅僅取決于 t 時的狀態,既然一共有 N 種狀態,那么從狀態 Si 到狀態 Sj 的概率就構成了一個 N*N 的方陣,稱為狀態轉移矩陣 A:
\[A=\left[p\left(y_{t+1}=s_{j} | y_{t}=s_{i}\right)\right]_{N \times N} \]
其中下標 i、j 分別表示狀態的第 i、j 種取值,狀態轉移概率的存在有其實際意義,在中文分詞中,標簽 B 的后面不可能是 S,于是就有 P(Yt+1 = S | Yt = B) = 0,同樣,詞性標注中的“形容詞->名詞”“副詞->動詞”也可通過狀態轉移概率來模擬,這些概率分布引數不需要手動設定,而是通過語料庫上的統計自動學習,
-
發射概率矩陣
有了狀態 Yt 之后,如何確定觀測 Xt 的概率分布呢?根據隱馬爾可夫假設②,當前觀測 Xt 僅僅取決于當前狀態 Yt,也就是說,給定每種 y,x 都是一個獨立的離散型隨機變數,其引數對應一個向量, 假設觀測 x 一共有 M 種可能的取值,則 x 的概率分布引數向量維度為 M,由于 y 共有 N 種,所以這些引數向量構成了 N*M 的矩陣,稱為發射概率矩陣B,
\(\boldsymbol{B}=\left[p\left(x_{t}=o_{i} | y_{t}=s_{j}\right)\right]_{N \times M}\)
其中,第 i 行 j 列的元素下標 i 和 j 分別代表觀測和狀態的第 i 種和第 j 種取值,
-
隱馬爾可夫模型的三個基本用法
-
樣本生成問題:給定模型,如何有效計算產生觀測序列的概率?換言之,如何評估模型與觀測序列之間的匹配程度?
-
序列預測問題:給定模型和觀測序列,如何找到與此觀測序列最匹配的狀態序列?換言之,如何根據觀測序列推斷出隱藏的模型狀態?
-
模型訓練問題:給定觀測序列,如何調整模型引數使得該序列出現的概率最大?換言之,如何訓練模型使其能最好地描述觀測資料?
前兩個問題是模式識別的問題:1) 根據隱馬爾科夫模型得到一個可觀察狀態序列的概率(評價);2) 找到一個隱藏狀態的序列使得這個序列產生一個可觀察狀態序列的概率最大(解碼),第三個問題就是根據一個可以觀察到的狀態序列集產生一個隱馬爾科夫模型(學習),
-
4.3 隱馬爾可夫模型的訓練
-
案例假設和模型構造
設想如下案例:某醫院招標開發“智能”醫療診斷系統,用來輔助感冒診斷,已知①來診者只有兩種狀態:要么健康,要么發燒,②來診者不確定自己到底是哪種狀態,只能回答感覺頭暈、體寒或正常,醫院認為,③感冒這種病,只跟病人前一天的狀態有關,并且,④當天的病情決定當天的身體感覺,有位來診者的病歷卡上完整地記錄了最近 T 天的身體感受(頭暈、體寒或正常),請預測這 T 天的身體狀態(健康或發燒),由于醫療資料屬于機密隱私,醫院無法提供訓練資料,但根據醫生經驗,感冒發病的規律如下圖所示(箭頭上的數值表示概率):
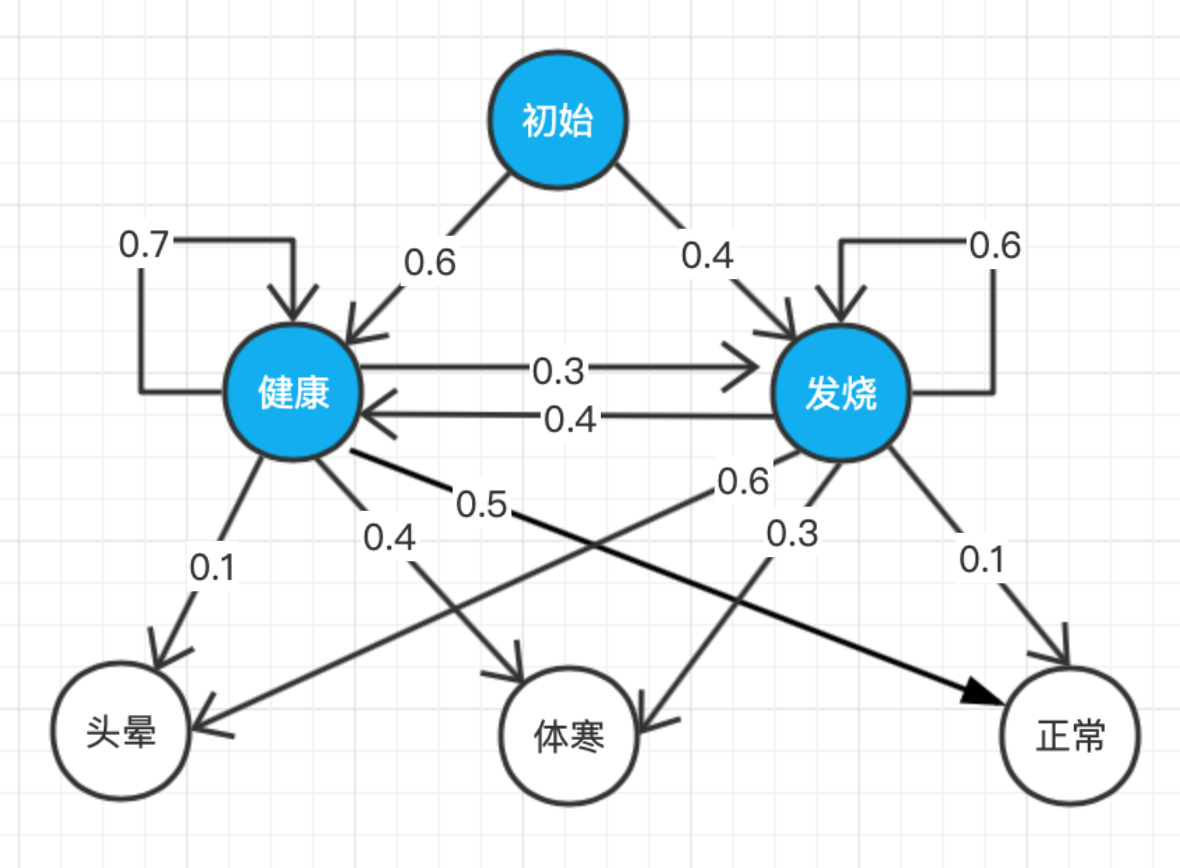
根據已知條件①②,病情狀態(健康、發燒)可作為隱馬爾可夫模型的隱狀態(上圖藍色狀態),而身體感受(頭暈、體寒或正常)可作為隱馬爾可夫模型的顯狀態(圖中白色狀態),條件③符合隱馬爾可夫模型假設一,條件④符 合隱馬爾可夫模型假設二,這個案例其實描述了一個隱馬爾可夫模型, 并且引數已經給定,構造模型代碼見:
import numpy as np from pyhanlp import * from jpype import JArray, JFloat, JInt to_str = JClass('java.util.Arrays').toString ## 隱馬爾可夫模型描述 states = ('Healthy', 'Fever') start_probability = {'Healthy': 0.6, 'Fever': 0.4} transition_probability = { 'Healthy': {'Healthy': 0.7, 'Fever': 0.3}, 'Fever': {'Healthy': 0.4, 'Fever': 0.6}, } emission_probability = { 'Healthy': {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1}, 'Fever': {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6}, } observations = ('normal', 'cold', 'dizzy') def generate_index_map(lables): index_label = {} label_index = {} i = 0 for l in lables: index_label[i] = l label_index[l] = i i += 1 return label_index, index_label states_label_index, states_index_label = generate_index_map(states) observations_label_index, observations_index_label = generate_index_map(observations) def convert_map_to_matrix(map, label_index1, label_index2): m = np.empty((len(label_index1), len(label_index2)), dtype=float) for line in map: for col in map[line]: m[label_index1[line]][label_index2[col]] = map[line][col] return JArray(JFloat, m.ndim)(m.tolist()) def convert_observations_to_index(observations, label_index): list = [] for o in observations: list.append(label_index[o]) return list def convert_map_to_vector(map, label_index): v = np.empty(len(map), dtype=float) for e in map: v[label_index[e]] = map[e] return JArray(JFloat, v.ndim)(v.tolist()) # 將numpy陣列轉為Java陣列 ## pi:初始狀態概率向量 ## A:狀態轉移概率矩陣 ## B:發射概率矩陣 A = convert_map_to_matrix(transition_probability, states_label_index, states_label_index) B = convert_map_to_matrix(emission_probability, states_label_index, observations_label_index) observations_index = convert_observations_to_index(observations, observations_label_index) pi = convert_map_to_vector(start_probability, states_label_index) FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel') given_model = FirstOrderHiddenMarkovModel(pi, A, B) -
樣本生成演算法
它的生成程序就是沿著隱馬爾可夫鏈走 T 步:
- 根據初始狀態概率向量采樣第一個時刻的狀態 Y1 = Si,即 Y1 ~ π,
- Yt 采樣結束得到 Si 后,根據狀態轉移概率矩s陣第 i 行的概率向量,采樣下一時刻的狀態 Yt+1,
- 對每個 Yt = Si,根據發射概率矩陣的第 i 行采樣 Xt,
- 重復步驟 2 共計 T-1 次,重復步驟 3 共計 T 次,輸出序列 x 與 y,
代碼如下(接上),直接通過模型進行生成:
## 第一個引數:序列最低長度 ## 第二個引數:序列最高長度 ## 第三個引數:需要生成的樣本數 for O, S in given_model.generate(3, 5, 2): print(" ".join((observations_index_label[o] + '/' + states_index_label[s]) for o, s in zip(O, S))) -
隱馬爾可夫模型的訓練
樣本生成后,我們就可以利用生成的資料重新訓練,通過極大似然法來估計隱馬爾可夫模型的引數,引數指的是三元組(π,A,B),
利用給定的隱馬爾可夫模型 P生成十萬個樣本,在這十萬個樣本上訓練新模型Q,比較新舊模型引數是否一致,
trained_model = FirstOrderHiddenMarkovModel() ## 第一個引數:序列最低長度 ## 第二個引數:序列最高長度 ## 第三個引數:需要生成的樣本數 trained_model.train(given_model.generate(3, 10, 100000)) print('新模型與舊模型是否相同:', trained_model.similar(given_model))輸出:
新模型與舊模型是否相同: True運行后一般都成立,由于亂數,僅有小概率發生失敗,
4.4 隱馬爾可夫模型的預測
隱馬爾可夫模型最具實際意義的問題當屬序列標注了:給定觀測序列,求解最可能的狀態序列及其概率,
-
概率計算的前向演算法
給定觀測序列 x 和一個狀態序列 y,就可以估計兩者的聯合概率 P(x,y),聯合概率就是一種結果的概率,在這些結果當中找到最大的聯合概率就是找到最有可能的結果預測,聯合概率:P(x,y) = P(y) P(x|y),下面我們來分別求出P(y)和P(x|y)
-
順著隱馬爾可夫鏈走,首先 t=1 時初始狀態沒有前驅狀態,發生概率由 π 決定:
\[P(y_1=s_i)=\pi_i \]
-
接著對 t >= 2,狀態 Yt 由前驅狀態 Yt-1 轉移而來,轉移矩陣由矩陣 A 決定:
\[P(y_t=s_j|y_{t-1}=s_i)=A_{i,j} \]
所以狀態序列的概率為上面式子的乘積:
\[p(y)=p\left(y_{1}, \cdots, y_{r}\right)=p\left(y_{1}\right) \prod_{i=2}^{T} p\left(y_{i} | y_{i-1}\right) \]
-
P(y) 我們已經求出來了,下面要求 P(x|y)
對于每個 Yt = Si,都會“發射”一個 Xt = Oj,發射概率由矩陣 B 決定:
\[P(x_t=O_j|y_t=s_i)=B_{i,j} \]
-
那么給定一個狀態序列 Y,對應的 X 的概率累積形式:
\[p(x | y)=\prod_{t=1}^{T} p\left(x_{t} | y_{t}\right) \]
-
最后帶入聯合概率公式得:
\[\begin{aligned} p(x, y) &=p(y) p(x | y) \\ &=p\left(y_{1}\right) \prod_{t=2}^{T} p\left(y_{t} | y_{t-1}\right) \prod_{t=1}^{T} p\left(x_{t} | y_{t}\right) \end{aligned} \]
將其中的每個 Xt、Yt 對應上實際發生序列的 Si、Oj,就能帶入(π,A,B)中的相應元素,從而計算出任意序列的概率,最后找出這些概率的最大值就得到預測結果,找出概率最大值要用到維特比演算法,
-
-
搜索狀態序列的維特比演算法
理解了前向演算法之后,找尋最大概率所對應的狀態序列無非是一個搜索問題,具體說來,將每個狀態作為有向圖中的一個節點, 節點間的距離由轉移概率決定,節點本身的花費由發射概率決定,那么所有備選狀態構成一幅有 向無環圖,待求的概率最大的狀態序列就是圖中的最長路徑,此時的搜索演算法稱為維特比演算法,如圖下圖所示:
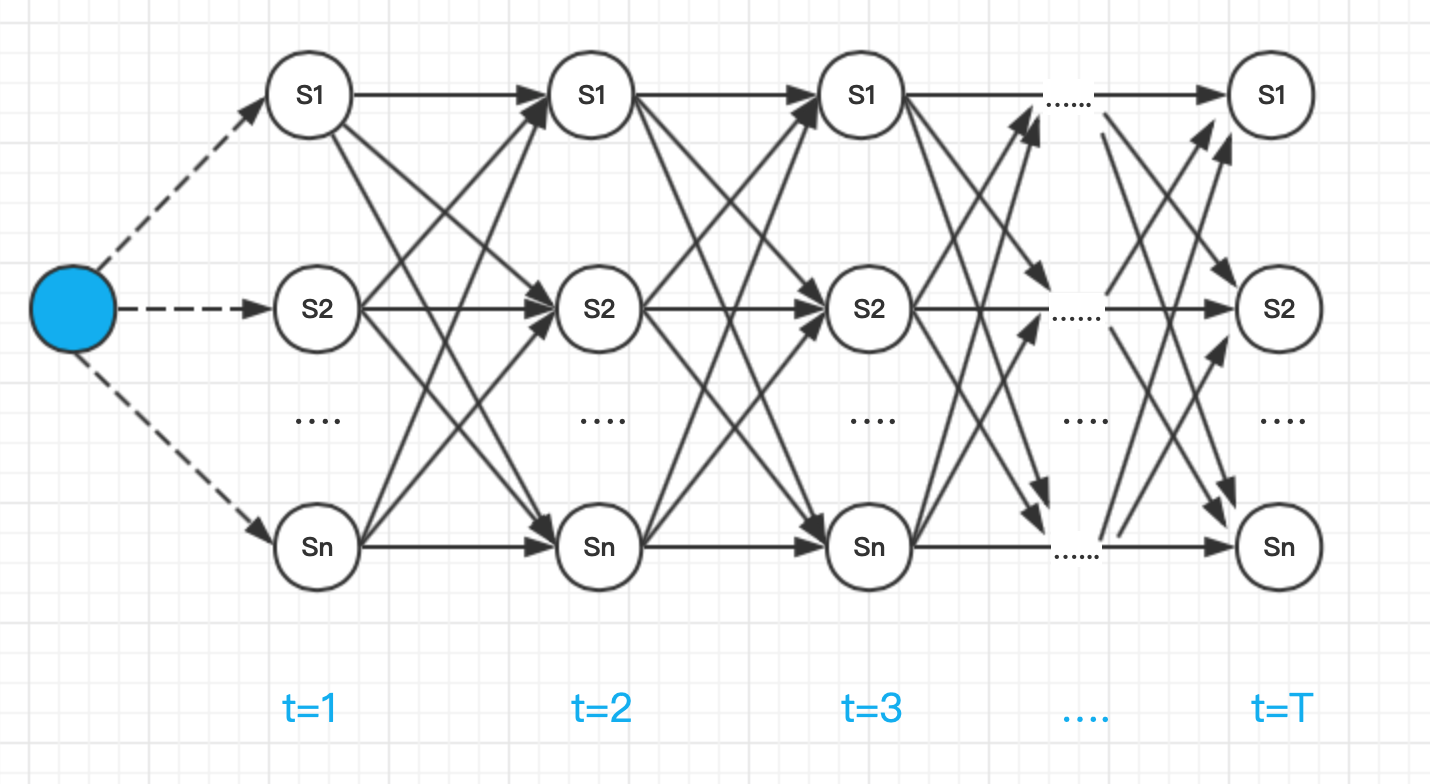
上圖從左往右時序遞增,虛線由初始狀態概率決定,實線則是轉移概率,由于受到觀測序列的約束,不同狀態發射觀測的概率不同,所以每個節點本身也必須計算自己的花費,由發射概率決定,又由于 Yt+1 僅依賴于 Yt,所以網狀圖可以動態規劃的搜索,也就是維特比演算法:
-
初始化,t=1 時初始最優路徑的備選由 N 個狀態組成,它們的前驅為空,
\[\begin{aligned} \delta_{1, i}=\pi_{i} \boldsymbol{B}_{i, o_{1}}, & i=1, \cdots, N \\ \psi_{1, i}=0, & i=1, \cdots, N \end{aligned} \]
其中,δ 存盤在時刻 t 以 Si 結尾的所有區域路徑的最大概率,ψ 存盤區域最優路徑末狀態 Yt 的前驅狀態,
-
遞推,t >= 2 時每條備選路徑像貪吃蛇一樣吃入一個新狀態,長度增加一個單位,根據轉移概率和發射概率計算花費,找出新的區域最優路徑,更新 δ、ψ 兩個陣列,
\[\begin{array}{ll} {\delta_{t, i}=\max _{1 \leqslant j \leqslant N}\left(\delta_{t-1, j} A_{j, i}\right) B_{i, o_{t}},} & {i=1, \cdots, N} \\ {\psi_{t, i}=\arg \max _{1 \leqslant j \leqslant N}\left(\delta_{t-1, j} A_{j, i}\right),} & {i=1, \cdots, N} \end{array} \]
-
終止,找出最終時刻 δt,i 陣列中的最大概率 P*,以及相應的結尾狀態下標 i*t,
\[\begin{aligned} &p^{*}=\max _{1 \leqslant i \leqslant N} \delta_{T, i}\\ &i_{T}^{*}=\arg \max _{1 \leqslant i \leqslant N} \delta_{T, i} \end{aligned} \]
-
回溯,根據前驅陣列 ψ 回溯前驅狀態,取得最優路徑狀態下標,
\[i_{t}^{*}=\psi_{t+1, i_{t+1}}, \quad t=T-1, T-2, \cdots, 1 \]
預測代碼如下(接上面代碼):
pred = JArray(JInt, 1)([0, 0, 0]) prob = given_model.predict(observations_index, pred) print(" ".join((observations_index_label[o] + '/' + states_index_label[s]) for o, s in zip(observations_index, pred)) + " {:.3f}".format(np.math.exp(prob)))輸出為:
normal/Healthy cold/Healthy dizzy/Fever 0.015觀察該結果,“/”隔開觀測和狀態,最后的 0.015 是序列的聯合概率,
-
4.5 隱馬爾可夫模型應用于中文分詞
HanLP 已經實作了基于隱馬爾可夫模型的中文分詞器 HMMSegmenter,并且實作了訓練介面,代碼詳見:
hmm_cws.py:https://github.com/NLP-LOVE/Introduction-NLP/tree/master/code/ch04/hmm_cws.py
4.6 性能評測
如果隱馬爾可夫模型中每個狀態僅依賴于前一個狀態, 則稱為一階;如果依賴于前兩個狀態,則稱為二階,既然一階隱馬爾可夫模型過于簡單,是否可以切換到二階來提高分數呢?
答案是可以的,跟一階類似,這里不再詳細介紹二階隱馬爾可夫模型,詳細請看原書,
這里我們使用 MSR語料庫進行評測,結果如下表所示:
| 演算法 | P | R | F1 | R(oov) | R(IV) |
|---|---|---|---|---|---|
| 最長匹配 | 89.41 | 94.64 | 91.95 | 2.58 | 97.14 |
| 二元語法 | 92.38 | 96.70 | 94.49 | 2.58 | 99.26 |
| 一階HHM | 78.49 | 80.38 | 79.42 | 41.11 | 81.44 |
| 二階HHM | 78.34 | 80.01 | 79.16 | 42.06 | 81.04 |
可以看到,二階隱馬爾可夫模型的 Roov 有少許提升,但綜合 F1 反而下降了,這說明增加隱馬爾可夫模型的階數并不能提高分詞器的準確率,單靠提高轉移概率矩陣的復雜度并不能提高模型的擬合能力,我們需要從別的方面想辦法,目前市面上一些開源分詞器仍然停留在一階隱馬爾可夫模型的水平,比如著名的結巴分詞,它們的準確率也只能達到80%左右,
4.7 總結
這一章我們想解決的問題是新詞識別,為此從詞語級模型切換到字符級模型,將中文分詞任務轉換為序列標注問題,作為新手起步,我們嘗試了最簡單的序列標注模型----隱馬爾可夫模型,隱馬爾可夫模型的基本問題有三個:樣本生成、引數估計、序列預測,
然而隱馬爾可夫模型用于中文分詞的效果并不理想,雖然召回了一半的 OOV,但綜合 F1 甚至低于詞典分詞,哪怕升級到二階隱馬爾可夫模型, F1 值依然沒有提升, 看來樸素的隱馬爾可夫模型不適合中文分詞,我們需要更高級的模型,
話說回來,隱馬爾可夫模型作為入門模型,比較容易上手,同時也是許多高級模型的基礎,打好基礎,我們才能挑戰高級模型,
4.8 GitHub專案
HanLP何晗--《自然語言處理入門》筆記:
https://github.com/NLP-LOVE/Introduction-NLP
專案持續更新中......
目錄
| 章節 |
|---|
| 第 1 章:新手上路 |
| 第 2 章:詞典分詞 |
| 第 3 章:二元語法與中文分詞 |
| 第 4 章:隱馬爾可夫模型與序列標注 |
| 第 5 章:感知機分類與序列標注 |
| 第 6 章:條件隨機場與序列標注 |
| 第 7 章:詞性標注 |
| 第 8 章:命名物體識別 |
| 第 9 章:資訊抽取 |
| 第 10 章:文本聚類 |
| 第 11 章:文本分類 |
| 第 12 章:依存句法分析 |
| 第 13 章:深度學習與自然語言處理 |
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/51664.html
標籤:其他
上一篇:PCA技術的自我理解(催眠