查找
【知識框架】

1.查找概論
查找的基本概念:
查找(Searching):就是根據給定的某個值,在查找表中確定一個其關鍵字等于給定值的資料元素( 或記錄),
查找表(Search Table):是由同一型別的資料元素(或記錄)構成的集合,
關鍵字(Key):資料元素中唯一標識該元素的某個資料項的值,使用基于關鍵字的查找,查找結果應該是唯一的,例如,在由一個學生元素構成的資料集合中,學生元素中“學號”這一資料項的值唯一地標識一名學生,
靜態查找表(Static Search Table):只作查找操作的查找表,
主要操作:
- 查詢某個“特定的”資料元素是否在查找表中,
- 檢索某個“特定的”資料元素和各種屬性,
動態查找表(Dynamic Search Table): 在查找程序中同時插入查找表中不存在的資料元素,或者從查找表中洗掉已經存在的某個資料元素,
主要操作:
- 查找時插入不存在的資料元素,
- 查找時洗掉已存在的資料元素,
平均查找長度:在查找程序中,一次查找的長度是指需要比較的關鍵字次數,而平均查找長度,則是所有查找程序中進行關鍵字的比較次數的平均值,
2.順序表查找
一、定義:
順序查找(Sequential Search) 又叫線性查找,是最基本的查找技術,作為一種最直觀的查找方法,其基本思想是從線性表的一端開始,逐個檢查關鍵字是否滿足給定的條件,若查找到某個元素的關鍵字滿足給定條件,則查找成功,回傳該元素在線性表中的位置;若已經查找到表的另一端,但還沒有查找到符合給定條件的元素,則回傳查找失敗的資訊,
二、演算法:
python實作演算法:
import time
import numpy as np
def Sequential_Search(arr, n, key):
"""
:param arr:待查元素所在陣列
:param n:在arr的前n位里查找
:param key:待查元素
:return:回傳待查元素位置或者提示資訊
"""
if 0 <= n <= len(arr):
for i in range(n):
if arr[i] == key:
return i
return "沒有查到此記錄"
return "對不起,n值不合法"
if __name__ == '__main__':
arr = np.arange(100000)
begin = time.time()
res = Sequential_Search(arr, len(arr), 88888)
end = time.time()
print(res)
print(f"耗時:{end - begin}")
運行結果:
88888
耗時:0.015154361724853516
時間復雜度分析:順序表查找時間復雜度是O(n)
3.有序表查找
(1)折半查找
折半查找(Binary Search)技術,又稱為二分查找,它的前提是線性表中的記錄必須是關鍵碼有序(通常從小到大有序),線性表必須采用順序存盤,折半查找的基本思想是:在有序表中,取中間記錄作為比較物件,若給定值與中間記錄的關鍵字相等,則查找成功;若給定值小于中間記錄的關鍵字,則在中間記錄的左半區繼續查找;若給定值大于中間記錄的關鍵字,則在中間記錄的右半區繼續查找,不斷重復上述程序,直到查找成功,或所有查找區域無記錄,查找失敗為止,
python代碼實作:
import time
def Binary_Search(arr, n, key):
"""
:param arr:待查元素所在陣列
:param n:在arr的前n位里查找
:param key:待查元素
:return:回傳待查元素位置或者提示資訊
"""
if 0 <= n <= len(arr): # 判斷查找范圍是否越界
low = 0 # 定義最低下標為記錄首位
high = n - 1 # 定義最高下標為記錄末位
while low <= high:
mid = (low + high) // 2 # 折半
if arr[mid] > key: # 若查找值比中值小
high = mid - 1 # 最高下標調整到中位下標小一位
elif arr[mid] < key: # 若查找值比中值大
low = mid + 1 # 最低下標調整到中位下標大一位
else:
return mid # 若相等則說明mid即為查找到的位置
return "沒有此元素"
return "n值不合法"
if __name__ == '__main__':
arr = range(1, 100000000000, 3)
res = None # 用來存盤返結果
begin = time.time() # 查找函式開始時的時間戳
for i in range(100000): # 查找多次以便求平均查找時間,如果只查早一次的話會因為耗時很短,結果為耗時0
res = Binary_Search(arr, len(arr), 4)
end = time.time() # 查找函式結束時的時間戳
print(res)
print(f"耗時:{(end - begin) / 100000}") # 列印平均耗時
運行結果:
1
耗時:7.2002077102661135e-06
時間復雜度分析:折半查找時間復雜度是O(logn)
(2)插值查找
現在我們的新問題是,為什么一定要折半,而不是折四分之一或者折更多呢?
比如要在取值范圍0 ~ 10000之間100個元素從小到大均勻分布的陣列中查找5,我們自然會考慮從陣列下標較小的開始查找,
所以,折半查找還是有改善空間的,
上述折半查找代碼的第4行,等式變換后可得到:
mid = (low + high) // 2 = l o w + ( h i g h ? l o w ) // 2
也就是mid等于最低下標low加上最高下標high與low的差的一半,接下來改進為下面的計算方案:
mid = low + ((key - arr[low]) // (arr[high] - arr[low])) * (high - low)
就得到了另一種有序表查找演算法,插值查找法,插值查找(Interpolation Search) 是根據要查找的關鍵字key與查找表中最大最小記錄的關鍵字比較后的查找方法,其核心就在于插值的計算公式,應該說,從時間復雜度來看,它也是O(logn),但對于表長較大,而關鍵字分布又比較均勻的查找表來說,插值查找演算法的平均性能比折半查找要好得多,反之,陣列中如果分布類似{0,1,2,2000,2001,......,999998, 99999}這種極端不均勻的資料,用插值查找未必是很合適的選擇,
python代碼實作:
import time
def Interpolation_Search(arr, n, key):
"""
:param arr:待查元素所在陣列
:param n:在arr的前n位里查找
:param key:待查元素
:return:回傳待查元素位置或者提示資訊
"""
if 0 <= n <= len(arr): # 判斷查找范圍是否越界
low = 0 # 定義最低下標為記錄首位
high = n - 1 # 定義最高下標為記錄末位
while low <= high:
mid = low + ((key - arr[low]) // (arr[high] - arr[low])) * (high - low) # 插值
if arr[mid] > key: # 若查找值比中值小
high = mid - 1 # 最高下標調整到中位下標小一位
elif arr[mid] < key: # 若查找值比中值大
low = mid + 1 # 最低下標調整到中位下標大一位
else:
return mid # 若相等則說明mid即為查找到的位置
return "沒有此元素"
return "n值不合法"
if __name__ == '__main__':
arr = range(1, 100000000000, 3)
res = None # 用來存盤返結果
begin = time.time() # 查找函式開始時的時間戳
for i in range(100000): # 查找多次以便求平均查找時間,如果只查早一次的話會因為耗時很短,結果為耗時0
res = Interpolation_Search(arr, len(arr), 4)
end = time.time() # 查找函式結束時的時間戳
print(res)
print(f"耗時:{(end - begin) / 100000}") # 列印平均耗時
運行結果:
1
耗時:1.3898181915283203e-06
從結果來看,二分查找的平均查找時間是插值查找的好幾倍,
(3)斐波那契查找
斐波那契查找(Fibonacci Search),它是利用了黃金分割原理來實作的,
我們先定義一個斐波那契陣列F:

python代碼實作:
import time
def Fibonacci_Search(arr, n, key, F):
"""
:param arr:待查元素所在陣列
:param n:在arr的前n位里查找
:param key:待查元素
:return:回傳待查元素位置或者提示資訊
"""
if 0 <= n <= len(arr): # 判斷查找范圍是否越界
low = 0 # 定義最低下標為記錄首位
high = n - 1 # 定義最高下標為記錄末位
k = 0
while n > F[k] - 1:
k += 1
for i in range(n, F[k] - 1):
arr.append(None)
arr[i] = arr[n - 1]
while low <= high:
mid = low + F[k - 1] - 1
if key < arr[mid]:
high = mid + 1
k -= 1
elif key > arr[mid]:
low = mid + 1
k -= 2
else:
if mid <= n:
return mid
else:
return n
return "沒有查到此元素"
return "n值不合法"
if __name__ == '__main__':
arr = [0, 1, 16, 24, 35, 47, 59, 62, 73, 88, 99]
res = None # 用來存盤返結果
F = [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55] # 部分斐波那契數列
begin = time.time() # 查找函式開始時的時間戳
for i in range(100000): # 查找多次以便求平均查找時間,如果只查早一次的話會因為耗時很短,結果為耗時0
res = Fibonacci_Search(arr, len(arr), 59, F)
end = time.time() # 查找函式結束時的時間戳
print(f"斐波那契查找結果為:{res}\n耗時:{(end - begin) / 100000}") # 列印平均耗時
運行結果:
斐波那契查找結果為:6
耗時:1.3396072387695312e-06
時間復雜度分析:O(logn)
斐波那契查找演算法的核心在于:
- 當key=a[mid]時,查找就成功;
- 當key<a[mid]時,新范圍是第low個到第mid-1個,此時范圍個數為F[k-1]-1個;
- 當key>a[mid]時,新范圍是第m+1個到第high個,此時范圍個數為F[k-2]-1個,

(4)線性索引查找
現實生活中計算機要處理的資料量是極其龐大的,而資料結構的最終目的是提高資料的處理速度,索引是為了加快查找速度而設計的一種資料結構,索引就是把一個關鍵字與它對應的記錄相關聯的程序, 一個索引由若干個索引項構成,每個索引項至少應包含關鍵字和其對應的記錄在存盤器中的位置等資訊,索引技術是組織大型資料庫以及磁盤檔案的一種重要技術,
索引按照結構可以分為線性索引、樹形索引和多級索引,
這里主要介紹線性索引,所謂線性索引就是將索引項集合組織為線性結構,也稱為索引表,我們重點介紹三種線性索引:稠密索引、分塊索引和倒排索引,
一、稠密索引
稠密索引是很簡單直白的一種索引結構,
稠密索引是指在線性索引中,將資料集中的每個記錄對應一個索引項,而索引項一定是按照關鍵碼有序的排列,如下圖所示:

索引項有序也就意味著,我們要查找關鍵字時,可以用到折半、插值、斐波那契等有序查找演算法,提高了效率,這是稠密索引優點,但是如果資料集非常大,比如上億,那也就意味著索引也得同樣的資料集長度規模,對于記憶體有限的計算機來說,可能就需要反復去訪問磁盤,查找性能反而大大下降了,
二、分塊索引
稠密索引因為索引項與資料集的記錄個數相同,所以空間代價很大,為了減少索引項的個數,我們可以對資料集進行分塊,使其分塊有序,然后再對每一塊建立一個索引項,從而減少索引項的個數,
分塊有序,是把資料集的記錄分成了若千塊,并且這些塊需要滿足兩個條件:
塊內無序:即每一塊內的記錄不要求有序,
塊間有序:例如,要求第二塊所有記錄的關鍵字均要大于第一塊中所有記錄的關鍵字,第三塊的所有記錄的關鍵字均要大于第二塊的所有記錄關鍵字…因為只有塊間有序,才有可能在查找時帶來效率,
對于分塊有序的資料集,將每塊對應一個索引項, 這種索引方法叫做分塊索引,如下圖所示,我們定義的分塊索引的索引項結構分三個資料項:
最大關鍵碼:它存盤每一塊中的最大關鍵字,這樣的好處就是可以使得在它之后的下一塊中的最小關鍵字也能比這一塊最大的關鍵字要大;
塊長:存盤了塊中的記錄個數,以便于回圈時使用;
塊首指標:用于指向塊首資料元素的指標,便于開始對這一塊中記錄進行遍歷,

在分塊索引表中查找,就是分兩步進行:
- 在分塊索引表中查找要查關鍵字所在的塊,由于分塊索引表是塊間有序的,因此很容易利用折半、插值等演算法得到結果,例如,在上圖的資料集中查找62 6262,我們可以很快可以從左上角的索引表中由57 < 62 < 96得到62在第三個塊中,
- 根據塊首指標找到相應的塊,并在塊中順序查找關鍵碼,
三、倒排索引
搜索引擎中涉及很多搜索技術,這里介紹一種最簡單,也是最基礎的搜索技術:倒排索引,
我們舉個簡單的例子:
假如下面兩篇極短的文章,
- Books and friends should be few but good.
- A good book is a good friend.
忽略字母大小寫,我們統計出每個單詞出現在哪篇文章之中:文章1、文章2、文章(1,2),得到下面這個表,并對單詞做了排序:

有了這樣一張單詞表,我們要搜索文章,就非常方便了,如果你在搜索框中填寫“book"關鍵字,系統就先在這張單詞表中有序查找“book" ,找到后將它對應的文章編號1和2的文章地址回傳,
在這里這張單詞表就是索引表,索引項的通用結構是:
- 次關鍵碼,例如上面的“英文單詞”;
- 記錄號表,例如上面的“文章編號",
其中記錄號表存盤具有相同次關鍵字的所有記錄的記錄號(可以是指向記錄的指標或者是該記錄的主關鍵字),這樣的索引方法就是倒排索引(inverted index) ,
這名字為什么要叫做“倒排索引”呢?
顧名思義,倒排索引源于實際應用中需要根據屬性(或欄位、次關鍵碼)的值來查找記錄(或主關鍵編碼),這種索引表中的每一項都包括一個屬性值和具有該屬性值的各記錄的地址,由于不是由記錄來確定屬性值,而是由屬性值來確定記錄的位置,因而稱為倒排索引,
4.動態查找表
(1)二叉排序樹
二叉排序樹(也稱二叉查找樹)或者是一棵空樹,或者是具有下列特性的二叉樹:
若左子樹非空,則左子樹上所有結點的值均小于根結點的值,
若右子樹非空,則右子樹上所有結點的值均大于根結點的值,
左、右子樹也分別是一棵二叉排序樹,
根據二叉排序樹的定義,左子樹結點值<根結點值<右子樹結點值,所以對二叉排序樹進行中序遍歷,可以得到一個遞增的有序序列,例如,下圖所示二叉排序樹的中序遍歷序列為123468,
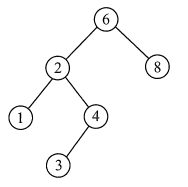
python代碼實作:
class Node:
"""節點類"""
def __init__(self, data):
self.data = https://www.cnblogs.com/minqiliang/archive/2022/11/05/data
self.lchild = None
self.rchild = None
class BST:"""二叉查找樹"""
def __init__(self, node_list):
self.root = Node(node_list[0]) # 設定樹的根為串列第一位
for data in node_list[1:]: # 依次把串列中除了第一位的其他所有元素插入到樹中
self.insert(data)
# 搜索
def search(self, T, p, key):
"""
:param T: 要搜索的樹的根節點
:param p: 當前節點的雙親節點
:param key: 要收索的鍵或元素
:return: (布林值:代表是否查到,T:當前查到的節點,p:查到的節點的雙親,用于確定所查元素的位置)
"""
if not T: # 查找不成功
return False, T, p
if T.data =https://www.cnblogs.com/minqiliang/archive/2022/11/05/= key: # 查找成功
return True, T, p
if T.data > key:
return self.search(T.lchild, T, key) # 在左子樹中繼續查找
else:
return self.search(T.rchild, T, key) # 在右子樹中繼續查找
# 插入
def insert(self, key):"""
:param key: 要插入的元素或鍵"
:return: True:插入成功 False:插入失敗
"""""
flag, n, p = self.search(self.root, None, key)
if not flag: # 當前要插入的鍵不存在
new_node = Node(key)
if key > p.data:
p.rchild = new_node # 插入到p的右孩子節點
return True
else:
p.lchild = new_node # 插入到p的左孩子節點
return True
else:
return False
# 洗掉
def delete(self, root, key):
"""
:param root: 要洗掉的鍵所在的樹的根
:param data: 要洗掉的鍵或節點
:return:
"""
flag, n, p = self.search(root, root, key)
if not flag: # 要洗掉的節點不存在
print("無該關鍵字,洗掉失敗")
else:
if n.lchild is None: # 如果要洗掉的節點只有右孩子
if n == p.lchild:
p.lchild = n.rchild
else:
p.rchild = n.rchild
elif n.rchild is None: # 如果要洗掉的節點只有左孩子
if n == p.lchild:
p.lchild = n.lchild
else:
p.rchild = n.lchild
else: # 左右子樹均不為空
pre = n.rchild # 這里找要洗掉節點的后繼,所以要在右子樹中找,所以讓pre指向待刪節點的右子樹
if pre.lchild is None: # 如果為None說明pre就是待刪節點的后繼
n.data = https://www.cnblogs.com/minqiliang/archive/2022/11/05/pre.data # 令把后繼的資料賦值給待刪節點
n.rchild = pre.rchild # 待刪節點的后繼賦值為待刪節點的后繼的右孩子
else:
next = pre.lchild
while next.lchild: # 一直查左孩子,最后查到的即為待刪節點的中序遍歷的后繼
pre = next
next = next.lchild
n.data = next.data
pre.lchild = next.rchild
# 中序遍歷
def inOrderTraverse(self, node):
if node:
self.inOrderTraverse(node.lchild)
print(node.data, end=" ")
self.inOrderTraverse(node.rchild)
if __name__ == '__main__':
a = [49, 38, 65, 97, 60, 76, 13, 27, 5, 1]
bst = BST(a) # 創建二叉查找樹
bst.inOrderTraverse(bst.root) # 中序遍歷
print()
# 插入 88 66 0
bst.insert(88)
bst.insert(66)
bst.insert(0)
bst.inOrderTraverse(bst.root) # 中序遍歷
print()
bst.delete(bst.root, 49) # 洗掉49
bst.inOrderTraverse(bst.root) # 中序遍歷
isFind, T, p = bst.search(bst.root, None, 88, )
print(f"\n查找結果為{isFind},它的雙親節點為{p.data}")
程式運行結果:
1 5 13 27 38 49 60 65 76 97
0 1 5 13 27 38 49 60 65 66 76 88 97
0 1 5 13 27 38 60 65 66 76 88 97
查找結果為True,它的雙親節點為76
性能分析:
二叉排序樹的優點明顯,插入洗掉的時間性能比較好,而對于二叉排序樹的查找,走的就是從根結點到要查找的結點的路徑,其比較次數等于給定值的結點在二叉排序樹的層數,極端情況,最少為1次,即根結點就是要找的結點,最多也不會超過樹的深度,也就是說,二叉排序樹的查找性能取決于二叉排序樹的形狀,可問題就在于,二叉排序樹的形狀是不確定的,
例如{ 62 , 88 , 58 , 47 , 35 , 73 , 51 , 99 , 37 , 93 }這樣的陣列,我們可以構建如下左圖的二叉排序樹,但如果陣列元素的次序是從小到大有序,如{35,37,47,51,58,62,73,88,93,99},則二叉排序樹就成了極端的右斜樹,如下面右圖的二叉排序樹:
也就是說,我們希望二叉排序樹是比較平衡的,即其深度與完全二叉樹相同,那么查找的時間復雜也就是O(logn),近似于折半查找,
不平衡的最壞情況就是像上面右圖的斜樹,查找時間復雜度為O ( n ),這等同于順序查找,
因此,如果我們希望對一個集合按二叉排序樹查找,最好是把它構建成一棵平衡的二叉排序樹,

(2)平衡二叉樹
平衡二叉樹(Self-Balancing Binary Search Tree 或 Height-Balanced Binary Search Tree)是一種二叉排序樹,其中每一個節點的左子樹和右子樹的高度差至多等于1,
它是一種高度平衡的二叉排序樹,它要么是一棵空樹, 要么它的左子樹和右子樹都是平衡二叉樹,且左子樹和右子樹的深度之差的絕對值不超過1,我們將二叉樹上結點的左子樹深度減去右子樹深度的值稱為平衡因子BF (Balance Factor) , 那么平衡二叉樹上所有結點的平衡因子只可能是-1、0和1,只要二叉樹上有一個結點的平衡因子的絕對值大于1,則該二叉樹就是不平衡的,
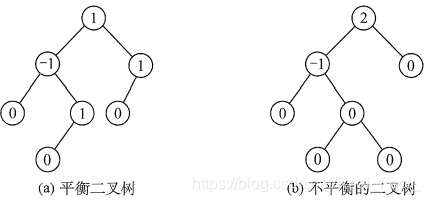
平衡二叉樹的插入程序的前半部分與二叉排序樹相同,但在新結點插入后,若造成查找路徑上的某個結點不再平衡,則需要做出相應的調整,可將調整的規律歸納為下列4種情況:
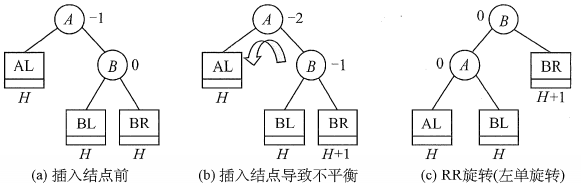
- LL平衡旋轉(右單旋轉),由于在結點A的左孩子(L)的左子樹(L)上插入了新結點,A的平衡因子由1增至2,導致以A為根的子樹失去平衡,需要一次向右的旋轉操作,將A的左孩子B向右上旋轉代替A成為根結點,將A結點向右下旋轉成為B的右子樹的根結點,而B的原右子樹則作為A結點的左子樹,如下圖所示,結點旁的數值代表結點的平衡因子,而用方塊表示相應結點的子樹,下方數值代表該子樹的高度,

- RR平衡旋轉(左單旋轉),由于在結點A的右孩子?的右子樹?上插入了 新結點,A的平衡因子由-1減至-2,導致以A為根的子樹失去平衡,需要一次向左的旋轉操作,將A的右孩子B向左上旋轉代替A成為根結點,將A結點向左下旋轉成為B的左子樹的根結點,而B的原左子樹則作為A結點的右子樹,
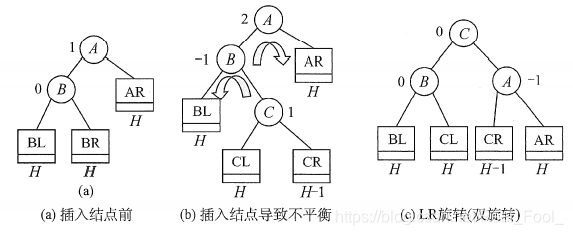
- LR平衡旋轉(先左后右雙旋轉),由于在A的左孩子(L)的右子樹?上插入新結點,A的平衡因子由1增至2,導致以A為根的子樹失去平衡,需要進行兩次旋轉操作,先左旋轉后右旋轉,先將A結點的左孩子B的右子樹的根結點C向左上旋轉提升到B結點的位置(即進行一次RR平衡旋轉(左單旋轉)),然后再把該C結點向右上旋轉提升到A結點的位置(即進行一次LL平衡旋轉(右單旋轉)),
- RL平衡旋轉(先右后左雙旋轉),由于在A的右孩子?的左子樹(L)上插入新結點,A的平衡因子由-1減至-2,導致以A為根的子樹失去平衡,需要進行兩次旋轉操作,先右旋轉后左旋轉,先將A結點的右孩子B的左子樹的根結點C向右上旋轉提升到B結點的位置(即進行一次LL平衡旋轉(右單旋轉)),然后再把該C結點向左上旋轉提升到A結點的位置(即進行一次RR平衡旋轉(左單旋轉)),
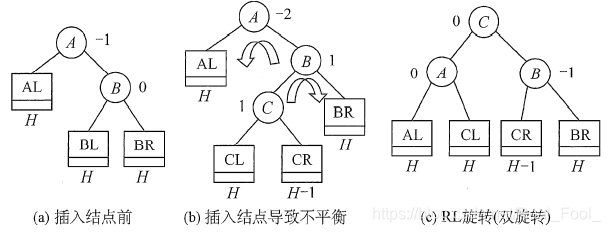
注意: LR和RL旋轉時,新結點究竟是插入C的左子樹還是插入C的右子樹不影響旋轉程序,而上圖中是以插入C的左子樹中為例,
舉個例子:
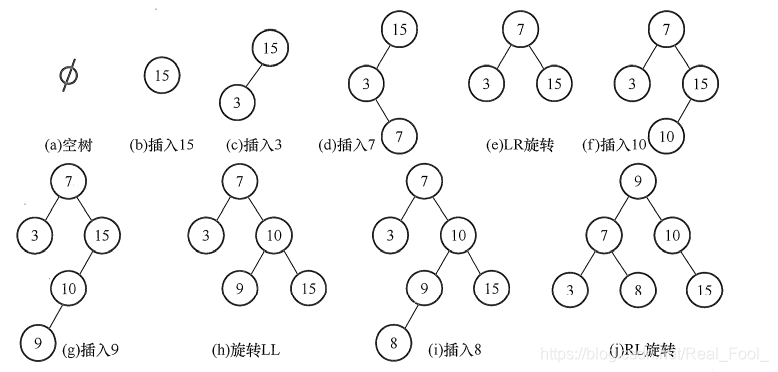
假設關鍵字序列為15 , 3 , 7 , 10 , 9 , 8 {15,3, 7, 10, 9, 8}15,3,7,10,9,8,通過該序列生成平衡二叉樹的程序如下圖所示,
c語言代碼實作:
#include "stdio.h"
#include "stdlib.h"
#include "math.h"
#include "time.h"
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
#define MAXSIZE 100 /* 存盤空間初始分配量 */
typedef int Status; /* Status是函式的型別,其值是函式結果狀態代碼,如OK等 */
/* 二叉樹的二叉鏈表結點結構定義 */
typedef struct BiTNode /* 結點結構 */
{
int data; /* 結點資料 */
int bf; /* 結點的平衡因子 */
struct BiTNode *lchild, *rchild; /* 左右孩子指標 */
} BiTNode, *BiTree;
/* 對以p為根的二叉排序樹作右旋處理, */
/* 處理之后p指向新的樹根結點,即旋轉處理之前的左子樹的根結點 */
void R_Rotate(BiTree *P)
{
BiTree L;
L=(*P)->lchild; /* L指向P的左子樹根結點 */
(*P)->lchild=L->rchild; /* L的右子樹掛接為P的左子樹 */
L->rchild=(*P);
*P=L; /* P指向新的根結點 */
}
/* 對以P為根的二叉排序樹作左旋處理, */
/* 處理之后P指向新的樹根結點,即旋轉處理之前的右子樹的根結點0 */
void L_Rotate(BiTree *P)
{
BiTree R;
R=(*P)->rchild; /* R指向P的右子樹根結點 */
(*P)->rchild=R->lchild; /* R的左子樹掛接為P的右子樹 */
R->lchild=(*P);
*P=R; /* P指向新的根結點 */
}
#define LH +1 /* 左高 */
#define EH 0 /* 等高 */
#define RH -1 /* 右高 */
/* 對以指標T所指結點為根的二叉樹作左平衡旋轉處理 */
/* 本演算法結束時,指標T指向新的根結點 */
void LeftBalance(BiTree *T)
{
BiTree L,Lr;
L=(*T)->lchild; /* L指向T的左子樹根結點 */
switch(L->bf)
{ /* 檢查T的左子樹的平衡度,并作相應平衡處理 */
case LH: /* 新結點插入在T的左孩子的左子樹上,要作單右旋處理 */
(*T)->bf=L->bf=EH;
R_Rotate(T);
break;
case RH: /* 新結點插入在T的左孩子的右子樹上,要作雙旋處理 */
Lr=L->rchild; /* Lr指向T的左孩子的右子樹根 */
switch(Lr->bf)
{ /* 修改T及其左孩子的平衡因子 */
case LH: (*T)->bf=RH;
L->bf=EH;
break;
case EH: (*T)->bf=L->bf=EH;
break;
case RH: (*T)->bf=EH;
L->bf=LH;
break;
}
Lr->bf=EH;
L_Rotate(&(*T)->lchild); /* 對T的左子樹作左旋平衡處理 */
R_Rotate(T); /* 對T作右旋平衡處理 */
}
}
/* 對以指標T所指結點為根的二叉樹作右平衡旋轉處理, */
/* 本演算法結束時,指標T指向新的根結點 */
void RightBalance(BiTree *T)
{
BiTree R,Rl;
R=(*T)->rchild; /* R指向T的右子樹根結點 */
switch(R->bf)
{ /* 檢查T的右子樹的平衡度,并作相應平衡處理 */
case RH: /* 新結點插入在T的右孩子的右子樹上,要作單左旋處理 */
(*T)->bf=R->bf=EH;
L_Rotate(T);
break;
case LH: /* 新結點插入在T的右孩子的左子樹上,要作雙旋處理 */
Rl=R->lchild; /* Rl指向T的右孩子的左子樹根 */
switch(Rl->bf)
{ /* 修改T及其右孩子的平衡因子 */
case RH: (*T)->bf=LH;
R->bf=EH;
break;
case EH: (*T)->bf=R->bf=EH;
break;
case LH: (*T)->bf=EH;
R->bf=RH;
break;
}
Rl->bf=EH;
R_Rotate(&(*T)->rchild); /* 對T的右子樹作右旋平衡處理 */
L_Rotate(T); /* 對T作左旋平衡處理 */
}
}
/* 若在平衡的二叉排序樹T中不存在和e有相同關鍵字的結點,則插入一個 */
/* 資料元素為e的新結點,并回傳1,否則回傳0,若因插入而使二叉排序樹 */
/* 失去平衡,則作平衡旋轉處理,布爾變數taller反映T長高與否, */
Status InsertAVL(BiTree *T,int e,Status *taller)
{
if(!*T)
{ /* 插入新結點,樹“長高”,置taller為TRUE */
*T=(BiTree)malloc(sizeof(BiTNode));
(*T)->data=https://www.cnblogs.com/minqiliang/archive/2022/11/05/e; (*T)->lchild=(*T)->rchild=NULL; (*T)->bf=EH;
*taller=TRUE;
}
else
{
if (e==(*T)->data)
{ /* 樹中已存在和e有相同關鍵字的結點則不再插入 */
*taller=FALSE; return FALSE;
}
if (e<(*T)->data)
{ /* 應繼續在T的左子樹中進行搜索 */
if(!InsertAVL(&(*T)->lchild,e,taller)) /* 未插入 */
return FALSE;
if(*taller) /* 已插入到T的左子樹中且左子樹“長高” */
switch((*T)->bf) /* 檢查T的平衡度 */
{
case LH: /* 原本左子樹比右子樹高,需要作左平衡處理 */
LeftBalance(T); *taller=FALSE; break;
case EH: /* 原本左、右子樹等高,現因左子樹增高而使樹增高 */
(*T)->bf=LH; *taller=TRUE; break;
case RH: /* 原本右子樹比左子樹高,現左、右子樹等高 */
(*T)->bf=EH; *taller=FALSE; break;
}
}
else
{ /* 應繼續在T的右子樹中進行搜索 */
if(!InsertAVL(&(*T)->rchild,e,taller)) /* 未插入 */
return FALSE;
if(*taller) /* 已插入到T的右子樹且右子樹“長高” */
switch((*T)->bf) /* 檢查T的平衡度 */
{
case LH: /* 原本左子樹比右子樹高,現左、右子樹等高 */
(*T)->bf=EH; *taller=FALSE; break;
case EH: /* 原本左、右子樹等高,現因右子樹增高而使樹增高 */
(*T)->bf=RH; *taller=TRUE; break;
case RH: /* 原本右子樹比左子樹高,需要作右平衡處理 */
RightBalance(T); *taller=FALSE; break;
}
}
}
return TRUE;
}
int main(void)
{
int i;
int a[10]={3,2,1,4,5,6,7,10,9,8};
BiTree T=NULL;
Status taller;
for(i=0;i<10;i++)
{
InsertAVL(&T,a[i],&taller);
}
printf("本樣例建議斷點跟蹤查看平衡二叉樹結構");
return 0;
}
(3)多路查找樹
多路查找樹(muitl-way search tree), 其每一個結點的孩子數可以多于兩個,且每一個結點處可以存盤多個元素,由于它是查找樹,所有元素之間存在某種特定的排序關系,
在這里,每一個結點可以存盤多少個元素,以及它的孩子數的多少是非常關鍵的,常見的有4種特殊形式:2-3樹、2-3-4樹、B樹和B+樹,這里主要介紹B樹和B+樹,因為2-3樹、2-3-4樹都是B樹的特例,
如下圖所示是一顆2-3樹:

一、B樹
B樹,又稱多路平衡查找樹,B樹中所有結點的孩子個數的最大值稱為B樹的階,通常用m 表示,一棵m 階B樹或為空樹,或為滿足如下特性的m叉樹:
- 樹中每個結點至多有m mm棵子樹,即至多含有m ? 1 m-1m?1個關鍵字,
- 若根結點不是終端結點,則至少有兩棵子樹,
- 除根結點外的所有非葉結點至少有? m / 2 ? 棵子樹,即至少含有? m / 2 ? ? 1 個關鍵字,
- 所有非葉結點的結構如下:
5.所有的葉結點都出現在同一層次上,并且不帶資訊(可以視為外部結點或類似于折半查找判定樹的查找失敗結點,實際上這些結點不存在,指向這些結點的指標為空),

B樹是所有結點的平衡因子均等于0的多路平衡查找樹,
下圖所示的B樹中所有結點的最大孩子數m = 5 ,因此它是一棵5階B樹,在m 階B樹中結點最多可以有m 個孩子,可以借助該實體來分析上述性質:
- 結點的孩子個數等于該結點中關鍵字個數加1(每一個空隙都存在一個分支),
- 如果根結點沒有關鍵字就沒有子樹,此時B樹為空;如果根結點有關鍵字,則其子樹必然大于等于兩棵,因為子樹個數等于關鍵字個數加1,
- 除根結點外的所有非終端結點至少有? m / 2 ? = ? 5 / 2 ? = 3 棵子樹(即至少有? m / 2 ? ? 1 = ? 5 / 2 ? ? 1 = 2 個關鍵字),至多有5棵子樹(即至多有4個關鍵字),
- 結點中關鍵字從左到右遞增有序,關鍵字兩側均有指向子樹的指標,左邊指標所指子樹的所有關鍵字均小于該關鍵字,右邊指標所指子樹的所有關鍵字均大于該關鍵字,或者看成下層結點關鍵字總是落在由上層結點關鍵字所劃分的區間內,如第二層最左結點的關鍵字劃分成了3個區間:( ? ∞ , 5 ) , ( 5 , 11 ) , ( 11 , + ∞ ) ,該結點3個指標所指子樹的關鍵字均落在這3個區間內,
- 所有葉結點均在第4層,代表查找失敗的位置,

B樹與磁盤存取:
B樹中的大部分操作所需的磁盤存取次數與B樹的高度成正比,
我們的外存,比如硬碟, 是將所有的資訊分割成相等大小的頁面,每次硬碟讀寫的都是一個或多個完整的頁面,對于一個硬碟來說,一頁的長度可能是211到214個位元組,
在一個典型的B樹應用中,要處理的硬碟資料量很大,因此無法一次全部裝入記憶體,因此我們會對B樹進行調整,使得B樹的階數(或結點的元素)與硬碟存盤的頁面大小相匹配,比如說一棵B樹的階為1001 (即1個結點包含1000個關鍵字),高度為2,它可以儲存超過10億個關鍵字,我們只要讓根結點持久地保留在記憶體中,那么在這棵樹上,尋找某一個關鍵字至多需要兩次硬碟的讀取即可,
通過這種方式,在有限記憶體的情況下,每一次磁盤的訪問我們都可以獲得最大數量的資料,由于B樹每結點可以具有比二叉樹多得多的元素,所以與二叉樹的操作不同,它們減少了必須訪問結點和資料塊的數量,從而提高了性能,可以說,B樹的資料結構就是為內外存的資料互動準備的,
B樹的查找:
在B樹上進行查找與二叉查找樹很相似,只是每個結點都是多個關鍵字的有序表,在每個結點上所做的不是兩路分支決定,而是根據該結點的子樹所做的多路分支決定,
B樹的查找包含兩個基本操作:①在B樹中找結點;②在結點內找關鍵字,由于B樹常存盤在磁盤上,因此前一個查找操作是在磁盤上進行的,而后一個查找操作是在記憶體中進行的,即在找到目標結點后,先將結點資訊讀入記憶體,然后在結點內采用順序查找法或折半查找法,
在B樹上查找到某個結點后,先在有序表中進行查找,若找到則查找成功,否則按照對應的指標資訊到所指的子樹中去查找,
例如,在上圖中查找關鍵字42 ,首先從根結點開始,根結點只有一個關鍵字,且42 > 22 ,若存在,必在關鍵字22 的右邊子樹上,右孩子結點有兩個關鍵字,而36 < 42 < 45 ,則若存在,必在36 和45 中間的子樹上,在該子結點中查到關鍵字42 ,查找成功,若查找到葉結點時(對應指標為空指標),則說明樹中沒有對應的關鍵字,查找失敗,

B樹的插入:
與二叉查找樹的插入操作相比,B樹的插入操作要復雜得多,在二叉査找樹中,僅需査找到需插入的終端結點的位置,但是,在B樹中找到插入的位置后,并不能簡單地將其添加到終端結點中,因為此時可能會導致整棵樹不再滿足B樹定義中的要求,將關鍵字key插入B樹的程序如下:
- 定位,利用前述的B樹査找演算法,找出插入該關鍵字的最低層中的某個非葉結點(在B樹中查找key時,會找到表示查找失敗的葉結點,這樣就確定了最底層非葉結點的插入位置,注意:插入位置一定是最低層中的某個非葉結點),
- 插入,在B樹中,每個非失敗結點的關鍵字個數都在區間[? m / 2 ? ? 1,m-1] 內,插入后的結點關鍵字個數小于m ,可以直接插入;插入后檢查被插入結點內關鍵字的個數,當插入后的結點關鍵字個數大于m ? 1時,必須對結點進行分裂,
分裂的方法是:取一個新結點,在插入key后的原結點,從中間位置? m / 2 ? 將其中的關鍵字分為兩部分,左部分包含的關鍵字放在原結點中,右部分包含的關鍵字放到新結點中,中間位置? m / 2 ? 的結點插入原結點的父結點,若此時導致其父結點的關鍵字個數也超過了上限,則繼續進行這種分裂操作,直至這個程序傳到根結點為止,進而導致B樹高度增1,對于m = 3的B樹,所有結點中最多有m ? 1 = 2 個關鍵字,若某結點中已有兩個關鍵字,則結點已滿,如下圖a所示,插入一個關鍵字60 后,結點內的關鍵字個數超過了m ? 1 ,如圖b所示,此時必須進行結點分裂,分裂的結果如圖c所示,

B樹的洗掉:
B樹中的洗掉操作與插入操作類似,但要更復雜一些,即要使得洗掉后的結點中的關鍵字個數≥ ? m / 2 ? ? 1 ,因此將涉及結點的“合并”問題,
-
當被刪關鍵字k kk不在終端結點(最低層非葉結點)中時,可以用k 的前驅(或后繼) k1來替替代k ,然后在相應的結點中洗掉k1,關鍵字k1必定落在某個終端結點中,則轉換成了被刪關鍵字在終端結點中的情形,在下圖的B樹中,洗掉關鍵字80,用其前驅78替代,然后在終端結點中洗掉78,因此只需討論洗掉終端結點中關鍵字的情形,

2.當被刪關鍵字在終端結點(最低層非葉結點)中時,有下列三種情況:
① 直接洗掉關鍵字,若被洗掉關鍵字所在結點的關鍵字個數≥ ? m / 2 ?,表明洗掉該關鍵字后仍滿足B樹的定義,則直接刪去該關鍵字,
② 兄弟夠借,若被洗掉關鍵字所在結點洗掉前的關鍵字個數= ? m / 2 ? ? 1,且與此結點相鄰的右(或左)兄弟結點的關鍵字個數≥ ? m / 2 ? ,則需要調整該結點、右(或左)兄弟結點及其雙親結點(父子換位法),以達到新的平衡,在圖(a)中洗掉B樹的關鍵字65 ,右兄弟關鍵字個數≥ ? m / 2 ? = 2 ,將71取代原65的位置,將74調整到71的位置,

③ 兄弟不夠借,若被洗掉關鍵字所在結點洗掉前的關鍵字個數= ? m / 2 ? ? 1 ,且此時與該結點相鄰的左、右兄弟結點的關鍵字個數均= ? m / 2 ? ? 1 ,則將關鍵字洗掉后與左(或右)兄弟結點及雙親結點中的關鍵字進行合并,在圖(b)中洗掉B樹的關鍵字5 ,它及其右兄弟結點的關鍵字個數= ? m / 2 ? ? 1 = 1 ,故在5洗掉后將60合并到65結點中,
在合并程序中,雙親結點中的關鍵字個數會減1,若其雙親結點是根結點且關鍵字個數減少至0(根結點關鍵字個數為1時,有2棵子樹),則直接將根結點洗掉,合并后的新結點成為根;若雙親結點不是根結點,且關鍵字個數減少到? m / 2 ? ? 2 ,則又要與它自己的兄弟結點進行調整或合并操作,并重復上述步驟,直至符合B樹的要求為止,
其實通俗點講,B樹的洗掉,洗掉結點無非就是多留少補的情況,多留不必多說;少補復雜點:當兄弟夠借時,就向左旋轉一次(即往左挪一個位置,重構根節點關鍵字的前驅和后繼);當兄弟不夠借時就拆根節點,合并到兄弟結點,合并拆分要始終保證B樹平衡,理清了就很容易理解,
二、B+樹
盡管B樹的諸多好處,但其實它還是有缺陷的,對于樹結構來說,我們都可以通過中序遍歷來順序查找樹中的元素,這一切都是在記憶體中進行,可是在B樹結構中,我們往返于每個結點之間也就意味著,我們必須得在硬碟的頁面之間進行多次訪問,
如上圖所示,我們希望遍歷這棵B樹,假設每個結點都屬于硬碟的不同頁面,我們中序遍歷所有的元素:
頁 面 2 → 頁 面 1 → 頁 面 3 → 頁 面 1 → 頁 面 4 → 頁 面 1 → 頁 面 5
而且我們每次經過結點遍歷時,都會對結點中的元素進行一次遍歷,這就非常糟糕,有沒有可能讓遍歷時每個元素只訪問一次呢?
B+樹來了,

定義:
B+樹是應檔案系統(比如資料庫)所需而出現的一種B樹的變形樹,
m階的B+樹與m階的B樹的主要差異如下:
- 有n棵子樹的結點中包含有n 個關鍵字;
- 所有的葉子結點包含全部關鍵字的資訊,及指向含這些關鍵字記錄的指標,葉子結點本身依關鍵字的大小自小而大順序鏈接;
- 所有分支結點可以看成是索引,結點中僅含有其子樹中的最大(或最小)關鍵字,
- 在B+樹中,每個結點(非根內部結點)的關鍵字個數n的范圍是? m / 2 ? ≤ n ≤ m (根結點:1 ≤ n ≤ m );在B樹中,每個結點(非根內部結點)的關鍵字個數n范圍是? m / 2 ? ? 1 ≤ n ≤ m ? 1 (根結點: 1 ≤ n ≤ m ? 1 ),
下圖所示為一棵4階B+樹:

B+樹的結構特別適合帶有范圍的查找,比如查找我們學校18~22歲的學生人數,我們可以通過從根結點出發找到第一個18歲的學生,然后再在葉子結點按順序查找到符合范圍的所有記錄,
B+樹的插入、洗掉程序也都與B樹類似,只不過插入和洗掉的元素都是在葉子結點上進行而已,

5.散串列查找(Hash Table)
(1) 散串列查找的基本概念
散串列是根據關鍵字而直接進行訪問的資料結構,也就是說,散串列建立了關鍵字和存盤地址之間的一種直接映射關系,我們只需要通過某個函式f,使得: 存 儲 位 置 = f ( 關 鍵 字 ) ,那樣我們可以通過查找關鍵字不需要比較就可獲得需要的記錄的存盤位置,
散列技術既是一種存盤方法, 也是一種查找方法,散列技術是在記錄的存盤位置和它的關鍵字之間建立一個確定的對應關系f,使得每個關鍵字key對應一個存盤位置f ( k e y ) ,查找時,根據這個確定的對應關系找到置上,
這里我們把這種對應關系f稱為散列函式,又稱為哈希(Hash) 函式,按這個思想,采用散列技術將記錄存盤在一塊連續的存盤空間中,這塊連續存盤空間稱為散串列或哈希表(Hash table),那么關鍵字對應的記錄存盤位置我們稱為散列地址,散列函式可能會把兩個或兩個以上的不同關鍵字映射到同一地址,稱這種情況為沖突,這些發生碰撞的不同關鍵字稱為同義詞,一方面,設計得好的散列函式應盡量減少這樣的沖突;另一方面,由于這樣的沖突總是不可避免的,所以還要設計好處理沖突的方法,
理想情況下,對散串列進行查找的時間復雜度為O(1),即與表中元素的個數無關,
(2) 散列函式的構造方法
在構造散列函式時,必須注意以下幾點:
散列函式的定義域必須包含全部需要存盤的關鍵字,而值域的范圍則依賴于散串列的大小或地址范圍,
散列函式計算出來的地址應該能等概率、均勻地分布在整個地址空間中,從而減少沖突的發生,
散列函式應盡量簡單,能夠在較短的時間內計算出任一關鍵字對應的散列地址,
下面介紹常用的散列函式:
1、直接定址法
直接取關鍵字的某個線性函式值為散列地址,散列函式為: H ( k e y ) = k e y 或 H ( k e y ) = a ? k e y + b ,式中,a和b是常數,這種方法計算最簡單,且不會產生沖突,它適合關鍵字的分布基本連續的情況,若關鍵字分布不連續,空位較多,則會造成存盤空間的浪費,
舉例:0~100歲的人口數字統計表,可以把年齡數值直接當做散列地址,2、數字分析法
例如當手機號碼為關鍵字時,其11位數字是有規則的,此時是無需把11位數值全部當做散列地址,這時我們給關鍵詞抽取, 抽取方法是使用關鍵字的一部分來計算散列存盤位置的方法,這在散列函式中是常常用到的手段,
數字分析法通常適合處理關鍵字位數比較大的情況,如果事先知道關鍵字的分布且關鍵字的若干位分布較均勻,就可以考慮用這個方法,這種方法適合于已知的關鍵字集合,若更換了關鍵字,則需要重新構造新的散列函式,3、平方取中法
這個方法計算很簡單,假設關鍵字是1234,那么它的平方就是1522756,再抽取中間的3位就是227,用做散列地址,再比如關鍵字是4321,那么它的平方就是18671041,抽取中間的3位就可以是671,也可以是710,用做散列地址,平方取中法比較適合于不知道關鍵字的分布,而位數又不是很大的情況,4、除留余數法
這是一種最簡單、最常用的方法,假定散串列表長為m,取一個不大于m但最接近或等于m的質數p,利用以下公式把關鍵字轉換成散列地址,散列函式為:
H ( k e y ) = k e y % p ( p < = m )
事實上,這方法不僅可以對關鍵字直接取模,也可在折疊、平方取中后再取模,
除留余數法的關鍵是選好p pp,使得每個關鍵字通過該函式轉換后等概率地映射到散列空間上的任一地址,從而盡可能減少沖突的可能性,5、亂數法
選擇一個亂數,取關鍵字的隨機函式值為它的散列地址,也就是
H ( k e y ) = r a n d o m ( k e y )
這里random是隨機函式,當關鍵字的長度不等時,采用這個方法構造散列函式是比較合適的,6、折疊法
把關鍵詞分割成位數相同的幾個部分,然后疊加
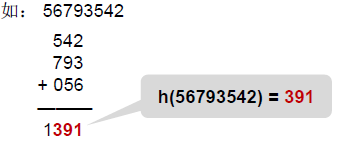
(3) 處理散列沖突
任何設計出來的散列函式都不可能絕對地避免沖突,為此,必須考慮在發生沖突時應該如何處理,即為產生沖突的關鍵字尋找下一個“空”的Hash地址,
用Hi表示處理沖突中第i次探測得到的散列地址,假設得到的另一個散列地址H1仍然發生沖突,只得繼續求下一個地址H2以此類推,直到Hk不發生沖突為止,則Hk為關鍵字在表中的地址,
1、開放定址法
所謂的開放定址法就是一旦發生了沖突,就去尋找下一個空的散列地址,只要散串列足夠大,空的散列地址總能找到,并將記錄存入,
它的公式是:
Hi( k e y ) = ( f ( k e y ) + di) % m ( di = 1 , 2 , 3 , . . . , m ? 1 )式中,Hi( k e y )為散列函式;i = 0 , 1 , 2 , . . . , k ( k < = m ? 1 );m表示散串列表長;di為增量序列,
取定某一增量序列后,對應的處理方法就是確定的,通常有以下4種取法:
線性探測法,當di = 0 , 1 , 2 , . . . , m ? 1時,稱為線性探測法,這種方法的特點是:沖突發生時,順序查看表中下一個單元(探測到表尾地址m ? 1時,下一個探測地址是表首地址0,直到找出一個空閑單元(當表未填滿時一定能找到一個空閑單元)或查遍全表,線性探測法可能使第i個散列地址的同義詞存入第i + 1個散列地址,這樣本應存入第i + 1個散列地址的元素就爭奪第i + 2個散列地址的元素的地址,從而造成大量元素在相鄰的散列地址上堆積,大大降低了查找效率,
平方探測法,當di= 02, 12 , ? 12, 22 , ? 22 , . . , k2 , ? k2 時,稱為平方探測法,其中k < m / 2,散串列長度m必須是一個可以表示成4 k + 3的素數,又稱二次探測法,
平方探測法是一種較好的處理沖突的方法,可以避免出現“堆積”問題,它的缺點是不能探測到散串列上的所有單元,但至少能探測到一半單元,再散列法,當di= Hash2 (key)時,稱為再散列法,又稱雙散列法,需要使用兩個散列函式,當通過第一個散列函式H ( k e y )得到的地址發生沖突時,則利用第二個散列函式Hash2(key) 計算該關鍵字的地址增量,它的具體散列函式形式如下:
Hi= ( H(key) + i ? Hash2(key)) % m
初始探測位置Hi= H(key),i是沖突的次數,初始為0,在再散列法中,最多經過m ? 1次探測就會遍歷表中所有位置,回到H0位置,偽隨機序列法,當di=偽亂數序列時,稱為偽隨機序列法,
注意:在開放定址的情形下,不能隨便物理洗掉表中的已有元素,因為若洗掉元素,則會截斷其他具有相同散列地址的元素的查找地址,因此,要洗掉一個元素時,可給它做一個洗掉標記,進行邏輯洗掉,但這樣做的副作用是:執行多次洗掉后,表面上看起來散串列很滿,實際上有許多位置未利用,因此需要定期維護散串列,要把洗掉標記的元素物理洗掉,
2、鏈地址法(拉鏈法)
不換地方,轉換一下思路,為什么非得有沖突就要換地方呢,如果不換地方該怎么處理?于是我們就有了鏈地址法,
將所有關鍵字為同義詞的記錄存盤在一個單鏈表中,我們稱這種表為同義詞子表,在散串列中只存盤所有同義詞子表的頭指標,
例如,關鍵字序列為{ 12 , 67 , 56 , 16 , 25 , 37 , 22 , 29 , 15 , 47 , 48 , 34 } ,我們用除留余數法構造散列函式H( k e y ) = k e y % 12 ,用拉鏈法處理沖突,建立的表如下圖所示,

3、公共溢位區法
這個方法其實就更加好理解,就是把凡是沖突的家伙額外找個公共場所待著,我們為所有沖突的關鍵字建立了一個公共的溢位區來存放,
就前面的例子而言,我們共有三個關鍵字37 , 48 , 34與之前的關鍵字位置有沖突,那么就將它們存盤到溢位表中,如下圖所示,

如果相對于基本表而言,有沖突的資料很少的情況下,公共溢位區的結構對查找性能來說還是非常高的,
(4) 演算法實作
class HashTable():
def __init__(self, hashsize):
"""
初始化哈希表
:param hashsize:哈希表的規模
"""
self.m = hashsize # 哈希表長
self.count = self.m # 當前資料元素個數
self.elem = [None for _ in range(self.m)] # 資料元素存盤基址,動態分配陣列
print("哈希表初始化已完成!")
def Hash(self, key):
"""散列函式"""
return key % self.m # 除留余數法
def InsertHash(self, key):
"""哈希表的插入操作"""
addr = self.Hash(key) # 求哈希地址
while self.elem[addr]: # 說明沖突了
addr = (addr + 1) % self.m # 開放定址法的線性探測
self.elem[addr] = key # 直到有空位后插入關鍵字
def SearchHash(self, key):
"""搜索關鍵字"""
addr = self.Hash(key) # 求哈希地址
while self.elem[addr] != key: # 說明沖突了
addr = (addr + 1) % self.m # 開放定址法的線性探測
if not self.elem[addr] or addr == self.Hash(key): # 如果回圈到原點,則說明關鍵字不存在
return "UNSUCCESSS"
return "您搜索的關鍵字地址為:{}".format(addr)
if __name__ == '__main__':
li = [12, 67, 56, 16, 25, 37, 22, 29, 15, 47, 48, 34]
H = HashTable(len(li))
for key in li:
H.InsertHash(key)
print(H.elem)
res = H.SearchHash(12)
print(res)
結果:
哈希表初始化已完成!
[12, 25, 37, 15, 16, 29, 48, 67, 56, 34, 22, 47]
您搜索的關鍵字地址為:0
從散串列的查找程序可見:
- 雖然散串列在關鍵字與記錄的存盤位置之間建立了直接映像,但由于“沖突”的產生,使得散串列的查找程序仍然是一個給定值和關鍵字進行比較的程序,因此,仍需要以平均查找長度作為衡量散串列的查找效率的度量,
- 散串列的查找效率取決于三個因素:散列函式、處理沖突的方法和裝填因子,
- 若用ci表示每一個關鍵字查找的次數,則平均查找次數可表示為:(c0+c1+c2+c3+ ... +cm) / m
裝填因子,散串列的裝填因子一般記為α,定義為一個表的裝滿程度,即α = n ( 表 中 記 錄 數 ) / m ( 散 列 表 長 度 )
散串列的平均查找長度依賴于散串列的裝填因子α ,而不直接依賴于n或m,直觀地看,α 越大,表示裝填的記錄越“滿”,發生沖突的可能性越大,反之發生沖突的可能性越小,
不管記錄個數n有多大,我們總可以選擇一個合適的裝填因子以便將平均查找長度限定在一個范圍之內,此時我們散列查找的時間復雜度就真的是O(1)了, 為了做到這一點,通常我們都是將散串列的空間設定得比查找集合大,此時雖然是浪費了一定的空間,但換來的是查找效率的大大提升,總的來說,還是非常值得的,
本文部分內容來自:https://blog.csdn.net/Real_Fool_/article/details/114359564
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/528019.html
標籤:其他
下一篇:全球名校AI課程庫(38)| 馬薩諸塞大學 · 自然語言處理進階課程『Advanced Natural Language Processing』