前言
由于透明混合在不同的繪制順序下結果會不同,這就要求繪制前要對物體進行排序,然后再從后往前渲染,但即便是僅渲染一個物體(如上一章的水波),也會出現透明繪制順序不對的情況,普通的繪制是無法避免的,如果要追求正確的效果,就需要對每個像素位置對所有的像素按深度值進行排序,本章將介紹一種僅DirectX11及更高版本才能實作的順序無關的透明度(Order-Independent Transparency,OIT),雖然它是用像素著色器來實作的,但是用到了計算著色器里面的一些相關知識,
這一章綜合性很強,在學習本章之前需要先了解如下內容:
| 章節內容 |
|---|
| 11 混合狀態 |
| 12 深度/模板狀態、平面鏡反射繪制(僅深度/模板狀態) |
| 14 深度測驗 |
| 24 Render-To-Texture(RTT)技術的應用 |
| 28 計算著色器:波浪(水波) |
| 深入理解與使用緩沖區資源(結構化緩沖區、位元組地址緩沖區) |
學習目標:
- 熟悉記憶體模型、執行緒同步
- 熟悉順序無關透明度
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什么問題也可以在這里匯報,
DirectCompute 記憶體模型
DirectCompute提供了三種記憶體模型:基于暫存器的記憶體、設備記憶體和組內共享記憶體,不同的記憶體模型在記憶體大小、速度、訪問方式等地方有所區別,
基于暫存器的記憶體:它的訪問速度非常快,但是暫存器不僅有數目限制,暫存器指向的資源內部也有大小限制,如紋理暫存器(t#),常量緩沖區暫存器(b#),無序訪問視圖暫存器(u#),臨時暫存器(r#或x#)等,而且我們在使用暫存器時也不是直接指定某一個暫存器來使用,而是通過著色器物件(例如tbuffer,它是在GPU內部的記憶體,因此訪問速度特別快)對應到某一暫存器,然后使用該著色器物件來間接使用該暫存器的,而且這些暫存器是隨著著色器編譯出來后定死了的,因此暫存器的可用情況取決于當前使用的著色器代碼,
下面的代碼展示了如何宣告一個基于暫存器的記憶體:
tbuffer tb : register(t0)
{
float weight[256]; // 可以從CPU更新,只讀
}
設備記憶體:通常指的是D3D設備創建出來的資源(如紋理、緩沖區),這些資源可以長期存在,只要參考計數不為0,你可以給這些資源創建很大的記憶體空間來使用,并且你還可以將它們作為著色器資源或者無序訪問資源系結到暫存器中供使用,當然,這種作為著色器資源的訪問速度還是沒有直接在暫存器上創建的記憶體物件來得快,因為它是存盤在GPU外部的顯存中,盡管這些記憶體可以通過非常高的內部帶寬來訪問,但是在請求值和回傳值之間也有一個相對較高的延遲,盡管無序訪問視圖可以用于在設備記憶體中實作與基于暫存器的記憶體相同的操作,但當執行頻繁的讀寫操作時,性能將會收到嚴重影響,此外,由于每個執行緒都可以通過無序訪問視圖讀取或寫入資源中的任何位置,這需要手動同步對資源的訪問,也可以使用原子操作,又或者定義一個合理的訪問方式避免出現多個執行緒訪問到設備記憶體的同一個資料,
組內共享記憶體:前面兩種記憶體模型是所有可編程著色階段都可使用的,但是group shared memory只能在計算著色器使用,它的訪問速度比設備記憶體資源快些,比暫存器慢,但是也有明顯的記憶體限制——每個執行緒組最多只能分配32KB記憶體,供內部所有執行緒使用,組內共享的記憶體必須確定執行緒將如何與記憶體互動和使用記憶體,因此它還必須同步對該記憶體的訪問,這將取決于正在實作的演算法,但它通常涉及到前面描述的執行緒尋址,
這三種型別的記憶體提供了不同的訪問速度和可用的大小,使得它們可以用于與其能力相匹配的不同情況,這也給計算著色器提供了更大的記憶體操作靈活性,下表則是對記憶體模型的總結:
| 記憶體模型 | 訪問速度 | 可用記憶體 | 使用方式 |
|---|---|---|---|
| 基于暫存器的記憶體 | 很快 | 小 | 宣告暫存器記憶體物件、全域變數 |
| 設備記憶體 | 慢 | 大 | 通過特定視圖系結到渲染管線 |
| 組內共享記憶體 | 較快 | 較小 | 僅支持計算著色器,在全域變數前面加groupshared |
執行緒同步
由于大量執行緒同時運行,并且執行緒能夠通過組內共享記憶體或通過無序訪問視圖對應的資源進行互動,因此需要能夠同步執行緒之間的記憶體訪問,與傳統的多執行緒編程一樣,許多執行緒可用讀取和寫入相同的記憶體位置,存在寫后讀(Read After Write,簡稱RAW)導致記憶體損壞的危險,如何在不損失GPU并行性帶來的性能的情況下還能夠高效地同步這么多執行緒?幸運的是,有幾種不同的機制可用用于同步執行緒組內的執行緒,
記憶體屏障(Memory Barriers)
這是一種最高級的同步技術,HLSL提供了許多內置函式,可用于同步執行緒組中所有執行緒的記憶體訪問,需要注意的是,它只同步執行緒組中的執行緒,而不是整個調度,這些函式有兩個不同的屬性,第一個是呼叫函式時執行緒正在同步的記憶體類別(設備記憶體、組內共享記憶體,還是兩者都有),第二個則指定給定執行緒組中的所有執行緒是否同步到其執行程序中的同一處,根據這兩個屬性,衍生出了下面這些不同版本的內置函式:
| 不帶組內同步 | 帶組內同步 |
|---|---|
| GroupMemoryBarrier | GroupMemoryBarrierWithGroupSync |
| DeviceMemoryBarrier | DeviceMemoryBarrierWithGroupSync |
| AllMemoryBarrier | AllMemoryBarrierWithGroupSync |
這些函式中都會阻止執行緒繼續,直到滿足該函式的特定條件位置,其中第一個函式GroupMemoryBarrior()阻塞執行緒的執行,直到執行緒組中的所有執行緒對組內共享記憶體的所有寫入都完成,這用于確保當執行緒在組內共享記憶體中彼此共享資料時,所需的值在被其他執行緒讀取之前有機會寫入組內共享記憶體,這里有一個很重要的區別,即著色器核心執行一個寫指令,而那個指令實際上是由GPU的記憶體系統執行的,并且寫入記憶體中,然后在記憶體中它將再次對其他執行緒可用,從開始寫入值到完成寫入到目標位置有一個可變的時間量,這取決于硬體實作,通過執行阻塞操作,直到這些寫操作被保證已經完成,開發人員可以確定不會有任何寫后讀錯誤引發的問題,
不過話說了那么多,總得實踐一下,個人將雙調排序專案中BitonicSort_CS.hlsl第15行的GroupMemoryBarrierWithGroupSync()修改為GroupMemoryBarrier(),執行后發現多次運行程式會出現一例排序結果不一致的情況,因此可以這樣判斷:GroupMemoryBarrier()僅在執行緒組內的所有執行緒組存在執行緒寫入操作時阻塞,因此可能會出現阻塞結束時絕大多數執行緒完成了共享資料寫入,但仍有少量執行緒甚至還沒開始寫入共享資料,因此實際上很少能夠見到他出場的機會,
然后是GroupMemoryBarriorWithGroupSync()函式,相比上一個函式,他還阻止那些先到該函式的執行緒執行,直到所有的執行緒都到達該函式才能繼續,很明顯,在所有組內共享記憶體都加載之前,我們不希望任何執行緒前進,這使它成為完美的同步方法,
而第二對同步函式也執行類似的操作,只不過它們是在設備記憶體池上操作,這意味著在繼續執行著色器程式前,可以同步通過無序訪問視圖寫入資源的所有掛起記憶體的寫入操作,這對于同步更大數目的記憶體更為有用,如果所需的共享存盤器的大小太大不適合用組內共享記憶體,則可以將資料存在更大的設備記憶體的資源中,
第三對同步函式則是一起執行前面兩種型別的同步,用于同時存在共享記憶體和設備記憶體的訪問和同步上,
原子操作
記憶體屏障對于同步執行緒中的所有執行緒非常有用,然而,在許多情況下,還需要較小規模的同步,可能一次只需要幾個執行緒,在其他情況下,執行緒應該同步的位置可能在同一個執行點,也可能不在同一個執行點(例如,當執行緒組中的不同執行緒執行異構任務時),Shader Model 5引入了許多新的原子操作,可以在執行緒之間提供更細力度的同步,這樣在多執行緒訪問共享資源時,能夠確保所有其他執行緒都不能在統一時間訪問相同資源,原子操作保證該操作一旦開始,就一直運行到結束:
| 原子操作 |
|---|
| InterlockedAdd |
| InterlockedMin |
| InterlockedMax |
| InterlockedOr |
| InterlockedAnd |
| InterlockedXor |
| InterlockedCompareStore |
| InterlockedCompareExchange |
| InterlockedExchange |
原子操作也可以用于組內共享記憶體和資源記憶體,這里舉個使用的例子,如果計算著色器程式希望保留遇到特定資料值的執行緒數的計數,那么總計數可以初始化為0,并且每個執行緒可以在組內共享記憶體(以最快的訪問速度)或資源(在調度呼叫之間持續存在)上執行InterLockedAdd函式,這些原子操作確保總計數正確遞增,而不會被不同執行緒重寫中間值,
每個函式都有其獨特的輸入要求和操作,因此在選擇合適的函式時應參考Direct3D 11檔案,像素著色階段也可以使用這些函式,允許它跨資源同步(注意像素著色器不支持組內共享記憶體),
順序無關透明度
現在讓我們再回顧一下正確的透明計演算法,對每一個像素來說,若當前的背景色為\(c_0\),然后待渲染的透明像素片元按深度值從大到小排序為\(c_1, c_2, ..., c_n\),透明度為\(a_1, a_2, ..., a_n\)則最終的像素顏色為:
\[c=[a_n c_n + (1 - a_n)...[a_2 c_2 + (1 - a_2)[a_1 c_1 + (1 - a_1)c_0]...] \]
在以往的繪制方式,我們無法控制透明像素片元的繪制順序,運氣好的話還能正確呈現,一旦換了視角就會出現問題,要是場景里各種透明物體交錯在一起,基本上無論你怎么換視角都無法呈現正確的混合效果,因此為了實作順序無關透明度,我們需要預先收集這些像素,然后再進行深度排序,最后再計算出正確的像素顏色,
逐像素使用鏈表(Per-Pixel Linked Lists)
Direct3D 11硬體為許多新的渲染演算法打開了大門,尤其是對PS寫入UAV、附著在Buffer的原子計數器的支持,為Per-Pixel Linked Lists帶來了可能,它可以實作諸如OIT,間接陰影,動態場景的光線追蹤等,
但是,由于著色器只有按值傳遞,沒有指標和參考,在GPU是做不到使用基于指標或參考的鏈表的,為此,我們使用的資料結構是靜態鏈表,它可以在陣列中實作,原本作為next的指標則變成了下一個元素的索引值,
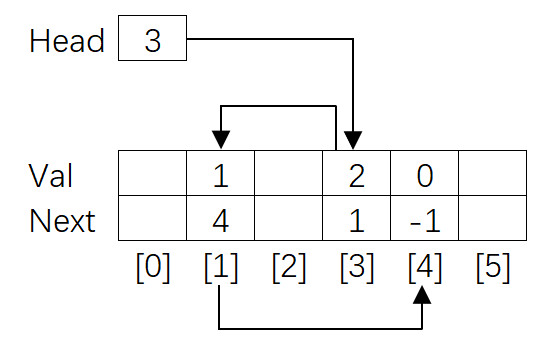
因為陣列是一個連續的記憶體區域,我們還可以在一個陣列中,存放多條靜態鏈表(只要空間足夠大),基于這個思想,我們可以為每個像素創建一個鏈表,用來收集對應螢屏像素位置的待渲染的所有像素片元,
該演算法需要歷經兩個步驟:
- 創建靜態鏈表,通過像素著色器,利用類似頭插法的思想在一個大陣列中逐漸形成靜態鏈表,
- 利用靜態鏈表渲染,通過計算著色器,取出當前像素對應的鏈表元素,進行排序,然后將計算結果寫入到渲染目標,
創建靜態鏈表
首先需要強調的是,這一步需要的是像素著色器5.0而不是計算著色器5.0,因為這一步實際上是把原本要繪制到渲染目標的這些像素片元給攔截下來,放到靜態鏈表當中,而要寫入Buffer就需要允許像素著色器支持無序訪問視圖(UAV),只有5.0及更高的版本才能這樣做,
此外,我們還需要原子操作的支持,這也需要使用著色器模型5.0,
最后我們還需要創建兩個支持讀/寫的緩沖區,用于系結到無序訪問視圖:
- 片元/鏈接緩沖區:該緩沖區存放的是片元資料和指向下一個元素的索引(即鏈接),并且由于它需要承擔所有像素的靜態鏈表,需要預留足夠大的空間來存放這些片元(元素數目通常為渲染目標像素總數的數倍),因此該演算法的一個主要開銷是GPU記憶體空間,其次,片元/鏈接緩沖區必須要使用結構化緩沖區,而不是多個有型別的緩沖區,因為只有
RWStructuredBuffer才能夠開啟隱藏的計數器,而這個計數器又是實作靜態鏈表必不可少的一部分,它用于統計緩沖區已經存放的鏈表節點數目, - 首節點偏移緩沖區:該緩沖區的寬度與高度渲染目標的一致,存放的元素是對應渲染目標像素在片元/鏈接緩沖區對應的靜態鏈表的首節點偏移,而且由于采用的是頭插法,指向的通常是當前像素最后一個寫入的片元位置,在使用之前我們需要定義-1(若是uint則為0xFFFFFFFF)為達到鏈表末端,因此每次使用之前都需要初始化鏈接值為-1.該緩沖區使用的是
RWByteAddressBuffer,因為它能夠支持原子操作,
下圖展示了通過像素著色器創建靜態鏈表的程序:
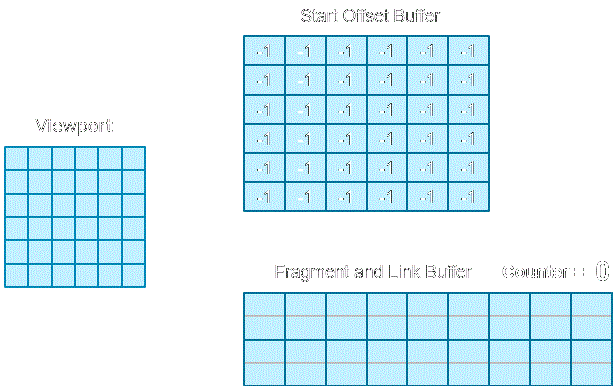
看完這個動圖后其實應該基本上能理解了,可能你的腦海里已經有了初步的代碼構造,但現在還是需要跟著現有的代碼學習才能實作,
首先放出實作該效果需要用到的常量緩沖區、結構體和函式:
// OIT.hlsli
cbuffer CBFrame : register(b6)
{
uint g_FrameWidth; // 幀像素寬度
uint g_FrameHeight; // 幀像素高度
uint2 g_Pad2;
}
struct FragmentData
{
uint Color; // 打包為R8G8B8A8的像素顏色
float Depth; // 深度值
};
struct FLStaticNode
{
FragmentData Data; // 像素片元資料
uint Next; // 下一個節點的索引
};
// 打包顏色
uint PackColorFromFloat4(float4 color)
{
uint4 colorUInt4 = (uint4) (color * 255.0f);
return colorUInt4.r | (colorUInt4.g << 8) | (colorUInt4.b << 16) | (colorUInt4.a << 24);
}
// 解包顏色
float4 UnpackColorFromUInt(uint color)
{
uint4 colorUInt4 = uint4(color, color >> 8, color >> 16, color >> 24) & (0x000000FF);
return (float4) colorUInt4 / 255.0f;
}
一個像素顏色的型別為float4,要是用它作為資料存盤到緩沖區會特別消耗顯存,因為最終顯示到后備緩沖區的型別為R8G8B8A8_UNORM或B8G8R8A8_UNORM,要是能夠將其打包成uint型,就可以節省這部分記憶體到原來的1/4,
當然,更狠的做法是,如果已知所有透明物體的Alpha值相同(都為0.5),那我們又可以將顏色壓縮成R5G6B5_UNORM,然后再把深度值壓縮成16為規格化浮點數,這樣一個像素只需要一半的記憶體空間就能夠表達了,當然代價為:顏色和深度都是有損的,
接下來是用于存盤像素片元的著色器:
#include "Basic.hlsli"
#include "OIT.hlsli"
RWStructuredBuffer<FLStaticNode> g_FLBuffer : register(u1);
RWByteAddressBuffer g_StartOffsetBuffer : register(u2);
// 靜態鏈表創建
// 提前開啟深度/模板測驗,避免產生不符合深度的像素片元的節點
[earlydepthstencil]
void PS(VertexPosHWNormalTex pIn)
{
// 省略常規的光照部分,最終計算得到的光照顏色為litColor
// ...
// 取得當前像素數目并自遞增計數器
uint pixelCount = g_FLBuffer.IncrementCounter();
// 在StartOffsetBuffer實作值交換
uint2 vPos = (uint2) pIn.PosH.xy;
uint startOffsetAddress = 4 * (g_FrameWidth * vPos.y + vPos.x);
uint oldStartOffset;
g_StartOffsetBuffer.InterlockedExchange(
startOffsetAddress, pixelCount, oldStartOffset);
// 向片元/鏈接緩沖區添加新的節點
FLStaticNode node;
// 壓縮顏色為R8G8B8A8
node.Data.Color = PackColorFromFloat4(litColor);
node.Data.Depth = pIn.PosH.z;
node.Next = oldStartOffset;
g_FLBuffer[pixelCount] = node;
}
這里面多了許多有趣的部分,需要逐一仔細講解一番,
首先是UAV暫存器,這里要先留個印象,暫存器索引初值不能從0開始,具體的原因要留到講C++的某個API時才能說的明白,
來到PS,我們也可以給像素著色器添加屬性,就像上面的[earlydepthstencil]那樣,因為在繪制透明物體之前我們已經繪制了不透明的物體,而不透明的物體會阻擋它后面的透明像素片元,雖然一般情況下深度測驗是在像素著色器之后,但也希望能拒絕掉那些被遮擋的像素片元寫入到片元/鏈接緩沖區種,因此我們可以使用屬性[earlydepthstencil],把深度/模板測驗提前到光柵化后,像素著色階段之前,這樣就可以有效剔除被遮擋的像素,既減小了性能開銷,又保證了渲染的正確,
然后是RWStructuredBuffer特有的方法IncrementCounter,它會回傳當前的計數值,并給計數器+1.與之對應的逆操作為DecrementCounter,它也屬于原子操作,因為涉及到大量的執行緒要訪問一個計數器,必須要有相應的同步操作才能保證一個時刻只有一個執行緒訪問該計數器,從而確保安全性,
這里又要再提一遍SV_POSITION,在作為頂點著色器的輸出時,提供的是未經過透視除法的NDC坐標;而作為像素著色器的輸入時,它歷經了透視除法、視口變換,得到的是對應像素的坐標值,比如說第233行,154列的像素對應的xy坐標為(232.5, 153.5),拋棄小數部分正好可以用作同寬高紋理相同位置的索引,
緊接著是RWByteAddressBuffer的InterlockedExchange方法:
void InterlockedExchange(
in uint dest, // 目的地址
in uint value, // 要交換的值
out uint original_value // 取出來的原值
);
你可以將其看作是一個寫入緩沖區的函式,同時它又吐出原來存盤的值,唯一要注意的是一切RWByteAddressBuffer的原子操作的地址值必須為4的倍數,因為它的讀寫單位都是32位的uint,
實際渲染階段
現在我們需要讓片元/鏈接緩沖區和首節點偏移緩沖區都作為著色器資源,因為還需要準備一個存放渲染了場景中不透明物體的背景圖作為混合初值,同時又還要將結果寫入到渲染目標,這樣的話我們還需要用到TextureRender類,存放與后備緩沖區等寬高的紋理,然后將場景中不透明的物體都渲染到此處,
對于頂點著色器來說,因為是渲染整個視窗,可以直接傳頂點:
// OIT_Render_VS.hlsl
#include "OIT.hlsli"
// 頂點著色器
float4 VS(float3 vPos : POSITION) : SV_Position
{
return float4(vPos, 1.0f);
}
而到了像素著色器,我們需要對當前像素對應的鏈表進行深度排序,由于訪問設備記憶體的效率相對較低,而且排序又涉及到頻繁的記憶體操作,在UAV進行鏈表排序的效率會很低,更好的做法是將所有像素拷貝到臨時暫存器陣列,然后再做排序,這樣效率會更高,其實也就是在像素著色器開辟一個全域靜態陣列來存放這些鏈表節點的元素,由于是靜態陣列,陣列元素固定,開辟較大的空間并不是一個比較好的選擇,這不僅涉及到排序的復雜程度,還涉及到顯存開銷,因此我們需要限制排序的像素片元數目,同時也意味著只需要讀取鏈表的前面幾個元素即可,這是一種比較折中的做法,
由于排序演算法的好壞也會影響最終的效率,對于小規模的排序,可以使用插入排序,它不僅是原址操作,對于已經有序的序列不會有多余的交換操作,又因為是執行緒內的排序,不能使用雙調排序,
像素著色器的代碼如下:
// OIT_Render_PS.hlsl
#include "OIT.hlsli"
StructuredBuffer<FLStaticNode> g_FLBuffer : register(t0);
ByteAddressBuffer g_StartOffsetBuffer : register(t1);
Texture2D g_BackGround : register(t2);
#define MAX_SORTED_PIXELS 8
static FragmentData g_SortedPixels[MAX_SORTED_PIXELS];
// 使用插入排序,深度值從大到小
void SortPixelInPlace(int numPixels)
{
FragmentData temp;
for (int i = 1; i < numPixels; ++i)
{
for (int j = i - 1; j >= 0; --j)
{
if (g_SortedPixels[j].Depth < g_SortedPixels[j + 1].Depth)
{
temp = g_SortedPixels[j];
g_SortedPixels[j] = g_SortedPixels[j + 1];
g_SortedPixels[j + 1] = temp;
}
else
{
break;
}
}
}
}
float4 PS(float4 posH : SV_Position) : SV_Target
{
// 取出當前像素位置對應的背景色
float4 currColor = g_BackGround.Load(int3(posH.xy, 0));
// 取出當前像素位置鏈表長度
uint2 vPos = (uint2) posH.xy;
int startOffsetAddress = 4 * (g_FrameWidth * vPos.y + vPos.x);
int numPixels = 0;
uint offset = g_StartOffsetBuffer.Load(startOffsetAddress);
FLStaticNode element;
// 取出鏈表所有節點
while (offset != 0xFFFFFFFF)
{
// 按當前索引取出像素
element = g_FLBuffer[offset];
// 將像素拷貝到臨時陣列
g_SortedPixels[numPixels++] = element.Data;
// 取出下一個節點的索引,但最多只取出前MAX_SORTED_PIXELS個
offset = (numPixels >= MAX_SORTED_PIXELS) ?
0xFFFFFFFF : element.Next;
}
// 對所有取出的像素片元按深度值從大到小排序
SortPixelInPlace(numPixels);
// 使用SrcAlpha-InvSrcAlpha混合
for (int i = 0; i < numPixels; ++i)
{
// 將打包的顏色解包出來
float4 pixelColor = UnpackColorFromUInt(g_SortedPixels[i].Color);
// 進行混合
currColor.xyz = lerp(currColor.xyz, pixelColor.xyz, pixelColor.w);
}
// 回傳手工混合的顏色
return currColor;
}
HLSL部分結束了,但C++端還有很多棘手的問題要處理,
OITRender類
在進行OIT像素收集時,需要通過替換像素著色器的手段來完成,因此它需要依附于BasicEffect,不好作為一個獨立的Effect使用,在此先放出OITRender類的定義:
class OITRender
{
public:
template<class T>
using ComPtr = Microsoft::WRL::ComPtr<T>;
OITRender() = default;
~OITRender() = default;
// 不允許拷貝,允許移動
OITRender(const OITRender&) = delete;
OITRender& operator=(const OITRender&) = delete;
OITRender(OITRender&&) = default;
OITRender& operator=(OITRender&&) = default;
HRESULT InitResource(ID3D11Device* device,
UINT width, // 幀寬度
UINT height, // 幀高度
UINT multiple = 1); // 用多少倍于幀像素數的緩沖區存盤像素片元
// 開始收集透明物體像素片元
void BeginDefaultStore(ID3D11DeviceContext* deviceContext);
// 結束收集,還原狀態
void EndStore(ID3D11DeviceContext* deviceContext);
// 將背景與透明物體像素片元混合完成最終渲染
void Draw(ID3D11DeviceContext * deviceContext, ID3D11ShaderResourceView* background);
void SetDebugObjectName(const std::string& name);
private:
struct {
int width;
int height;
int pad1;
int pad2;
} m_CBFrame; // 對應OIT.hlsli的常量緩沖區
private:
ComPtr<ID3D11InputLayout> m_pInputLayout; // 繪制螢屏的頂點輸入布局
ComPtr<ID3D11Buffer> m_pFLBuffer; // 片元/鏈接緩沖區
ComPtr<ID3D11Buffer> m_pStartOffsetBuffer; // 起始偏移緩沖區
ComPtr<ID3D11Buffer> m_pVertexBuffer; // 繪制背景用的頂點緩沖區
ComPtr<ID3D11Buffer> m_pIndexBuffer; // 繪制背景用的索引緩沖區
ComPtr<ID3D11Buffer> m_pConstantBuffer; // 常量緩沖區
ComPtr<ID3D11ShaderResourceView> m_pFLBufferSRV; // 片元/鏈接緩沖區的著色器資源視圖
ComPtr<ID3D11ShaderResourceView> m_pStartOffsetBufferSRV; // 起始偏移緩沖區的著色器資源視圖
ComPtr<ID3D11UnorderedAccessView> m_pFLBufferUAV; // 片元/鏈接緩沖區的無序訪問視圖
ComPtr<ID3D11UnorderedAccessView> m_pStartOffsetBufferUAV; // 起始偏移緩沖區的無序訪問視圖
ComPtr<ID3D11VertexShader> m_pOITRenderVS; // 透明混合渲染的頂點著色器
ComPtr<ID3D11PixelShader> m_pOITRenderPS; // 透明混合渲染的像素著色器
ComPtr<ID3D11PixelShader> m_pOITStorePS; // 用于存盤透明像素片元的像素著色器
ComPtr<ID3D11PixelShader> m_pCachePS; // 臨時快取的像素著色器
UINT m_FrameWidth; // 幀像素寬度
UINT m_FrameHeight; // 幀像素高度
UINT m_IndexCount; // 繪制索引數
};
這里不放出初始化的代碼,但在呼叫初始化的時候需要注意提供合理的幀像素的倍數,若設定的太低,則緩沖區可能不足以容納透明像素片元而渲染例外,
OITRender::BeginDefaultStore方法--在默認特效下收集像素片元
不管寫什么渲染類,渲染狀態的管理是最復雜的,一處錯誤都會導致渲染結果的不理想,
該方法首先要解決兩個主要問題:UAV的初始化、系結到像素著色階段,
ID3D11DeviceContext::ClearUnorderedAccessViewUint--使用特定值/向量設定UAV初始值
void ClearUnorderedAccessViewUint(
ID3D11UnorderedAccessView *pUnorderedAccessView, // [In]待清空UAV
const UINT [4] Values // [In]清空值/向量
);
該方法對任何UAV都有效,它是以二進制位的形式來清空值,若為DXGI特定型別,如R16G16_UNORM,則該方法會根據Values的前兩個元素取出各自的低16位分別復制到每個陣列元素的x分量和y分量,若為原始記憶體的視圖或結構化緩沖區的視圖,則只取Values的第一個元素來復制到緩沖區的每一個4位元組內,
ID3D11DeviceContext::OMSetRenderTargetsAndUnorderedAccessViews--輸出合并階段設定渲染目標并設定UAV
既然像素著色器能夠使用UAV,一開始找了半天都沒找到ID3D11DeviceContext::PSSetUnorderedAccessViews,結果發現居然是在OM階段的函式提供UAV系結,
void ID3D11DeviceContext::OMSetRenderTargetsAndUnorderedAccessViews(
UINT NumRTVs, // [In]渲染目標數
ID3D11RenderTargetView * const *ppRenderTargetViews, // [In]渲染目標視圖陣列
ID3D11DepthStencilView *pDepthStencilView, // [In]深度/模板視圖
UINT UAVStartSlot, // [In]UAV起始槽
UINT NumUAVs, // [In]UAV數目
ID3D11UnorderedAccessView * const *ppUnorderedAccessViews, // [In]無序訪問視圖陣列
const UINT *pUAVInitialCounts // [In]各個無序訪問視圖的計數器初始值
);
前三個引數和后三個引數應該都沒什么問題,但中間的那個引數是一個大坑,對于像素著色器,UAVStartSlot應當等于已經系結的渲染目標視圖數目,渲染目標和無序訪問視圖在寫入的時候共享相同的資源槽,這意味著必須為UAV指定偏移量,以便于它們放在待系結的渲染目標視圖之后的插槽中,因此在前面的HLSL代碼中,u暫存器需要從1開始就是這里來的,
注意:RTV、DSV、UAV不能獨立設定,它們都需要同時設定,
兩個系結了同一個子資源(也因此共享同一個紋理)的RTV,或者是兩個UAV,又或者是一個UAV和RTV,都會引發沖突,
OMSetRenderTargetsAndUnorderedAccessViews在以下情況才能運行正常:
當NumRTVs != D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL且NumUAVs != D3D11_KEEP_UNORDERED_ACCESS_VIEWS時,需要滿足下面這些條件:
- NumRTVs <= 8
- UAVStartSlot >= NumRTVs
- UAVStartSlot + NumUAVs <= 8
- 所有設定的RTVs和UAVs不能有資源沖突
- DSV的紋理必須匹配RTV的紋理(但不是相同)
當NumRTVs == D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL時,說明OMSetRenderTargetsAndUnorderedAccessViews只系結UAVs,需要滿足下面這些條件:
- UAVStartSlot + NumUAVs <= 8
- 所有設定的UAVs不能有資源沖突
它還會解除系結下面這些東西:
- 所有在slots >= UAVStartSlot的RTVs
- 所有與待系結的UAVs發生資源沖突的RTVs
- 所有當前系結的資源(SOTargets,CS UAVs, SRVs)沖突的UAVs
提供的深度/模板緩沖區會被忽略,并且已經系結的深度/模板緩沖區并沒有被卸下,
當NumUAVs == D3D11_KEEP_UNORDERED_ACCESS_VIEWS時,說明OMSetRenderTargetsAndUnorderedAccessViews只系結RTVs和DSV,需要滿足下面這些條件
-
NumRTVs <= 8
-
這些RTVs相互沒有資源沖突
-
DSV的紋理必須匹配RTV的紋理(但不是相同)
它還會解除系結下面這些東西:
-
所有在slots < NumRTVs的UAVs
-
所有與待系結的RTVs發生資源沖突的UAVs
-
所有當前系結的資源(SOTargets,CS UAVs, SRVs)沖突的RTVs
提供的UAVStartSlot忽略,
現在可以把目光放回到OITRender::BeginDefaultStore上:
void OITRender::BeginDefaultStore(ID3D11DeviceContext* deviceContext)
{
deviceContext->RSSetState(RenderStates::RSNoCull.Get());
UINT numClassInstances = 0;
deviceContext->PSGetShader(m_pCachePS.GetAddressOf(), nullptr, &numClassInstances);
deviceContext->PSSetShader(m_pOITStorePS.Get(), nullptr, 0);
// 初始化UAV
UINT magicValue[1] = { 0xFFFFFFFF };
deviceContext->ClearUnorderedAccessViewUint(m_pFLBufferUAV.Get(), magicValue);
deviceContext->ClearUnorderedAccessViewUint(m_pStartOffsetBufferUAV.Get(), magicValue);
// UAV系結到像素著色階段
ID3D11UnorderedAccessView* pUAVs[2] = { m_pFLBufferUAV.Get(), m_pStartOffsetBufferUAV.Get() };
UINT initCounts[2] = { 0, 0 };
deviceContext->OMSetRenderTargetsAndUnorderedAccessViews(D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL,
nullptr, nullptr, 1, 2, pUAVs, initCounts);
// 關閉深度寫入
deviceContext->OMSetDepthStencilState(RenderStates::DSSNoDepthWrite.Get(), 0);
// 設定常量緩沖區
deviceContext->PSSetConstantBuffers(6, 1, m_pConstantBuffer.GetAddressOf());
}
上面的代碼有兩個點要特別注意:
- 因為是透明物體,需要關閉背面消隱
- 因為沒有產生實際繪制,需要關閉深度寫入
OITRender::EndStore方法--結束收集
方法如下:
void OITRender::EndStore(ID3D11DeviceContext* deviceContext)
{
// 恢復渲染狀態
deviceContext->PSSetShader(m_pCachePS.Get(), nullptr, 0);
ComPtr<ID3D11RenderTargetView> currRTV;
ComPtr<ID3D11DepthStencilView> currDSV;
ID3D11UnorderedAccessView* pUAVs[2] = { nullptr, nullptr };
deviceContext->OMSetRenderTargetsAndUnorderedAccessViews(D3D11_KEEP_RENDER_TARGETS_AND_DEPTH_STENCIL,
nullptr, nullptr, 1, 2, pUAVs, nullptr);
m_pCachePS.Reset();
}
OITRender::Draw方法--對透明像素片元進行排序混合并完成繪制
方法如下,到這一步其實已經沒那么復雜了:
void OITRender::Draw(ID3D11DeviceContext* deviceContext, ID3D11ShaderResourceView* background)
{
UINT strides[1] = { sizeof(VertexPos) };
UINT offsets[1] = { 0 };
deviceContext->IASetVertexBuffers(0, 1, m_pVertexBuffer.GetAddressOf(), strides, offsets);
deviceContext->IASetIndexBuffer(m_pIndexBuffer.Get(), DXGI_FORMAT_R32_UINT, 0);
deviceContext->IASetInputLayout(m_pInputLayout.Get());
deviceContext->IASetPrimitiveTopology(D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST);
deviceContext->VSSetShader(m_pOITRenderVS.Get(), nullptr, 0);
deviceContext->PSSetShader(m_pOITRenderPS.Get(), nullptr, 0);
deviceContext->GSSetShader(nullptr, nullptr, 0);
deviceContext->RSSetState(nullptr);
ID3D11ShaderResourceView* pSRVs[3] = {
m_pFLBufferSRV.Get(), m_pStartOffsetBufferSRV.Get(), background};
deviceContext->PSSetShaderResources(0, 3, pSRVs);
deviceContext->PSSetConstantBuffers(6, 1, m_pConstantBuffer.GetAddressOf());
deviceContext->OMSetDepthStencilState(nullptr, 0);
deviceContext->OMSetBlendState(nullptr, nullptr, 0xFFFFFFFF);
deviceContext->DrawIndexed(m_IndexCount, 0, 0);
// 繪制完成后卸下系結的資源即可
pSRVs[0] = pSRVs[1] = pSRVs[2] = nullptr;
deviceContext->PSSetShaderResources(0, 3, pSRVs);
}
場景繪制
現在場景中除了山體、波浪,還有兩個透明相交的立方體,只考慮開啟OIT的GameApp::DrawScene方法如下:
void GameApp::DrawScene()
{
assert(m_pd3dImmediateContext);
assert(m_pSwapChain);
m_pd3dImmediateContext->ClearRenderTargetView(m_pRenderTargetView.Get(), reinterpret_cast<const float*>(&Colors::Silver));
m_pd3dImmediateContext->ClearDepthStencilView(m_pDepthStencilView.Get(), D3D11_CLEAR_DEPTH | D3D11_CLEAR_STENCIL, 1.0f, 0);
// 渲染到臨時背景
m_pTextureRender->Begin(m_pd3dImmediateContext.Get(), reinterpret_cast<const float*>(&Colors::Silver));
{
// ******************
// 1. 繪制不透明物件
//
m_BasicEffect.SetRenderDefault(m_pd3dImmediateContext.Get(), BasicEffect::RenderObject);
m_BasicEffect.SetTexTransformMatrix(XMMatrixIdentity());
m_Land.Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
// ******************
// 2. 存放透明物體的像素片元
//
m_pOITRender->BeginDefaultStore(m_pd3dImmediateContext.Get());
{
m_RedBox.Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
m_YellowBox.Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
m_pGpuWavesRender->Draw(m_pd3dImmediateContext.Get(), m_BasicEffect);
}
m_pOITRender->EndStore(m_pd3dImmediateContext.Get());
}
m_pTextureRender->End(m_pd3dImmediateContext.Get());
// 渲染到后備緩沖區
m_pOITRender->Draw(m_pd3dImmediateContext.Get(), m_pTextureRender->GetOutputTexture());
// ******************
// 繪制Direct2D部分
//
// ...
HR(m_pSwapChain->Present(0, 0));
}
演示
下面演示了關閉OIT和深度寫入、關閉OIT但開啟深度寫入、開啟OIT下的場景渲染效果:
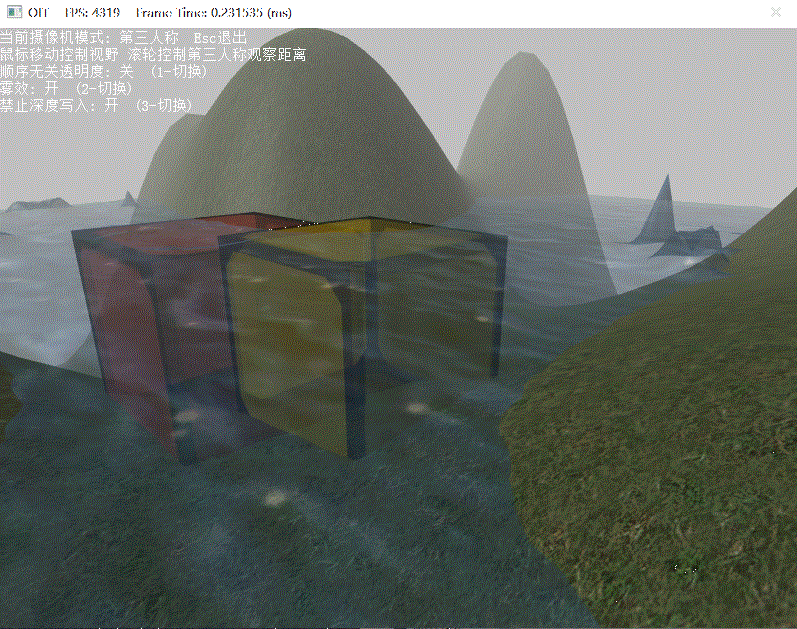
開啟OIT的平均幀數為2700,而默認平均幀數為4200,可見影響渲染性能的主要因素有:RTT的使用、場景中透明像素的復雜程度、排序演算法的選擇和n的限制,因此要保證渲染效率,最好是能夠減少透明物體的復雜程度、場景中透明物體的數目,必要時甚至是避免透明混合,
除錯問題
該專案無法圖形除錯,就和DirectX SDK Samples中OIT樣例一樣,遇到了未知問題,如果要除錯,需要把OIT相關的代碼撤走才能除錯,

練習題
- 嘗試改動HLSL代碼,將顏色壓縮成
R5G6B5_UNORM(規定透明物體Alpha統一為0.5),然后再把深度值壓縮成16為規格化浮點數,同時也要改動C++端代碼來適配,
參考資料
- DirectX SDK Samples中的OIT
- OIT-and-Indirect-Illumination-using-DX11-Linked-Lists 演示檔案
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什么問題也可以在這里匯報,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5306.html
標籤:其他