本文轉自Rancher Labs
Kubernetes可以幫助管理部署在Pod中的上百個容器的生命周期,它是高度分布式的并且各個部分是動態的,一個已經實作的Kubernetes環境通常涉及帶有集群和節點的幾個系統,這些系統托管著幾百個容器,而這些容器不斷地基于作業負載啟動、毀滅,
當在Kubernetes中處理大量的容器化應用和作業負載時,主動進行監控和除錯錯誤十分重要,在容器、節點或集群級別,這些錯誤都能在容器中看到,Kubernetes的日志機制是一個十分重要的組件,可以用來管理和監控服務以及基礎設施,在Kubernetes中,日志可以讓你跟蹤錯誤甚至可以調整托管應用程式的容器的性能,
配置stdout(標準輸出)和stderr(標準錯誤)資料流
圖片來源:kubernetes.io
第一步是理解日志是如何生成的,通過Kubernetes,日志會被發送到兩個資料流——stdout和stderr,這些資料流將寫入JSON檔案,并且此程序由Kubernetes內部處理,你可以配置將哪個日志發送到哪個資料流中,而一個最佳實踐的建議是將所有應用程式日志都發送到stdout并且所有錯誤日志都發送到stderr,
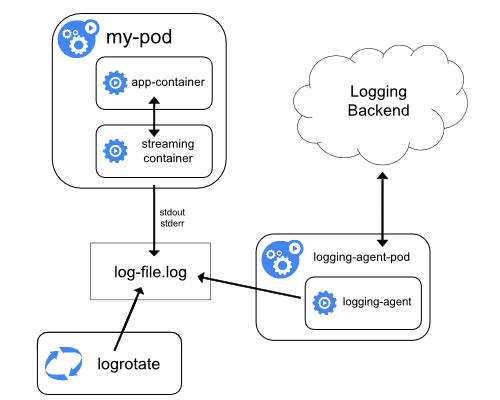
決定是否使用Sidecar模型
Kubernetes建議使用sidecar容器來收集日志,在這一方法中,每個應用程式容器將有一個鄰近的“streaming容器”,該容器將會將所有日志流傳輸到stdout和stderr,Sidecar模型可以幫助避免在節點級別公開日志,并且它可以讓你控制容器級別的日志,
然而,這一模型的問題是它能夠適用于小容量的日志記錄,如果面對大規模的日志記錄,可能會造成大量資源被占用,因此,你需要為每個正在運行的應用程式容器單獨運行一個日志容器,在Kubernetes檔案中,將sidecar模型形容為“幾乎沒有很大的開銷”,需要由你決定是否嘗試這一模型并在選擇它之前查看它所消耗的資源型別,
替代方法是使用日志代理,該代理在節點級別收集日志,這樣可以減少開銷,并確保安全地處理日志,Fluentd已成為大規模聚合Kubernetes日志的最佳選擇,它充當Kubernetes與你要使用Kubernetes日志的任意數量的端點之間的橋梁,你也可以選擇像Rancher這樣的Kubernetes管理平臺,在應用商店已經集成了Fluentd,無需從頭開始安裝配置,
確定Fluentd可以更好地匯總和路由日志資料后,下一步就是確定如何存盤和分析日志資料,
選擇日志分析工具:EFK或專用日志記錄
傳統上,對于以本地服務器為中心的系統,應用程式日志存盤在系統中的日志檔案中,這些檔案可以在定義的位置看到,也可以移動到中央服務器,但是對于Kubernetes,所有日志都發送到磁盤上/var/log的JSON檔案中,這種型別的日志聚合并不安全,因為節點中的Pod可以是臨時的也可以是短暫的,洗掉Pod時,日志檔案將丟失,如果你需要嘗試對部分日志資料丟失進行故障排除時,這可能很難,
Kubernetes官方推薦使用兩個選項:將所有日志發送到Elasticsearch,或使用你選擇的第三方日志記錄工具,同樣,這里存在一個潛在的選擇,采用Elasticsearch路線意味著你需要購買一個完整的堆疊,即EFK堆疊,包括Elasticsearch、Fluentd和Kibana,每個工具都有其自己的作用,如上所述,Fluentd可以聚合和路由日志,Elasticsearch是分析原始日志資料并提供可讀輸出的強大平臺,Kibana是一種開源資料可視化工具,可以從你的日志資料創建漂亮的定制dashboard,這是一個完全開源的堆疊,是使用Kubernetes進行日志記錄的強大解決方案,
盡管如此,有些事情仍然需要牢記,Elasticsearch除了由名為Elastic的組織構建和維護,還有龐大的開源社區開發人員為其做貢獻,盡管經過大量的實踐檢驗,它可以快速、強大地處理大規模資料查詢,但在大規模操作時可能會出現一些問題,如果采用的是自我管理(Self-managed)的Elasticsearch,那么需要有人了解如何構建大規模平臺,
替代方案是使用基于云的日志分析工具來存盤和分析Kubernetes日志,諸如Sumo Logic和Splunk等工具都是很好的例子,其中一些工具利用Fluentd來將日志路由到他們平臺,而另一些可能有它們自己的自定義日志代理,該代理位于Kubernetes中的節點級別,這些工具的設定十分簡單,并且使用這些工具可以花費最少的時間從零搭建一個可以查看日志的dashboard,
使用RBAC控制對日志的訪問
在Kubernetes中身份驗證機制使用的是基于角色訪問控制(RBAC)以驗證一個用戶的訪問和系統權限,根據用戶是否具有特權(authorization.k8s.io/decision )并向用戶授予原因(authorization.k8s.io/reason ),對在操作期間生成的審核日志進行注釋,默認情況下,審核日志未激活,建議激活它以跟蹤身份驗證問題,并可以使用kubectl進行設定,
保持日志格式一致
Kubernetes日志由Kubernetes架構中不同的部分生成,這些聚合的日志應該格式一致,以便諸如Fluentd或FluentBit的日志聚合工具更易于處理它們,例如,當配置stdout和stderr或使用Fluentd分配標簽和元資料時,需要牢記這一點,這種結構化日志提供給Elasticsearch之后,可以減少日志分析期間的延遲,
在日志收集守護行程上設定資源限制
由于生成了大量日志,因此很難在集群級別上管理日志,DaemonSet在Kubernetes中的使用方式與Linux類似,它在后臺運行以執行特定任務,Fluentd和filebeat是Kubernetes支持的用于日志收集的兩個守護程式,我們必須為每個守護程式設定資源限制,以便根據可用的系統資源來優化日志檔案的收集,
結 論
Kubernetes包含多個層和組件,因此對其進行良好地監控和跟蹤能夠讓我們在面對故障時從容不迫,Kubernetes鼓勵使用無縫集成的外部“Kubernetes原生”工具進行日志記錄,從而使管理員更輕松地獲取日志,文章中提到的實踐對于擁有一個健壯的日志記錄體系結構很重要,該體系結構在任何情況下都可以正常作業,它們以優化的方式消耗計算資源,并保持Kubernetes環境的安全性和高性能,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5316.html
標籤:其他
上一篇:lua學習之深入函式第一篇