摘要:今天帶領大家學習自然語言處理中的詞嵌入的內容,
本文分享自華為云社區《【MindSpore易點通】深度學習系列-詞嵌入》,作者:Skytier,
1 特征表示
在自然語言處理中,有一個很關鍵的概念是詞嵌入,這是語言表示的一種方式,可以讓演算法自動的理解一些同類別的詞,比如蘋果、橘子,比如襪子、手套,
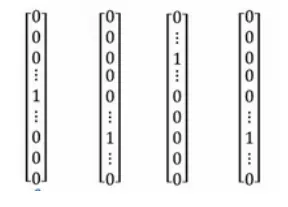 one-hot向量
one-hot向量
比如我們通常會說:“I want a glass of orange juice.”但如果演算法并不知道apple和orange的類似性(這兩個one-hot向量的內積是0),那么當其遇到“I want a glass of apple __”時,并不知道這里也應該填寫 juice,
如果用特征化的表示來表示庫里的每個詞,學習它們的特征或者數值,
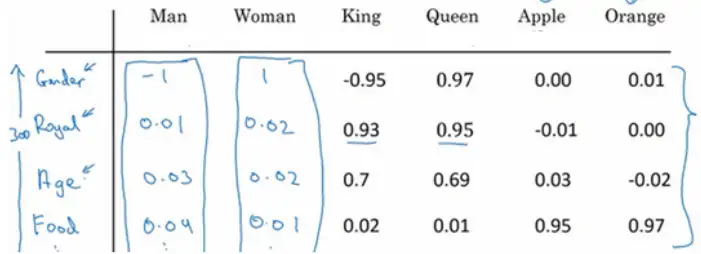

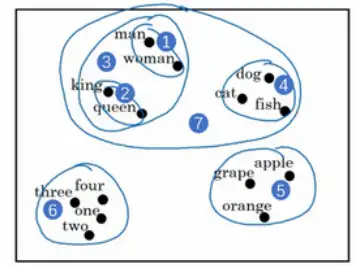
這樣我們就可以選用t-SNE演算法來對特征向量可視化,通過觀察這種詞嵌入的表示方法,最終同類別的單詞會聚集在一塊,詞嵌入演算法對于相近的概念,學到的特征也比較類似,
2 詞嵌入的使用
參考案例——句中找人名:Jack Li is a teacher.
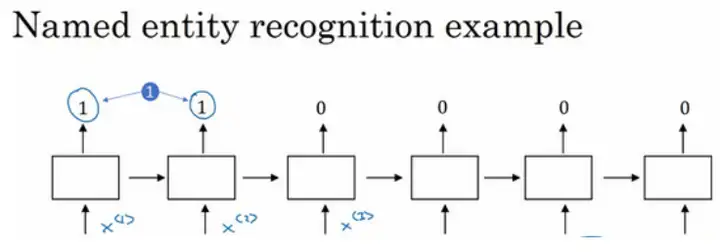
使用詞嵌入作為輸入訓練好的模型,如果看到一個新的輸入:“Jack Li is a farmer.”因為知道teacher和farmer很相近,那么演算法很容易就知道Jack Li是一個人的名字,同時,如果遇到不太常見的單詞,比如:Jack Li is a cultivator.(假設訓練集里沒有cultivator這個單詞),但是詞嵌入的演算法通過考察大量的無標簽文本,會發現farmer、teacher、cultivator相近,把它們都聚集在一塊,這樣一來即使只有一個很小的訓練集,但是使用遷移學習,把從大量的無標簽文本中學習到的知識遷移到一個任務中——比如少量標記的訓練資料集的命名物體識別任務,
如何用詞嵌入做遷移學習的步驟:
1.先從大量的文本集中學習詞嵌入,
2.用這些詞嵌入模型把它遷移到新的只有少量標注訓練集的任務中,比如說用300維的詞嵌入來表示單詞,這樣就可以用更低維度的特征向量代替原來的10000維的one-hot向量,
3.當在新的任務上訓練模型時,只有少量的標記資料集,可以選擇不進行微調,而是用新的資料調整詞嵌入,
當你的任務的訓練集相對較小時,詞嵌入的作用最明顯,所以它廣泛用于NLP領域,但是其對于一些語言模型和機器翻譯并不適用,
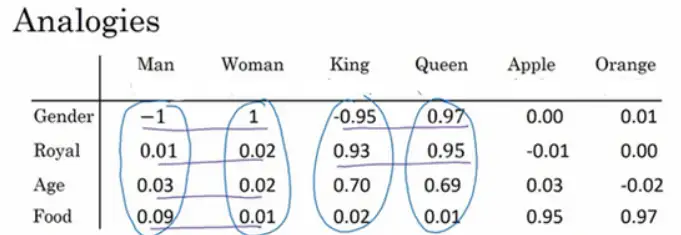
3 類比推理
詞嵌入有一個非常強大的特性就是可以幫助實作類比推理,比如從性別這個特征上來說,如果man應該對應woman,那么演算法可以推匯出king對應queen,



最常用的相似度函式是余弦相似度,假如在向量u和v之間定義相似度:
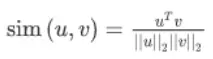
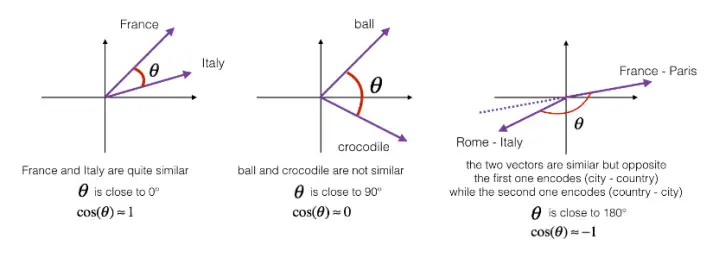
如果u和v非常相似,那么它們的內積將會很大,那么該式就是u和v的夾角Φ的余弦值,實際就是計算兩向量夾角Φ角的余弦,夾角為0度時,余弦相似度就是1,當夾角是90度角時余弦相似度就是0,當夾角是180度時相似度等于-1,因此角度越小,兩個向量越相似,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/531828.html
標籤:其他
上一篇:帶你從0到1開發AI影像分類應用
下一篇:【知識圖譜】概述