知識工程
知識工程最早在1977年被提出,當時圍繞知識工程的主要研究是專家系統,所謂專家系統是指利用某種方法將專業領域的專家知識收集下來,并存盤在程式中,然后利用程式代碼模擬人類的思維(推理+搜索)程序,去嘗試解決某些專業領域的問題,
專家系統是人工智能發展前期階段的一個主要研究方向,也是一種利用程式去試圖模擬人類在某些特定領域內的思維的一種嘗試,
專家系統的核心在于知識表示、知識獲取以及推理機制,
知識表示是指知識知識的組織結構與表現形式,知識在計算機中的存盤形式,知識的表示直接關乎知識的獲取以及推理機制,
知識獲取是指如何從領域專家或則其它來源去獲取和整理知識,獲取的內容要全面,但不能冗余,而且還要準確,這是一個比較大的難題,
推理機制是指將人類的推理方法用程式代碼表示出來,
這幾個方面在之后的二三十年中都各自有一定的發展,直到二十一世紀初,互聯網時代的到來,海量資料的爆發,傳統的專家系統的模式對這些已經無能為力了,專家系統的思路不能夠滿足發展對于“智能”方面的需求了,
2012年谷歌提出了知識圖譜,不過知識圖譜相關的一些技術研究基本都是前面幾十年技術的延續,而不是革新,目前,隨著智能資訊服務應用的不斷發展,知識圖譜已廣泛應用于智能搜索,智能問答,個性化推薦等領域,
知識圖譜主要在知識表示方面有了一些比較重大的改變,主要的變化在于更利于海量資料的知識圖譜的構建,以及更加利于自動化方法構建,而不是主要依賴人工構建,
傳統的專家系統中的知識庫的資料量一般在數萬或數十萬左右,一些經過幾十年積累至今的知識庫也就幾千萬的資料量,但是現在比較知名的知識圖譜的資料量都在數十到數百億的量級上,
知識圖譜中使用的自動化構建主要是指一些機器學習演算法、自然語言處理等方面的內容,
在知識加工方面,由于是通程序式自動獲取的資料,那么就需要對資料的內容進行處理,包括提取本體、物體、事件來構建本體庫、物體庫、事件庫等,還需要對內容進行匹配,鏈接,去冗余,融合,以及在知識庫中使用推理機制進行內部構建,利用知識發現新的知識等,
在知識的應用方面,從傳統的專家系統的注重邏輯推理,轉向了注重事實知識的檢索,知識圖譜更多的下沉到人工智能領域的基礎設施中,提供基礎的結構化知識,比如基于知識圖譜可以構建智能搜索、智能問答、對話機器人等應用,而不是像專家系統那樣作為一個獨立的應用出現,
語意網
實際上,知識圖譜并不是一個全新的概念,早在 2006 年就有文獻提出了語意網(Semantic Network)的概念,呼吁推廣、完善使用本體模型來形式化表達資料中的隱含語意,RDF(resource description framework,資源描述框架)模式和 OWL(Web ontology language,萬維網本體語言)就是基于上述目的產生的,用電子科技大學徐增林教授的論文原文來說:
知識圖譜技術的出現正是基于以上相關研究,是對語意網標準與技術的一次揚棄與升華,
語意網路由相互連接的節點和邊組成,節點表示概念或者物件,邊表示他們之間的關系(is-a關系,比如:貓是一種哺乳動物;part-of關系,比如:脊椎是哺乳動物的一部分),如下圖,在表現形式上,語意網路和知識圖譜相似,但語意網路更側重于描述概念與概念之間的關系,(有點像生物的層次分類體系——界門綱目科屬種),而知識圖譜則更偏重于描述物體之間的關聯,

知識圖譜定義
資訊與知識
-
資訊是指外部的客觀事實,
舉例:這里有一瓶水,它現在是7°,
-
知識是對外部客觀規律的歸納和總結,
舉例:水在零度的時候會結冰,
另一種解讀:
在資訊的基礎上,建立物體之間的聯系,就能形成 “知識”

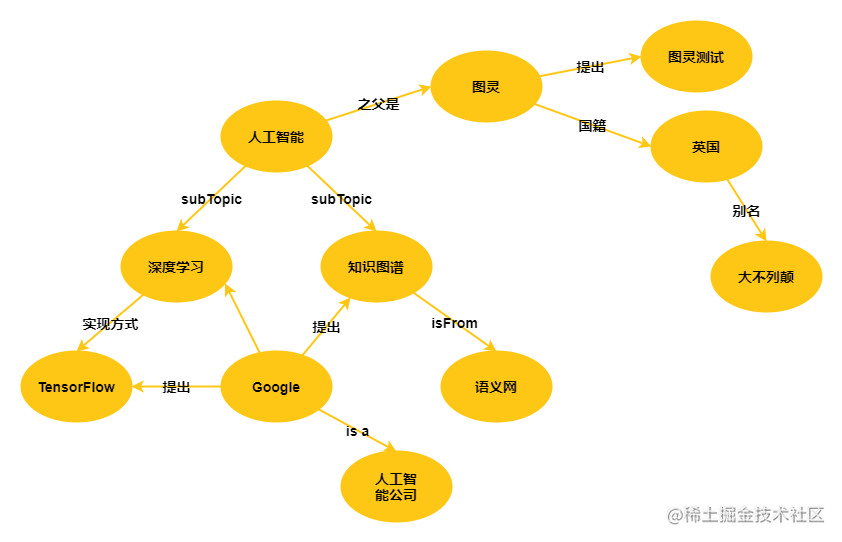
知識圖譜的概念誕生于2012年,由谷歌公司首先提出,大家都知道,谷歌是做搜索引擎的,所以他們最早提出了Google Knowledge Graph后,首先利用知識圖譜技術改善了搜索引擎核心,
目前在學術界還沒有給知識圖譜一個統一的定義,但是在谷歌發布的檔案中有明確的描述:“知識圖譜是一種用圖模型來描述知識和建模世界萬物之間關聯關系的技術方法”,
谷歌的Singhal博士用三個詞點出了知識圖譜加入之后搜索發生的變化:
“Things,not string.”
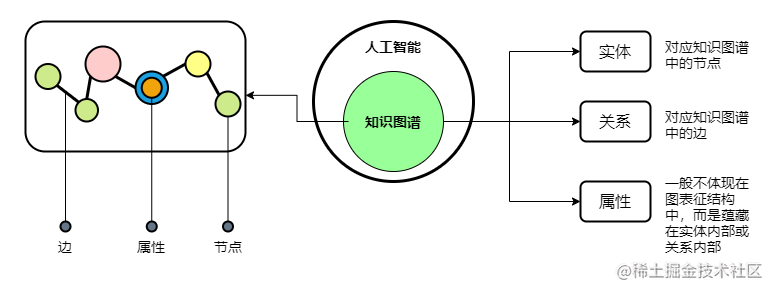
知識圖譜是由一些相互連接的物體和他們的屬性構成的
A knowledge graph consists of a set of interconnected typed entities and their attributes.
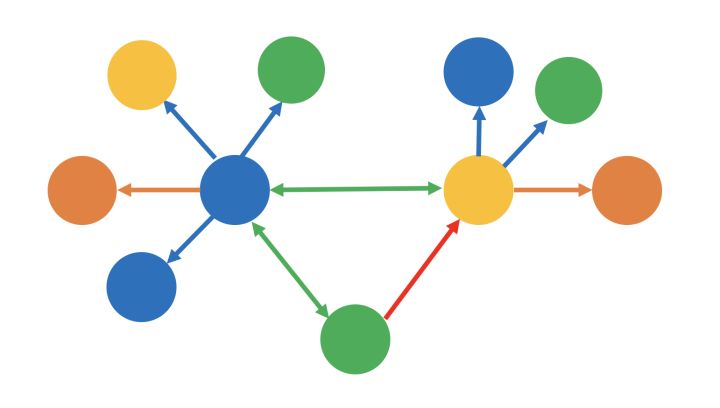
在知識圖譜中,通過三元組 <物體 × 關系 × 屬性> 集合的形式來描述事物之間的關系
- 物體:又叫作本體,指客觀存在并可相互區別的事物,可以是具體的人、事、物,也可以是抽象的概念或聯系,物體是知識圖譜中最基本的元素
- 關系:在知識圖譜中,邊表示知識圖譜中的關系,用來表示不同物體間的某種聯系
- 屬性:知識圖譜中的物體和關系都可以有各自的屬性
這里所說的物體和普通意義上的物體略有不同,借用NLP中本體的概念來理解它會比較好:
本體定義了組成主題領域的詞匯表的基本術語及其關系,以及結合這些術語和關系來定義詞匯表外延的規則,
構建方式
曾經知識圖譜非常流行自頂向下(top-down)的構建方式,自頂向下指的是先為知識圖譜定義好本體與資料模式,再將物體加入到知識庫,該構建方式需要利用一些現有的結構化知識庫作為其基礎知識庫,例如 Freebase 專案就是采用這種方式,它的絕大部分資料是從維基百科中得到的,
然而目前,大多數知識圖譜都采用自底向上(bottom-up)的構建方式,自底向上指的是從一些開放鏈接資料(也就是 “資訊”)中提取出物體,選擇其中置信度較高的加入到知識庫,再構建物體與物體之間的聯系,
存盤方式
知識圖譜主要有兩種存盤方式:一種是基于RDF的存盤;另一種是基于圖資料庫的存盤,它們之間的區別如下圖所示,RDF一個重要的設計原則是資料的易發布以及共享,圖資料庫則把重點放在了高效的圖查詢和搜索上,其次,RDF以三元組的方式來存盤資料而且不包含屬性資訊,但圖資料庫一般以屬性圖為基本的表示形式,所以物體和關系可以包含屬性,這就意味著更容易表達現實的業務場景

從不同的視角去審視知識圖譜:
- 在Web視角下,知識圖譜如同簡單文本之間的超鏈接一樣,通過建立資料之間的語意鏈接,支持語意搜索
- 在自然語言處理視角下,知識圖譜就是從文本中抽取語意和結構化的資料
- 在知識表示視角下,知識圖譜是采用計算機符號表示和處理知識的方法
- 在人工智能視角下,知識圖譜是利用知識庫來輔助理解人類語言的工具
- 在資料庫視角下,知識圖譜是利用圖的方式去存盤知識的方法
體系架構
知識圖譜的架構主要包括自身的邏輯結構以及體系架構,
知識圖譜在邏輯結構上可分為模式層與資料層兩個層次,
底層存盤資料三元組的邏輯層次可以被稱為資料層,通常通過本體庫來管理資料層,本體庫的概念相當于物件中“類”的概念,
而建立在資料層之上的模式層,是知識圖譜的核心,它借助本體庫來管理公理、規則和約束條件,規范物體、關系、屬性這些具體物件間的關系,
知識圖譜的體系架構是指其構建模式的結構
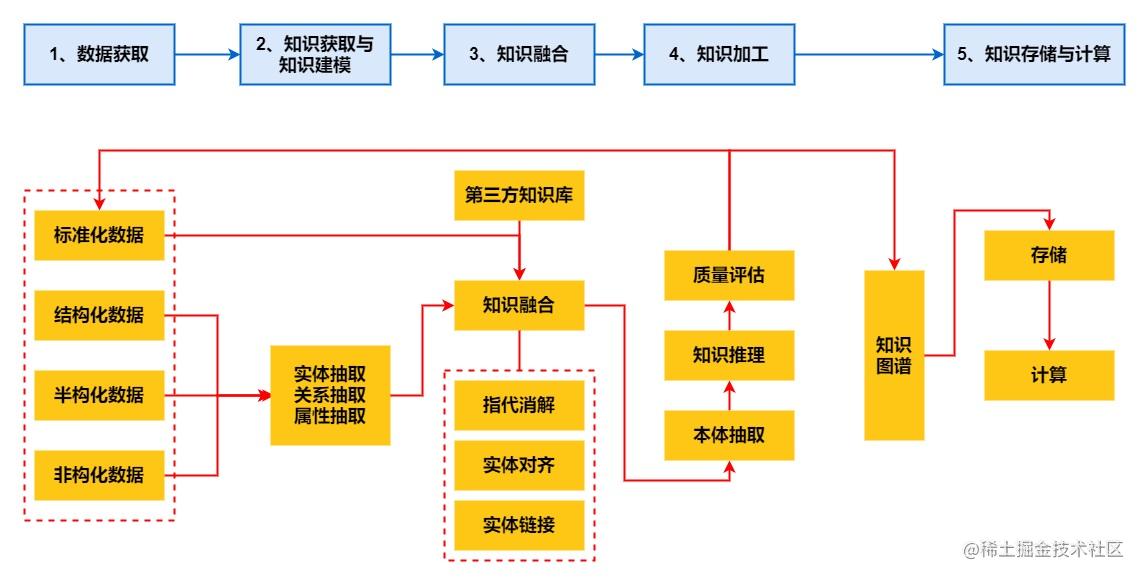
總的來說,整體程序可以分為下面5步:
- 資料獲取:主要獲取半結構化資料,為后續的物體與物體屬性構建做準備,結構化資料則為數值屬性做準備
- 知識抽取:從文本資料集中自動識別出命名物體,包括抽取人名、地名、機構名等;從語料中抽取物體之間的關系,形成關系網路;從不同的資訊源中采集特定的屬性資訊
- 知識融合:完成指示代詞與先行詞的合并;完成同一物體的歧義消除;將已識別的物體物件,無歧義地指向知識庫中的目標物體
- 知識加工:構建知識概念模塊,抽取本體;進行知識圖譜推理,并對知識圖譜的可信度進行量化評估,評估過關的知識圖譜流入知識圖譜庫中存盤,評估不過關的知識圖譜回傳一開始的資料環節進行調整,而后重復相同環節直到評估過關
- 知識存盤與計算:存盤是為了快速查詢與運用知識,需支持底層資料描述與上層計算,有的主體計算包含在存盤中
知識抽取
知識抽取主要是面向開放的鏈接資料,通過自動化的技術抽取出可用的知識單元,知識單元主要包括物體(概念的外延)、關系以及屬性3個知識要素,并以此為基礎,形成一系列高質量的事實表達,為上層模式層的構建奠定基礎,知識抽取有三個主要作業:
- 物體抽取
- 關系抽取
- 屬性抽取
物體抽取
物體抽取,在技術上更多稱為 NER(named entity recognition,命名物體識別),指的是從原始語料中自動識別出命名物體,由于物體是知識圖譜中的最基本元素,其抽取的完整性、準確、召回率等將直接影響到知識庫的質量,因此,物體抽取是知識抽取中最為基礎與關鍵的一步;這一程序還是針對不同結構的資料來看:
- 結構化資料:包括站內/垂直網站資訊、部分百科網站資訊,可以利用策略模式,將抽取的具體規則用groovy腳本來實作
- 半結構化資料:包括百科網站中的表格以及串列,可以利用基于監督學習的包裝器歸納方法進行抽取
- 非結構化資料:包括百科網站中的文本以及站內文本,可以利用自然語言處理的手段處理
關系抽取
目標是解決物體間語意鏈接的問題,早期的關系抽取主要是通過人工構造語意規則以及模板的方法識別物體關系,隨后,物體間的關系模型逐漸替代了人工預定義的語法與規則,
回顧一下我們前面提到過的知識圖譜三要素,分別是物體、關系和屬性,關系抽取我們同樣可以用一個三元組表示的RDF graph:
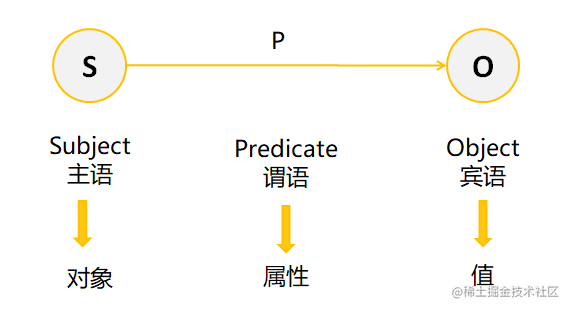
這樣的一個(S,P,O)三元組,就可以將一份知識分解為主語、謂語、賓語,這樣的SPO結構,在配合知識圖譜進行存盤時可以被用來當做存盤單元,
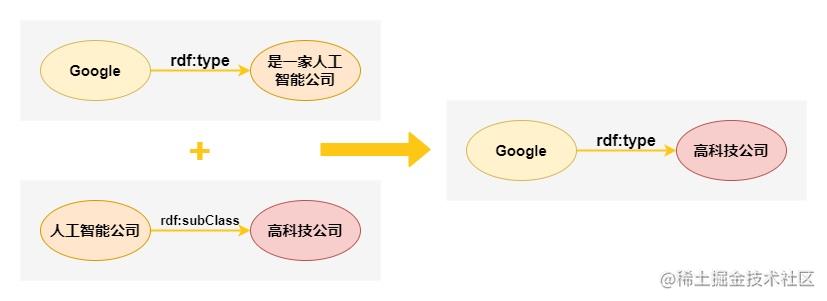
在RDF中可以宣告一些規則,從一些關系推匯出另一些關系,這些規則被稱為RDF Schema,規則可以用一些詞匯表示,如class、subClassOf、type、property、subPropertyOf、domain、range等,
下面這個例子中,節點到節點之間的關系就可以理解為前面提到的本體中的聯系,而這一關聯程序就可以被稱為知識圖譜中的推導或關聯推理:
屬性抽取
屬性抽取主要是針對物體而言的,通過屬性可形成對物體的完整勾畫,由于物體的屬性可以看成是物體與屬性值之間的一種名稱性關系,因此可以將物體屬性的抽取問題轉換為關系抽取問題,
知識融合
由于知識圖譜中的知識來源廣泛,存在知識質量良莠不齊、來自不同資料源的知識重復、知識間的關聯不夠明確等問題,所以必須要進行知識的融合,知識融合是高層次的知識組織,使來自不同知識源的知識在同一框架規范下進行異構資料整合、消歧、加工、推理驗證、更新等步驟,達到資料、資訊、方法、經驗以及人的思想的融合,形成高質量的知識庫,
其中,知識更新是一個重要的部分,人類的認知能力、知識儲備以及業務需求都會隨時間而不斷遞增,因此,知識圖譜的內容也需要與時俱進,不論是通用知識圖譜,還是行業知識圖譜,它們都需要不斷地迭代更新,擴展現有的知識,增加新的知識,
主要包括指代消解、物體對齊、物體鏈接等程序
知識補全
知識圖譜普遍存在不完備的問題,因此需要基于圖譜里已有的關系,去推理出缺失的關系,
在下面的這張知識圖譜的物體網路中,黃色的箭頭表示已經存在的關系,紅色的虛線則是缺失的關系,我們可以根據物體之間的關系,來補全缺失的e3到e4之間的關系,
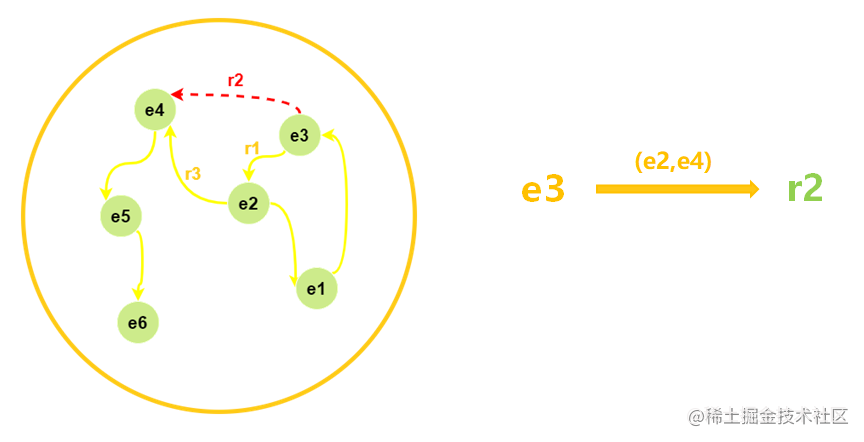
補全程序可采用基于路徑查找的方法,基于強化學習的方法,基于推理規則的方法,基于元學習的方法等等,
知識存盤
知識圖譜的存盤依賴于圖資料庫及其引擎,不同廠商的實作可能大有不同,例如可以選用的圖資料庫有RDF4j、Virtuoso、Neo4j等,例如愛奇藝的圖資料庫引擎選擇了JanusGraph,借助云平臺的Hbase和ES集群,搭建了自己的JanusGraph分布式圖資料庫引擎,
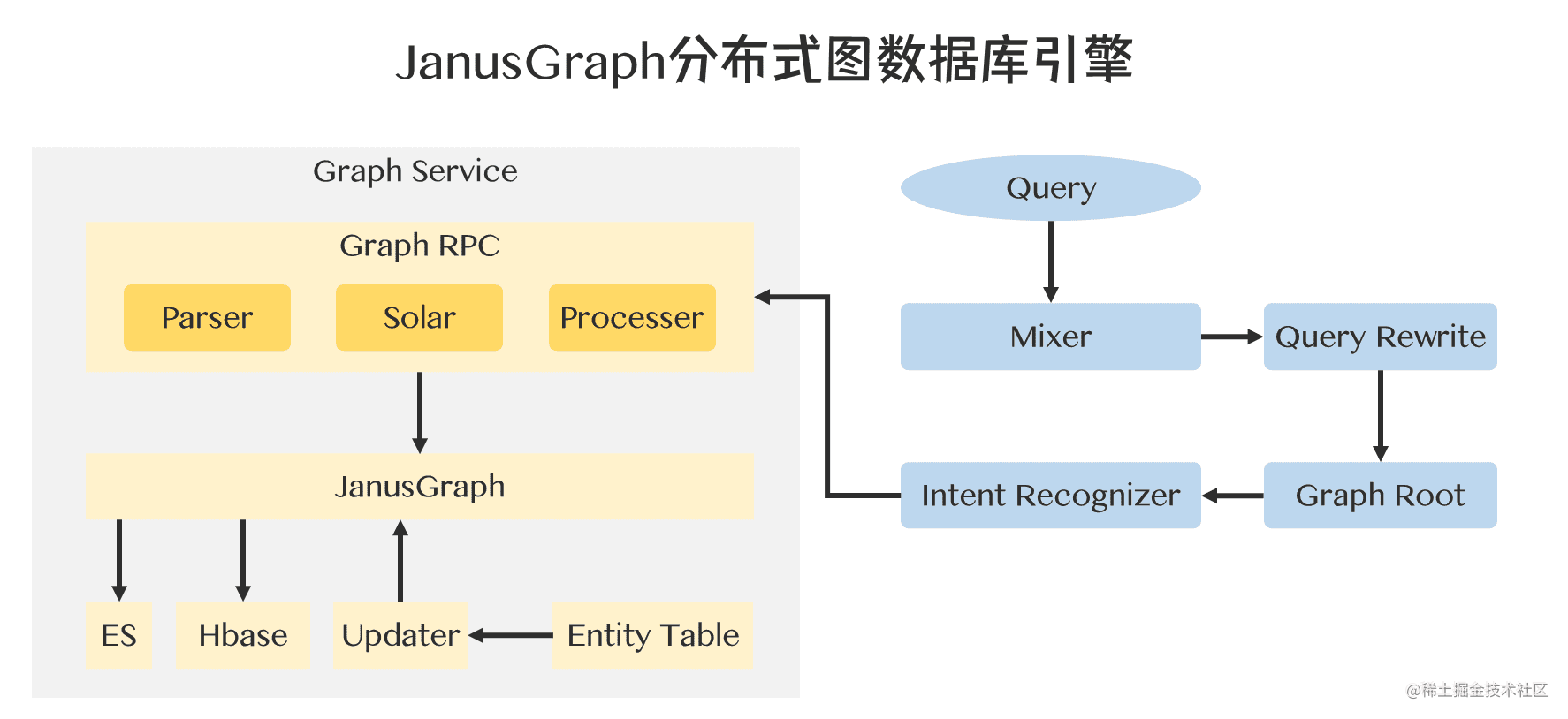
JanusGraph通過借助外部的存盤系統與外部索引系統的支持,支撐了上游的在線查詢服務,
總結
從技術來說,知識圖譜的難點在于 NLP,因為我們需要機器能夠理解海量的文字資訊,但在工程上,我們面臨更多的問題,來源于知識的獲取,知識的融合,搜索領域能做的越來越好,是因為有成千上萬(成百萬上億)的用戶,用戶在查詢的程序中,實際也在優化搜索結果,這也是為什么百度的英文搜索不可能超過 Google,因為沒有那么多英文用戶,知識圖譜也是同樣的道理,如果將用戶的行為應用在知識圖譜的更新上,才能走的更遠,
Inspiration
- 知識工程是什么-清歡不知味
- 什么是知識圖譜? - 知乎 (zhihu.com)
- 為什么需要知識圖譜?什么是知識圖譜?——KG的前世今生 - 知乎 (zhihu.com)
- 今天不寫代碼,聊聊熱門的知識圖譜 - 掘金 (juejin.cn)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/531829.html
標籤:其他
上一篇:帶你了解NLP的詞嵌入