反向傳播演算法詳細推導
反向傳播(英語:Backpropagation,縮寫為BP)是“誤差反向傳播”的簡稱,是一種與最優化方法(如梯度下降法)結合使用的,用來訓練人工神經網路的常見方法,該方法對網路中所有權重計算損失函式的梯度,這個梯度會反饋給最優化方法,用來更新權值以最小化損失函式, 在神經網路上執行梯度下降法的主要演算法,該演算法會先按前向傳播方式計算(并快取)每個節點的輸出值,然后再按反向傳播遍歷圖的方式計算損失函式值相對于每個引數的偏導數,
我們將以全連接層,激活函式采用 Sigmoid 函式,誤差函式為 Softmax+MSE 損失函式的神經網路為例,推導其梯度傳播方式,
準備作業
1、Sigmoid 函式的導數
回顧 sigmoid 函式的運算式:
\[\sigma(x) = \frac{1}{1+e^{-x}} \]
其導數為:
\[\frac{d}{dx}\sigma(x) = \frac{d}{dx} \left(\frac{1}{1+e^{-x}} \right) \]
\[= \frac{e^{-x}}{(1+e^{-x})^2} \]
\[= \frac{(1 + e^{-x})-1}{(1+e^{-x})^2} \]
\[=\frac{1+e^{-x}}{(1+e^{-x})^2} - \left(\frac{1}{1+e^{-x}}\right)^2 \]
\[= \sigma(x) - \sigma(x)^2 \]
\[= \sigma(1-\sigma) \]
可以看到,Sigmoid 函式的導數運算式最終可以表達為激活函式的輸出值的簡單運算,利
用這一性質,在神經網路的梯度計算中,通過快取每層的 Sigmoid 函式輸出值,即可在需
要的時候計算出其導數,Sigmoid 函式導數的實作:
import numpy as np # 匯入 numpy
def sigmoid(x): # sigmoid 函式
return 1 / (1 + np.exp(-x))
def derivative(x): # sigmoid 導數的計算
return sigmoid(x)*(1-sigmoid(x))
2、均方差函式梯度
均方差損失函式運算式為:
\[L = \frac{1}{2}\sum_{k=1}^{K}(y_k-o_k)^2 \]
其中\(y_k\)為真實值,\(o_k\)為輸出值,則它的偏導數\(\frac{\partial L}{\partial o_i}\) 可以展開為:
\[\frac{\partial L}{\partial o_i} = \frac{1}{2}\sum_{k=1}^{K}\frac{\partial}{\partial o_i}(y_k - o_k)^2 \]
利用鏈式法則分解為
\[\frac{\partial L}{\partial o_i} = \frac{1}{2}\sum_{k=1}^{K}\cdot2\cdot(y_k-o_k)\cdot\frac{\partial(y_k-o_k)}{\partial o_i} \]
\[\frac{\partial L}{\partial o_i} = \sum_{k=1}^{K}(y_k-o_k)\cdot(-1)\cdot\frac{\partial o_k}{\partial o_i} \]
\(\frac{\partial o_k}{\partial o_i}\)僅當 k = i 時才為 1,其他點都為 0, 也就是說 \(\frac{\partial o_k}{\partial o_i}\)只與第 i 號節點相關,與其他節點無關,因此上式中的求和符號可以去掉,均方差的導數可以推導為
\[\frac{\partial L}{\partial o_i} = (o_i - y_i) \]
單個神經元梯度
對于采用 Sigmoid 激活函式的神經元模型,它的數學模型可以寫為
\[o^1 = \sigma(w^1x+b^1) \]
其中
- 變數的上標表示層數,如 \(o^1\) 表示第一個隱藏層的輸出
x表示網路的輸入
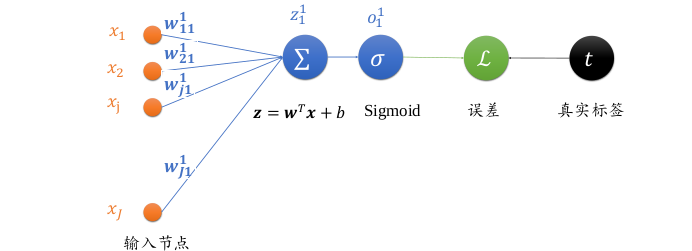
單個神經元模型如下圖所示
- 輸入節點數為
J- 其中輸入第 \(j\) 個節點到輸出 \(o^1\) 的權值連接記為 \(w^1_{j1}\)
- 上標表示權值屬于的層數,下標表示當前連接的起始節點號和終止節點號
- 如下標 \(j1\) 表示上一層的第 \(j\) 號節點到當前層的 1 號節點
- 未經過激活函式的輸出變數為 \(z_1^1\),經過激活函式之后的輸出為 \(o_1^1\)
- 由于只有一個輸出節點,故 \(o_1^1 = o^1\)
下面我們來計算均方差算是函式的梯度
由于單個神經元只有一個輸出,那么損失函式可以表示為
\[L = \frac{1}{2}(o_1^1 - t)^2 \]
添加 \(\frac{1}{2}\) 是為了計算方便,我們以權值連接的第 \(j\in[1,J]\) 號節點的權值 \(w_{j1}\) 為例,考慮損失函式 \(L\) 對其的偏導數 \(\frac{\partial L}{\partial w_{j1}}\)
\[\frac{\partial L}{\partial w_{j1}} = (o_1 - t)\frac{\partial o_1}{\partial w_{j1}} \]
由于 \(o_1 = \sigma(z_1)\) ,由上面的推導可知 Sigmoid 函式的導數 \(\sigma' = \sigma(1-\sigma)\)
\[\frac{\partial L}{\partial w_{j1}} = (o_1 - t)\frac{\partial \sigma(z_1)}{\partial w_{j1}} \]
\[= (o_1-t)\sigma(z_1)(1-\sigma(z_1))\frac{\partial z_1}{\partial w_{j1}} \]
把 \(\sigma(z_1)\) 寫成 \(o_1\)
\[= (o_1-t)o_1(1-o_1)\frac{\partial z_1}{\partial w_{j1}} \]
由于 \(\frac{\partial z_1}{\partial w_{j1}} = x_j\)
\[\frac{\partial L}{\partial w_{j1}} = (o_1-t)o_1(1-o_1)x_j \]
從上式可以看到,誤差對權值 \(w_{j1}\) 的偏導數只與輸出值 \(o_1\) 、真實值 t 以及當前權值連接的輸 \(x_j\) 有關
全鏈接層梯度
我們把單個神經元模型推廣到單層全連接層的網路上,如下圖所示,輸入層通過一個全連接層得到輸出向量 \(o^1\) ,與真實標簽向量 t 計算均方差,輸入節點數為 \(J\) ,輸出節點數為 K ,
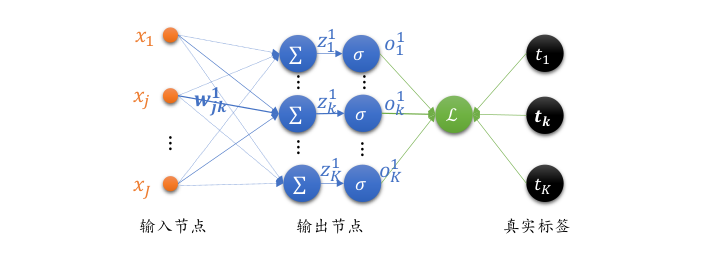
與單個神經元不同,全鏈接層有多個輸出節點 \(o_1^1, o_2^1, o_3^1,...,o_K^1\) ,每個輸出節點對應不同真實標簽 \(t_1, t_2, t_3,..., t_K\) ,均方誤差可以表示為
\[L = \frac{1}{2}\sum_{i=1}^K(o_i^1-t_i)^2 \]
由于 \(\frac{\partial L}{\partial w_{jk}}\) 只與 \(o_k^1\) 有關聯,上式中的求和符號可以去掉,即 \(i = k\)
\[\frac{\partial L}{\partial w_{jk}} = (o_k-t_k)\frac{\partial o_k}{\partial w_{jk}} \]
將 \(o_k=\sigma(z_k)\) 帶入
\[\frac{\partial L}{\partial w_{jk}} = (o_k-t_k)\frac{\partial \sigma(z_k)}{\partial w_{jk}} \]
考慮 \(Sigmoid\) 函式的導數 \(\sigma' = \sigma(1-\sigma)\)
\[\frac{\partial L}{\partial w_{jk}} = (o_k-t_k)\sigma(z_k)(1-\sigma(z_k))\frac{\partial z_k^1}{\partial w_{jk}} \]
將 \(\sigma(z_k)\) 記為 \(o_k\)
\[\frac{\partial L}{\partial w_{jk}} = (o_k-t_k)o_k(1-o_k)\frac{\partial z_k^1}{\partial w_{jk}} \]
最終可得
\[\frac{\partial L}{\partial w_{jk}} = (o_k-t_k)o_k(1-o_k)\cdot x_j \]
由此可以看到,某條連接 \(w_{jk}\) 上面的連接,只與當前連接的輸出節點 \(o_k^1\) ,對應的真實值節點的標簽 \(t_k^1\) ,以及對應的輸入節點 x 有關,
我們令 \(\delta_k = (o_k-t_k)o_k(1-o_k)\) ,則 \(\frac{\partial L}{\partial w_{jk}}\) 可以表達為
\[\frac{\partial L}{\partial w_{jk}}=\delta_k\cdot x_j \]
其中 \(\delta _k\) 變數表征連接線的終止節點的梯度傳播的某種特性,使用 \(\delta_k\) 表示后,\(\frac{\partial L}{\partial w_{jk}}\) 偏導數只與當前連接的起始節點 \(x_j\),終止節點處 \(\delta_k\) 有關,理解起來比較直觀,
反向傳播演算法
看到這里大家也不容易,畢竟這么多公式哈哈哈,不過激動的時刻到了
先回顧下輸出層的偏導數公式
\[\frac{\partial L}{\partial w_{jk}} = (o_k-t_k)o_k(1-o_k)\cdot x_j = \delta_k \cdot x_j \]
多層全連接層如下圖所示
- 輸出節點數為
K,輸出 \(o^k = [o_1^k, o_2^k, o_3^k,..., o_k^k]\) - 倒數的二層的節點數為
J,輸出為 \(o^J=[o_1^J, o_2^J,..., o_J^J]\) - 倒數第三層的節點數為
I,輸出為 \(o^I = [o_1^I, o_2^I,..., o_I^I]\)
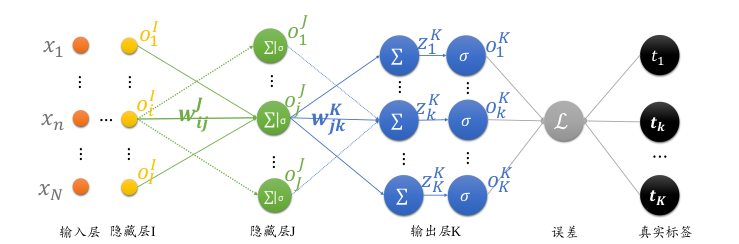
均方誤差函式
\[\frac{\partial L}{\partial w_{ij}}=\frac{\partial}{\partial w_{ij}}\frac{1}{2}\sum_{k}(o_k-t_k)2 \]
由于 \(L\) 通過每個輸出節點 \(o_k\) 與 \(w_i\) 相關聯,故此處不能去掉求和符號
\[\frac{\partial L}{\partial w_{ij}}=\sum_k(o_k-t_k)\frac{\partial o_k}{\partial w_{ij}} \]
將 \(o_k=\sigma(z_k)\) 帶入
\[\frac{\partial L}{\partial w_{ij}}=\sum_k(o_k-t_k)\frac{\partial \sigma(z_k)}{\partial w_{ij}} \]
\(Sigmoid\) 函式的導數 \(\sigma' = \sigma(1-\sigma)\) ,繼續求導,并將 \(\sigma(z_k)\) 寫回 \(o_k\)
\[\frac{\partial L}{\partial w_{ij}}=\sum_k(o_k-t_k)o_k(1-o_k)\frac{\partial z_k}{\partial w_{ij}} \]
對于 \(\frac{\partial z_k}{\partial w_{ij}}\) 可以應用鏈式法則分解為
\[\frac{\partial z_k}{\partial w_{ij}} = \frac{\partial z_k}{o_j}\cdot \frac{\partial o_j}{\partial w_{ij}} \]
由圖可知 \(\left(z_k = o_j \cdot w_{jk} + b_k\right)\) ,故有
\[\frac{\partial z_k}{o_j} = w_{jk} \]
所以
\[\frac{\partial L}{\partial w_{ij}}=\sum_k(o_k-t_k)o_k(1-o_k)w_{jk}\cdot\frac{\partial o_j}{\partial w_{ij}} \]
考慮到 \(\frac{\partial o_j}{\partial w_{ij}}\) 與 k 無關,可將其提取出來
\[\frac{\partial L}{\partial w_{ij}}=\frac{\partial o_j}{\partial w_{ij}}\cdot\sum_k(o_k-t_k)o_k(1-o_k)w_{jk} \]
再一次有 \(o_k=\sigma(z_k)\) ,并利用 \(Sigmoid\) 函式的導數 \(\sigma' = \sigma(1-\sigma)\) 有
\[\frac{\partial L}{\partial w_{ij}}= o_j(1-o_j)\frac{\partial z_j}{\partial w_{ij}} \cdot\sum_k(o_k-t_k)o_k(1-o_k)w_{jk} \]
由于 \(\frac{\partial z_j}{\partial w_{ij}} = o_i \left(z_j = o_i\cdot w_{ij} + b_j\right)\)
\[\frac{\partial L}{\partial w_{ij}}= o_j(1-o_j)o_i \cdot\sum_k(o_k-t_k)o_k(1-o_k)w_{jk} \]
其中 \(\delta _k^K = (o_k-t_k)o_k(1-o_k)\) ,則
\[\frac{\partial L}{\partial w_{ij}}= o_j(1-o_j)o_i \cdot\sum_k\delta _k^K\cdot w_{jk} \]
仿照輸出層的書寫方式,定義
\[\delta_j^J = o_j(1-o_j) \cdot \sum_k \delta _k^K\cdot w_{jk} \]
此時 \(\frac{\partial L}{\partial w_{ij}}\) 可以寫為當前連接的起始節點的輸出值 \(o_i\) 與終止節點 \(j\) 的梯度資訊 \(\delta _j^J\) 的簡單相乘運算:
\[\frac{\partial L}{\partial w_{ij}} = \delta_j^J\cdot o_i^I \]
通過定義 \(\delta\) 變數,每一層的梯度運算式變得更加清晰簡潔,其中 $ \delta $ 可以簡單理解為當前連接 \(w_{ij}\) 對誤差函式的貢獻值,
總結
輸出層:
\[\frac{\partial L}{\partial w_{jk}} = \delta _k^K\cdot o_j \]
\[\delta _k^K = (o_k-t_k)o_k(1-o_k) \]
倒數第二層:
\[\frac{\partial L}{\partial w_{ij}} = \delta _j^J\cdot o_i \]
\[\delta_j^J = o_j(1-o_j) \cdot \sum_k \delta _k^K\cdot w_{jk} \]
倒數第三層:
\[\frac{\partial L}{\partial w_{ni}} = \delta _i^I\cdot o_n \]
\[\delta _i^I = o_i(1-o_i)\cdot \sum_j\delta_j^J\cdot w_{ij} \]
其中 \(o_n\) 為倒數第三層的輸入,即倒數第四層的輸出
依照此規律,只需要回圈迭代計算每一層每個節點的 \(\delta _k^K, \delta_j^J, \delta_i^I,...\) 等值即可求得當前層的偏導數,從而得到每層權值矩陣 \(W\) 的梯度,再通過梯度下降演算法迭代優化網路引數即可,
好了,反向傳播演算法推導完畢,代碼實作可以參考另一篇博客神經網路之反向傳播演算法(BP)代碼實作
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53523.html
標籤:其他