這篇文章是閱讀AMiner《2018自然語言處理研究報告》前幾篇內容整理所得,
一. 自然語言處理概述
自然語言處理就是要計算機理解自然語言,計算機要理解自然語言文本的意義,最后能以自然文本形式來表達意圖,處理程序主要是理解、轉化、生成,
自然語言的理解和分析是一個層次化的程序,許多語言學家把這一程序分為五個層次, 可以更好地體現語言本身的構成,五個層次分別是
語音分析、詞法分析、句法分析、語意分析和語用分析,
自然語言處理的研究可以分為基礎性研究和應用性研究兩部分,語音和文本是兩類 研究的重點,
ACL、EMNLP、NAACL、COLING 4個會議是自然語言處理最重要的4個會議,
二. 自然語言處理發展歷程
1950年“圖靈測驗”到70年代前,這時的自然語言處理停留在理性主義思潮階段,以基于規則的方法為代表,
70年代后互聯網高速發展,自然語言處理思潮由經驗主義向理性主義過渡,基于統計的方法逐漸代替了基于規則的方 法,
從 2008 年到現在,在影像識別和語音識別領域的成果激勵下,人們也逐漸開始引入深度學習來做自然語言處理研究,
三. 自然語言處理技術

自然語言處理的基礎研究方面,自然語言的基礎技術包括詞匯、短語、 句子和篇章級別的表示,分詞、句法分析和語意分析以及語言認知模型和知識圖譜等,
基礎技術
-
詞法分析
主要任務是詞性標注和詞義標注, -
句法分析
主要任務是判斷句子的句法結構和組成句子的各成分,明確它們之間的相互關系, -
語意分析
主要任務是根據句子的句法結構和句子中每個實詞的詞義推匯出能夠反映這個句子意義的形式化表示, -
語用分析
語用指人對語言的具體運用,主要任務是研究和分析語言使用者的真正用意,它與語境、語言使用者的知識涵養、言語行為、想法和意圖是分不開的,是對自然語言的深層理解,情景語境和文化語境是語境分析主要涉及的方面, -
篇章分析
將研究擴展到句子的界限之外,主要任務是對段落和整篇文章進行理解和分析, -
知識圖譜
表示知識,描述客觀世界的概念、物體、事件等之間關系的一種表示形式,知識圖譜在表現形式上與語意網路比較類似,不同的是,語意網路側重于表示概念與概念之間的關系,而知識圖譜更側重于表述物體之間的關系,現在的知識網路被用來泛指大規模的知識庫,
除此之外,自然語言的基礎研究還涉及詞義消歧、指代消解、命名物體識別等方面的研究,
應用技術
-
機器翻譯
指運用機器,通過特定的計算機程式將一種書寫形式或聲音形式的自然語言,翻譯成另一種書寫形式或聲音形式的自然語言,按照媒介可以將機器翻譯分為文本翻譯、語音翻譯、影像翻譯以及視頻和 VR 翻譯等, -
資訊檢索
從相關檔案集合中查找用戶所需資訊的程序,先將資訊按一定的方式組織和存盤起來,然后根據用戶的需求從已經存盤的檔案集合當中找出相關的資訊,這是廣義的資訊檢索,資訊檢索包括“存”與“取”兩個方面,對資訊進行收集、標引、描述、組織,進行有 14 序的存放是“存”,按照某種查詢機制從有序存放的資訊集合(資料庫)中找出用戶所需資訊或獲取其線索的程序是“取”,搜索引擎可以看成是一種特殊且重要的資訊檢索系統, -
情感分析
又稱意見挖掘,是指通過計算技術對文本的主客觀性、觀點、情緒、極性的挖掘和分析,對文本的情感傾向做出分類判斷,情感分析是自然語言理解領域的重要分支,涉及統計學、語言學、心理學、人工智能等領域的理論與方法,情感分析在電商評價、互聯網輿情分析、選舉預測等地方發揮重要作用, -
自動問答
指利用計算機自動回答用戶所提出的問題以滿足用戶知識需求的任務,問答系統是資訊服務的一種高級形式,系統反饋給用戶的不再是基于關鍵詞匹配排序的檔案串列,而是精準的自然語言答案,這和搜索引擎提供給用戶模糊的反饋是不同的, -
自動文摘
運用計算機技術,依據用戶需求從源文本中提取最重要的資訊內容,進行精簡、提煉和總結,最后生成一個精簡版本的程序,生成的文摘具有壓縮性、內容完整性和可讀性, -
社會計算
也稱計算社會學,是指在互聯網的環境下,以現代資訊技術為手段,以社會科學理論為指導,幫助人們分析社會關系,挖掘社會知識,協助社會溝通,研究社會規律,破解社會難題的學科,社會媒體是社會計算的主要工具和手段,社會網路是一種關系網路,通過個人與群體及其相互之間的關系和互動,發現它們的組織特點、行為方式等特征,進而研究人群的社會結構,以利于他們之間的進一步共享、交流與協作, -
資訊抽取
主要是指從文本中抽取出特定的事實資訊,與之關系密切的是資訊檢索,資訊檢索主要是要從大量的檔案中找到用戶所需要的檔案,而資訊抽取是獲取用戶感興趣或所需要的事實資訊,這就需要對文本有深入的理解和分析,資訊檢索的結果可以作為資訊抽取的范圍,提高效率,資訊抽取用于資訊檢索可以提高檢索質量,更好地滿足用戶的需求,
四. 自然語言處理機構
下面列舉的是自然語言處理方向研究較好的一些機構,
工業界
國外: google、微軟亞洲研究院、Facebook
國內:百度、阿里、騰訊、京東、科大訊飛
國外學術界
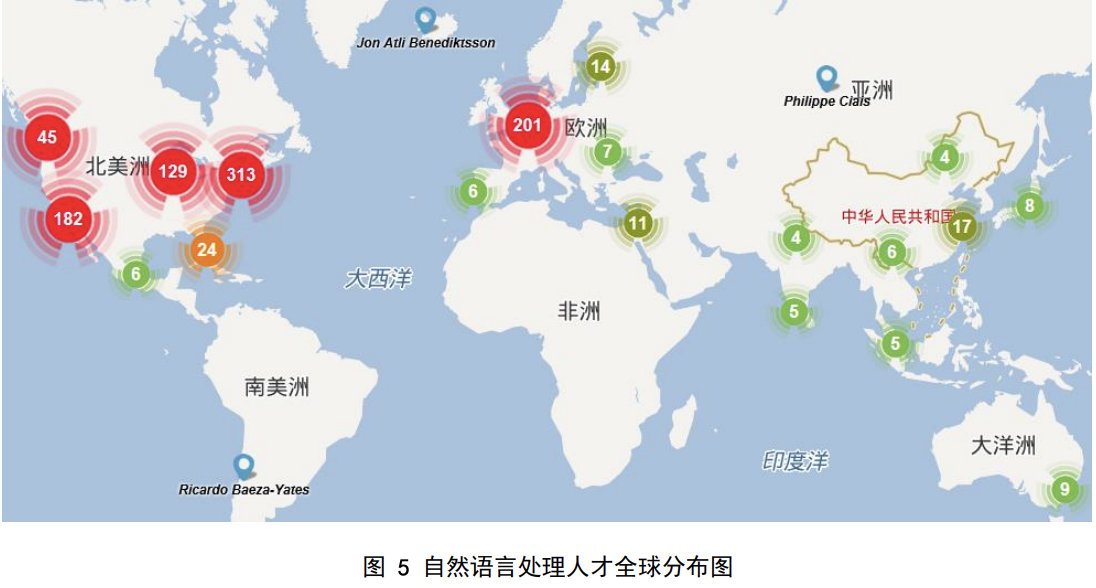
從國家來看,美國是自然語言處理研究學者聚集 最多的國家,英國、德國、加拿大和意大利緊隨其后;從地區來看,美國東部是自然語言處理人才的集中地,而西歐、美國西部等其他先進地區也吸引了大量自然語言處理的研究者,
國內學術界
- 清華大學
- 北京大學
- 中科院
- 哈爾濱工業大學
- 復旦大學
- 蘇州大學
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53531.html
標籤:其他