出門旅行,訂酒店是必不可少的一個環節,住得干凈、舒心對于每個出門在外的人來說都非常重要,
在線預訂酒店讓這件事更加方便,當用戶在馬蜂窩打開一家選中的酒店時,不同供應商提供的預訂資訊會形成一個聚合串列準確地展示給用戶,這樣做首先避免同樣的資訊多次展示給用戶影響體驗,更重要的是幫助用戶進行全網酒店實時比價,快速找到性價比最高的供應商,完成消費決策,
酒店聚合能力的強弱,決定著用戶預訂酒店時可選價格的「厚度」,進而影響用戶個性化、多元化的預訂體驗,為了使酒店聚合更加實時、準確、高效,現在馬蜂窩酒店業務中近 80% 的聚合任務都是由機器自動完成,本文將詳細闡述酒店聚合是什么,以及時下熱門的機器學習技術在酒店聚合中是如何應用的,
Part.1 應用場景和挑戰
1.酒店聚合的應用場景
馬蜂窩酒旅平臺接入了大量的供應商,不同供應商會提供很多相同的酒店,但對同一酒店的描述可能會存在差異,比如:
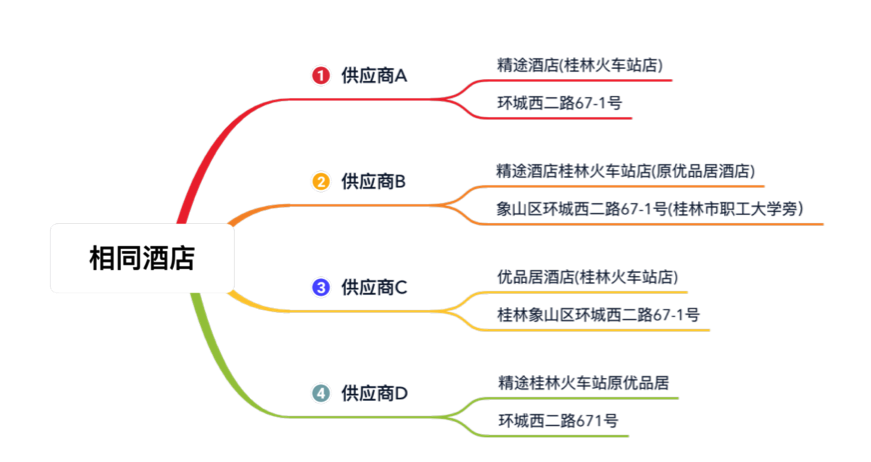
酒店聚合要做的,就是將這些來自不同供應商的酒店資訊聚合在一起集中展示給用戶,為用戶提供一站式實時比價預訂服務:

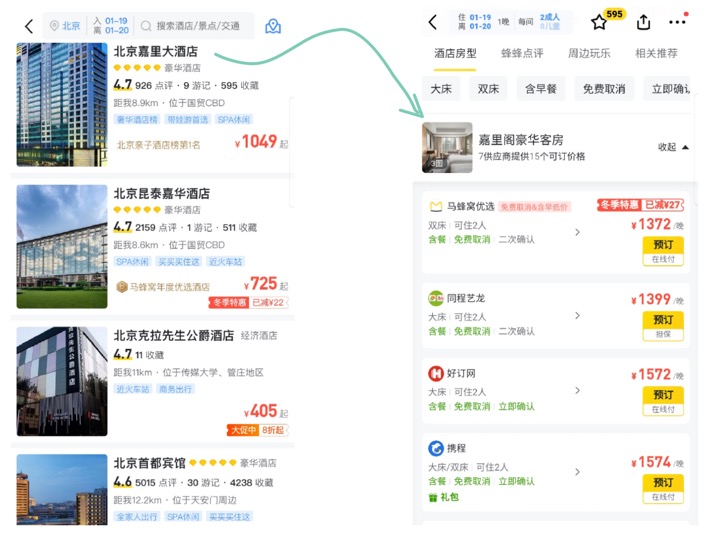
下圖為馬蜂窩對不同供應商的酒店進行聚合后的展示,不同供應商的報價一目了然,用戶進行消費決策更加高效、便捷,
2.挑戰
(1) 準確性
上文說過,不同供應商對于同一酒店的描述可能存在偏差,如果聚合出現錯誤,就會導致用戶在 App 中看到的酒店不是實際想要預訂的:
![]()
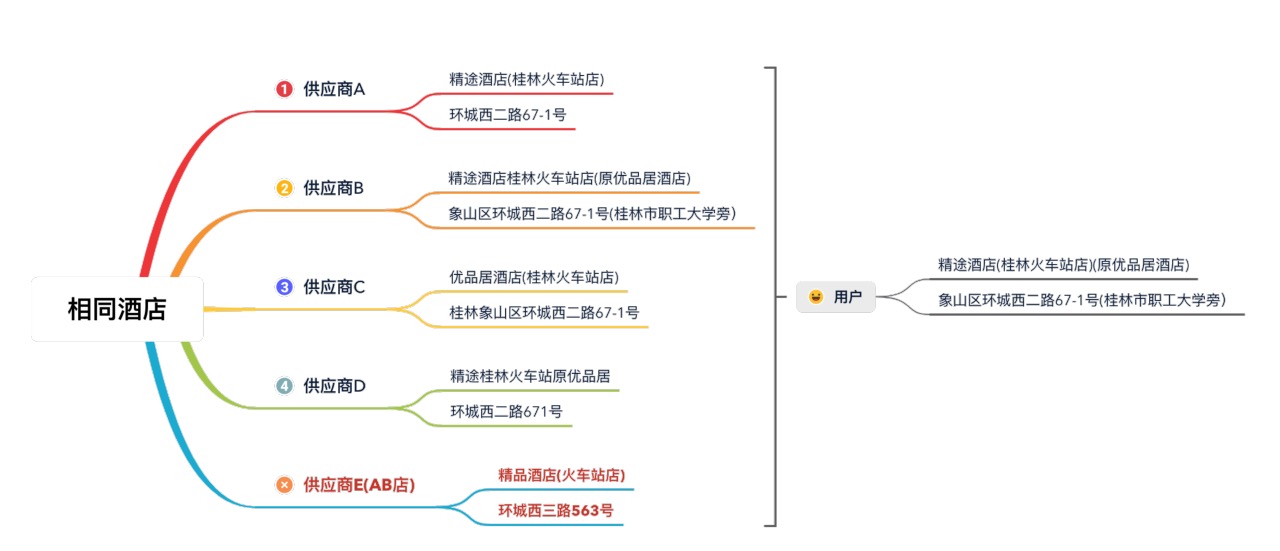
在上圖中,用戶在 App 中希望打開的是「精途酒店」,但系統可能為用戶訂到了供應商 E 提供的「精品酒店」,對于這類聚合錯誤的酒店我們稱之為 「AB 店」,可以想象,當到店后卻發現沒有訂單,這無疑會給用戶體驗造成災難性的影響,
(2) 實時性
解決上述問題,最直接的方式就是全部采取人工聚合,人工聚合可以保證高準確率,在供應商和酒店資料量還不是那么大的時候是可行的,
但馬蜂窩對接的是全網供應商的酒店資源,采用人工的方式聚合處理得會非常慢,一來會造成一些酒店資源沒有聚合,無法為用戶展示豐富的預訂資訊;二是如果價格出現波動,無法為用戶及時提供當前報價,而且還會耗費大量的人力資源,
酒店聚合的重要性顯而易見,但隨著業務的發展,接入的酒店資料快速增長,越來越多的技術難點和挑戰接踵而來,
Part.2 初期方案:余弦相似度演算法
初期我們基于余弦相似度演算法進行酒店聚合處理,以期降低人工成本,提高聚合效率,
通常情況下,有了名稱、地址、坐標這些資訊,我們就能對一家酒店進行唯一確定,當然,最容易想到的技術方案就是通過比對兩家酒店的名稱、地址、距離來判斷是否相同,
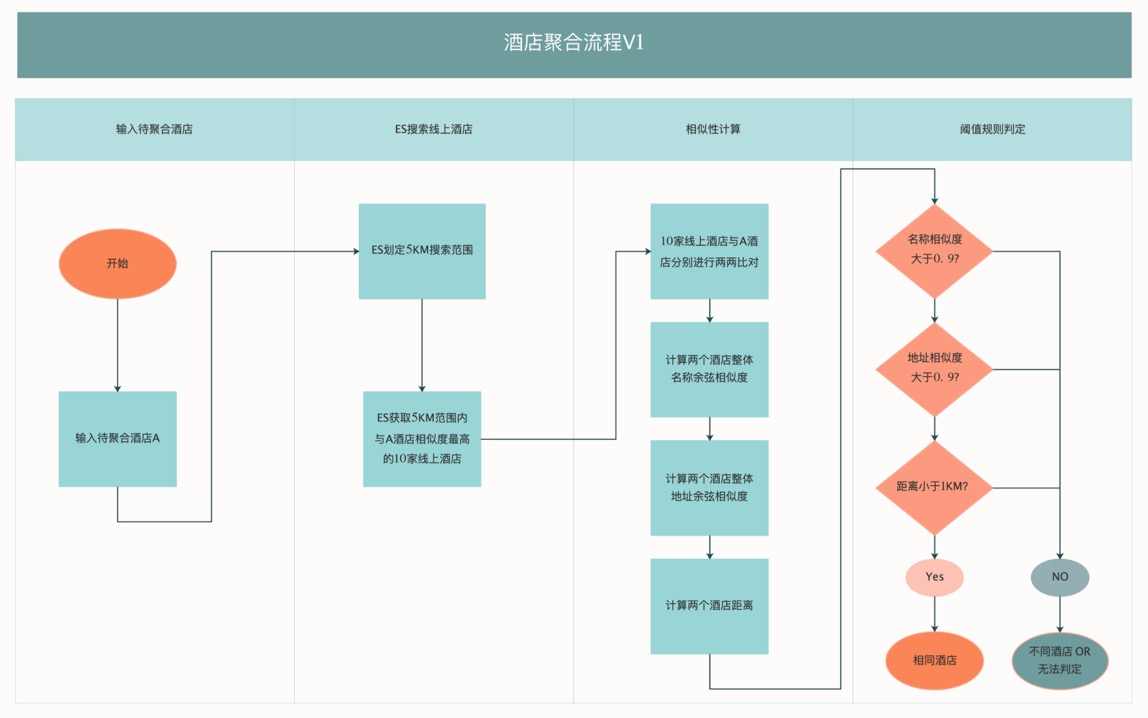
基于以上分析,我們初版技術方案的聚合流程為:
-
輸入待聚合酒店 A;
-
ES 搜索與 A 酒店相距 5km 范圍內相似度最高的 N 家線上酒店;
-
N 家酒店與 A 酒店分別開始進行兩兩比對;
-
酒店兩兩計算整體名稱余弦相似度、整體地址余弦相似度、距離;
-
通過人工制定相似度、距離的閾值來得出酒店是否相同的結論,
整體流程示意圖如下:
「酒店聚合流程 V1」上線后,我們驗證了這個方案是可行的,它最大的優點就是簡單,技術實作、維護成本很低,同時機器也能自動處理部分酒店聚合任務,相比完全人工處理更加高效及時,
但也正是因為這個方案太簡單了,問題也同樣明顯,我們來看下面的例子 (圖中資料虛構,僅為方便舉例):
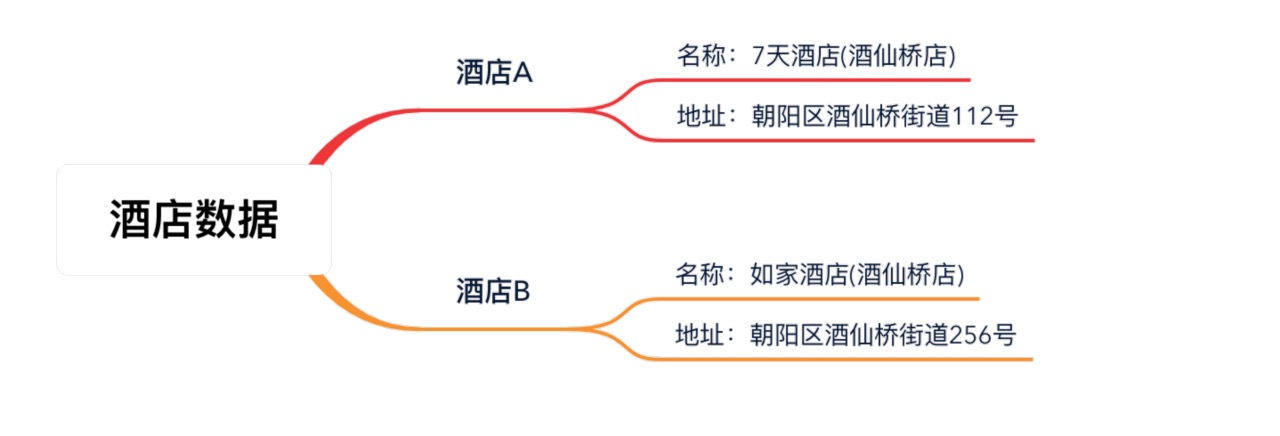
![]()
相信我們每個人都可以很快判斷出這是兩家不同的酒店,但是當機器進行整體的相似度計算時,得到的數值并不低:![]()
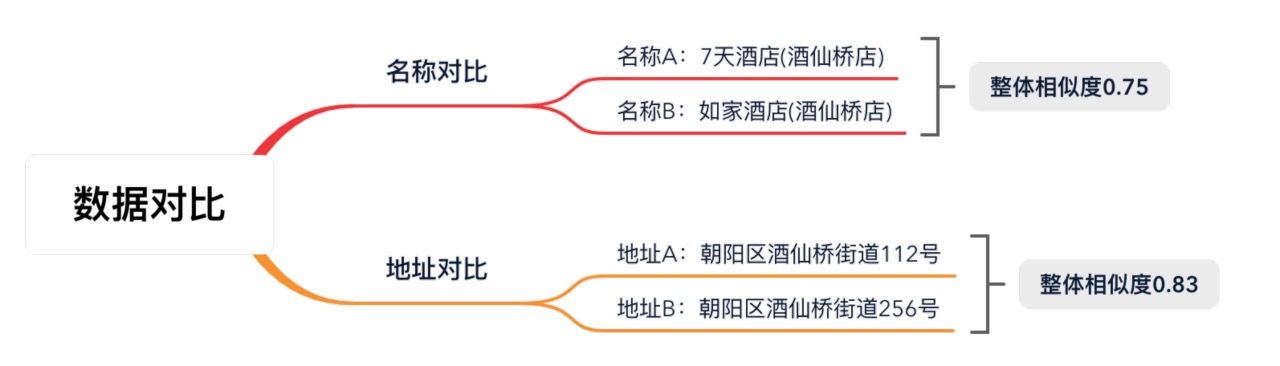
為了降低誤差率,我們需要將相似度比對的閾值提升至一個較高的指標范圍內,因此大量的相似酒店都不會自動聚合,仍需要人工處理,
最后,此版方案機器能自動處理的部分只占到約 30%,剩余 70% 仍需要人工處理;且機器自動聚合準確率約為 95%,也就是有 5% 的概率會產生 AB 店,用戶到店無單,入住體驗非常不好,
于是,伴隨著機器學習的興起,我們開始了將機器學習技術應用于酒店聚合中的探索之旅,來解決實時性和準確性這對矛盾,
Part.3 機器學習在酒店聚合中的應用
下面我將結合酒店聚合業務場景,分別從機器學習中的分詞處理、特征構建、演算法選擇、模型訓練迭代、模型效果來一一介紹,
3.1 分詞處理
之前的方案通過比對「整體名稱、地址」獲取相似度,粒度太粗,
分詞是指對酒店名稱、地址等進行文本切割,將整體的字串分為結構化的資料,目的是解決名稱、地址整體比對粒度太粗的問題,同時也為后面構建特征向量做準備,
3.1.1 分詞詞典
在聊具體的名稱、地址分詞之前,我們先來聊一下分詞詞典的構建,現有分詞技術一般都基于詞典進行分詞,詞典是否豐富、準確,往往決定了分詞結果的好壞,
在對酒店的名稱分詞時,我們需要使用到酒店品牌、酒店型別詞典,如果純靠人工維護的話,需要耗費大量的人力,且效率較低,很難維護出一套豐富的詞典,
在這里我們使用統計的思想,采用機器+人工的方式來快速維護分詞詞典:
-
隨機選取 100000+酒店,獲取其名稱資料;
-
對名稱從后往前、從前往后依次逐級切割;
-
每一次切割獲取切割詞且切割詞的出現頻率+1;
-
出現頻率較高的詞,往往就是酒店品牌詞或型別詞,
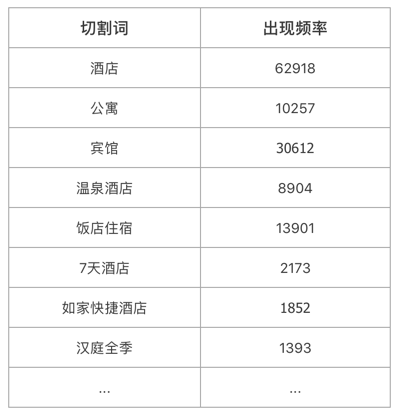
上表中示意的是出現頻率較高的詞,得到這些詞后再經過人工簡單篩查,很快就能構建出酒店品牌、酒店型別的分詞詞典,
3.1.2 名稱分詞
想象一下人是如何比對兩家酒店名稱的?比如:
-
A:7 天酒店 (酒仙橋店)
-
B:如家酒店 (望京店)
首先,因為經驗知識的存在,人會不自覺地進行「先分詞后對比」的判斷程序,即:
-
7 天--->如家
-
酒店--->酒店
-
酒仙橋店--->望京店
所以要想對比準確,我們得按照人的思維進行分詞,經過對大量酒店名稱進行人工模擬分詞,我們對酒店名稱分為如下結構化欄位:
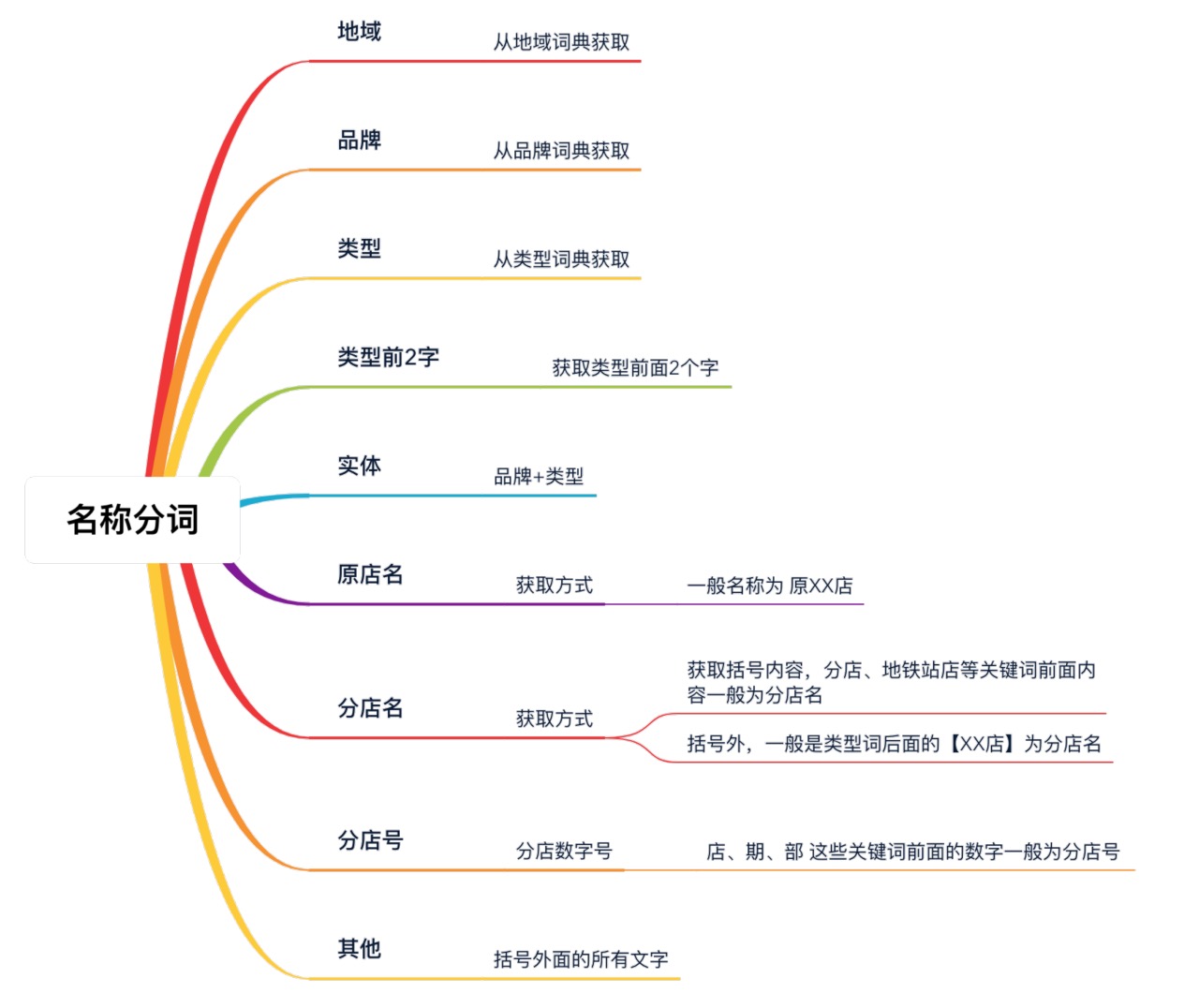
著重說下「型別前 2 字」這個欄位,假如我們需要對如下 2 家酒店名稱進行分詞:
-
酒店 1:龍門南昆山碧桂園紫來龍庭溫泉度假別墅
-
酒店 2:龍門南昆山碧桂園瀚名居溫泉度假別墅
分詞效果如下:![]()

我們看到分詞后各個欄位相似度都很高,但型別前 2 字分別為:
-
酒店 1 型別前 2 字:龍庭
-
酒店 2 型別前 2 字:名居
這種情況下此欄位 (型別前 2 字) 具有極高的區分度,因此可以作為一個很高效的對位元征,
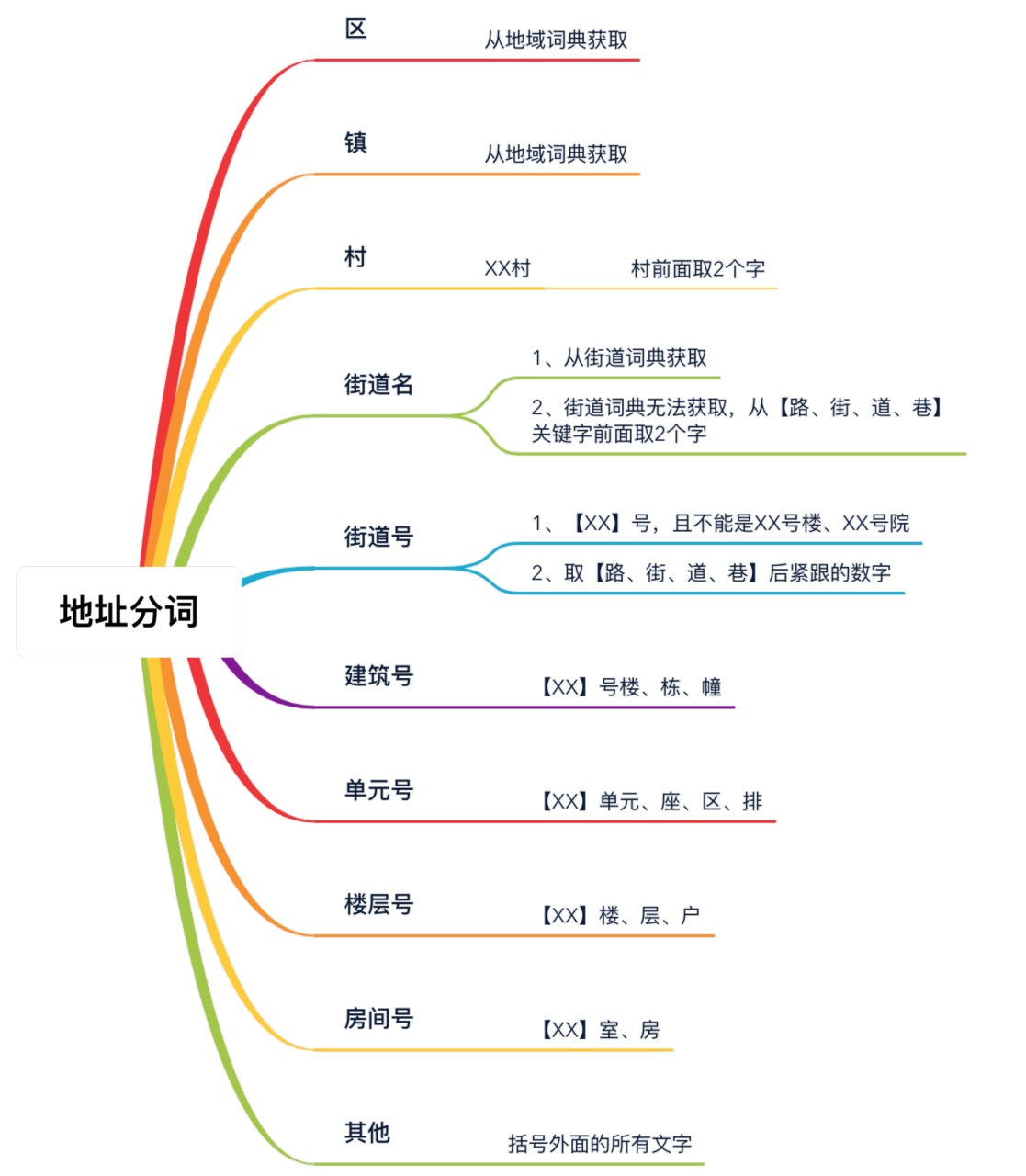
3.1.3 地址分詞
同樣,模擬人的思維進行地址分詞,使之地址的比對粒度更細更具體,具體分詞方式見下圖:
下面是具體的分詞效果展示如下:
小結
分詞解決了對比粒度太粗的缺點,現在我們大約有了 20 個對比維度,但對比規則、閾值怎么確定呢?
人工制定規則、閾值存在很多缺點,比如:
-
規則多變,20 個對比維度進行組合會出現 N 個規則,人工不可能全部覆寫這些規則;
-
人工制定閾值容易受「經驗主義」先導,容易出現誤判,
所以,對比維度雖然豐富了,但規則制定的難度相對來說提升了 N 個數量級,機器學習的出現,正好可以彌補這個缺點,機器學習通過大量訓練資料,從而學習到多變的規則,有效解決人基本無法完成的任務,
下面我們來詳細看下特征構建以及機器學習的程序,
3.2 特征構建
我們花了很大的力氣來模擬人的思維進行分詞,其實也是為構建特征向量做準備,
特征構建的程序其實也是模擬人思維的一個程序,目的是針對分詞的結構化資料進行兩兩比對,將比對結果數字化以構造特征向量,為機器學習做準備,
對于不同供應商,我們確定能拿到的資料主要包括酒店名稱、地址、坐標經緯度,可能獲得的資料還包括電話和郵箱,
經過一系列資料調研,最終確定可用的資料為名稱、地址、電話,主要是:因為
-
部分供應商經緯度坐標系有問題,精準度不高,因此我們暫不使用,但待聚合酒店距離限制在 5km 范圍內;
-
郵箱覆寫率較低,暫不使用,
要注意的是,名稱、地址拓展對比維度主要基于其分詞結果,但電話資料加入對比的話首先要進行電話資料格式的清洗,
最終確定的特征向量大致如下,因為相似度演算法比較簡單,這里不再贅述:

3.3 演算法選擇:決策樹
判斷酒店是否相同,很明顯這是有監督的二分類問題,判斷標準為:
-
有人工標注的訓練集、驗證集、測驗集;
-
輸入兩家酒店,模型回傳的結果只分為「相同」或「不同」兩類情況,
經過對多個現有成熟演算法的對比,我們最終選擇了決策樹,核心思想是根據在不同 Feature 上的劃分,最終得到決策樹,每一次劃分都向減小資訊熵的方向進行,從而做到每一次劃分都減少一次不確定性,這里摘錄一張圖片,方便大家理解:

(圖源:《機器學習西瓜書》)
3.3.1 Ada Boosting OR Gradient Boosting
具體的演算法我們選擇的是 Boosting,「三個臭皮匠,頂過諸葛亮」這句話是對 Boosting 很好的描述,Boosting 類似于專家會診,一個人決策可能會有不確定性,可能會失誤,但一群人最終決策產生的誤差通常就會非常小,
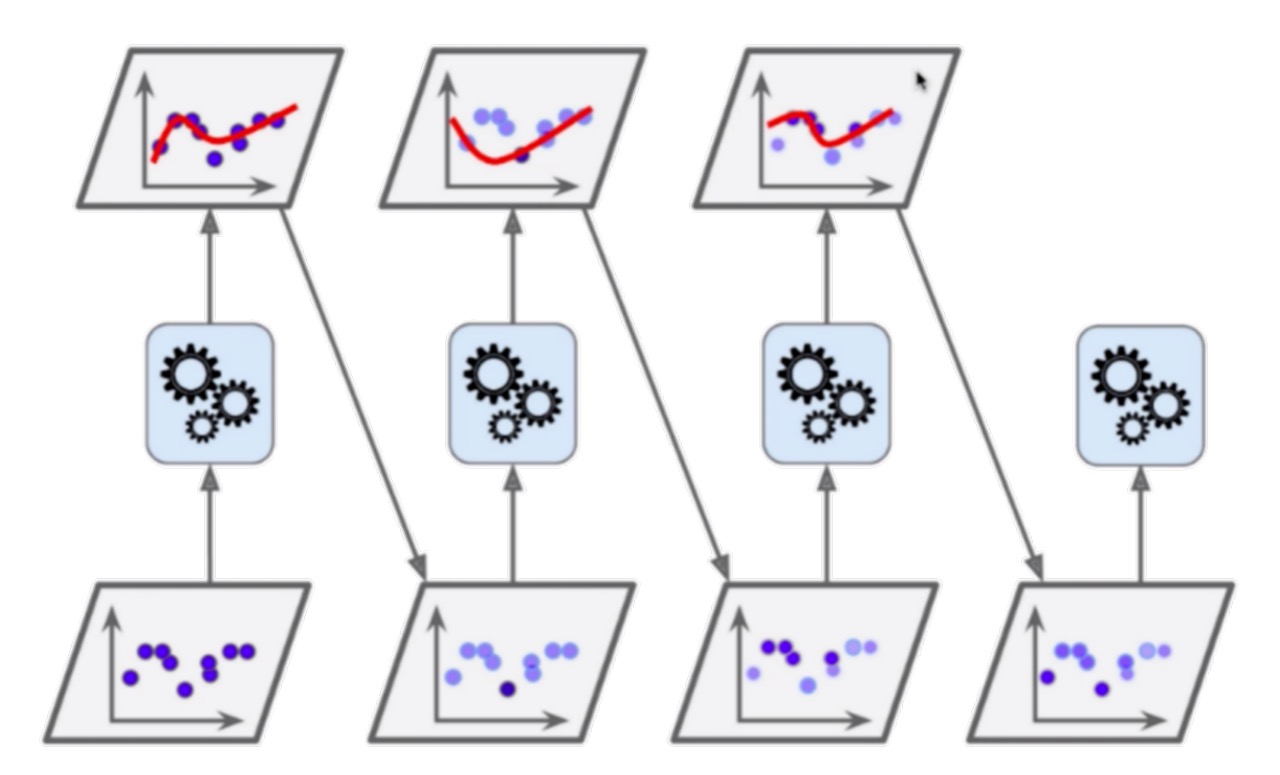
Boosting 一般以樹模型作為基礎,其分類目前主要為 Ada Boosting、Gradient Boosting,Ada Boosting初次得出來一個模型,存在無法擬合的點,然后對無法擬合的點提高權重,依次得到多個模型,得出來的多個模型,在預測的時候進行投票選擇,如下圖所示:
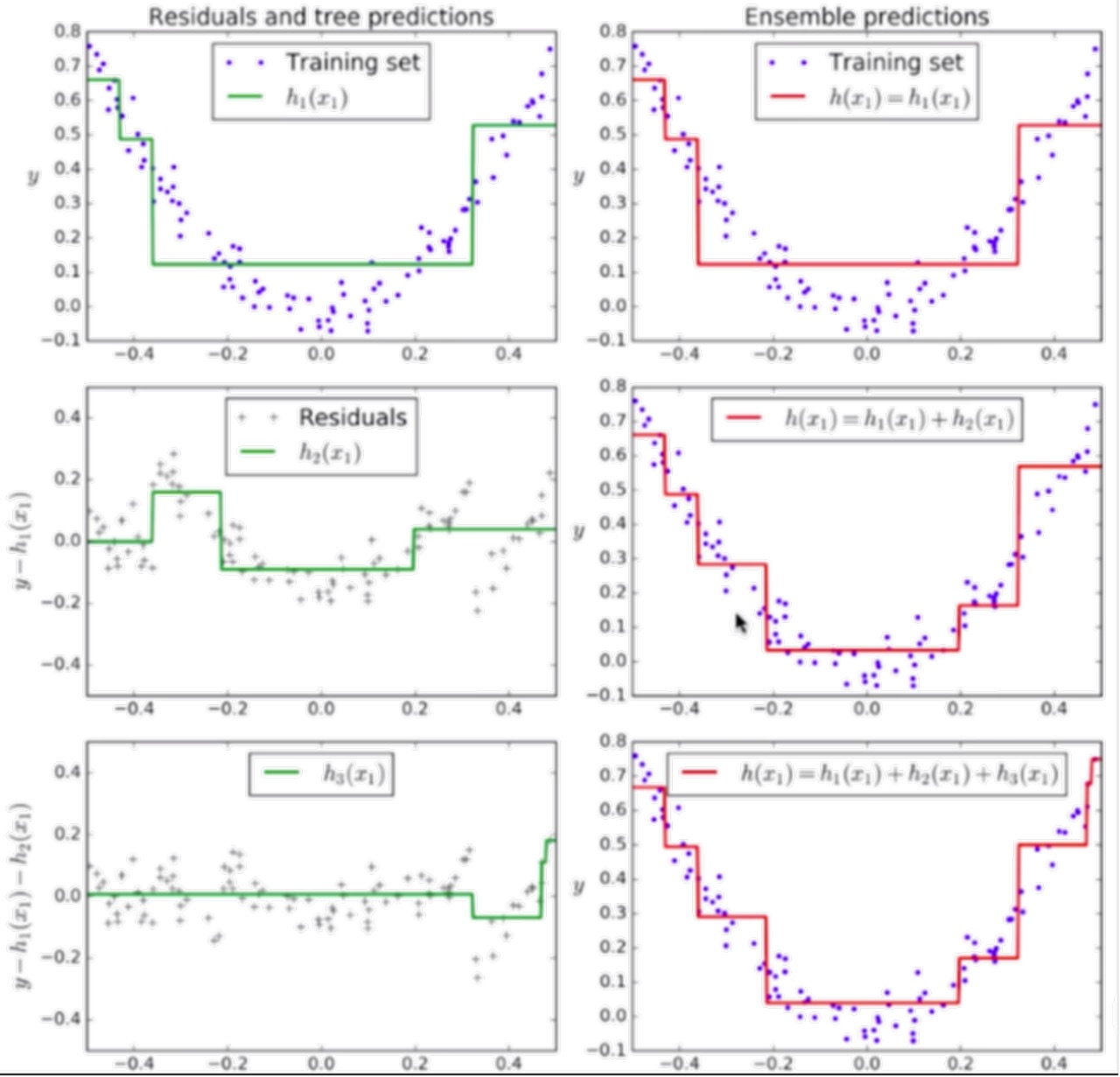
Gradient Boosting 則是通過對前一個模型產生的錯誤由后一個模型去擬合,對于后一個模型產生的錯誤再由后面一個模型去擬合…然后依次疊加這些模型:
一般來說,Gradient Boosting 在工業界使用的更廣泛,我們也以 Gradient Boosting 作為基礎,
3.3.2 XGBoost OR LightGBM
XGBoost、LightGBM 都是 Gradient Boosting 的一種高效系統實作,
我們分別從記憶體占用、準確率、訓練耗時方面進行了對比,LightGBM 記憶體占用降低了很多,準確率方面兩者基本一致,但訓練耗時卻也降低了很多,
記憶體占用對比:
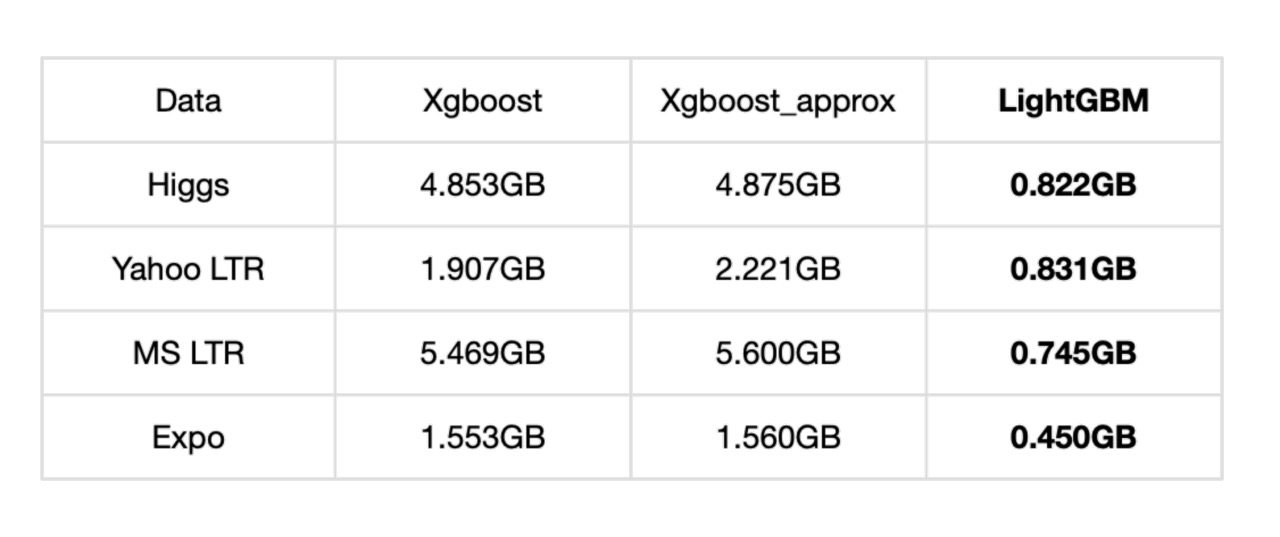
準確率對比:
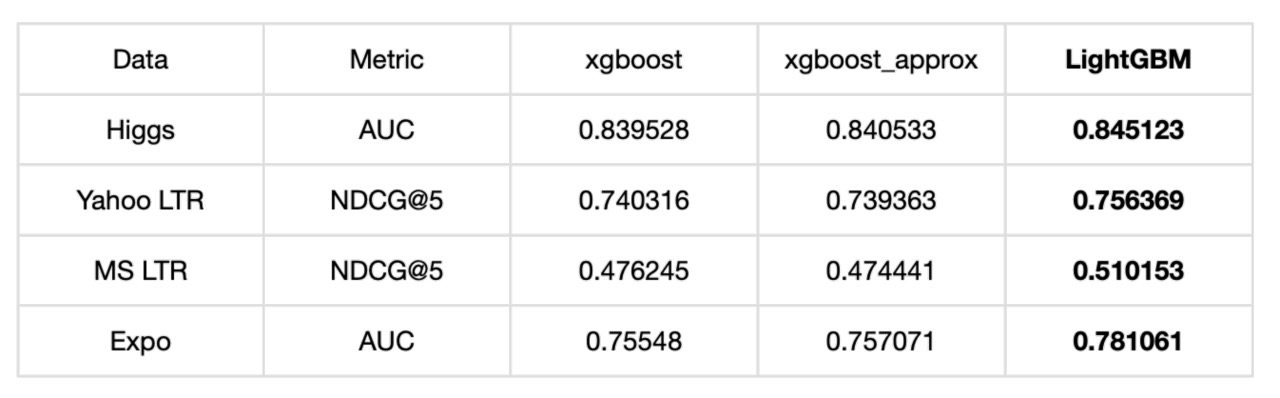
訓練耗時對比:

(圖源:微軟亞洲研究院)
基于以上對比資料參考,為了模型快速迭代訓練,我們最終選擇了 LightGBM,
3.4 模型訓練迭代
由于使用 LightGBM,訓練耗時大大縮小,所以我們可以進行快速的迭代,
模型訓練主要關注兩方面內容:
-
訓練結果分析
-
模型超參調節
3.4.1 訓練結果分析
訓練結果可能一開始差強人意,沒有達到理想的效果,這時需要我們仔細分析什么原因導致的這個結果,是特征向量的問題?還是相似度計算的問題?還是演算法的問題?具體原因具體分析,但總歸會慢慢達到理想的結果,
3.4.2 模型超參調節
這里主要介紹一些超引數調節的經驗,首先大致說一下比較重要的引數:
(1) maxdepth 與 numleaves
maxdepth 與 numleaves 是提高精度以及防止過擬合的重要引數:
-
maxdepth : 顧名思義為「樹的深度」,過大可能導致過擬合
-
numleaves 一棵樹的葉子數,LightGBM 使用的是 leaf-wise 演算法,此引數是控制樹模型復雜度的主要引數
(2) feature_fraction 與 bagging_fraction
feature_fraction 與 bagging_fraction 可以防止過擬合以及提高訓練速度:
-
feature_fraction :隨機選擇部分特征 (0<feature_fraction <1)
-
bagging_fraction 隨機選擇部分資料 (0<bagging_fraction<1)
(3) lambda_l1 與 lambda_l2
lambda_l1 與 lambda_l2 都是正則化項,可以有效防止過擬合,
-
lambda_l1 :L1 正則化項
-
lambda_l2 :L2 正則化項
3.5 模型效果
經過多輪迭代、優化、驗證,目前我們的酒店聚合模型已趨于穩定,
對方案效果的評估通常是憑借「準確率」與「召回率」兩個指標,但酒店聚合業務場景下,需要首先保證絕對高的準確率(聚合錯誤產生 AB 店影響用戶入住),然后才是較高的召回率,
經過多輪驗證,目前模型的準確率可以達到 99.92% 以上,召回率也達到了 85.62% 以上:

可以看到準確率已經達到一個比較高的水準,但為保險起見,聚合完成后我們還會根據酒店名稱、地址、坐標、設施、型別等不同維度建立一套二次校驗的規則;同時對于部分當天預訂當天入住的訂單,我們還會介入人工進行實時的校驗,來進一步控制 AB 店出現的風險,
3.6 方案總結
整體方案介紹完后,我們將基于機器學習的酒店聚合流程大致示意為下圖:
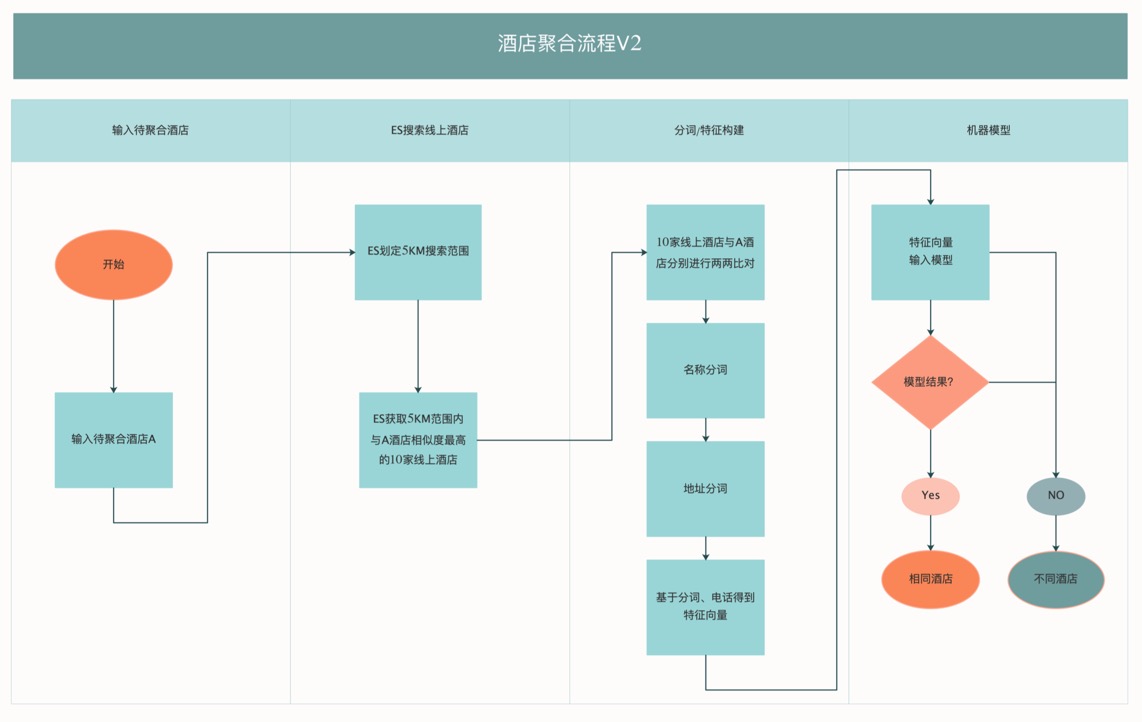
經過上面的探索,我們大致理解了:
-
解決方案都是一個慢慢演進的程序,當發現滿足不了需求的時候就會進行迭代;
-
分詞解決了對比粒度太粗的缺點,模擬人的思維進行斷句分詞;
-
機器學習可以得到復雜的規則,通過大量訓練資料解決人無法完成的任務,
Part 4 寫在最后
新技術的探索充滿挑戰也很有意義,未來我們會進一步迭代優化,高效完成酒店的聚合,保證資訊的準確性和及時性,提升用戶的預訂體驗,比如:
-
進行不同供應商國內酒店資源的坐標系統一,坐標對于酒店聚合是很重要的 Feature,相信坐標系統一后,酒店聚合的準確率、召回率會進一步提高,
-
打通風控與聚合的倍訓,風控與聚合建立實時雙向資料通道,從而進一步提高兩個服務的基礎能力,
上述主要講的是國內酒店聚合的演進方案,對于「國外酒店」資料的機器聚合,方法其實又很不同,比如國外酒店名稱、地址如何分詞,詞形還原與詞干提取怎么做等,我們在這方面有相應的探索和實戰,總體效果甚至優于國內酒店的聚合,后續我們也會通過文章和大家分享,希望感興趣的同學持續關注,
本文作者:劉書超,交易中心-酒店搜索研發工程師;賀夏龍、康文云,智能中臺-內容挖掘工程師,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53549.html
標籤:其他
上一篇:從頭學pytorch(十九):批量歸一化batch normalization
下一篇:手寫數字識別——手動搭建全連接層