本文使用TensorFlow2.0手動搭建簡單的全連接網路進行MNIST手寫資料集的分類識別,逐步講述實作程序,穿插TensorFlow2.0語法,文末給出完整的代碼,廢話少說,開始動手吧!
一、量子波動擼代碼
該節先給出各代碼片段,第二節將這些片段匯總成程式,這些代碼片段故意包含了一些錯誤之處,在第二節中會進行一一修正,如要正確的代碼,請直接參考第三節,如若讀者有一番閑情逸致,可跟隨筆者腳步,看看自己是否可以事先發現這些錯誤,
首先,匯入依賴的兩個模塊,一個是tensorflow,另一個是tensorflow.keras.datasets,我們要的資料集MNIST就是由這個datasets管理下載的,https://tensorflow.google.cn/datasets/catalog/overview?hl=en中列出了datasets管理的所有資料集,
import tensorflow as tf #資料集管理器 from tensorflow.keras import datasets
匯入資料集,資料集一般由訓練資料和測驗資料構成,用(x,y)存盤訓練圖片和標簽,用(val_x,val_y)存盤測驗圖片和標簽,
(x,y),(val_x,val_y) = datasets.mnist.load_data()
在匯入后,需要對資料形式進行初步查看,對于影像識別來說,圖片的數量、大小、通道數量和資料范圍、型別是必須了解的,以一下程式能列印出這些資訊,注釋為輸出結果,由結果可知,datasets匯出的資料是Numpy陣列,型別為uint8,訓練圖片共60k張,大小為28*28,為灰度影像,灰度范圍0~255;測驗圖片共10k張,
print(type(x),x.dtype) #<class 'numpy.ndarray'> uint8 print(type(y),y.dtype) #<class 'numpy.ndarray'> uint8 print(x.shape,y.shape) #(60000, 28, 28) (60000,) print(val_x.shape,val_y.shape) #(10000, 28, 28) (10000,) print(x.max(),x.min()) #255 0 print(y.max(),y.min()) #9 0
在訓練前必須先將資料轉為Tensor,用tf.convert_to_tensor(value,dtype)函式可將value轉為Tensor,并可指定資料型別(dtype),將x,val_x轉成浮點型別,而訓練資料的標簽y需要先轉為Tensor整型再轉化為獨熱碼形式,測驗資料val_y的標簽轉化為Tensor整型,獨熱碼轉換可用tf.one_hot(indices,depth,dtype),indices必須是整型,這也就是為什么先轉成Tensor整型的原因,depth決定獨熱碼位數,dtype默認是tf.float32,以下代碼完成資料型別轉換,
#需要將資料轉成Tensor x = tf.convert_to_tensor(x,dtype=tf.float32) y = tf.convert_to_tensor(y,dtype=tf.int32) val_x = tf.convert_to_tensor(val_x,dtype=tf.float32) val_y = tf.convert_to_tensor(val_y,dtype=tf.int32) #獨熱碼 y = tf.one_hot(y,depth=10) print(y.shape) #(60000, 10)
對于如此龐大的資料集,直接一次性加載到記憶體進行計算是不現實的,所以采用批處理的方式將資料集分批喂進網路,在分批前先對資料shuffle一下,以防網路發現順序規律,事實上,把整個資料集一次喂給網路來更新引數的程序稱為批梯度下降;而每次只喂一張圖片,則稱為隨機梯度下降;每次將一小批圖片喂給網路,稱為小批量梯度下降,關于三者的區別可以參考https://www.cnblogs.com/lliuye/p/9451903.html,簡單來說,小批量梯度下降是最合適的,一般Batch設的較大,則達到最大準確率的速度變慢,但更容易收斂;Batch設小了,在一開始,準確率提高得非常快,但是最終收斂可能不太好,
test_db = tf.data.Dataset.from_tensor_slices((val_x,val_y)).shuffle(10000).batch(256)
train_db = tf.data.Dataset.from_tensor_slices((x,y)).shuffle(10000).batch(256)
train_db是可以直接迭代的,下面進行一次迭代,觀察迭代結果,可以知道每一次迭代圖片數量就是Batch大小,
train_iter = iter(train_db) sample = next(train_iter) print(sample[0].shape,sample[1].shape) #(256, 28, 28) (256, 10)
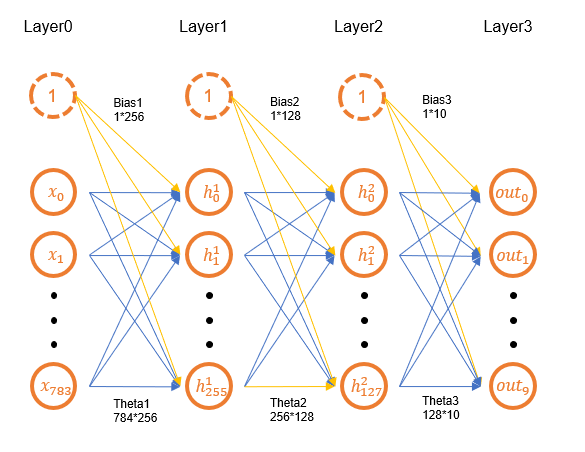
下面就可以開始構建全連接網絡了,結構如上圖所示,網路節點數為784(input)->256->128->10(output),加上輸入輸出一共4層,其中輸入層是打平后的圖片,共28*28=784個像素;輸出層由類別數決定,這里手寫數字0~9共10類,故輸出有10個節點,這些節點表示屬于該類的概率,構建網路需要有初始化的引數,可以利用高斯分布進行引數的初始化,即函式tf.random.normal(shape,mean=0.0,stddev=1.0),但是為了避免引數初始化過大,常采用截斷型正態分布,即函式tf.random.truncated_normal(shape,mean=0.0,stddev=1.0),該函式將丟棄幅度大于平均值的2個標準偏差的值并重新選擇,這里也就是說隨機的值范圍在-2~2之間,在初始化引數時也要注意引數的shape,例如784->256的引數shape應為(784,256),偏置shape應為(256,),這樣還方便之后的矩陣運算,偏置一般都初始化為0,此外,所有引數都必須轉為tf.Variable型別,才可以記錄下梯度資訊,
#input(layer0)->layer1: nodes:784->256 theta_1 = tf.Variable(tf.random.truncated_normal([784,256]))#因為后面要記錄梯度資訊,所以要用Varible bias_1 = tf.Variable(tf.zeros([256])) #layer1->layer2: nodes:256->128 theta_2 = tf.Variable(tf.random.truncated_normal([256,128])) bias_2 = tf.Variable(tf.zeros([128])) #layer2->out(layer3): nodes:128->10 theta_3 = tf.Variable(tf.random.truncated_normal([128,10])) bias_3 = tf.Variable(tf.zeros([10]))
初始化引數后,可以統計一下網路的引數量:784*256+256*128+128*10+256+128+10=235146,大約20萬個引數,相比一些經典卷積網路,全連接網路的引數量還是比較少的,
對train_db進行迭代,套上enumerate()以便獲取迭代批次,每一批資料,都要進行前向傳播,首先,將shape為[256,28,28]圖片打平為[256,784],這個可以借助tf.reshape(tensor,shape),在不改變元素個數的前提下,對維度進行分解或者合并,這樣,h_1=x@theta1+bias1就可以得到下一層網路的節點值,h_1的shape為[256,256];同理,h_2的shape為[256,128],h_3的shape為[256,10],每一層計算之后都應該加上一個激活函式,最常用的就是ReLu,通過激活函式可以增加網路的非線性表達能力,這里使用函式tf.nn.relu(features),
由于更新引數需要得到各引數的梯度資訊,因此前向傳播要用with tf.GradientTape() as tape:包裹起來,關于with as 的語法如果不熟悉可以參考https://www.cnblogs.com/DswCnblog/p/6126588.html,此外,還得計算代價函式,就是Loss,一般采用差平方的均值來計算,差平方使用tf.math.square(x),均值采用tf.math.reduce_mean(input_tensor,axis=None),如果不指定axis就對所有元素求均值,回傳值是標量,而如果指定axis,就僅對該axis做均值,結果的shape中該axis消失,
for batch, (x, y) in enumerate(train_db): # x:[256,28,28] x = tf.reshape(x, [-1, 28 * 28]) # 最后一批<256個,用-1可以自動計算 with tf.GradientTape() as tape: # 前向傳播 # x:[256,784] theta_1:[784,256] bias_1:[256,] h_1:[256,256] h_1 = x @ theta_1 + bias_1 h_1 = tf.nn.relu(h_1) # h_1:[256,256] theta_2:[256,128] bias_2:[128,] h_2:[256,128] h_2 = h_1 @ theta_2 + bias_2 h_2 = tf.nn.relu(h_2) # h_2:[256,128] theta_3:[128,10] bias_2:[10,] out:[256,10] out = h_2 @ theta_3 + bias_3# 計算代價函式 # out:[256,10] y:[256,10] loss = tf.math.square(y - out) # loss:[256,10]->scalar loss = tf.math.reduce_mean(loss)
上一部分對梯度資訊進行了記錄,我們要更新引數,必須先執行loss對各引數求導,之后根據學習率進行引數更新:
alpha = tf.constant(1e-3) #獲取梯度資訊,grads為一個串列,順序依據給定的引數串列 grads = tape.gradient(loss,[theta_1,bias_1,theta_2,bias_2,theta_3,bias_3]) #根據給定串列順序,對引數求導 theta_1 = theta_1 - alpha * grads[0] theta_2 = theta_2 - alpha * grads[2] theta_3 = theta_3 - alpha * grads[4] bias_1 = bias_1 - alpha * grads[1] bias_2 = bias_2 - alpha * grads[3] bias_3 = bias_3 - alpha * grads[5] #每隔100個batch列印一次loss if batch % 100 ==0: print(batch,'loss:',float(loss))
到此為止,整個訓練網路就完成了,為了測驗網路的效果,我們需要對測驗資料集進行預測,并且計算出準確率,關于測驗的前向傳播同之前的一樣,但測驗時并不需要對引數進行更新,網路的輸出層有10個類別的概率,我們要取概率最大的作為預測的類別,這可以通過tf.math.argmax(input,axis=None)來實作,該函式可以回傳陣列中最大數的位置,axis的作用類似與reduce_mean,預測結果的正確與否可用tf.math.equal(x,y)來判別,它回傳Bool型串列,由于一批次有256個圖片,那么預測結果也有256個,可以用tf.math.reduce_sum(input_tensor,axis=None)進行求和,求和前通過tf.cast(x,dtype)將Bool型別轉為整型,
correct_cnt = 0 # 預測對的數量 total_val = val_y.shape[0] # 測驗樣本總數 # 測驗資料預測 for (val_x, val_y) in test_db: val_x = tf.reshape(val_x, [-1, 28 * 28]) val_h_1 = val_x @ theta_1 + bias_1 val_h_1 = tf.nn.relu(val_h_1) val_h_2 = val_h_1 @ theta_2 + bias_2 val_h_2 = tf.nn.relu(val_h_2) val_out = val_h_2 @ theta_3 + bias_3 # val_out:(256,10) pred:(256,) pred = tf.math.argmax(val_out, axis=-1) # acc:bool (256,) acc = tf.math.equal(pred, val_y) acc = tf.cast(acc, dtype=tf.int32) correct_cnt += tf.math.reduce_sum(acc) percent = float(correct_cnt / total_val) print('val_acc:',percent)
自此所有的代碼片段都已分析完畢,下一節將展示綜合的代碼和運行結果,
二、亡羊補牢,搞定BUG
為了之后敘述的方便,這里先給出綜合的代碼,在原有基礎上,還加上了訓練集的準確度計算,和時間記錄,
1 import tensorflow as tf 2 #資料集管理器 3 from tensorflow.keras import datasets 4 import time 5 6 #匯入資料集 7 (x,y),(val_x,val_y) = datasets.mnist.load_data() 8 #資料集資訊 9 print('type_x:',type(x),'dtype_x:',x.dtype) 10 print('type_y:',type(y),'dtype_y:',y.dtype) 11 print('shape_x:',x.shape,'shape_y:',y.shape) 12 print('shape_val:',val_x.shape,'shape_val:',val_y.shape) 13 print('max_x:',x.max(),'min_x:',x.min()) 14 print('max_y:',y.max(),'min_y:',y.min()) 15 16 #需要將資料轉成Tensor 17 x = tf.convert_to_tensor(x,dtype=tf.float32) 18 y = tf.convert_to_tensor(y,dtype=tf.int32) 19 val_x = tf.convert_to_tensor(val_x,dtype=tf.float32) 20 val_y = tf.convert_to_tensor(val_y,dtype=tf.int32) 21 #獨熱碼 22 y = tf.one_hot(y,depth=10) 23 print('one_hot_y:',y.shape) 24 25 #生成批處理 26 test_db = tf.data.Dataset.from_tensor_slices((val_x,val_y)).shuffle(10000).batch(256) 27 train_db = tf.data.Dataset.from_tensor_slices((x,y)).shuffle(10000).batch(256) 28 #批處理資料資訊 29 train_iter = iter(train_db) 30 sample = next(train_iter) 31 print('sample_x_shape:',sample[0].shape,'sample_y_shape:',sample[1].shape) 32 33 #引數初始化 34 #input(layer0)->layer1: nodes:784->256 35 theta_1 = tf.Variable(tf.random.truncated_normal([784,256]))#因為后面要記錄梯度資訊,所以要用Varible 36 bias_1 = tf.Variable(tf.zeros([256])) 37 38 #layer1->layer2: nodes:256->128 39 theta_2 = tf.Variable(tf.random.truncated_normal([256,128])) 40 bias_2 = tf.Variable(tf.zeros([128])) 41 42 #layer2->out(layer3): nodes:128->10 43 theta_3 = tf.Variable(tf.random.truncated_normal([128,10])) 44 bias_3 = tf.Variable(tf.zeros([10])) 45 46 #確定學習率 47 alpha = tf.constant(1e-3) 48 # 測驗樣本總數 49 total_val = val_y.shape[0] 50 # 訓練樣本總數 51 total_y = y.shape[0] 52 #開始時間 53 start_time = time.time() 54 55 for echo in range(500): 56 #前向傳播 57 correct_cnt = 0 # 預測對的數量 58 59 for batch, (x, y) in enumerate(train_db): 60 # x:[256,28,28] 61 x = tf.reshape(x, [-1, 28 * 28]) # 最后一批<256個,用-1可以自動計算 62 with tf.GradientTape() as tape: 63 # 前向傳播 64 # x:[256,784] theta_1:[784,256] bias_1:[256,] h_1:[256,256] 65 h_1 = x @ theta_1 + bias_1 66 h_1 = tf.nn.relu(h_1) 67 # h_1:[256,256] theta_2:[256,128] bias_2:[128,] h_2:[256,128] 68 h_2 = h_1 @ theta_2 + bias_2 69 h_2 = tf.nn.relu(h_2) 70 # h_2:[256,128] theta_3:[128,10] bias_2:[10,] out:[256,10] 71 out = h_2 @ theta_3 + bias_3 72 # 計算代價函式 73 # out:[256,10] y:[256,10] 74 loss = tf.math.square(y - out) 75 # loss:[256,10]->scalar 76 loss = tf.math.reduce_mean(loss) 77 78 # 獲取梯度資訊,grads為一個串列,順序依據給定的引數串列 79 grads = tape.gradient(loss, [theta_1, bias_1, theta_2, bias_2, theta_3, bias_3]) 80 # 根據給定串列順序,對引數求導 81 theta_1 = theta_1 - alpha * grads[0] 82 theta_2 = theta_2 - alpha * grads[2] 83 theta_3 = theta_3 - alpha * grads[4] 84 bias_1 = bias_1 - alpha * grads[1] 85 bias_2 = bias_2 - alpha * grads[3] 86 bias_3 = bias_3 - alpha * grads[5] 87 88 pred = tf.math.argmax(out, axis=-1) 89 y_label = tf.math.argmax(y, axis=-1) 90 acc = tf.math.equal(pred, y_label) 91 acc = tf.cast(acc, dtype=tf.int32) 92 correct_cnt += tf.math.reduce_sum(acc) 93 94 # 每隔100個batch列印一次loss 95 if batch % 100 == 0: 96 print(batch, 'loss:', float(loss)) 97 98 #訓練的準確度 99 percent = float(correct_cnt / total_y) 100 print('train_acc:', percent) 101 102 correct_cnt = 0 # 預測對的數量 103 104 105 # 測驗資料預測 106 for (val_x, val_y) in test_db: 107 val_x = tf.reshape(val_x, [-1, 28 * 28]) 108 val_h_1 = val_x @ theta_1 + bias_1 109 val_h_1 = tf.nn.relu(val_h_1) 110 val_h_2 = val_h_1 @ theta_2 + bias_2 111 val_h_2 = tf.nn.relu(val_h_2) 112 val_out = val_h_2 @ theta_3 + bias_3 113 114 # val_out:(256,10) pred:(256,) 115 pred = tf.math.argmax(val_out, axis=-1) 116 # acc:bool (256,) 117 acc = tf.math.equal(pred, val_y) 118 acc = tf.cast(acc, dtype=tf.int32) 119 correct_cnt += tf.math.reduce_sum(acc) 120 121 #測驗準確度 122 percent = float(correct_cnt / total_val) 123 print('val_acc:', percent) 124 print('time:',int(time.time()-start_time)//60,':',int(time.time()-start_time)%60)
以為自此萬事大吉,沒想到剛跑就報錯,報錯如下:
0 loss: 75169185792.0
Traceback (most recent call last):
File "D:/programe/tensorflow/tf-project/practice01/forward.py", line 76, in <module>
theta_1 = theta_1 - alpha * grads[0]
ValueError: Attempt to convert a value (None) with an unsupported type (<class 'NoneType'>) to a Tensor.
由報錯可知,錯誤大概出在引數更新那里,并且此時第一loss已經被列印出來了,雖然這個Loss有點大得離譜,不過應該不會使得theta_1為None或者grads為None,經過Debug確認為grads為None,并且還發現引數經過一次更新后,其型別從Variable變成了普通的Tensor型別,這就說明問題了,Variable在和Tensor計算時會轉換成Tensor,之前曾說過,只有Variable才能記錄下梯度資訊,因此在第二輪更新時,梯度已經不能正常記錄了,才導致grads為None,解決的辦法有兩種,一種在更新后用tf.Variable進行轉換;第二種就是使用原地更新,Variable特有方法.assign_sub進行減法運算,除此之外,還有類似的加法運算等,將上面程式的81~86行改成下面程式段:
theta_1.assign_sub(alpha*grads[0])#原地更新,型別不變 theta_2.assign_sub(alpha * grads[2]) theta_3.assign_sub(alpha * grads[4]) bias_1.assign_sub(alpha*grads[1]) bias_2.assign_sub(alpha * grads[3]) bias_3.assign_sub(alpha * grads[5])
再次運行程式,且看報錯資訊:
0 loss: 87516119040.0 100 loss: nan 200 loss: nan train_acc: 0.09881666666666666 Traceback (most recent call last): File "D:/programe/tensorflow/tf-project/practice01/forward.py", line 110, in <module> acc = tf.math.equal(pred, val_y) tensorflow.python.framework.errors_impl.InvalidArgumentError: cannot compute Equal as input
#1(zero-based) was expected to be a int64 tensor but is a int32 tensor [Op:Equal]
這里的報錯跟loss也沒關系,根據報錯提示,這里的equal應該要求兩個資料的型別要相同,而實際上pred是argmax默認回傳的int64型別,val_y我們之前把它轉為了int32,為了統一,將程式的第20行改為:
val_y = tf.convert_to_tensor(val_y,dtype=tf.int64) #與argmax回傳值型別統一
再次運行程式,終于不報錯了,但是之前忽略的Loss問題就出現了,看一下輸出結果:
0 loss: 110720491520.0 100 loss: nan 200 loss: nan train_acc: 0.09888333333333334 val_acc: 0.098 0 loss: nan 100 loss: nan 200 loss: nan train_acc: 0.09871666666666666 val_acc: 0.098
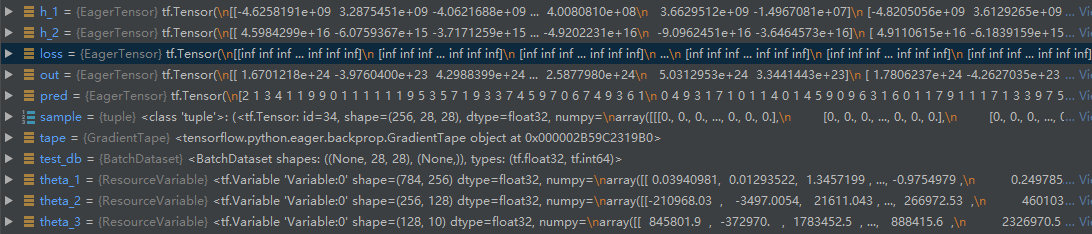
關于Python值出現nan的原因可以參考博客https://www.jianshu.com/p/d9caa4ab46e1,根據博客,inf的運算可能會導致nan,那么,我們可以通過Debug查看運算程序中是否有變數出現了inf,結果在Debug到71行時第70行的loss變為了inf,并且其他變數包括網路權重都非常大,例如下圖:
為了解決該問題,可以采用特征縮放,即把圖片的灰度值縮放到(0,1)或者(-0.5,0.5)之間,有關特征縮放的好處可以參考https://www.cnblogs.com/kensporger/p/11747100.html#_lab2_2_3,將第17行、19行改為:
x = tf.convert_to_tensor(x,dtype=tf.float32) /255.5 -0.5
val_x = tf.convert_to_tensor(val_x,dtype=tf.float32) /255.5 -0.5
再次運行程式,但是loss仍然為nan,但第一次計算的loss比原先小了許多,但還不夠小,看一下輸出結果:
0 loss: 2819718.5 100 loss: nan 200 loss: nan train_acc: 0.09841666666666667 val_acc: 0.098 0 loss: nan 100 loss: nan 200 loss: nan train_acc: 0.09871666666666666 val_acc: 0.098
我們之前縮小了特征值,但是引數初始化的范圍是[-2,2],這個引數還是過大了,通過Debug可以知道輸出節點大約在1k左右,那么用這個1k去做差平方顯然是不對的,要知道標簽值也就0/1,因此我們將引數初始化為[-0.2,0.2],這樣輸出節點值大約在1左右,梯度大約為1e-3級別,將第35、39、43行改為以下內容:
theta_1 = tf.Variable(tf.random.truncated_normal([784,256],stddev=0.1))#因為后面要記錄梯度資訊,所以要用Varible theta_2 = tf.Variable(tf.random.truncated_normal([256,128],stddev=0.1)) theta_3 = tf.Variable(tf.random.truncated_normal([128,10],stddev=0.1))
再次運行程式,可發現loss在穩步下降,acc正常上升,所有問題都已解決,程式最終準確率大約為0.9,訓練時間25分鐘,可以試一下增加以下網路層數,因為就目前的train_acc和val_acc來看,并沒有達到過擬合狀態,可能層數增加,準確度還可以提高個2%左右,如果還想再有所提升,可能就得采用TensorFlow提供的優化手段了,這個下次再寫,
補充:到這里,筆者忽略了一個錯誤,實際上對Loss的計算不應該采用差平方的均值,這種方法更適合二分類;對于多分類,應采用交叉熵函式進行計算,改動原程式的第73-76行,注意,我們仍需要對交叉熵計算出的Loss取均值才是每個樣本的Loss,
loss = tf.keras.losses.categorical_crossentropy(y,out,from_logits=True)
loss = tf.math.reduce_mean(loss)
事實證明,通過交叉熵計算Loss,準確率上升更快,經過大約7分鐘的訓練,準確度能達到0.93左右,
三、智慧結晶
這次實體,需要注意的地方:
1.Variable要用assign_sub進行更新;
2.equal要求比較的兩者資料型別要一致;
3.argmax默認回傳int64型別;
4.特征縮放是必須的;
5.權重初始化要使得輸出節點值和梯度值合理;
6.多元分類使用交叉熵計算Loss;
1 import tensorflow as tf 2 #資料集管理器 3 from tensorflow.keras import datasets 4 import time 5 6 #匯入資料集 7 (x,y),(val_x,val_y) = datasets.mnist.load_data() 8 #資料集資訊 9 print('type_x:',type(x),'dtype_x:',x.dtype) 10 print('type_y:',type(y),'dtype_y:',y.dtype) 11 print('shape_x:',x.shape,'shape_y:',y.shape) 12 print('shape_val:',val_x.shape,'shape_val:',val_y.shape) 13 print('max_x:',x.max(),'min_x:',x.min()) 14 print('max_y:',y.max(),'min_y:',y.min()) 15 16 #需要將資料轉成Tensor 17 x = tf.convert_to_tensor(x,dtype=tf.float32) /255 -0.5 18 y = tf.convert_to_tensor(y,dtype=tf.int32) 19 val_x = tf.convert_to_tensor(val_x,dtype=tf.float32)/255 -0.5 20 val_y = tf.convert_to_tensor(val_y,dtype=tf.int64) #與argmax回傳值型別統一 21 #獨熱碼 22 y = tf.one_hot(y,depth=10) 23 print('one_hot_y:',y.shape) 24 25 #生成批處理 26 test_db = tf.data.Dataset.from_tensor_slices((val_x,val_y)).shuffle(10000).batch(256) 27 train_db = tf.data.Dataset.from_tensor_slices((x,y)).shuffle(10000).batch(256) 28 #批處理資料資訊 29 train_iter = iter(train_db) 30 sample = next(train_iter) 31 print('sample_x_shape:',sample[0].shape,'sample_y_shape:',sample[1].shape) 32 33 #引數初始化 34 #input(layer0)->layer1: nodes:784->256 35 theta_1 = tf.Variable(tf.random.truncated_normal([784,256],stddev=0.1))#因為后面要記錄梯度資訊,所以要用Varible 36 bias_1 = tf.Variable(tf.zeros([256])) 37 38 #layer1->layer2: nodes:256->128 39 theta_2 = tf.Variable(tf.random.truncated_normal([256,128],stddev=0.1)) 40 bias_2 = tf.Variable(tf.zeros([128])) 41 42 #layer2->out(layer3): nodes:128->10 43 theta_3 = tf.Variable(tf.random.truncated_normal([128,10],stddev=0.1)) 44 bias_3 = tf.Variable(tf.zeros([10])) 45 46 #確定學習率 47 alpha = tf.constant(1e-3) 48 # 測驗樣本總數 49 total_val = val_y.shape[0] 50 # 訓練樣本總數 51 total_y = y.shape[0] 52 #開始時間 53 start_time = time.time() 54 55 for echo in range(500): 56 #前向傳播 57 correct_cnt = 0 # 預測對的數量 58 59 for batch, (x, y) in enumerate(train_db): 60 # x:[256,28,28] 61 x = tf.reshape(x, [-1, 28 * 28]) # 最后一批<256個,用-1可以自動計算 62 with tf.GradientTape() as tape: 63 # 前向傳播 64 # x:[256,784] theta_1:[784,256] bias_1:[256,] h_1:[256,256] 65 h_1 = x @ theta_1 + bias_1 66 h_1 = tf.nn.relu(h_1) 67 # h_1:[256,256] theta_2:[256,128] bias_2:[128,] h_2:[256,128] 68 h_2 = h_1 @ theta_2 + bias_2 69 h_2 = tf.nn.relu(h_2) 70 # h_2:[256,128] theta_3:[128,10] bias_2:[10,] out:[256,10] 71 out = h_2 @ theta_3 + bias_3 72 73 # 計算代價函式 74 # out:[256,10] y:[256,10] 75 loss = tf.losses.categorical_crossentropy(y,out,from_logits=True)# loss:[256,10]->scalar 76 loss = tf.math.reduce_mean(loss) 77 78 # 獲取梯度資訊,grads為一個串列,順序依據給定的引數串列 79 grads = tape.gradient(loss, [theta_1, bias_1, theta_2, bias_2, theta_3, bias_3]) 80 # 根據給定串列順序,對引數求導 81 theta_1.assign_sub(alpha * grads[0]) # 原地更新,型別不變 82 theta_2.assign_sub(alpha * grads[2]) 83 theta_3.assign_sub(alpha * grads[4]) 84 bias_1.assign_sub(alpha * grads[1]) 85 bias_2.assign_sub(alpha * grads[3]) 86 bias_3.assign_sub(alpha * grads[5]) 87 88 pred = tf.math.argmax(out, axis=-1) 89 y_label = tf.math.argmax(y, axis=-1) 90 acc = tf.math.equal(pred, y_label) 91 acc = tf.cast(acc, dtype=tf.int32) 92 correct_cnt += tf.math.reduce_sum(acc) 93 94 # 每隔100個batch列印一次loss 95 if batch % 100 == 0: 96 print(batch, 'loss:', float(loss)) 97 98 #訓練的準確度 99 percent = float(correct_cnt / total_y) 100 print('train_acc:', percent) 101 102 correct_cnt = 0 # 預測對的數量 103 104 105 # 測驗資料預測 106 for (val_x, val_y) in test_db: 107 val_x = tf.reshape(val_x, [-1, 28 * 28]) 108 val_h_1 = val_x @ theta_1 + bias_1 109 val_h_1 = tf.nn.relu(val_h_1) 110 val_h_2 = val_h_1 @ theta_2 + bias_2 111 val_h_2 = tf.nn.relu(val_h_2) 112 val_out = val_h_2 @ theta_3 + bias_3 113 114 # val_out:(256,10) pred:(256,) 115 pred = tf.math.argmax(val_out, axis=-1) 116 # acc:bool (256,) 117 acc = tf.math.equal(pred, val_y) 118 acc = tf.cast(acc, dtype=tf.int32) 119 correct_cnt += tf.math.reduce_sum(acc) 120 121 #測驗準確度 122 percent = float(correct_cnt / total_val) 123 print('val_acc:', percent) 124 print('time:',int(time.time()-start_time)//60,':',int(time.time()-start_time)%60)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/53552.html
標籤:其他
下一篇:聚集索引和非聚集索引區別