作者:盧運強,主要從事 Java、Python 和 Golang 相關的開發作業,熱愛學習和使用新技術;有著十分強烈的代碼潔癖;喜歡重構代碼,善于分析和解決問題,原文鏈接,
我司從 2022 年 6 月開始使用 KubeSphere,到目前為止快一年時間,簡要記錄下此程序中的經驗積累,供大家參考,
背景
公司當前有接近 3000 人的規模,主要業務為汽車配套相關的軟硬體開發,其中專門從事軟體開發約有 800 人,這其中 Java 開發的約占 70%,余下的為 C/C++ 嵌入式和 C# 桌面程式的開發,
在 Java 開發部分,約 80% 的都是 Java EE 開發,由于公司的業務主要是給外部客戶提供軟硬體產品和咨詢服務,在早期公司和部門更關注的是如何將產品銷售給更多的客戶、獲得更多的訂單和盡快回款,對軟體開發流程這塊沒有過多的重視,故早期在軟體開發部分不是特別規范化,軟體開發基于專案主要采用敏捷開發或瀑布模型,而對于軟體部署和運維依舊采用的純手工方式,
隨著公司規模的擴大與軟體產品線的增多,上述方式逐漸暴露出一些問題:
- 存在大量重復性作業,在軟體快速迭代時,需要頻繁的手工編譯部署,耗費時間,且此程序缺乏日志記錄,后續無法追蹤審計;
- 缺乏審核功能,對于測驗環境和生產環境的操作需要審批流程,之前通過郵件和企業微信無法串聯;
- 缺乏準入功能,隨著團隊規模擴大,人員素質參差不齊,需要對軟體開發流程、代碼風格都需要強制固化;
- 缺乏監控功能,后續不同團隊、專案采用的監控方案不統一,不利于知識的積累;
- 不同客戶的定制化功能太多(logo,字體,IP 地址,業務邏輯等),采用手工打包的方式效率低,容易遺漏出錯,
在競爭日益激烈的市場環境下,公司需要把有限的人力資源優先用于業務迭代開發,解決上述問題變得愈發迫切,
選型說明
基于前述原因,部門準備選用網路上開源的系統來盡可能的解決上述痛點,在技術選型時有如下考量點:
- 采用盡量少的系統,最好一套系統能解決前述所有問題,避免多個系統維護和整合的成本;
- 采用開源版本,避免公司內部手工開發,節約人力;
- 安裝程序簡潔,不需要復雜的操作,能支持離線安裝;
- 檔案豐富、社區活躍、使用人員較多,遇到問題能較容易的找到答案;
- 支持容器化部署,公司和部門的業務中自動駕駛和云仿真相關的越來越多,此部分對算力和資源提出了更高的要求,
我們最開始采用的是 Jenkins,通過 Jenkins 基本上能解決我們 90% 的問題,但依舊有如下問題影使用體驗:
- 對于云原生支持不太好,不利于部門后續云仿真相關的業務使用;
- UI 界面簡陋,互動方式不友好(專案構建日志輸出等);
- 對于專案,資源的權限分配與隔離過于簡陋,不滿足多專案多部門使用時細粒度的區分要求,
在網路上查找后發現類似的工具有很多,經過初步對比篩選后傾向于 KubeSphere、Zadig 這 2 款產品,它們的基本功能都類似,進一步對比如下:
| KubeSphere | Zadig | |
|---|---|---|
| 云原生支持 | 高 | 一般 |
| UI 美觀度 | 高 | 一般 |
| GitHub Star | 12.4k | 2k |
| 社區活躍度 | 高 | 一般 |
經過對比,KubeSphere 較為符合我們的需求,尤其是 KubeSphere 的 UI 界面十分美觀,故最終選定 KubeSphere 作為部門內部的持續集成與容器化管理系統!
至此,部門內部經歷了手工操作->Jenkins->KubeSphere這 3 個階段,各階段的主要使用點如下:
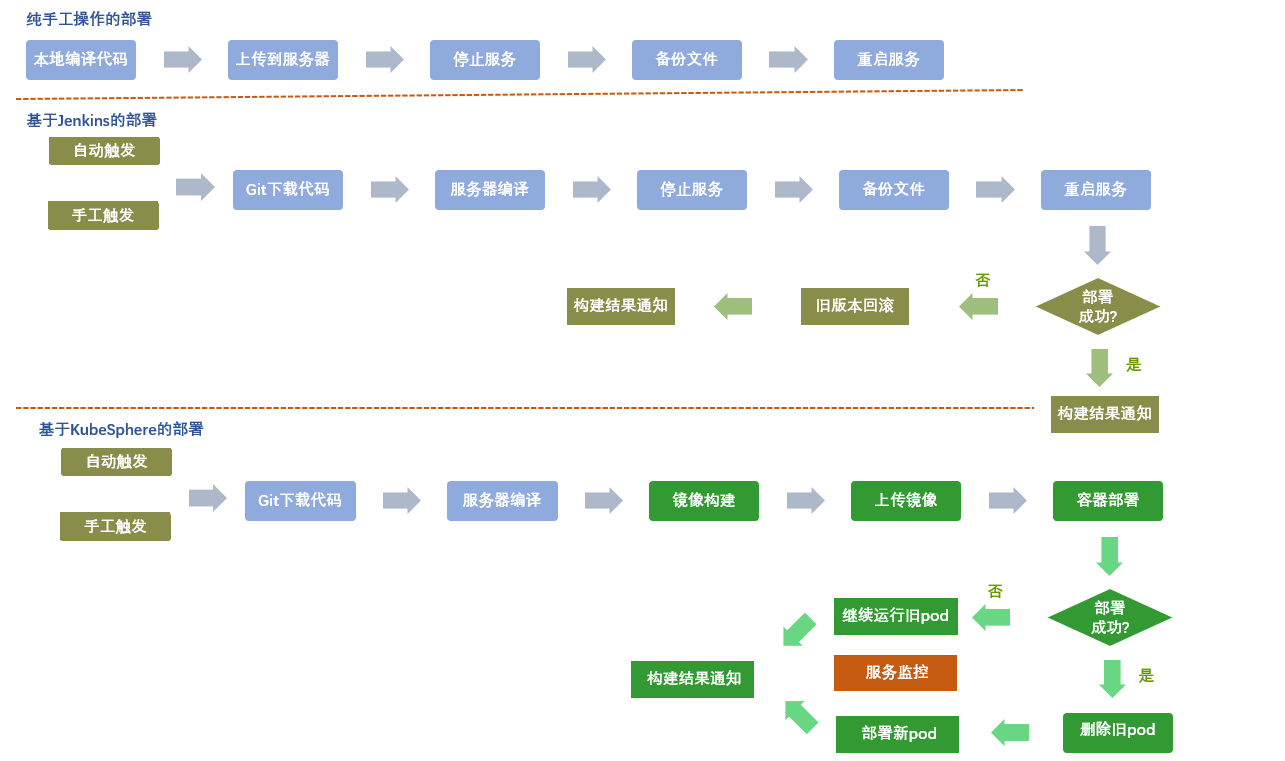
實踐程序
KubeSphere 在公司內部的整體部署架構如下圖所示,其作為最頂層的應用程式直接與使用人員互動,提供主動/定時觸發構建、應用監控等功能,使用人員不必關心底層的 Jenkins、Kubernetes 等依賴組件,只需要與 Gitlab 和 KubeSphere 互動即可,
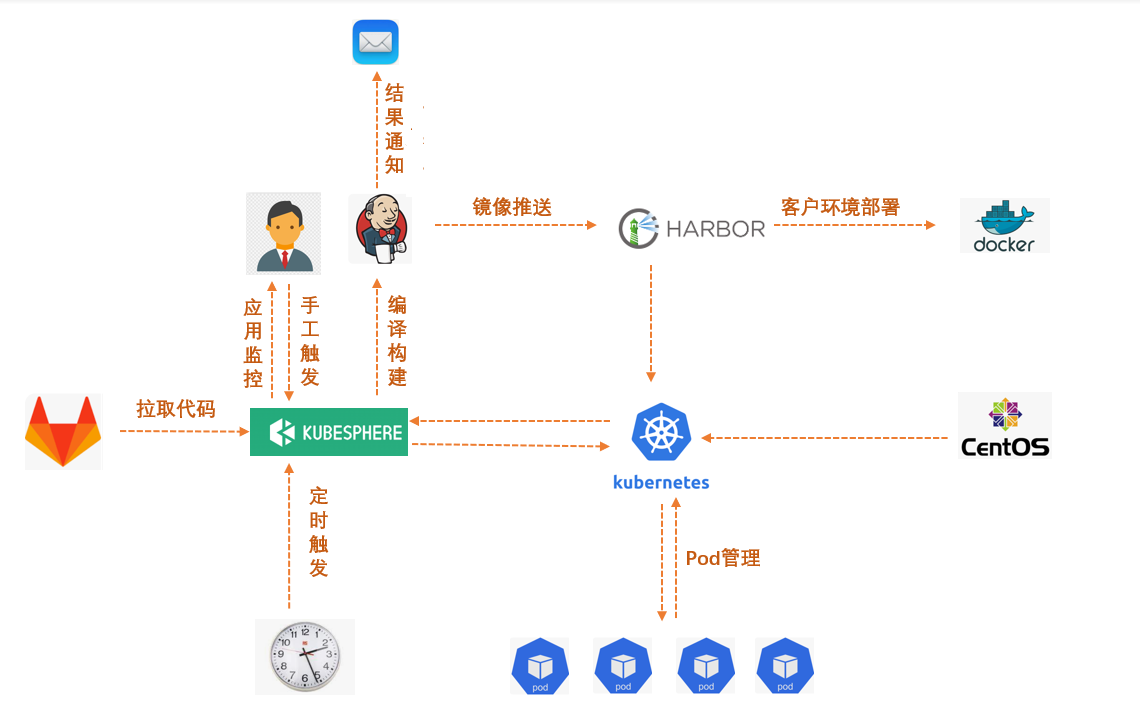
持續集成
初始實作
在最初的嘗試階段只規劃了 4 套環境:dev(開發環境)、sit(除錯環境)、test(測驗環境)、prod(生產環境),
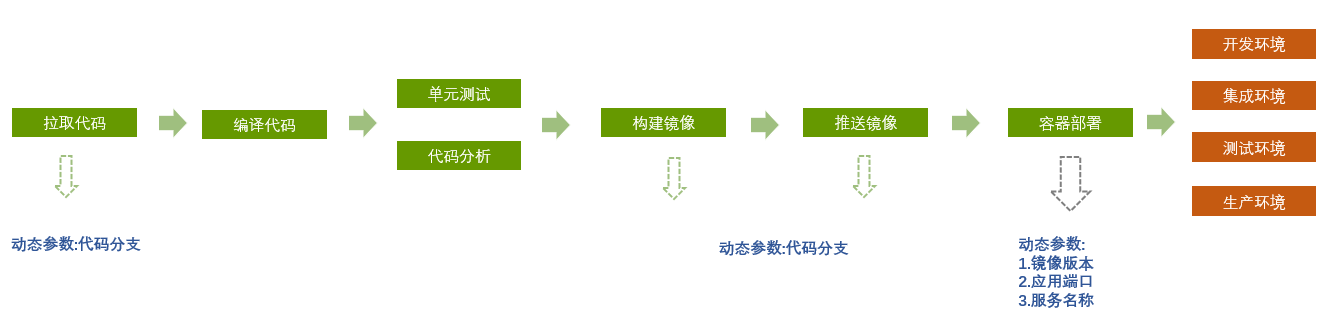
出于簡化使用與維護的考慮,計劃對每個工程模塊只維護一條流水線,通過構建時選擇不同的環境引數來實作定制化打包與部署,
KubeSphere 和 Kubernetes 目前在部門是以單機版形式安裝的,故對于不同環境的區分主要是通過分配不同埠來實作,具體實作時需要能在 Jenkins 和 Kubernetes 的 yaml 檔案中都能動態的獲取對應的埠引數和專案名稱,參考實作代碼如下:
-
在基于
Groovy的script中根據選擇環境動態分配相關埠switch(PRODUCT_PHASE) { case "sit": env.NODE_PORT = 13003 env.DUBBO_PORT = 13903 break case "test": env.NODE_PORT = 14003 env.DUBBO_PORT = 14903 break case "prod": env.NODE_PORT = 15003 env.DUBBO_PORT = 15903 break } -
script中讀取引數print env.DUBBO_IP -
shell中讀取引數docker build -f kubesphere/Dockerfile \ -t idp-data:$BUILD_TAG \ --build-arg PROJECT_VERSION=$PROJECT_VERSION \ --build-arg NODE_PORT=$NODE_PORT \ --build-arg DUBBO_PORT=$DUBBO_PORT \ --build-arg PRODUCT_PHASE=$PRODUCT_PHASE . -
yaml檔案中讀取引數spec: ports: - name: http port: $NODE_PORT protocol: TCP targetPort: $NODE_PORT nodePort: $NODE_PORT - name: dubbo port: $DUBBO_PORT protocol: TCP targetPort: $DUBBO_PORT nodePort: $DUBBO_PORT selector: app: lucumt-data-$PRODUCT_PHASE sessionAffinity: None type: NodePort
運行效果類似下圖:
詳細內容請參見KubeSphere 使用心得,
環境擴容
基于前述方式搭建的 4 套環境一開始使用較為順利,但隨著專案的推進以及開發人員的增多,同時有多個功能模塊需要并行開發與測驗,導致原有的 4 套環境不夠用,經過一番摸索后,實作了結合 Nacos在 KubeSphere 中動態配置多套環境功能,通過修改 Nacos 中的JSON組態檔可很容易的從 4 套擴展為 16 套甚至更多,
結合專案實際情況以及避免后續再次修改 KubeSphere 流水線,為了實作靈活的配置多套環境,制定了如下 2 個規則:
- 埠資訊存放到組態檔中,KubeSphere 在構建時去流水線讀取相關配置
- 當需要擴展環境或修改埠時,不需要修改 KubeSphere 中的流水線,只需要修改對應的埠組態檔即可
由于專案中采用 Nacos 作為配置中心與服務管理平臺,故決定采用 Nacos 作為埠的配置中心,實作流程如下:
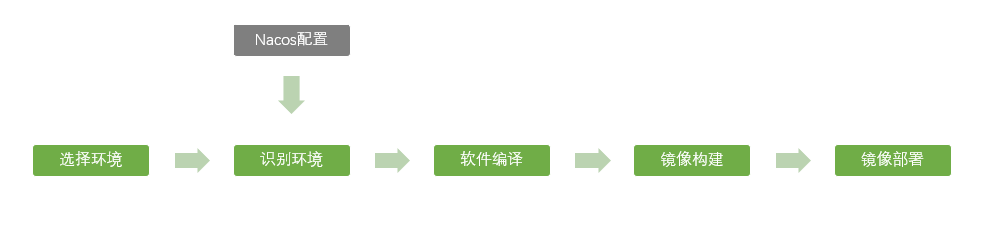
基于上述流程,在具體實作時面臨如下問題:
- 利用
Groovy代碼獲取Nacos中特定的埠JSON組態檔,并能動態決議; - 利用
Groovy代碼根據輸入輸入引數動態的獲取Nacos中對應的namespace; - 由于環境的增多,不可能每套環境都準備一個
YAML檔案,此時需要動態的讀取并更新YAML檔案,
由于 Jenkins 默認不支持 JSON、YAML 的決議,需要在 Jenkins 中預先安裝 Pipeline Utility Steps插件,該插件提供了對 JSON、YAML、CSV、PROPERTIES 等常見檔案格式的讀取與修改操作,
-
JSON檔案設計如下,通過 env、server、dubbo 等屬性記錄環境和埠資訊,通過 project 來記錄具體的專案名稱,由于組態檔中的 key 都是固定的,后續Groovy決議時會較為方便,在需要擴展環境時只需要更新此JSON檔案即可,{ "portConfig":[ { "project":"lucumt-system", "ports":[ { "env":"dev-1", "server":12001, "dubbo":12002 }, { "env":"dev-2", "server":12201, "dubbo":12202 } ] }, { "project":"lucumt-idp", "ports":[ { "env":"dev-1", "server":13001, "dubbo":13002 }, { "env":"dev-2", "server":13201, "dubbo":13202 } ] } ] } -
Nacos Open Api 中可知查詢
namespace的請求為/nacos/v1/console/namespaces,查詢組態檔的請求為/nacos/v1/cs/configs,基于Groovy的讀取代碼如下:response = sh(script: "curl -X GET 'http://xxx.xxx.xxx.xxx:8848/nacos/v1/console/namespaces'", returnStdout: true) jsonData = https://www.cnblogs.com/kubesphere/archive/2023/04/20/readJSON text: response namespaces = jsonData.data for(nm in namespaces){ if(BUILD_TYPE==nm.namespaceShowName){ NACOS_NAMESPACE = nm.namespace } } response = sh(script:"curl -X GET 'http://xxx.xxx.xxx.xxx:8848/nacos/v1/cs/configs?dataId=idp-custom-config.json&group=idp-custom-config&tenant=0f894ca6-4231-43dd-b9f3-960c02ad20fa'", returnStdout: true) jsonData = https://www.cnblogs.com/kubesphere/archive/2023/04/20/readJSON text: response configs = jsonData.portConfig for(config in configs){ project = config.project if(project!=PROJECT_NAME){ continue } ports = config.ports for(port in ports){ if(port.env!=BUILD_TYPE){ continue } env.NODE_PORT = port.server } } -
動態更新
yaml檔案yamlFile = 'src/main/resources/bootstrap-dev.yml' yamlData = https://www.cnblogs.com/kubesphere/archive/2023/04/20/readYaml file: yamlFile yamlData.spring.cloud.nacos.discovery.group = BUILD_TYPE yamlData.spring.cloud.nacos.discovery.namespace = NACOS_NAMESPACE yamlData.spring.cloud.nacos.config.namespace = NACOS_NAMESPACE sh"rm $yamlFile" writeYaml file: yamlFile, data: yamlData
詳細內容請參見利用 Nacos 與 KubeSphere 創建多套開發與測驗環境,
擴展功能
-
在專案構建時添加審核功能,對于
test和prod環境必須經過相關人的審核才能進行后續構建流程,避免破壞相關版本的穩定性,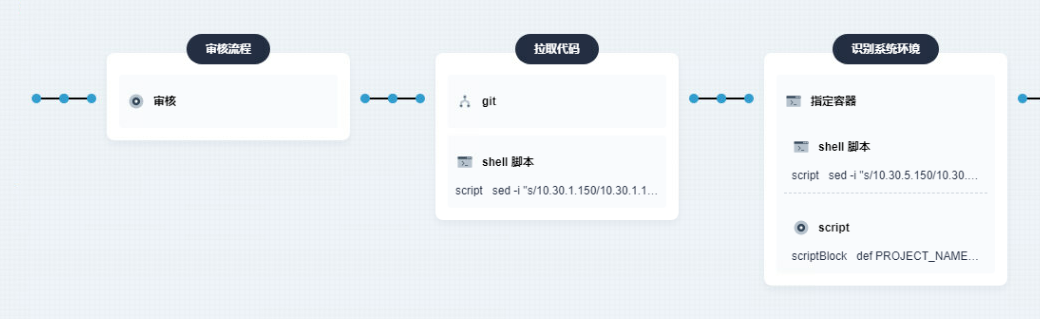
-
在 KubeSphere 的容器組頁面可以查看 pod 節點的 CPU 和記憶體消耗,可初步滿足對代碼潛在性能問題的排查,
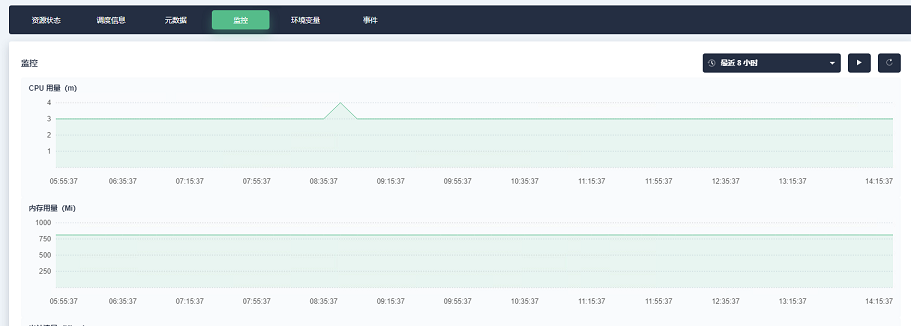
-
在專案構建完成時發送郵件通知給相關人,
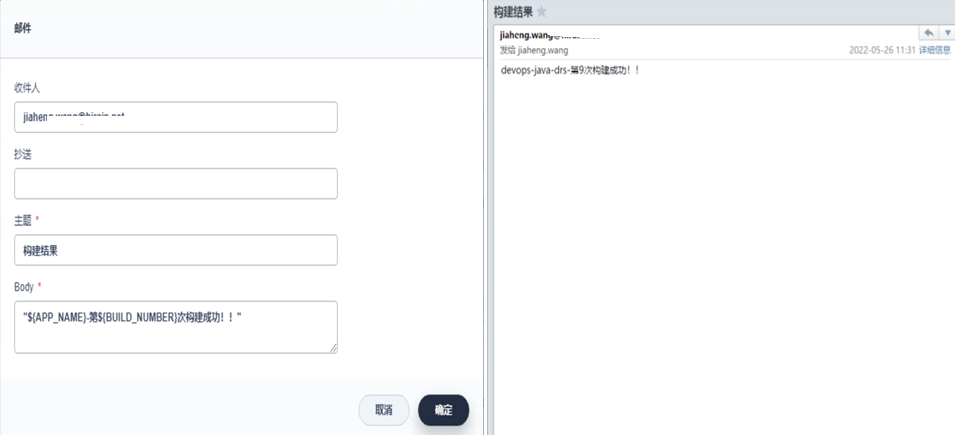
外部部署
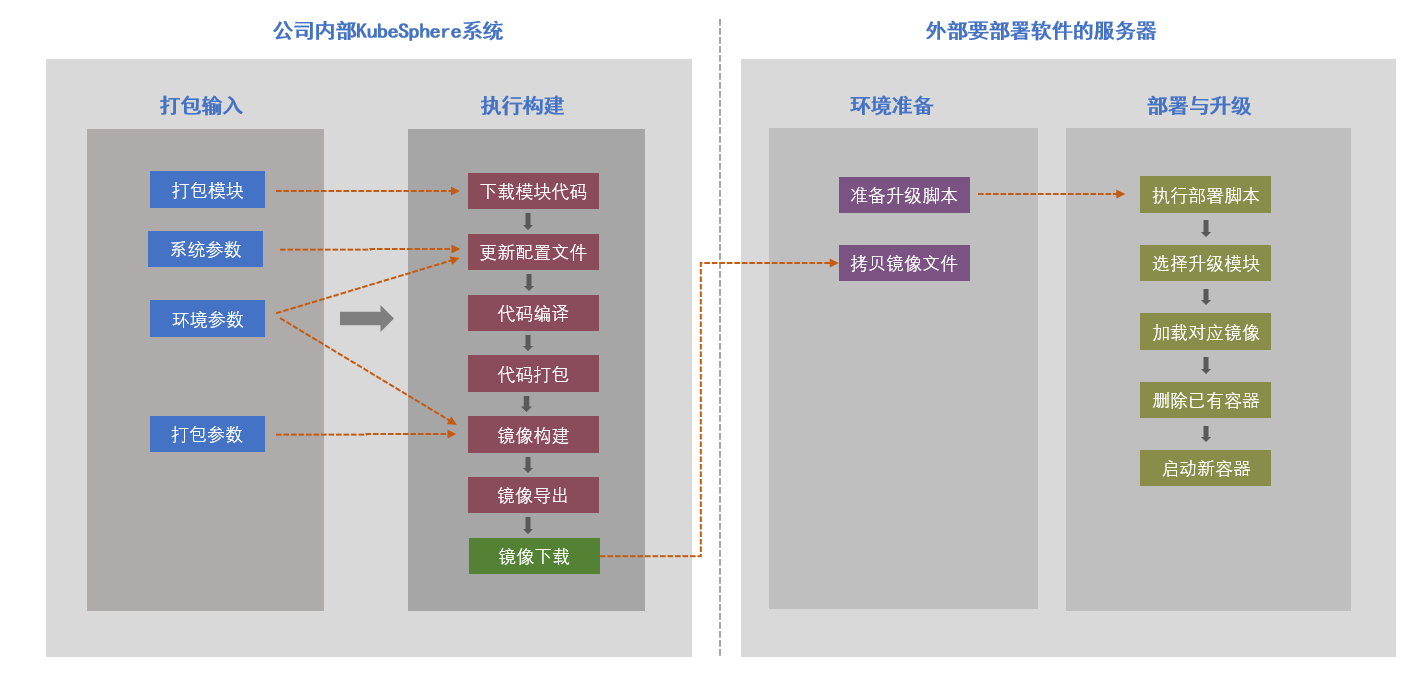
部門內部的軟體最終都會銷售并交付給相關客戶,由于客戶網路與公司網路不通以及代碼保密等要求,無法在客戶現場使用原有的 Jenkins 流水線進行部署交付,基于此部門采取折中方案:在公司內部通過 KubeSphere 進行編譯打包,匯出 Docker 鏡像,拷貝到客戶處然后基于 Docker 鏡像部署運行,具體請參見如下鏈接:
- 在 Jenkins 中根據配置從不同的倉庫中 Checkout 代碼
- 利用 shell 腳本實作將微服務程式以 docker 容器方式自動部署
使用協助
在使用程序中確實遇到了不少問題,主要通過如下三條途徑解決:
- 閱讀官方檔案,根據檔案說明操作;
- 若官網檔案沒有,則去用戶論壇查看是否有人遇到類似問題或直接發帖;
- 通過微信群尋求協助,
根據部門使用經驗,90% 的問題可通過官方檔案或用戶論壇獲得答案,
使用效果
部分同事習慣于原始的手工操作或基于 Docker 部署,導致在推廣程序中受到了一定的阻力,部門內部基于充分溝通和逐步替換的方式引導相關同事來慢慢適應,經過約一年的時間磨合,大家都認可了擁抱云原生和 KubeSphere 給我們帶來的便利,使用過的同事都說很香!
對我司而言,有如下幾個方面的提升:
- 研發人員幾乎不用耗費時間在軟體的部署和監控上,節省約 20% 時間,產品迭代速度更快;
- 定制化的功能通過腳本實作,徹底杜絕了給客戶交付軟體時由于人工疏漏導致的偶發問題,在提高軟體交付質量的同時也提升了客戶我司的認可度;
- 軟體開發、測驗流程更規范,通過在
Jenkins流水線強制添加各種規范檢查和審核流程,實作了軟體研發的規范統一,代碼質量更高,更利于擴展維護,同時也在一定程式上減少了由于人員流失/變更對專案造成的影響; - 基于
KubeSphere的云原生部署結合Nacos可以更快速的分配多套環境,有效的實作了開發、測驗、生產環境的隔離,在云仿真相關的業務場景中可基于業務場景更方便的對pod進行監控與調整,前瞻性的業務研發開展更順利,

未來規劃
結合公司與部門的實際情況,短期的規劃依然是完善基于 Jenkins 的 CI/CD 使用來完善打包與部署流程,部門內部在進行全面 web 化,基于此中長期擁抱云原生,
- 接入企業微信,將構建與運行結果隨時通知相關人,構建結果與專案監控更實時;
- 將部門內部基于
Eclipse RCP的桌面應用程式通過Jenkins實作標準化與自動化的構建; - 將底層的
Kubernetes從單機升級為集群,支持更多pod的部署,支持公司內部需要大量pod并發運行的云仿真專案; - 部門內部的
web專案全部通過KubeSphere構建部署,完善其使用檔案,挖掘KubeSphere在部門業務中新的應用場景(如對設計檔案、開發檔案、bug 修復的定時與強制檢查通知等),
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/550683.html
標籤:其他
下一篇:返回列表