國內視頻地址:https://www.bilibili.com/video/BV17441137fa/?spm_id_from=333.880.my_history.page.click&vd_source=bda72e785d42f592b8a2dc6c2aad2409
1 NLP 基礎
1.1 詞的表示程序演進:
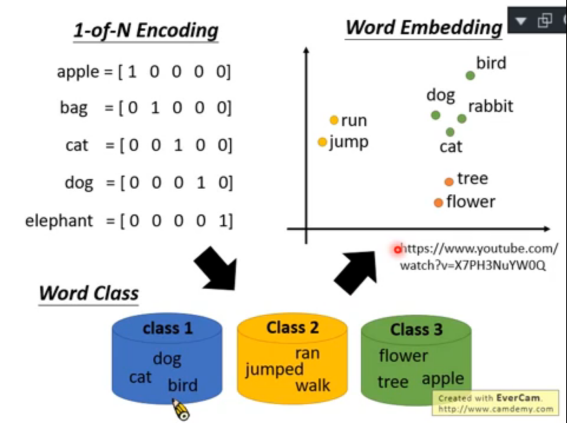
- one-hot 編碼
- 詞袋模型
- word embedding
1.2 multiple sense
1)明確兩個概念:token 和 type
- type:形式
- token:含義
例如 bank 有很多不同的(token)含義(銀行、河岸等),但它們都有著相同的(type)形式,
2)考慮到上面的問題,現在的 embedding 做法是為每個 token 提供一個 word embedding
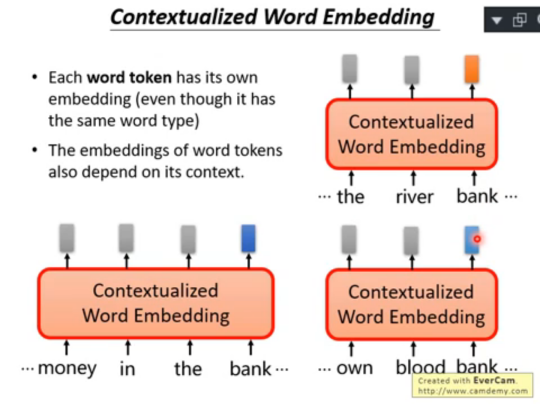
然后具有相近語意的 token 也具有較為接近的 embedding 距離,
1.3 如何 embedding
1)基于 RNN 的 ELMO
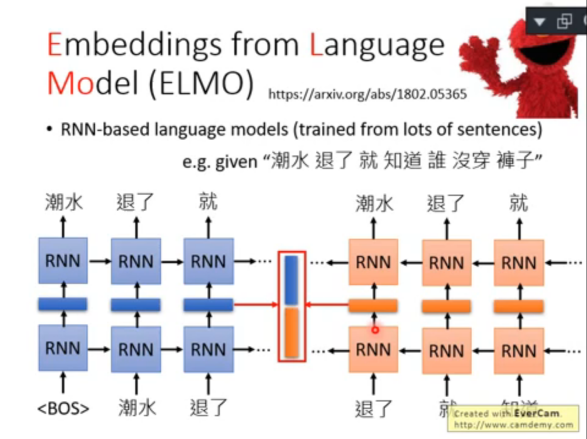
最終我們取 hidden layer 層的向量做為 token 的 embedding,
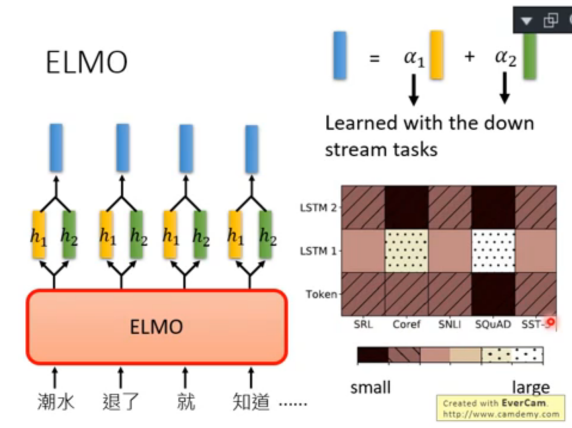
或者更進一步,通過 weight 將所有的輸出進行加權求和:
2)基于 Bert
Bert 基于 Transformer,關于 transformer 可以參考:
- https://zhuanlan.zhihu.com/p/526155983
- https://zhuanlan.zhihu.com/p/526694027
bert 的原理可能無法一直記得很清楚,但我們只需要記得 bert 的作用,簡單來說可以理解為 transformer 中的 encoder,給定一個句子(或詞匯),輸出該句子(或詞匯)的 embedding 表示:
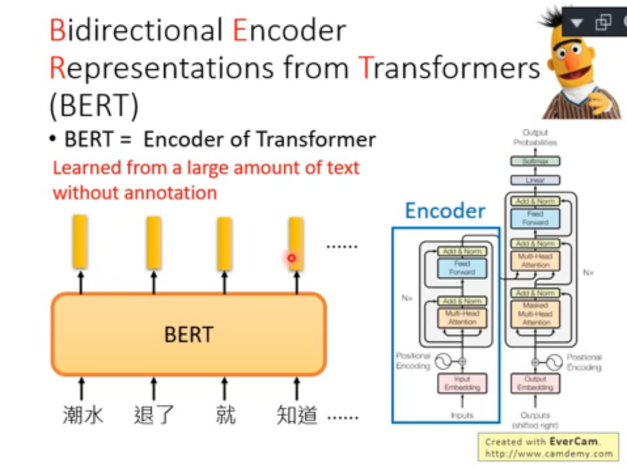
注意:這里圖片中中文的例子是用“詞”作為輸入,但是更推薦用中文的 “字”作為輸入,因為中文的“字”是有限的,而“詞”理論上是無窮的,這會導致編碼空間非常大,
2 BERT 介紹
2.1 背景
可以參考上面 1.3 節 2),
2.2 如何訓練 Bert
1)方法一:Masked Language Model(Masked LM)
采用對輸入進行 mask 讓其重建來訓:
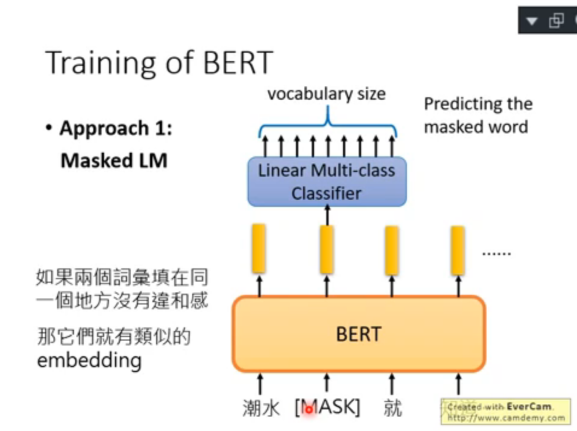
- 將輸入的某個詞 mask 掉,然后取其輸出 embedding,丟入一個 multi-class classifier 中,要求其預測出現在被 mask 掉的那個詞匯是哪個詞匯
- 由于 linear classifier 的分類能力較弱,所以 BERT 就需要輸出一個表征能力比較好的 embedding,這樣就巧妙的獲取了對特定詞的良好的 embedding
- 另一個好處是相似的詞,在這種訓練框架下,也能獲得距離較近的 embedding 表征
2)方法二:Next sentence Prediction
采用預測兩個句子是否能連成一個句子:
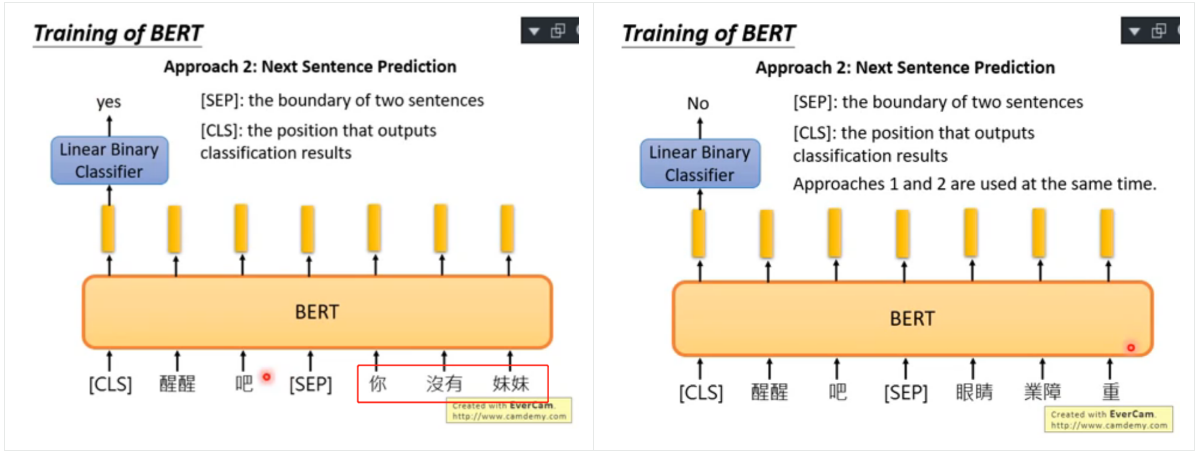
- 在兩個句子間加一個特殊符號 [SEP] 標識告訴模型這是兩個句子
- 在開頭加一個特殊符號 [CLS] 告訴模型接下來做的是分類任務,就是預測是否能組成一個句子
這里注意:由于 BERT 的內部是 transformer 架構,使用 self-attention 機制使得任意兩個輸入向量之間的距離是一樣的,所以任務標識可以放在開頭,如果單向 RNN 結構,則需要放在末尾, - 同上一節一樣,linear classifier 的分類能力有限,這也會促使 BERT 去產生更好的 embedding
3)小結
通常情況下,上面這兩種方式在訓練 BERT 時是一起使用的,讓 BERT 同時去解這兩個任務時,它會學的更好,
2.3 How to use Bert
在 BERT 的論文中,作者其實時將 BERT model 模塊本身和下游任務一起訓練的(當然 bert 大部分情況下都是 fine-tune),為此舉了四個例子來展示如何實作訓練和使用
1)case 1:sentence classification
輸入:句子
輸出:預測類別
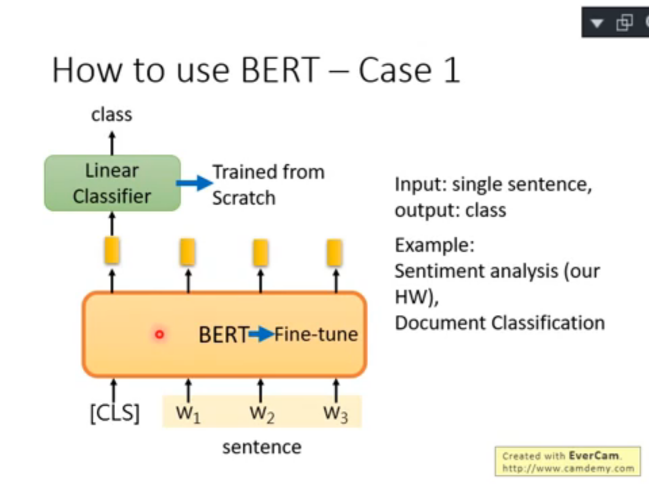
- 下游任務是文本分類,由 Linear Classifier 模塊表示,這個部分是通過隨機初始化引數,從頭開始學的
- 文本表征(embedding)模塊主要就是 BERT,這部分是 Fine-tune 形式參與訓練的
2)case 2:each word insentence classification
輸入:句子
輸出:句子中每個詞的預測類別
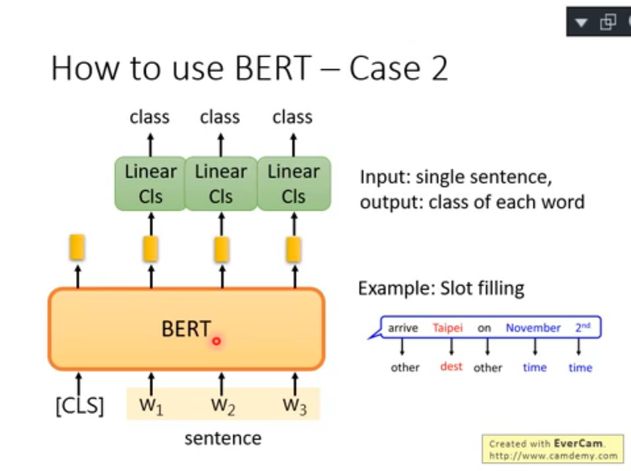
- Linear Cls 是下游任務模塊,從頭訓
- Bert 采用 fine-tune 方式
- 訓練時需要給定當前句子 以及 當前句子中每個詞的類別
3)case 3:Nature Language Inference(推理)
輸入:兩個句子,一個作為前提(A),一個作為假設結論(B)
輸出:預測類別,即判斷以 A 作為前提的情況下,B 假設是否成立(T、F or unknown)
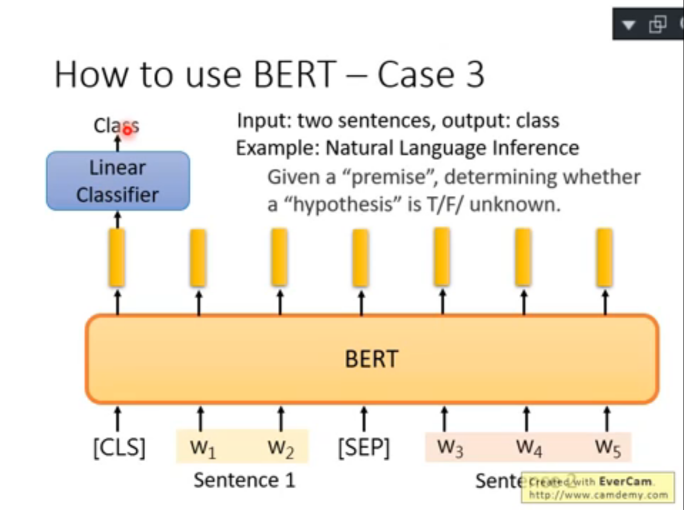
- sentence 1 作為 premise,采用 [SEP] 與 sentence 2 作為 hypothesis 分隔開;
- 第一個位置用于 CLS;
4)case 4:Extraction-base Question(抽取文章用于回答,QA)
先介紹這個 case 吧:
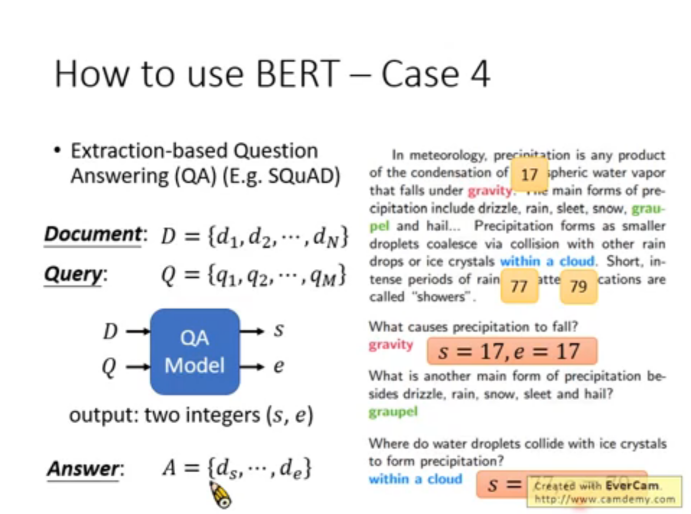
通常情況下,這類問題期望我們輸入一篇文章給 Model,然后根據我們的 question 由 model 抽取出答案,
注意:這里面有個限制就是 answer 是要在文章中出現過的,比如上圖第一個問題的回答 gravity 就在文章中出現過,
這個問題的結構化表示如上圖,定義文章 Document 由一系列 token 組成(\(\{d_1, d_2, ..., d_N\}\)),其中 \(d_i\)即表示第 i 個 token,同理問題 Query 也用此方式表示,
接下來,我們將 D 和 Q 作為輸入送入 Model,模型會輸出來兩個整數 s、e,分表代表回答內容在 Document 中的起始位置,例如上面第一個問題,答案 gravity 在 D 中的位置區間就是 17-17(第17個單詞到第17個單詞),
那么,BERT 中如何解這個問題呢?
- 首先,將 question 和 document 拼接作為 BERT 的輸入
- 接兩個網路層分別產出兩個向量(下圖中紅色、藍色),這兩個向量和 BERT 輸出的 embedding 向量具有相同的 size
- 先將紅色向量與 document 中每個輸出 token 進行點乘(dot product),結果過 softmax,得到每個 token 的概率表征,取其中最大的作為 s 輸出(例如圖1中第二個 token 的概率最大,所以 s=2)
- 再將藍色向量與 document 中每個輸出 token 進行點乘,過 softmax 后,取概率最大的位置作為 e 的輸出
- 最后的答案就由 s、e 來進行定位
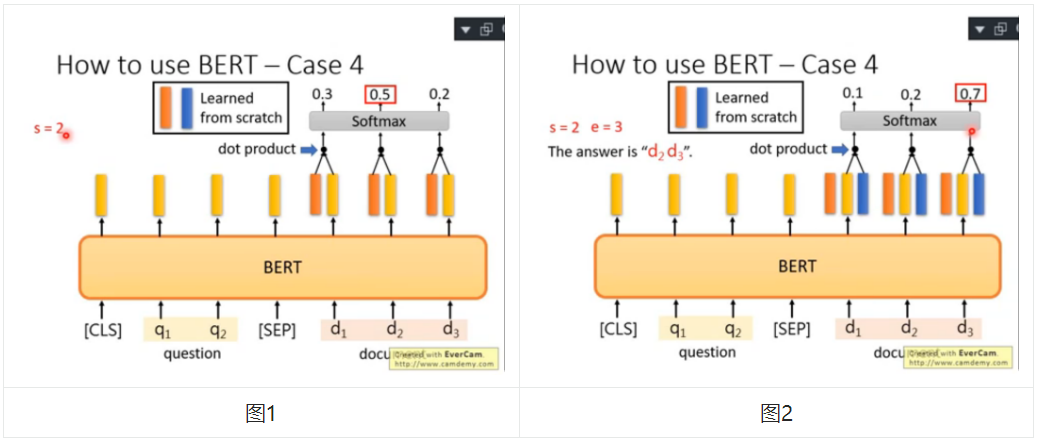
- s、e 任務的點乘向量與 token 的 Embedding 向量維度一致
- 如果 s、e 不滿足正常情況(s<=e),此種情況作為“此題無解”輸出
- Bert 采用 fine-tune,紅、藍向量從頭開始訓
2.4 for chinese:ERNIE
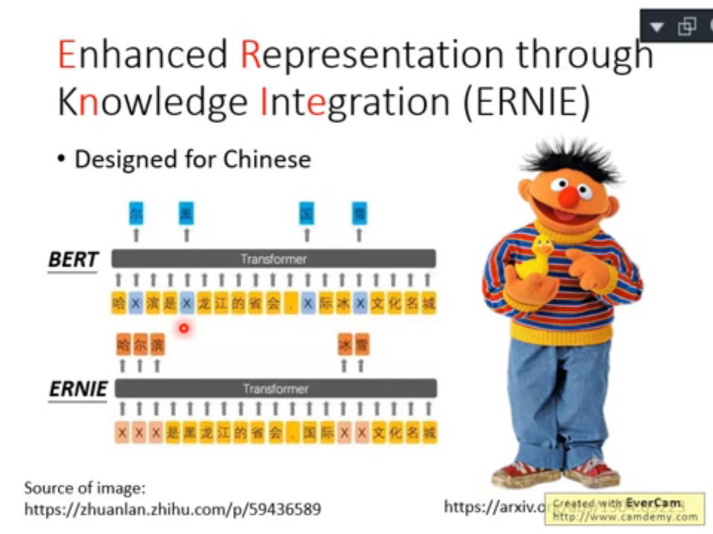
ERNIE 是為中文設計的 BERT,其采用的訓練方式有一點不一樣,因為 BERT 采用對單個 字 進行 mask,但這在中文中是很容易被猜出來的,所以其采用了 mask 詞 的方式進行訓練,
這里只是提一嘴,更具體的還是看論文吧:https://arxiv.org/abs/1904.09223
2.5 BERT 每層的側重
常用 Bert 為 24 層,nlp 任務其實是一個 pipiline 任務,從語言學的角度上來說,對一個句子的分析通常包含詞法分析、語法分析、語意分析等程序,這張圖就展示了在不同任務上,Bert 的不同層所占的權重大小(也即哪些層的輸出在這些特定任務上的表現更好):
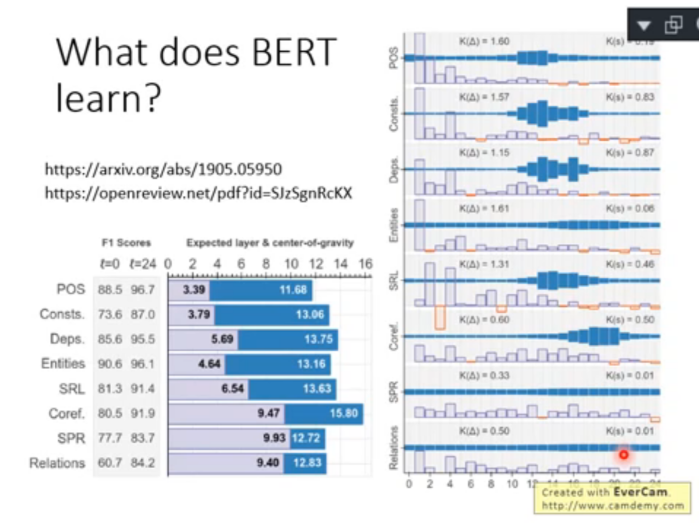
這啟發我們,可以根據 nlp 任務的不同特性來選擇使用 bert 不同層抽象出來的 token embedding 進行使用,例如對于 POS 任務來說,第 11-13 層的權重較大,其 hidden embedding 效果較好,
3 GPT-2
Generative Pre-Training(GPT)本質上就是一個巨大無比的 language model,其底層采用的是 transformer 的 Decoder 模塊,

3.1 GPT 的訓練
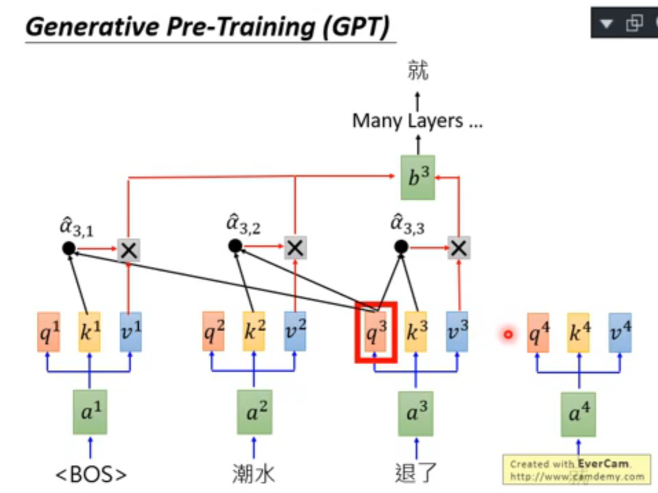
- 訓練模式和 bert 類似,輸入一個句子的開始標志
、當前詞匯,預測下一個詞匯 - 每個詞匯過 self-attention,其 query 輸出和前面的詞的 key 輸出做權重計算,同時也和自己的 key 做權值計算,最后將所有計算結果做 sum,注意這里通常是過好幾層 self-attention 層,猜得到最終的輸出,最終的輸出其實是一個 embedding,
3.2 zero-shot
GPT 是非監督學習,采用 zero-shot 方式進行訓練,即使是在這種缺失監督資訊的情況下,仍然能奇跡般的泛化出對某些任務的解題能力,這是比較神奇的,

- Reading Comprehension:只通過輸入文章表征、query 表征,然后接上 "A:" 提示標志,GPT 就會自動的給出該 query 的回答,上圖折線是不同引數(橫軸)下 GPT 的 F1(縱軸)指標效果;
- Summarization:類似的,給出文章表征和特定 "TL;DR:" 提示標志,就會得到摘要;
- Translation:給出前兩個如上圖所述的范式,再給出第三行范式,就會自動的得到對應的法語翻譯結果(但是這個任務的效果很差);
本文來自博客園,作者:sinatJ,轉載請注明原文鏈接:https://www.cnblogs.com/zishu/p/17363205.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551467.html
標籤:其他
上一篇:閱讀文獻《DCRNet:Dilated Convolution based CSI Feedback Compression for Massive MIMO Systems》
下一篇:返回列表