深度學習的實踐層面
訓練集 驗證集 測驗集
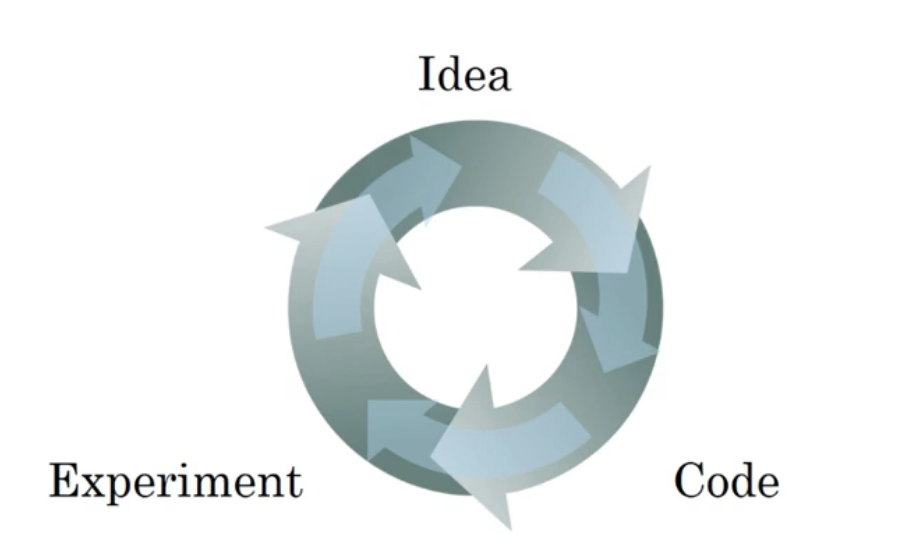
程序
神經網路的訓練是一個需要不斷迭代的程序,一般先提出idea,然后編碼實作、測驗,根據測驗結果再次調整思路......
分組與比例
資料集通常分為3個部分:訓練集、驗證集和測驗集,
- 訓練集用于訓練模型的引數,
- 驗證集用于選擇最好的模型,
- 測驗集用于評估訓練結果,
一般講資料集按照60%訓練,20%驗證和20%測驗集來劃分,
當資料集的大小達到一百萬時,則比例可以調整為98%+1%+1%,因為驗證集和測驗集實際上不需要太多,
如果超過百萬級別,甚至可以調整為99.5%+0.25%+0.25%.
分布
訓練集、驗證集和測驗集應當保證分布一致,
防止出現這種情況:在分辨貓圖片的模型訓練中,如果訓練集都是貓的圖片,本來訓練得很好,但是測驗集都是狗的圖片,結果得到了很差的評估,
偏差 方差
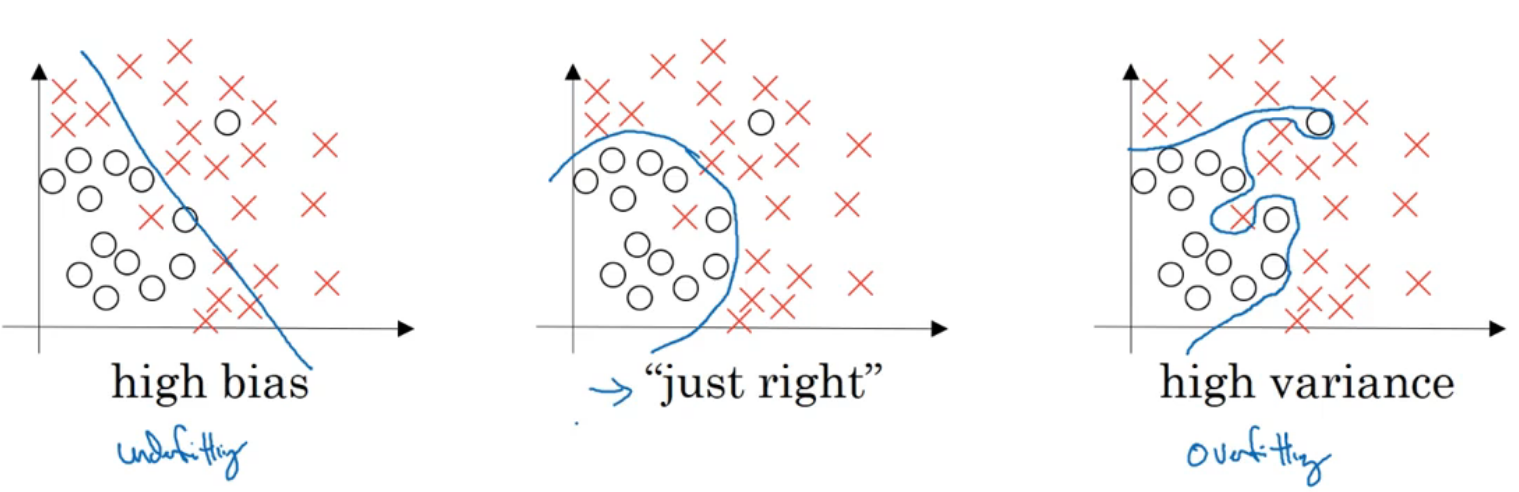
- 高偏差:欠擬合
- 高方差:過擬合
如果出現高偏差問題,一般無法通過增加資料量解決問題,如果出現高方差問題,可以嘗試使用正則化,
正則化
一般使用正則化來防止出現過擬合現象,
使用正則化會引入超引數\(\lambda\),
可以只正則化引數\(W\),因為偏置項\(b\)只是單個數字,正則化的意義不大,
L2正則化
正則項為:
\[\frac{\lambda}{2m}\parallel w \parallel_2^2=\frac{\lambda}{2m}\sum\limits_{j=1}^{n_x}w_j^2 \]其中\(\parallel w\parallel_2\)為\(w\)的L2范數,也叫歐幾里得范數,
L1正則化
使用的是L1范數,會使得模型變得稀疏(部分引數變為0),
L2正則化是較為常用的,
正則化如何生效?
誤差函式\(J\)中加入了正則項,而\(J\)的值又會影響引數的更新,
如果\(\lambda\)太大了,就會導致\(W\)幾乎為0,使得模型變得簡單,甚至可能欠擬合,
如果\(\lambda\)太小,對\(W\)的修正效果不大,如果原先模型就有過擬合現象,則不能很好的解決問題,
dropout正則化
隨機失活,到達某一層的時候,會先遍歷該層結點,以一定的概率(超引數)決定是否將其失活,
通過隨機失活可以避免一些\(W\)變得太大,導致過擬合,
使用dropout正則化之前,\(a\)的原本值假設是100,使用dropout正則化之后,如果存活概率設定為80%,那么\(a\)的值可能變為80,為了保持數值,應該計算a=a/0.8,
實施dropout正則化的相關知識:
- 每層的存活率可以設定不同值,做出相應調整,但是會引入較多超引數,
- 通常存活率不能設定太低,最好接近1,甚至大多數時候是不需要失活的,某些層直接設定為1,
其它正則化方法
-
資料擴增
如果資料集是影像,可以考慮通過旋轉,翻轉等操作來擴增資料集,
-
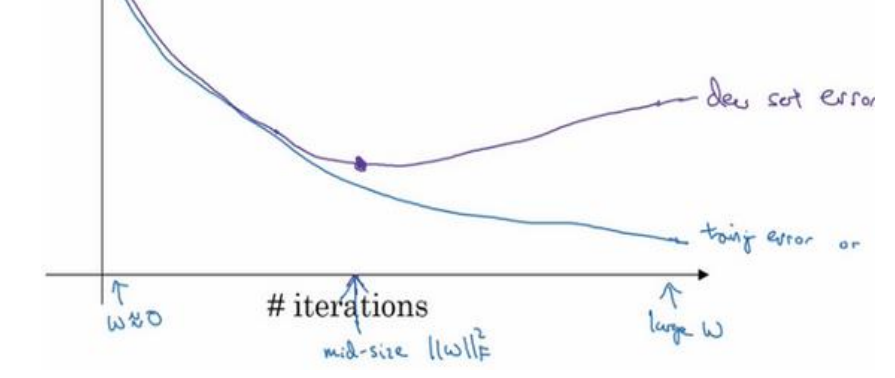
early stopping
有時候迭代次數太多反而得到較差的結果,提前結束訓練可以得到較好結果,
歸一化
可以使資料分布得更”均勻“
思路和標準化正態分布是一致的:
- 求均值,
- 求方差,
- \(X:=\frac{X-\mu}{\sigma^2}\)
歸一化可以提高訓練速度,
梯度爆炸和梯度消失
這個問題通常發生在層數較多的神經網路,
梯度爆炸:如果每個權重\(W\)都大于1,那么不斷地乘上\(W\),到最后輸出值會變得非常大,
? 這種情況下,可能導致\(W\)的值越來越大,最后甚至溢位為NaN.
梯度消失:如果每個權重\(W\)都小于1,那么不斷地乘上\(W\),到最后輸出值會變得非常小,
? 這種情況下,可能因為梯度太小,導致梯度下降速度緩慢,
權重初始化
合理的權重初始化可以緩解梯度爆炸和梯度消失帶來的痛點,
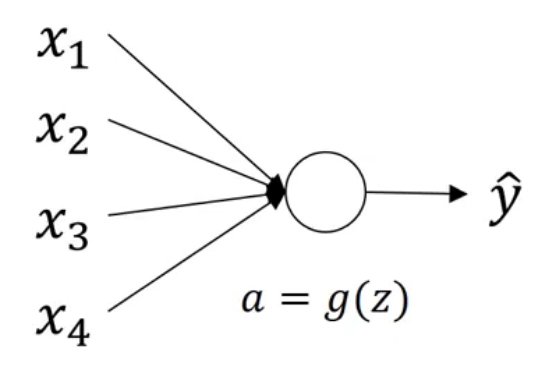
對于上圖這種簡單案例,有:
\[z = \sum\limits_{i=1}^nw_ix_i \]可以考慮將權重初始化為:
\[w_i=\frac{1}{n} \]其它激活函式
-
如果使用的是Relu,則建議\(w_i=\frac{2}{n}\)
-
如果使用的是\(\tanh\),則建議\(w_i=\sqrt{\frac{1}{n}}\)
梯度的數值逼近
聯系導數與導數的近似值即可:
-
\(f'(x)=\lim\limits_{\epsilon\to0}\frac{f(x+\epsilon)-f(x-\epsilon)}{2\epsilon}\)
-
\(f'(x)\approx\frac{f(x+\epsilon)-f(x-\epsilon)}{2\epsilon}\)
梯度檢驗
- 將\(W\)和\(b\)都扁平化組合起來,形成一個向量\(\theta\)
- 將\(dW\)和\(db\)都扁平化組合起來,形成一個向量\(d\theta\)
則誤差函式\(J(W,b)\)可以記為\(J(\theta)\).
對于向量\(\theta\)的每一項\(\theta_i\),我們可以計算其近似值:
\[d\theta_{approx}[i]=\frac{J(\theta_1,\theta_2,\cdots,\theta_i+\epsilon,\cdots)-J(\theta_1,\theta_2,\cdots,\theta_i-\epsilon,\cdots)}{2\epsilon} \]這個近似值應該接近它的真實值:\(d\theta[i]\)
評估指標
\[\frac{\parallel d\theta_{approx}-d\theta\parallel_2}{ \parallel d\theta_{approx}\parallel_2 +\parallel d\theta\parallel_2 } \]分子部分:歐幾里得范數,計算兩個向量”終點“之間的”距離“,
分母部分:防止分子數值相差過大,分母將這個指標變成一種”比率“,
參考數值
- 如果指標的數量級為\(10^{-7}\),則是好的結果,
- 如果指標的數量級為\(10^{-5}\),中規中矩,可能有問題,
- 如果指標的數量級為\(10^{-3}\),則是壞的結果,需要調整,
注意事項
- 不要在訓練中使用梯度檢驗,只用于除錯,
- 如果演算法的梯度檢驗失敗,要檢查所有項,檢查每一項,并試著找出 bug,
- 梯度檢驗不能與dropout同時使用,因為每次迭代程序中,dropout會隨機消除隱藏層單元的不同子集,難以計算dropout在梯度下降上的代價函式\(J\)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551468.html
標籤:其他
上一篇:[筆記] ELMO, BERT, GPT 簡單講解 - 李宏毅
下一篇:返回列表