一分鐘精華速覽
全鏈路灰度發布是指在微服務體系架構中,應用的新、舊版本間平滑過渡的一種發布方式,由于微服務之間依賴關系錯綜復雜,一次發布可能會涉及多個服務升級,所以在發布前進行小規模的生產環境驗證,讓新版本的應用實體來承接、處理限定規模或范圍的業務流量,能最大限度控制發布上線風險,保證業務連續性,
本文詳細解讀微盟全鏈路灰度平臺實踐難點、解決思路及使用場景,還原其服務百萬商家客戶的全程序,

作者介紹

微盟基礎架構團隊技術專家——戴明智
TakinTalks社區專家團成員,SpringFramework、Apache Skywalking社區Contributor,個人博客閱讀量100w+,2019年入職微盟,基礎架構團隊技術專家,參與并負責微盟全鏈路灰度平臺的建設,經歷了整個全鏈路灰度平臺從0到1 的全程序,
溫馨提醒:本文約6000字,預計花費12分鐘閱讀,
「TakinTalks穩定性社區」公眾號后臺回復 “交流” 進入讀者交流群;回復“0412”獲取課件資料;
背景
隨著微盟業務的高速發展,商家系統的迭代頻率和質量要求也在變高,在多環境推出之前,業務研發團隊進行產品并行迭代開發時,發布系統存在兩個非常顯著的問題——
1)只有一套標準的QA測驗環境,多版本并行測驗困難,
即當兩個版本涉及到同一個應用,則第二個版本就會因為環境占用,而無法開始測驗,這樣就嚴重影響了測驗和發布計劃,
2)微盟業務線眾多且存在相互依賴,發布程序中出現問題時需要回滾,靈活度和掌控力需進一步提升,
微盟業務線眾多且存在相互依賴,而微盟所有應用均采用微服務模式,以上導致微盟一次發布迭代涉及的應用數眾多,需要上下游人力協調進行發布,且發布程序中出現問題時需要挨個回滾,靈活度和掌控力需進一步提升,
微盟最終選擇引入全鏈路灰度發布來解決以上發布問題,當然,在近兩年的實踐和落地中,我們也遇到了不少挑戰,我將詳細分享微盟全鏈路灰度在落地程序中的一些難點和解決思路,
一、什么是全鏈路灰度?
1.1 全鏈路灰度
微服務全鏈路灰度是單體架構下灰度發布的衍生物,它的實施成本及復雜度更高,在單體架構下,一次迭代只會涉及到一個服務,但在微服務架構下,則需要鏈路上的多個服務同時進入灰度環境,
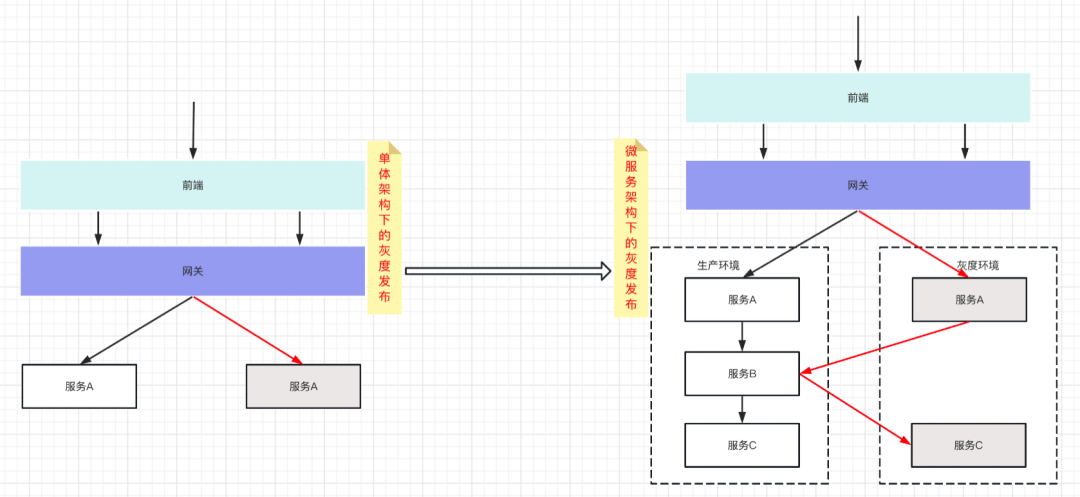
如圖所示,單體架構下灰度發布只涉及服務A,則只需要對服務A進行灰度,而微服務架構下,一個用戶請求鏈路上會涉及多個服務,此時則需要服務A和服務C同時進入灰度環境,因此,微服務架構下的灰度發布也被稱之為“全鏈路灰度”,
1.2 全鏈路灰度有哪些挑戰
全鏈路灰度我認為需要克服以下問題,
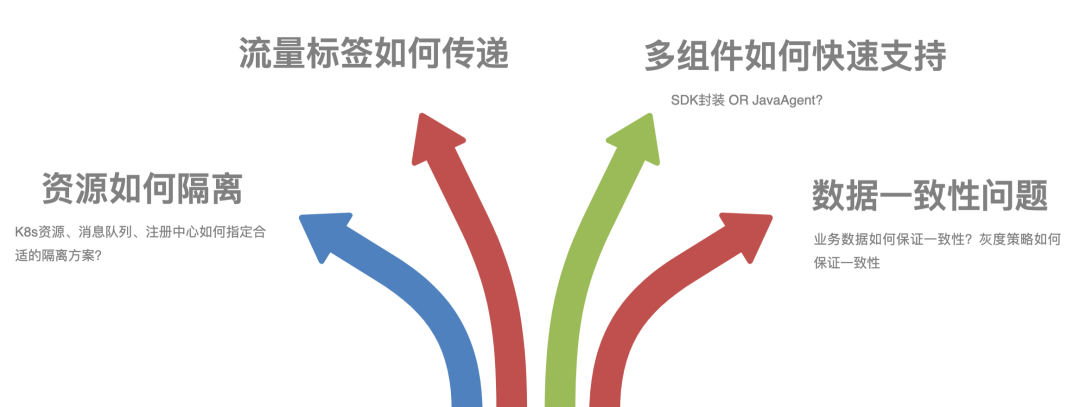
1)資源隔離:要做獨立的灰度環境,而這個獨立的灰度環境會涉及到很多資源,包括K8S資源、訊息佇列、注冊中心等,如何對這些資源制定合適的隔離方案?
2)流量標簽傳遞:我們要保證灰度流量在整個灰度環境里流轉,那么灰度流量標簽如何做到全鏈路的傳遞?
3)多組件支持:全鏈路灰度會涉及到大量組件和應用,尤其微盟的組件多、每個組件的版本多、框架也很多,且沒有統一標準,如何用一個合理的方式支持這些組件快速接入?
4)資料一致性:不管什么樣的灰度方案,都需要確保業務資料一致性,以及灰度策略一致性,這些資料一致性如何得到保證?
二、如何應對全鏈路灰度的挑戰?
2.1 挑戰1:資源如何隔離
2.1.1 資源隔離需要關注的指標
資源隔離要考慮很多方面,包括穩定性、實施復雜度、成本和性能,
穩定性是做隔離的一個重要指標,灰度須對生產環境的影響越小越好,且實施灰度方案時,不能影響生產呼叫的性能,復雜度高代表著其維護成本高,也越容易出錯,因此復雜度是越低越好,成本方面亦然,

2.1.2 K8S資源隔離
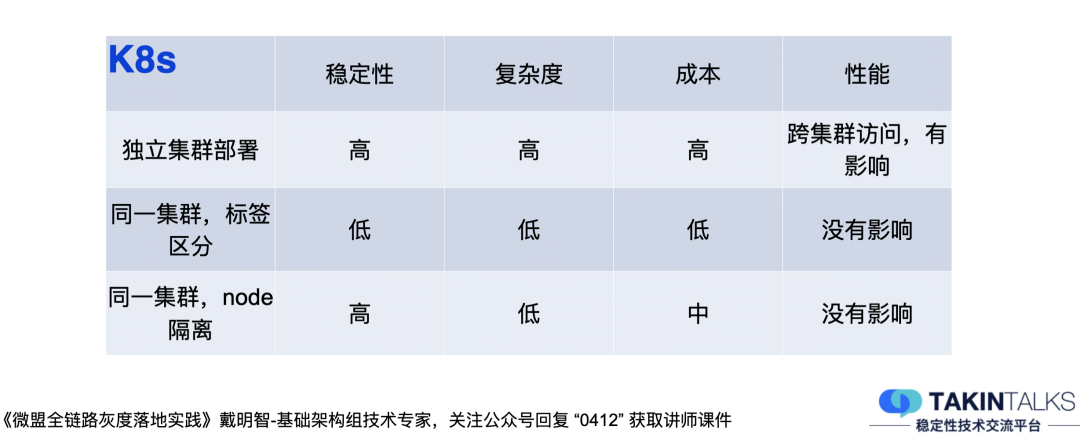
一般會有三種方案,獨立集群部署、同一集群標簽區分、同一集群node隔離,
1)獨立集群部署,不推薦,因為獨立集群部署相當于再部署了一套環境,盡管穩定性可能會高一些,但它的復雜度很高,成本也很高,除此之外還要解決跨集群訪問的問題,整體性價比不高,
2)同一套物理集群,通過標簽區分容器里的資源,它的穩定性相對來說會低一點,但是整體比較簡單,成本也低,性能也沒有影響,導致其穩定性低的原因,是灰度的所有POD和生產的所有POD共享同一套物理集群,當灰度和生產同時拉起時,就會導致Node的CPU和記憶體都飆高,從而影響生產,我們曾經就出現過,所有灰度同時拉起時,被調度到了同一臺物理機上,影響到了那臺Node機器上的生產環境的應用,
3)同一套物理集群,Node做隔離,即在同一套K8S集群里,Node機器通過標簽、POD親和性等機制,來保證灰度的POD優先調度到灰度的機器上,穩定性也因此得到提升,因為獨立出來的Node機器,需要設定冗余機器,所以其成本是居于方案一和方案二之間,
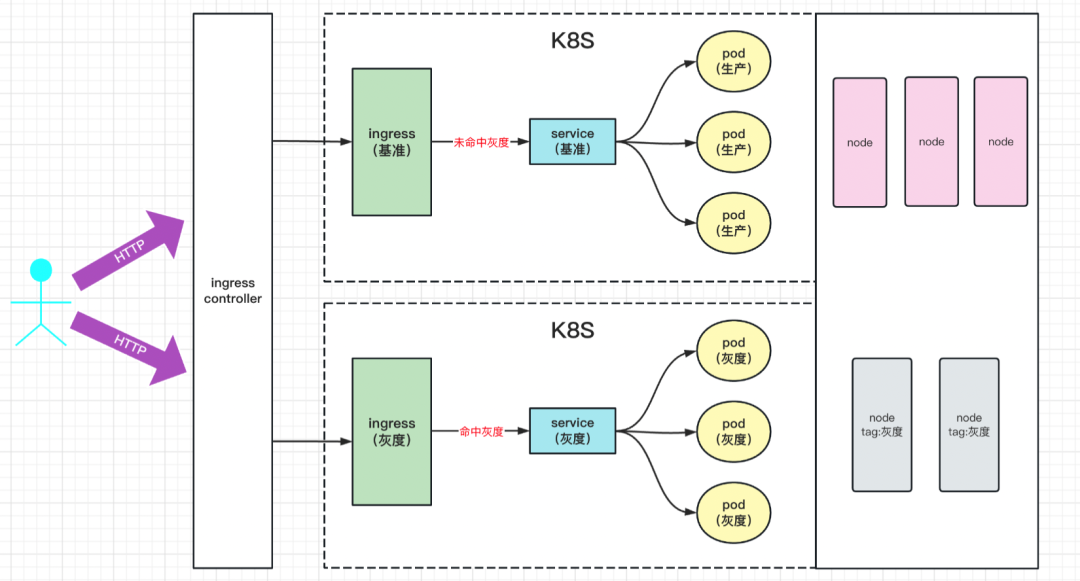
以上是K8S資源隔離后的一張架構圖,從這里可以看到Ingress、Service、POD都是通過灰度的標簽,做了邏輯上的隔離,至于Node上是否要做隔離,可以根據具體的情況而定,
我個人推薦Node做隔離,灰度的規模足夠大是需要隔離的,雖然會冗余20%~25%的Node機器,但是它帶來的穩定性收益是很高的,
2.1.3 注冊中?隔離
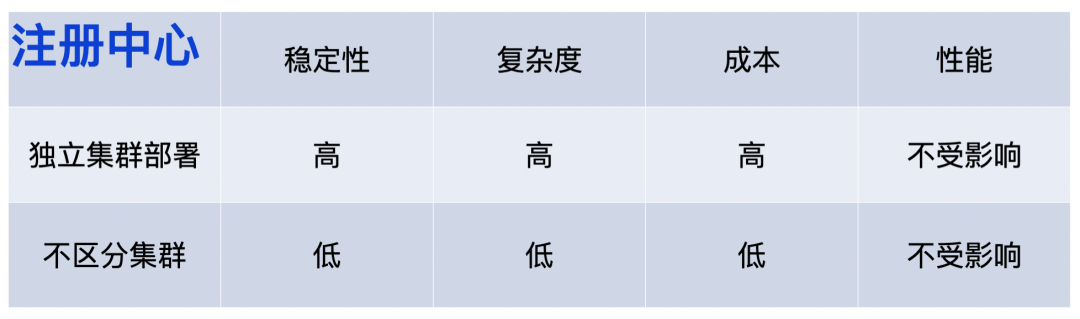
注冊中心的隔離主要考慮RPC的呼叫,即要保證RPC呼叫的穩定性,以及能夠區分RPC的流量,
注冊中心的隔離方式也有兩種,獨立集群部署和不區分集群,
1)獨立集群部署,如果注冊中心用的是ZK,就單獨為灰度去部署一套ZK,這樣它的穩定性會高一些,但復雜度也會相應較高,因為需要同時監聽兩套注冊中心上的服務提供方,還需要識別注冊中心是灰度的還是生產的,再去做呼叫,導致它的成本也會比較高,
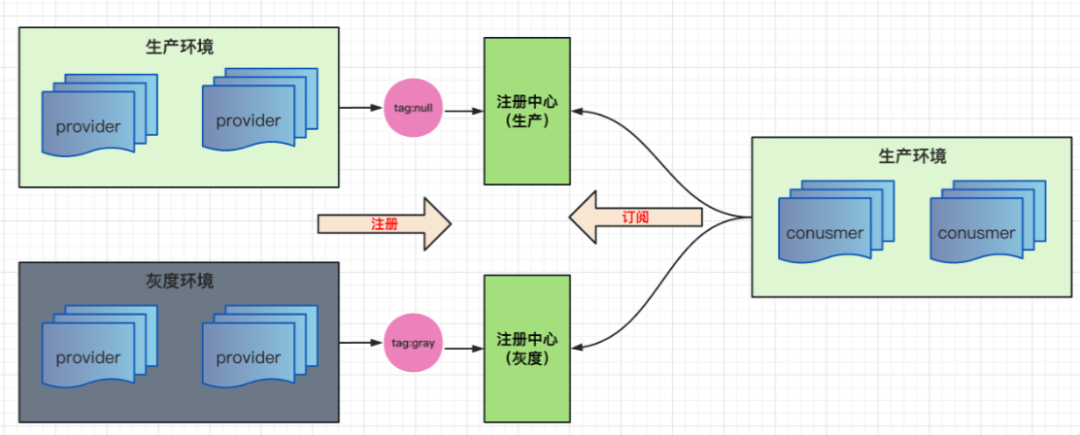
(獨立集群模式,生產環境和灰度環境分開注冊)
2)不區分集群,穩定性相對會低一些,因為如果使用同一套集群,那么在做灰度的程序中,到某一階段時,作業中心的負載會比較高,比如,如果用ZK,那么因為多了一些灰度的生產者和消費者,就會導致Z-node數量上升,節點激增,CPU也會上漲,此時就很可能會影響到生產上正常的服務訂閱和注冊,當然,若不區分集群,則復雜度和成本會比較低,
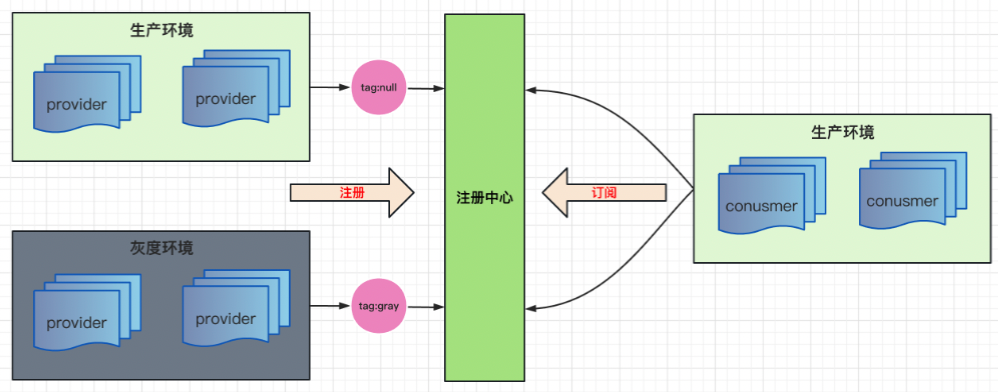
(使用同一集群模式,用標簽區分實體)
微盟使用了單一集群的方案,為了避免ZK負載過高,對ZK做了擴容,
2.1.4 訊息佇列隔離
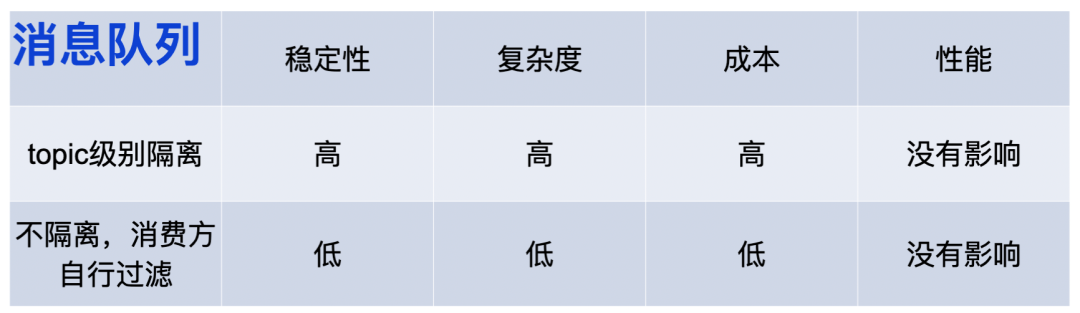
全鏈路灰度涉及到核心三個呼叫,正常的Http呼叫,還有RPC和訊息,所以訊息的隔離也很重要,
訊息佇列的隔離也有兩種方式,第一種是Topic級別的隔離,第二種是不隔離,消費方自行過濾,
1)Topic級別的隔離:也可以認為是一種物理上的隔離,因為每一個Topic對應的就是物理的Partition,不會因為生產環境的延遲導致灰度環境的延遲,而灰度環境也不會影響到生產環境,所以它的穩定性會比較高,為什么復雜度也會比較高?因為對一個Topic進行灰度,需要生產方把訊息同時生產到兩個Topic,消費方也需要同時消費兩個Topic中的訊息,這樣就比較復雜,
同時,一個Topic的生產方會有多個,當一個生產方需要灰度時,其他不必要做灰度的生產方,也必須把自己的訊息同時發布到灰度環境中去,這樣就會對其他生產方帶來額外的負擔,而新建一個Topic就意味著要多占一些磁區,所以其成本也相應會比較高,
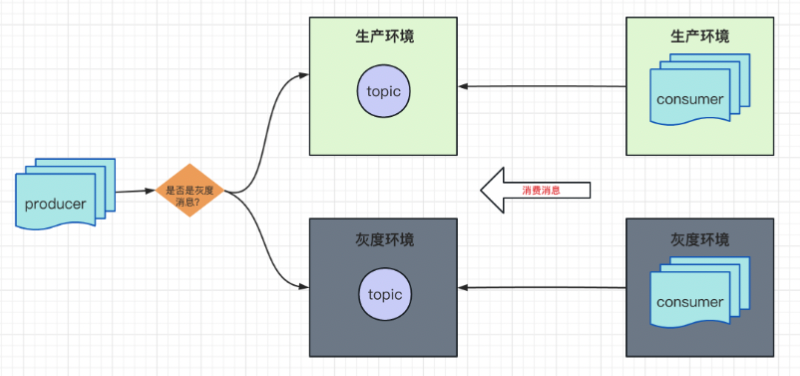
2)不做Topic級別的隔離:只在訊息生產時攜帶灰度標簽,消費方在消費時,根據訊息里的標簽自行過濾,消費方只消費其對應環境的訊息,比如,當生產環境的消費方拉到一潭訓度訊息時,直接不處理然后回應ZK就結束,同理,當灰度環境的消費方拉到生產訊息,也不做處理,這樣不會帶來額外的物理成本,所以成本也相對較低,性能不會受影響,
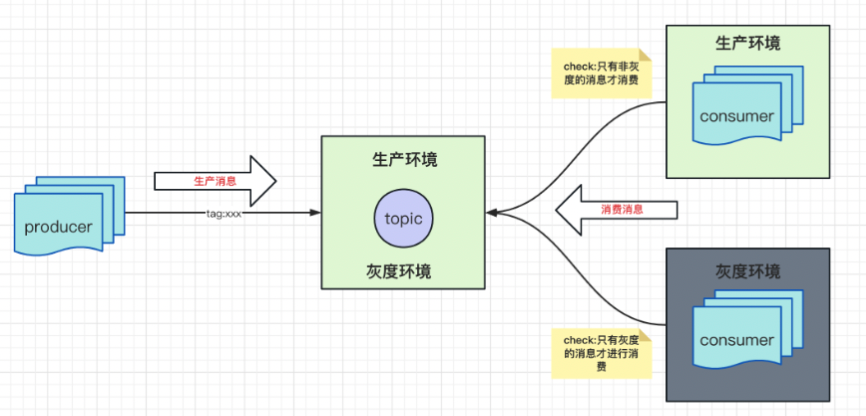
基于穩定性及監控考慮,微盟目前采用了獨立Topic的方案,
2.2 挑戰2:流量標簽如何傳遞
之前我們介紹過微盟在分布式鏈路的場景下,整個鏈路的Trace ID傳遞(支撐百萬商戶、千億級呼叫:微盟如何通過鏈路設計降本40%?),流量標簽的傳遞基本上可以借鑒這套流程,
全鏈路灰度主要傳遞的場景有兩個,一個是跨執行緒,一個是跨行程,
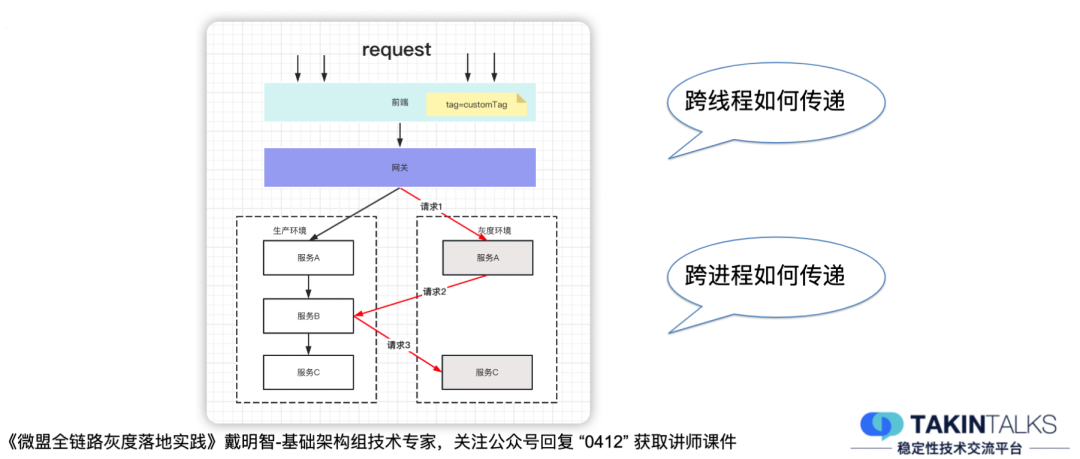
跨執行緒的傳遞:可以借助阿里開源的TTL完成傳遞,也可以借助Skywalking提供的SDK對執行緒進行封裝,這樣也可以完成,
跨行程的傳遞:跨行程的傳遞主要是找到流量標簽傳遞用的載體,Http的請求可以通過Header設定一個固定的Key來傳遞流量標簽,RPC可以通Double本身提供的RPC Contest來傳遞,而訊息的傳遞,可以通過在訊息中添加Attachment,或者設計一個完整的訊息協議,在訊息的Header中添加流量標簽,以此來完成流量標簽的傳遞,
2.3 挑戰3:如何快速支持多組件
我們需要對很多SDK做灰度能力的支持,而微盟的SDK特別多,且同一個SDK在不同的業務部門還有不同的版本,所以在全鏈路灰度時碰到了比較多的問題,以Double為例,Double 2.7中提供了標簽路由的功能,基于這個功能去做灰度呼叫會很簡單,但是微盟只有部分業務組用了這個版本,大部分還停留在2.6的版本,此時,如何快速讓這些組件都擁有灰度的能力就是一個很大的問題,
一般會有兩種方案,一種是SDK開發封裝,一種是JavaAgent,
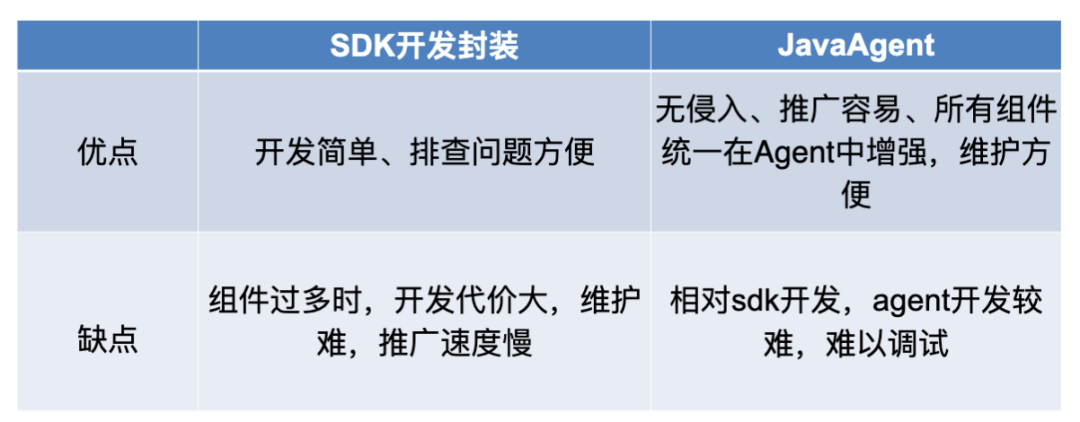
1)SDK開發封裝:基于每一個組件不同的SDK,不同的版本,去做一層封裝,然后去提供灰度能力的支持,它的優點是開發比較簡單,排查問題也比較方便,因為在本地就可以除錯,研發可以自行排查問題,然而,因為微盟的組件實在太多,這意味著需要開發的SDK會特別多,且后期還要去維護升級每一個SDK,推廣速度也會很慢,因此并不適合微盟,
2)JavaAgent:這種方式的好處是無侵入,可以把所有的SDK的增強邏輯都維護在同一個Java中,推廣也會比較容易,Agent在微盟應用比較廣泛,因此有一個專門的管理平臺,在管理平臺中可以對Agent做灰度推廣,比如先推廣到200個應用,然后逐步遞增到300個、400個等等,逐步覆寫到所有應用,這樣的好處是維護方便,但相對于SDK的開發,Agent的開發難度更高,且因為它難以除錯,導致一旦灰度鏈路中Agent出問題,就必須我們協同業務組去定位和解決,同時,還會有很多隱藏問題,比如,兩個或者多個Agent之間可能會觸發相互干擾,此時定位會比較難,這也是其缺點之一,
2.4 挑戰4:如何克服資料一致性
資料一致性是灰度場景下所有人都會碰到的共性問題,而且是比較麻煩的問題,
2.4.1 什么是資料一致性
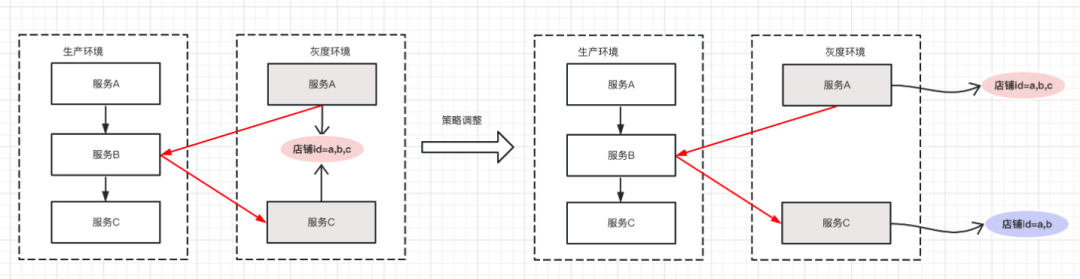
假設在灰度環境中,有服務A和服務C兩個應用,當前執行的策略是“店鋪ID=a,b,c”,流量進入灰度環境,假設此時通過中心化的策略平臺下發了一個新的策略,那么服務A和服務C之間可能會有延遲,即兩個應用不一定能同時接到新下發的策略,且這個延時的值是不確定的,此時會導致兩個服務執行兩個不同的策略,服務A執行的策略還是“店鋪ID=a,b,c”,而服務C執行的策略變成了“店鋪ID=a,b”,假設此時有一股流量“店鋪ID=c”進來,此時流量會進入服務A的灰度環境,以及服務C的基準環境,這時流量就會出現問題,這個就是策略一致性問題,
2.4.2 如何解決資料一致性問題
1)方案一:下發策略時添加生效時間戳,減少網路延遲帶來的影響,
也就是,讓服務A和服務C約定到達某個時間后同時生效,但是這種方式并不能保障強一致性,因為即使是統一的生效時間戳,不同機器上的時間也可能是不一致的,且會受到計時策略的影響,比如到期計時是每一毫秒判斷一次,還是每秒判斷一次,所以這種方案并不能保證資料的強一致性,
2)方案二:先下發策略,策略帶有版本號,確認所有應用接收到策略后,通過入口應用啟用指定版本的策略,
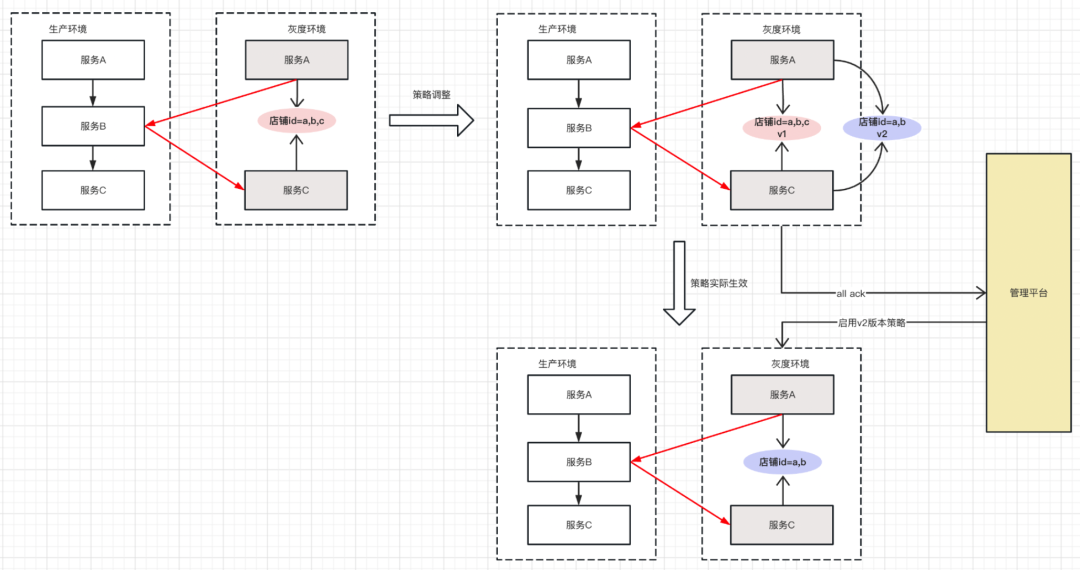
如圖所示,在做策略調整時,服務A和服務C會同時存在兩個版本的策略,假設這個灰度環境的流量入口應用是服務A,就可以通知服務A啟用V2版本的流量,確保服務A這條鏈路上涉及到的應用都收到V2版本的策略,這樣就能解決策略一致性問題,而業務資料一致性的問題,則需要業務部門自行解決,全鏈路灰度平臺很難解決應用中業務資料的一致性,所以在這里不做展開,
三、全鏈路灰度在微盟的落地效果如何?
3.1 整體架構
基于對微盟業務的思考,我們做了業務關鍵字的能力,這里不在于技術的實作,而在于這個訴求本身如何滿足,微盟全鏈路灰度平臺的整體架構分為 4 部分,互動層、業務層、策略層和路由層,
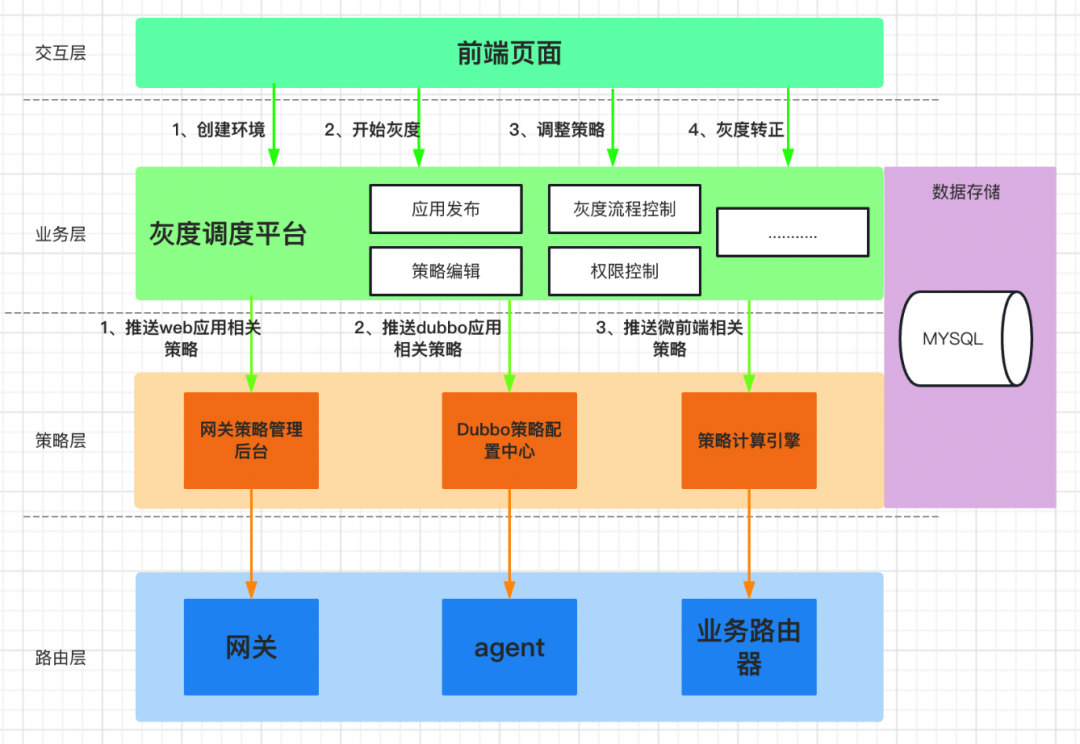
互動層主要就是UI界面,即產品入口,通過互動層可以進行創建環境、開始灰度、調整策略、灰度轉正等等一系列的操作,所有的請求都會被業務層,也就是灰度調度平臺接收到,然后在灰度調度平臺中做一系列操作,最核心的就是灰度策略和灰度轉正,所有的灰度策略都會被策略層處理,再按照特定的格式推送到路由層,最后由路由層去完成整個灰度流量的路由,
3.2 灰度生命周期
微盟設計了一個比較完整且復雜的灰度生命周期,如圖所示,
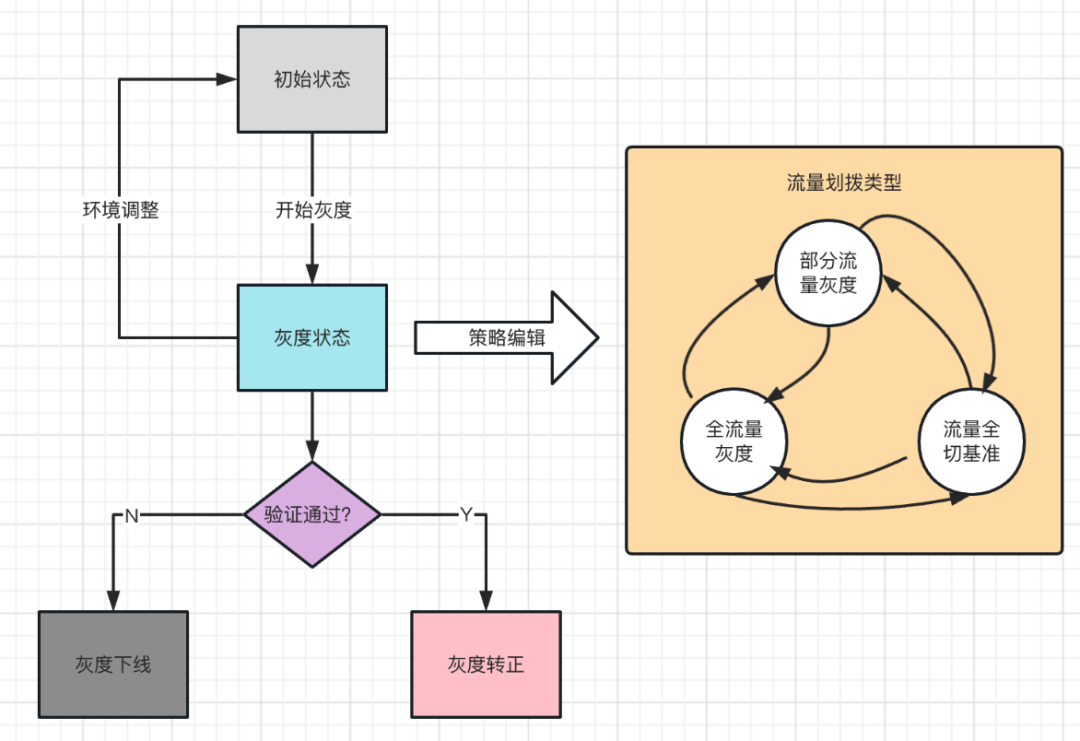
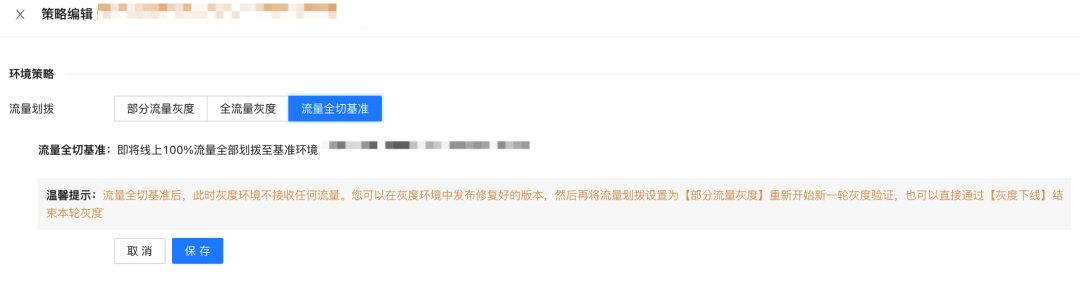
一個灰度環境在平臺上從創建到結束,要經過以上幾個流程,初始狀態下,需要把這個灰度環境內涉及的所有應用加進來后去創建環境,確認準備作業完成后,可以開始灰度的操作,此時環境就會流轉到灰度狀態,在灰度狀態下,可以做策略編輯,通過策略編輯去實作逐步放大流量的功能,對應文章片頭提到的,在微盟SaaS業務中,頭部商家的流量占了大部分,通過這種策略編輯就可以先讓少量商家承接灰度版本,然后再逐步放大流量,等流量到一定比例后再逐步引入頭部商家,這樣就保證了發布是足夠安全的,灰度狀態下,在流量逐步劃撥的程序中如果完全沒有問題,那么就可以發起一次轉正,把灰度版本完全轉換成基準版本,如果驗證有問題且不可修復的,也可以快速下線,把灰度占用的資源釋放掉,
3.3 實踐場景
3.3.1 實踐場景1:快速創建灰度環境
圖中展示的是一個已創建完畢的環境,在創建環境程序中,只需要關注兩點,一個是哪些應用需要參與到這次灰度中,另一個是灰度的策略是什么,錄入這些資訊后,即可開始灰度操作,
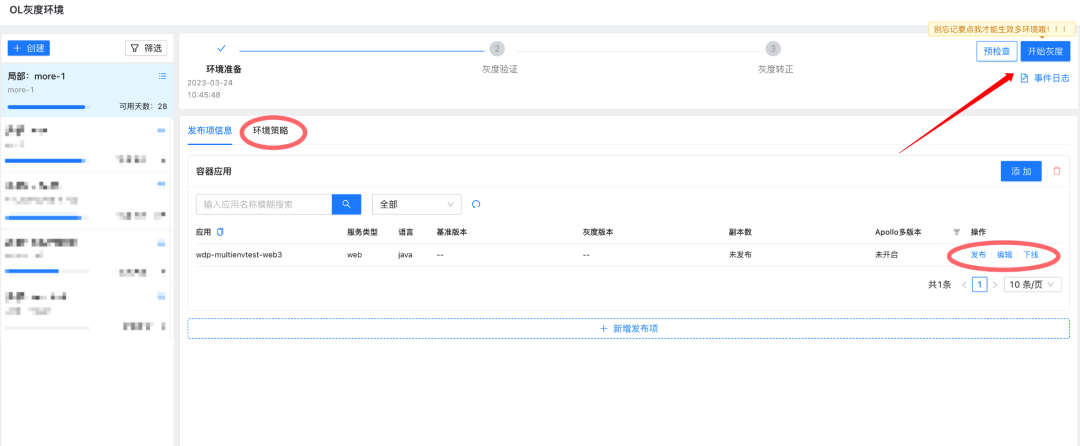
3.3.2 實踐場景2:配置流量策略
配置流量策略目前已經支持比較復雜的流量策略,按條件灰度,包含Http的Header、域名的Host、Per-stream,以及域名中某些特定值的灰度,這些都已能實作,按比例灰度,對某一個應用控制固定比例(如20%、30%)的流量進入灰度,這個目前也支持,
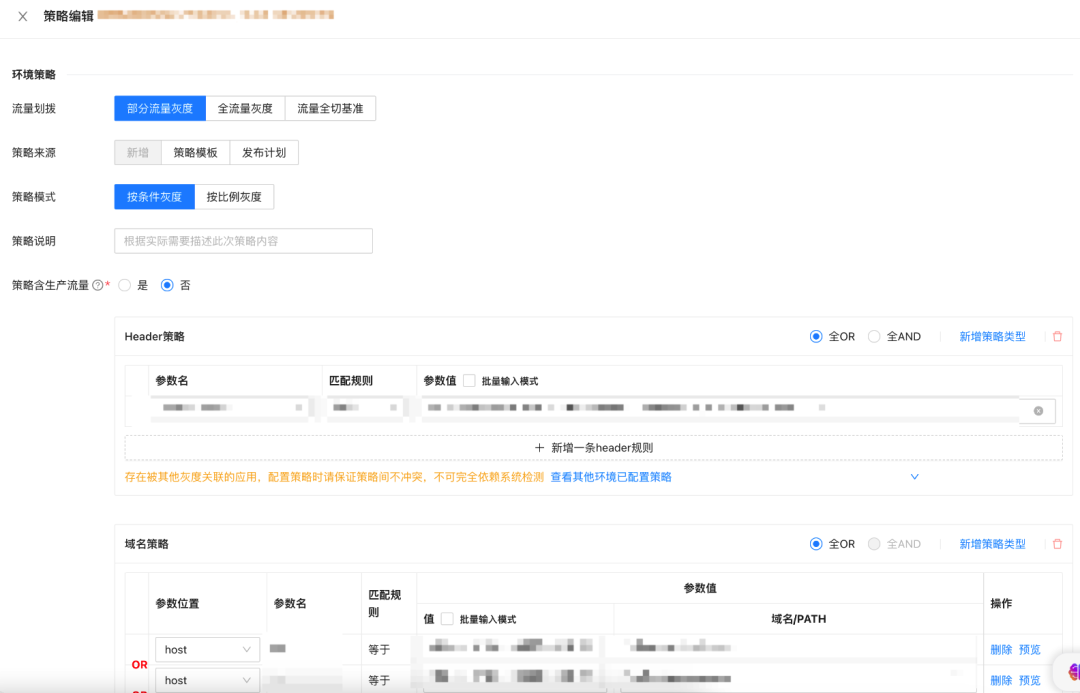
在配置流量策略的程序中,有一個需要大家關注的問題,流量調整程序中,需要對底層所用的資源做擴容,其中很核心的是需要對POD做擴容,且POD擴容應該要發生在把流量調度到灰度環境之前,因此平臺需要允許在每一次配置策略時,同步設定擴容比例,以此來保證它不會被突然的流量增長打崩,
3.3.3 實踐場景3:灰度推進到藍綠狀態
在微盟有一個強制要求,無論哪一次灰度,都必須在藍綠狀態做停留,
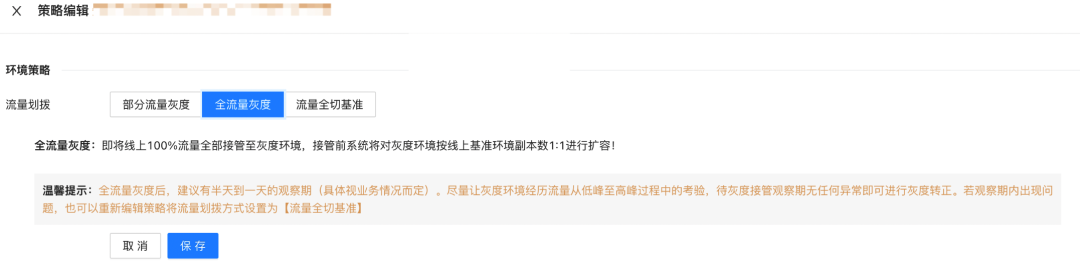
藍綠狀態在平臺上的體現,就是在策略編輯時,要進入全流量灰度的狀態,也就是所有的流量都進入灰度的狀態,之所以這么設計,是因為很多問題在20%、50%甚至80%流量狀態下,是無法得到完全驗證的,灰度必須要經歷一次完整的流量高峰并驗證沒有問題,才可以認為是安全的,而至于停留多久,平臺不做限制,由業務部門視業務情況自行決定,
3.3.4 實踐場景4:灰度轉正,灰度發布完成
藍綠狀態驗證完成后,此時可以發起灰度轉正,前面我們提到了資源隔離,灰度轉正的作用就是釋放這部分隔離的資源,把灰度版本發布到生產環境中去,
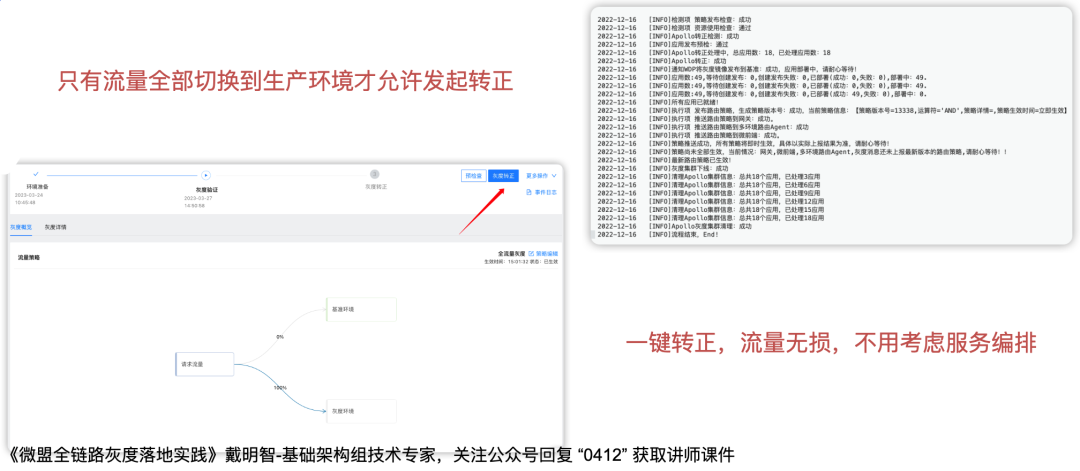
而此前,業務部門去執行一次大版本的發布,是需要考慮流量損失、服務編排等等一系列問題的,通過這個灰度轉正流程,可以確保流量無損,也無需業務方考慮服務編排,灰度轉正后才會把流量切回生產,以此來保證整個程序中對業務不造成影響,
3.3.5 實踐場景5:流量回切,灰度下線
在灰度的程序中可能會碰到一些例外的問題,如果問題比較嚴重,則可以利用流量回切能力,一鍵把流量快速切到生產環境,然后再選擇灰度下線,或者在灰度環境下繼續做驗證和修復,
3.4 落地效果
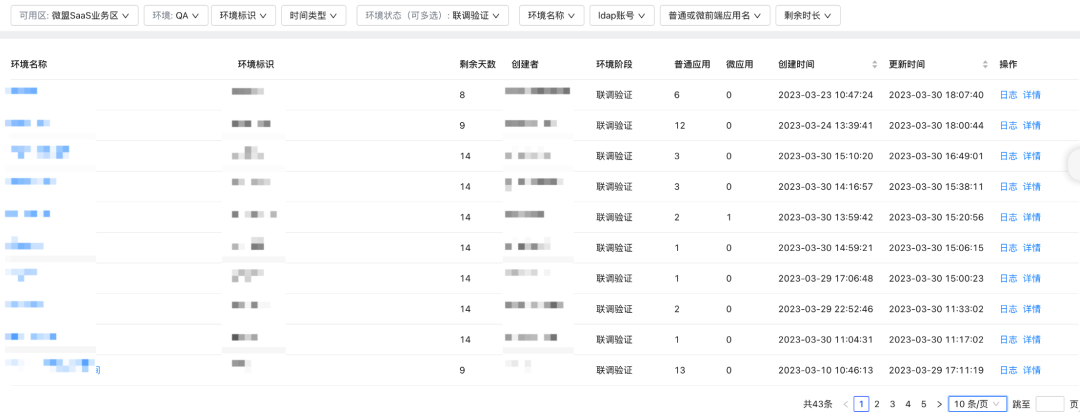
QA測驗環境從1套到80+套,支持多部門并行測驗,各業務團隊可以快速在平臺上隔離出一套獨立的環境,來解決開篇提到的并行測驗環境占用的問題,閑時會有40+環境并行,忙時有高達80+的環境同步運行,
內部覆寫率超過85%,目前應用基本完成接入灰度,覆寫率超過85%,
發布效率大幅提升,使用灰度發布后,沒有出現過因為發布導致線上流量受損,同時發布效率大幅提升,即使在大規模迭代的情況下,也沒有出現過通宵發布,
四、未來規劃
4.1 監控能力提升
目前微盟全鏈路灰度平臺已經能完全區分灰度鏈路和生產鏈路,但其監控能力與公司現有的監控能力相比,還有一些短板,比如POD的監控、指標、告警等,接下來都要重點去加強,
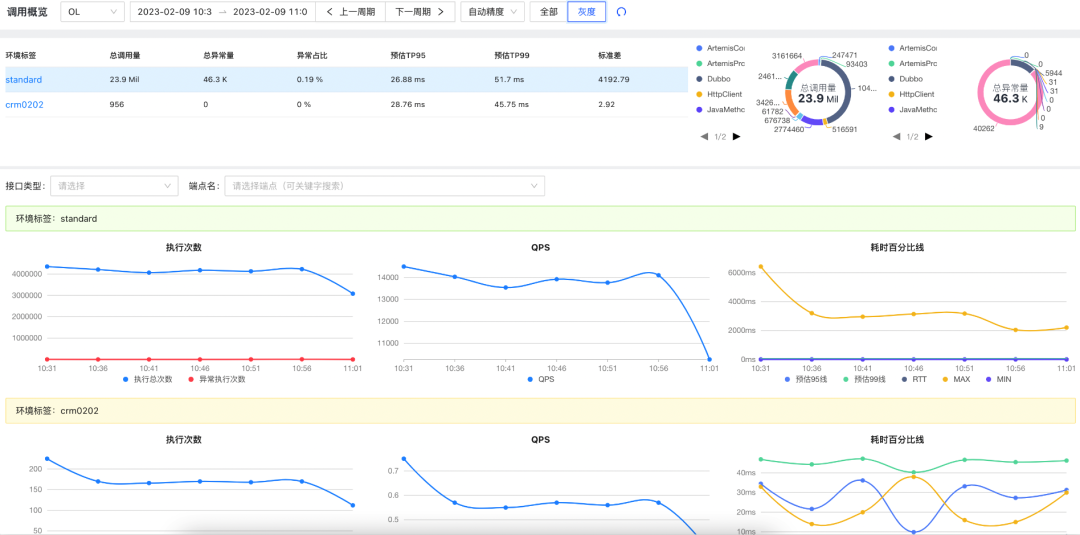
(微盟灰度平臺鏈路監控頁面)
4.2 開放能力
隨著全鏈路灰度平臺的推廣,我們收到了越來越多的訴求,比如小程式發布平臺、APP管理平臺、微盟特有生態系統盟鏈等等,也希望接入到灰度平臺中來,以此來降低對商家造成的影響,
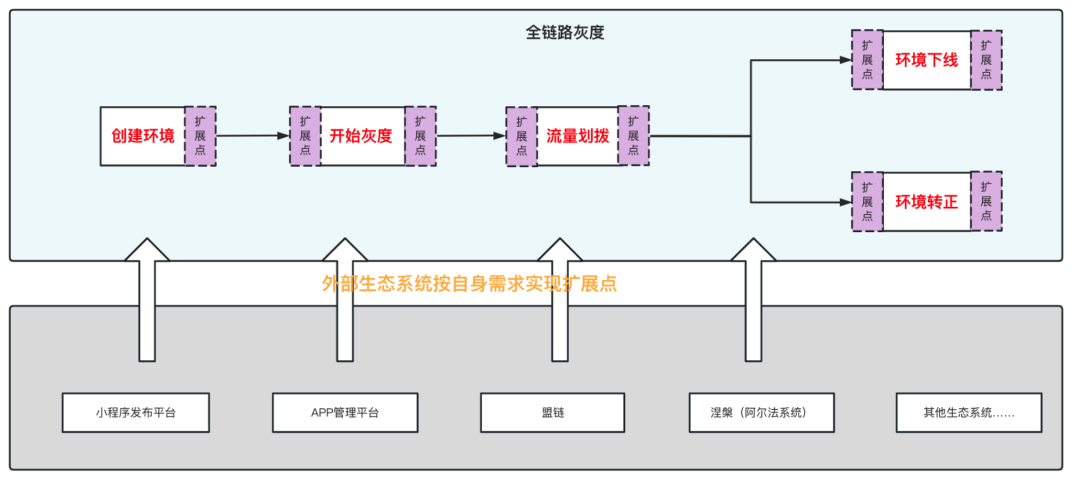
因此我們需要去做擴展能力,來支撐這些訴求,目前我們已經提供了兩套擴展機制,幫助外部生態系統接入平臺,當然這部分作業也正在優化迭代中,(全文完)
Q&A
1、灰度環境是不是單獨一套更好還是怎么樣?
2、訊息佇列隔離,為什么沒有考慮不同的消費組?
3、Redis怎么進行灰度?
4、怎么控制灰度的影響范圍?
更多詳細內容,歡迎點擊“閱讀全文”,觀看完整版解答!
本文由博客一文多發平臺 OpenWrite 發布!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551471.html
標籤:其他
上一篇:開啟云上高效開發新時代,華為云開發者日東莞站成功舉辦
下一篇:返回列表